
한국형 우울증 딥러닝 예측 모델 및 진단 프로그램 "Kor-DEEPression" 개발 과정 정리 및 회고.
(4-2) Final Model & Compression (최종모델 및 모델경량화)
- (1) Outline & Introduction (개요 & 서론)
- (2) Preprocess & Database (전처리 & 데이터베이스 구축)
- (3) EDA & Dashboard (시각화 분석 & 대시보드)
- (4-1) ML / DL Modeling (모델링)
- (4-2) Final Model & Compression (최종모델 및 모델경량화)
- (5) Deployment & Conclusion (프로그램 배포 & 결론)
Kor-DEEPression
- 한국형 우울증 딥러닝 예측 모델 및 진단 프로그램
- Korean Depression Deep-Learning Model and Diagnosis Program

Project Information
- 프로젝트명 : Kor-DEEPression
- 한국형 우울증 딥러닝 예측 모델 및 진단 프로그램 개발
- Development of Korean Depression Deep-Learning Model and Diagnosis Program
- Codestates AI Bootcamp CP2 project
- 자유주제 개인 프로젝트
- Full-Stack Deep-Learning Project
- DS (Data Science)
- Machine Learning & Deep Learning 모델링
- 모델 성능 평가 및 모델 개선
- 모델 경량화 (tensorflow-lite)
- DA (Data Analysis)
- EDA 및 시각화 분석
- Trend Dashboard 구현 (Looker-Studio)
- DE (Data Engineering)
- Back-end : Cloud DB 구축, 프로그램 Flask 배포
- Front-end : Web page 제작 (HTML5, CSS3)
- DS (Data Science)
Process Pipeline 파이프라인

Outline & Intro. 개요 및 서론
4. Modeling 모델링
(Part 4-1 ~ 4-5) Modeling 모델링
- Preprocessing for Modeling
모델링용 전처리 - Logistic Regression
로지스틱 회귀 - LightGBM
LGBM 모델 - MLP
다층 퍼셉트론 신경망 - 1D-CNN
합성곱층 신경망
(Part 4-6, 4-7) Final Model최종모델 - Final Model
최종 모델 선정 - Model Compression
모델 경량화
4-6. Final Model 최종 모델 선정
- 현재까지 튜닝하고 재학습하여 저장한 모델들에 대해서 Cross-validation을 통해 성능 비교를 실시한 이후에 타겟별로 최종 모델을 선정하였으며, 시각화를 통한 분석을 위해 Jupyter Notebook을 통해 코드 결과들을 담아냈음

- 이번 비교분석에서는 함수들을 따로 모듈화하지 않고 하나의 파일 안에서 프로그래밍을 실시하였으며 전체적인 진행순서는 다음과 같음
- 데이터를 불러온 뒤 학습,검증,예측용 데이터에 대한 EDA(탐색적분석) 실시
- 데이터 분리(Train & Test) 후 Baseline Model(최빈 Class) 정의
- 튜닝 후 저장된 데이터를 불러온 뒤 Cross-validation 실시
- 성능 비교 분석 후 최종 모델 선정
- 최종 모델 예측 테스트 실시
💻 Library Import (라이브러리 불러오기)
# 데이터 관련 Library Import
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
# 시각화 관련 Library Import
import matplotlib.pyplot as plt
import seaborn as sns
# Matplotlib setting for VSCode
plt.rcParams['font.family'] = 'Malgun Gothic'
plt.rcParams['axes.unicode_minus'] = False
# Model 불러오기 관련 Library Import
import pickle
from keras.models import load_model
# Cross Validation 관련 Library Import
from sklearn.model_selection import cross_val_score, cross_val_predict, StratifiedKFold
from sklearn.metrics import accuracy_score, roc_auc_score
# Cross Validation 시각화 관련 Library Import
from sklearn.metrics import roc_curve, confusion_matrix🧠 Depression
(정상 vs 우울증)
💾 데이터 불러오기
# 전처리를 마친 데이터를 불러오기
df_depr = pd.read_csv("./downloads/Encoded_depr.csv")
print(f"Depression Dataset Shape : {df_depr.shape}")
'''
Depression Dataset Shape : (16570, 48)
'''⚙️ Feature, Target 분리
# Feature, Target 분리
features_depr = df_depr.drop(columns='depression')
target_depr = df_depr['depression']
# Shape 확인
print(f"분리 전 Shape : {df_depr.shape}")
print(f"\n분리 후 Shape : {features_depr.shape}, {target_depr.shape}")
'''
분리 전 Shape : (16570, 48)
분리 후 Shape : (16570, 47), (16570,)
'''📊 Target 분포 확인
# Target 수 확인
count_depr = target_depr.value_counts().sort_index()
print("Target(depression) 수")
print(count_depr)
# Target 비율 확인
ratio_depr = target_depr.value_counts(normalize=True).sort_index()
print("\nTarget(depression) 비율")
print(ratio_depr)
'''
Target(depression) 수
0 13211
1 3359
Name: depression, dtype: int64
Target(depression) 비율
0 0.797284
1 0.202716
Name: depression, dtype: float64
'''- 시각화
# label 정의
label_depr = ['정상(0)', '우울증(1)']
# 시각화 (빈도)
ax_bar_depr = sns.countplot(x=target_depr)
ax_bar_depr.bar_label(ax_bar_depr.containers[0])
plt.xticks([0,1], label_depr)
plt.title("Count plot of Target(Depression)")
plt.xlabel("Depression")
plt.ylabel("")
plt.show()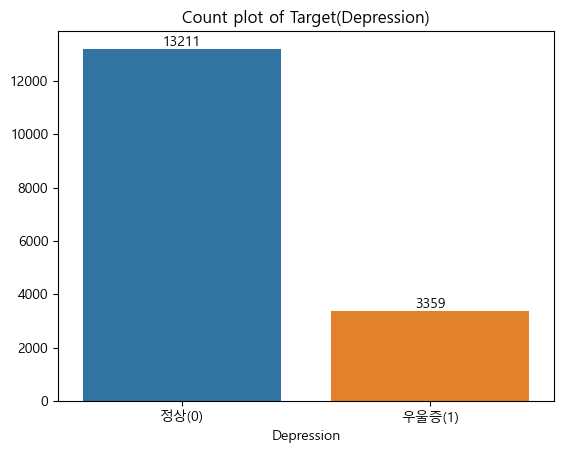
# 시각화 (비율)
plt.pie(x = count_depr, labels=label_depr, autopct='%.2f%%', startangle=90)
plt.legend(loc = 'upper left')
plt.title('우울증(depression) 비율 pie plot')
plt.show()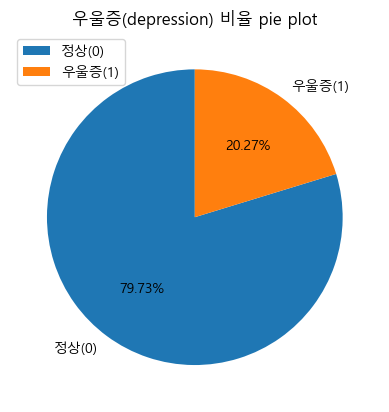
🔎 Feature 분포 확인
# 수치형변수(age, BMI) 분포, 상관관계 시각화
num_feat = ['age', 'BMI']
sns.pairplot(features_depr[num_feat])
plt.suptitle("Pair plot of 'age' & 'BMI' (Depression)", y=1.05)
plt.show()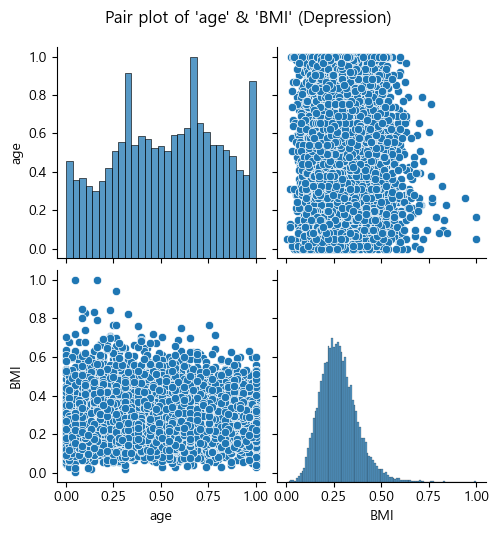
# Feature Column 표준화 여부 확인 (min, max 값 확인)
print(f"Feature Min Value : {features_depr.min().min()}")
print(f"Feature Max Value : {features_depr.max().max()}")
'''
Feature Min Value : 0.0
Feature Max Value : 1.0
'''⚙️ Train, Test 데이터 분리
# Train, Test 분리 (test 비율 20%, seed=2023)
X_train_depr, X_test_depr, y_train_depr, y_test_depr = train_test_split(
features_depr, target_depr, test_size=0.2, random_state=2023)
print('X_train_depr : {}'.format(X_train_depr.shape))
print('y_train_depr : {}'.format(y_train_depr.shape))
print('\nX_test_depr : {}'.format(X_test_depr.shape))
print('y_test_depr : {}'.format(y_test_depr.shape))
'''
X_train_depr : (13256, 47)
y_train_depr : (13256,)
X_test_depr : (3314, 47)
y_test_depr : (3314,)
'''# Train, Test의 Target 데이터 비율 확인
print("Depression - Train")
print(y_train_depr.value_counts(normalize=True))
print("\nDepression - Test")
print(y_test_depr.value_counts(normalize=True))
