

이번에 리뷰할 논문은 Noise2Noise: Learning Image Restoration without Clean Data 라는 논문입니다. 본격적으로 해당 후속 연구인 Noise2Void 논문을 공부하기 앞서 Noise2Noise에 대한 이해를 수행한 다음 읽으면 더 이해가 잘 될 것 같아 해당 Noise2Noise: Learning Image Restoration without Clean Data 논문을 먼저 리뷰해보도록 하겠습니다.
결론적으로 먼저 해당 논문의 핵심 mechanism은 다음과 같습니다.
“Noise2Noise는 깨끗한 정답 이미지를 사용하지 않고, 동일한 장면으로부터 독립적인 노이즈가 더해진 두 관측값 중 하나를 입력으로, 다른 하나를 타겟으로 사용하여 모델 출력과 타겟 사이의 평균 제곱 오차를 최소화한다. 이때 노이즈가 평균 0이며 서로 독립이라는 가정 하에서, L2 loss의 특성에 의해 모델은 노이즈가 제거된 clean image로 수렴하게 된다.”
이제 본격적으로 논문 리뷰를 수행해보도록 하겠습니다.
Abstract
Noise2Noise(N2N)는 노이즈 이미지에서 깨끗한 이미지로 매핑하는 과정에서 기본적인 통계적 추론을 적용하였으며 이로 인해서 명시적인 Clean target images 없이도 Noisy images만을 보고도 Clean하게 복원이 가능합니다. 이때, 단순히 손상된 신호만을 가지고 복원했음에도 불구하고 Clean target image와 함께 학습한 Traditional한 기법들과 비교했을 때, 성능이 비슷하거나 때로는 능가하는 결과를 볼 수 있습니다. 실제로 N2N은 오로지 Noisy iamge만을 기반으로 사진에 있는 노이즈 제거 및 synthetic Monte Carlo images에서의 노이즈 제거, 언더샘플링된 MRI 스캔에서 노이즈를 제거하고 재구성하는 Task에서 활용 및 학습이 가능합니다.

Introduction
Signal reconstruction은 statistical data analysis 분야에서 중요한 분야입니다. 최근 딥러닝의 발전으로 인해서 Signal reconstruction은 단순히 전통적이고 명시적인 통계 모델링으로 처리하는 것이 아닌 Noisy image에서 깨끗한 image로 매핑하는 학습에 많은 관심을 불러왔습니다. Traditional기법으로는 손상된 입력과 깨끗한 타겟의 쌍을 대량으로 사용하여 회귀 모델, 예를 들어 컨볼루션 신경망(CNN)을 훈련함으로써 이루어집니다.(Noisy input image, Clean Target iamge)
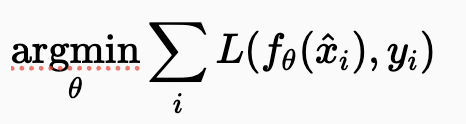
여기서 noisy input image는 Clean target image의 distribution을 따르고 있습니다. 즉, 노이즈 이미지와 깨끗한 타겟 이미지를 학습에 활용하면서 이들의 error를 최소화하는 방식으로 동작하고 있습니다. 더불어 옛날에는 Denoising을 Regression Task로 다뤘을 정도입니다. 이러한 기법을 활용해서 다양한 노이즈 제거 분야에서 많은 활용과 유의미한 결과를 가져왔습니다.
하지만 본 논문에서 제안하는 N2N의 경우, Clean Target iamge를 사용하는 것이 아니라 오로지 Noisy iamge pair만을 학습하여 Image Restoration 수행하려고 합니다. 해당 방식은 앞서 이야기 했듯이 통계적 모델이나 Clean image의 사전 정보가 필요 없으며 오로지 nosiy image의 쌍을 학습함으로 Clean target image의 특징들을 간접적으로 학습할 수 있습니다. 이를 통해서 노이즈를 통계적 모델링 하기 어려운 분야 혹은 Clean target image 쌍을 구하기 어려운 환경 속에서 해당 N2N은 유용하게 활용할 수 있음을 이야기하고 있습니다.
