Smart Pet Door - 04
저번 포스팅에 이어서 진행
동물 칩 인식 부분 변경
먼저 작품 내 변경된 부분이 존재해서 변경된 부분부터 설명하겠다.
기존에는 장거리 RFID 리더 모듈을 이용해서 반려동물을 인식하려고 했지만
모듈의 하드웨어적인 문제 때문에 이 부분을 카메라 모듈로 교체하였다.

RFID 동물 칩 인식 대신에 아두이노 나노 33 센스 보드와 카메라 모듈로 TinyML 기술을 이용할 계획이다.
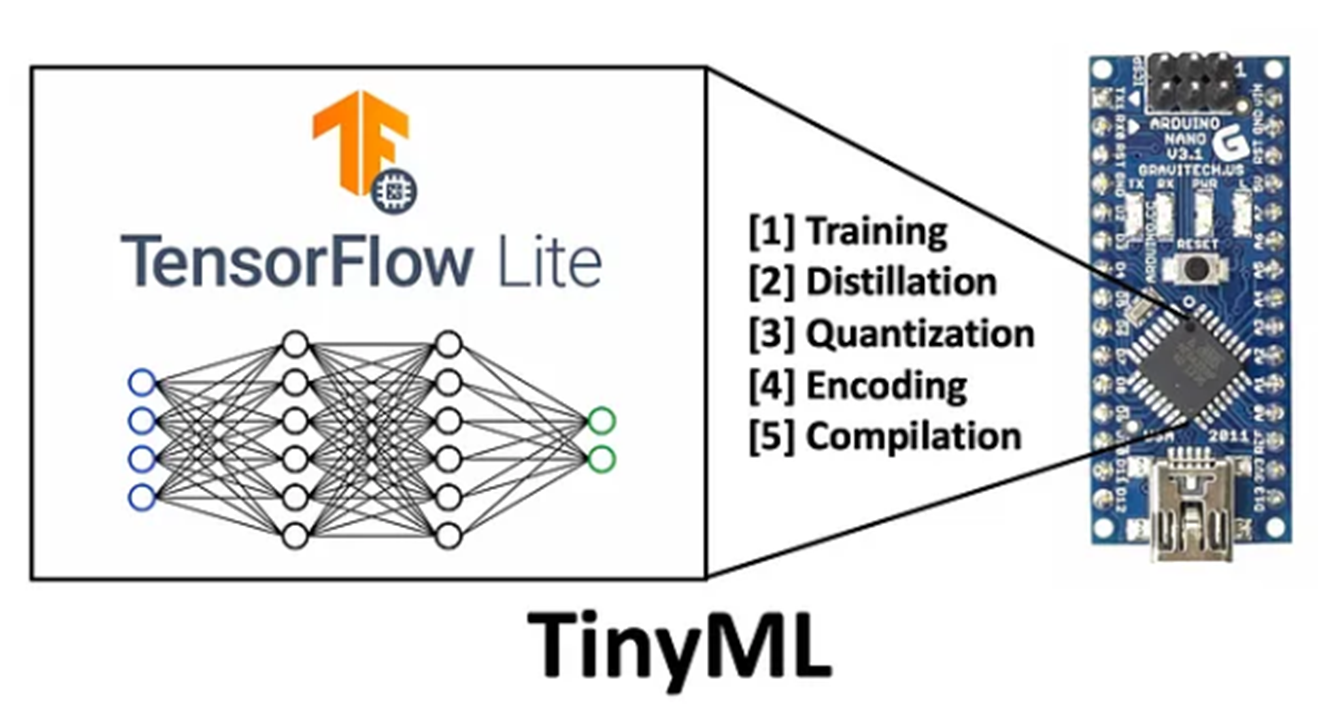
먼저 구글 티쳐블 머신으로 등록할 반려동물의 사진을 학습시킨다. 그리고 학습 모델을 나노 보드에 입력 시킨다.
