이번에 리뷰해볼 논문은 AlexNet을 다루는 'ImageNet Classification with Deep Convolutional Neural Networks, Krizhevsky et al. (2012)' 라는 논문이다. Deep Convolutional Neural Network의 error rate를 의미있는 지표로 줄이고, 딥러닝이 핫해지는데 큰 기여를 한 논문이다.
1. 저자가 이루려고 한 것
이 논문은 large, deep CNN을 훈련시켜 의미있는 결과를 얻으려고 노력했다. dataset은 ImageNet LSVRC-2010버전을 사용했다. 그 과정에서 AlexNet이라는 CNN Architecture를 제안했고, 결과적으로 그 당시 SOTA 성능을 뛰어넘는 top-1 error rate 37.5%와 top-5 error rate 17.0% 성능을 이루었다. 이전까지 문제였던 것은 ImageNet과 같이 큰 데이터셋을 훈련시키기 위해 large learning capacity를 가진 모델이 필요했다는 것이다. 그러나 모델의 capacity가 커지면 data에 대한 overfitting을 방지하는 것 또한 굉장히 중요한 부분이었다. 저자는 이를 해결하기 위해 다양한 방법을 사용해 AlexNet을 구현하였다.
2. 주요 내용
1) The Dataset
논문에서 사용한 dataset은 ImageNet의 subset이다. 원래의 ImageNet이 15 million개의 이미지와 22000개의 category를 가지고 있었다면, 논문에서 사용된 ImageNet-LSVRC-2010은 1000개의 category에 해당하는 이미지들이 각각 1000장씩 있다. 따라서 총 1.2 million개의 training 이미지와 50000개의 validation 이미지, 150000개의 testing 이미지를 가지는 것이다. ImageNet에서는 top-1 error rate와 top-5 error rate를 밝히는 것이 관행이기 때문에 이 지표를 사용한다. 만약 모델이 이미지를 분류할 때 correct label의 가능성이 가장 높은 5개의 class를 골랐는데 그 중 correct label이 있다면 top-5 error는 0%가 된다. 즉, 모델이 correct label로 예측한 상위 5개의 label중 정답 값이 없으면 top-5 error 관점에서는 error로 판별한다는 뜻이다.
또, CNN은 fixed input을 요구하기 때문에, 다양한 resolution의 이미지가 있는 ImageNet의 크기를 일정하게 해주는 작업이 필요하다. 모든 이미지를 256x256 크기로 downsampling을 함으로써 이를 해결한다고 한다. 그리고 나서 mean image를 빼주는 것 말고는 특별한 전처리 기법은 사용하지 않는다.
2) The Architecture
모델에서 사용한 unusual feature들에 대한 설명을 중요한 순서대로 설명한다.
2.1) ReLU Nonlinearity
가장 기본적인 nonlinearity function은 나 를 이용하는 것이었다. 그러나 이 두 식들은 saturation이라는 문제가 있어 훈련 속도가 굉장히 저하되는 문제점이 있었다. 따라서 논문은 의 형태를 가진 non-saturating nonlinearity인 ReLU를 적용했다. 그 결과 Deep CNN에서 같은 성능을 얻기 위해 걸리는 시간이 를 적용한 것보다 몇배는 빠른 것으로 나타났다.
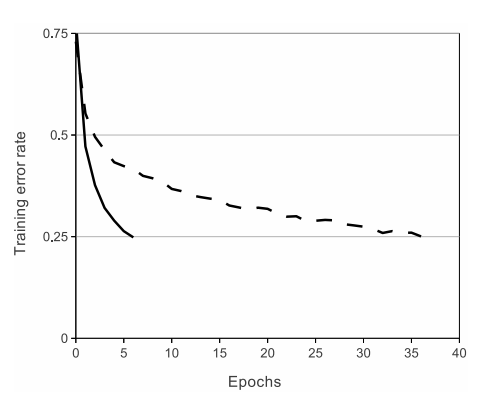
위의 그래프를 보면, 같은 error rate를 얻기 위해 필요한 epoch수가 ReLU 적용 모델이 tanh 적용 모델보다 현저히 적다. ReLU가 큰 Neural Network의 훈련을 가능하게 하는데에 큰 기여를 했다는 것을 알 수 있다.