Theoretical Background
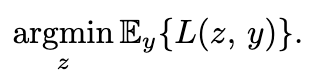
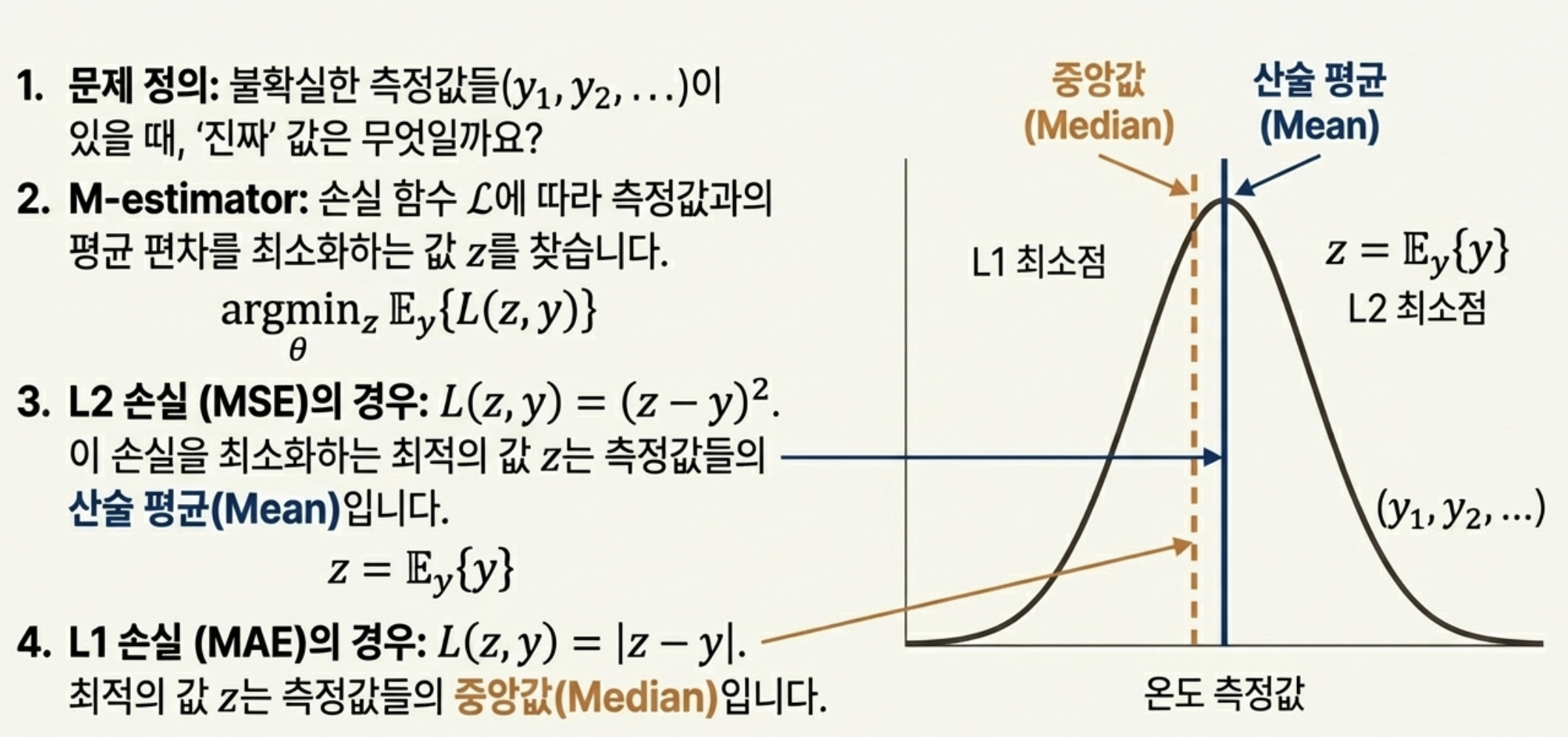
먼저 해당 수식은 최소화하는 z값을 찾는 것을 목표로 하고 있습니다. 이때, Loss function으로 크게 두 가지에 대해서 이야기하고 있습니다. 먼저 MAE(Mean Absolute Error)를 의미하는 L1 loss function, MSE(Mean Squared Error)를 의미하는 L2 Loss가 있습니다. 먼저 결론적으로 말씀드리자면 L1 Loss function을 활용하는 경우, 중앙값을 L2 Loss function의 경우, 평균값을 기대값으로 갖게 됩니다.
