
"본격적으로 데이터를 씹뜯맛즐 해보겠다”고 선언해 놓고, 며칠동안 귀차니즘에 빠져 다른 쉬운 글부터 쓰고 딴짓만 실컷 하다 왔습니다.
이번 편에서는 각 변수들(종속변수)과 생존 여부(독립변수)가 어떤 관계를 보이는지, 데이터 분석을 통해얻을 수 있는 인사이트가 무엇인지 확인해보는 시간을 갖도록 하겠습니다.
1. 일변량 평균 비교하기
일단 전체 생존률부터 확인해봅시다.
# 전체 생존률 (0은 사망, 1은 생존)
df['Survived'].value_counts(normalize=True)Survived
0 0.616162
1 0.383838
Name: proportion, dtype: float64위와 같은 결과가 출력됩니다. 약 61.6%가 사망하고 38.3%가 생존하였군요. 안타깝습니다. 명복을 빕니다.
그 다음은 성별별 생존률 평균을 보겠습니다.
df.groupby('Sex')['Survived'].mean()groupby 메써드를 통해 sex(성별) 항목을 그룹핑하고, 생존률과의 평균을 계산합니다.
Sex
female 0.742038
male 0.188908
Name: Survived, dtype: float64다음과 같은 결과가 출력됩니다. 여성이 74.2%로 훨씬 높은데, 아마 당시에 여성과 아이를 먼저 구조하기 위해 탑승객들이 백방으로 노력한 덕분일 것 같다는 생각이 듭니다.
다음은 사회적 계층의 영향을 보고자 합니다.
df.groupby('Pclass')['Survived'].mean()반드시 그런것은 아니겠지만, 사회적 계층이 높으면(부유한) 상대적으로 높은 등급의 객실을 예약했을거라는 가정하에, Pclass(객실 등급)을 그룹핑하고 생존률과의 평균을 계산합니다.
Pclass
1 0.629630
2 0.472826
3 0.242363
Name: Survived, dtype: float641등석 62.9%, 2등석 47.2%, 3등석 24.2% 순으로 나왔습니다. 꼭 부유한 사람이 생존률이 높다기 보다는, 당시 객실 등급이 높을수록 상대적으로 갑판에 가까운 쪽에 편성이 되어 있었기 때문에 배의 하부에 있는 3등석 승객보다 탈출이 용이했기 때문인 것으로 생각됩니다.
이를 요금 구간으로도 확인해볼까요?
df['FareGroup'] = pd.qcut(df['Fare'], 4)
df.groupby('FareGroup')['Survived'].mean()요금 구간을 ~7.91달러, 7.91~14.454달러, 14.454~31.0달러, 31.0~512.319달러로 나누고 생존률을 확인해 보았습니다. 제가 그렇게 정한건 아니고 객실 등급에 따라 저렇게 요금이 차등 지불되는 듯 합니다.
FareGroup
(-0.001, 7.91] 0.197309
(7.91, 14.454] 0.303571
(14.454, 31.0] 0.454955
(31.0, 512.329] 0.581081
Name: Survived, dtype: float64이것도 1등석 승객의 생존률과 비슷한 경향을 보입니다. 상대적으로 빠져나오기 힘든 곳에 위치한 승객들의 생존률이 많이 낮은거라고 생각됩니다.
나이의 경우 고윳값이 워낙 다양한지라, 구간화 연습 겸 AgeGroup 컬럼을 하나 만들어서 나이 구간별 생존률 평균을 계산해보도록 하겠습니다.
df['AgeGroup'] = pd.cut(df['Age'], bins=[0,10,20,40,60,80], labels=['0-10','10-20','20-40','40-60','60-80'])
df.groupby('AgeGroup')['Survived'].mean()가장 최소 나이(?)가 0.24세, 최고 나이가 80세임을 감안하여 각 구간을 0-10, 10-20, 20-40, 40-60, 60-80 으로 나누고 그룹별 생존률 평균을 구해보았습니다.
