
한국형 우울증 딥러닝 예측 모델 및 진단 프로그램 "Kor-DEEPression" 개발 과정 정리 및 회고.
(2) Preprocess & Database (전처리 & 데이터베이스 구축)
- (1) Outline & Introduction (개요 & 서론)
- (2) Preprocess & Database (전처리 & 데이터베이스 구축)
- (3) EDA & Dashboard (시각화 분석 & 대시보드)
- (4-1) ML / DL Modeling (모델링)
- (4-2) Final Model & Compression (최종모델 및 모델경량화)
- (5) Deployment & Conclusion (프로그램 배포 & 결론)
Kor-DEEPression
- 한국형 우울증 딥러닝 예측 모델 및 진단 프로그램
- Korean Depression Deep-Learning Model and Diagnosis Program

Project Information
- 프로젝트명 : Kor-DEEPression
- 한국형 우울증 딥러닝 예측 모델 및 진단 프로그램 개발
- Development of Korean Depression Deep-Learning Model and Diagnosis Program
- Codestates AI Bootcamp CP2 project
- 자유주제 개인 프로젝트
- Full-Stack Deep-Learning Project
- DS (Data Science)
- Machine Learning & Deep Learning 모델링
- 모델 성능 평가 및 모델 개선
- 모델 경량화 (tensorflow-lite)
- DA (Data Analysis)
- EDA 및 시각화 분석
- Trend Dashboard 구현 (Looker-Studio)
- DE (Data Engineering)
- Back-end : Cloud DB 구축, 프로그램 Flask 배포
- Front-end : Web page 제작 (HTML5, CSS3)
- DS (Data Science)
Process Pipeline 파이프라인

Outline & Intro. 개요 및 서론
2. Database 데이터베이스
(Part2) Database 데이터베이스
- Data Preprocessing
데이터 전처리 - Cloud Database
클라우드 DB 구축 - SQL query
SQL쿼리
2-1. Data Preprocessing 데이터 전처리
- 전처리 과정은 코드의 효율성을 높이기 위해 함수들을 module로 묶고 이를 package화 하여 이를 불러오는 방식으로 진행 되었음
- 자세한 소스코드는 다음 링크를 통해 확인가능함

라이브러리 및 함수 불러오기
- custom_modules/preprocess.py
# 라이브러리 import
import pandas as pd- 1-1_data-prepare.py
# 라이브러리 및 함수 Import
import pandas as pd
from custom_modules.preprocess import *데이터 불러오기
- custom_modules/preprocess.py
# column 리스트 정의(기본변수, 건강설문, 생활습관, 만성질환, 우울증변수)
col_demo = ['year', 'age', 'HE_BMI', 'sex', 'edu', 'genertn', 'marri_2', 'EC1_1']
col_health = ['D_1_1', 'LQ4_00', 'D_2_1', 'BO1_1', 'BO2_1']
col_life = ['BD1_11', 'BD2_1', 'sm_presnt', 'BP1']
col_disease = ['HE_HP', 'HE_DM', 'HE_HCHOL', 'HE_HTG']
col_disease_20 = ['HE_HP', 'HE_DM_HbA1c', 'HE_HCHOL', 'HE_HTG']
col_dpr = ['DF2_pr', 'mh_PHQ_S']# 데이터 불러오기 기능(2014, 2016, 2018)
def data_load(filedir):
'''
data_load
데이터 불러오기 기능(2014, 2016, 2018)
---
입력 변수 정보
filedir : (str)불러올 파일의 디렉토리
---
출력 : DataFrame
'''
# csv file 불러오기(여러 type이 섞여있는 column도 있으므로 low_memory=False로 설정)
df0 = pd.read_csv(filedir, low_memory=False)
# 분석에 이용할 column list를 정의(리스트 합 연산)
col_list = ['id']+col_demo+col_health+col_disease+col_life+col_dpr
# column list에 해당하는 column을 추출
df1 = df0[col_list]
# column을 추출한 DataFrame 출력
return df1# 데이터 불러오기 기능(2020)
def data_load_20(filedir):
'''
data_load
데이터 불러오기 기능(2020)
---
입력 변수 정보
filedir : (str)불러올 파일의 디렉토리
---
출력 : DataFrame
'''
# csv file 불러오기(여러 type이 섞여있는 column도 있으므로 low_memory=False로 설정)
df0 = pd.read_csv(filedir, low_memory=False)
# 분석에 이용할 column list를 정의(리스트 합 연산)
col_list = ['ID']+col_demo+col_health+col_disease_20+col_life+col_dpr
# column list에 해당하는 column을 추출 및 column 이름을 통일시키기
df1 = df0[col_list].rename(columns={'ID':'id','HE_DM_HbA1c':'HE_DM'})
# column을 추출한 DataFrame 출력
return df1- 1-1_data-prepare.py
# 데이터 불러오기 기능
df14 = data_load('./1_DataBase/downloads/raw_data/HN14_ALL.csv')
df16 = data_load('./1_DataBase/downloads/raw_data/HN16_ALL.csv')
df18 = data_load('./1_DataBase/downloads/raw_data/HN18_ALL.csv')
df20 = data_load_20('./1_DataBase/downloads/raw_data/HN20_ALL.csv')
print('\nData Loading : Success')
print(df14.shape, df16.shape, df18.shape, df20.shape)
'''
Data Loading : Success
(7550, 24) (8150, 24) (7992, 24) (7359, 24)
'''데이터 병합
- custom_modules/preprocess.py
# 데이터 병합 기능(concatenate)
def concat_df(df_list):
'''
concat_df
데이터 병합 기능 (row 방향)
---
입력 변수 정보
