
한국형 우울증 딥러닝 예측 모델 및 진단 프로그램 "Kor-DEEPression" 개발 과정 정리 및 회고.
(4-1) ML / DL Modeling (모델링)
- (1) Outline & Introduction (개요 & 서론)
- (2) Preprocess & Database (전처리 & 데이터베이스 구축)
- (3) EDA & Dashboard (시각화 분석 & 대시보드)
- (4-1) ML / DL Modeling (모델링)
- (4-2) Final Model & Compression (최종모델 및 모델경량화)
- (5) Deployment & Conclusion (프로그램 배포 & 결론)
Kor-DEEPression
- 한국형 우울증 딥러닝 예측 모델 및 진단 프로그램
- Korean Depression Deep-Learning Model and Diagnosis Program

Project Information
- 프로젝트명 : Kor-DEEPression
- 한국형 우울증 딥러닝 예측 모델 및 진단 프로그램 개발
- Development of Korean Depression Deep-Learning Model and Diagnosis Program
- Codestates AI Bootcamp CP2 project
- 자유주제 개인 프로젝트
- Full-Stack Deep-Learning Project
- DS (Data Science)
- Machine Learning & Deep Learning 모델링
- 모델 성능 평가 및 모델 개선
- 모델 경량화 (tensorflow-lite)
- DA (Data Analysis)
- EDA 및 시각화 분석
- Trend Dashboard 구현 (Looker-Studio)
- DE (Data Engineering)
- Back-end : Cloud DB 구축, 프로그램 Flask 배포
- Front-end : Web page 제작 (HTML5, CSS3)
- DS (Data Science)
Process Pipeline 파이프라인

Outline & Intro. 개요 및 서론
4. Modeling 모델링
(Part 4-1 ~ 4-5) Modeling 모델링
- Preprocessing for Modeling
모델링용 전처리 - Logistic Regression
로지스틱 회귀 - LightGBM
LGBM 모델 - MLP
다층 퍼셉트론 신경망 - 1D-CNN
합성곱층 신경망
(Part 4-6, 4-7) Final Model최종모델 - Final Model
최종 모델 선정 - Model Compression
모델 경량화
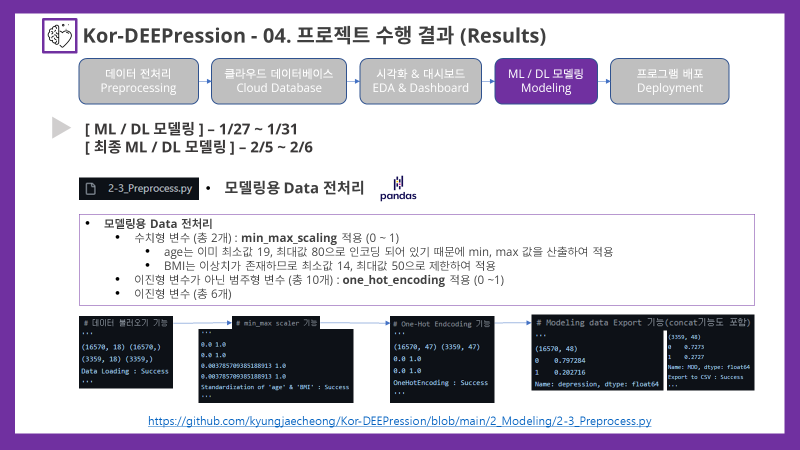
4-1. Preprocessing for Modeling 모델링용 전처리
라이브러리 불러오기
- custom_modules/data_preprocess.py
# 라이브러리 import
import pandas as pd- 2-3_Preprocess.py
# 라이브러리 및 함수 Import
from custom_modules.data_preprocess import *데이터 불러오기 (특성, 타겟 분리 포함)
- custom_modules/data_preprocess.py
# 데이터 불러오기 기능
def data_load(filedir, target_name):
'''
data_load
데이터 불러오기 기능 (X, y 분리 기능도 추가)
---
입력 변수 정보
filedir : (str)불러올 파일의 디렉토리
target_name : (str) target 변수명
---
출력 : DataFrame, DataFrame
'''
# csv데이터를 DataFrame으로 불러옴
df0 = pd.read_csv(filedir)
# Feature column 정의
features = df0.drop(columns=[target_name]).columns
# 독립변수 및 종속변수 분리
df_X = df0[features]
df_y = df0[target_name]
# DataFrame들을 반환
return df_X, df_y- 2-3_Preprocess.py
# 데이터 불러오기 기능
df_X_depr, df_y_depr = data_load(target_name='depression', filedir='./2_Modeling/downloads/Model_depr.csv')
df_X_mdd, df_y_mdd = data_load(target_name='MDD', filedir='./2_Modeling/downloads/Model_mdd.csv')
print(df_X_depr.shape, df_y_depr.shape)
print(df_X_mdd.shape, df_y_mdd.shape)
print("Data Loading : Success\n")
'''
(16570, 18) (16570,)
(3359, 18) (3359,)
Data Loading : Success
'''이상치 제한
-
EDA를 통해 BMI의 경우 최대값을 50, 최소값을 14로 정하기로 하였기 때문에 그 이상의 값은 최대값 혹은 최소값으로 변환시키는 과정을 실시하였음. 제거하는 방법도 있지만, 예측시 이상치에 대해서도 동일하게 적용되도록 하기위해서 변환하는 방법을 택하였음.
-
custom_modules/data_preprocess.py
# EDA를 통해 설정한 이상치를 제한하기 위한 기능
def limitation(data, column, min_value, max_value):
'''
limitation
데이터값 제한 함수
---
입력 변수 정보
data : (DataFrame) 변경 대상 데이터프레임
column : (str) 변경 대상 column
min_value : (int, float) 제한하고자하는 최소값
max_value : (int, float) 제한하고자하는 최대값
---
출력 : DataFrame
'''
# 빈 리스트 생성
new_data = []
# 이상치를 설정한 최소값 및 최대값으로 append
for index, value in enumerate(data[column]):
if value < min_value:
new_data.append(min_value)
elif value > max_value:
new_data.append(max_value)
else: new_data.append(value)
# 기존 column에 덮어쓰기
df_fix = data.copy()
df_fix[column] = new_data
# 덮어쓴 DataFrame을 반환
return df_fix- 2-3_Preprocess.py
# EDA를 통해 설정한 이상치를 제한하기 위한 기능
# BMI 최소값 : 14미만, 최대값 : 50초과
limit_bmi_depr = limitation(df_X_depr, 'BMI', min_value=14, max_value=50)
limit_bmi_mdd = limitation(df_X_mdd, 'BMI', min_value=14, max_value=50)Min Max Scaling (표준화)
- 수치형 변수인 'age'와 'BMI'에 대해서 0~1사이의 값을 가질 수 있도록 표준화하는 작업을 실시함
- 옵션을 통해서 min값과 max값을 지정할 수 있도록 프로그래밍 하였음
- custom_modules/data_preprocess.py
# min_max scaler 기능
def min_max_scaler(data, column, min_value=None, max_value=None):
'''
min_max_scaler
연속형 데이터를 0~1사이의 값으로 변환시키는 기능
---
입력 변수 정보
data : (DataFrame) 변경 대상 데이터프레임
column : (str) 변경 대상 column
min_value : 최소값 (기본값 : None)
max_value : 최대값 (기본값 : None)
---
출력 : DataFrame
'''
# 원본 수정 방지를 위한 copy실시
df_fix = data.copy()
# (optional)min_value 혹은 max_value를 설정하지 않은 경우 최소값 및 최대값을 산출
if min_value is None:
min_value = df_fix[column].min()
if max_value is None:
max_value = df_fix[column].max()
# min_max_scaling을 통해 기존 column에 덮어쓰기
df_fix[column] = (df_fix[column] - min_value) / (max_value - min_value)
# 덮어쓴 DataFrame을 반환
return df_fix- 2-3_Preprocess.py
# min_max scaler 기능 (옵션으로 min값과 max값을 추가적으로 설정 가능)
mms_age_depr = min_max_scaler(limit_bmi_depr, 'age')
mms_age_mdd = min_max_scaler(limit_bmi_mdd, 'age')
df_mms_depr = min_max_scaler(mms_age_depr, 'BMI', min_value=14, max_value=50)
df_mms_mdd = min_max_scaler(mms_age_mdd, 'BMI', min_value=14, max_value=50)
print(df_mms_depr.age.min(), df_mms_depr.age.max())
print(df_mms_mdd.age.min(), df_mms_mdd.age.max())
print(df_mms_depr.BMI.min(), df_mms_depr.BMI.max())
print(df_mms_mdd.BMI.min(), df_mms_mdd.BMI.max())
