
한국형 우울증 딥러닝 예측 모델 및 진단 프로그램 "Kor-DEEPression" 개발 과정 정리 및 회고.
(3) EDA & Dashboard (시각화 분석 & 대시보드)
- (1) Outline & Introduction (개요 & 서론)
- (2) Preprocess & Database (전처리 & 데이터베이스 구축)
- (3) EDA & Dashboard (시각화 분석 & 대시보드)
- (4-1) ML / DL Modeling (모델링)
- (4-2) Final Model & Compression (최종모델 및 모델경량화)
- (5) Deployment & Conclusion (프로그램 배포 & 결론)
Kor-DEEPression
- 한국형 우울증 딥러닝 예측 모델 및 진단 프로그램
- Korean Depression Deep-Learning Model and Diagnosis Program

Project Information
- 프로젝트명 : Kor-DEEPression
- 한국형 우울증 딥러닝 예측 모델 및 진단 프로그램 개발
- Development of Korean Depression Deep-Learning Model and Diagnosis Program
- Codestates AI Bootcamp CP2 project
- 자유주제 개인 프로젝트
- Full-Stack Deep-Learning Project
- DS (Data Science)
- Machine Learning & Deep Learning 모델링
- 모델 성능 평가 및 모델 개선
- 모델 경량화 (tensorflow-lite)
- DA (Data Analysis)
- EDA 및 시각화 분석
- Trend Dashboard 구현 (Looker-Studio)
- DE (Data Engineering)
- Back-end : Cloud DB 구축, 프로그램 Flask 배포
- Front-end : Web page 제작 (HTML5, CSS3)
- DS (Data Science)
Process Pipeline 파이프라인

Outline & Intro. 개요 및 서론
3. Trend Analysis 트렌드 분석
(Part3) Trend Analysis 트렌드 분석
- EDA
탐색적 데이터 분석 - Dashboard
대시보드
3-1. EDA 탐색적 데이터 분석
- 시각화 결과를 담아내기 위해 Jupyter Notebook을 통해 EDA 과정을 진행하였고, 주로 사용된 시각화 라이브러리는
Plotly임 - 자세한 소스 코드들은 아래 링크를 통해서도 확인 가능함
라이브러리 불러오기
# Library Import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as plex
import plotly.graph_objects as go
from plotly.subplots import make_subplots as plsp
# Matplotlib setting for VSCode
plt.rcParams['font.family'] = 'Malgun Gothic'
plt.rcParams['axes.unicode_minus'] = False
# Renderer setting for VSCode & Github
import plotly.io as pio
pio.renderers.default = 'vscode+png'EDA용 데이터 불러오기
# csv파일을 DataFrame으로 불러오기(Depression)
df_depr = pd.read_csv('downloads/EDA_depr.csv')
print("Depression(정상vs우울증)")
df_depr.head()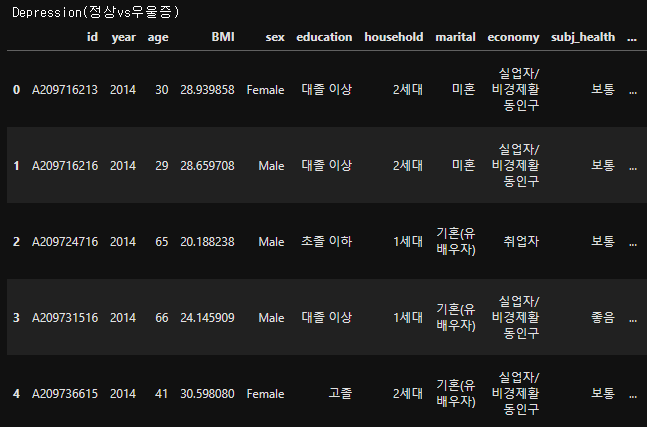
# csv파일을 DataFrame으로 불러오기(MDD)
df_mdd = pd.read_csv('downloads/EDA_mdd.csv')
print("MDD(경도우울vs주요우울)")
df_mdd.head()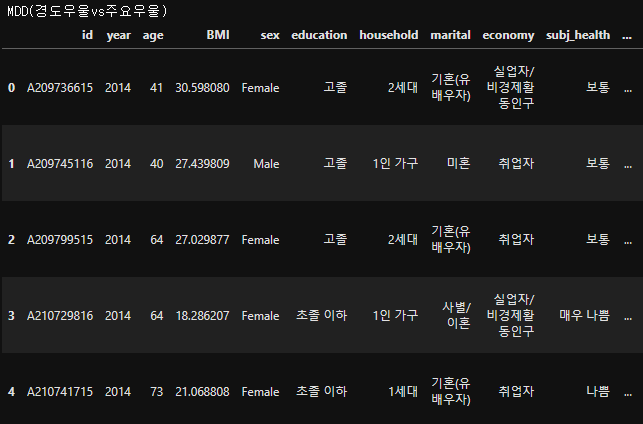
Step1. 데이터 확인