L2 Loss
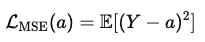
해당 위의 식을 전개 하면 아래와 같은 수식이 나오게 됩니다.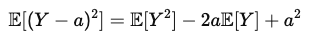
이때, 해당 수식은 흔히 저희가 알고 있는 2차 함수로 볼 수 있고 이를 미분해서 최소값을 찾기 위해서 미분 이후 이를 0으로 두면 바로 최소일 때 값이 바로 E[Y] 가 됨을 볼 수 있습니다.
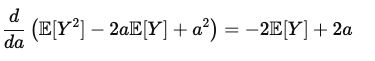
즉 , L2 Loss function에서 Globla minimum이 E[Y]가 되기 때문에 앞서 이야기했듯이 L2 Loss function은 기대값을 추정하게 된다고 설명했습니다.
L1 Loss
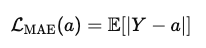
L1 Loss의 경우 위와 같은 식으로 설명할 수 있습니다.
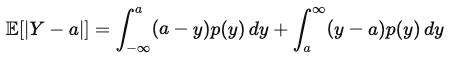
이때, 기대값을 구하기 위해서 이를 위와 같은 식으로 나타낼 수 있습니다. 이때, (a-y), (y-a)가 된 이유는 범위에 따라서 절대값으로 인해서 부호가 바뀌기 때문에 그렇습니다. 이후, 여기서 a에 대해서 미분을 수행하면 아래와 같은 수식이 나오게 됩니다.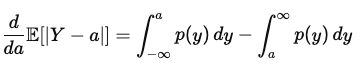
동일하게 해당 수식에서 저희가 관심이 있는 것은 바로 최소인 부분이기 때문에 이를 0으로 두고 수식을 풀어보면 다음과 같습니다.
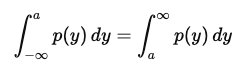
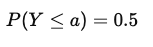
즉, L1 Loss를 활용하게 되었을 때에는 중앙값(Median)을 학습하게 됩니다.
이 두 Loss function은 서로 각각의 특징이 존재합니다. 먼저 L2 loss의 경우, 극단값이 제곱으로 인해서 강하게 작용하고 L1 loss의 경우, 선형적으로 반영이 되는 특징이 존재합니다. 해당 논문에서 활용하는 Loss function의 경우 주로 L2 loss를 활용하고 있습니다. 이는 동일한 장면에 대해 독립적으로 추가된 노이즈의 조건부 기댓값을 학습하여, 노이즈 평균이 0이라는 가정 하에서 clean image로 수렴하게 학습할 수 있기 때문입니다. 반면 L1 loss를 활용하는 경우는 L1(MAE) loss는 오차 분포가 평균이 아니라 ‘중앙값(median)’이 의미를 가질 때, 즉 outlier가 많거나 노이즈가 Laplacian/비대칭적인 상황에서 사용합니다. 즉, 뒤에서 나오게 되는 이미지 위에 글자와 같은 노이즈 즉, 스파이크 노이즈와 같은 경우에는 L1을 활용하게 됩니다.
이제 L2 loss를 기반으로 설명드리도록 하겠습니다. N2N은 이름에서도 알 수 있듯이 입력과 타겟 모두 Noisy image를 활용하게 됩니다. 모두 같은 위치의 픽셀을 비교하고 있으며 Clean image로부터 독립적인 노이즈가 더해져 쌍을 활용해서 학습에 활용합니다. 이때, 노이즈의 경우 평균은 0이며 서로 독립적이라고 가정을 하게 됩니다. 그렇다면 해당 논문에서 제안하는 Loss는 다음과 같은 수식이 되겠습니다.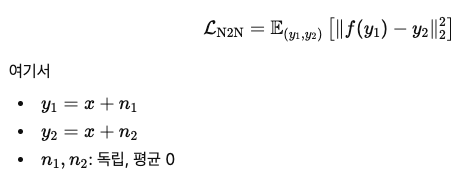
우리는 위에서 이미 L2 loss가 기대값이 평균을 의미하는 것을 확인할 수 있었습니다.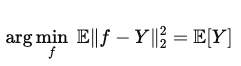
이를 저희가 흔히 아는 x와 y로 나타내면 다음과 같습니다.