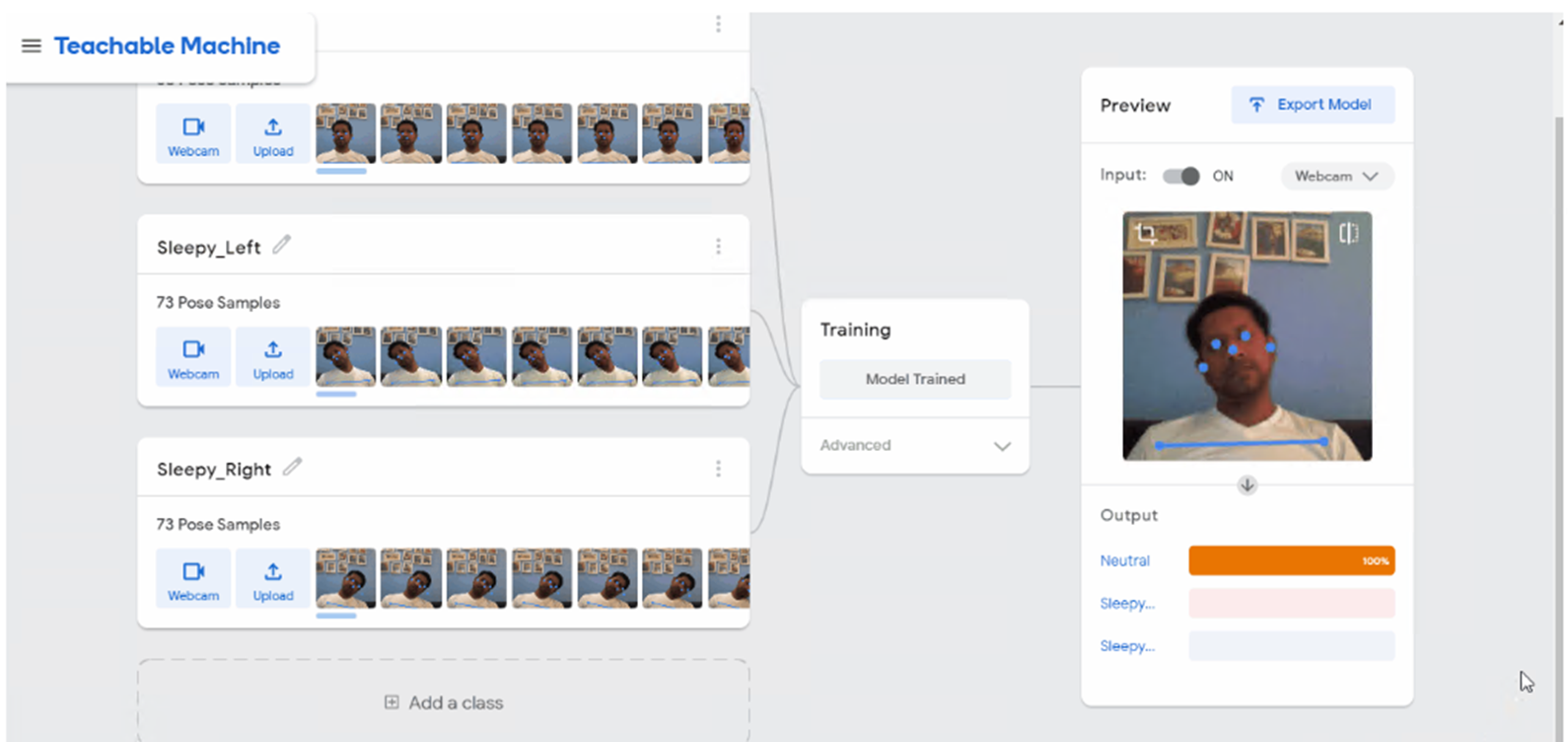
그러면 나노보드와 연결된 카메라 모듈이 실시간으로 영상을 읽어와 영상에 학습된 반려동물이 나타나게 되면 나노보드와 연결된 서보모터가 작동하여 문이 열리게 되는 방식이다.