- Shape (모양 확인)
# Shape 확인
print(f"Data Shape (Depression) : {df_depr.shape}")
print(f"Data Shape (MDD) : {df_mdd.shape}")
'''
Data Shape (Depression) : (16570, 21)
Data Shape (MDD) : (3359, 21)
'''- Check Null values & Duplicate values (결측값 및 중복값)
# 결측치 확인
print(f"Sum of Null Values (Depression) : {df_depr.isnull().sum().sum()}")
print(f"Sum of Null Values (MDD) : {df_mdd.isnull().sum().sum()}")
# 중복값 확인 (고유식별코드인 "id" column만 확인)
print(f"Sum of Duplicated Data (Depression) : {df_depr.id.duplicated().sum()}")
print(f"Sum of Duplicated Data (MDD) : {df_mdd.id.duplicated().sum()}")
'''
Sum of Null Values (Depression) : 0
Sum of Null Values (MDD) : 0
Sum of Duplicated Data (Depression) : 0
Sum of Duplicated Data (MDD) : 0
'''- column's dtype 일치여부 확인
# dtype 일치여부 확인
list(df_depr.dtypes) == list(df_mdd.dtypes)
'''
True
'''- Variable Classification (변수 분류)
# 식별코드 "id"를 제외한 변수들의 수치형 변수 및 범주형 변수 갯수 확인
# describe() 함수의 include 기능을 활용하여 갯수를 산출함(number에 int,float 모두 포함되므로 좀 더 간편하게 산출할 수 있음)
print('(Depression)')
print(f"Sum of Numerical Data : {df_depr.iloc[:,1:].describe(include=['number']).shape[1]}")
print(f"Sum of Categorical Data : {df_depr.iloc[:,1:].describe(include=['object']).shape[1]}")
print('(MDD)')
print(f"Sum of Numerical Data : {df_mdd.iloc[:,1:].describe(include=['number']).shape[1]}")
print(f"Sum of Categorical Data : {df_mdd.iloc[:,1:].describe(include=['object']).shape[1]}")
'''
(Depression)
Sum of Numerical Data : 3
Sum of Categorical Data : 17
(MDD)
Sum of Numerical Data : 3
Sum of Categorical Data : 17
'''- 독립변수 및 종속변수 확인
num_cols = list(df_depr.iloc[:,1:].describe(include=['number']).columns[1:])
cat_cols = list(df_depr.iloc[:,1:].describe(include=['object']).columns[:-1])
print("독립변수(Independent Variable)")
print(f"\t수치형 변수(Numerical Data) : 총 {len(num_cols)} 개")
print(f"\t범주형 변수(Categorical Data) : 총 {len(cat_cols)} 개")
print("종속변수(Dependent Variable)")
print(f"\tDepression(정상vs우울증) : '{df_depr.columns[-1]}'")
print(f"\tMDD(경도우울vs주요우울) : '{df_mdd.columns[-1]}'")
'''