print("Standardization of 'age' & 'BMI' : Success\n")
'''
0.0 1.0
0.0 1.0
0.003785709385188913 1.0
0.003785709385188913 1.0
Standardization of 'age' & 'BMI' : Success
'''One-Hot Endcoding
-
이진형 변수가 아닌 범주형 변수들을 0 또는 1의 값을 갖는 이진형 변수로 변환하는 One-Hot Encoding을 실시
-
custom_modules/data_preprocess.py
# One-Hot Endcoding 기능
def one_hot_endcoding(data, cat_columns):
'''
one_hot_endcoding
이진형 변수가 아닌 범주형 변수들을 이진형 변수로 변환하는 기능
---
입력 변수 정보
data : (DataFrame) 인코딩 대상 데이터프레임
cat_columns : (list) 인코딩 대상 column 리스트
---
출력 : DataFrame
'''
# Pandas의 get_dummies함수를 이용하여 One_hot_Encoding 실시
df_ohe = pd.get_dummies(data, columns=cat_columns)
# One_hot_Encoding을 적용한 DataFrame을 반환
return df_ohe- 2-3_Preprocess.py
# One-Hot Endcoding 기능 (이진형 변수가 아닌 범주형 변수들을 이진형 변수로 변환)
# 변환 대상 column 지정
cat_cols = ['sex', 'education', 'household', 'marital', 'economy',
'subj_health', 'drk_freq', 'drk_amount', 'smoke', 'stress']
# One-Hot Endcoding
df_ohe_depr = one_hot_endcoding(df_mms_depr, cat_columns=cat_cols)
df_ohe_mdd = one_hot_endcoding(df_mms_mdd, cat_columns=cat_cols)
print(df_ohe_depr.shape, df_ohe_mdd.shape)
print(df_ohe_depr.min().min(), df_ohe_depr.max().max())
print(df_ohe_mdd.min().min(), df_ohe_mdd.max().max())
print("OneHotEncoding : Success\n")
'''
(16570, 47) (3359, 47)
0.0 1.0
0.0 1.0
OneHotEncoding : Success
'''모델링용 데이터 Export
- custom_modules/data_preprocess.py
# Modeling data Export 기능
def export_to_csv(X_data, y_data, savepath):
'''
export_to_csv
독립변수(X)와 종속변수(y)를 병합하고 csv로 export하는 기능
---
입력 변수 정보
X_data : (DataFrame) 독립변수(X)
y_data : (DataFrame, Series) 종속변수(y)
savepath : (str) csv file 저장 경로
---
출력 : None
'''
# Concat (데이터 병합, 열방향(axis=1))
df = pd.concat([X_data, y_data], axis=1)
# csv로 지정한 경로(savepath)에 파일을 생성 혹은 덮어쓰기
df.to_csv(savepath, index=False)
# 테스트용 코드
print(df.shape)
print(df.iloc[:,-1].value_counts(normalize=True))- 2-3_Preprocess.py
# Modeling data Export 기능(concat기능도 포함)
export_to_csv(df_ohe_depr, df_y_depr, savepath='./2_Modeling/downloads/Encoded_depr.csv')
export_to_csv(df_ohe_mdd, df_y_mdd, savepath='./2_Modeling/downloads/Encoded_mdd.csv')
print("Export to CSV : Success\n")
'''
(16570, 48)
0 0.797284
1 0.202716
Name: depression, dtype: float64
(3359, 48)
0 0.7273
1 0.2727
Name: MDD, dtype: float64
Export to CSV : Success
'''4-2~5. Modeling 개요
- 전반적으로 모델링 과정은 함수들을 module로 묶고, 이를 package로 만들어 함수를 불러오는 방식으로 진행되었으며, 소스코드는 다음 링크에서 확인 가능함

- 4가지 모델에 대한 튜닝을 실시한 후 성능을 비교하여 최종 모델을 선정함
- 선형 모델 : Logistic Regression
- 트리형 앙상블 모델 : LightGBM
- 다층 퍼셉트론 모델 : MLP, Multi Layer Perceptron
- 합성곱층 신경망 모델 : CNN, Convolutional Neural Network
- 모델들에 공통적으로 적용되는 사항은 다음과 같음
- Feature 47개, Target 1개
- 학습데이터, 테스트데이터 분리 = 0.8:0.2
- 딥러닝 모델은 검증데이터도 분리 = 0.6:0.2:0.2
- Baseline 모델 : Target별 최빈 Class
- 평가지표 : Accuracy, ROC_AUC score
- 타겟 불균형이 심하지 않아 정확도를 평가지표로 선정, 불균형문제를 조금이나마 해소하고자 모델링은 AUC를 중심으로 튜닝되었고 비교분석에도 이용함
모델링용 라이브러리 import
- custom_modules/modeling.py
# 라이브러리 import
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import accuracy_score, roc_auc_score
from sklearn.linear_model import LogisticRegression
import lightgbm as lgbm
import tensorflow as tf
import keras
from keras.models import Sequential
from keras.layers import *
from keras.callbacks import EarlyStopping, ModelCheckpoint4-2. Logistic Regression 로지스틱 회귀

라이브러리 불러오기
- 2-4-1_Logistic.py
# 라이브러리 및 함수 Import
from custom_modules.modeling import *
import pickle데이터 불러오기 (특성, 타겟 분리 포함)
- custom_modules/modeling.py
# Data Import 기능 (Feature, Target 분리기능 포함)
def data_load(filepath, target_name):
'''
data_load
데이터 불러오기 기능 (X, y 분리 기능도 추가)
---
입력 변수 정보
filepath : (str)불러올 파일의 디렉토리
target_name : (str) target 변수명
---
출력 : DataFrame, DataFrame
'''
# csv데이터를 DataFrame으로 불러옴
df0 = pd.read_csv(filepath)
print(f"\tDataFrame Shape : {df0.shape}")
# 독립변수 및 종속변수 분리
df_X = df0.drop(columns=[target_name])
df_y = df0[target_name]
print(f"\tFeatures(X) Shape : {df_X.shape}")
print(f"\tTarget(y) Shape : {df_y.shape}")
# DataFrame들을 Tuple형태로 반환
return df_X, df_y- 2-4-1_Logistic.py
# 데이터 불러오기 기능
print("\n(Data Loading)")
print("\t(Depression)")
df_X_depr, df_y_depr = data_load(target_name='depression', filepath='./2_Modeling/downloads/Encoded_depr.csv')
print("\n\t(MDD)")
df_X_mdd, df_y_mdd = data_load(target_name='MDD', filepath='./2_Modeling/downloads/Encoded_mdd.csv')
'''
(Data Loading)
(Depression)
DataFrame Shape : (16570, 48)
Features(X) Shape : (16570, 47)
Target(y) Shape : (16570,)
(MDD)
DataFrame Shape : (3359, 48)
Features(X) Shape : (3359, 47)
Target(y) Shape : (3359,)
'''학습 및 테스트 데이터 분리
- custom_modules/modeling.py
# Train Test Split 기능
# 옵션으로 Validation 데이터 생성가능, DL 모델 학습과정에서 이용할 예정
def data_split(X_data, y_data, seed=2023, val_set=False):
'''
data_split
데이터 분리 기능
---
입력 변수 정보
X_data : (DataFrame) 독립변수(X, features)
y_data : (DataFrame, Series) 종속변수(y, target)
seed : (int) Random Seed 값 (기본값 2023)