AgeGroup
0-10 0.593750
10-20 0.382609
20-40 0.364769
40-60 0.390625
60-80 0.227273
Name: Survived, dtype: float640~10세 의 생존률이 59.3%로 가장 높게 나왔고, 6~80세의 생존률이 22.7%로 가장 낮게 나왔습니다. 0~10대가 가장 높은 것은 여자와 어린이 중심으로 구조하였기 때문이라고 생각했으며, 60~80대가 가장 낮다는 점에서 노인들이 양보하였거나 체력 혹은 기력 부족으로 인해 생존률이 저하되었을 것으로 추측하였습니다.
실제로 어린 승객에게 구명조끼를 양보하고 1등석 부부가 나란히 침대에서 생을 마감했다는 슬픈 일화도 존재하죠. 이러한 데이터가 일화의 사실성에 힘을 실어주는 것 같습니다.
다음은 가족규모 기준으로 그룹핑하여 생존률을 확인해 보았습니다.
df['FamilySize'] = df['SibSp'] + df['Parch'] + 1
df.groupby('FamilySize')['Survived'].mean()여기서 SibSp는 함께 탑승한 형제자매/배우자 수, Parch는 함께 탑승한 부모/자녀 수 기준이라고 하였는데, 이를 모두 그룹핑하여 FamilySize라는 하나의 그룹으로 하여 그룹별로 생존률 평균을 구하였습니다. 여기서 '+1' 이 중요합니다. '함께 탑승한' 이기 때문에 대부분 나를 제외하고 숫자를 적습니다. 거기에 '나'까지 포함되어야 가족 구성원의 숫자가 맞게 되죠. 정확한 분석을 위해 꼭 필요한 항목입니다.
FamilySize
1 0.303538
2 0.552795
3 0.578431
4 0.724138
5 0.200000
6 0.136364
7 0.333333
8 0.000000
11 0.000000
Name: Survived, dtype: float64사실 가족 구성원 숫자가 무슨 의미가 있겠냐마는, 당시 탑승객 그룹은 아마 2~4인 가족 구성원이 제일 많았던 것으로 추정됩니다.
2. 다변량 평균 비교하기
이제부터는 변수를 한번에 몇개씩 조합하여 간단한 상관관계를 함께 확인해보겠습니다. 먼저 성별 + 객실 등급 조합입니다.
df.groupby(['Sex','Pclass'])['Survived'].mean()이미 그룹핑이 되어있어서 분석하기도 용이합니다. 결과를 보겠습니다.
Sex Pclass
female 1 0.968085
2 0.921053
3 0.500000
male 1 0.368852
2 0.157407
3 0.135447
Name: Survived, dtype: float64위의 일변량 분석에서 보인 경향이 여기서도 나타납니다. '여성'이면서 '상등객실' 에 있던 사람들의 생존률이 높군요. 높은 등급 객실에 있던 사람들이 많이 빠져나가기도 했지만, 객실 등급에 상관없이 남성분들은 본인들의 생존보다 타인의 구조를 우선시했던 것 같습니다.
이번에는 성별 + 나이 그룹의 조합입니다.
df.groupby(['Sex','AgeGroup'])['Survived'].mean()역시 그룹핑이 되어있던 부분이라 결과 도출이 비교적 쉽습니다.
Sex AgeGroup
female 0-10 0.612903
10-20 0.739130
20-40 0.756614
40-60 0.755556
60-80 1.000000
male 0-10 0.575758
10-20 0.144928
20-40 0.166220
40-60 0.192771
60-80 0.105263
Name: Survived, dtype: float64전연령에 걸쳐 여성의 생존률이 매우 높은 반면, 남성 생존률은 0~10세 구간의 어린이들 생존률도 절반을 조금 넘는 수준입니다. 가슴이 아프네요.
객실등급 + 요금 조합은 어짜피 거기서 거기일것 같아 넘어가겠습니다.