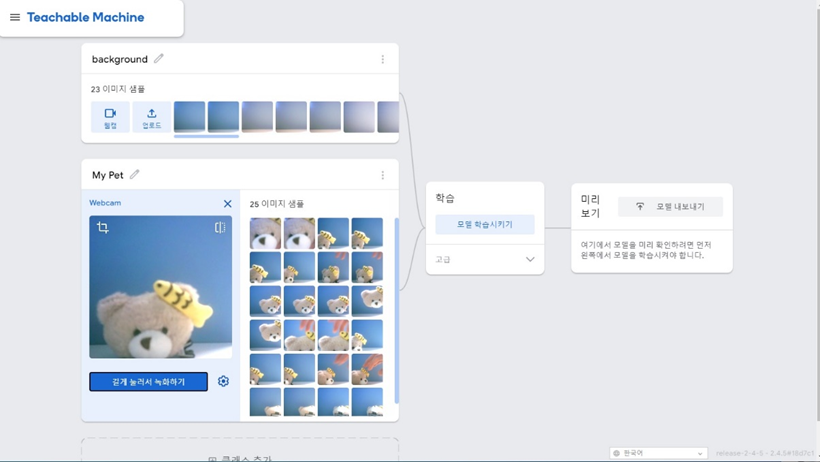
먼저 사진에 보이는 곰돌이 인형을 반려동물이라고 가정하고 테스트를 진행하였다. Google Teachable Machine 툴을 이용하여 간편하게 학습모델을 제작하였다.
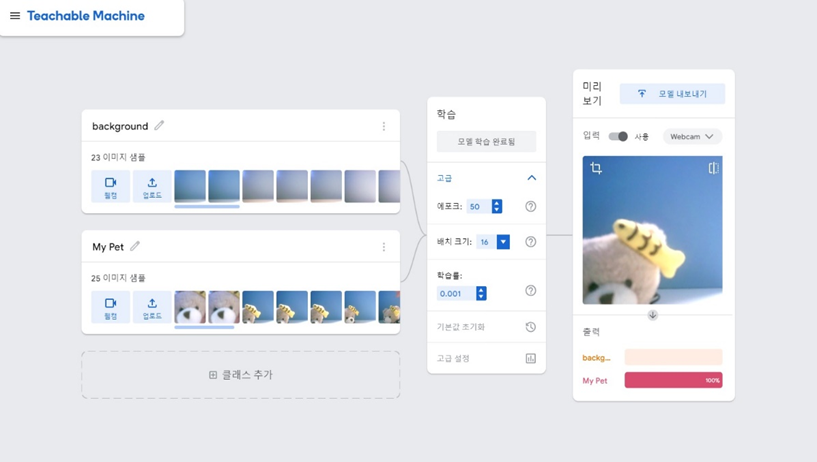
background 와 my pet 객체를 학습하여 실시간으로 웹켐으로 테스트를 진행하였더니 잘 분류가 되는 모습이다.
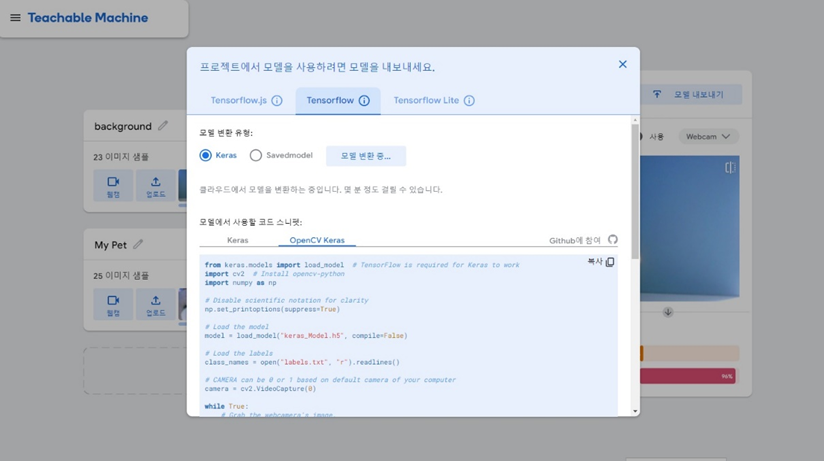
하지만 여기서 문제가 발생하였다. 학습모델을 모두 제작하고 이 모델을 Tensorflow Lite 모델로 내보낸뒤, 이 .tflite 모델을 아두이노에 import 시키는 과정에서 문제가 발생하였다.