val_set : (Boolean) 기본값 False, 검증용 데이터셋도 생성할지 결정
---
출력 : DataFrame, DataFrame
'''
# Train & Test 분리 (비율은 8:2)
X_tr, X_test, y_tr, y_test = train_test_split(X_data, y_data, test_size=0.2, random_state=seed)
# val_set=False(기본값)
if val_set is False:
print(f"\tX_train, y_train : {X_tr.shape}, {y_tr.shape}")
print(f"\tX_test, y_test : {X_test.shape}, {y_test.shape}")
return X_tr, X_test, y_tr, y_test
# val_set=True (0.75 : 0.25 비율로 split) : 최종 비율 (6:2:2)
elif val_set is True:
X_train, X_val, y_train, y_val = train_test_split(X_tr, y_tr, test_size=0.25, random_state=seed)
print(f"\tX_train, y_train : {X_train.shape}, {y_train.shape}")
print(f"\tX_val, y_val : {X_val.shape}, {y_val.shape}")
print(f"\tX_test, y_test : {X_test.shape}, {y_test.shape}")
return X_train, X_val, X_test, y_train, y_val, - 2-4-1_Logistic.py
# 데이터 분리 기능
print("\n(Data Splitting)")
print("\t(Depression)")
X_train_depr, X_test_depr, y_train_depr, y_test_depr = data_split(df_X_depr, df_y_depr)
print("\n\t(MDD)")
X_train_mdd, X_test_mdd, y_train_mdd, y_test_mdd = data_split(df_X_mdd, df_y_mdd)
'''
(Data Splitting)
(Depression)
X_train, y_train : (13256, 47), (13256,)
X_test, y_test : (3314, 47), (3314,)
(MDD)
X_train, y_train : (2687, 47), (2687,)
X_test, y_test : (672, 47), (672,)
'''Baseline (최빈 Class) 모델 생성
- custom_modules/modeling.py
# Baseline (최빈class) 생성 기능
def make_baseline(y_data):
'''
make_baseline
Baseline (최빈class) 생성 기능
---
입력 변수 정보
y_data : (DataFrame, Series) 종속변수(y, target)
---
출력 : List
'''
# 최빈 Class 산출
base_mode = y_data.mode()[0]
# Baseline 리스트 생성
baseline = [base_mode]*len(y_data)
# 평가지표(정확도, AUCscore) 출력
print("\tBaseline Accuracy : {:.4f}".format(accuracy_score(y_data, baseline)))
print("\tBaseline AUC_score : {:.1f}".format(roc_auc_score(y_data, baseline)))
# Baseline data 반환
return baseline- 2-4-1_Logistic.py
# Baseline (최빈 Class) 생성 기능
print("\n(Baseline)")
print("\t(Depression)")
baseline_depr = make_baseline(y_train_depr)
print("\n\t(MDD)")
baseline_mdd = make_baseline(y_train_mdd)
'''
(Baseline)
(Depression)
Baseline Accuracy : 0.7956
Baseline AUC_score : 0.5
(MDD)
Baseline Accuracy : 0.7276
Baseline AUC_score : 0.5
'''Logistic Regression Tuning (GridSearchCV)
- 연산속도가 빠르기 때문에 GridSearchCV를 통해서 최적의 하이퍼파라미터를 탐색함
- 하이퍼파라미터는 C값과 max_iter 두개 정도 말고는 건드릴 만할게 없어서 두가지 파라미터에 대한 튜닝을 진행
- custom_modules/modeling.py
# Logistic Regression Tuning (GridSearchCV)
# 튜닝을 거친 후의 모델을 반환하도록 프로그래밍
def Tuning_Logistic(train_X, train_y, cv=4):
'''
Tuning_Logistic
Logistic Regression Tuning(GridSearchCV) & Make Tuning model
---
입력 변수 정보
train_X : (DataFrame, ndarray) 독립변수(X, features)
train_y : (Series, ndarray) 종속변수(y, target)
---
출력 : Model
'''
# LogisticRegression 모델 생성
model = LogisticRegression(max_iter=100)
# 탐색 파라미터 범위 지정
params = {'C':np.logspace(-4,4,50),
'max_iter':[100,200,400,800]}
# GridSearchCV 모델 정의 (평가지표 기준은 AUC score)
grid_model = GridSearchCV(estimator=model,
param_grid=params,
n_jobs=-1,
cv=cv,
scoring='roc_auc',
verbose=1)
# Fit (GridSearchCV 실시)
grid_model.fit(train_X, train_y)
# 최적 하이퍼파라미터 및 최적 AUC score 출력
print("Best Parameters: ", grid_model.best_params_)
print("Best AUC Score: ", grid_model.best_score_)
# 최적 하이퍼파라미터로 모델을 재정의
tuned_model = LogisticRegression(C=grid_model.best_params_['C'],
max_iter=grid_model.best_params_['max_iter'])
# 튜닝을 거친 모델을 반환함
return tuned_model- 2-4-1_Logistic.py
# Logistic Regression Tuning (GridSearchCV)
print("\n(GridSearchCV) - Depression")
tuned_model_depr = Tuning_Logistic(X_train_depr, y_train_depr, cv=4)
print("\n(GridSearchCV) - MDD")
tuned_model_mdd = Tuning_Logistic(X_train_mdd, y_train_mdd, cv=4)
'''
(GridSearchCV) - Depression
Fitting 4 folds for each of 200 candidates, totalling 800 fits
Best Parameters: {'C': 0.12648552168552957, 'max_iter': 100}
Best AUC Score: 0.8160942375138954
(GridSearchCV) - MDD
Fitting 4 folds for each of 200 candidates, totalling 800 fits
Best Parameters: {'C': 0.040949150623804234, 'max_iter': 100}
Best AUC Score: 0.7500140314821807
'''튜닝 모델 Encoding
-
튜닝을 거친 모델을 pickle 라이브러리를 통해 .pkl 파일로 변환하여 비교분석에 이용할 것임
-
2-4-1_Logistic.py
# Encoding Tuning Models to .pkl file (Pickle)
# 튜닝을 거친 모델을 pkl file로 부호화하여 저장함 (모델 비교 시 다시 사용될 예정)
with open('./tuning-models/Logistic_depr.pkl', 'wb') as pf:
pickle.dump(tuned_model_depr, pf)
with open('./tuning-models/Logistic_mdd.pkl', 'wb') as pf:
pickle.dump(tuned_model_mdd, pf)
print("\nModel Export to pkl file : Success\n")
'''
Model Export to pkl file : Success
'''4-3. LightGBM LGBM 모델

- 데이터를 불러오고, 분리하고, Baseline모델을 만드는 과정이 Logistic Regression과정과 동일하기 때문에 튜닝으로 바로 넘어가도록 하겠음.
LightGBM Classifier Tuning (GridSearchCV)
- 연산속도가 빠르기 때문에 GridSearchCV를 통해서 최적의 하이퍼파라미터를 탐색함
- 하이퍼파라미터는 참고논문을 바탕으로 선정한 4가지의 파라미터로 튜닝을 실시하였음
- learning_rate
- n_estimators
- max_depth
- subsample
- 참고논문 : 남원우, & 김병욱. (2020). 환경적 요소 선별을 통한 딥러닝 기반 우울증 분류 예측. 전기학회논문지, 69(7), 1102-1110.