'''
Depression - Train
0 0.79564
1 0.20436
Name: depression, dtype: float64
Depression - Test
0 0.803862
1 0.196138
Name: depression, dtype: float64
'''⚙️ Baseline Model 정의 (최빈 Class 비율)
# 최빈값 지정 및 Baseline 모델 정의
mode_depr = y_train_depr.mode()[0]
baseline_depr = [mode_depr]*len(y_train_depr)
# Baseline Accuracy & ROC_AUCscore 산출
baseline_acc_depr = accuracy_score(y_train_depr, baseline_depr)
baseline_AUC_depr = roc_auc_score(y_train_depr, baseline_depr)
print("[Depression]")
print("Baseline Accuracy : {:.4f}".format(baseline_acc_depr))
print("Baseline AUC_score : {}".format(baseline_AUC_depr))
'''
[Depression]
Baseline Accuracy : 0.7956
Baseline AUC_score : 0.5
'''🛠️ Cross-Validation (Depression) - Logistic Regression
- Accuracy (정확도)
# Tuning Model 불러오기 (Decoding, 복호화)
model_logistic_depr = pickle.load(open("../tuning-models/Logistic_depr.pkl", "rb"))
# 학습 실시 (Fit)
model_logistic_depr.fit(X_train_depr, y_train_depr)
# CV Accuracy(정확도) 산출 (cv=4)
CV_acc_logistic_depr = cross_val_score(estimator = model_logistic_depr,
X=X_train_depr, y=y_train_depr,
cv=4, n_jobs=-1, scoring='accuracy')
print("[Depression]")
print("Baseline Accuracy : {:.4f}".format(baseline_acc_depr))
print("LogisticRegression Accuracy : {:.4f}".format(CV_acc_logistic_depr.mean()))
'''
[Depression]
Baseline Accuracy : 0.7956
LogisticRegression Accuracy : 0.8300
'''- CV Prediction (교차검증 예측)
# CV prediction 실시
CV_pred_logistic_depr = cross_val_predict(estimator = model_logistic_depr,
X=X_train_depr, y=y_train_depr,
cv=4, n_jobs=-1)
# Table을 통해 확인해보기
df_pred_logistic_depr = pd.DataFrame(data={'true_depr': y_train_depr,
'pred_depr': CV_pred_logistic_depr})
table_pred_logistic_depr = pd.crosstab(df_pred_logistic_depr['true_depr'],
df_pred_logistic_depr['pred_depr'])
display(table_pred_logistic_depr)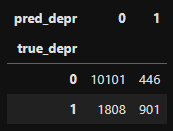
# Confusion matrix (혼동행렬)
cfm_logistic_depr = confusion_matrix(y_train_depr, CV_pred_logistic_depr)
# 시각화에 표시할 값들을 정의하기
group_names_logistic_depr = ['True Negative','False Positive','False Negative','True Positive']
group_counts_logistic_depr = ['{0:0.0f}'.format(value) for value in cfm_logistic_depr.flatten()]
group_percent_logistic_depr = ['{0:.2%}'.format(value) for value in cfm_logistic_depr.flatten()/np.sum(cfm_logistic_depr)]
labels_logistic_depr = [f'{v1}\n\n{v2}\n\n{v3}' for v1,v2,v3 in zip(group_names_logistic_depr,
group_counts_logistic_depr,
group_percent_logistic_depr)]
labels_logistic_depr = np.asarray(labels_logistic_depr).reshape(2,2)
tick_logistic_depr = ['정상(0)', '우울증(1)']
# 시각화(heatmap)
sns.heatmap(cfm_logistic_depr, annot=labels_logistic_depr, fmt='', cmap='Blues',
xticklabels=tick_logistic_depr, yticklabels=tick_logistic_depr)
plt.xlabel("Prediction(예측값)")
plt.ylabel("True(실제값)")
plt.title("Confusion matrix of Logistic Regression\n[Depression] (CV=4)")
plt.show()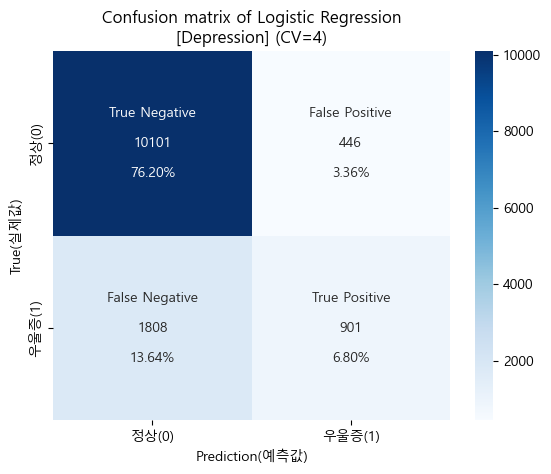
- ROC_AUC score
# ROC curve 그리기 (KFold 이용)
kf_4 = StratifiedKFold(n_splits=4, shuffle=True, random_state=2023)
# TPR(True Positive Rate) 리스트
TPRs_logistic_depr = []
# FPR 축의 정밀도를 계산할 기본 linespace 정의(300개의 값이 들어가도록 설정함)
base_FPR_logistic_depr = np.linspace(0,1,300)
# Cross-validation 및 ROC curve plotting 실시 (KFold)
for train_idx, val_idx in kf_4.split(X_train_depr, y_train_depr):
# Train, Validation Split
X_train_cv, X_val_cv = X_train_depr.iloc[train_idx], X_train_depr.iloc[val_idx]
y_train_cv, y_val_cv = y_train_depr.iloc[train_idx], y_train_depr.iloc[val_idx]
# Fit
model_logistic_depr.fit(X_train_cv, y_train_cv)
# Predict Probability
y_val_prob = model_logistic_depr.predict_proba(X_val_cv)[:,1]
# get FRP, TPR
FPR, TPR, _ = roc_curve(y_val_cv, y_val_prob)
# plot ROC curve (투명하게 설정)
plt.plot(FPR, TPR, alpha=0.25)
# 기본 linespace에 대응하는 TPR array 생성후 값을 append하기
TPR_depr = np.interp(x=base_FPR_logistic_depr, xp=FPR, fp=TPR)
TPR_depr[0] = 0.0
TPRs_logistic_depr.append(TPR_depr)
# TPR 리스트를 array로 변환 후 평균값의 array 생성
TPRs_logistic_depr = np.array(TPRs_logistic_depr)
mean_TPRs_logistic_depr = TPRs_logistic_depr.mean(axis=0)
# 평균 ROC curve plotting
plt.plot(base_FPR_logistic_depr, mean_TPRs_logistic_depr,
label='LogisticRegression(CV=4)', color='Blue')
# Baseline plotting
plt.plot([0,1],[0,1], label='Baseline', color='black', linestyle='--', alpha=0.5)
# plot 설정
plt.xlabel('FPR (False Positive Rate)')
plt.ylabel('TPR (True Positive Rate)')
plt.title("ROC_curve of Logistic Regression\n[Depression] (CV=4)")
plt.legend(loc='lower right')
plt.show()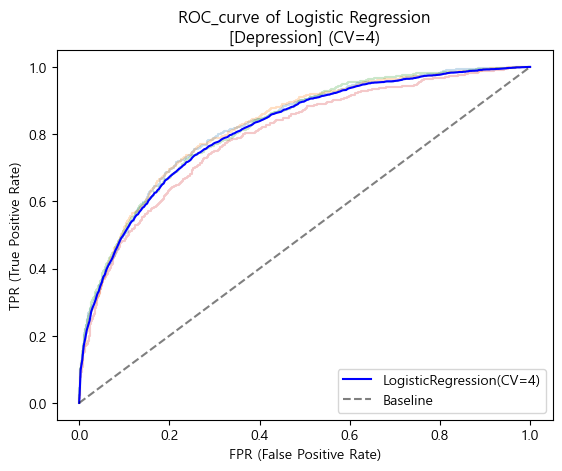
# ROC_AUC score 산출 (cv=4)
CV_AUC_logistic_depr = cross_val_score(estimator = model_logistic_depr,
X=X_train_depr, y=y_train_depr,
cv=4, n_jobs=-1, scoring='roc_auc')
print("[Depression]")
print("Baseline AUC score : {:.4f}".format(baseline_AUC_depr))
print("LogisticRegression AUC score : {:.4f}".format(CV_AUC_logistic_depr.mean()))
'''
[Depression]
Baseline AUC score : 0.5000
LogisticRegression AUC score : 0.8161
'''🛠️ Cross-Validation (Depression) - LightGBM Classifier
-
코드는 Logistic Regression과 동일하기 때문에, 결과만을 다루도록 하겠음.
