Kimi K2: Open Agentic Intelligence
Kimi Team (MoonshotAI) · arXiv 2507.20534 (v1 2025-07-28 / v2 2026-02-03)
GitHub · HuggingFace · 프로젝트 페이지
한 줄 요약
1.04T / 32B activated MoE를 15.5T 토큰 동안 zero loss spike 로 사전학습한 뒤, 20K+ 합성 tool과 3K+ 실제 MCP tool로 agentic trajectory를 합성해 Verifiable Rewards Gym + Self-Critique Rubric으로 RL 한다. SWE-bench Verified 71.6(multi attempt)·Tau2-Bench 66.1·ACEBench 76.5를 Modified MIT license로 공개. open weight 기반 agentic LLM의 전체 recipe가 technical report 형태로 풀린 몇 안 되는 사례.
왜 이 논문이 흥미로운가
이 블로그의 앞 네 편은 LLM4TS 회의론(003)·경량화(006)·semantic refiner(009)·그리고 attention 구조(012) 라인을 따라왔다. 다섯 번째인 이번 글은 그 라인을 벗어나 agentic LLM 축으로 첫 진입한다.
Kimi K2를 골라온 이유는 단순하다. agent를 어떻게 학습시키는가는 학계·대학원생 입장에서 가장 궁금한 블랙박스 중 하나인데, 현재까지 풀린 자료는 OpenAI o1의 system card·Anthropic의 blog post처럼 "우리가 이런 방향으로 했다" 수준에 머문다. Kimi K2의 technical report는 이 블랙박스를 세 단계 파이프라인으로 분해해 open으로 적어 뒀다 — SFT에서 tool trajectory를 합성하는 방식부터, RL의 verifiable reward gym 구성, 그리고 Self-Critique Rubric Reward까지. 구현을 그대로 복제하긴 여전히 어렵지만, 적어도 어떤 재료들이 어디에 들어가는가 는 외부에서 읽을 수 있다.
하나 더 덧붙이면, 이 모델은 9개월째 계속 진화 중이라는 점도 흥미롭다. 2025-07의 K2 Instruct → 2025-09 Instruct-0905 → 2025-11 K2 Thinking → 2026-Q1 K2.5 → 바로 지난주(2026-04-20) K2.6(SWE-bench Verified 80.2% 주장). 이 글은 v2 논문이 다루는 K2 / K2 Thinking까지만 다루고, 이후 K2.5·K2.6은 후기에서만 짧게 언급한다.
배경 — agentic post-training은 왜 대체로 닫혀 있나
LLM이 tool을 부르고 multi-step으로 작업을 수행하는 "agentic" 능력은 최근 1~2년의 주된 목표 중 하나다. 하지만 이걸 훈련하는 recipe는 대체로 공개되지 않는다. 이유는 몇 가지가 겹친다.
- 합성 데이터의 스케일·품질 비용. 합성 tool trajectory 한 건을 만들려면 시뮬레이터(또는 실행 sandbox) + tool 정의 + LLM judge가 동시에 필요하다. 이 파이프라인 자체가 research code보다 system engineering에 가깝다.
- 검증 가능한 보상(verifiable reward)의 설계 자유도. 수학·코딩처럼 자동 채점 가능한 도메인도 "어떻게 주느냐"에 따라 reward hacking이 생기고, 그 회피 기법은 lab 내부 지식으로 축적된다.
- self-critique류 subjective reward의 bias. 모델이 자기 출력을 평가하게 하면 언제나 reward hacking의 여지가 생긴다. 실제 production에서 어떻게 안정화했는지는 공개할 incentive가 낮다.
그래서 open side의 선행 작업들은 대체로 부분만 풀어둔다 — DeepSeek-V3는 verifier 구조를, Qwen·Llama는 tool-use dataset을 따로 공개했지만 end-to-end agentic recipe 전체를 technical report 한 편으로 다룬 경우는 드물다. Kimi K2 논문의 §3 post-training 섹션이 희소한 지점이 여기다.
