
- 전체보기(12)
- DeepLearning(2)
- 시계열데이터(1)
- muchinelearning(1)

선형대수 - 고유벡터와 고유값
행렬A 와 (1, 1)벡터를 계산하게되면 (8, 8)이라는 벡터가 나옴.이때 8은 Eigenvalues인 고윳값이되고, (1, 1)은 Eigenvector인 고유벡터가 나옴.(1, 1)라는 벡터가있을때, (8, 8)벡터를 보고 실수 k배를 한것을 복잡한 연산없이 알아낼

LabelImg로 라벨링 하기
이것은 Ubuntu 및 Fedora와 같은 최신 Linux 배포판에서 가장 간단한(단일 명령) 설치 방법입니다.Linux/Ubuntu/Mac에는 Python 2.6 이상이 필요하며 PyQt 4.8 에서 테스트되었습니다 . 그러나 Python 3 이상 및 PyQt5 를
맥북 m1 Conda 환경에 Tensorflow 설치하기
애플 사이트에서는 위와 같은 방법으로 Miniforge를 설치하도록 하고 있는데, 아래 11.0 이하처럼 brew를 사용해도 무방하다.Conda를 이용한다는 것은 가상환경을 이용한다는 것이니, Tensorflow를 설치할 가상환경을 만들어주자.패키지 관리자 Brew를

Back_Bone network(백본네트워크)
ackbone (백본)기업 전산망의 근간이 되는 네트워크를 연결시켜 주는 고속 통신망. 계층적 네트워크의 최상위 레벨로 중계 네트워크는 내부 접속을 보증받고 있다.일반적으로 네트워킹의 구조는 몇 가지 아키텍처가 지배하고 있다. 고성능 라우터주변에 모여든 분산(Distr