- custom_modules/modeling.py
# LightGBM Classifier Tuning (GridSearchCV)
# 튜닝을 거친 후의 모델을 반환하도록 프로그래밍
def Tuning_LGBM(train_X, train_y, cv=4):
'''
Tuning_LGBM
LightGBM Classifier Tuning(GridSearchCV) & Make Tuning model
---
입력 변수 정보
train_X : (DataFrame, ndarray) 독립변수(X, features)
train_y : (Series, ndarray) 종속변수(y, target)
---
출력 : Model
'''
# LightGBM Classifier 모델 생성
model = lgbm.LGBMClassifier(objective='binary', boosting_type='gbdt')
# 탐색 파라미터 범위 지정
params = {'learning_rate' : [0.01, 0.05, 0.1],
'n_estimators' : [100, 200, 300],
'max_depth' : [3, 5, 7, 9],
'subsample' : [0.7, 0.8]}
# GridSearchCV 모델 정의 (평가지표 기준은 AUC score)
grid_model = GridSearchCV(estimator=model,
param_grid=params,
n_jobs=-1,
cv=cv,
scoring='roc_auc',
verbose=1)
# Fit (GridSearchCV 실시)
grid_model.fit(train_X, train_y)
# 최적 하이퍼파라미터 및 최적 AUC score 출력
print("Best Parameters: ", grid_model.best_params_)
print("Best AUC Score: ", grid_model.best_score_)
# 최적 하이퍼파라미터로 모델을 재정의
tuned_model = lgbm.LGBMClassifier(objective='binary',
boosting_type='gbdt',
learning_rate=grid_model.best_params_['learning_rate'],
n_estimators=grid_model.best_params_['n_estimators'],
max_depth=grid_model.best_params_['max_depth'],
subsample=grid_model.best_params_['subsample'])
# 튜닝을 거친 모델을 반환함
return tuned_model- 2-4-2_LightGBM.py
# LightGBM Classifier Tuning (GridSearchCV)
print("\n(GridSearchCV) - Depression")
tuned_model_depr = Tuning_LGBM(X_train_depr, y_train_depr, cv=4)
print("\n(GridSearchCV) - MDD")
tuned_model_mdd = Tuning_LGBM(X_train_mdd, y_train_mdd, cv=4)
'''
(GridSearchCV) - Depression
Fitting 4 folds for each of 72 candidates, totalling 288 fits
Best Parameters: {'learning_rate': 0.1, 'max_depth': 3, 'n_estimators': 100, 'subsample': 0.7}
Best AUC Score: 0.815388799827848
(GridSearchCV) - MDD
Fitting 4 folds for each of 72 candidates, totalling 288 fits
Best Parameters: {'learning_rate': 0.01, 'max_depth': 3, 'n_estimators': 300, 'subsample': 0.7}
Best AUC Score: 0.740004286385952
'''튜닝 모델 Encoding
-
튜닝을 거친 모델을 pickle 라이브러리를 통해 .pkl 파일로 변환하여 비교분석에 이용할 것임
-
2-4-2_LightGBM.py
# Encoding Tuning Models to .pkl file (Pickle)
# 튜닝을 거친 모델을 pkl file로 부호화하여 저장함 (모델 비교 시 다시 사용될 예정)
with open('./tuning-models/LightGBM_depr.pkl', 'wb') as pf:
pickle.dump(tuned_model_depr, pf)
with open('./tuning-models/LightGBM_mdd.pkl', 'wb') as pf:
pickle.dump(tuned_model_mdd, pf)
print("\nModel Export to pkl file : Success\n")
'''
Model Export to pkl file : Success
'''4-4. MLP 다층 퍼셉트론 신경망
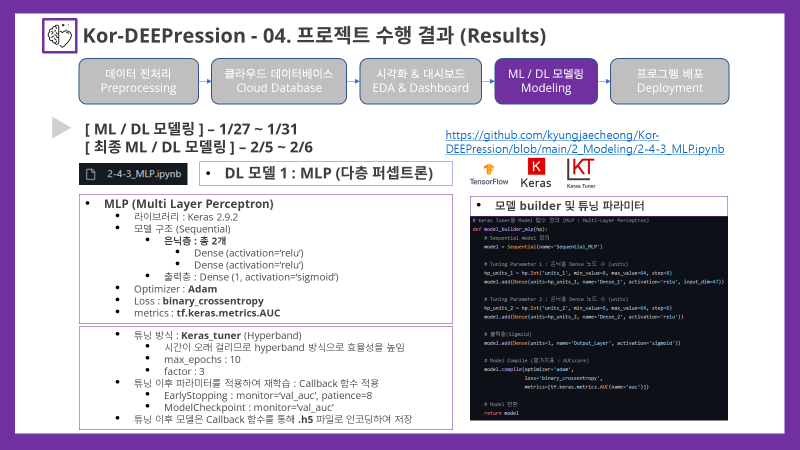
- 딥러닝 모델들은 Jupyter Notebook을 통해 튜닝 및 모델링이 진행되었으며, 우선 가장 간단한 모델인 MLP(다층퍼셉트론)모델로 튜닝 및 모델링을 실시하였음
데이터 불러오기 (특성, 타겟 분리 포함)
from custom_modules.modeling import data_load
# 데이터 불러오기 기능
print("\n(Data Loading)")
print("\t(Depression)")
df_X_depr, df_y_depr = data_load(target_name='depression', filepath='downloads/Encoded_depr.csv')
print("\n\t(MDD)")
df_X_mdd, df_y_mdd = data_load(target_name='MDD', filepath='downloads/Encoded_mdd.csv')
'''
(Data Loading)
(Depression)
DataFrame Shape : (16570, 48)
Features(X) Shape : (16570, 47)
Target(y) Shape : (16570,)
(MDD)
DataFrame Shape : (3359, 48)
Features(X) Shape : (3359, 47)
Target(y) Shape : (3359,)
'''학습, 검증, 테스트 데이터 분리
from custom_modules.modeling import data_split
# 데이터 분리 기능 (val_set=True)
print("\n(Data Splitting)")
print("\t(Depression)")
X_train_depr, X_val_depr, X_test_depr, y_train_depr, y_val_depr, y_test_depr = data_split(df_X_depr, df_y_depr, val_set=True)
print("\n\t(MDD)")
X_train_mdd, X_val_mdd, X_test_mdd, y_train_mdd, y_val_mdd, y_test_mdd = data_split(df_X_mdd, df_y_mdd, val_set=True)
'''
(Data Splitting)
(Depression)
X_train, y_train : (9942, 47), (9942,)
X_val, y_val : (3314, 47), (3314,)
X_test, y_test : (3314, 47), (3314,)
(MDD)
X_train, y_train : (2015, 47), (2015,)
X_val, y_val : (672, 47), (672,)
X_test, y_test : (672, 47), (672,)
'''Baseline 모델 생성
from custom_modules.modeling import make_baseline
# Baseline (최빈 Class) 생성 기능
print("\n(Baseline)")
print("\t(Depression)")
baseline_depr = make_baseline(y_train_depr)
print("\n\t(MDD)")
baseline_mdd = make_baseline(y_train_mdd)
'''
(Baseline)
(Depression)
Baseline Accuracy : 0.7944
Baseline AUC_score : 0.5
(MDD)
Baseline Accuracy : 0.7300
Baseline AUC_score : 0.5
'''keras_tuner 라이브러리 불러오기
- 모델 튜닝은 keras_tuner 라이브러리를 통해 진행되었으며, 연산속도가 오래걸리는 편이기 때문에 효율성을 위해 튜닝 방식은 Hyperband로 진행하였음
# keras_tuner 라이브러리를 import
import keras_tuner as kt
# keras Tuner Output을 자동으로 갱신하는 Class 선언(overriding)
from keras.callbacks import Callback
import IPython
# Callback 클래스를 상속받고 오버라이딩 실시
class ClearTrainingOutput(Callback):
def on_train_end(*args, **kwargs):
IPython.display.clear_output(wait=True)튜닝 모델 정의
- custom_modules/modeling.py
# Keras Tuner용 Model 함수 정의 (MLP : Multi-Layer Perceptron)
def model_builder_mlp(hp):
# Sequential model 정의
model = Sequential(name='Sequential_MLP')
# Tuning Parameter 1 : 은닉층 Dense 노드 수 (units)
hp_units_1 = hp.Int('units_1', min_value=8, max_value=64, step=8)
model.add(Dense(units=hp_units_1, name='Dense_1', activation='relu', input_dim=47))
# Tuning Parameter 2 : 은닉층 Dense 노드 수 (units)
hp_units_2 = hp.Int('units_2', min_value=8, max_value=64, step=8)
model.add(Dense(units=hp_units_2, name='Dense_2', activation='relu'))
# 출력층(Sigmoid)
model.add(Dense(units=1, name='Output_Layer', activation='sigmoid'))
# Model Compile (평가지표 : AUCscore)
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=[tf.keras.metrics.AUC(name='auc')])
# Model 반환
return model- 2-4-3_MLP.ipynb
# custom_modules에서 정의한 model_builder를 불러옴
from custom_modules.modeling import model_builder_mlp
# keras tuner 정의 (튜닝방식은 Hyperband로 실시)
# 평가지표 기준은 AUC score를 최대화 하는 방향으로 설정함
tuner_depr = kt.Hyperband(hypermodel=model_builder_mlp,
objective=kt.Objective(name='val_auc', direction='max'),
max_epochs=10,
factor=3,
directory='kt_tuning',
project_name='mlp_tuning_depr')Depression(정상vs우울증) Model Tuning
