
최근 저는 AI 교육을 받고 있습니다. 아직은 무슨말인지 모를 것들 80%, 알겠는데 혼자 해보라고 하면 못할 것들이 19%, 혼자 할 수 있는 것이 1%쯤 됩니다.😭
아직 제가 하고 있는 작업이 'AI'라고 하긴 뭣하지만, Data를 탐색하고 전처리하고 분석하는 과정을 하나의 Pipeline으로써 연습하고자 'Kaggle 탐방기'라는 이름으로 시리즈를 만들까 합니다.
왜 하필 첫 시작이 'Titanic'이냐?
약 2~3년 전, 대학원 전공자분들 사이에서 빅데이터분석 수업을 들은 적이 있습니다. 전공자 대상 수업이라 뭐 하나 쉽지 않았던게, Jupyter Notebook 실행을 위해 Conda도 Docker container로 설치하고, 전공 강의다보니 교수님께서 다들 알고 있다는 가정하에 진도를 나가시는 바람에 한국어 강의임에도 영어 원어 수업 같아 너무 힘들었습니다. (교수님 잘 해주셨는데 정말 죄송해요🙇)
그때 처음으로 실습한 데이터셋이 이 Titanic 입니다. 그때는 아무것도 모르고 코드를 Ctrl+c & Ctrl+v 하기 바빴는데, 이젠 제법 머리가 컸다고 어떤 결과를 얻기 위해 하는지 정도는 알게 되었기 때문에 지금 제 수준에 가장 적당하다고 생각하였습니다.
지식이 늘수록 코드도 간결해지고 분석 수준도 높아질거라 생각됩니다만, 지금은 어디까지나 '초보자의' 수준에서 진행한 분석이라는 것을 숙련자분들이시라면 감안해주시길 바랍니다.
1. 데이터 로딩 & 확인하기
일단 라이브러리는 pandas 원툴입니다. 초보자이기 때문입니다.
import pandas as pd※ 일반적으로 'pandas'를 불러올때는 약어로 'pd'를 많이 쓴다고 합니다.
이제 데이터를 불러옵니다. 데이터는 작성하고 있는 파이썬 문서와 같은 폴더 내에 있으면 별도의 경로지정을 하지 않아도 됩니다.
# 데이터 불러오기
dataframe = pd.read_csv('Titanic-Dataset.csv')
이제 데이터 확인을 할건데, 데이터 확인의 경우
컬럼 확인, 1차 데이터 형태 확인, 인덱스 확인, 컬럼별 데이터 타입, 데이터프레임 형태
부터 확인할겁니다.
df = dataframe # df는 곧 데이터프레임이라 선언
df.head() #데이터의 첫 5행 출력이를 실행시키면
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
이런 테이블이 나옵니다. (캡쳐하면 표가 짤릴까봐 html로 재구성했습니다.)
컬럼명만 따로 추출하고 싶으면
df.columns명령어로 추출합니다. 그러면
 이런 결과값이 출력됩니다. 컬럼명들과 함께 컬럼명 타입이 'object'라는 것까지 확인됩니다. 컬럼들이 모두 문자타입이군요.
이런 결과값이 출력됩니다. 컬럼명들과 함께 컬럼명 타입이 'object'라는 것까지 확인됩니다. 컬럼들이 모두 문자타입이군요.
각 컬럼별 설명은 다음과 같습니다.
| 컬럼명 | 설명 |
|---|---|
| PassengerID | 승객 ID(고유 구분자) |
| Survived | 생존 여부 (1: 생존, 0: 사망) |
| Pclass | 객실 등급 (1 → 2 → 3 등급 순) |
| Name | 승객명(성 + 호칭 + 이름 / 기혼 여성은 결혼 전 성 포함) |
| Sex | 성별 (male / female) |
| Age | 나이 |
| SibSp | 함께 탑승한 형제자매/배우자 수 |
| Parch | 함께 탑승한 부모/자녀 수 |
| Ticket | 티켓 ID |
| Fare | 요금 |
| Cabin | 객실 번호 |
| Embarked | 출항 항구 |
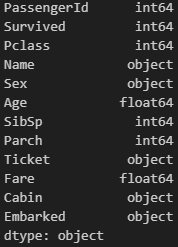
이제, 컬럼별 데이터 타입도 한번 살펴보겠습니다. 타이타닉 데이터셋은 각 열이 숫자 혹은 문자로만 이루어져서 비교적 깔끔하고, 심지어 정수형(int), 실수형(float)까지 구분되어 있는 것이 특징입니다. 여러모로 초보자가 접근하기 쉬운 형태입니다.
dt.types그럼 아래와 같은 결과값이 출력됩니다.