관련 문서들을 구글링을 통해서 찾아본 뒤 진행하려고 했지만 이 부분에서 막혔다. TinyML 과 Tensorflow 를 더 공부해야겠다고 느꼈다.
일단 이번학기에 결과물이 있어야해서 급한대로 라즈베리파이와 웹켐을 사용하기로 했다.

TensorFlow Lite Object Detection Model

라즈베리파이와 웹켐 모터를 연결한 뒤 오픈소스인 TensorFlow Lite Object Detection Model을 가져와서 사용했다. 이 모델은 미리 약 64개의 물체를 학습시킨 모델이다. 카메라로 촬영된 영상에서 미리 학습된 객체가 인식되면 초록색 박스와 그 객체의 이름, 일치하는 정도를 화면에 나타내게 된다.
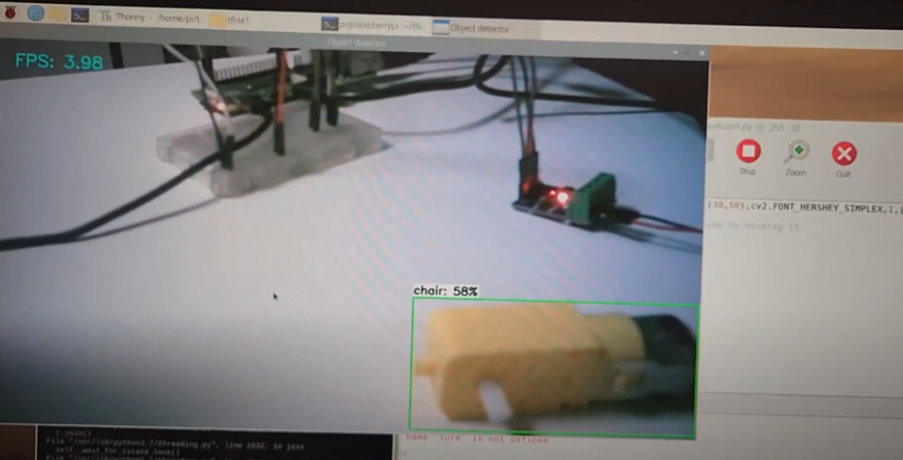
https://www.youtube.com/watch?v=z6VhSjb-W2I
필자는 이 모델을 이용해서 원하는 객체가 카메라에 탐지 되면 모터가 작동하게 코드를 작성하였다.