-
Accuracy (정확도)
'''
[Depression]
Baseline Accuracy : 0.7956
LightGBM Accuracy : 0.8296
'''-
CV Prediction (교차검증 예측)
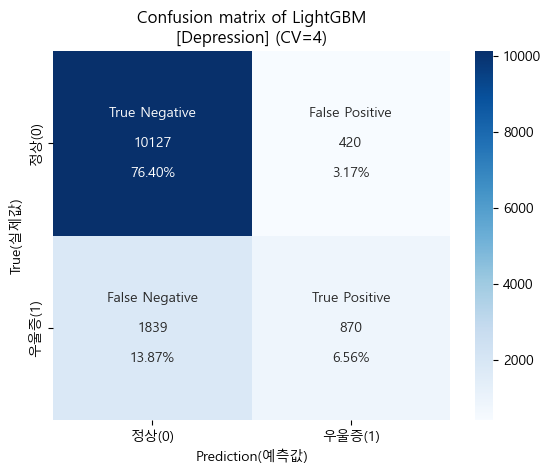
-
ROC_AUC score
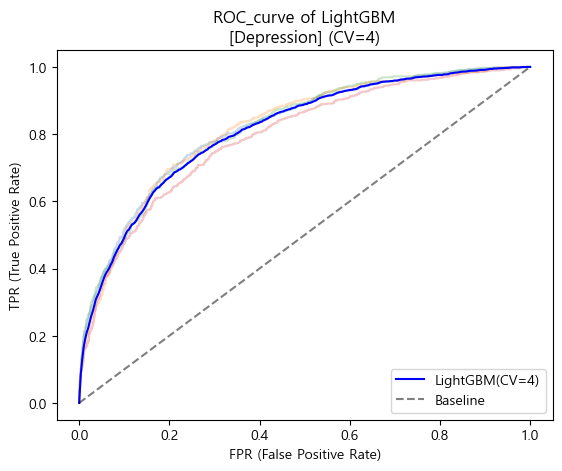
'''
[Depression]
Baseline AUC score : 0.5000
LightGBM AUC score : 0.8154
'''🛠️ Cross-Validation (Depression) - MLP(Multi Layer Perceptron)
- 딥러닝 모델인 MLP와 1D-CNN은 머신러닝 모델에서 진행한 Scikit-Learn의 기능들을 이용하려면 wrapper 기능으로 변환하는 작업이 필요함.
- 하지만... SciKeras 라이브러리를 통해 이를 시도해본 결과 오류가 너무 많이 발생하기도하고 속도도 현저히 느려져서 K-fold를 통해 직접 구현하는 편이 훨씬 빠르고 오류도 적었음
- Accuracy (정확도)
# Tuning Model 불러오기 (Decoding, 복호화)
model_mlp_depr = load_model('../tuning-models/MLP_depr.h5')
# Accuracy score를 담을 리스트를 생성
mlp_val_acc_cv = []
# KFold로 Accuracy Score 산출
for train_idx, val_idx in kf_4.split(X_train_depr, y_train_depr):
X_train_cv, X_val_cv = X_train_depr.iloc[train_idx], X_train_depr.iloc[val_idx]
y_train_cv, y_val_cv = y_train_depr.iloc[train_idx], y_train_depr.iloc[val_idx]
# Prediction 실시
y_val_prob = model_mlp_depr.predict(X_val_cv, verbose=0).flatten()
y_val_pred = np.where(y_val_prob<0.5, 0, 1)
# Accuracy score 연산, 리스트에 append
mlp_val_acc = accuracy_score(y_val_cv, y_val_pred)
mlp_val_acc_cv.append(mlp_val_acc)
# 평균 Accuracy score 연산
CV_acc_mlp_depr = np.array(mlp_val_acc_cv).mean()
print("[Depression]")
print("Baseline Accuracy : {:.4f}".format(baseline_acc_depr))
print("DL_MLP Accuracy : {:.4f}".format(CV_acc_mlp_depr.mean()))
'''
[Depression]
Baseline Accuracy : 0.7956
DL_MLP Accuracy : 0.8324
'''- CV Prediction (교차검증 예측)
# cv마다 true value와 predict value를 append하는 방식으로 cross_val_predict를 구현해본다
# KFold를 통해 shuffle이 이루어지기 때문에 true값에 대한 array도 함께 정의
mlp_val_true_cv = np.array([], dtype=int)
mlp_val_pred_cv = np.array([], dtype=int)
# KFold 수행
for train_idx, val_idx in kf_4.split(X_train_depr, y_train_depr):
X_train_cv, X_val_cv = X_train_depr.iloc[train_idx], X_train_depr.iloc[val_idx]
y_train_cv, y_val_cv = y_train_depr.iloc[train_idx], y_train_depr.iloc[val_idx]
# Prediction 실시
y_val_prob = model_mlp_depr.predict(X_val_cv, verbose=0).flatten()
y_val_pred = np.where(y_val_prob<0.5, 0, 1)
# true값(Series)를 array로 변환
y_val_true = np.array(y_val_cv)
# true값과 pred값을 append
mlp_val_true_cv = np.append(mlp_val_true_cv, y_val_true)
mlp_val_pred_cv = np.append(mlp_val_pred_cv, y_val_pred)
# Table을 통해 확인해보기
df_pred_mlp_depr = pd.DataFrame(data={'true_depr': mlp_val_true_cv,
'pred_depr': mlp_val_pred_cv})
table_pred_mlp_depr = pd.crosstab(df_pred_mlp_depr['true_depr'],
df_pred_mlp_depr['pred_depr'])
display(table_pred_mlp_depr)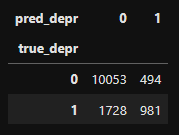
# Confusion matrix (혼동행렬)
cfm_mlp_depr = confusion_matrix(mlp_val_true_cv, mlp_val_pred_cv)
# 시각화에 표시할 값들을 정의하기
group_names_mlp_depr = ['True Negative','False Positive','False Negative','True Positive']
group_counts_mlp_depr = ['{0:0.0f}'.format(value) for value in cfm_mlp_depr.flatten()]
group_percent_mlp_depr = ['{0:.2%}'.format(value) for value in cfm_mlp_depr.flatten()/np.sum(cfm_mlp_depr)]
labels_mlp_depr = [f'{v1}\n\n{v2}\n\n{v3}' for v1,v2,v3 in zip(group_names_mlp_depr,
group_counts_mlp_depr,
group_percent_mlp_depr)]
labels_mlp_depr = np.asarray(labels_mlp_depr).reshape(2,2)
tick_mlp_depr = ['정상(0)', '우울증(1)']
# 시각화(heatmap)
sns.heatmap(cfm_mlp_depr, annot=labels_mlp_depr, fmt='', cmap='Blues',