이제 데이터프레임 형태(행, 열)도 살펴보겠습니다.
df.shape그럼 다음과 같은 결과가 출력됩니다.
(891, 12)
891개 행, 12개의 열로 구성되어 있군요.
이제 컬럼별로 고유데이터 숫자를 확인해보겠습니다. 여기서 고유데이터 수 ≠ 데이터 전체의 수가 아님을 유념해야 합니다. 범주형 데이터는 해당 데이터가 여러번 나올 수 있으니까요.
df.nunique(axis=0, dropna=False)여기서 굳이 axis=0을 붙인 이유는 각 열의 모든 행에 동작하게 하기 위함이고, NaN 혹은 Null, N/A 등의 결측치가 존재한다면 무시하지 않고 포함하겠다는 의미입니다.
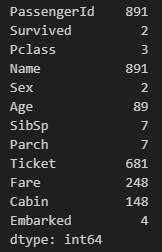 결과는 이렇게 출력되는군요. 확실히 범주형/순서형 데이터들은 상대적으로 낮은 수치를 보입니다.
결과는 이렇게 출력되는군요. 확실히 범주형/순서형 데이터들은 상대적으로 낮은 수치를 보입니다.
여기까지가 데이터 확인 과정이었습니다. 이제 데이터 전처리 과정으로 넘어가 보겠습니다.
2. 데이터 전처리
데이터 전처리 과정은 데이터를 '분석 가능한 형태로 처리'하는 과정인데, 이 과정은 여러가지가 있지만 일단 여기에서는 공백이나 null, NaN, N/A 등의 '결측치'와 중복값 위주로 보겠습니다. 처리를 하려면 먼저 확인을 해봐야겠죠.
먼저 중복값 확인입니다.
df.duplicated(subset=None, keep='first')지금 이 코드는 열 단위로 중복을 체크하면서 행 전체를 확인하는 과정입니다.
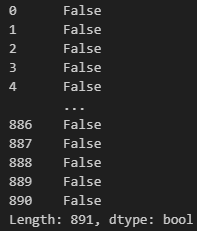 음.. 이렇게 봐서는 어느 행에(혹은 열에) 중복값이 있는지 한 눈에 들어오지 않는군요. 하지만 이렇게 하는 이유는 중복되는 행이 여러 개 있을 경우 '첫 번째 행만
음.. 이렇게 봐서는 어느 행에(혹은 열에) 중복값이 있는지 한 눈에 들어오지 않는군요. 하지만 이렇게 하는 이유는 중복되는 행이 여러 개 있을 경우 '첫 번째 행만 True가 아니고 → 나머지 중복되는 행들이 True가 된다'는 원리를 이용한 것입니다. 그러니 일단 없다고 봐야겠네요.
다른 방법으로는 람다lambda함수를 활용해서 컬럼별 중복값의 합을 계산하는 방법도 있습니다.
df.apply(lambda col: col.duplicated().sum())코드를 실행시켜보니 아래와 같은 결과가 나옵니다.
 아마 승객ID는 각각 고유의 값이니 중복값이 없을거고, 이름도 마찬가지일 겁니다. 생존여부는 생존/사망 중 하나이므로 중복값이 있는게 당연할테고, 아마 객실등급, 성별, 나이 등의 다른 숫자 혹은 순서형 데이터들도 마찬가지겠죠?
아마 승객ID는 각각 고유의 값이니 중복값이 없을거고, 이름도 마찬가지일 겁니다. 생존여부는 생존/사망 중 하나이므로 중복값이 있는게 당연할테고, 아마 객실등급, 성별, 나이 등의 다른 숫자 혹은 순서형 데이터들도 마찬가지겠죠?