2.2) Training in Multiple GPUs
이 당시의 GTX 580 GPU는 3GB의 메모리를 가지고 있었다. 이것 하나 가지고는 훈련시킬 수 있는 모델의 최대 사이즈가 제한되는 문제가 있다. 1.2million개의 훈련 데이터가 하나의 GPU에는 들어가지 않았던 것이다. 그렇기 때문에 저자는 2개의 GPU를 사용해 네트워크를 나눈다. 이때 당시 GPU들이 Cross-GPU parallelization에 용이했기 때문에 이것이 가능했다. 이렇게 훈련시에 모델의 뉴런들 중 반을 하나의 GPU에 넣고, 나머지 반은 다른 GPU에 넣는데, 이 두 GPU들은 특정 layer에서만 서로 communicate한다고 한다. 자세한 내용은 적지 않겠다. 두 개의 GPU를 사용한 결과 하나의 GPU로 훈련시킨 것보다는 조금 적은 training time을 얻을 수 있었다.
2.3) Local Response Normalization (LRN)
사실 LRN은 batch normalization의 등장 이후 잘 사용하지는 않는다고 한다. 그러나 어떤 방식으로 normalization을 진행하는지는 알 필요가 있다. 공식은 아래 사진을 이용한다.
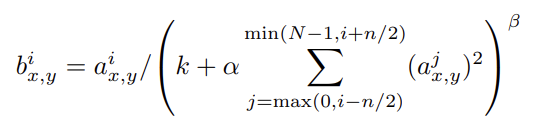
LRN의 기본적인 컨셉은 의 주변 response(kernel map)들을 이용해 normalization을 진행하겠다는 뜻이다. k, n, alpha, beta는 hyperparameter들이다. 이때 n은 주변 kernel map을 몇개 사용할지에 대한 변수이고, N은 총 kernel map의 개수이다. 논문의 실험결과는 k=2, n=5, alpha=10^(-4), beta=0.75를 사용했다.