모델 구조 — DeepSeek-V3 ± α를 빠르게 짚고 넘어가기
핵심만 정리한다. post-training이 메인이라 구조 자체는 지나가며 본다.
| 항목 | Kimi K2 | DeepSeek-V3 (비교) |
|---|---|---|
| 총 파라미터 | 1.04T | 671B |
| Activated 파라미터 | 32B (per token) | 37B |
| Experts | 384 (1 shared + 8 active/token) | 256 (1 shared + 8 active) |
| Layers | 61 (1 dense + 60 MoE) | 61 |
| Attention | MLA, 64 heads | MLA, 128 heads |
| Vocabulary | 160K | 129K |
| Context | 128K (base) · 256K (Thinking) | 128K |
| Sparsity ratio | 48 | 32 |
구조 수준의 변경점은 두 가지다. (1) experts 수를 256 → 384로 늘리되 activated는 8로 고정 — sparsity ratio가 32에서 48로 커졌다. 더 많은 전문가 중에서 고르게 되므로 specialization 유연성이 올라간다. (2) attention heads를 128 → 64로 절반 축소 — head doubling의 validation loss 기여가 0.5~1.2%에 불과한 반면 long-context 추론 비용은 크다는 ablation을 근거로 제시한다 (§2.3). Sebastian Raschka는 자신의 LLM architecture comparison에서 이 선택을 "more experts, fewer heads" 로 짧게 요약했다.
DeepSeek MLA·SwiGLU·shared expert 등은 그대로 물려받는다. 즉 계보상 DeepSeek-V3의 직계 확장에 가깝고, 차별화는 구조보다 학습 동역학과 post-training 레시피에 몰려 있다.
MuonClip — 1T scale에서 AdamW를 대체한 첫 optimizer
post-training 이야기를 하기 전에, pre-training이 어떻게 안정화됐는지 한 섹션만 짚고 가자. 이게 있어야 post-training이 필요로 하는 "고품질 base model"이 성립한다.
Muon (Jordan, 2024)은 지난 1년 사이 주목받은 optimizer다. SGD의 update 방향을 ortho-normalize해서 adam류 대비 training 효율이 좋다는 결과가 small/mid scale에서 누적돼 왔다. 문제는 scale up 하면 불안정해지는 경향 — 특히 attention logit이 explode하는 현상이 반복 관찰됐다.
Kimi K2는 이걸 단순한 한 줄 trick으로 잡는다. QK-Clip: query/key projection matrix를 Muon update 직후에 post-hoc으로 rescale해서, 각 attention head의 logit이 특정 임계값 τ = 100을 넘지 않도록 clip한다. 수식적으로는
clip이 발생하는 경우에만 로 rescale되어 attention logit의 magnitude가 τ 아래로 내려간다.
효과는 두 층에서 드러난다. 먼저 attention logit의 explosion이 잡힌다 — baseline Muon은 mid-scale 학습 중 logit이 1000을 쉽게 넘어서며 수치 불안정을 만들 수 있는데, MuonClip은 전체 학습 구간 동안 τ=100 안쪽으로 제어한다 (논문 Figure 2). 그 결과 15.5T 토큰 전 구간에서 loss spike가 단 한 번도 나타나지 않는다 (Figure 3). Appendix D의 ablation은 clip이 품질을 해치지 않는다는 것도 제시한다 — QK-Clip 적용/미적용 동일 setup에서 validation loss·downstream benchmark 모두 차이 없거나 clipped 쪽이 살짝 더 좋았다.
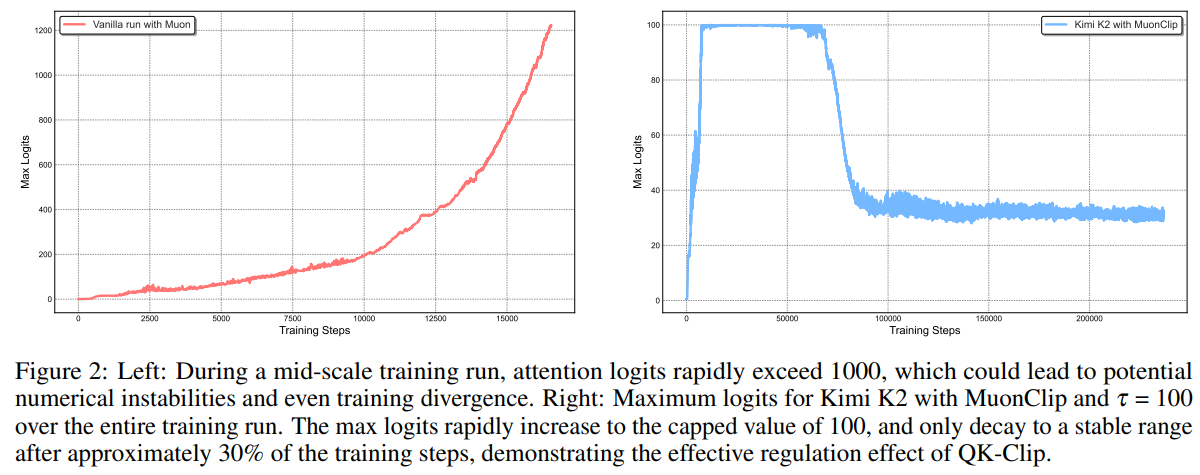 ![]
![]
Raschka는 자신의 블로그에서 이 한 줄을 "production 1T scale에서 AdamW 대신 Muon을 쓴 사실상 첫 사례" 로 평가한다. optimizer를 production에서 건드리는 건 학계에서도 드물고 industry에선 AdamW 관성이 거의 절대적이었다는 맥락 위에서 나온 평가다.