독립변수(Independent Variable)
수치형 변수(Numerical Data) : 총 2 개
범주형 변수(Categorical Data) : 총 16 개
종속변수(Dependent Variable)
Depression(정상vs우울증) : 'depression'
MDD(경도우울vs주요우울) : 'MDD'
'''- 데이터 확인 결과 요약

Step2. 종속변수(Targets) 분포(Distribution)
Subject Counts
- Depression(정상vs우울증)
# Group By Target counts
group_depr = df_depr.groupby(['depression'], as_index=False)['id'].count()
display(group_depr)
# 변수 값 수정
count_depr = group_depr.replace({'No': 'Normal (정상)', 'Yes': 'Depression (우울증)'})
display(count_depr)- output
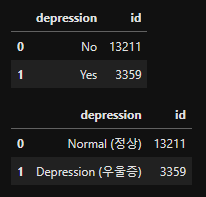
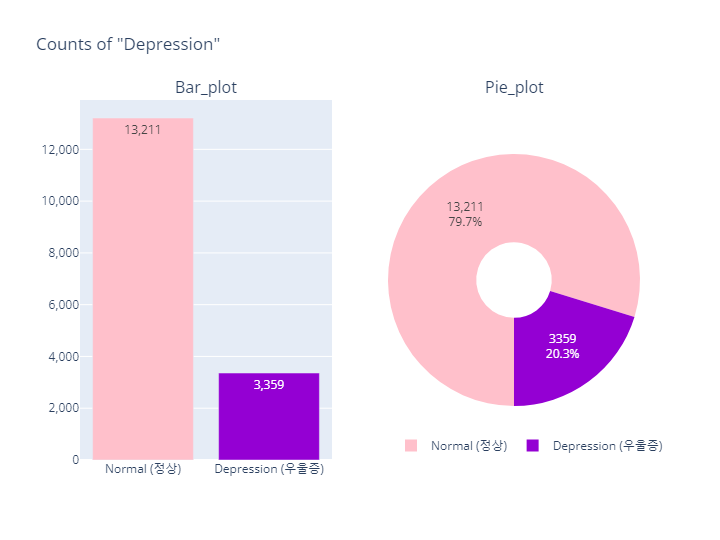
# Depression(정상vs우울증)-Count 시각화
plot_depr = plsp(rows=1, cols=2,
subplot_titles=('Bar_plot','Pie_plot'),
specs=[[{'type':'xy'}, {'type':'domain'}]])
plot_depr.add_trace(
go.Bar(x=count_depr.depression,
y=count_depr.id,
marker_color=['pink', 'darkviolet'],
texttemplate="%{y:,}",
showlegend=False,
hoverinfo='x+y'
),
row=1, col=1
)
plot_depr.add_trace(
go.Pie(values=count_depr.id,
labels=count_depr.depression,
hole=0.3,
showlegend=True,
marker_colors=['pink', 'darkviolet'],
hoverinfo="label+value+percent",
textinfo='value+percent',
rotation=180
),
row=1, col=2
)
plot_depr.update_layout(title_text='Counts of "Depression"',
width=720,
height=540,
legend=dict(orientation='h',
yanchor='bottom', y=0,
xanchor='right', x=1.05))
plot_depr.update_yaxes(tickformat=',')
plot_depr.show()- output
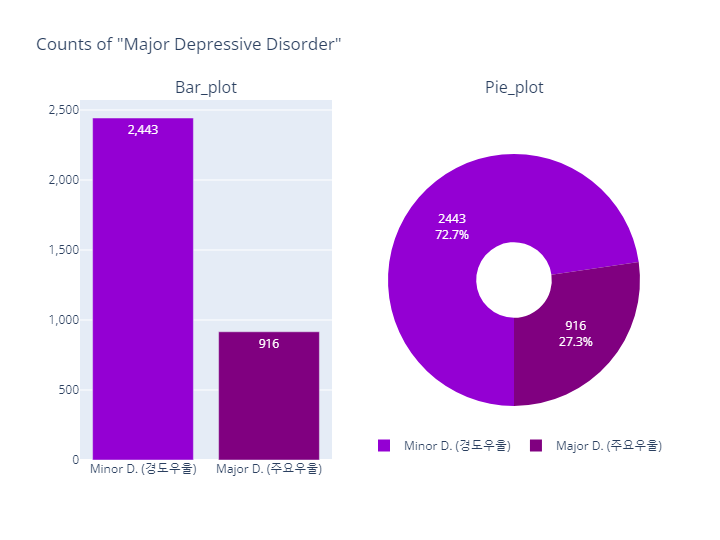
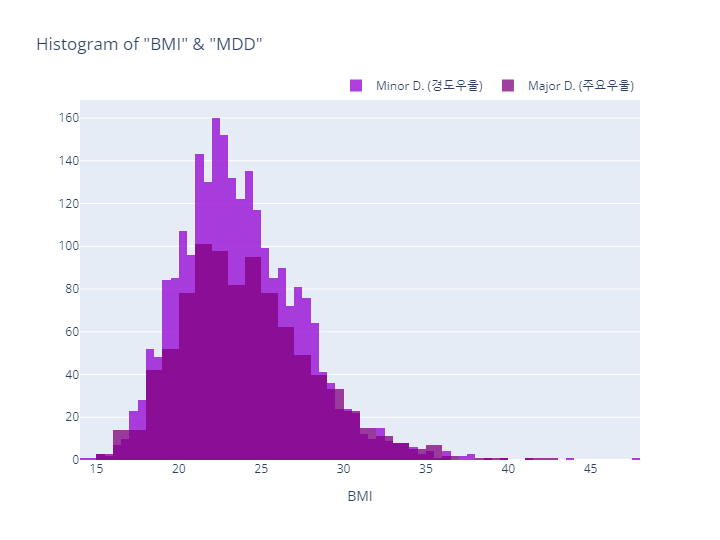
- MDD(경도우울vs주요우울장애)는 코드내용이 동일하므로 결과만 살펴보도록하겠음
Year (연도별 Target 분포)
- Depression(정상vs우울증) - Year
# Group By Target & Year
group_year_depr = df_depr.groupby(['depression', 'year'], as_index=False)['id'].count()
count_year_depr = group_year_depr.replace({'No': 'Normal (정상)', 'Yes': 'Depression (우울증)'})
display(count_year_depr)- output
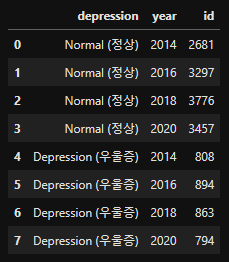
# Depression(정상vs우울증)-Year 시각화
bar_year_depr = plex.bar(data_frame=count_year_depr, barmode='group',
x='year', y='id', color='depression',
text_auto=True, color_discrete_sequence=['pink', 'darkviolet'],