- 튜닝 진행
tuner_depr.search(X_train_depr, y_train_depr,
epochs=10,
validation_data=(X_val_depr, y_val_depr),
callbacks=[ClearTrainingOutput()])
best_hps_depr = tuner_depr.get_best_hyperparameters(num_trials=1)[0]
'''
Trial 30 Complete [00h 00m 20s]
val_auc: 0.8214871883392334
Best val_auc So Far: 0.8241401314735413
Total elapsed time: 00h 04m 27s
INFO:tensorflow:Oracle triggered exit
'''- 최적화 하이퍼파라미터 확인
print(f"""
최적화된 Dense_1 노드 수 : {best_hps_depr.get('units_1')}
최적화된 Dense_2 노드 수 : {best_hps_depr.get('units_2')}
""")
'''
최적화된 Dense_1 노드 수 : 32
최적화된 Dense_2 노드 수 : 16
'''- 최적화 튜닝 모델 재구성
# 최적화된 파라미터로 모델을 다시 Build
best_model_depr = tuner_depr.hypermodel.build(best_hps_depr)
# 모델 구조 출력
best_model_depr.summary()
'''
Model: "Sequential_MLP"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
Dense_1 (Dense) (None, 32) 1536
Dense_2 (Dense) (None, 16) 528
Output_Layer (Dense) (None, 1) 17
=================================================================
Total params: 2,081
Trainable params: 2,081
Non-trainable params: 0
_________________________________________________________________
'''Depression(정상vs우울증) 튜닝 모델 재학습
- custom_modules/modeling.py
# Callback 함수 정의(EarlyStopping, ModelCheckpoint)
# 하이퍼파라미터 튜닝 모델의 재학습에 이용될 것임
def callback_sets(monitor, mode, patience, savepath):
'''
callback_sets
Keras 모델들의 callback함수를 하나로 묶어주는 기능
---
입력 변수 정보
monitor : (str) 기준 평가지표 혹은 손실값
mode : (str) 'max'(metric) 혹은 'min'(loss)
patience : (int) early stop의 적용 기준
savepath : (str) best 모델을 저장할 경로
---
출력 : List
'''
# EarlyStopping (patience번 안에 성능이 개선되지 않으면 종료)
early_stop = EarlyStopping(monitor=monitor, mode=mode, patience=patience,
restore_best_weights=True)
# ModelCheckpoint (성능이 가장 좋은 모델을 저장)
check_point = ModelCheckpoint(filepath=savepath, monitor=monitor, mode=mode,
verbose=0, save_best_only=True)
# 출력 : list
return [early_stop, check_point]- 2-4-3_MLP.ipynb
# Callback 함수 불러오기(EarlyStopping, ModelCheckpoint)
from custom_modules.modeling import callback_sets
savepath = '../tuning-models/MLP_depr.h5'
callbacks = callback_sets(monitor='val_auc', mode='max', patience=8, savepath=savepath)
# 최적화된 파라미터로 모델 재학습
best_model_depr.fit(X_train_depr, y_train_depr,
validation_data=(X_val_depr, y_val_depr),
epochs=100,
callbacks=callbacks)
'''
Epoch 1/100
311/311 [==============================] - 3s 7ms/step - loss: 0.4601 - auc: 0.7164 - val_loss: 0.3924 - val_auc: 0.8122
Epoch 2/100
311/311 [==============================] - 2s 6ms/step - loss: 0.3972 - auc: 0.8106 - val_loss: 0.3835 - val_auc: 0.8222
Epoch 3/100
311/311 [==============================] - 2s 6ms/step - loss: 0.3912 - auc: 0.8165 - val_loss: 0.3830 - val_auc: 0.8215
Epoch 4/100
311/311 [==============================] - 2s 6ms/step - loss: 0.3898 - auc: 0.8174 - val_loss: 0.3827 - val_auc: 0.8226
Epoch 5/100
311/311 [==============================] - 2s 7ms/step - loss: 0.3868 - auc: 0.8204 - val_loss: 0.3877 - val_auc: 0.8211
Epoch 6/100
311/311 [==============================] - 2s 6ms/step - loss: 0.3843 - auc: 0.8235 - val_loss: 0.3827 - val_auc: 0.8211
Epoch 7/100
311/311 [==============================] - 2s 6ms/step - loss: 0.3831 - auc: 0.8249 - val_loss: 0.3843 - val_auc: 0.8214
Epoch 8/100
311/311 [==============================] - 2s 7ms/step - loss: 0.3805 - auc: 0.8270 - val_loss: 0.3873 - val_auc: 0.8180
Epoch 9/100
311/311 [==============================] - 2s 7ms/step - loss: 0.3791 - auc: 0.8289 - val_loss: 0.3856 - val_auc: 0.8190
Epoch 10/100
311/311 [==============================] - 2s 7ms/step - loss: 0.3766 - auc: 0.8310 - val_loss: 0.3851 - val_auc: 0.8203
Epoch 11/100
311/311 [==============================] - 2s 7ms/step - loss: 0.3753 - auc: 0.8318 - val_loss: 0.3852 - val_auc: 0.8181
Epoch 12/100
311/311 [==============================] - 2s 6ms/step - loss: 0.3733 - auc: 0.8340 - val_loss: 0.3900 - val_auc: 0.8159
'''- 성능 평가 및 모델 저장 여부 확인
# Evaluation Best Model
best_model_depr.evaluate(X_train_depr, y_train_depr, verbose=2)
best_model_depr.evaluate(X_val_depr, y_val_depr, verbose=2)
best_model_depr.evaluate(X_test_depr, y_test_depr, verbose=2)
'''
311/311 - 1s - loss: 0.3827 - auc: 0.8256 - 937ms/epoch - 3ms/step
104/104 - 0s - loss: 0.3827 - auc: 0.8226 - 317ms/epoch - 3ms/step
104/104 - 0s - loss: 0.3788 - auc: 0.8200 - 318ms/epoch - 3ms/step
'''# Saved model Evaluation
from keras.models import load_model
model_test_depr = load_model('../tuning-models/MLP_depr.h5')
model_test_depr.evaluate(X_train_depr, y_train_depr, verbose=2)
model_test_depr.evaluate(X_val_depr, y_val_depr, verbose=2)
model_test_depr.evaluate(X_test_depr, y_test_depr, verbose=2)
'''
311/311 - 1s - loss: 0.3827 - auc: 0.8256 - 1s/epoch - 4ms/step
104/104 - 0s - loss: 0.3827 - auc: 0.8226 - 331ms/epoch - 3ms/step
104/104 - 0s - loss: 0.3788 - auc: 0.8200 - 332ms/epoch - 3ms/step
'''- EarlyStopping이 적용된 Best 모델과 저장된 모델의 Evaluation 수치가 동일함을 확인할 수 있음
MDD(경도우울증vs주요우울장애) Model Tuning
- 튜닝 진행
# Depression과 동일한 구조와 방식으로 진행함
tuner_mdd = kt.Hyperband(hypermodel=model_builder_mlp,
objective=kt.Objective(name='val_auc', direction='max'),
max_epochs=10,
factor=3,
directory='kt_tuning',
project_name='mlp_tuning_mdd')
tuner_mdd.search(X_train_mdd, y_train_mdd,
epochs=10,
validation_data=(X_val_mdd, y_val_mdd),
callbacks=[ClearTrainingOutput()])
best_hps_mdd = tuner_mdd.get_best_hyperparameters(num_trials=1)[0]
'''
Trial 30 Complete [00h 00m 06s]
val_auc: 0.7162057757377625
Best val_auc So Far: 0.7283497452735901
Total elapsed time: 00h 01m 37s
INFO:tensorflow:Oracle triggered exit
'''- 최적화 하이퍼파라미터 확인
print(f"""
최적화된 Dense_1 노드 수 : {best_hps_mdd.get('units_1')}
최적화된 Dense_2 노드 수 : {best_hps_mdd.get('units_2')}
""")
'''
최적화된 Dense_1 노드 수 : 40
최적화된 Dense_2 노드 수 : 40
'''- 최적화 튜닝 모델 재구성
# 최적화된 파라미터로 모델을 다시 Build
best_model_mdd = tuner_mdd.hypermodel.build(best_hps_mdd)