df_list : (list)병합할 DataFrame의 List
---
출력 : DataFrame
'''
# concat(default는 row 방향, index 초기화를 위해 ignore_index=True로 설정)
df = pd.concat(df_list, ignore_index=True)
# 병합한 DataFrame 출력
return df- 1-1_data-prepare.py
# 데이터 병합 기능
df_list = [df14, df16, df18, df20]
df = concat_df(df_list)
print('\nData Merge : Success')
print(df.shape)
'''
Data Merge : Success
(31051, 24)
'''결측치 제거
공백(' ')으로 채워진 결측치를 제거
- custom_modules/preprocess.py
# 결측치 제거 기능 : 결측치는 ' '(공백)으로 채워져 있음
def drop_nan_df(df):
'''
drop_nan_df
결측치 제거 기능 (결측치는 ' '(공백)으로 채워져 있음)
---
입력 변수 정보
df : (DataFrame)결측치 제거할 DataFrame
---
출력 : 결측치 제거 후 DataFrame
'''
# 공백(' ')을 None값으로 변환하는 함수 정의
def fill_nan(value):
if value == ' ':
value = None
return value
# 원본 데이터 변환 방지를 위해 copy 실시
df1 = df.copy()
# applymap으로 모든 데이터 값에 변환 함수를 적용
df1 = df1.applymap(fill_nan)
# 결측치가 하나라도 존재(any)하면 row(axis=0)를 제거
df1 = df1.dropna(axis=0, how='any')
# 결측치 제거한 DataFrame 출력
return df1- 1-1_data-prepare.py
# 결측치 제거 기능 1
df_drop = drop_nan_df(df)
print('\nDroped NaN values : Success')
# print(df_drop.info())
'''
Droped NaN values : Success
'''dtype변환을 간단하게 처리하기 위해 임시 저장 후 다시 불러오기
- 1-1_data-prepare.py
# dtype변환을 간단하게 처리하기 위해 임시 저장 후 다시 불러오기
df_drop.to_csv('./1_DataBase/downloads/temp_data/HN_drop_14_20.csv', index=False)
df_temp = pd.read_csv('./1_DataBase/downloads/temp_data/HN_drop_14_20.csv')설문변수중에서 응답을 거부하거나 모르겠다고 응답한 경우(9 or 99)
- custom_modules/preprocess.py
# csv editor를 통해 직접 확인하였으며, 제거는 query함수로 실시함
def drop_9s_df(df):
'''
drop_9s_df
설문변수 무응답 데이터(결측치) 제거 기능 (9 또는 99)
---
입력 변수 정보
df : (DataFrame)결측치 제거할 DataFrame
---
출력 : 결측치 제거 후 DataFrame
'''
# marri_2(결혼상태), D_1_1(주관적건강인지)
df1 = df.query('marri_2!=99 and marri_2!=8 and marri_2!=9 and D_1_1!=9')
# BO1_1(연간체중변화), BD1_11(연간음주빈도), BD2_1(1회음주량), BP1(스트레스인지정도)
df2 = df1.query('BO1_1!=9 and BD1_11!=9 and BD2_1!=9 and BP1!=9')
# index reset
df2 = df2.reset_index(drop=True)
# 결측치 제거한 DataFrame 출력
return df2- 1-1_data-prepare.py
# 결측치 제거 기능 2
df_drop2 = drop_9s_df(df_temp)
print('\nDropped 9 or 99 values : Success')
# print(f"{df_drop2.tail()}\n{df_drop2.shape}")
print(df_drop2.shape)
'''
Dropped 9 or 99 values : Success
(16570, 24)
'''Target & Feature 재조합 (Feature Engineering)

Target (타겟, 종속변수)
- custom_modules/preprocess.py
# Target으로 쓸 Column을 추가하는 기능
def get_targets(df):
'''
get_targets
Target으로 쓸 Column을 추가하는 기능
---
입력 변수 정보
df : (DataFrame) DataFrame
---
출력 : target column을 추가한 DataFrame
'''
# 빈 리스트 생성
depression = []
MDD = []
# 우울증 관련 변수만 추출하기
df_targets = df[col_dpr] # ['DF2_pr', 'mh_PHQ_S']
# DataFrame의 row 한줄씩 반복 수행
for i in range(len(df_targets)):
# 우울증을 현재 가지고 있다고 응답 or PHQ-9점수가 5점 이상인 경우
if df_targets.loc[i, 'DF2_pr'] == 1\
or df_targets.loc[i, 'mh_PHQ_S'] > 4:
# Depression = 1
depression.append(1)
# PHQ-9점수가 10점 이상인 경우 : 주요우울장애(MDD)로 구분
if df_targets.loc[i, 'mh_PHQ_S'] > 9:
MDD.append(1)
else:
MDD.append(0)
# 우울증 의사진단 받지 않거나(8) 현재 우울증이 없으며(0), PHQ-9점수도 4점 이하
else:
# Depression & MDD = 0
depression.append(0)
MDD.append(0)
# Target Column 추가
df['Depression'] = depression
df['MDD'] = MDD
# target column을 추가한 DataFrame 출력
return dfFeature (특성, 독립변수)
- custom_modules/preprocess.py
# Feature 1차 가공(재분류)
def get_features(df):
'''
get_features
가공한 Feature의 Column을 추가하는 기능
---
입력 변수 정보
df : (DataFrame) DataFrame
---
출력 : 가공한 Feature column을 추가한 DataFrame
'''
# 빈 리스트 생성
household = []
marital = []
limit = []
modality = []
w_change = []
HE_HBP = []
HE_DB = []
HE_DYSL = []
drink_freq = []
drink_amount = []
# DataFrame의 row 한줄씩 반복 수행
for i in range(len(df)):