예를 들어
y_1 = x + n_1으로 표현할 수 있고 총 4개의 관측이 있다고 했을 때,
y1 = 100 + 5 = 105
y2 = 100 - 4 = 96
y3 = 100 + 2 = 102
y4 = 100 - 3 = 97
이와 같다면 이들의 평균은 결론적으로 100이 됩니다. 즉, 노이즈는 사라지게 되고 원래 깨끗한 Signal이 남게 됩니다. 그렇기 때문에 “Noise2Noise는 깨끗한 정답 이미지를 사용하지 않고, 동일한 장면으로부터 독립적인 노이즈가 더해진 두 관측값 중 하나를 입력으로, 다른 하나를 타겟으로 사용하여 모델 출력과 타겟 사이의 평균 제곱 오차를 최소화를 수행하게 됩니다. 이때 노이즈가 평균 0이며 서로 독립이라는 가정 하에서, L2 loss의 특성에 의해 모델은 노이즈가 제거된 clean image로 수렴하게 됨을 확인할 수 있습니다.
Practical Experiments
이제 본 논문에서 제안하는 N2N을 실험을 통해서 검정을 하고자 합니다. 먼저, 간단한 노이즈 분포(가우시안, 포아송, 베르누이)로 시작하여, 훨씬 더 어렵고 해석적으로 다루기 어려운 문제인 몬테카를로 이미지 합성 노이즈에 대해서 검정을 하겠습니다. 이후에는 MRI의 나이퀴스트 스펙트럼 샘플링으로부터 검정을 해보도록 하겠습니다.
Additive Gaussian Noise
먼저, 가우시안 노이즈는 평균이 0인 노이즈 입니다. 해당 Task에서도 동일하게 L2 Loss를 활용해서 데이터터를 복원하고자 하며 손실 함수의 경우, 다음과 같습니다. 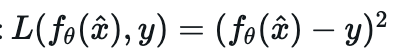
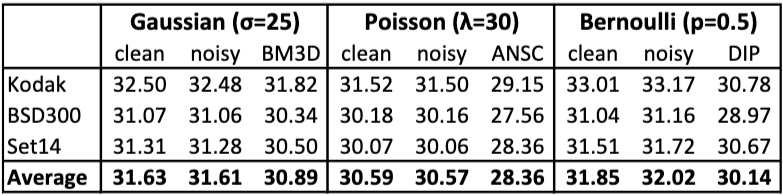
먼저, 선행 연구인 RED30을 활용하였습니다. 해당 모델은 30-layer의 Residual Network로 구성되어져 있습니다.이와 동시에 얕지만 훈련 속도를 10배 빠르게 하며 유사한 성능을 제공하는 U-Net 기반으로 전환하여 실험하였습니다. 학습에 활용한 데이터 셋은 IamgeNet의 Validation set을 활용하였으며 노이즈의 표준 편차는 [0, 50] 범위 내에서 무작위로 설정하여 수행했으며 노이즈의 크기는 모델의 학습 과정에서 제거하여 모델이 노이즈의 강도를 모르도록 학습하였습니다. 이후, KODAK, BSD300, SET14 데이터셋으로 성능을 평가했습니다.
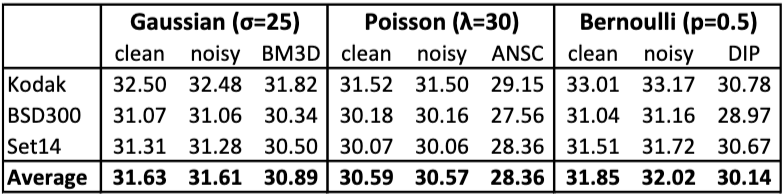
해당 실험에서 가장 중요한 점은 N2N이 Clean target image pair가 아닌 Noisy input image pair를 활용하여 훈련 했을 때, 이미지 복원 성능(PSNR)이 깨끗한 타겟으로 훈련했을 때와 거의 동일하게 우수했습니다 (예: KODAK 데이터셋에서 깨끗한 타겟 32.50 dB vs. 노이즈 있는 타겟 32.48 dB). 이는 기존 벤치마크인 BM3D보다 약 0.7 dB 더 나은 결과입니다.