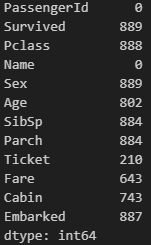
그럼 이제 결측치로 넘어가보겠습니다. 결측치 확인 메써드는 isna(), isnull(), isnan() 등 끌리는 대로 쓰시면 됩니다. 저는 isna가 맘에 들어서(1자라도 짧아서) isna를 쓰고 있습니다.😅
df.isna()실행을 시켜보면,
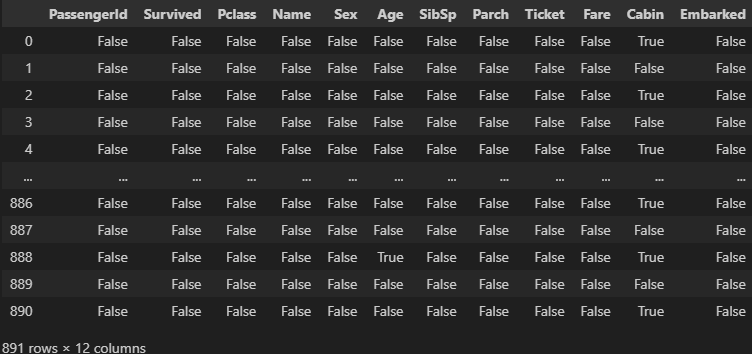 역시나 모르겠습니다. 대충 보니 Cabin쪽에
역시나 모르겠습니다. 대충 보니 Cabin쪽에 True가 간간히 보이긴 하는데, 다른 열엔.. 정말 없을까요?
다행히 결측치는 중복값보다 훨씬 간단하게 열별로 확인할 수 있는 방법이 있습니다.
df.isna().sum()뒤에 .sum()만 붙여주시면 됩니다. 합계를 알고싶다는 메써드지요. 지금같은 형태는 체인처럼 결합해서 쓴다 하여 메써드 체이닝(method chaining)이라고 합니다.
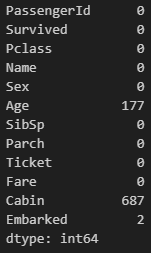 아주 깔끔하게 열별 결측치를 확인할 수 있습니다.
아주 깔끔하게 열별 결측치를 확인할 수 있습니다.
특정 열만 보고싶으면 아래와 같이 쓰면 되긴 합니다. print를 붙인 이유는 Jupyter Notebook 에서 print를 안붙이고 두 줄을 실행시킬 경우 먼저 실행시킨 코드가 씹히는 경우가 있어서 입니다.
print(df['Age'].isna().sum())
print(df['Cabin'].isna().sum())이러면 'Age'열이나 'Cabin'열의 결측치만 따로 숫자로 볼 수 있습니다.
이제 Age열과 Cabin 열에 결측치가 있는것을 알았으니, 결측치를 대체하기 위한 방법을 알아봅시다. 사실 결측치는 제거하는게 가장 편하긴 한데요, 타이타닉 데이터셋의 경우 데이터가 891줄 뿐이라 가뜩이나 '빅데이터'라 하기도 애매한데 거기서 Age 열에서 발견한 결측치를 제거한다고 177줄을 더 제거해버리면 소중한 데이터가 날아가 버리니, 일단 대체하는 방법을 생각해보겠습니다.
이를 위해 일단 각 열별로 간단한 기술통계를 돌려보겠습니다.
df.describe()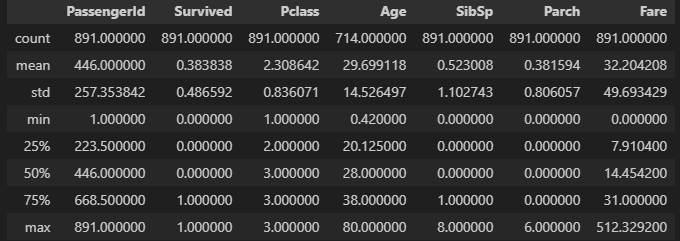 위에서부터 count는 데이터의 갯수이고, mean은 해당 열 데이터의 평균값, std는 아마 표준편차일겁니다. min은 최소값, max는 최대값이고 25%, 50%, 75%는 정규분포에서 상위 25, 50, 75%에 분포하는 값들입니다.