이 글에서 A축으로 굳이 MuonClip을 끼운 이유는, post-training 레시피가 아무리 정교해도 base model이 흔들리면 무의미하기 때문이다. zero spike 15.5T 학습이라는 안정적인 바닥이 있어야 SFT·RL 단계에서 합성 데이터와 verifiable reward를 올려도 무너지지 않는다. 본 글 메인이 post-training이지만 그 전제가 여기에 있다.
Post-training 3단 파이프라인 — 이 글의 메인
§3는 세 단계로 구성된다: SFT → RL (Verifiable Rewards Gym) → Self-Critique Rubric Reward. 각 단계의 재료·절차·검증 기법을 순서대로 본다.
(1) SFT — 20K+ 합성 tool과 3K+ 실제 MCP tool로 trajectory 합성
agent가 도구를 부르고 multi-step으로 답하는 trajectory를 얻는 게 SFT 단계의 목표다. 하지만 이런 trajectory는 인간 annotator가 수작업으로 만들기엔 비효율적이고, 실제 사용자 로그는 scale·diversity 양쪽에서 부족하다. Kimi K2의 해결책은 합성 + 실제 혼합이다.
- Synthetic tools (약 20K+): 가상 도메인별로 tool signature(name, parameters, output schema)를 LLM-generate. 도메인 범위는 code execution·file system·browser·DB·email·calendar·multi-modal retrieval 등 10여 종.
- Real MCP tools (약 3K+): Model Context Protocol 기반 실제 공개 서버에서 가져온 tool들. production-like signature가 더 정교하다.
이 tool pool을 주고 시뮬레이션·실행 sandbox에서 base model이 스스로 multi-turn trajectory를 생성한다. 각 trajectory는 다음 단계를 거친다.
- Task generation: user query를 다양성 있게 생성 (LLM-generate + curated seed mix).
- Trajectory rollout: model이 tool 호출 → tool 결과 관찰 → next action 반복. 실제 실행되는 tool은 sandbox에서, 가상 tool은 LLM이 response role-play.
- LLM-judge 필터링: 생성된 trajectory의 correctness·format·tool use reasonableness를 judge LLM이 평가. 일정 threshold 이상만 SFT dataset에 포함.
결과적으로 SFT 단계에서 모델은 "tool을 어떻게 호출하고, 결과를 어떻게 해석하고, 언제 끝내야 하는지" 의 형태(format)를 먼저 익힌다. 중요한 건 이 단계가 reward를 주지 않는다 — 형태 학습이라 demonstration 기반 지도학습으로 충분하다. reward는 다음 RL 단계에서 들어간다.
(2) RL — Verifiable Rewards Gym
SFT로 형태만 익힌 모델을 실제 "잘하게" 만드는 건 RL이다. Kimi K2는 이걸 Verifiable Rewards Gym이라 부르는 환경 5종 mixture로 구성한다.
| 도메인 | reward source |
|---|---|
| Math | 자동 채점(수치 정답 비교) |
| STEM | GPQA류 객관식 채점 |
| IF (Instruction Following) | format rule checker |
| Coding | unit test 통과 여부 |
| Safety | policy classifier |
핵심은 모든 reward가 프로그램적으로 verifiable이라는 것. 즉 "LLM judge가 주는 모호한 점수"가 아니라 "정답 맞았나 / test 통과했나 / format 지켰나" 같은 결정적 신호만 쓴다. 이게 RL의 bias와 reward hacking을 크게 줄인다.