xticklabels=tick_mlp_depr, yticklabels=tick_mlp_depr)
plt.xlabel("Prediction(예측값)")
plt.ylabel("True(실제값)")
plt.title("Confusion matrix of DL_MLP\n[Depression] (CV=4)")
plt.show()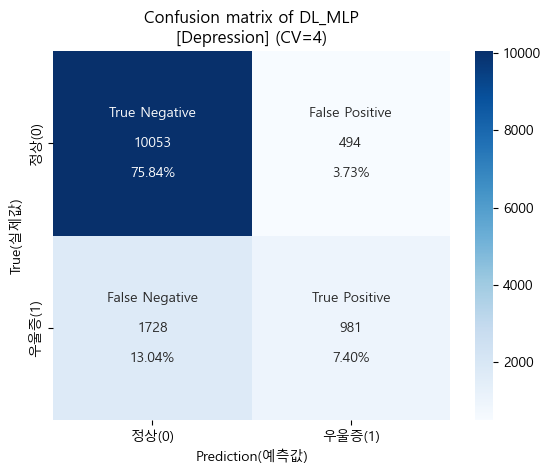
- ROC_AUC score
# TPR(True Positive Rate) 리스트
TPRs_mlp_depr = []
# FPR 축의 정밀도를 계산할 기본 linespace 정의(300개의 값이 들어가도록 설정함)
base_FPR_mlp_depr = np.linspace(0,1,300)
# Cross-validation 및 ROC curve plotting 실시 (KFold)
for train_idx, val_idx in kf_4.split(X_train_depr, y_train_depr):
# Train, Validation Split
X_train_cv, X_val_cv = X_train_depr.iloc[train_idx], X_train_depr.iloc[val_idx]
y_train_cv, y_val_cv = y_train_depr.iloc[train_idx], y_train_depr.iloc[val_idx]
# Prediction 실시
y_val_prob = model_mlp_depr.predict(X_val_cv, verbose=0).flatten()
# get FRP, TPR
FPR, TPR, _ = roc_curve(y_val_cv, y_val_prob)
# plot ROC curve (투명하게 설정)
plt.plot(FPR, TPR, alpha=0.25)
# 기본 linespace에 대응하는 TPR array 생성후 값을 append하기
TPR_depr = np.interp(x=base_FPR_mlp_depr, xp=FPR, fp=TPR)
TPR_depr[0] = 0.0
TPRs_mlp_depr.append(TPR_depr)
# TPR 리스트를 array로 변환 후 평균값의 array 생성
TPRs_mlp_depr = np.array(TPRs_mlp_depr)
mean_TPRs_mlp_depr = TPRs_mlp_depr.mean(axis=0)
# 평균 ROC curve plotting
plt.plot(base_FPR_mlp_depr, mean_TPRs_mlp_depr,
label='DL_MLP(CV=4)', color='Blue')
# Baseline plotting
plt.plot([0,1],[0,1], label='Baseline', color='black', linestyle='--', alpha=0.5)
# plot 설정
plt.xlabel('FPR (False Positive Rate)')
plt.ylabel('TPR (True Positive Rate)')
plt.title("ROC_curve of DL_MLP\n[Depression] (CV=4)")
plt.legend(loc='lower right')
plt.show()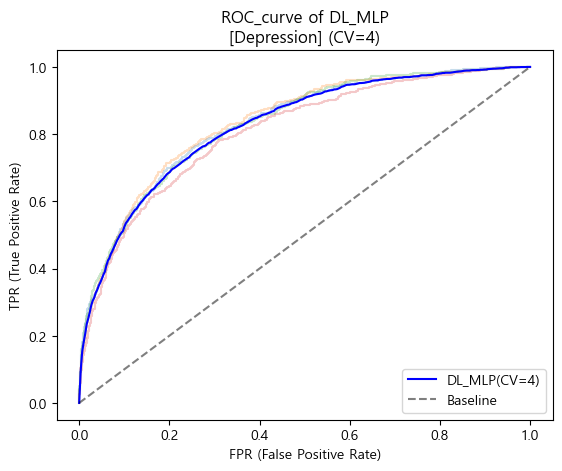
# ROC_AUC score 산출 (cv=4)
# AUC score를 담을 리스트를 생성
mlp_val_AUC_cv = []
# KFold로 AUC score 산출
for train_idx, val_idx in kf_4.split(X_train_depr, y_train_depr):
X_train_cv, X_val_cv = X_train_depr.iloc[train_idx], X_train_depr.iloc[val_idx]
y_train_cv, y_val_cv = y_train_depr.iloc[train_idx], y_train_depr.iloc[val_idx]
# Prediction 실시
y_val_prob = model_mlp_depr.predict(X_val_cv, verbose=0).flatten()
# AUC score 연산, 리스트에 append
mlp_val_AUC = roc_auc_score(y_val_cv, y_val_prob)
mlp_val_AUC_cv.append(mlp_val_AUC)
# 평균 AUC score 연산
CV_AUC_mlp_depr = np.array(mlp_val_AUC_cv).mean()
print("[Depression]")
print("Baseline AUC score : {:.4f}".format(baseline_AUC_depr))
print("DL_MLP AUC score : {:.4f}".format(CV_AUC_mlp_depr.mean()))
'''
[Depression]
Baseline AUC score : 0.5000
DL_MLP AUC score : 0.8249
'''🛠️ Cross-Validation (Depression) - 1D-CNN (Convolutional Neural Networks)
-
진행방식과 코드는 MLP와 동일하기 때문에 여기선 결과만을 다루도록 하겠음
-
Accuracy (정확도)
'''
[Depression]
Baseline Accuracy : 0.7956
DL_1D-CNN Accuracy : 0.8366
'''-
CV Prediction (교차검증 예측)
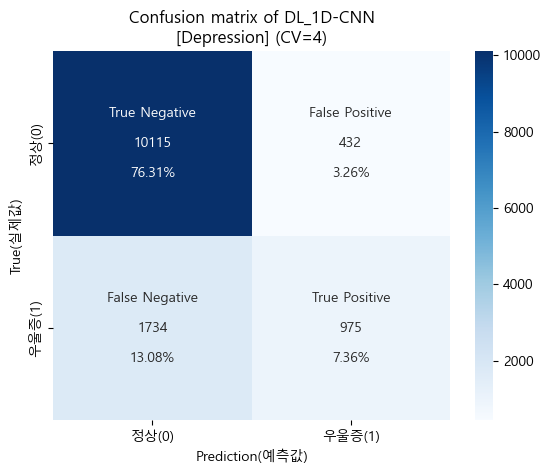
-
ROC_AUC score
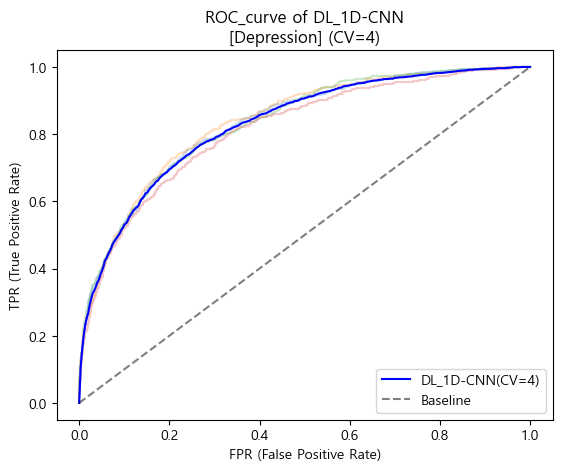
'''
[Depression]
Baseline AUC score : 0.5000
DL_1D-CNN AUC score : 0.8291
'''📊 Compare Models Performance (모델 성능 비교분석)
- Accuracy & AUC score 비교 데이터 생성
# 성능 비교를 위한 DataFrame 정의
df_score_depr = pd.DataFrame({'Accuracy':[baseline_acc_depr,
CV_acc_logistic_depr.mean(),
CV_acc_lgbm_depr.mean(),
CV_acc_mlp_depr,
CV_acc_cnn_depr],
'AUC_score':[baseline_AUC_depr,
CV_AUC_logistic_depr.mean(),
CV_AUC_lgbm_depr.mean(),
CV_AUC_mlp_depr,
CV_AUC_cnn_depr]},
index=['Baseline', 'Logistic', 'LightGBM', 'DL_MLP', 'DL_1D-CNN'])\
.sort_values(by='AUC_score',ascending=True)