title='Counts of "Depression" by "year"')
bar_year_depr.update_layout(width=720, height=540,
legend_title_text="Depression",
xaxis_title_text="Year",
yaxis_title_text="")
bar_year_depr.update_yaxes(tickformat=',')
bar_year_depr.show()- output
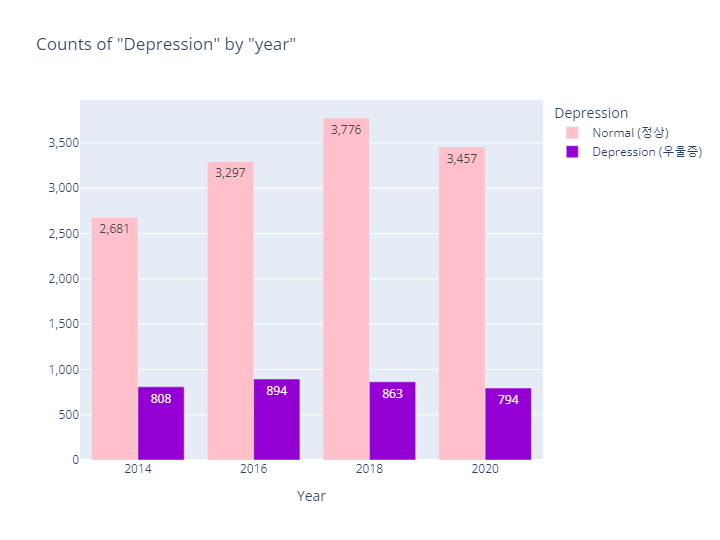
- MDD(경도우울vs주요우울장애)는 코드내용이 동일하므로 결과만 살펴보도록하겠음
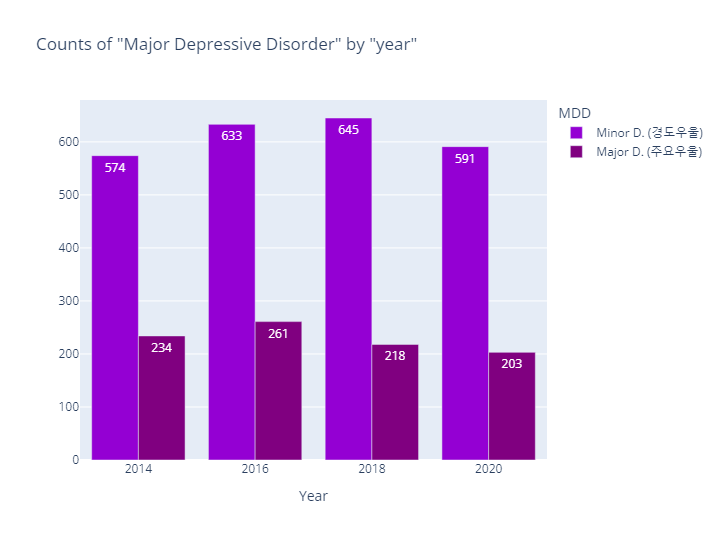
- 종속변수(Targets) 분포(Distribution) 정리

Step3. 독립변수(Features) 분포(Distribution)
수치형(Numerical) 변수
Age (만나이)
# Age(만나이) Histogram (Depression)
sns.histplot(data=df_depr, x='age', kde=True, bins=12, color='darkviolet')
plt.title('Histogram of "Age" (Depression)')
plt.xlabel('Age')
plt.ylabel('')
plt.show()- output
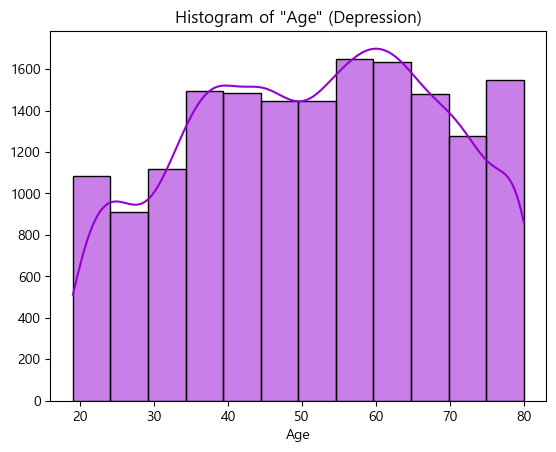
- MDD(경도우울vs주요우울장애)는 Depression(정상vs우울증)과 코드내용이 동일하므로 결과만 살펴보도록하겠음
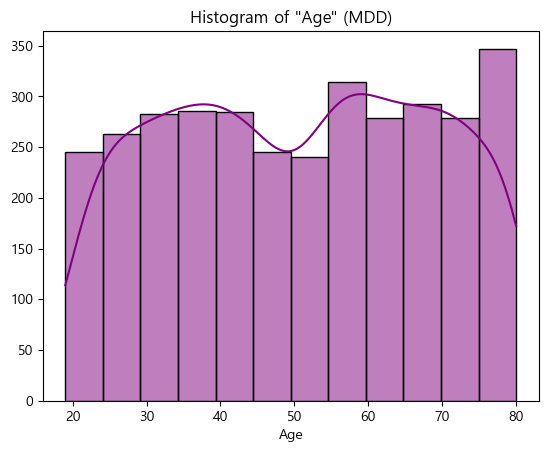
Age & Target
# Age(만나이) & Target Histogram (Depression)
query_age_depr_no = df_depr.query('depression == "No"')
query_age_depr_yes = df_depr.query('depression == "Yes"')
hist_age_depr = go.Figure()
hist_age_depr.add_trace(
go.Histogram(x=query_age_depr_no.age,
nbinsx=12,
name='Normal (정상)',
marker_color='pink',
texttemplate="%{y}",
hoverinfo='x+y')
)
hist_age_depr.add_trace(
go.Histogram(x=query_age_depr_yes.age,
nbinsx=12,
name='Depression (우울증)',
marker_color='darkviolet',
texttemplate="%{y}",
hoverinfo='x+y')
)
hist_age_depr.update_layout(barmode='overlay',
title_text='Histogram of "Age" & "Depression"',
xaxis_title_text="Age",
yaxis_title_text="",
width=720,
height=540,
legend=dict(orientation='h',
yanchor='bottom', y=1,
xanchor='right', x=1))
hist_age_depr.update_xaxes(dtick=10)
hist_age_depr.update_yaxes(tickformat=',')
hist_age_depr.update_traces(opacity=0.75)
hist_age_depr.show()- output
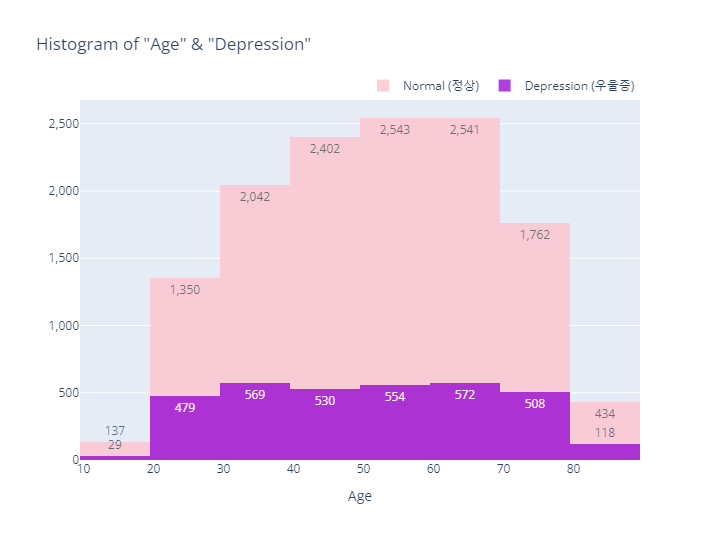
- MDD(경도우울vs주요우울장애)는 Depression(정상vs우울증)과 코드내용이 동일하므로 결과만 살펴보도록하겠음
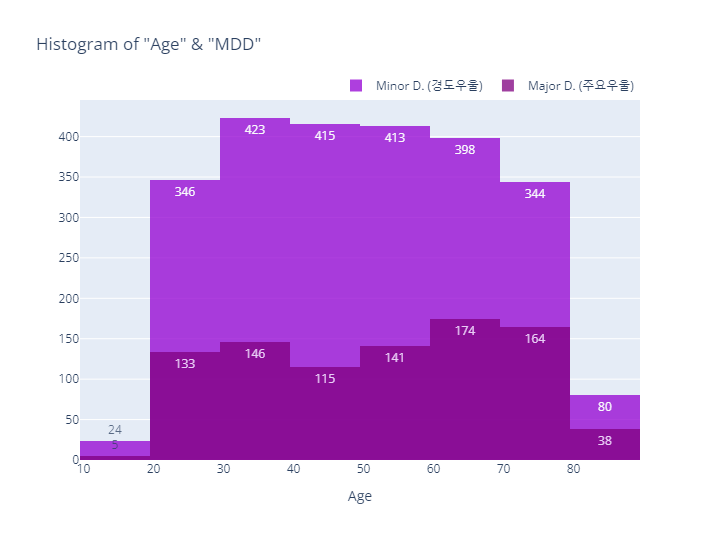
- Age (만나이) 분포 정리

BMI (체질량지수)
# BMI (체질량지수) Histogram (Depression)
sns.histplot(data=df_depr, x='BMI', kde=True, color='darkviolet')