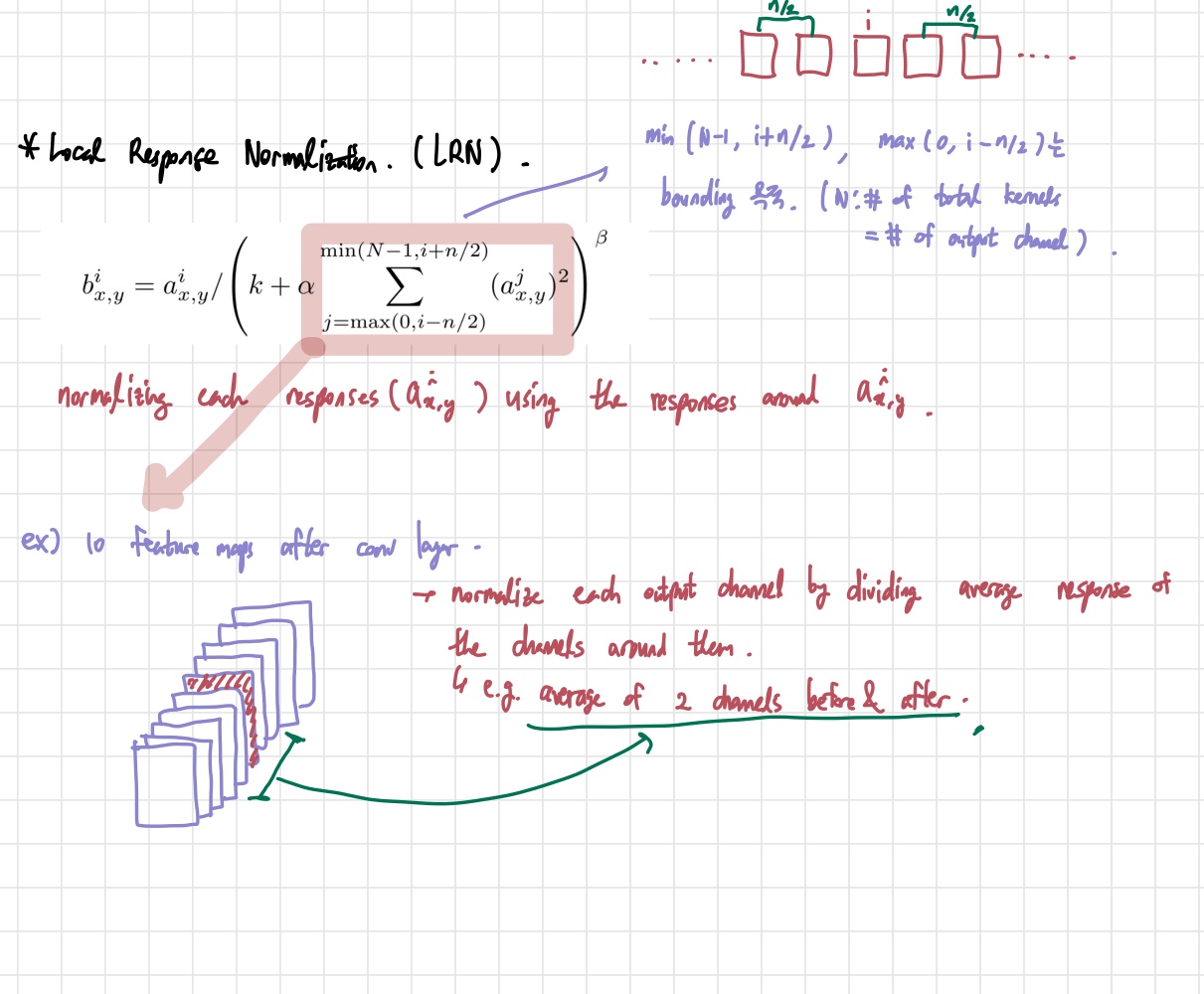
위의 공식에서 j에 대해 반복할 때 min, max로 bounding 처리가 되어 있는 것은 j가 음수가 되거나 총 kernel map수를 넘어가면 안되기 때문이다. 현재의 kernel map 기준으로 앞 뒤로 n/2개의 kernel map들을 average해서 normalization을 진행한다. 그 결과 LRN은 top-1과 top-5 error rate를 1.4%, 1.2%씩 줄여준다.
2.4) Overlapping Pooling
Pooling layer는 이웃하는 neuron들의 output을 summarize해주는 효과가 있다. 같은 feature map내에서만 이루어진다. 전통적으로 pooling을 할 때에는 overlapping이 일어나지 않게 설정한다. 예를 들면, 가장 많이 사용하는 stride=2, 2x2 max pooling의 경우, overlapping이 나타나지 않는다. 그러나 만약 stride가 1, 2x2 max pooling과 같은 경우, overlapping이 발생하게 된다. 논문에서는 의도적으로 overlapping pooling을 사용한다. stride=3, 3x3 pooling을 사용함으로써 top-1과 top-5 error rate가 각각 0.4%와 0.3%씩 감소한다. 이를 통해 논문은 overlapping pooling이 overfitting을 방지하는데 조금은 기여한다고 주장한다.
2.5) Overall Architecture
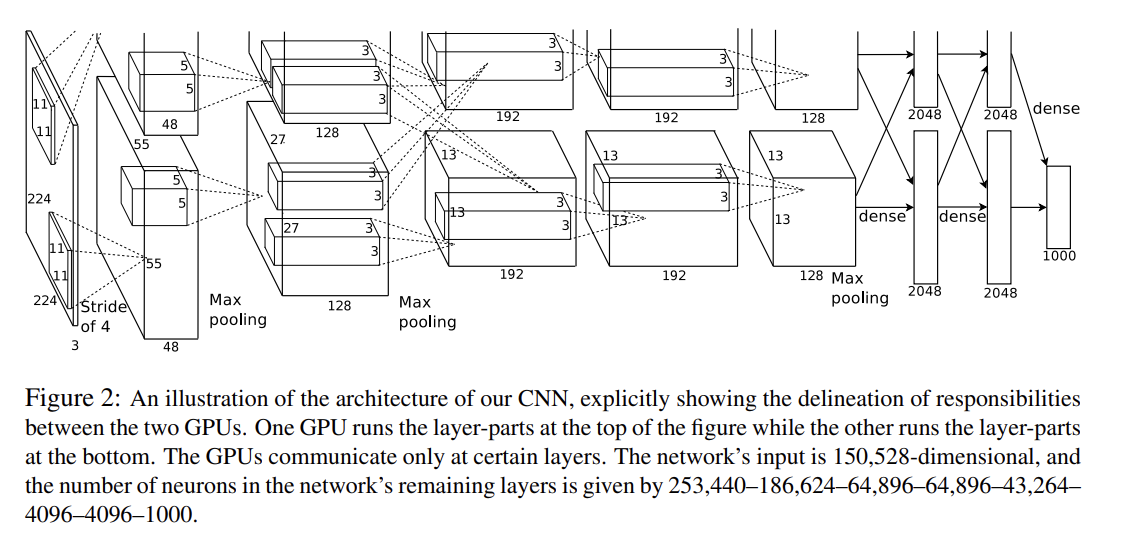
위의 사진이 AlexNet의 전체적인 구조이다.