display(df_score_depr)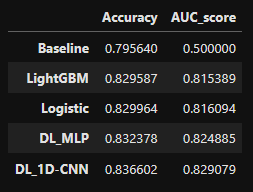
- 평가지표 시각화 (bar-plot)
# 검증 스코어 시각화
x_depr = np.arange(len(df_score_depr))
width_depr = 0.4
# subplot 정의
fig_depr, ax_depr = plt.subplots()
# Accuracy bar
rect1 = ax_depr.bar(x= x_depr - width_depr/2,
height=df_score_depr.Accuracy.round(3),
width=width_depr,
label='Accuracy',
color='Blue', alpha=0.5)
# AUC score bar
rect2 = ax_depr.bar(x= x_depr + width_depr/2,
height=df_score_depr.AUC_score.round(3),
width=width_depr,
label='Accuracy',
color='Blue', alpha=0.75)
# plot 설정
ax_depr.set_title("Comparing Models Evaluation Scores\n[Depression] (CV=4)")
ax_depr.set_xticks(x_depr, df_score_depr.index)
ax_depr.bar_label(rect1, padding=3)
ax_depr.bar_label(rect2, padding=3)
fig_depr.tight_layout()
plt.ylim([0,1])
plt.legend(ncol=2)
plt.show()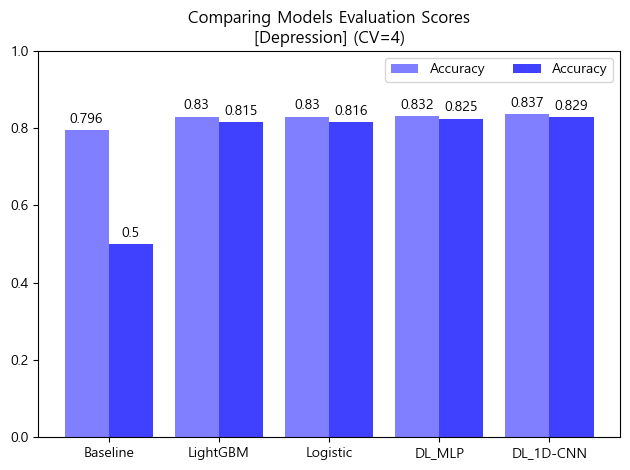
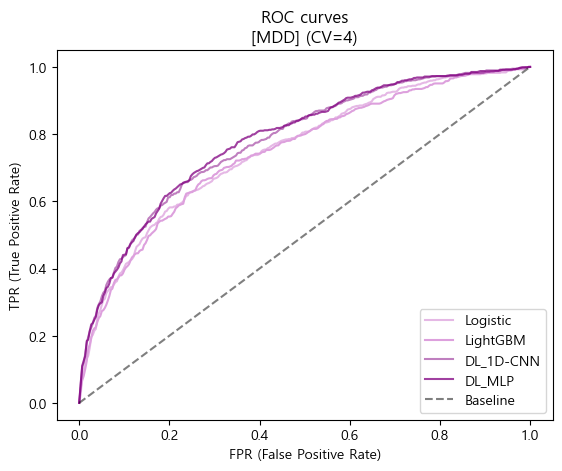
- ROC curves 시각화
# CV 평균 ROC curve를 비교하기 위한 시각화
plt.plot(base_FPR_logistic_depr, mean_TPRs_logistic_depr,
label='Logistic', color='skyblue', alpha=0.75)
plt.plot(base_FPR_lgbm_depr, mean_TPRs_lgbm_depr,
label='LightGBM', color='skyblue', alpha=1)
plt.plot(base_FPR_mlp_depr, mean_TPRs_mlp_depr,
label='DL_MLP', color='blue', alpha=0.5)
plt.plot(base_FPR_cnn_depr, mean_TPRs_cnn_depr,
label='DL_1D-CNN', color='blue', alpha=0.75)
plt.plot([0,1],[0,1], label='Baseline', linestyle='--', color='black', alpha=0.5)
plt.title('ROC curves\n[Depression] (CV=4)')
plt.xlabel('FPR (False Positive Rate)')
plt.ylabel('TPR (True Positive Rate)')
plt.legend(loc='lower right')
plt.show()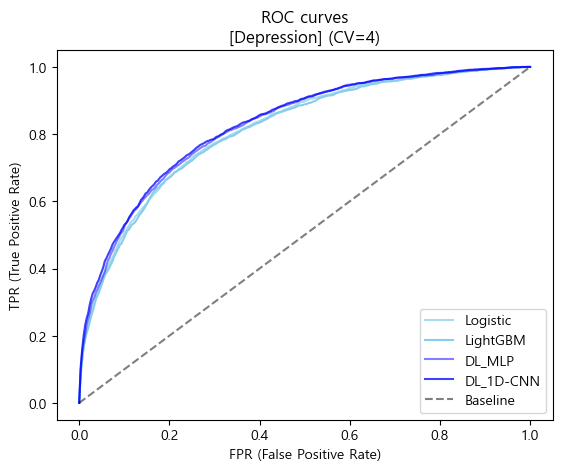
🏆 Final Model Selection (최종 모델 선정)
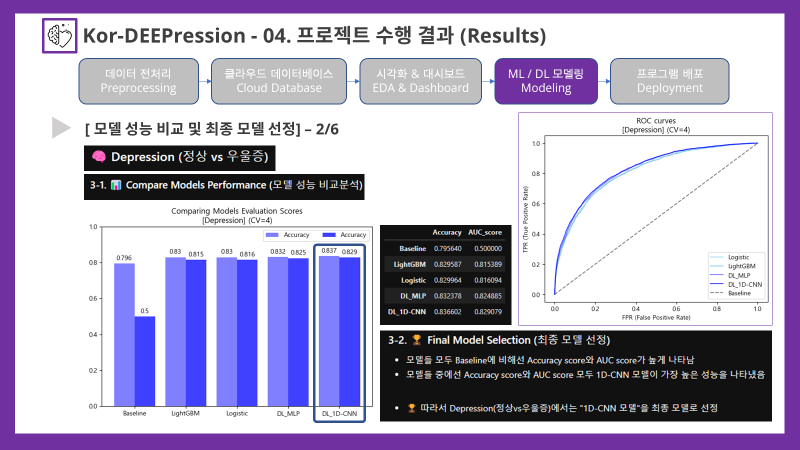
- 모델들 모두 Baseline에 비해선 Accuracy score와 AUC score가 높게 나타남
- 모델들 중에선 Accuracy score와 AUC score 모두 1D-CNN 모델이 가장 높은 성능을 나타냈음
- 🏆 따라서 Depression(정상vs우울증)에서는 "1D-CNN 모델"을 최종 모델로 선정
📝 Final Model Test (최종 모델 테스트)
- 학습에 이용되지 않았던 Test Dataset을 통해 일반화 가능성을 최종적으로 검증함
# Test Data Prediction
y_test_prob = model_cnn_depr.predict(X_test_depr, verbose=0).flatten()
y_test_pred = np.where(y_test_prob<0.5, 0, 1)
# Table을 통해 확인해보기
df_test_depr = pd.DataFrame(data={'true_depr': y_test_depr,
'pred_depr': y_test_pred})
table_test_depr = pd.crosstab(df_test_depr['true_depr'],
df_test_depr['pred_depr'])
display(table_test_depr)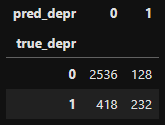
# Confusion matrix (혼동행렬)
cfm_test_depr = confusion_matrix(y_test_depr, y_test_pred)
# 시각화에 표시할 값들을 정의하기
group_names_test_depr = ['True Negative','False Positive','False Negative','True Positive']
group_counts_test_depr = ['{0:0.0f}'.format(value) for value in cfm_test_depr.flatten()]
group_percent_test_depr = ['{0:.2%}'.format(value) for value in cfm_test_depr.flatten()/np.sum(cfm_test_depr)]
labels_test_depr = [f'{v1}\n\n{v2}\n\n{v3}' for v1,v2,v3 in zip(group_names_test_depr,
group_counts_test_depr,
group_percent_test_depr)]
labels_test_depr = np.asarray(labels_test_depr).reshape(2,2)
tick_test_depr = ['정상(0)', '우울증(1)']
# 시각화(heatmap)
sns.heatmap(cfm_test_depr, annot=labels_test_depr, fmt='', cmap='Blues',
xticklabels=tick_test_depr, yticklabels=tick_test_depr)
plt.xlabel("Prediction(예측값)")
plt.ylabel("True(실제값)")
plt.title("Confusion matrix of Test Model (DL_1D-CNN)\n[Depression] (CV=4)")
plt.show()
- Accuracy (정확도)
# Test Model Accuracy Score
score_acc_test_depr = accuracy_score(y_test_depr, y_test_pred)