plt.title('Histogram of "BMI" (Depression)')
plt.xlabel('BMI')
plt.ylabel('')
plt.show()- output
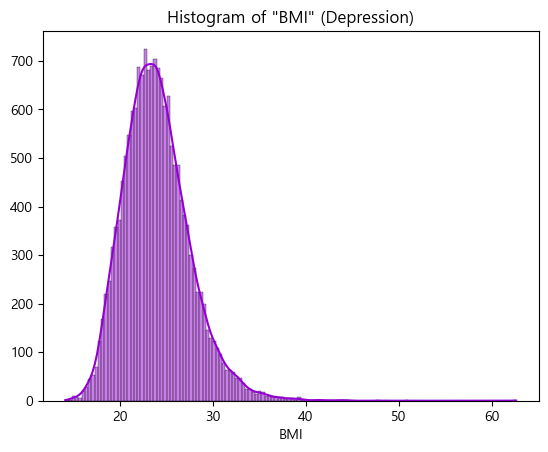
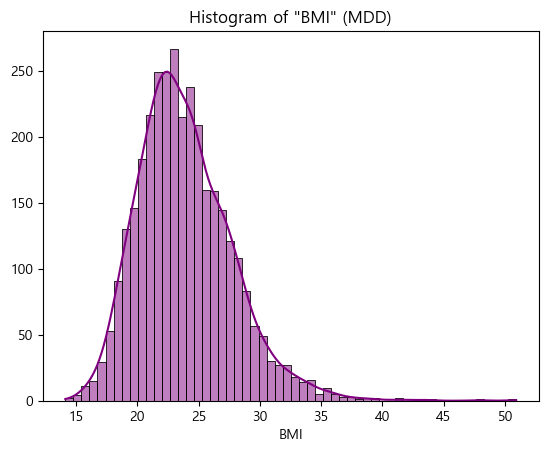
- MDD(경도우울vs주요우울장애)는 Depression(정상vs우울증)과 코드내용이 동일하므로 결과만 살펴보도록하겠음
BMI & Target
# BMI (체질량지수) & Target Histogram (Depression)
query_BMI_depr_no = df_depr.query('depression == "No"')
query_BMI_depr_yes = df_depr.query('depression == "Yes"')
hist_BMI_depr = go.Figure()
hist_BMI_depr.add_trace(
go.Histogram(x=query_BMI_depr_no.BMI,
xbins=dict(end=50),
name='Normal (정상)',
marker_color='pink',
hoverinfo='x+y')
)
hist_BMI_depr.add_trace(
go.Histogram(x=query_BMI_depr_yes.BMI,
xbins=dict(end=50),
name='Depression (우울증)',
marker_color='darkviolet',
hoverinfo='x+y')
)
hist_BMI_depr.update_layout(barmode='overlay',
title_text='Histogram of "BMI" & "Depression"',
xaxis_title_text="BMI",
yaxis_title_text="",
width=720,
height=540,
legend=dict(orientation='h',
yanchor='bottom', y=1,
xanchor='right', x=1))
hist_BMI_depr.update_xaxes(dtick=5)
hist_BMI_depr.update_yaxes(tickformat=',')
hist_BMI_depr.update_traces(opacity=0.75)
hist_BMI_depr.show()- output
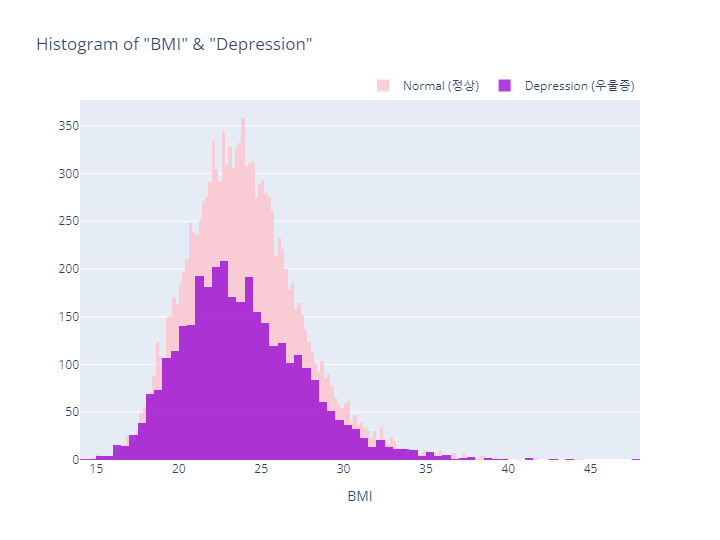
- MDD(경도우울vs주요우울장애)는 Depression(정상vs우울증)과 코드내용이 동일하므로 결과만 살펴보도록하겠음
- BMI (체질량지수) 분포 정리

Step4. 독립변수(Features) 분포(Distribution)
범주형(Categorical) 변수
- 독립변수중 범주형변수가 16개나 되므로 모두 살펴보기엔 너무 많아서 대시보드에 이용할 5가지의 변수들만 추려서 살펴보도록 하겠음.
- sex (성별)
- household (세대 유형)
- marital (혼인상태)
- subj_health (주관적 건강 인지도)
- stress (스트레스 인지도)
- 각 변수 별로 Depression과 MDD 유병률 차이를 살펴볼 것이고, 변수간 조합을 통한 상관관계 분석은 생략
시각화 함수 정의
- Bar plot
# 범주형 변수 bar_plot 함수 정의
def bar_category(target, col, order_list=None):
if target == 'depression':
# Group By Target & column
group_df = df_depr.groupby([target, col], as_index=False)['id'].count()
count_df = group_df.copy()
count_df[target] = count_df[target].replace({'No': 'Normal (정상)', 'Yes': 'Depression (우울증)'})
# 시각화 (depression)
bar_plot = plex.bar(data_frame=count_df, barmode='group',
x=col, y='id', color=target,