각 layer의 세부사항은 위와 같다. 각 layer를 거치고 나서의 output size는 공식 을 사용해서 구했다. 예를 들어 Conv1을 거치고 나오면, 가 나오게 되어 55x55x96의 사이즈를 얻게 되는 것이다. AlexNet은 5개의 Conv layer와 3개의 FC layer로 이루어져 있다. LRN을 적용한 layer는 Conv1,2 이며, max pooling은 Conv1,2,5 이후 각각 적용했다. ReLU는 모든 neuron에 다 적용했다.
AlexNet architecture에서 중요한 것은 위에서도 말했듯이 GPU를 나누어 훈련을 진행한다는 것이다. 그 점이 위의 Architecture에도 나타나는 것을 볼 수 있다.
참고로, 논문에서는 224x224x3 크기의 input image를 사용했다고 하지만, 이는 잘못된 수치이고, 실제로는 227x227x3의 input image를 사용한 것이라고 한다.
3) Reducing Overfitting
논문의 network는 60million개의 parameter를 가진다. 이렇게 많은 parameter들을 overfitting을 억제하며 배우기에는 어려워보인다. 때문에 저자는 2개의 방법을 통해 Overfitting을 방지한다.
3.1) Data Augmentation
우리가 인공적인 방법으로 dataset의 크기를 키우는 것이다. 이미 가지고 있는 이미지를 좌우반전 시키는 방법과 RGB pixel에 PCA를 적용하는 방법을 사용해 augmentation을 한다. 이 결과, top-1 error rate가 1%이상 감소된다고 한다.
3.2) Dropout
Dropout은 랜덤한 확률(논문에서는 0.5)로 특정 neuron을 끄고 training을 진행해 overfitting을 방지하는 기법 중 하나이다. 꺼진 neuron은 training에 기여할 수 없으므로, network는 input이 주어질 때마다 다른 architecture로 학습을 진행한다. 이와 같은 방법은 neuron간의 co-adaptation을 줄여주는 효과를 준다. 훈련시에 0.5라는 확률로 neuron들을 꺼주었기 때문에 test time때는 output에 0.5를 곱해주는 방식으로 보상을 해준다. Dropout은 FC1, FC2에 적용한다.
여기서 드는 의문이 있다. 왜 Dropout은 FC layer에만 적용하고 CNN에는 사용하지 않을까? 찾아보니 크게 4가지의 이유가 있었다.
i) parameter의 대다수가 FC layer들에 몰려있다.
ii) CNN은 spacial informatiation을 담고 있기 때문에 dropout을 사용한다면 spacial information을 망치게 될 것이다.
iii) Dropout은 regularization 테크닉 중에 하나로 알려져 있는데, CNN에서는 local connectivity와 weight sharing으로 인해 이미 일종의 regularization이 이루어지고 있다고 한다.
iv) FC layer에 비해 CNN의 구조가 비교적 복잡해 FC layer에 dropout을 적용하기 편하다고 한다.
4) Details of learning
모델은 SGD + momentum의 방식을 사용했으며, momentum=0.9, batch size=128, weight decay=0.0005로 학습을 진행했다.
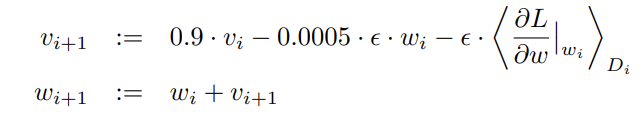
update rule은 위의 사진과 같았다. 은 learning rate를 뜻하고, 는 batch D_i에서의 편미분값의 평균을 뜻한다. 각 layer들의 weight들은 zero mean, standard deviation=0.01인 gaussian 분포에서 random하게 초기화했고, bias들은 Conv2,3,5, 그리고 FC layer들에서는 1로 초기화했고, 나머지 layer들에서는 0으로 초기화했다고 한다. 몇 개의 layer들을 1로 초기화해서 초기 학습에서 ReLU의 positive한 부분으로 input들을 유도하는 효과를 준다. learning rate는 0.01로 초기화했다.