# 가구 세대 구성 (1~7) --> household (0~3)
# 1인 가구 (1)
if df.loc[i, 'genertn'] == 1:
household.append(0)
# 1세대 가구 (2,3)
elif df.loc[i, 'genertn'] in [2,3]:
household.append(1)
# 2세대 가구 (4,5,6)
elif df.loc[i, 'genertn'] in [4,5,6]:
household.append(2)
# 3세대 이상 가구 (7)
elif df.loc[i, 'genertn'] == 7:
household.append(3)
# 결혼 상태(1~4,88) --> marital(1~3)
# 기혼 및 유배우자 (1,2)
if df.loc[i, 'marri_2'] in [1,2]:
marital.append(1)
# 사별 혹은 이혼 (3,4)
elif df.loc[i, 'marri_2'] in [3,4]:
marital.append(2)
# 미혼(88)
elif df.loc[i, 'marri_2'] == 88:
marital.append(3)
# 질환 및 사고에 의한 활동 제한 여부
# 아니오(2) --> 0
if df.loc[i, 'LQ4_00'] == 2:
limit.append(0)
# 예(1) --> 1
elif df.loc[i, 'LQ4_00'] == 1:
limit.append(1)
# 2주간 이환(질환) 여부
# 아니오(2) --> 0
if df.loc[i, 'D_2_1'] == 2:
modality.append(0)
# 예(1) --> 1
elif df.loc[i, 'D_2_1'] == 1:
modality.append(1)
# 1년간 체중 조절 노력 없이 체중이 3kg이상 변화한 경우
# 체중변화없음(1) --> 0
if df.loc[i, 'BO1_1'] == 1:
w_change.append(0)
# 체중감소(2)or체중증가(3) & 체중 조절 노력함(1,2,3) --> 0
elif df.loc[i, 'BO1_1'] in [2,3]\
and df.loc[i, 'BO2_1'] in [1,2,3]:
w_change.append(0)
# 체중감소(2)or체중증가(3) & 체중 조절 노력 안함(4) --> 1
elif df.loc[i, 'BO1_1'] in [2,3]\
and df.loc[i, 'BO2_1'] == 4:
w_change.append(1)
# 고혈압 유병 여부
# 고혈압(3) --> 1
if df.loc[i, 'HE_HP'] == 3:
HE_HBP.append(1)
# 정상(1), 전단계(2) --> 0
elif df.loc[i, 'HE_HP'] in [1,2]:
HE_HBP.append(0)
# 당뇨병 유병 여부
# 당뇨병(3) --> 1
if df.loc[i, 'HE_DM'] == 3:
HE_DB.append(1)
# 정상(1), 공복혈당장애(2) --> 0
elif df.loc[i, 'HE_DM'] in [1,2]:
HE_DB.append(0)
# 이상지질혈증(고지혈증) 유병 여부
# 고콜레스테롤혈증(1) or 고중성지방혈증(1) --> 1
if df.loc[i, 'HE_HCHOL'] == 1\
or df.loc[i, 'HE_HTG'] == 1:
HE_DYSL.append(1)
# 모두 정상(0) --> 0
elif df.loc[i, 'HE_HCHOL'] == 0\
and df.loc[i, 'HE_HTG'] == 0:
HE_DYSL.append(0)
# 1년간 음주 빈도 (1~6, 8) --> (0~6)
# 평생마셔본적없음(8) --> 0
if df.loc[i, 'BD1_11'] == 8:
drink_freq.append(0)
# 나머지 변수(1~6) 그대로 사용
elif df.loc[i, 'BD1_11'] in [1,2,3,4,5,6]:
drink_freq.append(df.loc[i, 'BD1_11'])
# 1회 음주량 (1~5, 8) --> (0~5)
# 1년간 안마심(8) or 평생 안마심(8) --> 0
if df.loc[i, 'BD2_1'] == 8:
drink_amount.append(0)
# 나머지 변수(1~5) 그대로 사용
elif df.loc[i, 'BD2_1'] in [1,2,3,4,5]:
drink_amount.append(df.loc[i, 'BD2_1'])
# 가공한 Feature의 Column을 추가
df['household'] = household
df['marital'] = marital
df['limit'] = limit
df['modality'] = modality
df['w_change'] = w_change
df['HE_HBP'] = HE_HBP
df['HE_DB'] = HE_DB
df['HE_DYSL'] = HE_DYSL
df['dr_freq'] = drink_freq
df['dr_amount'] = drink_amount
# 가공한 Feature column을 추가한 DataFrame 출력
return dfTarget & Feature column 추가
- 1-1_data-prepare.py
# Target Column 및 가공한 Feature Column들을 추가하는 기능
df_add_targets = get_targets(df_drop2)
df_add_features = get_features(df_add_targets)
print('\nAdd Features & Add Targets : Success')
'''
Add Features & Add Targets : Success
'''가공한 DataFrame을 RDB형태에 맞도록 재조합
- custom_modules/preprocess.py
# 가공한 DataFrame을 RDB형태에 맞도록 재조합하는 기능
def devide_for_RDB(df):
'''
devide_for_RDB
가공한 DataFrame을 RDB형태에 맞도록 재조합하는 기능
---
입력 변수 정보
df : (DataFrame) 분리 할 DataFrame의 List
---
출력 : tuple of DataFrame
'''
# 변수 리스트 정의
col_year = ['id', 'year']
col_feature = ['id', 'age', 'HE_BMI', 'sex', 'edu',
'household', 'marital', 'EC1_1',
'D_1_1', 'limit', 'modality', 'w_change',
'HE_HBP', 'HE_DB', 'HE_DYSL',
'dr_freq', 'dr_amount', 'sm_presnt', 'BP1']
col_target = ['id', 'Depression', 'MDD']
# column 추출
df_year = df[col_year]
df_feature = df[col_feature]
df_target = df[col_target]
# 분리한 DataFrame들을 Tuple로 출력
return df_year, df_feature, df_target- 1-1_data-prepare.py
# 가공한 DataFrame을 RDB형태에 맞도록 분리하는 기능
df_year, df_feature, df_target = devide_for_RDB(df_add_features)