이제 다변량 테스트를 돌려보겠습니다. 먼저 객실등급 & 성별 & 나이 부터 수행해봅니다.
result = (
df.groupby(['Pclass', 'Sex', 'AgeGroup'], observed=True)['Survived']
.mean()
.reset_index()
)
print(result.to_string(index=False))결과를 볼까요?
Pclass Sex AgeGroup Survived
1 female 0-10 0.000000
1 female 10-20 1.000000
1 female 20-40 0.981481
1 female 40-60 0.958333
1 female 60-80 1.000000
1 male 0-10 1.000000
1 male 10-20 0.400000
1 male 20-40 0.415385
1 male 40-60 0.342105
1 male 60-80 0.083333
2 female 0-10 1.000000
2 female 10-20 1.000000
2 female 20-40 0.914894
2 female 40-60 0.846154
2 male 0-10 1.000000
2 male 10-20 0.100000
2 male 20-40 0.073529
2 male 40-60 0.055556
2 male 60-80 0.333333
3 female 0-10 0.500000
3 female 10-20 0.520000
3 female 20-40 0.534091
3 female 40-60 0.000000
3 female 60-80 1.000000
...
3 male 10-20 0.129630
3 male 20-40 0.125000
3 male 40-60 0.074074
3 male 60-80 0.000000너무 길어서 짤렸습니다. 하지만 경향성을 보는데는 무방합니다. 여태까지 일변량, 이변량으로 확인한 내용과 거의 비슷한 것 같습니다.
이제 본격적으로 모델을 태워보겠습니다.
3. 머신러닝 모델 돌려보기
제가 채택한 모델은 로지스틱 회귀분석, 랜덤포레스트 분류, 서포트 벡터 머신(SVM), 다층 신경망(MLP Neural Network) 4가지 입니다. 각 모델은 다음과 같은 데이터에 특화되어 있습니다.
-
로지스틱 회귀(Logistic Regression): 선형적으로 구분되는 데이터에서 빠르고 안정적으로 확률 기반 예측을 제공합니다.
-
랜덤포레스트(Random Forest Classifier): 여러 개의 결정트리를 결합해 복잡한 패턴도 비교적 잘 잡아내며 과적합에 강합니다.
-
서포트 벡터 머신(SVM): 고차원 공간에서 경계를 그리는 데 강해, 데이터가 깔끔하게 분리되지 않아도 우수한 분류 성능을 보여줍니다.
-
(다층 퍼셉트론(MLP Neural Network): 비선형 패턴을 학습하는 데 강점을 보이며, 데이터 내부 구조가 복잡할 때 유연한 모델링이 가능합니다.
Titanic 데이터는 범주형·수치형 변수가 섞여 있고, 변수 간 관계도 단순하지 않기 때문에 하나의 모델만으로 전체 패턴을 판단하기에는 무리가 있습니다. 그래서 서로 다른 관점에서 데이터를 바라보는 네 가지 모델을 골랐습니다.
일단 Scikit-learn을 import 하고, 모델들을 한꺼번에 불러온 다음, X축-y축을 분리하고 열 구분을 해보겠습니다.
# 사이킷런 import
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score
# X, y 분리
X = df.drop('Survived', axis=1)
y = df['Survived']
# 범주형/수치형 열 구분
categorical_cols = ['Sex', 'Embarked', 'AgeGroup', 'FareGroup']
numeric_cols = ['Age', 'Fare', 'FamilySize', 'Pclass', 'SibSp', 'Parch']머신러닝을 문제 없이 돌리기 위해서는 모든 열이 다 수치형이어야 하지만, 자동 전처리를 위해 Column Transformer를 돌려보도록 하겠습니다. Column Transfomer 란 수치형 컬럼에는 이 전처리, 범주형 컬럼에는 저 전처리를 적용해주고 마지막에 다시 합쳐주는 자동 전처리 장치입니다. 제가 아직 배움이 짧아 이 전처리와 저 전처리에 무엇이 들어가는지는 나중에 천천히 설명하겠습니다.
preprocess = ColumnTransformer(
transformers=[
('num', StandardScaler(), numeric_cols),
('cat', OneHotEncoder(drop='first'), categorical_cols)
]
)자, 이제 모델을 돌려봅니다. 동시에. 한꺼번에.