5) Results
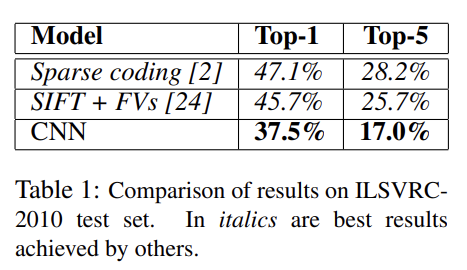
위의 사진은 ILSVRC-2010 dataset을 기반으로 얻은 top-1,5 error rate들이다. 위의 두 가지 기존 방식보다 CNN 모델이 좋은 성능을 내는 것을 알 수 있다.
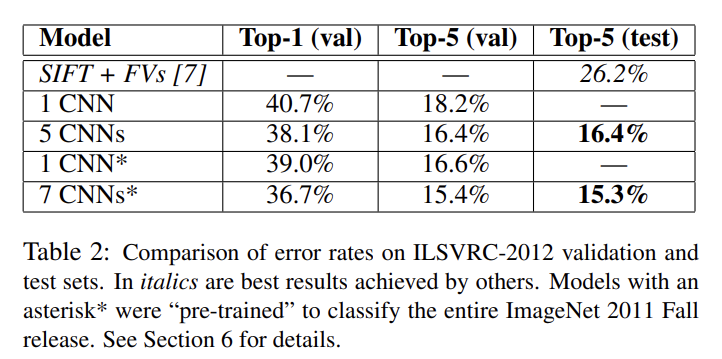
위의 사진은 ILSVRC-2012 dataset을 기반으로 얻은 top-1,5 error rate들이다. 각 모델이 어떻게 구성되어 있는지는 논문을 보면 나와 있지만, 주목할 것은 논문에서 주로 다루는 모델은 1 CNN이라고 쓰여있는 모델이다. 기존의 방식보다 더 좋은 성능을 내는 것을 확인할 수 있다.
6) Qualitative Evaluations

위의 filter들은 Conv1에서 배운 filter들을 출력해본 것이다. 위의 48개는 GPU1에서 학습한 것이고, 그 아래 48개는 GPU2에서 학습한 것이다. 자세히 보면, filter들은 oriented edge, color blob, 여러가지 frequency를 학습했음을 유추해볼 수 있다. 또, GPU1에서 나온 filter들은 색보다는 oriented edge들을 학습하는데 집중했고, GPU2에서 나온 filter들은 보다 color-specific하다. 이 결과는 weight initialization과는 관련이 없다.

위의 사진의 왼쪽 부분은 test image의 top-5 class들의 비율을 시각화한 것이다. mite 같이 중심에서 벗어난 object들도 잘 분류하는 것을 알 수 있다. 오른쪽의 사진의 가장 왼쪽 열은 test image들을 몇 개 뽑은 것이고, 그 왼쪽의 모든 열들은 Euclidean distance에 기반해서 최소 거리인 training set 내의 사진들을 출력한 것이다. 이때 거리는 마지막 layer에서 얻은 feature activation vector간의 거리로 측정했다. 두 사진의 feature activation vector의 Euclidean distance가 작으면 사진들이 비슷하다고 볼 수 있다. pixel level에서 보면, test image와 뽑힌 training set의 image들은 비슷하지 않다는 것 또한 알 수 있다.
3. 논문 내용의 실용성
이 논문은 딥러닝 열풍이 돌게 한 시초와도 같은 논문이기 때문에 중요한 의미를 갖는다. ILSVRC에서 처음으로 CNN기반의 네트워크를 이용해 우승한 모델이라는 것도 짚고 넘어가야 할 부분이다. Deep Neural Network의 overfitting 문제를 해결하고, 의미 있는 성능 개선 또한 이루었다는 점도 대단하게 느껴진다. 또한, GPU의 효과적인 사용을 제안했다는 점도 중요하다.
4. 찾아볼 레퍼런스
Dropout이 어떻게 이루어지는지 구체적으로 알고 싶어져서 Dropout 논문("Improving neural networks by preventing co-adaptation of feature detectors", Hinton et al., 2012)도 한 번 읽어봐야 할 것 같다. 아직은 논문을 많이 읽은 단계가 아니어서 GoogLeNet, VGGNet, ResNet 논문들도 읽으면서 CNN Architecture가 어떻게 변해갔는지에 대한 insight를 따라가야 가는 것도 해야 할 과제 중 하나이다.