text_auto=True, color_discrete_sequence=['pink', 'darkviolet'],
title=f'Bar plot of "Depression" by "{col.capitalize()}"')
elif target == 'MDD':
# Group By Target & column
group_df = df_mdd.groupby([target, col], as_index=False)['id'].count()
count_df = group_df.copy()
count_df[target] = count_df[target].replace({'No': 'Minor D. (경도우울)', 'Yes': 'Major D. (주요우울)'})
# 시각화 (MDD)
bar_plot = plex.bar(data_frame=count_df, barmode='group',
x=col, y='id', color=target,
text_auto=True, color_discrete_sequence=['darkviolet', 'purple'],
title=f'Bar plot of "MDD" by "{col.capitalize()}"')
else:
raise Exception('Error : target must be "depression" or "MDD"')
# 시각화 설정(공통)
bar_plot.update_layout(width=720, height=540,
legend_title_text="",
xaxis_title_text=f"{col.capitalize()}",
yaxis_title_text="",
legend=dict(orientation="h",
yanchor='bottom', y=1,
xanchor='right', x=1))
if order_list:
bar_plot.update_layout(xaxis={'categoryorder':'array', 'categoryarray':order_list})
bar_plot.update_yaxes(tickformat=',')
bar_plot.show() - Pie plot (Sunburst)
# 범주형 변수 pie_plot 함수 정의
def pie_category(target, col):
if target == 'depression':
# Group By Target & column
group_df = df_depr.groupby([target, col]).count()[['id']].rename(columns={'id':'Count'})
group_df['Total'] = 'Total'
count_df = group_df.reset_index()
count_df[target] = count_df[target].replace({'No': 'Normal<br>(정상)', 'Yes': 'Depression<br>(우울증)'})
# 시각화 (depression)
pie_plot = plex.sunburst(data_frame=count_df,
path=['Total',target, col],
values='Count',
color_discrete_sequence=['pink', 'darkviolet'],
title=f'Pie plot of "Depression" by "{col.capitalize()}"')
elif target == 'MDD':
# Group By Target & column
group_df = df_mdd.groupby([target, col]).count()[['id']].rename(columns={'id':'Count'})
group_df['Total'] = 'Total'
count_df = group_df.reset_index()
count_df[target] = count_df[target].replace({'No': 'Minor D.<br>(경도우울)', 'Yes': 'Major D.<br>(주요우울)'})
# 시각화 (MDD)
pie_plot = plex.sunburst(data_frame=count_df,
path=['Total',target, col],