print('\nData division completed')
print('Shapes : df_year, df_feature, df_target')
print(df_year.shape, df_feature.shape, df_target.shape)
'''
Data division completed
Shapes : df_year, df_feature, df_target
(16570, 2) (16570, 19) (16570, 3)
'''전처리 데이터 csv Export
- 1-1_data-prepare.py
# 최종 DataFrame들을 csv로 Export
df_year.to_csv('./1_DataBase/downloads/HN_year.csv', index=False)
df_feature.to_csv('./1_DataBase/downloads/HN_feature.csv', index=False)
df_target.to_csv('./1_DataBase/downloads/HN_target.csv', index=False)
print('\nData Saved at "Kor-DEEPression/1_DataBase/downloads/"\n')
'''
Data Saved at "Kor-DEEPression/1_DataBase/downloads/"
'''2-2. Cloud Database 클라우드 DB 구축
- Cloud DB 서비스는 무료로 이용할 수 있는
ElephantSQL을 이용하여 데이터베이스를 생성하고 구축하였음 - DB 구축 과정 또한 코드의 효율성을 높이기 위해 함수들을 module로 묶고 이를 package화 하여 이를 불러오는 방식으로 진행 되었음
- 자세한 소스코드는 다음 링크를 통해 확인가능함

라이브러리 불러오기
- custom_modules/postgresql_upload.py
# 라이브러리 import
import csv
import json- 1-2_PostgreSQL-RDB.py
# 라이브러리 및 함수 Import
import os
import sys
import psycopg2
from dotenv import load_dotenv
from custom_modules.postgresql_upload import *SQL 서버 연결 정보 불러오기
-
보안 유지를 위해 호스트, DB이름, user이름, 비밀번호는
.env파일에 담고python-dotenv라이브러리를 통해 불러온 뒤에 정보들을 전역변수(global var)로 저장하여 진행하였음 -
1-2_PostgreSQL-RDB.py
# .env파일에 저장된 정보들을 불러옴
load_dotenv(verbose=True)
# HOST, PORT, DATABASE, USERNAME, PASSWORD를 전역변수로 저장
HOST = os.getenv('postgre_host')
PORT = 5432
DATABASE = os.getenv('postgre_database')
USERNAME = os.getenv('postgre_user')
PASSWORD = os.getenv('postgre_password')main 함수 정의 및 자동 실행
- 파이썬 파일을 실행시키면 자동으로 main함수가 실행되도록 세팅
- 이후 과정은 main함수 안에서 작성된 코드를 정리하였음
- 1-2_PostgreSQL-RDB.py
# 파일이 실행되면 자동으로 동작하는 main 함수
def main():
~~코드 내용~~
# 파일이 실행되면 자동으로 main 함수를 동작하도록 함
if __name__ == '__main__':
main()PostgreSQL 서버 연결
- 1-2_PostgreSQL-RDB.py
# postgreSQL 연결
try:
conn = psycopg2.connect(
host=HOST,
port=PORT,
database=DATABASE,
user=USERNAME,
password=PASSWORD)
# 커서 지정
cur = conn.cursor()
print('\nconnection success to DB')
# 예외처리 : 연결 실패할 경우 시스템을 중단
except:
print('\nconnection error to DB')
sys.exit()
'''
connection success to DB
'''테이블 리스트 정의 및 테이블 초기화
-
테이블 리스트 초기화 및 생성을 효율적으로 진행하기 위해 table 리스트를 정의함 (순서가 중요하기 때문에 리스트로써 정의함)
-
1-2_PostgreSQL-RDB.py
# 테이블 리스트 정의 (id_year-->targets-->범주형변수들-->features)
table_list = ['id_year',
'targets',
'sex',
'education',
'household',
'marital',
'economy',
'subj_health',
'drk_freq',
'drk_amount',
'smoke',
'stress',
'features']테이블 초기화
-
수정사항을 원활하게 반영하기 위해 DB CRUD 중에서 Update 대신 Delete 후 Create하도록 프로그래밍을 설계하였으므로 테이블 초기화 함수 부터 정의, 순서는 위에서 정의한 리스트의 역순으로 진행되어야 오류 없이 초기화가 가능함
-
custom_modules/postgresql_upload.py
# 테이블 초기화 기능(features-->범주형변수들-->targets-->id_year)
# 외래키를 가진 테이블(자식)부터 제거해야하므로 순서가 중요함
def table_initialization(cursor, table_list):
'''
table_initialization
테이블 초기화 기능
---
입력 변수 정보
cursor : (object) psycopg2.connect.cursor()
table_list : (list) 테이블 이름 리스트
---
출력 : None
'''
# 입력 받은 table list의 역순으로 반복을 진행함
for table_name in reversed(table_list):
# 테이블 이름과 동일한 테이블이 존재하면 삭제하는 명령어 실행
cursor.execute(f"""DROP TABLE IF EXISTS {table_name};""")- 1-2_PostgreSQL-RDB.py
# 테이블 초기화 (features-->범주형변수들-->targets-->id_year)
table_initialization(cursor=cur, table_list=table_list)
print('\ntable initialization complete')
'''
table initialization complete
'''테이블 생성
- Delete를 통해 테이블이 초기화 되었으므로 테이블을 생성하는 Create를 실시, 이때 순서는 위에서 정의한 테이블 리스트 순서대로 진행되도록 함
- feature 테이블에서 for문을 쓰지 않았는데, 그 이유는 전처리한 데이터의 순서대로 column을 생성해야 했기 때문이었는데... 전처리 과정에서 column 순서를 바꾸어서 저장하거나 테이블을 분리해서 진행했으면 좀 더 간결한 코딩이 가능하지 않았을까 하는 생각이 듦..