학습 trick 몇 가지가 이어진다.
- Budget control: trajectory 길이 예산을 제한해 모델이 "무한히 생각해서 정답 맞히는" 우회를 막음.
- PTX loss: pre-training loss의 일부를 RL objective에 섞어, catastrophic forgetting을 방지.
- Temperature decay: 학습 초반엔 exploration을 위해 sampling temperature를 높게, 후반엔 낮춰 stable policy로 수렴.
(3) Self-Critique Rubric Reward
하지만 verifiable reward만으론 한계가 있다. 도메인이 수학·코딩·IF·safety 5종으로 닫혀 있어, open-ended 대화·창의적 글쓰기·미묘한 사용자 의도 파악 같은 채점 불가능한 축은 학습 신호가 없다.
Kimi K2의 해답은 Self-Critique Rubric Reward다. 요점만 적으면:
- 모델 자기 자신이 먼저 output을 생성한다.
- 그 output을 rubric(채점 기준) 체크리스트에 따라 자기 자신이 평가한다. rubric은 도메인별로 미리 정의 — 예를 들어 helpfulness·truthfulness·format·reasoning depth 등.
- 평가 점수를 reward로 삼아 RL을 돈다.
이 아이디어 자체는 새로운 게 아니다 (Constitutional AI·RLAIF 계열). 하지만 Kimi K2가 한 일은 rubric drift 방지 기법을 같이 풀어뒀다는 것. rubric 자체가 학습 중에 자꾸 풀어지는(점점 후하게 주는) 경향을 막기 위해:
- Rubric anchor: 매 RL step에서 고정된 anchor rubric 집합으로 점수 calibration
- Adversarial rubric: 일부 trajectory에 대해 "trap" rubric(함정이 있는 기준)으로 평가해 hacking 검출
- Cross-model rubric consistency: 같은 output을 서로 다른 judge instance에 주고 점수 variance 체크
이 세 가지를 같이 쓴다는 점이 technical report의 기여다. "self-critique로 reward 주면 잘 돌더라"는 블로그 포스트는 많지만, rubric drift를 실측·계측·대응하는 구체 기법까지 묶은 건 흔치 않다.
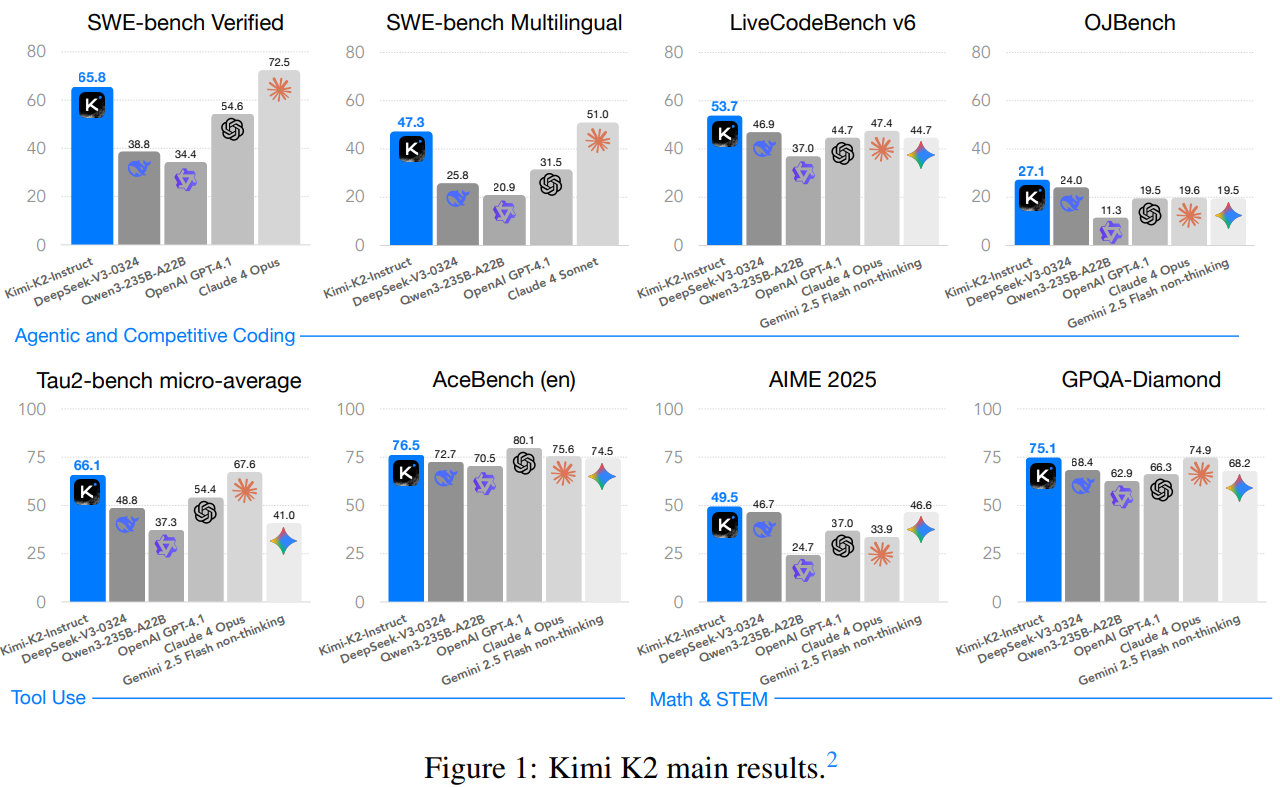
결과 — benchmark
| Benchmark | K2 (multi) | 비교 | 출처 |
|---|---|---|---|
| SWE-bench Verified | 71.6 | DeepSeek-V3 ~42 · Claude 3.5 Sonnet 54 | Table 3 |
| SWE-bench Multilingual | 47.3 | — | Table 3 |