# 모델 구조 출력
best_model_mdd.summary()
'''
Model: "Sequential_MLP"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
Dense_1 (Dense) (None, 40) 1920
Dense_2 (Dense) (None, 40) 1640
Output_Layer (Dense) (None, 1) 41
=================================================================
Total params: 3,601
Trainable params: 3,601
Non-trainable params: 0
_________________________________________________________________
'''MDD(경도우울증vs주요우울장애) 튜닝 모델 재학습
savepath_mdd = '../tuning-models/MLP_mdd.h5'
callbacks_mdd = callback_sets(monitor='val_auc', mode='max', patience=8, savepath=savepath_mdd)
# 최적화된 파라미터로 모델 재학습
best_model_mdd.fit(X_train_mdd, y_train_mdd,
validation_data=(X_val_mdd, y_val_mdd),
epochs=100,
callbacks=callbacks_mdd)
'''
Epoch 1/100
63/63 [==============================] - 1s 10ms/step - loss: 0.5654 - auc: 0.6181 - val_loss: 0.5549 - val_auc: 0.6869
Epoch 2/100
63/63 [==============================] - 0s 7ms/step - loss: 0.5157 - auc: 0.7426 - val_loss: 0.5386 - val_auc: 0.7074
Epoch 3/100
63/63 [==============================] - 0s 6ms/step - loss: 0.4914 - auc: 0.7697 - val_loss: 0.5344 - val_auc: 0.7145
Epoch 4/100
63/63 [==============================] - 0s 6ms/step - loss: 0.4802 - auc: 0.7799 - val_loss: 0.5346 - val_auc: 0.7163
Epoch 5/100
63/63 [==============================] - 0s 6ms/step - loss: 0.4720 - auc: 0.7892 - val_loss: 0.5357 - val_auc: 0.7158
Epoch 6/100
63/63 [==============================] - 0s 6ms/step - loss: 0.4670 - auc: 0.7933 - val_loss: 0.5359 - val_auc: 0.7170
Epoch 7/100
63/63 [==============================] - 0s 7ms/step - loss: 0.4597 - auc: 0.8021 - val_loss: 0.5342 - val_auc: 0.7165
Epoch 8/100
63/63 [==============================] - 0s 6ms/step - loss: 0.4563 - auc: 0.8068 - val_loss: 0.5378 - val_auc: 0.7147
Epoch 9/100
63/63 [==============================] - 0s 6ms/step - loss: 0.4512 - auc: 0.8122 - val_loss: 0.5385 - val_auc: 0.7161
Epoch 10/100
63/63 [==============================] - 0s 6ms/step - loss: 0.4455 - auc: 0.8171 - val_loss: 0.5438 - val_auc: 0.7145
Epoch 11/100
63/63 [==============================] - 0s 6ms/step - loss: 0.4423 - auc: 0.8207 - val_loss: 0.5410 - val_auc: 0.7155
Epoch 12/100
63/63 [==============================] - 0s 6ms/step - loss: 0.4370 - auc: 0.8272 - val_loss: 0.5534 - val_auc: 0.7106
Epoch 13/100
63/63 [==============================] - 0s 7ms/step - loss: 0.4316 - auc: 0.8338 - val_loss: 0.5476 - val_auc: 0.7143
Epoch 14/100
63/63 [==============================] - 0s 6ms/step - loss: 0.4245 - auc: 0.8390 - val_loss: 0.5517 - val_auc: 0.7103
'''- 성능 평가 및 모델 저장 여부 확인
# Evaluation Best Model
best_model_mdd.evaluate(X_train_mdd, y_train_mdd, verbose=2)
best_model_mdd.evaluate(X_val_mdd, y_val_mdd, verbose=2)
best_model_mdd.evaluate(X_test_mdd, y_test_mdd, verbose=2)
'''
63/63 - 0s - loss: 0.4596 - auc: 0.8065 - 431ms/epoch - 7ms/step
21/21 - 0s - loss: 0.5359 - auc: 0.7170 - 76ms/epoch - 4ms/step
21/21 - 0s - loss: 0.5094 - auc: 0.7468 - 75ms/epoch - 4ms/step
'''# Saved model Evaluation
model_test_mdd = load_model('../tuning-models/MLP_mdd.h5')
model_test_mdd.evaluate(X_train_mdd, y_train_mdd, verbose=2)
model_test_mdd.evaluate(X_val_mdd, y_val_mdd, verbose=2)
model_test_mdd.evaluate(X_test_mdd, y_test_mdd, verbose=2)
'''
63/63 - 0s - loss: 0.4596 - auc: 0.8065 - 412ms/epoch - 7ms/step
21/21 - 0s - loss: 0.5359 - auc: 0.7170 - 83ms/epoch - 4ms/step
21/21 - 0s - loss: 0.5094 - auc: 0.7468 - 83ms/epoch - 4ms/step
'''- EarlyStopping이 적용된 Best 모델과 저장된 모델의 Evaluation 수치가 동일함을 확인할 수 있음
4-5. 1D-CNN 합성곱층 신경망

- 1D-CNN 모델은 MLP와 동일하게 Jupyter Notebook을 통해 튜닝 및 모델링이 진행되었으며, CNN 모델로 우울증 예측 성능을 높였다는 논문을 통해 도입하게 되었고, 모델 구조 또한 논문과 유사하게 구성하여 튜닝 및 모델링을 실시하였음
- 참고논문 : 남원우, & 김병욱. (2020). 환경적 요소 선별을 통한 딥러닝 기반 우울증 분류 예측. 전기학회논문지, 69(7), 1102-1110.
- 튜닝 및 모델링 과정은 MLP와 동일하게 진행되었기 때문에, 여기서는 MLP와의 차이점들만 다루도록 하겠음.
튜닝 모델 정의
- custom_modules/modeling.py
# Keras Tuner용 Model 함수 정의 (1D-CNN : 1D-Convolutional Neural Networks)
def model_builder_cnn(hp):
# Sequential model 정의
model = Sequential(name='Sequential')
# Tuning Parameter 1 : 합성곱층 Conv1D 필터 수 (filters)
hp_filters = hp.Choice('Conv1D_Filters', values = [4, 8, 16, 32])
# Tuning Parameter 2 : 합성곱층 Conv1D 커널 크기 (kernel_size)
hp_kernel_size = hp.Int('kernel_size', min_value = 3, max_value = 7, step=1)
# 합성곱층 Conv1D 추가
model.add(Conv1D(filters=hp_filters, kernel_size=hp_kernel_size, strides=1,
activation='relu', kernel_initializer='he_normal',
input_shape=(47,1), name='Conv1D_Layer'))
# 입력값이 쏠리는 것을 막기위해 BatchNormalization 실시
model.add(BatchNormalization(name='Batch_Normalization'))
# Flatten으로 FC(Fully Connected)층을 추가
model.add(Flatten(name='Flatten_Layer'))
# Tuning Parameter 3 : FC(Fully Connected)층 Dense unit 수
hp_fc_units = hp.Int('FC_units', min_value=64, max_value=256, step=64)
model.add(Dense(units=hp_fc_units, name='FC_Dense_Layer',
activation='relu', kernel_initializer='he_normal'))
# 과적합 방지를 위한 Dropout층 추가
# Tuning Parameter 3 : Dropout층 dropout_rate
hp_dropout_rate = hp.Choice('Dropout_rate', values = [0.7, 0.8, 0.9])
model.add(Dropout(rate=hp_dropout_rate, name='Dropout'))
# 출력층(Sigmoid)
model.add(Dense(units=1, name='Output_Layer',
activation='sigmoid', kernel_initializer='glorot_normal'))
# Tuning Parameter 4 : Adam optimizer의 learning_rate
hp_learning_rate = hp.Choice('learning_rate', values = [1e-2, 1e-3, 1e-4])
model.compile(optimizer = keras.optimizers.Adam(learning_rate=hp_learning_rate),
loss = 'binary_crossentropy',
metrics = [tf.keras.metrics.AUC(name='auc')])
# Model 반환
return model- 2-4-4_CNN.ipynb
# custom_modules에서 정의한 model_builder를 불러옴
from custom_modules.modeling import model_builder_cnn
# keras tuner 정의 (튜닝방식은 Hyperband로 실시)
# 평가지표 기준은 AUC score를 최대화 하는 방향으로 설정함
tuner_depr = kt.Hyperband(hypermodel=model_builder_cnn,
objective=kt.Objective(name='val_auc', direction='max'),