print("[Depression]")
print("Baseline Accuracy : {:.4f}".format(baseline_acc_depr))
print("Validation Accuracy (cv=4) : {:.4f}".format(CV_acc_cnn_depr))
print("Test Accuracy : {:.4f}".format(score_acc_test_depr))
'''
[Depression]
Baseline Accuracy : 0.7956
Validation Accuracy (cv=4) : 0.8366
Test Accuracy : 0.8352
'''- ROC_AUC score
# ROC curve 시각화
FPR_test_depr, TPR_test_depr, _ = roc_curve(y_test_depr, y_test_prob)
plt.plot(FPR_test_depr, TPR_test_depr,
label='Test Data (Depression)', color='blue', alpha=0.75)
plt.plot(base_FPR_cnn_depr, mean_TPRs_cnn_depr,
label='Validation Data (CV=4)', color='blue', alpha=0.5)
plt.plot([0,1],[0,1], linestyle='--',
label='Baseline', color='black', alpha=0.5)
plt.title("ROC curve of Test (DL_1D-CNN)\n[Depression]")
plt.xlabel('FPR (False Positive Rate)')
plt.ylabel('TPR (True Positive Rate)')
plt.legend(loc='lower right')
plt.show()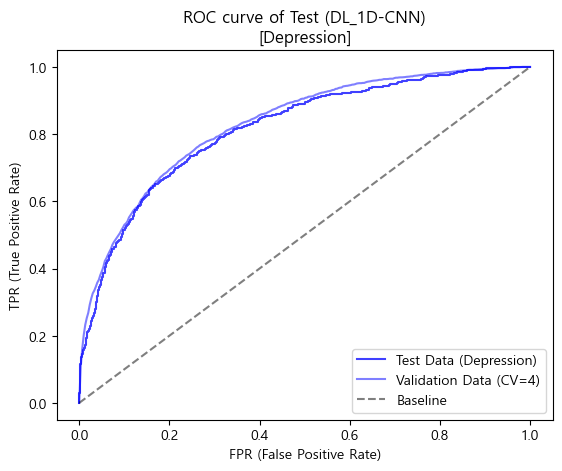
# Test Model AUC Score
score_AUC_test_depr = roc_auc_score(y_test_depr, y_test_prob)
print("[Depression]")
print("Baseline AUC score : {:.4f}".format(baseline_AUC_depr))
print("Validation AUC score (cv=4) : {:.4f}".format(CV_AUC_cnn_depr))
print("Test AUC score : {:.4f}".format(score_AUC_test_depr))
'''
[Depression]
Baseline AUC score : 0.5000
Validation AUC score (cv=4) : 0.8291
Test AUC score : 0.8156
'''- Test Model 평가지표 시각화 비교분석 (bar-plot)
# Test Model 평가지표 시각화 (bar-plot)
df_test_cnn_depr = pd.DataFrame({'Baseline':[baseline_acc_depr,
baseline_AUC_depr],
'Validation':[CV_acc_cnn_depr,
CV_AUC_cnn_depr],
'Test':[score_acc_test_depr,
score_AUC_test_depr]},
index=['Accuracy', 'AUC score'])
x_cnn_depr = np.arange(len(df_test_cnn_depr))
width_cnn_depr = 0.3
# subplot 정의
fig_cnn_depr, ax_cnn_depr = plt.subplots()
# Baseline bar
rect1 = ax_cnn_depr.bar(x= x_cnn_depr - width_cnn_depr,
height=df_test_cnn_depr.Baseline.round(4),
width=width_cnn_depr,
label='Baseline',
color='black', alpha=0.5)
# Validation bar
rect2 = ax_cnn_depr.bar(x= x_cnn_depr,
height=df_test_cnn_depr.Validation.round(4),
width=width_cnn_depr,
label='Validation',
color='blue', alpha=0.5)
# Test bar
rect3 = ax_cnn_depr.bar(x= x_cnn_depr + width_cnn_depr,
height=df_test_cnn_depr.Test.round(4),
width=width_cnn_depr,
label='Test',
color='blue', alpha=0.75)
# plot 설정
ax_cnn_depr.set_title("Comparing Scores of Test (DL_1D-CNN)\n[Depression] (CV=4)")
ax_cnn_depr.set_xticks(x_cnn_depr, df_test_cnn_depr.index)
ax_cnn_depr.bar_label(rect1, padding=3)
ax_cnn_depr.bar_label(rect2, padding=3)
ax_cnn_depr.bar_label(rect3, padding=3)
fig_cnn_depr.tight_layout()
plt.ylabel("Scores")
plt.ylim([0,1])
plt.legend(ncol=3)
plt.show()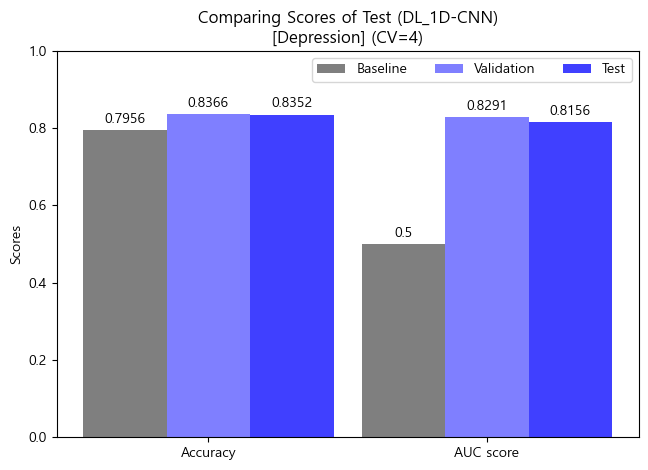
💡 Final Model Test 일반화 가능성
- Depression(정상vs우울증)의 최종 모델인 1D-CNN 모델에 대하여 테스트 데이터셋으로 일반화 가능성을 최종적으로 검증하였음
- 테스트 결과, Validation 및 Test 데이터의 Accuracy와 AUC score 모두 비슷하게 나타났으며, 이에따라 일반화 가능성도 높은 모델이라 판단해 볼 수 있었음.
🧠 Major Depressive Disorder
(경도우울증 vs 주요우울장애)
- 데이터만 차이가 있을 뿐, 진행방식은 동일하게 진행되었기 때문에 Target 분포, Baseline 모델, 최종 비교분석 결과만을 여기서는 다루도록 하겠음
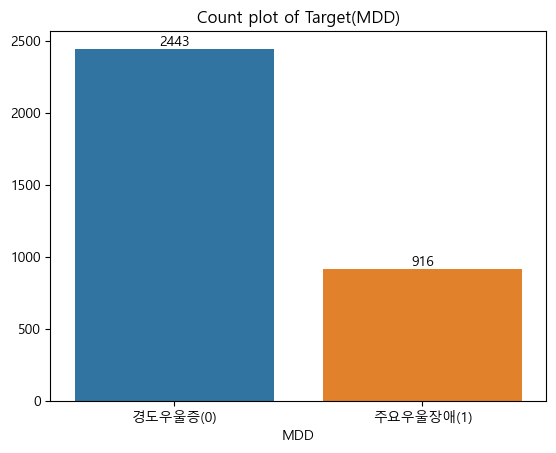
📊 Target 분포 확인
'''
Target(MDD) 수
0 2443
1 916
Name: MDD, dtype: int64
'''
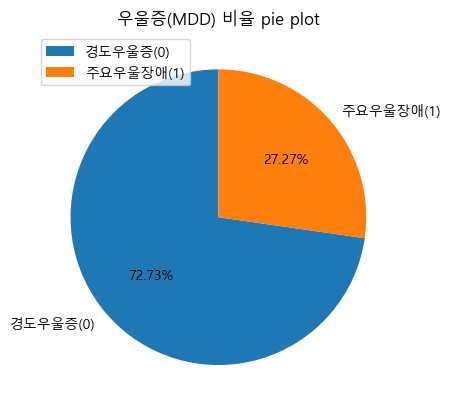
'''
Target(MDD) 비율
0 0.7273
1 0.2727
Name: MDD, dtype: float64
'''
⚙️ Baseline Model 정의 (최빈 Class 비율)