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.neural_network import MLPClassifier
models = {
"Logistic Regression": LogisticRegression(max_iter=200),
"Random Forest": RandomForestClassifier(n_estimators=200, random_state=42),
"SVM": SVC(kernel='rbf', C=1, gamma='scale'),
"Neural Network": MLPClassifier(hidden_layer_sizes=(16, 8), max_iter=1000, random_state=42)
}
results = {}
for name, model in models.items():
pipeline = Pipeline(steps=[('preprocess', preprocess),
('model', model)])
pipeline.fit(X, y)
y_pred = pipeline.predict(X)
acc = accuracy_score(y, y_pred)
results[name] = acc
results(내장 GPU가 없는 노트북이나 GPU환경이 아닌곳에서는 따라하지 마세요.. 저는 데스크톱이에요...)
단순 성능 결과를 출력해봅니다.
{'Logistic Regression': 0.8114478114478114,
'Random Forest': 0.9809203142536476,
'SVM': 0.8383838383838383,
'Neural Network': 0.8832772166105499}Random Forest 모델이 약 98.0% 성능을 발휘하며 가장 성능이 좋은 모델로 나타났습니다. 이것만 봐서는 믿을 수 없어서 비교모델을 다시 세팅하고 교차검증 + F1-score 평가를 진행해보겠습니다.
# 비교모델 다시 세팅
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.svm import SVC
models = {
"Logistic Regression": LogisticRegression(max_iter=500),
"Random Forest": RandomForestClassifier(n_estimators=200, random_state=42),
"SVM": SVC(kernel='rbf', C=1, gamma='scale'),
"Neural Network (MLP)": MLPClassifier(hidden_layer_sizes=(16, 8), max_iter=800, random_state=42)
}
# 교차검증 + F1-score 평가
from sklearn.pipeline import Pipeline
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
results = []
for name, model in models.items():
pipeline = Pipeline(steps=[
('preprocess', preprocess),
('model', model)
])
# Accuracy 교차검증
acc_scores = cross_val_score(pipeline, X, y, cv=cv, scoring='accuracy')
# F1-score 교차검증
f1 = make_scorer(f1_score)
f1_scores = cross_val_score(pipeline, X, y, cv=cv, scoring=f1)
results.append({
"Model": name,
"Accuracy (CV Mean)": acc_scores.mean(),
"F1-score (CV Mean)": f1_scores.mean()
})
results결과를 보겠습니다.
[{'Model': 'Logistic Regression',
'Accuracy (CV Mean)': np.float64(0.8013621241604418),
'F1-score (CV Mean)': np.float64(0.7340794958272673)},
{'Model': 'Random Forest',
'Accuracy (CV Mean)': np.float64(0.8305128366078713),
'F1-score (CV Mean)': np.float64(0.7743982449716935)},
{'Model': 'SVM',
'Accuracy (CV Mean)': np.float64(0.8282656455966355),
'F1-score (CV Mean)': np.float64(0.7628940832868203)},
{'Model': 'Neural Network (MLP)',
'Accuracy (CV Mean)': np.float64(0.811436821291821),
'F1-score (CV Mean)': np.float64(0.7421206421715436)}]역시 Random Forest가 정확도 및 F1-score 측면에서 성능이 좋군요. 하지만 83.1%의 정확도로 누구 코에 붙이냐! 하며 다른 모델을 불러와 봅니다.
Kaggle 데이터 단골 손님인 LightGMB과 XGBoost를 소환해봅니다. Titanic 데이터처럼 범주형·수치형 변수가 섞여 있고, 변수 간 상호작용이 존재하는 경우 트리 기반 부스팅 모델은 특히 강력한 성능을 보여줍니다.