- custom_modules/postgresql_upload.py
# 테이블 생성 기능(id_year-->targets-->범주형변수들-->features)
# 외래키를 가지지 않는 테이블(부모)부터 생성해야하므로 순서가 중요함
def table_creation(cursor, table_list):
'''
table_creation
테이블 생성 기능
---
입력 변수 정보
cursor : (object) psycopg2.connect.cursor()
table_list : (list) 테이블 이름 리스트
---
출력 : None
'''
# id_year 테이블 생성 (부모 테이블)
cursor.execute(f"""CREATE TABLE IF NOT EXISTS {table_list[0]} (
id VARCHAR NOT NULL,
year INTEGER,
CONSTRAINT {table_list[0]}_pk PRIMARY KEY (id)
);""")
# targets 테이블 생성 (id_year의 자식 테이블)
cursor.execute(f"""CREATE TABLE IF NOT EXISTS {table_list[1]} (
id VARCHAR NOT NULL,
depression INTEGER,
mdd INTEGER,
CONSTRAINT {table_list[1]}_pk PRIMARY KEY (id),
CONSTRAINT {table_list[1]}_fk FOREIGN KEY (id) REFERENCES {table_list[0]} (id)
);""")
# 범주형 변수들(총 10개)의 테이블들을 생성 (부모 테이블)
for feature_name in table_list[2:-1]:
cursor.execute(f"""CREATE TABLE IF NOT EXISTS {feature_name} (
id_{feature_name} INTEGER,
{feature_name} VARCHAR,
CONSTRAINT {feature_name}_pk PRIMARY KEY (id_{feature_name})
);""")
# features 테이블 생성 (id_year와 범주형 테이블들의 자식 테이블)
cursor.execute(f"""CREATE TABLE IF NOT EXISTS {table_list[-1]} (
id VARCHAR NOT NULL,
age INTEGER,
bmi FLOAT,
{table_list[2]} INTEGER,
{table_list[3]} INTEGER,
{table_list[4]} INTEGER,
{table_list[5]} INTEGER,
{table_list[6]} INTEGER,
{table_list[7]} INTEGER,
limitation INTEGER,
modality INTEGER,
w_change INTEGER,
high_bp INTEGER,
diabetes INTEGER,
dyslipidemia INTEGER,
{table_list[-5]} INTEGER,
{table_list[-4]} INTEGER,
{table_list[-3]} INTEGER,
{table_list[-2]} INTEGER,
CONSTRAINT {table_list[-1]}_pk PRIMARY KEY (id),
CONSTRAINT {table_list[-1]}_fk FOREIGN KEY (id) REFERENCES {table_list[0]} (id),
CONSTRAINT {table_list[-1]}_fk_{table_list[2]} FOREIGN KEY ({table_list[2]}) REFERENCES {table_list[2]} (id_{table_list[2]}),
CONSTRAINT {table_list[-1]}_fk_{table_list[3]} FOREIGN KEY ({table_list[3]}) REFERENCES {table_list[3]} (id_{table_list[3]}),
CONSTRAINT {table_list[-1]}_fk_{table_list[4]} FOREIGN KEY ({table_list[4]}) REFERENCES {table_list[4]} (id_{table_list[4]}),
CONSTRAINT {table_list[-1]}_fk_{table_list[5]} FOREIGN KEY ({table_list[5]}) REFERENCES {table_list[5]} (id_{table_list[5]}),
CONSTRAINT {table_list[-1]}_fk_{table_list[6]} FOREIGN KEY ({table_list[6]}) REFERENCES {table_list[6]} (id_{table_list[6]}),
CONSTRAINT {table_list[-1]}_fk_{table_list[7]} FOREIGN KEY ({table_list[7]}) REFERENCES {table_list[7]} (id_{table_list[7]}),
CONSTRAINT {table_list[-1]}_fk_{table_list[-5]} FOREIGN KEY ({table_list[-5]}) REFERENCES {table_list[-5]} (id_{table_list[-5]}),
CONSTRAINT {table_list[-1]}_fk_{table_list[-4]} FOREIGN KEY ({table_list[-4]}) REFERENCES {table_list[-4]} (id_{table_list[-4]}),
CONSTRAINT {table_list[-1]}_fk_{table_list[-3]} FOREIGN KEY ({table_list[-3]}) REFERENCES {table_list[-3]} (id_{table_list[-3]}),
CONSTRAINT {table_list[-1]}_fk_{table_list[-2]} FOREIGN KEY ({table_list[-2]}) REFERENCES {table_list[-2]} (id_{table_list[-2]})
);""")- 1-2_PostgreSQL-RDB.py
# 테이블 생성 (id_year-->targets-->범주형변수들-->features)
table_creation(cursor=cur, table_list=table_list)
print('\ntable created complete')
'''
table created complete
'''csv, json 데이터 삽입
- custom_modules/postgresql_upload.py
# csv data를 RDB에 입력하는 기능
# csv에서 한줄씩 넣는 executemany 방식은 시간이 상당히 오래 걸림
# cursor의 copy_from 메소드로 csv전체를 복사하여 RDB에 붙여 넣으면 훨씬 간단하고 빠르게 수행할 수 있음!
def insertion_csv(cursor, table_name, path):
'''
insertion_csv
csv data를 RDB에 입력하는 기능
---
입력 변수 정보
cursor : (object) psycopg2.connect.cursor()
table_name : (str) 테이블 이름
path : csv file 디렉토리
---
출력 : None
'''
# 연산 실시후 파일이 닫히도록 with문을 활용한다
with open(path, 'r') as cf:
# csv 모듈의 reader를 통해 csv 파일을 읽기
csv_reader = csv.reader(cf)
# 첫 행에는 변수 이름이 저장되어 있으므로 next로 넘어가기
next(csv_reader)
# copy_from으로 csv데이터를 통째로 입력하기
cursor.copy_from(cf, table_name, sep=',')# json data를 RDB에 입력하는 기능
# 데이터 수가 많지 않기 때문에 executemany 방식으로 데이터를 입력
def insertion_json(cursor, table_list, path):
'''
insertion_json
json data를 RDB에 입력하는 기능
---
입력 변수 정보
cursor : (object) psycopg2.connect.cursor()
table_list : (list) 테이블 이름 리스트
path : json file 디렉토리
---
출력 : None
'''
# 연산 실시후 파일이 닫히도록 with문을 활용한다
with open(path, 'r', encoding='utf-8') as jf:
json_reader = json.load(jf)
# 전달받은 table list의 요소를 순서대로 반복하여 json 데이터를 입력
for table_name in table_list:
cursor.executemany(f"""INSERT INTO {table_name} (id_{table_name}, {table_name}) VALUES (%s, %s);""",
[list(dict.values()) for dict in json_reader[table_name]])- json_variable.json (예시로 1개의 변수에 대해서만 작성함)
{
"sex":
[
{
"sex" : 1,
"name" : "Male"
},
{
"sex" : 2,
"name" : "Female"
}
]
}- 1-2_PostgreSQL-RDB.py
# 데이터 삽입 (id_year-->targets-->범주형변수들-->features)
insertion_csv(cur, table_list[0], path='./1_DataBase/downloads/HN_year.csv')
insertion_csv(cur, table_list[1], path='./1_DataBase/downloads/HN_target.csv')
insertion_json(cur, table_list[2:-1], path='./1_DataBase/json_variable.json')
insertion_csv(cur, table_list[-1], path='./1_DataBase/downloads/HN_feature.csv')
print('\ndata insert complete')
'''
data insert complete
'''변경 사항 저장 및 SQL 서버 연결 종료
- 1-2_PostgreSQL-RDB.py
# 변경사항을 저장(commit)
conn.commit()
# postgreSQL 연결 종료
conn.close()
print('\nSuccessfully Disconnected to DB\n')
'''
Successfully Disconnected to DB
'''데이터베이스 스키마
- 최종적으로 구축한 데이터베이스의 구조는 아래 그림과 같음.