values='Count',
color_discrete_sequence=['darkviolet', 'purple'],
title=f'Pie plot of "MDD" by "{col.capitalize()}"')
else:
raise Exception('Error : target must be "depression" or "MDD"')
# 시각화 설정(공통)
pie_plot.update_traces(textinfo='label+percent parent')
pie_plot.update_layout(width=540, height=540)
pie_plot.show()Sex (성별)
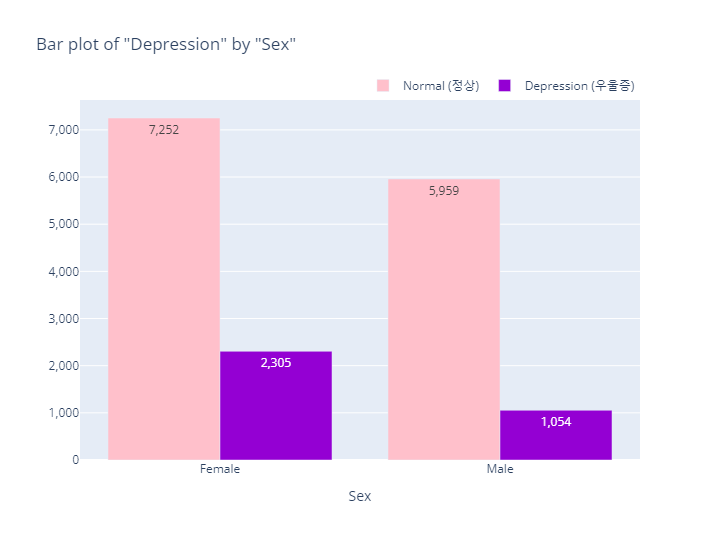
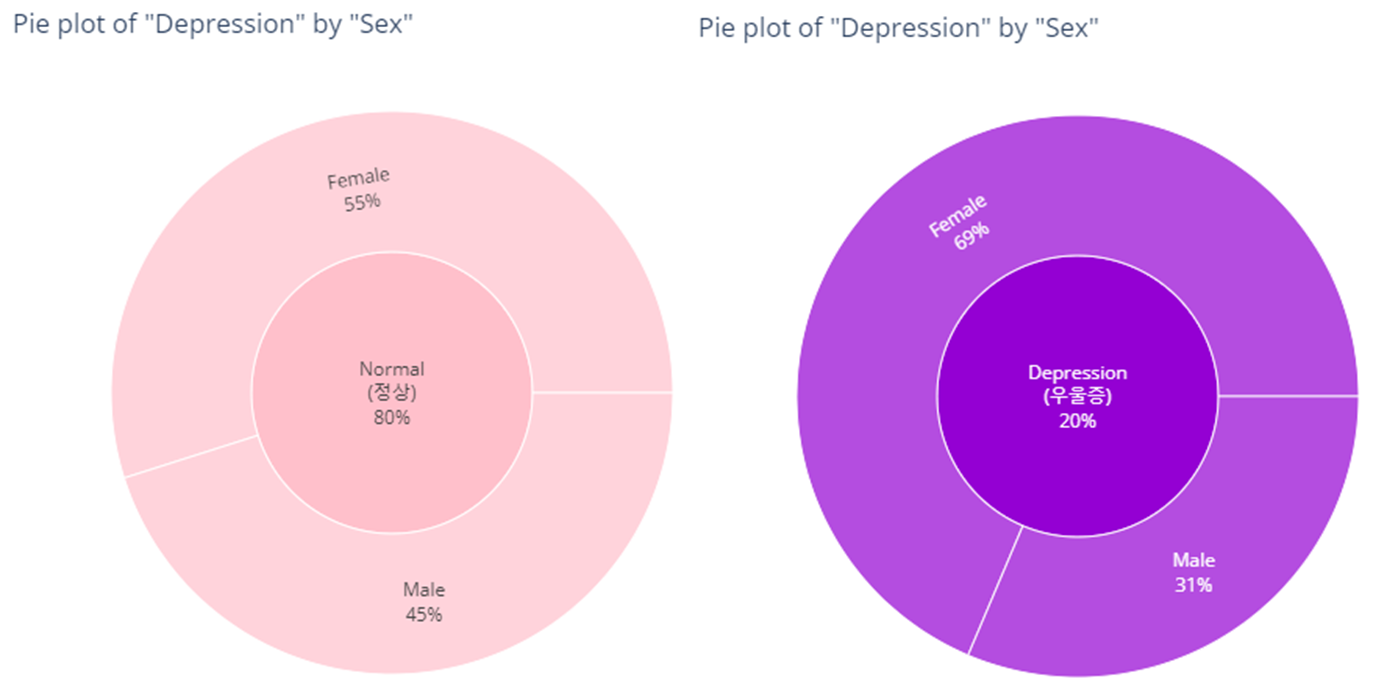
Depression(정상vs우울증)
bar_category(target='depression', col='sex')
pie_category(target='depression', col='sex')- barplot
- pie plot
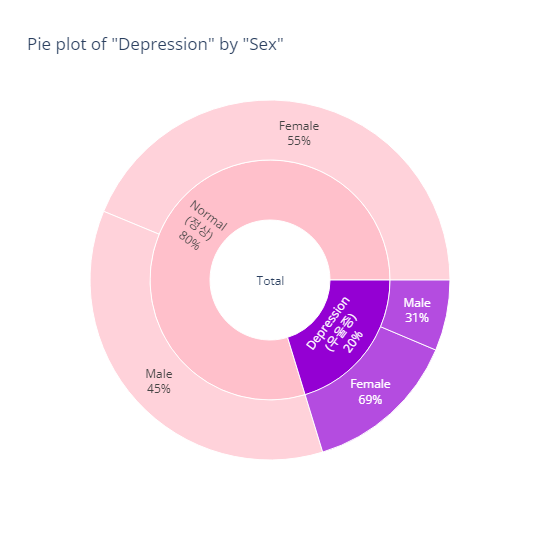
- pie plot (plotly의 장점은 Interactive한 그래프를 만들 수 있다는 것임, 그러나 github에서는 이미지 파일 형태로만 나타낼 수 있어서 renderer 설정을 따로 해줘야함)
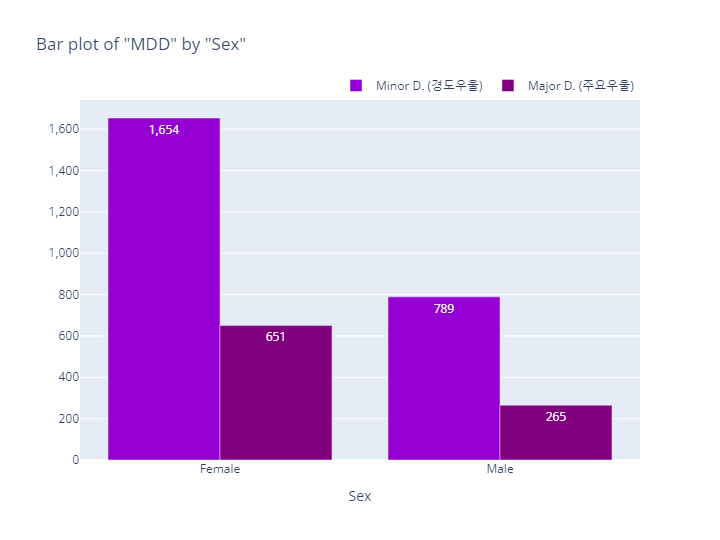
MDD(경도우울vs주요우울장애)
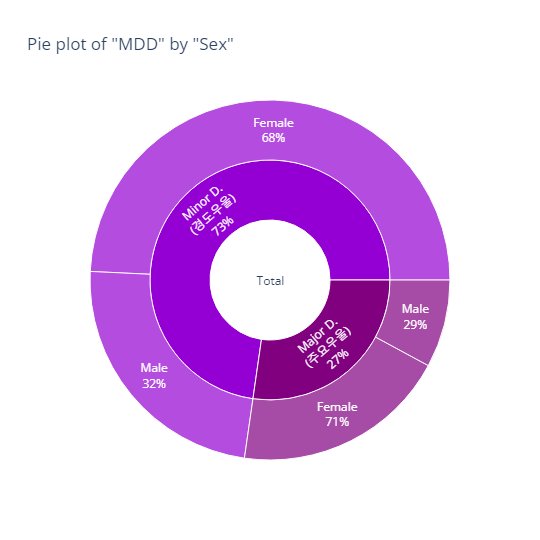
bar_category(target='MDD', col='sex')
pie_category(target='MDD', col='sex')- barplot
- pie plot
- pie plot (plotly의 장점은 Interactive한 그래프를 만들 수 있다는 것임, 그러나 github에서는 이미지 파일 형태로만 나타낼 수 있어서 renderer 설정을 따로 해줘야함)
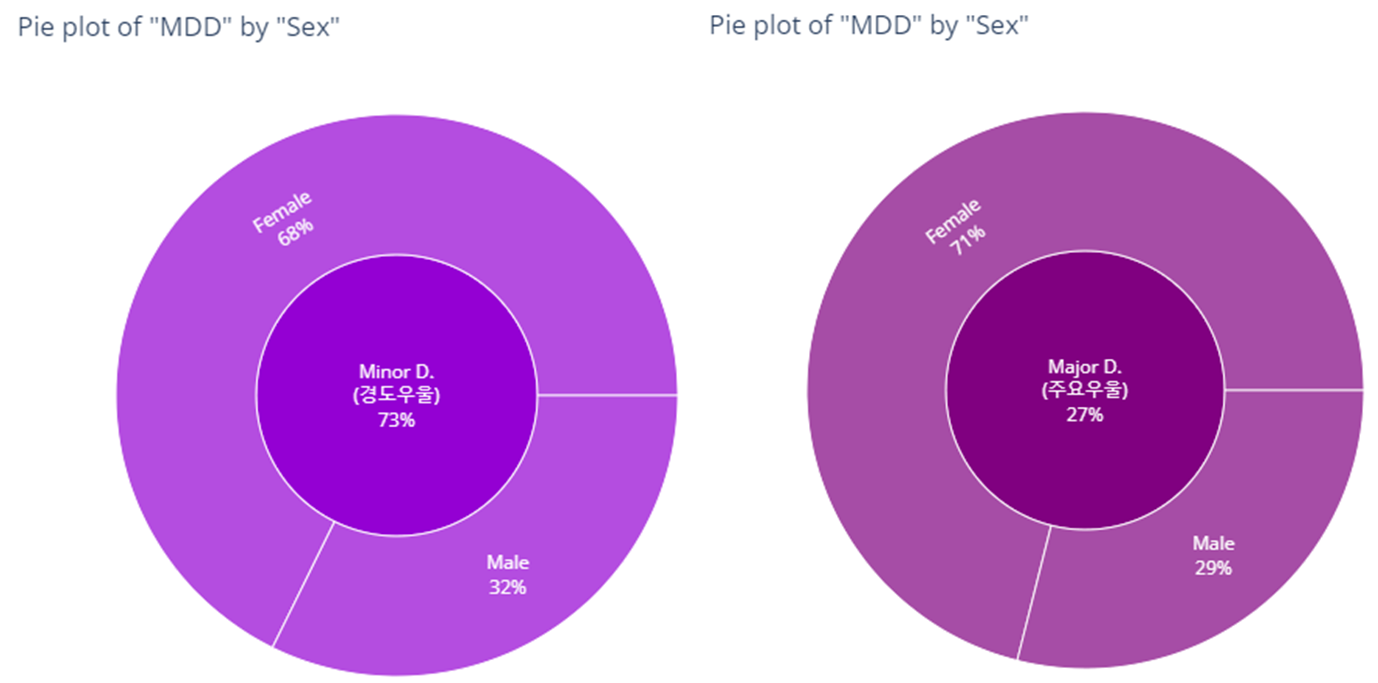
Sex(성별) - 인사이트

- 나머지 변수들은 Interactive pie plot 결과는 제외하고 bar plot과 pie plot만 살펴보도록 하겠음
Household(세대 유형)
Depression(정상vs우울증)
household_order = ['1인 가구', '1세대', '2세대', '3세대 이상']
bar_category(target='depression', col='household', order_list=household_order)
pie_category(target='depression', col='household')- barplot
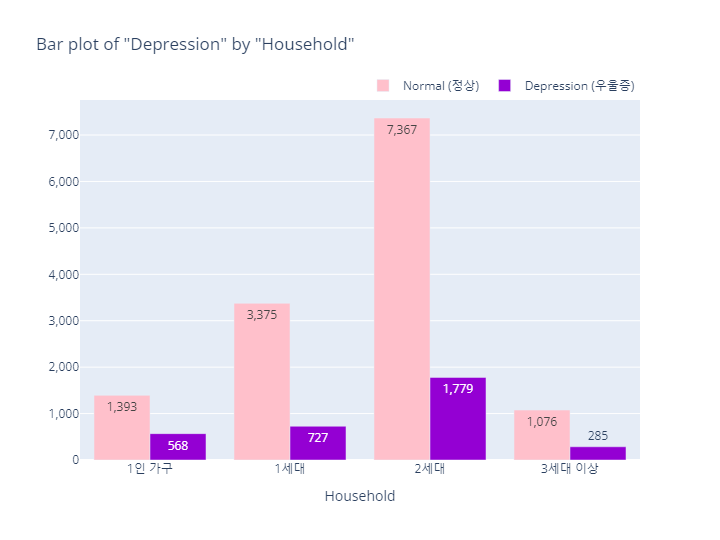
- pie plot
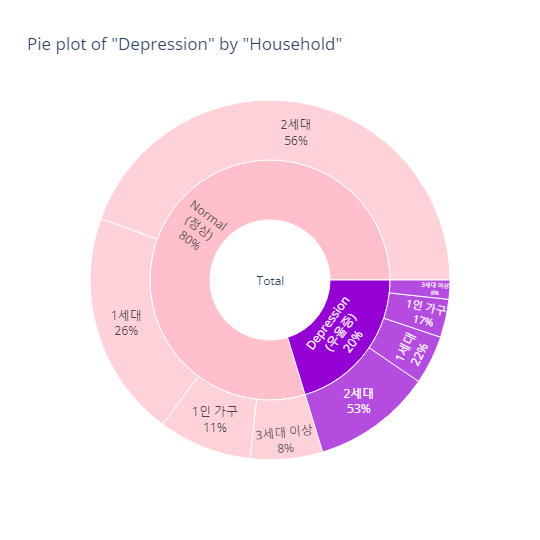
MDD(경도우울vs주요우울장애)
bar_category(target='MDD', col='household', order_list=household_order)
pie_category(target='MDD', col='household')- barplot
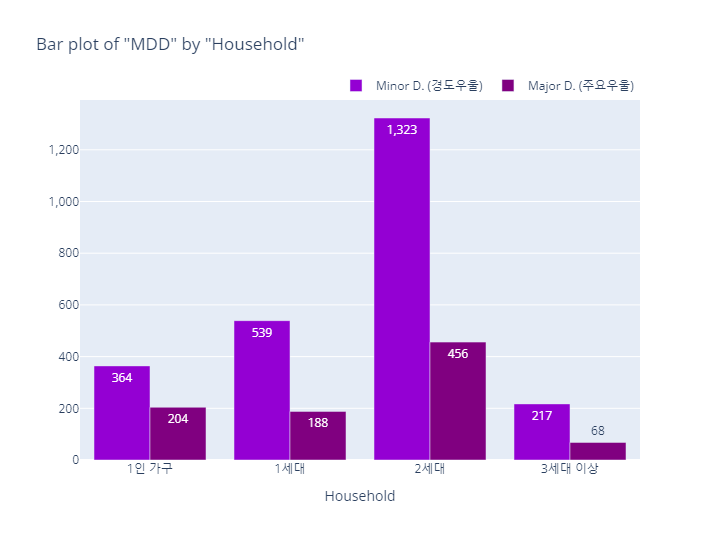
- pie plot
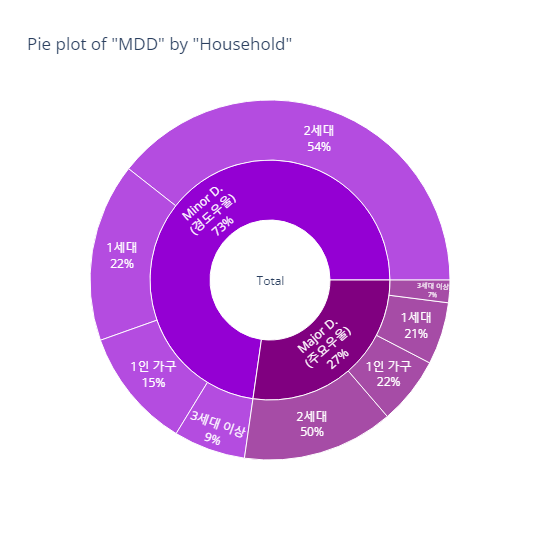
Household(세대 유형) - 인사이트
Marital status (혼인상태)
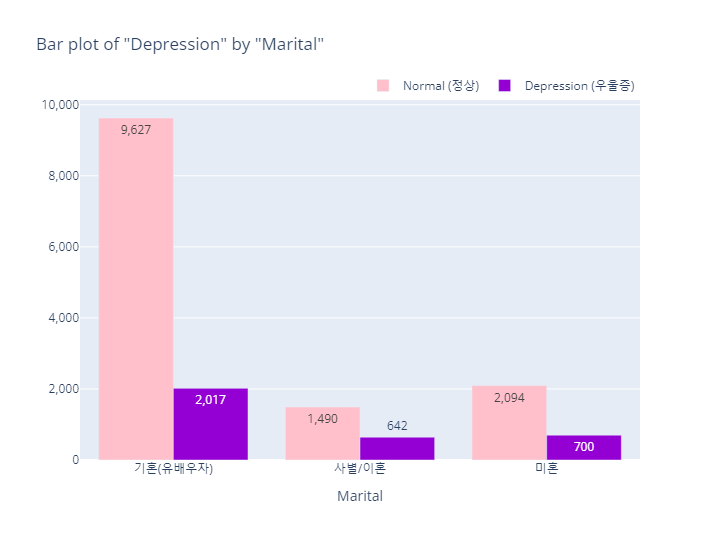
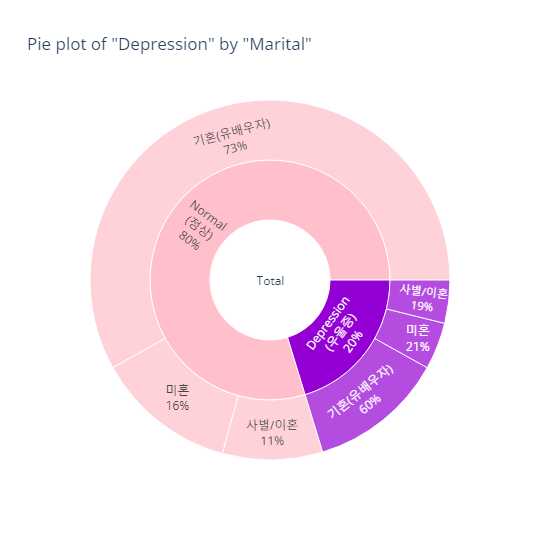
Depression(정상vs우울증)
marital_order = ['기혼(유배우자)', '사별/이혼', '미혼']
bar_category(target='depression', col='marital', order_list=marital_order)
pie_category(target='depression', col='marital')- barplot