max_epochs=10,
factor=3,
directory='kt_tuning',
project_name='cnn_tuning_depr')Depression(정상vs우울증) Model Tuning
- 튜닝 진행
# Tuning 실시
tuner_depr.search(X_train_depr, y_train_depr,
epochs=10,
validation_data=(X_val_depr, y_val_depr),
callbacks=[ClearTrainingOutput()])
best_hps_depr = tuner_depr.get_best_hyperparameters(num_trials=1)[0]
'''
Trial 30 Complete [00h 00m 24s]
val_auc: 0.821434736251831
Best val_auc So Far: 0.8224851489067078
Total elapsed time: 00h 05m 32s
INFO:tensorflow:Oracle triggered exit
'''- 최적화 하이퍼파라미터 확인
print(f"""
최적화된 Conv1D_Filters : {best_hps_depr.get('Conv1D_Filters')}
최적화된 kernel_size : {best_hps_depr.get('kernel_size')}
최적화된 FC_units : {best_hps_depr.get('FC_units')}
최적화된 Dropout_rate : {best_hps_depr.get('Dropout_rate')}
최적화된 learning_rate : {best_hps_depr.get('learning_rate')}
""")
'''
최적화된 Conv1D_Filters : 16
최적화된 kernel_size : 3
최적화된 FC_units : 128
최적화된 Dropout_rate : 0.8
최적화된 learning_rate : 0.001
'''- 최적화 튜닝 모델 재구성
# 최적화된 파라미터로 모델을 다시 Build
best_model_depr = tuner_depr.hypermodel.build(best_hps_depr)
# 모델 구조 출력
best_model_depr.summary()
'''
Model: "Sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
Conv1D_Layer (Conv1D) (None, 45, 16) 64
Batch_Normalization (BatchN (None, 45, 16) 64
ormalization)
Flatten_Layer (Flatten) (None, 720) 0
FC_Dense_Layer (Dense) (None, 128) 92288
Dropout (Dropout) (None, 128) 0
Output_Layer (Dense) (None, 1) 129
=================================================================
Total params: 92,545
Trainable params: 92,513
Non-trainable params: 32
_________________________________________________________________
'''Depression(정상vs우울증) 튜닝 모델 재학습
# Callback 함수 불러오기(EarlyStopping, ModelCheckpoint)
from custom_modules.modeling import callback_sets
savepath = '../tuning-models/CNN_depr.h5'
callbacks = callback_sets(monitor='val_auc', mode='max', patience=8, savepath=savepath)
# 최적화된 파라미터로 모델 재학습
best_model_depr.fit(X_train_depr, y_train_depr,
validation_data=(X_val_depr, y_val_depr),
epochs=100,
callbacks=callbacks)
'''
Epoch 1/100
311/311 [==============================] - 3s 8ms/step - loss: 0.5173 - auc: 0.7071 - val_loss: 0.4044 - val_auc: 0.8149
Epoch 2/100
311/311 [==============================] - 2s 8ms/step - loss: 0.4355 - auc: 0.7699 - val_loss: 0.3975 - val_auc: 0.8163
Epoch 3/100
311/311 [==============================] - 2s 7ms/step - loss: 0.4266 - auc: 0.7798 - val_loss: 0.3876 - val_auc: 0.8152
Epoch 4/100
311/311 [==============================] - 2s 8ms/step - loss: 0.4159 - auc: 0.7887 - val_loss: 0.3864 - val_auc: 0.8176
Epoch 5/100
311/311 [==============================] - 2s 7ms/step - loss: 0.4156 - auc: 0.7919 - val_loss: 0.3891 - val_auc: 0.8166
Epoch 6/100
311/311 [==============================] - 2s 7ms/step - loss: 0.4145 - auc: 0.7926 - val_loss: 0.3924 - val_auc: 0.8189
Epoch 7/100
311/311 [==============================] - 2s 7ms/step - loss: 0.4139 - auc: 0.7927 - val_loss: 0.3866 - val_auc: 0.8170
Epoch 8/100
311/311 [==============================] - 2s 7ms/step - loss: 0.4102 - auc: 0.7976 - val_loss: 0.3860 - val_auc: 0.8197
Epoch 9/100
311/311 [==============================] - 2s 7ms/step - loss: 0.4085 - auc: 0.7978 - val_loss: 0.3854 - val_auc: 0.8208
Epoch 10/100
311/311 [==============================] - 2s 7ms/step - loss: 0.4096 - auc: 0.7989 - val_loss: 0.3875 - val_auc: 0.8174
Epoch 11/100
311/311 [==============================] - 2s 7ms/step - loss: 0.4092 - auc: 0.7992 - val_loss: 0.3844 - val_auc: 0.8201
Epoch 12/100
311/311 [==============================] - 2s 7ms/step - loss: 0.4062 - auc: 0.8017 - val_loss: 0.3862 - val_auc: 0.8204
Epoch 13/100
311/311 [==============================] - 2s 7ms/step - loss: 0.4057 - auc: 0.8008 - val_loss: 0.3854 - val_auc: 0.8194
Epoch 14/100
311/311 [==============================] - 2s 7ms/step - loss: 0.3992 - auc: 0.8074 - val_loss: 0.3872 - val_auc: 0.8191
Epoch 15/100
311/311 [==============================] - 2s 7ms/step - loss: 0.4011 - auc: 0.8076 - val_loss: 0.3831 - val_auc: 0.8208
Epoch 16/100
311/311 [==============================] - 2s 7ms/step - loss: 0.4034 - auc: 0.8031 - val_loss: 0.3848 - val_auc: 0.8204
Epoch 17/100
311/311 [==============================] - 2s 7ms/step - loss: 0.3986 - auc: 0.8081 - val_loss: 0.3893 - val_auc: 0.8213
Epoch 18/100
311/311 [==============================] - 2s 7ms/step - loss: 0.4018 - auc: 0.8034 - val_loss: 0.3870 - val_auc: 0.8193
Epoch 19/100
311/311 [==============================] - 2s 7ms/step - loss: 0.4021 - auc: 0.8055 - val_loss: 0.3843 - val_auc: 0.8190
Epoch 20/100
311/311 [==============================] - 2s 7ms/step - loss: 0.3968 - auc: 0.8119 - val_loss: 0.3840 - val_auc: 0.8198
Epoch 21/100
311/311 [==============================] - 2s 7ms/step - loss: 0.3996 - auc: 0.8080 - val_loss: 0.3917 - val_auc: 0.8199
Epoch 22/100
311/311 [==============================] - 2s 7ms/step - loss: 0.3948 - auc: 0.8120 - val_loss: 0.3891 - val_auc: 0.8171
Epoch 23/100
311/311 [==============================] - 2s 7ms/step - loss: 0.3987 - auc: 0.8073 - val_loss: 0.3845 - val_auc: 0.8208
Epoch 24/100
311/311 [==============================] - 2s 7ms/step - loss: 0.3937 - auc: 0.8136 - val_loss: 0.3823 - val_auc: 0.8211
Epoch 25/100
311/311 [==============================] - 2s 7ms/step - loss: 0.3950 - auc: 0.8131 - val_loss: 0.3825 - val_auc: 0.8202
'''- 성능 평가 및 모델 저장 여부 확인
# Evaluation Best Model
best_model_depr.evaluate(X_train_depr, y_train_depr, verbose=2)
best_model_depr.evaluate(X_val_depr, y_val_depr, verbose=2)
best_model_depr.evaluate(X_test_depr, y_test_depr, verbose=2)
'''
311/311 - 1s - loss: 0.3799 - auc: 0.8316 - 992ms/epoch - 3ms/step
104/104 - 0s - loss: 0.3893 - auc: 0.8213 - 323ms/epoch - 3ms/step
104/104 - 0s - loss: 0.3874 - auc: 0.8156 - 325ms/epoch - 3ms/step
'''# Saved model Evaluation