- DB 구조 시각화는
DBeaver프로그램을 통해 확인함
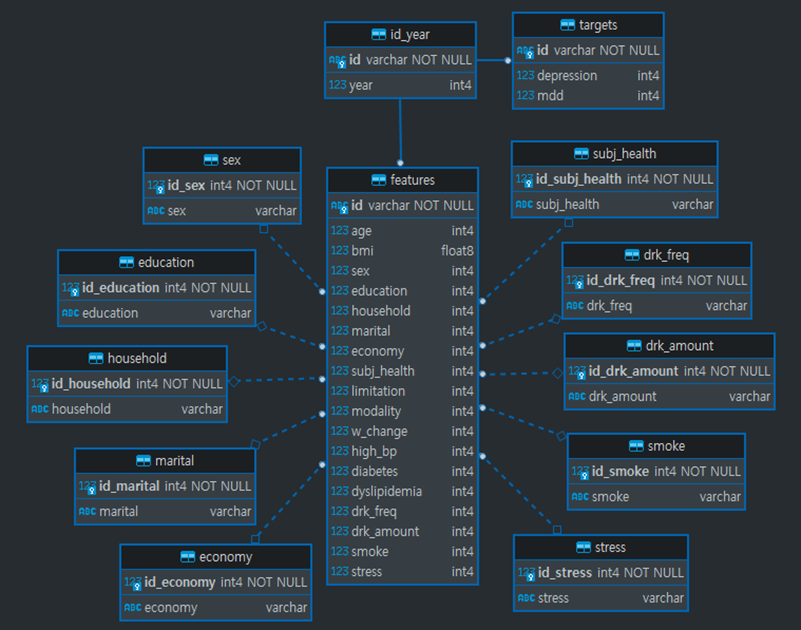
2-3. SQL query SQL쿼리
- dashboard용 데이터를 제외한 EDA 및 Modeling용 데이터 쿼리는 이전 과정들과 마찬가지로 함수들을 module화하고, package로 묶어 이를 불러오는 방식으로 진행
- DB 연결 및 종료는 이전 과정과 동일하므로 본 과정에선 생략
- 자세한 소스코드는 아래 링크에서 확인 가능함
라이브러리 불러오기
- custom_modules/postgresql_down.py
# 라이브러리 import
import pandas as pd- 2-1_PostgreSQL-Query.py
# 라이브러리 및 함수 Import
import os
import sys
import psycopg2
from dotenv import load_dotenv
from custom_modules.postgresql_down import *SQL Query -> csv 생성
- custom_modules/postgresql_down.py
# SQL Qurey문을 통해 csv 데이터를 생성하는 기능
# mode를 지정하여 목적에 맞게 쿼리를 실시함
def get_csv_file(cursor, mode, target, savepath):
'''
get_csv_file
SQL Qurey문을 통해 csv 데이터를 생성하는 기능
---
입력 변수 정보
cursor : (object) psycopg2.connect.cursor()
mode : (str) 'EDA' or 'Model'
target : (str) 'depression', 'MDD'
savepath : (str) 저장 파일 경로
---
출력 : None
'''
# mode가 'EDA' 인 경우(EDA용 데이터 쿼리)
if mode == 'EDA':
# target이 'depression' 인 경우
if target == 'depression':
sql_query = """
SELECT f.id , y."year" , f.age , f.bmi , f1.sex , f2.education , f3.household , f4.marital , f5.economy ,
f6.subj_health , f.limitation , f.modality , f.w_change , f.high_bp , f.diabetes , f.dyslipidemia ,
f7.drk_freq , f8.drk_amount , f9.smoke , f10.stress , t.depression
FROM features AS f
JOIN targets AS t ON f.id = t.id
JOIN id_year AS y ON f.id = y.id
JOIN sex AS f1 ON f.sex = f1.id_sex
JOIN education AS f2 ON f.education = f2.id_education
JOIN household AS f3 ON f.household = f3.id_household
JOIN marital AS f4 ON f.marital = f4.id_marital
JOIN economy AS f5 ON f.economy = f5.id_economy
JOIN subj_health AS f6 ON f.subj_health = f6.id_subj_health
JOIN drk_freq AS f7 ON f.drk_freq = f7.id_drk_freq
JOIN drk_amount AS f8 ON f.drk_amount = f8.id_drk_amount
JOIN smoke AS f9 ON f.smoke = f9.id_smoke
JOIN stress AS f10 ON f.stress = f10.id_stress
"""
# target이 'MDD' 인 경우
elif target == 'MDD':
sql_query = """
SELECT f.id , y."year" , f.age , f.bmi , f1.sex , f2.education , f3.household , f4.marital , f5.economy ,
f6.subj_health , f.limitation , f.modality , f.w_change , f.high_bp , f.diabetes , f.dyslipidemia ,
f7.drk_freq , f8.drk_amount , f9.smoke , f10.stress , t.mdd
FROM features AS f
JOIN targets AS t ON f.id = t.id
JOIN id_year AS y ON f.id = y.id
JOIN sex AS f1 ON f.sex = f1.id_sex
JOIN education AS f2 ON f.education = f2.id_education
JOIN household AS f3 ON f.household = f3.id_household
JOIN marital AS f4 ON f.marital = f4.id_marital
JOIN economy AS f5 ON f.economy = f5.id_economy
JOIN subj_health AS f6 ON f.subj_health = f6.id_subj_health
JOIN drk_freq AS f7 ON f.drk_freq = f7.id_drk_freq
JOIN drk_amount AS f8 ON f.drk_amount = f8.id_drk_amount
JOIN smoke AS f9 ON f.smoke = f9.id_smoke
JOIN stress AS f10 ON f.stress = f10.id_stress
WHERE t.depression = 1
"""
# 예외처리 : Exception 문을 출력하도록 설정하고 함수를 종료 시킴
else:
raise Exception("\nERROR : 'target' must be 'depression' or 'MDD'")
# mode가 'Model'인 경우(Modeling용 데이터 쿼리)
elif mode == 'Model':
# target이 'depression' 인 경우
if target == 'depression':
sql_query = """
SELECT f.* , t.depression
FROM features AS f
JOIN targets AS t ON f.id = t.id
"""
# target이 'MDD' 인 경우
elif target == 'MDD':
sql_query = """
SELECT f.* , t.mdd
FROM features AS f
JOIN targets AS t ON f.id = t.id
WHERE t.depression = 1
"""
# 예외처리 : Exception 문을 출력하도록 설정하고 함수를 종료 시킴
else:
raise Exception("\nERROR : 'target' must be 'depression' or 'MDD'")
# 예외처리 : Exception 문을 출력하도록 설정하고 함수를 종료 시킴
else:
raise Exception("\nERROR : 'mode' must be 'EDA' or 'Model'")
# csv 생성 SQL 쿼리문
sql_csv = f"""COPY ({sql_query}) TO STDOUT WITH CSV DELIMITER ',';"""
with open(savepath, 'w', encoding='utf-8') as cf:
cursor.copy_expert(sql_csv, cf)