######## Webcam Object Detection Using Tensorflow-trained Classifier #########
#
# Author: Evan Juras
# Date: 10/27/19
# Description:
# This program uses a TensorFlow Lite model to perform object detection on a live webcam
# feed. It draws boxes and scores around the objects of interest in each frame from the
# webcam. To improve FPS, the webcam object runs in a separate thread from the main program.
# This script will work with either a Picamera or regular USB webcam.
#
# This code is based off the TensorFlow Lite image classification example at:
# https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/examples/python/label_image.py
#
# I added my own method of drawing boxes and labels using OpenCV.
# Import packages
import os
import argparse
import cv2
import numpy as np
import sys
import time
from threading import Thread
import importlib.util
import RPi.GPIO as GPIO
GPIO.setmode(GPIO.BCM)
p1 = 20
p2 = 21
GPIO.setup(p1, GPIO.OUT)
GPIO.setup(p2, GPIO.OUT)
# Define VideoStream class to handle streaming of video from webcam in separate processing thread
# Source - Adrian Rosebrock, PyImageSearch: https://www.pyimagesearch.com/2015/12/28/increasing-raspberry-pi-fps-with-python-and-opencv/
class VideoStream:
"""Camera object that controls video streaming from the Picamera"""
def __init__(self,resolution=(640,480),framerate=30):
# Initialize the PiCamera and the camera image stream
self.stream = cv2.VideoCapture(0)
ret = self.stream.set(cv2.CAP_PROP_FOURCC, cv2.VideoWriter_fourcc(*'MJPG'))
ret = self.stream.set(3,resolution[0])
ret = self.stream.set(4,resolution[1])
# Read first frame from the stream
(self.grabbed, self.frame) = self.stream.read()
# Variable to control when the camera is stopped
self.stopped = False
def start(self):
# Start the thread that reads frames from the video stream
Thread(target=self.update,args=()).start()
return self
def update(self):
# Keep looping indefinitely until the thread is stopped
while True:
# If the camera is stopped, stop the thread
if self.stopped:
# Close camera resources
self.stream.release()
return
# Otherwise, grab the next frame from the stream
(self.grabbed, self.frame) = self.stream.read()
def read(self):
# Return the most recent frame
return self.frame
def stop(self):
# Indicate that the camera and thread should be stopped
self.stopped = True
# Define and parse input arguments
parser = argparse.ArgumentParser()
parser.add_argument('--modeldir', help='Folder the .tflite file is located in',
required=True)
parser.add_argument('--graph', help='Name of the .tflite file, if different than detect.tflite',
default='detect.tflite')
parser.add_argument('--labels', help='Name of the labelmap file, if different than labelmap.txt',
default='labelmap.txt')
parser.add_argument('--threshold', help='Minimum confidence threshold for displaying detected objects',
default=0.5)
parser.add_argument('--resolution', help='Desired webcam resolution in WxH. If the webcam does not support the resolution entered, errors may occur.',
default='1280x720')
parser.add_argument('--edgetpu', help='Use Coral Edge TPU Accelerator to speed up detection',
action='store_true')
args = parser.parse_args()
MODEL_NAME = args.modeldir
GRAPH_NAME = args.graph
LABELMAP_NAME = args.labels
min_conf_threshold = float(args.threshold)
resW, resH = args.resolution.split('x')
imW, imH = int(resW), int(resH)
use_TPU = args.edgetpu
# Import TensorFlow libraries
# If tflite_runtime is installed, import interpreter from tflite_runtime, else import from regular tensorflow
# If using Coral Edge TPU, import the load_delegate library
pkg = importlib.util.find_spec('tflite_runtime')
if pkg:
from tflite_runtime.interpreter import Interpreter
if use_TPU:
from tflite_runtime.interpreter import load_delegate
else:
from tensorflow.lite.python.interpreter import Interpreter
if use_TPU:
from tensorflow.lite.python.interpreter import load_delegate
# If using Edge TPU, assign filename for Edge TPU model
if use_TPU:
# If user has specified the name of the .tflite file, use that name, otherwise use default 'edgetpu.tflite'
if (GRAPH_NAME == 'detect.tflite'):
GRAPH_NAME = 'edgetpu.tflite'
# Get path to current working directory
CWD_PATH = os.getcwd()
# Path to .tflite file, which contains the model that is used for object detection
PATH_TO_CKPT = os.path.join(CWD_PATH,MODEL_NAME,GRAPH_NAME)
# Path to label map file
PATH_TO_LABELS = os.path.join(CWD_PATH,MODEL_NAME,LABELMAP_NAME)
# Load the label map
with open(PATH_TO_LABELS, 'r') as f:
labels = [line.strip() for line in f.readlines()]
# Have to do a weird fix for label map if using the COCO "starter model" from
# https://www.tensorflow.org/lite/models/object_detection/overview
# First label is '???', which has to be removed.
if labels[0] == '???':
del(labels[0])