선형대수 - 선형변환
Domain (정의역) : 함수의 입력에 들어가는 모든 집합.Co-domain(공역) : target함수의 출력값 output의 집합.Image : 함수의 output.range(치역) : 수가 취하는 값 전체의 집합 공역에 대한 y의 부분집합.note : x 는 유니
비지도학습(Unsupervised Learning)에 대하여
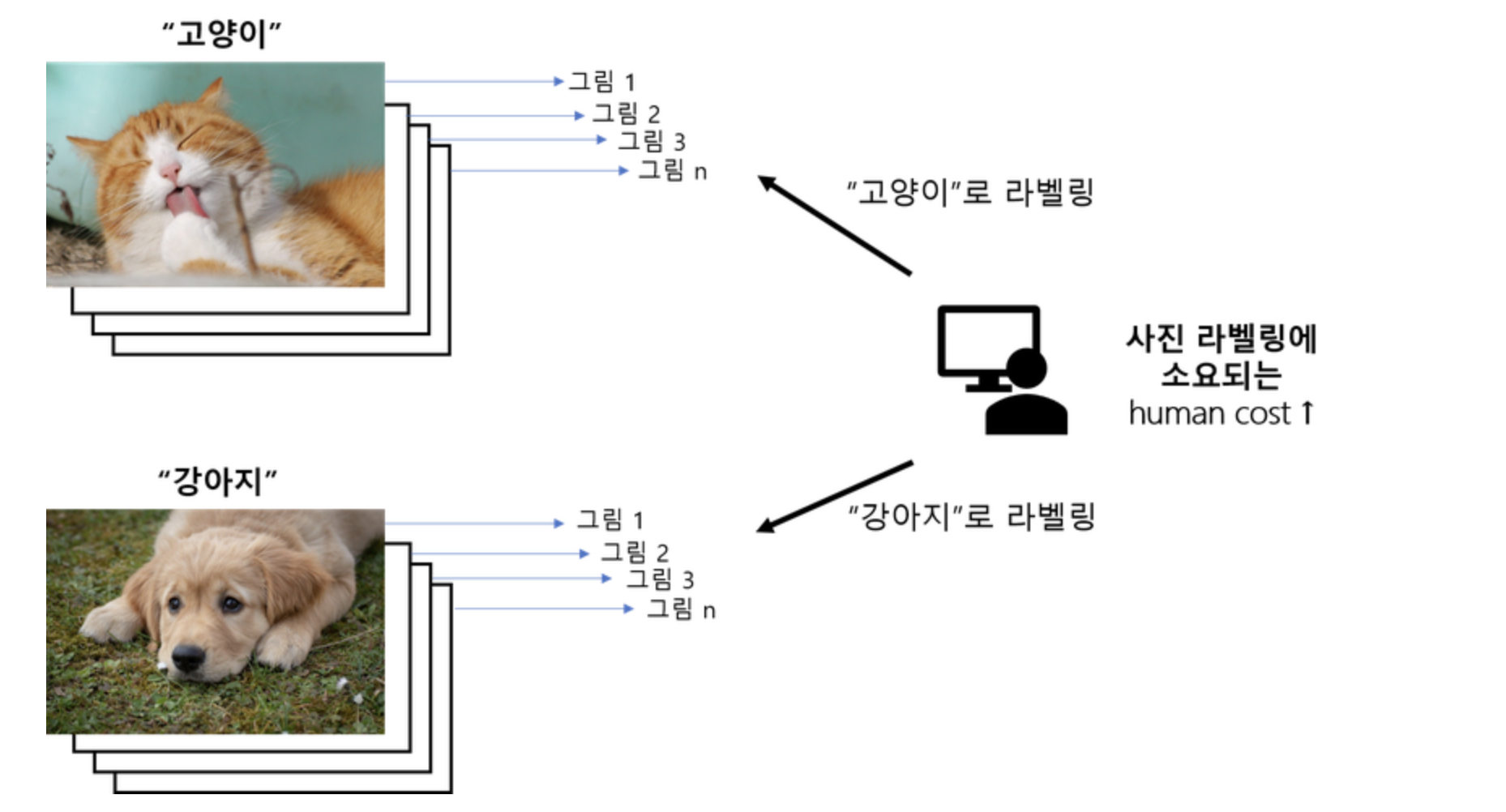
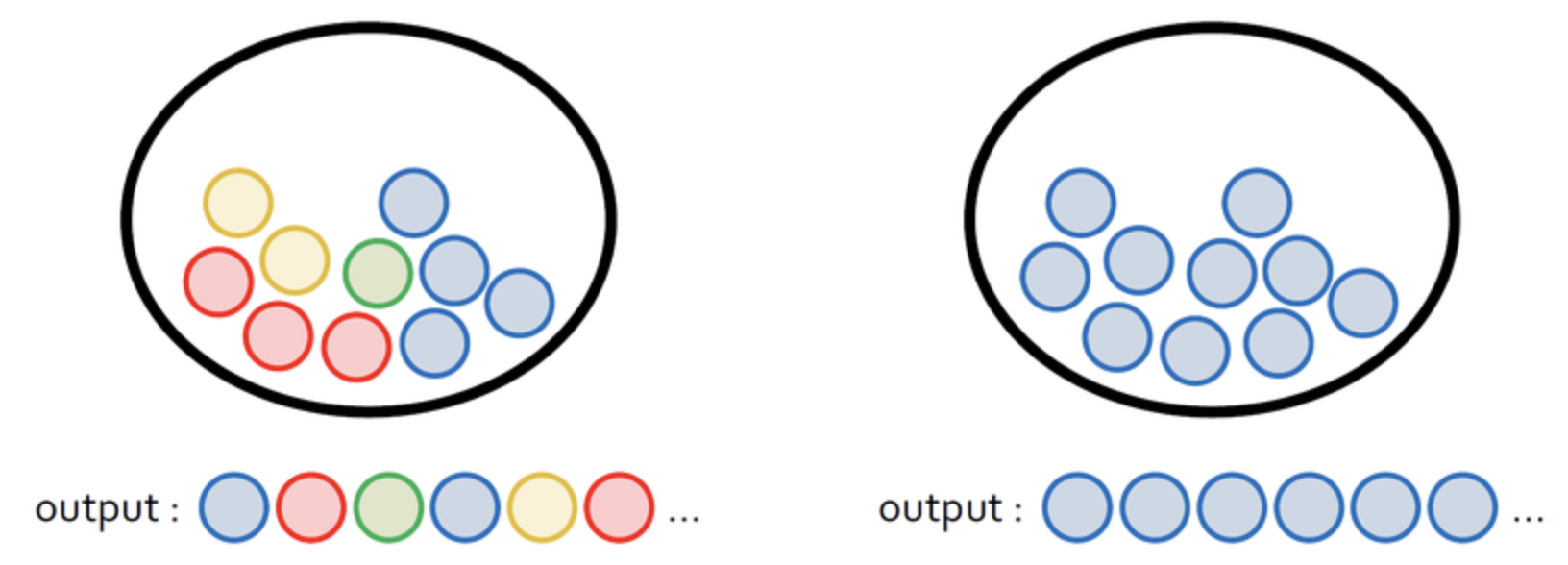
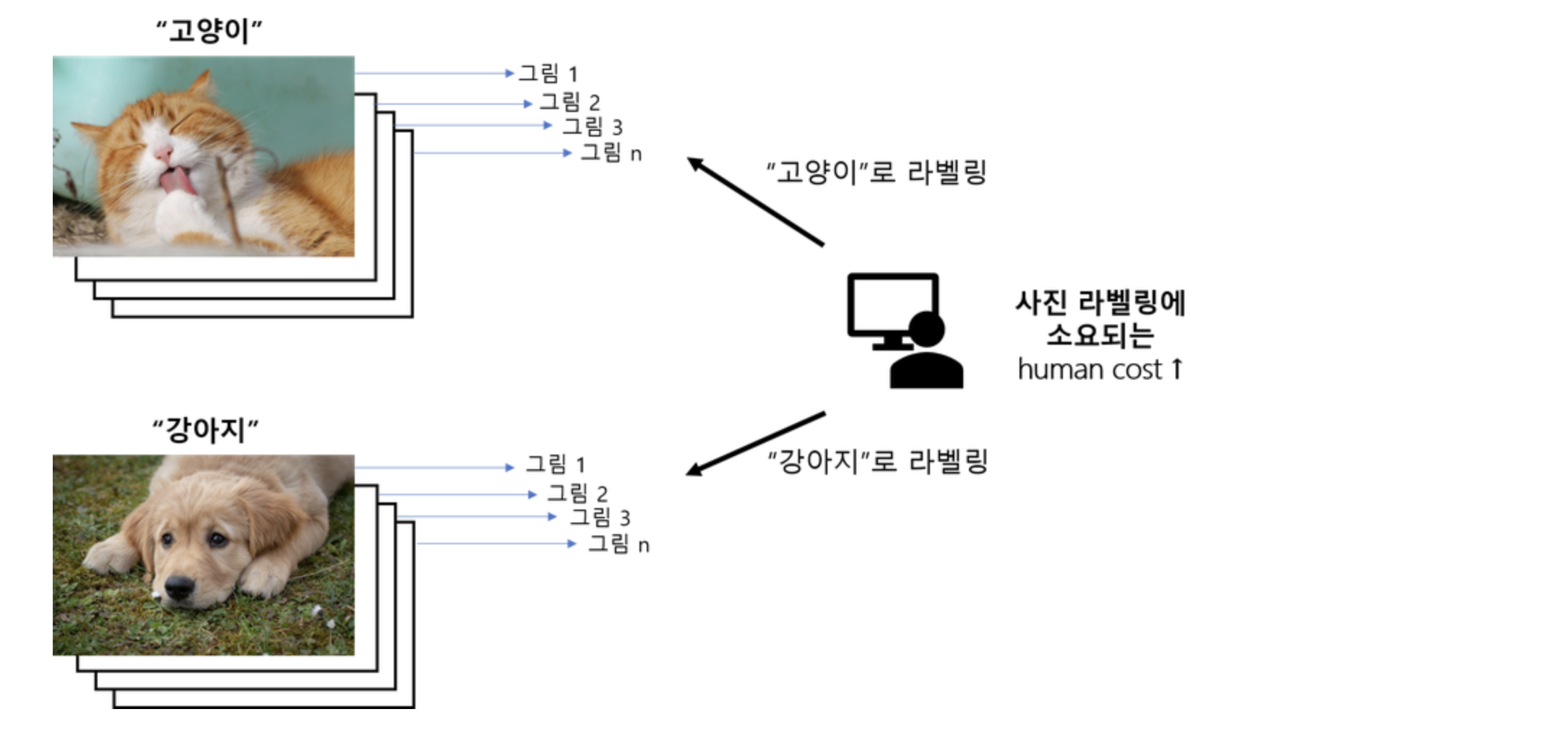
지도학습과 달리 training data로 정답(label)이 없는 데이터가 주어지는 학습방법을 말합니다.비지도학습은 주어진 데이터가 어떻게 구성되어 있는지 스스로 알아내는 방법이라고도 말할 수 있습니다. 아무도 정답을 알려주지 않은 채 오로지 데이터셋의 특징(feat
dicisiontree_entropy
Information ContentEntropyKullback Leibler DivergenceCross Entropy LossDecision Tree와 Entropy정보 이론(information theory)이란 추상적인 '정보'라는 개념을 정량화하고 정보의 저장과

Deeplearning_Detection
Object detection은 물체의 클래스를 분류(classification)할 뿐만 아니라 위치 측정 (localization)까지 함께 수행하는 작업입니다.Localization이란 이미지 내에 하나의 물체(Object)가 있을 때 그 물체의 위치를 특정하는 것

regulariztion OR normalization
Regularization : 정칙화오버피팅을 해결하기 위한 방법 중의 하나입니다.오늘 우리가 가장 중요하게 다룰 주제이기도 하죠.L1, L2 Regularization, Dropout, Batch normalization 등이 있습니다.이 방법들은 모두 오버피팅을 해
비지도학습(Unsupervised Learning)
jupyter_notebook에서 마크다운 image를 이용하려면 밑에 코드를 작성해줍니다.비지도학습(Unsupervised learning)이란,지도학습과 달리 training data로 정답(label)이 없는 데이터가 주어지는 학습방법을 말합니다.비지도학습은 주어

시계열 데이터분석(Time Series)
시간 : 특정 간격 갖는 시간 -Lag 에서 Data의 Trend를 찾는다. 일변량 정상시계열 -ARIMA Model Trend : 추세 - 데이터의 변화되어있는 모형 Seasonality : 계절성 - 주기에 따라 trend가 달라질