# 최빈값 지정 및 Baseline 모델 정의
mode_mdd = y_train_mdd.mode()[0]
baseline_mdd = [mode_mdd]*len(y_train_mdd)
# Baseline Accuracy & ROC_AUCscore 산출
baseline_acc_mdd = accuracy_score(y_train_mdd, baseline_mdd)
baseline_AUC_mdd = roc_auc_score(y_train_mdd, baseline_mdd)
print("[MDD]")
print("Baseline Accuracy : {:.4f}".format(baseline_acc_mdd))
print("Baseline AUC_score : {}".format(baseline_AUC_mdd))
'''
[MDD]
Baseline Accuracy : 0.7276
Baseline AUC_score : 0.5
'''📊 Compare Models Performance (모델 성능 비교분석)
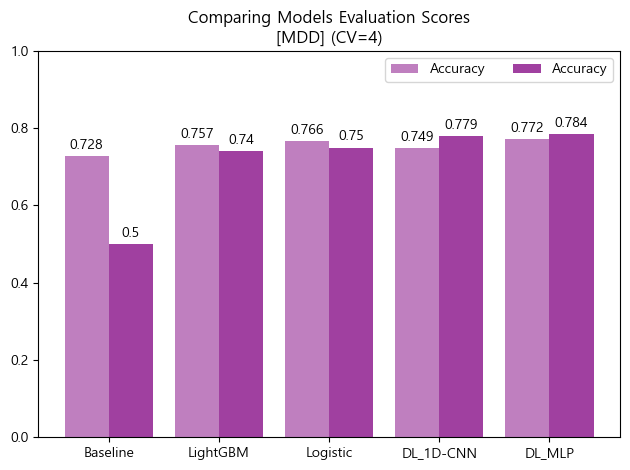
- ROC curves 시각화
🏆 Final Model Selection (최종 모델 선정)
- 모델들 모두 Baseline에 비해선 Accuracy score와 AUC score가 높게 나타남
- 모델들 중에선 Accuracy score와 AUC score 모두 MLP 모델이 가장 높은 성능을 나타냈음
- Depression과 비교했을 때 튜닝과정에서 1D-CNN모델에서 과적합이 발생한 것이 원인이 아닐까 유추해봄 (MDD의 1D-CNN모델 파라미터 수가 36만개나 되었기 때문인 것으로 보임)
📝 Final Model Test (최종 모델 테스트)
- Accuracy (정확도)
'''
[MDD]
Baseline Accuracy : 0.7276
Validation Accuracy (cv=4) : 0.7722
Test Accuracy : 0.7426
'''- ROC_AUC score
'''
[MDD]
Baseline AUC score : 0.5000
Validation AUC score (cv=4) : 0.7838
Test AUC score : 0.7469
'''- Test Model 평가지표 시각화 비교분석 (bar-plot)
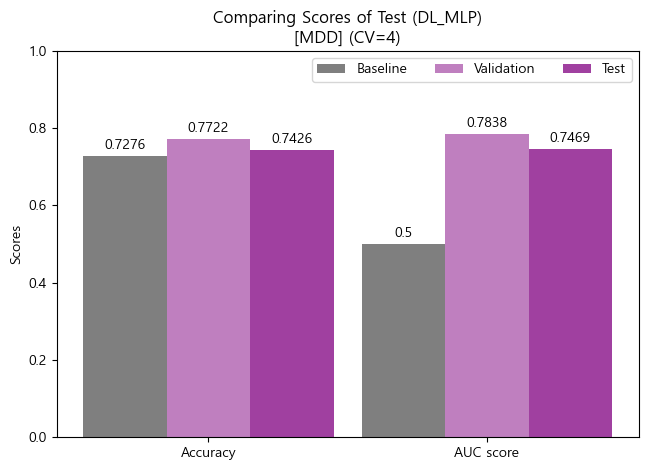
💡 Final Model Test 일반화 가능성
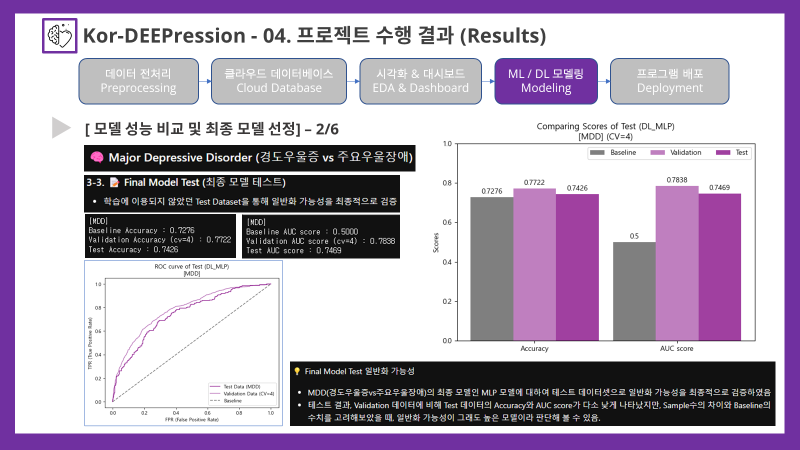
- MDD(경도우울증vs주요우울장애)의 최종 모델인 MLP 모델에 대하여 테스트 데이터셋으로 일반화 가능성을 최종적으로 검증하였음
- 테스트 결과, Validation 데이터에 비해 Test 데이터의 Accuracy와 AUC score가 다소 낮게 나타났지만, Sample수의 차이와 Baseline의 수치를 고려해보았을 때, 일반화 가능성이 그래도 높은 모델이라 판단해 볼 수 있음.
4-7. Model Compression 모델 경량화
- 사실 프로그램 개발 순서상 1차 개발을 완료한 이후에 피드백을 통해 경량화를 실시하였지만, 최종 수정 버전의 웹배포 전단계에서 이루어지는 작업이기 때문에 웹 배포 과정을 다루기 전으로 순서를 배치하여 글을 작성하게 되었음
- 모델 경량화 작업은 웹 배포 서비스의 용량 제한으로 추가적인 라이브러리 설치가 곤란했던 상황이어서 Tensorflow의 경량화 기능이 있는지를 살펴보게 되었음.
- 그러한 과정 속에서 Tensorflow의 lite 패키지를 통해 경량화할 수 있음을 확인하였고, 테스트 결과 모델 예측 속도 향상과 예측 오류 해결도 가능해졌음.
- Tensorflow-lite를 통한 변환 과정 및 예측 테스트의 소스코드는 아래 링크를 통해 확인할 수 있으며, Tensorflow 공식 문서를 참고하여 경량화 작업을 실시하였음.
라이브러리 불러오기
# 라이브러리 import
import os
import numpy as np
import tensorflow as tf
import keras
# tensorflow-cpu 경고문 출력 없애기
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'.h5 모델 불러오기
기존에 .h5 형식으로 저장했던 Keras 모델을 불러오고 예측을 진행해본다.
- Depression(정상vs우울증) : 1D-CNN 모델
# .h5 모델 불러오기 (CNN_depr.h5)
model_depr = keras.models.load_model('./tuning-models/CNN_depr.h5')- MDD(경도우울증vs주요우울장애) : MLP 모델
# .h5 모델 불러오기 (MLP_mdd.h5)
model_mdd = keras.models.load_model('./tuning-models/MLP_mdd.h5')모델 예측 테스트
- Depression(정상vs우울증) : 1D-CNN 모델
# model 예측 테스트 (sample중 가장 높은 확률을 나타낸 case로 테스트함)
print("Prediction Test")
test_input = [0.6557377049180327,0.1793442469983833,1,1,1,0,1,1,1,0,0,0,1,0,1,0,0,0,0,1,0,0,1,0,0,0,0,1,0,0,0,0,0,0,1,0,0,0,0,0,1,0,1,1,0,0,0]
test_array = np.array(test_input).reshape(1,-1)
test_output = model_depr.predict(test_array ,verbose=False)
print("Test output: ", test_output)
'''
Prediction Test
Test output: [[0.99963725]]
'''- MDD(경도우울증vs주요우울장애) : MLP 모델
# model 예측 테스트 (sample중 가장 높은 확률을 나타낸 case로 테스트함)
print("Prediction Test")
test_input = [0.0491803278688524,0.1387595313607444,1,0,0,0,0,1,0,1,0,0,0,1,0,0,1,0,0,0,1,0,1,0,0,0,0,1,0,0,1,0,0,0,0,0,0,0,0,0,1,1,0,1,0,0,0]
test_array = np.array(test_input).reshape(1,-1)
test_output = model_mdd.predict(test_array ,verbose=False)
print("Test output: ", test_output)
'''
Prediction Test
Test output: [[0.85330164]]
'''모델 구조 시각화 (png로 export)
모델을 변환하기에 앞서서 모델 구조를 이미지파일로 출력해본다.