# Load the Tensorflow Lite model.
# If using Edge TPU, use special load_delegate argument
if use_TPU:
interpreter = Interpreter(model_path=PATH_TO_CKPT,
experimental_delegates=[load_delegate('libedgetpu.so.1.0')])
print(PATH_TO_CKPT)
else:
interpreter = Interpreter(model_path=PATH_TO_CKPT)
interpreter.allocate_tensors()
# Get model details
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
height = input_details[0]['shape'][1]
width = input_details[0]['shape'][2]
floating_model = (input_details[0]['dtype'] == np.float32)
input_mean = 127.5
input_std = 127.5
# Check output layer name to determine if this model was created with TF2 or TF1,
# because outputs are ordered differently for TF2 and TF1 models
outname = output_details[0]['name']
if ('StatefulPartitionedCall' in outname): # This is a TF2 model
boxes_idx, classes_idx, scores_idx = 1, 3, 0
else: # This is a TF1 model
boxes_idx, classes_idx, scores_idx = 0, 1, 2
# Initialize frame rate calculation
frame_rate_calc = 1
freq = cv2.getTickFrequency()
# Initialize video stream
videostream = VideoStream(resolution=(imW,imH),framerate=30).start()
time.sleep(1)
#for frame1 in camera.capture_continuous(rawCapture, format="bgr",use_video_port=True):
while True:
# Start timer (for calculating frame rate)
t1 = cv2.getTickCount()
# Grab frame from video stream
frame1 = videostream.read()
# Acquire frame and resize to expected shape [1xHxWx3]
frame = frame1.copy()
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame_resized = cv2.resize(frame_rgb, (width, height))
input_data = np.expand_dims(frame_resized, axis=0)
# Normalize pixel values if using a floating model (i.e. if model is non-quantized)
if floating_model:
input_data = (np.float32(input_data) - input_mean) / input_std
# Perform the actual detection by running the model with the image as input
interpreter.set_tensor(input_details[0]['index'],input_data)
interpreter.invoke()
# Retrieve detection results
boxes = interpreter.get_tensor(output_details[boxes_idx]['index'])[0] # Bounding box coordinates of detected objects
classes = interpreter.get_tensor(output_details[classes_idx]['index'])[0] # Class index of detected objects
scores = interpreter.get_tensor(output_details[scores_idx]['index'])[0] # Confidence of detected objects
# Loop over all detections and draw detection box if confidence is above minimum threshold
for i in range(len(scores)):
if ((scores[i] > min_conf_threshold) and (scores[i] <= 1.0)):
# Get bounding box coordinates and draw box
# Interpreter can return coordinates that are outside of image dimensions, need to force them to be within image using max() and min()
ymin = int(max(1,(boxes[i][0] * imH)))
xmin = int(max(1,(boxes[i][1] * imW)))
ymax = int(min(imH,(boxes[i][2] * imH)))
xmax = int(min(imW,(boxes[i][3] * imW)))
cv2.rectangle(frame, (xmin,ymin), (xmax,ymax), (10, 255, 0), 2)
# Draw label
object_name = labels[int(classes[i])] # Look up object name from "labels" array using class index
label = '%s: %d%%' % (object_name, int(scores[i]*100)) # Example: 'person: 72%'
labelSize, baseLine = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.7, 2) # Get font size
label_ymin = max(ymin, labelSize[1] + 10) # Make sure not to draw label too close to top of window
cv2.rectangle(frame, (xmin, label_ymin-labelSize[1]-10), (xmin+labelSize[0], label_ymin+baseLine-10), (255, 255, 255), cv2.FILLED) # Draw white box to put label text in
cv2.putText(frame, label, (xmin, label_ymin-7), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 0), 2) # Draw label text
if object_name =='teddy bear':
GPIO.output(p1, True)
GPIO.output(p2, False)
time.sleep(3)
GPIO.output(p1, False)
GPIO.output(p2, False)
time.sleep(1)
GPIO.output(p1, False)
GPIO.output(p2, True)
time.sleep(3)
GPIO.output(p1, False)
GPIO.output(p2, False)
# Draw framerate in corner of frame
cv2.putText(frame,'FPS: {0:.2f}'.format(frame_rate_calc),(30,50),cv2.FONT_HERSHEY_SIMPLEX,1,(255,255,0),2,cv2.LINE_AA)