| Tau2-Bench | 66.1 (retail 70.6) | GPT-4.1 ~62 · Claude 4 Sonnet 68 | Table 3 |
| ACEBench | 76.5 | — | Table 3 |
| LiveCodeBench v6 | 53.7 | — | Table 3 |
| AIME'24 / AIME'25 | 69.6 / 49.5 | — | Table 3 |
| MMLU | 89.5 | DeepSeek-V3 88.5 · Claude 4 Sonnet 91 | Table 3 |
| GPQA-Diamond | 75.1 | — | Table 3 |
LMSYS Chatbot Arena (2025-07 기준): open-source 1위, 전체 5위. 이 순위는 이후 K2 Thinking이 갱신해 2025-11~12 사이 선두권 유지. NIST CAISI가 공식 평가 리포트를 낸 것도 이 시점.
숫자 몇 개가 시리즈로 읽힌다.
- SWE-bench Verified 71.6은 논문 v2 시점(2026-02) open-weight SOTA. Claude 4 Sonnet/Opus와 비슷하거나 살짝 아래. agentic coding 축에서 open이 closed를 추격했다는 신호.
- Tau2-Bench 66.1은 retail domain 70.6으로 특히 강하고, airline·telecom에선 closed 모델에 밀린다. multi-turn tool use의 도메인 편차.
- ACEBench 76.5가 가장 뾰족한 숫자인데, ACEBench는 tool 호출의 정확성·argument 품질·error recovery까지 측정하는 composite benchmark라 single-number로도 의미가 있다.
한계 / caveat
논문이 명시한 것보다 읽으면서 추가로 짚인 것까지 함께.
- 재현 불가능성. 20K 합성 tool·3K MCP tool dataset은 공개되지 않는다. SFT·RL training code도 없다. open weight만 있고 open recipe는 방법론 설명 수준. 외부 그룹이 이 숫자를 재현할 방법은 사실상 없음.
- benchmark harness의 내부화. SWE-bench 71.6은 Kimi 내부 harness(SWE-agent 파생, bash/createfile/insert/view/strreplace/submit 6 tool) 기준이다. 공식 SWE-bench leaderboard의 baseline harness와 평가 조건이 다를 수 있고, 실제로 같은 모델이 다른 harness에서는 숫자가 달라지는 게 일반적.
- Self-Critique Rubric의 bias·drift. anchor rubric·adversarial rubric·cross-model consistency 세 가지로 drift를 잡는다고 하지만, 이게 충분한지는 외부 ablation이 없다. 특히 rubric 자체가 모델에 의해 학습된 tacit knowledge로 수렴할 경우 인간 평가와 멀어질 가능성은 열려 있다.