- Depression(정상vs우울증) : 1D-CNN 모델
# 모델 구조 시각화 --> png image로 저장
keras.utils.plot_model(model_depr, to_file='./final-models/final_depr_img.png',
show_shapes=True, show_layer_names=True,
rankdir='TB', expand_nested=False, dpi=96)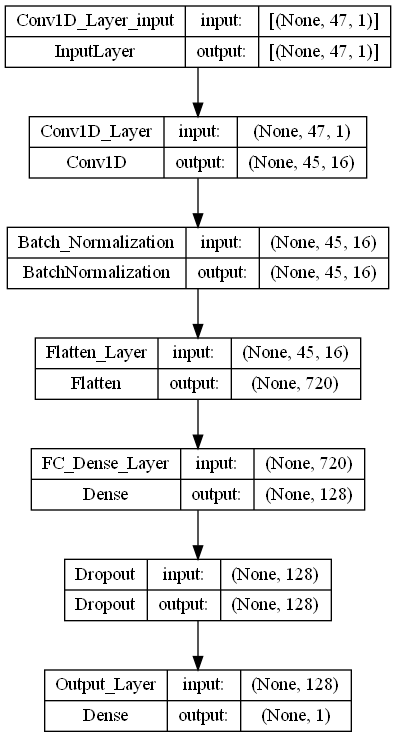
- MDD(경도우울증vs주요우울장애) : MLP 모델
# 모델 구조 시각화 --> png image로 저장
keras.utils.plot_model(model_mdd, to_file='./final-models/final_mdd_img.png',
show_shapes=True, show_layer_names=True,
rankdir='TB', expand_nested=False, dpi=96)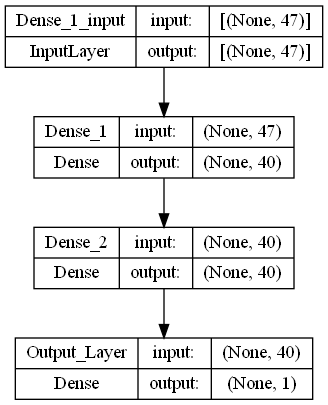
Directory 형식으로 모델 저장하기
공식문서에서는 directory 형식(폴더 형식)으로 저장하여 변환을 진행할 것을 권장하므로 directory로 모델을 저장한다.
- Depression(정상vs우울증) : 1D-CNN 모델
# directory 형식으로 저장하는 것을 권장하므로 directory로 모델 저장
model_depr.save('./final-models/model_depr')- MDD(경도우울증vs주요우울장애) : MLP 모델
# directory 형식으로 저장하는 것을 권장하므로 directory로 모델 저장
model_mdd.save('./final-models/model_mdd')저장 모델 예측 테스트
- Depression(정상vs우울증) : 1D-CNN 모델
# 저장 모델 예측 테스트 (동일한 테스트 데이터로 실시함)
test_load_model_depr = keras.models.load_model('./final-models/model_depr')
test_load_output = test_load_model_depr.predict(test_array ,verbose=False)
print("Test loaded model: ", test_load_output)
'''
Test loaded model: [[0.99963725]]
'''- MDD(경도우울증vs주요우울장애) : MLP 모델
# 저장 모델 예측 테스트 (동일한 테스트 데이터로 실시함)
test_load_model_mdd = keras.models.load_model('./final-models/model_mdd')
test_load_output = test_load_model_mdd.predict(test_array ,verbose=False)
print("Test loaded model: ", test_load_output)
'''
Test loaded model: [[0.85330164]]
'''- 두 모델 모두 동일한 테스틑 데이터에 대한 동일한 예측 결과 값을 나타냈음
.tflite 형식으로 변환
디렉토리(폴더) 형식으로 저장한 모델을 .tflite 형식으로 변환함.
- Depression(정상vs우울증) : 1D-CNN 모델
# Convert to .tflite format (lite모델 변환)
converter_depr = tf.lite.TFLiteConverter.from_saved_model('./final-models/model_depr')
tflite_depr = converter_depr.convert()
open('./final-models/final_model_depr.tflite','wb').write(tflite_depr)- MDD(경도우울증vs주요우울장애) : MLP 모델
# Convert to .tflite format (lite모델 변환)
converter_mdd = tf.lite.TFLiteConverter.from_saved_model('./final-models/model_mdd')
tflite_mdd = converter_mdd.convert()
open('./final-models/final_model_mdd.tflite','wb').write(tflite_mdd).tflite 모델 예측 테스트
- Depression(정상vs우울증) : 1D-CNN 모델
# Interpretation of .tflite model (lite모델 테스트)
# 불러오기
interpreter_depr = tf.lite.Interpreter(model_path='./final-models/final_model_depr.tflite')
# 할당하기
interpreter_depr.allocate_tensors()
# input, output 정보 저장
input_detail_depr = interpreter_depr.get_input_details()
output_detail_depr = interpreter_depr.get_output_details()
# input shape 형태 확인하기
input_shape_depr = input_detail_depr[0]['shape']
print("Input shape of Model_depr: ", input_shape_depr)
'''
Input shape of Model_depr: [ 1 47 1]
'''
# input shape에 맞게 테스트 데이터(list)를 array로 변환 (dtype은 float32로 맞춰줘야 동작함)
input_test_data = np.array(test_input, dtype=np.float32).reshape(input_shape_depr)
print("Shape of test input : ", input_test_data.shape)
'''
Shape of test input : (1, 47, 1)
'''
# input data를 tensor에 맞게 세팅 후 모델을 thread에 의해 손상되지 않도록 invoke함수를 실행함
interpreter_depr.set_tensor(input_detail_depr[0]['index'], input_test_data)
interpreter_depr.invoke()
# 예측을 실행하여 동작 확인
output_test_data = interpreter_depr.get_tensor(output_detail_depr[0]['index'])print("Output of Model_depr: ", output_test_data)
'''
Output of Model_depr: [[0.9996372]]
'''- MDD(경도우울증vs주요우울장애) : MLP 모델
# Interpretation of .tflite model (lite모델 테스트) - depr과 동일한 방식으로 진행
interpreter_mdd = tf.lite.Interpreter(model_path='./final-models/final_model_mdd.tflite')
interpreter_mdd.allocate_tensors()
input_detail_mdd = interpreter_mdd.get_input_details()
output_detail_mdd = interpreter_mdd.get_output_details()
# input shape 형태 확인하기
input_shape_mdd = input_detail_mdd[0]['shape']
print("Input shape of Model_mdd: ", input_shape_mdd)
'''
Input shape of Model_mdd: [ 1 47]
'''
# input shape에 맞게 테스트 데이터(list)를 array로 변환 (dtype은 float32로 맞춰줘야 동작함)
input_test_data = np.array(test_input, dtype=np.float32).reshape(input_shape_mdd)
print("Shape of test input : ", input_test_data.shape)
'''
Shape of test input : (1, 47)
'''
# 예측을 실행하여 동작 확인
interpreter_mdd.set_tensor(input_detail_mdd[0]['index'], input_test_data)
interpreter_mdd.invoke()
output_test_data = interpreter_mdd.get_tensor(output_detail_mdd[0]['index'])print("Output of Model_mdd: ", output_test_data)
'''
Output of Model_mdd: [[0.85330164]]
'''- 두 모델 모두 동일한 테스틑 데이터에 대한 동일한 예측 결과 값을 나타냈음
변환 전후 용량 변화 살펴보기
.h5 모델에서 .tflite로 변환할 때의 파일 용량 변화를 확인함으로써 경량화가 제대로 이루어졌는지 확인해본다.
- Depression(정상vs우울증) : 1D-CNN 모델
- 경량화 이전 (CNN_depr.h5) : 1,130KB = 1.10MB
- 경량화 이후 (final_model_depr.tflite) : 366KB = 0.37MB
- MDD(경도우울증vs주요우울장애) : MLP 모델
- 경량화 이전 (MLP_mdd.h5) : 74KB
- 경량화 이후 (final_model_depr.tflite) : 17KB
- 동일한 예측 결과를 나타내면서 용량 면에서 경량화가 잘 되었음을 알 수 있음!
- 예측 속도면에서는 웹 배포 과정에서 다시 다루겠지만, 두가지 모델의 예측을 동시에 동작시켜도 Worker Timeout이 되어버리는 문제가 해결 될 정도로 예측 속도 또한 상당한 개선이 이루어졌음
- 따라서 최종 버전의 웹배포 과정에서는 .tflite로 경량화 시킨 모델을 최종 모델로써 배포를 진행하였고, 이후 배포 과정은 다음 글에서 자세히 다루도록 하겠음.
5~. 이후 과정
다음 과정에서는 웹페이지 배포 과정을 다루고, 결론 및 회고를 통해 마무리해보도록 하겠음

일 때문에 포스팅은 잠시 쉬어요 ㅠ // Now. 수학 강사 (광교) // Prev. Machine Learning (AI) Engineer & BackEnd Engineer