# 동작 여부를 확인하기 위한 print문
print(f"{mode}_{target}_temp.csv file created Successfully")- 2-1_PostgreSQL-Query.py
# Query & Get csv(temp) : SQL Qurey문을 통해 csv 데이터를 생성하는 기능
# EDA모드에서는 범주형 변수의 테이블을 모두 JOIN하여 모두 문자열로 불러옴
get_csv_file(cur, mode='EDA', target='depression', savepath="./2_Modeling/downloads/temp_data/EDA_depr_temp.csv")
get_csv_file(cur, mode='EDA', target='MDD', savepath="./2_Modeling/downloads/temp_data/EDA_mdd_temp.csv")
# Model모드에서는 모두 수치형으로 데이터를 불러옴
get_csv_file(cur, mode='Model', target='depression', savepath="./2_Modeling/downloads/temp_data/Model_depr_temp.csv")
get_csv_file(cur, mode='Model', target='MDD', savepath="./2_Modeling/downloads/temp_data/Model_mdd_temp.csv")
'''
EDA_depression_temp.csv file created Successfully
EDA_MDD_temp.csv file created Successfully
Model_depression_temp.csv file created Successfully
Model_MDD_temp.csv file created Successfully
'''DataFrame으로 column 이름 추가
-
SQL 쿼리를 통해 얻은 데이터에는 column 이름에 대한 정보가 포함되어 있지 않기 때문에, 이를 pandas를 통해 추가함
-
custom_modules/postgresql_down.py
# DataFrame을 통해 column 이름을 추가하는 함수
# mode를 지정하여 목적에 맞게 기능을 수행함
def load_df_with_columns(mode, target, filepath):
'''
load_df_with_columns
column 이름을 추가하는 함수
---
입력 변수 정보
mode : (str) 'EDA' or 'Model'
target : (str) 'depression', 'MDD'
filepath : (str) 파일 경로
---
출력 : DataFrame
'''
# 공통적으로 담고 있는 Feature의 리스트를 정의함
col_feat = ['age', 'BMI', 'sex', 'education', 'household', 'marital', 'economy',
'subj_health', 'limitation', 'modality', 'w_change', 'high_bp',
'diabetes', 'dyslipidemia', 'drk_freq', 'drk_amount', 'smoke', 'stress']
# 지정한 mode와 target에 따라 column 이름 리스트를 결정함
if mode == 'EDA':
if target == 'depression':
col_list = ['id', 'year'] + col_feat + ['depression']
elif target == 'MDD':
col_list = ['id', 'year'] + col_feat + ['MDD']
else: # 예외처리 : Exception 문을 출력하도록 설정하고 함수를 종료 시킴
raise Exception("\nERROR : 'target' must be 'depression' or 'MDD'")
elif mode == 'Model':
if target == 'depression':
col_list = ['id'] + col_feat + ['depression']
elif target == 'MDD':
col_list = ['id'] + col_feat + ['MDD']
else: # 예외처리 : Exception 문을 출력하도록 설정하고 함수를 종료 시킴
raise Exception("\nERROR : 'target' must be 'depression' or 'MDD'")
else: # 예외처리 : Exception 문을 출력하도록 설정하고 함수를 종료 시킴
raise Exception("\nERROR : 'mode' must be 'EDA' or 'Model'")
# 위에서 결정한 col_list에 따라서 column의 이름을 붙여주면서 DataFrame을 불러옴
df = pd.read_csv(filepath, names=col_list)
# 동작여부 테스트용 코드
print(f"{mode}_{target} : {df.shape}")
# 출력 : DataFrame
return df- 2-1_PostgreSQL-Query.py
# Data loading : column 이름을 추가하기 위해 저장한 임시 데이터를 다시 불러옴
df_eda_depr = load_df_with_columns(mode='EDA', target='depression', filepath="./2_Modeling/downloads/temp_data/EDA_depr_temp.csv")
df_eda_mdd = load_df_with_columns(mode='EDA', target='MDD', filepath="./2_Modeling/downloads/temp_data/EDA_mdd_temp.csv")
df_depr = load_df_with_columns(mode='Model', target='depression', filepath="./2_Modeling/downloads/temp_data/Model_depr_temp.csv")
df_mdd = load_df_with_columns(mode='Model', target='MDD', filepath="./2_Modeling/downloads/temp_data/Model_mdd_temp.csv")
print('Data loading : Success\n')
'''
EDA_depression : (16570, 21)
EDA_MDD : (3359, 21)
Model_depression : (16570, 20)
Model_MDD : (3359, 20)
Data loading : Success
'''최종 데이터 최종 가공 및 Export
- custom_modules/postgresql_down.py
# column 이름을 추가한 DataFrame을 csv로 저장하는 기능
# mode를 지정하여 목적에 맞게 기능을 수행함(EDA 모드에서는 이진변수를 문자열로 수정)
def df_to_csv(df, mode, target, savepath):
'''
df_to_csv
DataFrame을 csv로 저장하는 기능
---
입력 변수 정보
df : (DataFrame) 저장할 DataFrame
mode : (str) 'EDA' or 'Model'
target : (str) 'depression', 'MDD'
savepath : (str) 저장 파일 경로
---
출력 : None
'''
# mode가 'EDA'인 경우 : 이진변수를 문자열(Yes,No)로 수정
if mode == 'EDA':
df1 = df.replace({0:'No', 1:'Yes'})