- 짧은 context MCP의 일반화. 훈련에 쓰인 3K MCP tool은 주로 short-context interaction. 긴 문서·긴 로그·멀티모달 input이 섞인 real-world agent task에서 이 훈련이 얼마나 전이되는지는 미지수. K2 Thinking과 K2.6이 context를 256K로 늘린 이유도 이 gap 때문일 가능성.
- single-organization ablation의 한계. 012 Gated Attention과 같은 문제. Kimi 내부 production 후보의 실측 결과라는 점이 강점이자 약점 — 학계 외부에서 이 3단 파이프라인의 어느 component가 실제 효과 크기를 만드는지 독립 분리 검증할 방법이 없다.
- v2와 현재 최신의 gap. 논문 v2는 2026-02이고 K2 Thinking까지 다룬다. 이후 K2.5(2026-Q1)·K2.6(2026-04-20)이 SWE-bench Verified 80.2% 주장까지 밀고 갔지만, 그 개선이 어떤 component 수정에서 왔는지는 이 논문 범위 밖. 글 읽을 때 "2026-02 기준 snapshot"임을 기억해야 한다.
짧은 코멘트
논문을 덮고 남는 인상 두 가지.
하나는 MuonClip이다. AdamW는 거의 10년 동안 LLM pre-training의 기본값이었고, Muon 같은 후보가 small·mid scale에서 증거를 쌓아도 1T scale production으로 올라가는 건 별개의 문턱이었다. Kimi가 그 문턱을 넘은 방법이 우아해서가 아니라 — QK-Clip τ=100이라는 한 줄짜리 안전장치라서 — 오히려 기억에 남는다. 더 흥미로운 건 K2.5·K2.6까지 9개월째 이 optimizer를 유지한다는 점이다. 한두 iteration 실험이 아니라 production 관성으로 정착했다는 뜻. 이 한 줄이 다음 세대 open-weight 학습의 기본값을 바꿀지는 앞으로 1~2년 Qwen·DeepSeek의 흉내 여부로 결정될 것 같다.
또 하나는 9개월 타임라인의 속도다. 2025-07 K2 Instruct가 SWE-bench Verified 71.6으로 Claude 4 Sonnet을 간신히 따라잡던 자리에서, 2026-04 K2.6이 Verified 80.2%로 Claude Opus 4.6·GPT-5.4 역전 주장까지 왔다. open recipe가 technical report로 풀린 덕에 Qwen·DeepSeek도 비슷한 파이프라인을 따라 벤치를 끌어올리기 시작했고, closed 쪽의 agentic moat이 예전만큼 깊지 않다는 감각이 뚜렷해졌다. Llama 1→2의 18개월 추격 사이클보다 확실히 빠른 속도다.
두 관찰을 묶으면 이 논문은 한 모델의 spec sheet라기보다, optimizer 한 줄과 recipe 한 벌을 open으로 올린 덕에 2025~26 open-weight 경쟁의 선두 지점에 찍힌 좌표처럼 읽힌다. MuonClip과 3단 파이프라인이 후속 Qwen·DeepSeek·Hermes류에서 어떻게 변형·흡수될지가 다음 1~2년의 관전 포인트.
참고
- arXiv: Kimi K2: Open Agentic Intelligence (2507.20534) · HTML v2
- GitHub: MoonshotAI/Kimi-K2 — Modified MIT license
- HuggingFace: moonshotai (Kimi-K2-Base / Instruct / Instruct-0905 / Thinking / K2.5 / K2.6)
- Sebastian Raschka: The Big LLM Architecture Comparison · Beyond Standard LLMs
- Nathan Lambert: 5 Thoughts on Kimi K2 Thinking
- NIST CAISI: K2 Thinking 공식 평가 보고서
- Artificial Analysis: K2.6 리포트 (2026-04)
- 배경 레퍼런스
- Muon optimizer: Jordan, Muon: An optimizer for hidden layers in neural networks (2024)
- DeepSeek-V3 (MoE + MLA 계보): arXiv 2412.19437
- Model Context Protocol: 공식 문서
- 이 블로그의 관련 리뷰
- [논문리뷰] Gated Attention (NeurIPS '25 Best Paper) — attention 구조 한 줄
- [논문리뷰] LoFT-LLM — LLM을 semantic refiner로
- [논문리뷰] One-for-All (rsLoRA) — 경량 PEFT
- [논문리뷰] Rethinking LLMs in TS Forecasting