위에서부터 count는 데이터의 갯수이고, mean은 해당 열 데이터의 평균값, std는 아마 표준편차일겁니다. min은 최소값, max는 최대값이고 25%, 50%, 75%는 정규분포에서 상위 25, 50, 75%에 분포하는 값들입니다.
결측치 대체를 하는데 왜 갑자기 쌩뚱맞게 통계를? 이라는 의문이 생길 수 있습니다.
데이터의 성격이나 분석 목적에 따라 다르겠지만, 대부분 결측값을 삭제하지 않는 경우 대체할 값을 ① 해당 열의 평균 ② 해당 열의 최빈값(가장 많이 나오는 값) ③ 해당 열의 중앙값(평균과는 다름) 중에서 택하거나 통계 결과값중에서 택하기 때문입니다.
그렇다면 'Age'열의 저 177개 결측치는 무엇으로 대체할 수 있을까요?
일단 '나이'라는 항목 특성상 평균으로 대체하기엔 너무 위험합니다. 0.4세에서 80세라는 편차가 존재하는 그룹의 나이 평균이 과연 29.7세일까요?
그렇다면 다음으로 중앙값은 얼마일까요?
print(df['Age'].median())'28'이 나옵니다. 단순 수학계산으로 해보면 0~80의 절반인 40이 나올 것 같은데 28이 나온것도 의외입니다. (수포자의 알 수 없는 수학의 세계🙄)
그래서 일단 제가 생각한 방법은 객실 등급과 성별을 조합한 중앙값의 조건부 대체입니다.
groupby(['Pclass', 'Sex'])['Age']로 객실등급과 성별 조합별로 나이를 묶어준 뒤, transform을 이용해 각 그룹에 같은 길이의 결과를 되돌려받으면서 lambda x: x.fillna(x.median())로 그룹별 중앙값으로 결측치를 채우는 것입니다. 이렇게 하면 각 승객은 “자기와 같은 등급·성별 그룹”의 중앙값으로 나이가 보정될 것입니다.
df['Age'] = df.groupby(['Pclass', 'Sex'])['Age'].transform(lambda x: x.fillna(x.median()))조금 쉽게 풀어쓰면,
1등석 여성이면 → 평균 나이가 낮을 것이다.
3등석 남성이면 → 평균 나이가 높을 것이다.
이러한 가정을 프로그램 언어로 표현한 것입니다.
객실번호의 경우 분석에 크게 의미가 있는 변수가 아니라서 Unknown = '그 자체가 정보'라 간주하고 모두 'Unknown' 처리하였습니다.
df['Cabin'] = df['Cabin'].fillna('Unknown')출항항구(Embarked)의 경우 이 또한 손님의 객실 등급이나 요금에 따라 각각 다른 곳에서 탑승했다고는 하는데, 이 또한 크게 의미가 없어 고유값 'S', 'C', 'Q' 중 최빈값으로 대체하였습니다.
df['Embarked'] = df['Embarked'].fillna(df['Embarked'].mode()[0])여기까지 하면 이제 '분석 가능한 데이터 만들기' 과정이 어느 정도 마무리 되었습니다.
물론 이상치(튀는 값) 탐색 및 처리, 데이터 타입 오류, IQR, Z-Score, 도메인 검토, 범주형 인코딩, 스케일링, 정규화, 파생변수 생성, 불균형 처리, Feature Selection 등 다양한 전처리 과정이 있지만 친절한(?) Titanic 데이터 덕분에 이 정도로 마무리해도 될 것 같습니다.
물론, 데이터 형태가 모두 문자형이라서 숫자 데이터를 정수 혹은 실수형으로 바꾸는것도 필요해보이긴 합니다만, 나중에 ColumnTransfomer를 통해 한번에 자동 전처리 할거라 여기서는 생략하겠습니다.
1-2에서는 본격적으로 데이터를 씹뜯맛즐 해보며 데이터를 통해 알아낸 것들을 풀어나가는 시간을 가져보도록 하겠습니다.