- pie plot
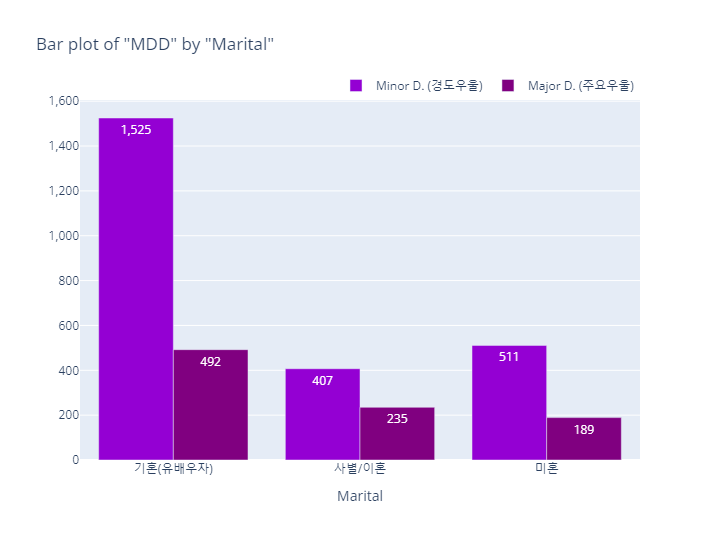
MDD(경도우울vs주요우울장애)
bar_category(target='MDD', col='marital', order_list=marital_order)
pie_category(target='MDD', col='marital')- barplot
- pie plot
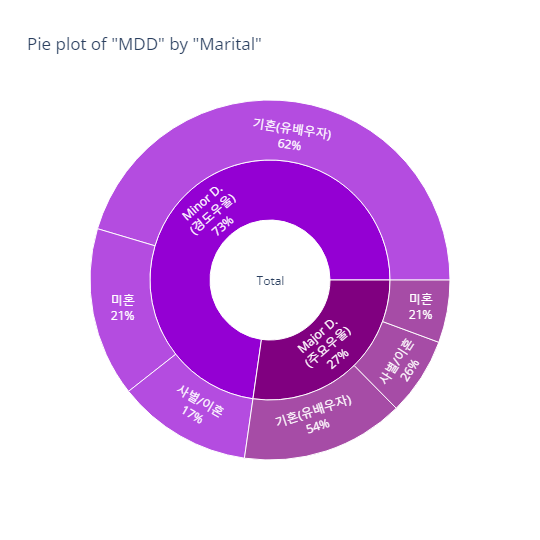
Marital status (혼인상태) - 인사이트

Subjective Health status (주관적 건강 인지도)
Depression(정상vs우울증)
subj_health_order = ['매우 나쁨', '나쁨', '보통', '좋음', '매우 좋음']
bar_category(target='depression', col='subj_health', order_list=subj_health_order)
pie_category(target='depression', col='subj_health')- barplot
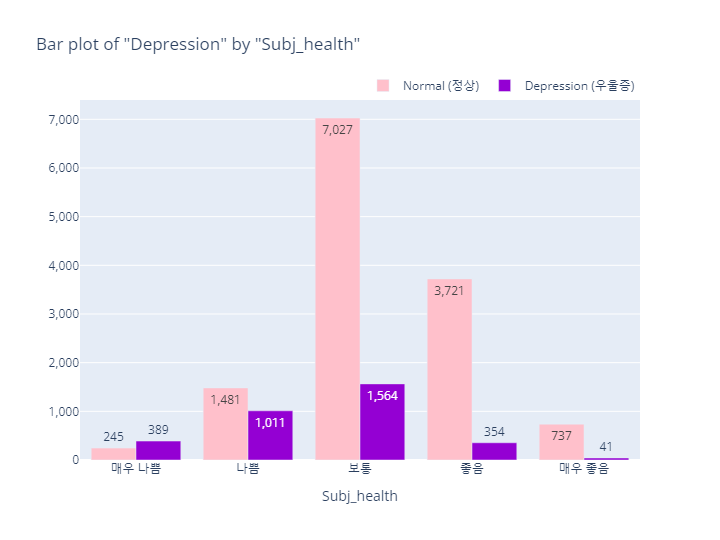
- pie plot
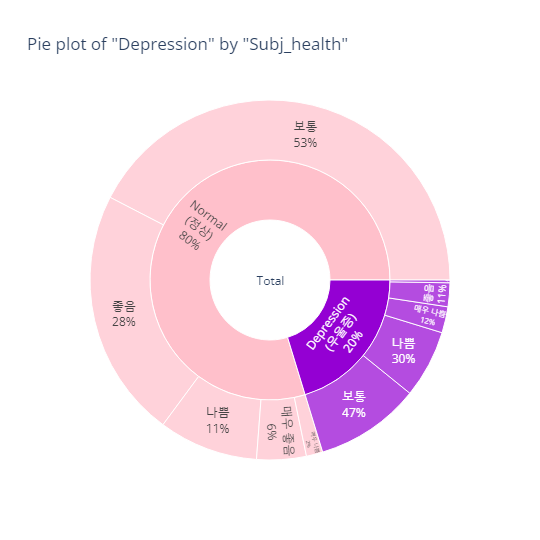
MDD(경도우울vs주요우울장애)
bar_category(target='MDD', col='subj_health', order_list=subj_health_order)
pie_category(target='MDD', col='subj_health')- barplot
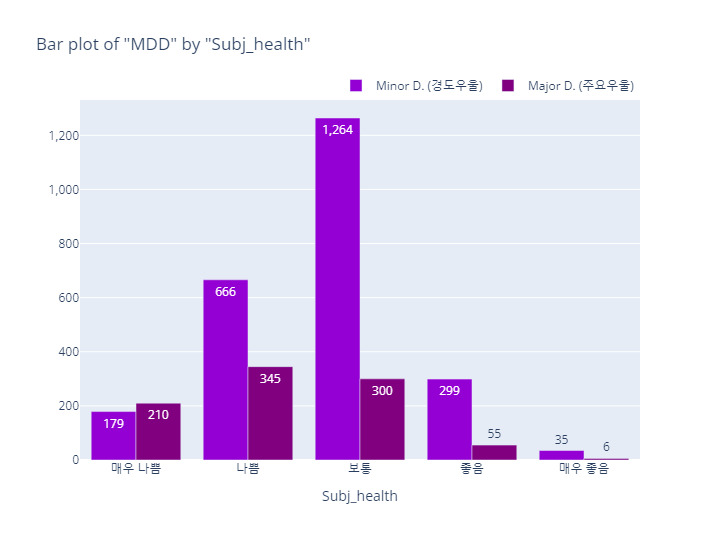
- pie plot
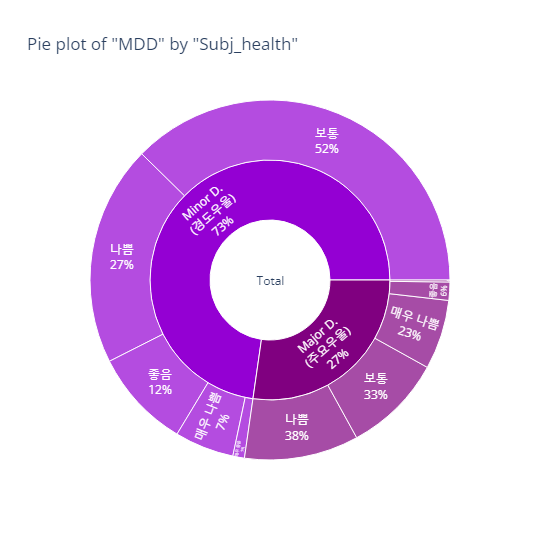
Subjective Health status (주관적 건강 인지도) - 인사이트

Stress (스트레스 인지도)
Depression(정상vs우울증)
stress_order = ['거의 느끼지 않음', '적게 느끼는 편임', '많이 느끼는 편임', '대단히 많이 느낌']
bar_category(target='depression', col='stress', order_list=stress_order)
pie_category(target='depression', col='stress')- barplot
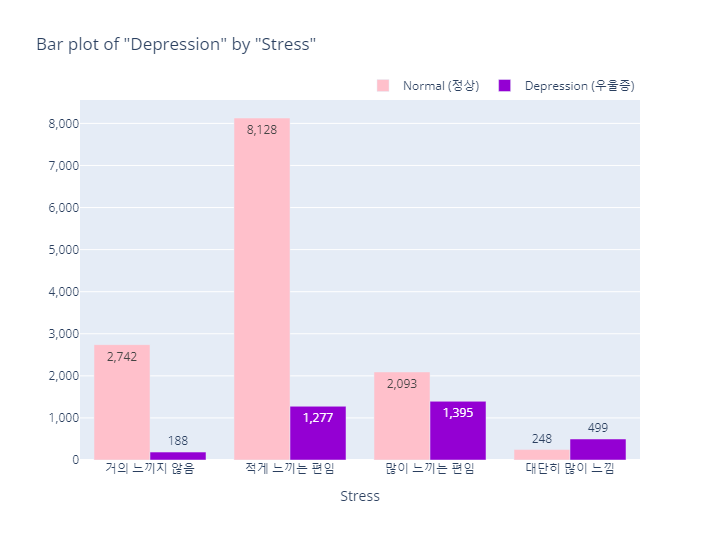
- pie plot

MDD(경도우울vs주요우울장애)
bar_category(target='MDD', col='stress', order_list=stress_order)
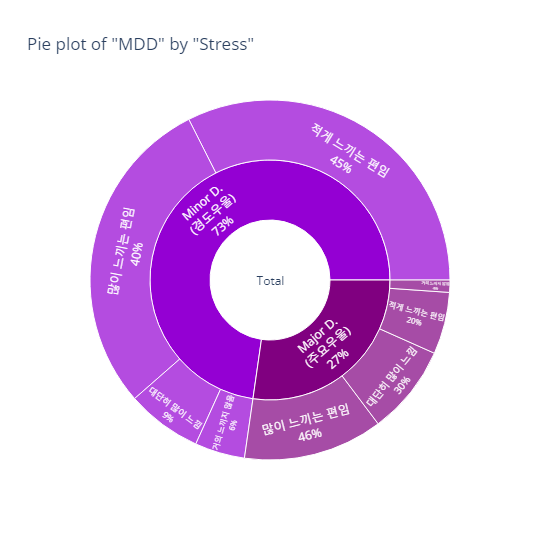
pie_category(target='MDD', col='stress')- barplot
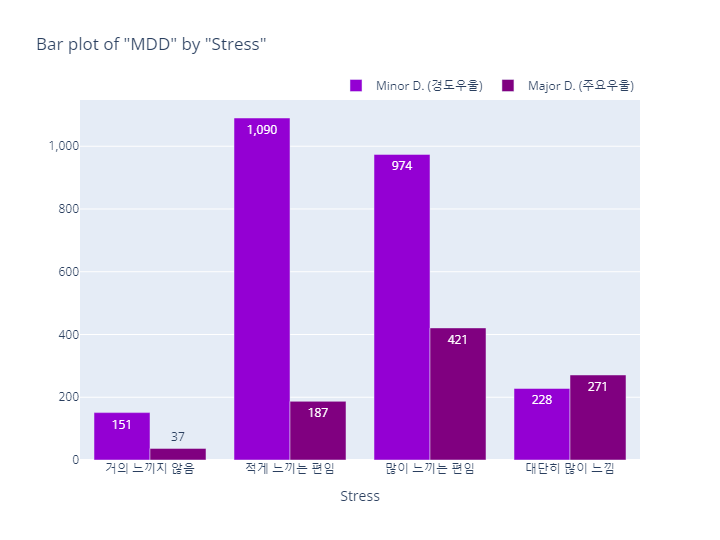
- pie plot
Stress (스트레스 인지도) - 인사이트

Step5. EDA 결론 및 모델링 전 체크사항

3-2. Dashboard 대시보드
- Dashboard는 Google Looker Studio를 통해 구현하였으며, 대시보드 링크는 다음과 같음
- 하지만 웹페이지를 통해 Embedding하였기 때문에, 아래 링크를 통해서도 확인할 수 있음
<대시보드 스크린샷>
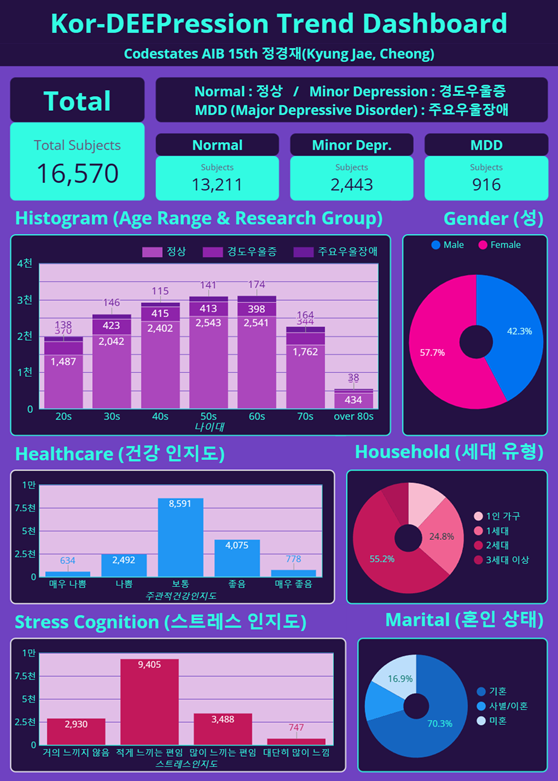
- 대시보드의 경우 처음에는 PostgreSQL을 통해 DB에서 직접 가져와서 진행하고자 했으나, IP주소 할당을 새로 해야하는 경고문이 생김. 지속적인 이용을 위해 유료결제가 필요한 부분이었기 때문에, csv 파일을 통해 dashboard를 제작하였음.
- 웹페이지 임베딩 과정은 추후에 웹 배포 과정을 다루는 글을 통해 다시 다룰 예정임
4~. 이후 과정
다음 과정에서는 머신러닝 및 딥러닝 모델링 및 성능비교분석 과정을 다루도록 하겠음.

일 때문에 포스팅은 잠시 쉬어요 ㅠ // Now. 수학 강사 (광교) // Prev. Machine Learning (AI) Engineer & BackEnd Engineer