-
LightGBM: 대규모 데이터에서도 빠르게 학습되고, 복잡한 패턴을 효율적으로 포착하는 트리 기반 부스팅 모델입니다.
-
XGBoost: 정규화(regularization)를 활용해 과적합을 잘 억제하고, 안정적인 예측 성능을 내는 강력한 그라디언트 부스팅 모델입니다.
모델을 불러와봅니다.
# LightGBM 불러오기 및 모델 세팅
from lightgbm import LGBMClassifier
lgb_model = LGBMClassifier(
n_estimators=500,
num_leaves=31,
learning_rate=0.03,
subsample=0.8,
colsample_bytree=0.8,
random_state=42
)
# XGBoost vs LightGBM 모델 비교 검증
models = {
"XGBoost": xgb_model,
"LightGBM": lgb_model
}
results = []
for name, model in models.items():
pipeline = Pipeline(steps=[
('preprocess', preprocess),
('model', model)
])
acc_scores = cross_val_score(pipeline, X, y, cv=cv, scoring='accuracy')
f1_scores = cross_val_score(pipeline, X, y, cv=cv, scoring=f1)
results.append({
"Model": name,
"Accuracy (CV Mean)": acc_scores.mean(),
"F1-score (CV Mean)": f1_scores.mean()
})
results웬 알 수 없는 경고메세지가 가득 뜨더니 (...) 분석이 끝났습니다.
[{'Model': 'XGBoost',
'Accuracy (CV Mean)': np.float64(0.8338773460548616),
'F1-score (CV Mean)': np.float64(0.7730610983042278)},
{'Model': 'LightGBM',
'Accuracy (CV Mean)': np.float64(0.8327537505492437),
'F1-score (CV Mean)': np.float64(0.7764329819318035)}]웬지 모르겠지만 Random Forest와 성능이 비슷합니다. 같은 트리 계열이라서 그럴까요..? 이게 최선인가 봅니다.
이제 Random Forest pipeline을 재학습하고, feature를 가져오는 연습을 해봅니다. feature란 분석 과정에서 영향력이 높은 변수들을 의미합니다.
# 랜덤 포레스트 파이프라인 재학습
final_model = Pipeline(steps=[
('preprocess', preprocess),
('model', RandomForestClassifier(n_estimators=200, random_state=42))
])
final_model.fit(X, y)
다음과 같은 화면이 나옵니다. 물론 배경지식 없이 처음에 보면 당황스럽습니다.
제가 사용한 Pipeline은 전처리 과정과 모델 학습을 하나로 묶어둔 구조입니다. 먼저 전처리 단계에서는 수치형 변수들은 StandardScaler로 정규화하고, 범주형 변수들은 OneHotEncoder로 변환해 변수 타입에 맞는 처리를 자동으로 적용하도록 구성했습니다. 이렇게 하면 모델마다 따로 전처리를 반복하지 않아도 되고, 교차검증을 할 때도 동일한 흐름을 그대로 유지할 수 있다는 장점이 있습니다.
전처리가 끝난 데이터는 RandomForest 모델로 전달되는데, 여기서는 트리 개수를 200개로 설정해 조금 더 안정적인 예측을 기대할 수 있도록 했습니다. 분할 기준은 기본값인 Gini를 사용했고, 트리 깊이에는 별도 제한을 두지 않아 데이터 패턴을 최대한 학습할 수 있도록 했습니다. 또한 random_state는 42로 고정해 매번 같은 결과를 얻을 수 있게 했습니다.
전체적으로 보면 '전처리 → 모델 학습'이 하나의 흐름으로 자연스럽게 이어지도록 구성해둔 것이고, 덕분에 나중에 다른 모델로 바꿔 실험할 때도 구조를 그대로 재사용할 수 있는 깔끔한 형태를 갖추게 됩니다.