# mode가 'Model' 인 경우 : 'id' column을 제외
elif mode == 'Model':
df1 = df.iloc[:,1:]
# 예외처리 : Exception 문을 출력하도록 설정하고 함수를 종료 시킴
else:
raise Exception("\nERROR : 'mode' must be 'EDA' or 'Model'")
# 지정한 경로에 DataFrame을 csv로 Export
df1.to_csv(savepath, index=False)
# 동작 여부를 확인하기 위한 테스트용 코드
print(f"csv file for {mode}_{target} exported Successfully")- 2-1_PostgreSQL-Query.py
# Data to csv(final) : column 이름을 추가한 최종 데이터들을 Export함
# EDA 모드에서는 이진변수를 문자열(Yes,No)로 수정
df_to_csv(df_eda_depr, mode='EDA', target='depression', savepath='./2_Modeling/downloads/EDA_depr.csv')
df_to_csv(df_eda_mdd, mode='EDA', target='MDD', savepath='./2_Modeling/downloads/EDA_mdd.csv')
# Model 모드에서는 'id' column을 제외
df_to_csv(df_depr, mode='Model', target='depression', savepath='./2_Modeling/downloads/Model_depr.csv')
df_to_csv(df_mdd, mode='Model', target='MDD', savepath='./2_Modeling/downloads/Model_mdd.csv')
print('Data to csv file : Success\n')
'''
csv file for EDA_depression exported Successfully
csv file for EDA_MDD exported Successfully
csv file for Model_depression exported Successfully
csv file for Model_MDD exported Successfully
Data to csv file : Success
'''Dashboard용 csv 데이터 생성
- Looker Studio에서 직접 PostgreSQL로 서버데이터를 이용하려 했지만, IP주소 할당 문제가 계속 발생하여, 지속적인 서비스를 위해서 csv데이터를 따로 만들어 대시보드 제작에 이용함
- 소스코드는 다음 링크를 통해 확인가능
- 코드 내용이 위에서 실시한 코드들과 거의 유사하기 때문에, 본 블로그 포스팅에서는 특징적으로 차이가 있는 내용들만 따로 정리하도록 하겠음
- SQL 쿼리문
# SQL Qurey문 정의 (변수는 EDA에서 정한 변수로 추출)
sql_query = """
SELECT f.id, y."year", f.age,
f.sex, f1.sex,
f.household, f2.household,
f.marital, f3.marital,
f.subj_health, f4.subj_health,
f.stress, f5.stress,
t.depression, t.mdd
FROM features AS f
JOIN targets AS t ON f.id = t.id
JOIN id_year AS y ON f.id = y.id
JOIN sex AS f1 ON f.sex = f1.id_sex
JOIN household AS f2 ON f.household = f2.id_household
JOIN marital AS f3 ON f.marital = f3.id_marital
JOIN subj_health AS f4 ON f.subj_health = f4.id_subj_health
JOIN stress AS f5 ON f.stress = f5.id_stress
"""- Column 이름 추가
# Column 이름이 없는 상태로 저장되므로 다시 불러와서 Column 이름을 추가
column_list = ['id', 'year', 'age', 'sex', '성별', 'household', '세대유형',
'marital', '혼인상태', 'subj_health', '주관적건강인지도',
'stress', '스트레스인지도', 'Depression', 'MDD']
df_temp = pd.read_csv(save_path_temp, names=column_list)- 변수 재가공 및 재조합
# Age column 범주화
Ages = []
for index, value in enumerate(df_temp.age):
if value < 30:
Ages.append('20s')
elif value < 40:
Ages.append('30s')
elif value < 50:
Ages.append('40s')
elif value < 60:
Ages.append('50s')
elif value < 70:
Ages.append('60s')
elif value < 80:
Ages.append('70s')
else: Ages.append('over 80s')
df_fix = df_temp.copy()
df_fix['나이대'] = Ages
# Depression 과 MDD를 종합한 Column을 새로 생성
Depr_MDD_Code = []
Depr_MDD_label = []
for index in range(df_fix.shape[0]):
if df_fix.loc[index, 'Depression'] == 0:
Depr_MDD_Code.append(0)
Depr_MDD_label.append('정상')
elif df_fix.loc[index, 'MDD'] == 0:
Depr_MDD_Code.append(1)
Depr_MDD_label.append('경도우울증')
elif df_fix.loc[index, 'MDD'] == 1:
Depr_MDD_Code.append(2)
Depr_MDD_label.append('주요우울장애')
df_add_target = df_fix.copy()
df_add_target['Depr_MDD'] = Depr_MDD_Code
df_add_target['우울증분류'] = Depr_MDD_label- Column 순서 바꾸기
# 열 순서 바꾸기
sort_columns = ['id', 'year', 'age', '나이대', 'sex', '성별', 'household', '세대유형',
'marital', '혼인상태', 'subj_health', '주관적건강인지도', 'stress', '스트레스인지도',
'Depression', 'MDD', 'Depr_MDD', '우울증분류']
df_sorted = df_add_target[sort_columns]- csv 파일로 Export
# CSV file로 Export
df_sorted.to_csv(save_path_final, index=False)
print("Column Addition & Saving csv : Success\n")
'''
Column Addition & Saving csv : Success
'''3~. 이후 과정
다음 과정에서는 시각화 분석 및 대시보드 제작에 관련된 내용을 다루도록 하겠음.

일 때문에 포스팅은 잠시 쉬어요 ㅠ // Now. 수학 강사 (광교) // Prev. Machine Learning (AI) Engineer & BackEnd Engineer