from keras.models import load_model
model_test_depr = load_model('../tuning-models/CNN_depr.h5')
model_test_depr.evaluate(X_train_depr, y_train_depr, verbose=2)
model_test_depr.evaluate(X_val_depr, y_val_depr, verbose=2)
model_test_depr.evaluate(X_test_depr, y_test_depr, verbose=2)
'''
311/311 - 1s - loss: 0.3799 - auc: 0.8316 - 1s/epoch - 4ms/step
104/104 - 0s - loss: 0.3893 - auc: 0.8213 - 326ms/epoch - 3ms/step
104/104 - 0s - loss: 0.3874 - auc: 0.8156 - 326ms/epoch - 3ms/step
'''- EarlyStopping이 적용된 Best 모델과 저장된 모델의 Evaluation 수치가 동일함을 확인할 수 있음
MDD(경도우울증vs주요우울장애) Model Tuning
- 튜닝 진행
# Depression과 동일한 구조와 방식으로 진행함
tuner_mdd = kt.Hyperband(hypermodel=model_builder_cnn,
objective=kt.Objective(name='val_auc', direction='max'),
max_epochs=10,
factor=3,
directory='kt_tuning',
project_name='cnn_tuning_mdd')
tuner_mdd.search(X_train_mdd, y_train_mdd,
epochs=10,
validation_data=(X_val_mdd, y_val_mdd),
callbacks=[ClearTrainingOutput()])
best_hps_mdd = tuner_mdd.get_best_hyperparameters(num_trials=1)[0]
'''
Trial 30 Complete [00h 00m 08s]
val_auc: 0.6838897466659546
Best val_auc So Far: 0.7213106751441956
Total elapsed time: 00h 01m 56s
INFO:tensorflow:Oracle triggered exit
'''- 최적화 하이퍼파라미터 확인
print(f"""
최적화된 Conv1D_Filters : {best_hps_mdd.get('Conv1D_Filters')}
최적화된 kernel_size : {best_hps_mdd.get('kernel_size')}
최적화된 FC_units : {best_hps_mdd.get('FC_units')}
최적화된 Dropout_rate : {best_hps_mdd.get('Dropout_rate')}
최적화된 learning_rate : {best_hps_mdd.get('learning_rate')}
""")
'''
최적화된 Conv1D_Filters : 32
최적화된 kernel_size : 4
최적화된 FC_units : 256
최적화된 Dropout_rate : 0.8
최적화된 learning_rate : 0.01
'''- 최적화 튜닝 모델 재구성
# 최적화된 파라미터로 모델을 다시 Build
best_model_mdd = tuner_mdd.hypermodel.build(best_hps_mdd)
# 모델 구조 출력
best_model_mdd.summary()
'''
Model: "Sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
Conv1D_Layer (Conv1D) (None, 44, 32) 160
Batch_Normalization (BatchN (None, 44, 32) 128
ormalization)
Flatten_Layer (Flatten) (None, 1408) 0
FC_Dense_Layer (Dense) (None, 256) 360704
Dropout (Dropout) (None, 256) 0
Output_Layer (Dense) (None, 1) 257
=================================================================
Total params: 361,249
Trainable params: 361,185
Non-trainable params: 64
_________________________________________________________________
'''MDD(경도우울증vs주요우울장애) 튜닝 모델 재학습
savepath_mdd = '../tuning-models/CNN_mdd.h5'
callbacks_mdd = callback_sets(monitor='val_auc', mode='max', patience=8, savepath=savepath_mdd)
# 최적화된 파라미터로 모델 재학습
best_model_mdd.fit(X_train_mdd, y_train_mdd,
validation_data=(X_val_mdd, y_val_mdd),
epochs=100,
callbacks=callbacks_mdd)
'''
Epoch 1/100
63/63 [==============================] - 2s 13ms/step - loss: 1.9440 - auc: 0.5732 - val_loss: 0.5822 - val_auc: 0.6898
Epoch 2/100
63/63 [==============================] - 0s 7ms/step - loss: 0.6090 - auc: 0.6411 - val_loss: 0.5531 - val_auc: 0.6980
Epoch 3/100
63/63 [==============================] - 0s 7ms/step - loss: 0.5620 - auc: 0.6804 - val_loss: 0.5442 - val_auc: 0.6949
Epoch 4/100
63/63 [==============================] - 0s 8ms/step - loss: 0.5401 - auc: 0.7053 - val_loss: 0.5467 - val_auc: 0.7024
Epoch 5/100
63/63 [==============================] - 0s 8ms/step - loss: 0.5252 - auc: 0.7127 - val_loss: 0.5373 - val_auc: 0.7120
Epoch 6/100
63/63 [==============================] - 0s 7ms/step - loss: 0.5213 - auc: 0.7252 - val_loss: 0.5407 - val_auc: 0.7022
Epoch 7/100
63/63 [==============================] - 0s 7ms/step - loss: 0.5097 - auc: 0.7431 - val_loss: 0.5357 - val_auc: 0.7088
Epoch 8/100
63/63 [==============================] - 1s 8ms/step - loss: 0.5019 - auc: 0.7483 - val_loss: 0.5418 - val_auc: 0.7153
Epoch 9/100
63/63 [==============================] - 1s 8ms/step - loss: 0.5151 - auc: 0.7445 - val_loss: 0.5358 - val_auc: 0.7147
Epoch 10/100
63/63 [==============================] - 0s 7ms/step - loss: 0.4917 - auc: 0.7695 - val_loss: 0.5405 - val_auc: 0.7072
Epoch 11/100
63/63 [==============================] - 0s 8ms/step - loss: 0.5046 - auc: 0.7461 - val_loss: 0.5423 - val_auc: 0.7064
Epoch 12/100
63/63 [==============================] - 0s 7ms/step - loss: 0.5030 - auc: 0.7560 - val_loss: 0.5485 - val_auc: 0.7055
Epoch 13/100
63/63 [==============================] - 0s 7ms/step - loss: 0.4983 - auc: 0.7616 - val_loss: 0.5533 - val_auc: 0.7034
Epoch 14/100
63/63 [==============================] - 0s 7ms/step - loss: 0.4979 - auc: 0.7612 - val_loss: 0.5550 - val_auc: 0.7084
Epoch 15/100
63/63 [==============================] - 0s 8ms/step - loss: 0.4931 - auc: 0.7649 - val_loss: 0.5403 - val_auc: 0.7135
Epoch 16/100
63/63 [==============================] - 0s 7ms/step - loss: 0.5055 - auc: 0.7533 - val_loss: 0.5466 - val_auc: 0.7012
'''- 성능 평가 및 모델 저장 여부 확인
# Evaluation Best Model
best_model_mdd.evaluate(X_train_mdd, y_train_mdd, verbose=2)
best_model_mdd.evaluate(X_val_mdd, y_val_mdd, verbose=2)
best_model_mdd.evaluate(X_test_mdd, y_test_mdd, verbose=2)
'''
63/63 - 0s - loss: 0.5034 - auc: 0.8009 - 465ms/epoch - 7ms/step
21/21 - 0s - loss: 0.5418 - auc: 0.7153 - 74ms/epoch - 4ms/step
21/21 - 0s - loss: 0.5226 - auc: 0.7447 - 82ms/epoch - 4ms/step
'''# Saved model Evaluation
model_test_mdd = load_model('../tuning-models/CNN_mdd.h5')
model_test_mdd.evaluate(X_train_mdd, y_train_mdd, verbose=2)
model_test_mdd.evaluate(X_val_mdd, y_val_mdd, verbose=2)
model_test_mdd.evaluate(X_test_mdd, y_test_mdd, verbose=2)
'''
63/63 - 0s - loss: 0.5034 - auc: 0.8009 - 438ms/epoch - 7ms/step
21/21 - 0s - loss: 0.5418 - auc: 0.7153 - 85ms/epoch - 4ms/step
21/21 - 0s - loss: 0.5226 - auc: 0.7447 - 81ms/epoch - 4ms/step
'''- EarlyStopping이 적용된 Best 모델과 저장된 모델의 Evaluation 수치가 동일함을 확인할 수 있음
4-6~. 이후 과정
다음 글에서는 최종 모델 선정 및 경량화 과정을 이어서 다루어 보도록 하겠음

일 때문에 포스팅은 잠시 쉬어요 ㅠ // Now. 수학 강사 (광교) // Prev. Machine Learning (AI) Engineer & BackEnd Engineer