(사실 저도 힘들어서 GPT의 힘을 좀 빌렸습니다.)
이제 전처리 이후 실제 feature를 가져오는 과정입니다.
# 전처리 이후 실제 feature 가져오기
# ColumnTransformer 내부에서 OneHotEncoder가 생성한 컬럼 이름 포함
ohe = final_model.named_steps['preprocess'].named_transformers_['cat']
ohe_features = ohe.get_feature_names_out(categorical_cols)
# 숫자 컬럼은 그대로
feature_names = list(numeric_cols) + list(ohe_features)
# 랜덤포레스트 feature importance 가져오기
importances = final_model.named_steps['model'].feature_importances_
# 데이터프레임 만들기
fi = pd.DataFrame({
"Feature": feature_names,
"Importance": importances
}).sort_values(by="Importance", ascending=False)
fi결과를 시각화해보겠습니다.
# 시각화
import matplotlib.pyplot as plt
plt.figure(figsize=(10,6))
plt.barh(fi['Feature'], fi['Importance'])
plt.gca().invert_yaxis()
plt.xlabel("Importance"),
plt.title("Feature Importance (RandomForest)")
plt.show()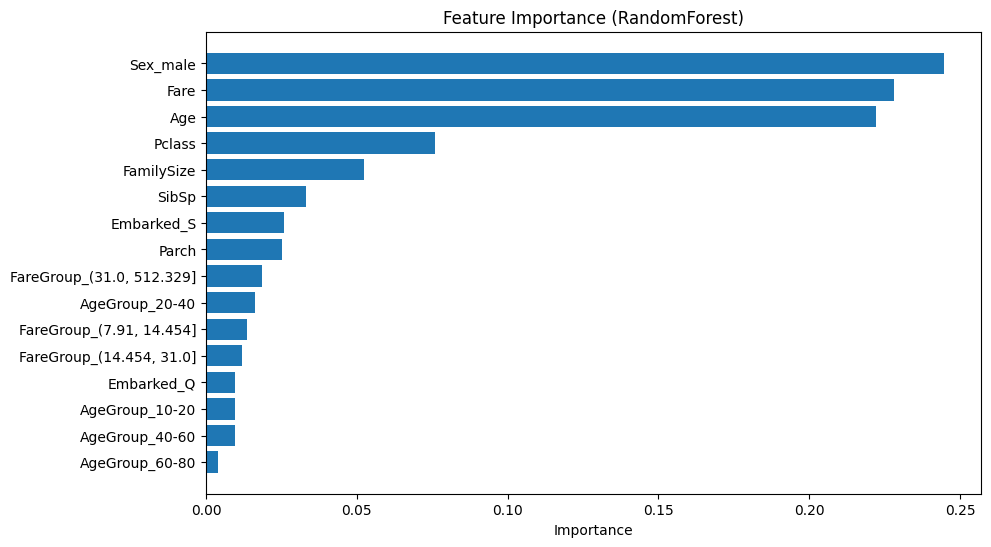
아까도 말씀드렸듯, Feture Importance는 중요도 순위에서 중요한 영향을 미친 변수 ≠ 생존률(positive)이 아니며, 생존률이 높거나 낮은데 '높은 영향을 미친' 요소라고 보았을 때, 어떤 나이든, 어떤 객실이든, 어떤 요금을 냈든 '남성'의 생존률이 낮은 것이 분석 과정에서 높은 영향을 미치고 있음을 알 수 있습니다.
일단 Titanic Data 탐방기는 여기까지입니다. 뭔가 싸다가 말고 바지 올린 느낌이지만, 아직 저의 배움이 짧아서 그렇습니다. 앞으로 배우는게 많아질수록 저의 콘텐츠도 풍부해질 것이라 기대해 봅니다.
다음에는 무슨 데이터로 돌아올지 한동안 궁리를 좀 해봐야겠습니다. 긴 글 봐주셔서 감사합니다! 🙇