# All the results have been drawn on the frame, so it's time to display it.
cv2.imshow('Object detector', frame)
# Calculate framerate
t2 = cv2.getTickCount()
time1 = (t2-t1)/freq
frame_rate_calc= 1/time1
# Press 'q' to quit
if cv2.waitKey(1) == ord('q'):
GPIO.cleanup()
break
# Clean up
cv2.destroyAllWindows()
videostream.stop()다음은 작품의 데모 영상이다.

https://www.youtube.com/watch?v=C4eYfbvS1ps
웹페이지 부분
다음은 기존 ESP8266으로 만든 웹페이지 이다.
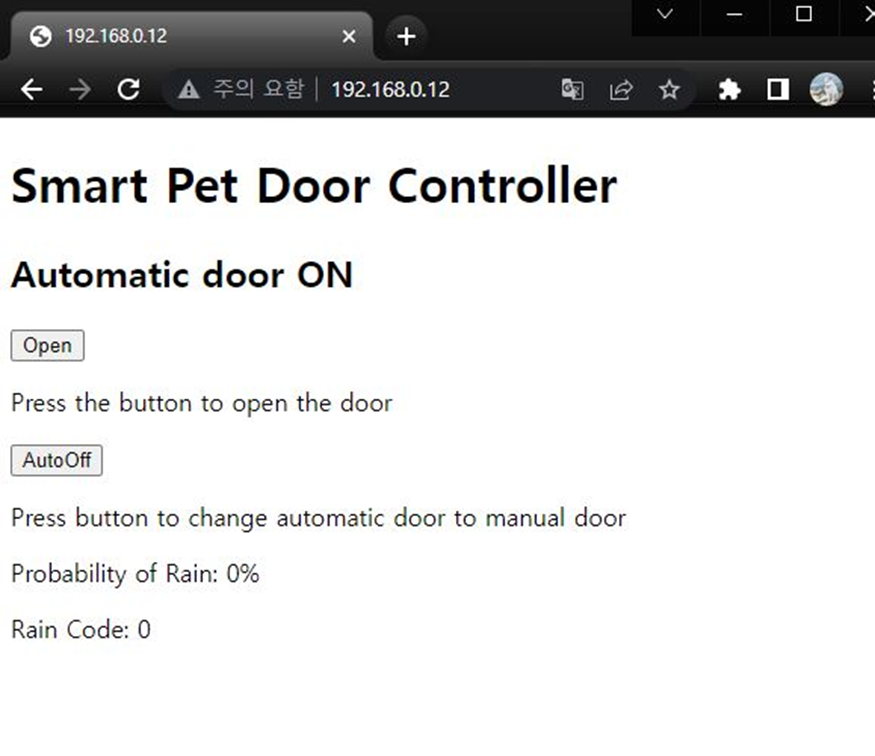
하지만 인터넷 통신이 가능한 라즈베리파이로 변경하면서 굳이 ESP8266 모듈을 사용할 필요가 사라졌다.

따라서 Flask 를 사용해서 모터를 제어할 수 있는 웹페이지를 제작 하였다.

일단 이번학기 졸업작품의 진행상황은 여기까지이다.
처음에 기획했던 대로 진행되지 않아서 중간에 변경사항이 많았다. 그리고 현재 계획중인 TinyML 기술을 이용하여 직접 모델을 제작하려면 인공지능 관련 공부가 더 필요하다고 생각했다.
이번 방학때 "TinyML 초소형 머신러닝 TinyML" 책과 Embedded AI 스터디를 통해서 임베디드 시스템과 AI 쪽을 중점적으로 공부할 예정이다.