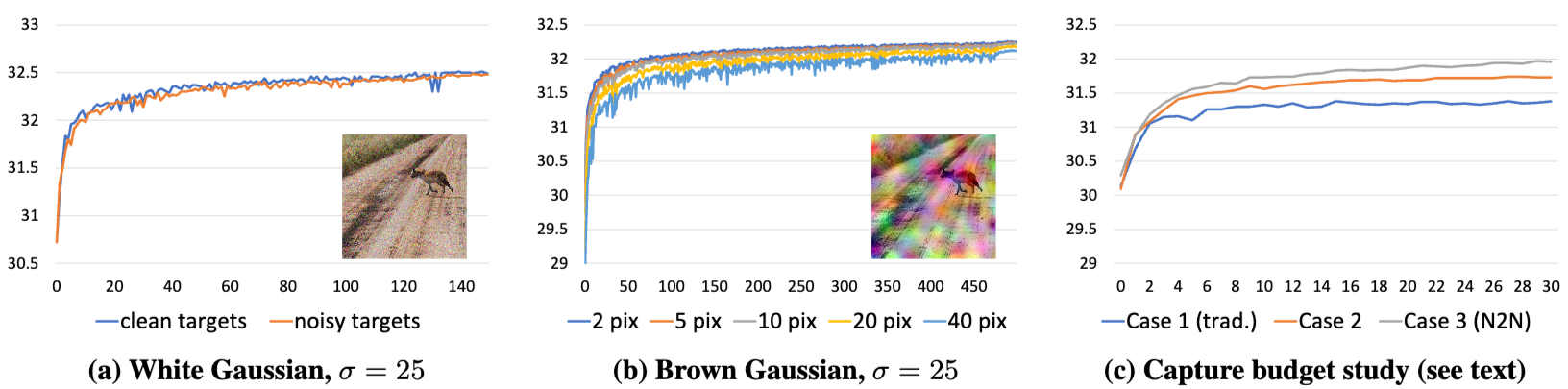
더불어 수렴 속도에 대해서 비교했을 때, 노이즈가 있는 타겟으로 훈련해도 수렴 속도는 Clean target image로 훈련할 때와 비슷했습니다. 이는 가우시안 노이즈가 독립 항등 분포(i.i.d.)를 가지기 때문에, 활성화(activation) 그래디언트는 노이즈가 많지만, 가중치(weight) 그래디언트가 다수의 픽셀에 대해 평균화되면서 상대적으로 깨끗해지기 때문이라고 이야기하고 있습니다. 이때, 픽셀 간 상관관계가 있는 Brown Gaussian noise를 도입했을 때, N2N의 수렴 속도가 느려졌지만, 최종 성능은 여전히 비슷했음을 확인할 수 있었습니다. 다음으로는 Capture budget에 대해서 확인해보도록 하겠습니다. 즉, 유한 데이터 및 캡처에서의 예산 연구이며 이를 위해서 제한된 데이터 상황을 시뮬레이션 하기 위해서 Capture Unit 개념을 도입하여 진행하였습니다. 먼저, Case1인 기존 방식은 100개의 Noisy input iamge와 이에 쌍을 이루는 Clean target iamge를 활용하여 훈련하였습니다. Case 2의 경우, 동일한 잠재 이미지(latent image)에 대해 노이즈 실현(noisy realizations)을 더 많이 사용하여 훈련 쌍의 수를 크게 늘렸을 때, 기존 방식보다 훨씬 좋은 결과를 보였습니다. Case 3의 경우, 더 많은 잠재 이미지를 사용하되, 각 이미지당 노이즈 실현 수를 줄여 훈련 쌍 수를 조절했을 때도 매우 좋은 결과를 보였습니다. 이를 통해서 유한한 데이터 환경에서 노이즈가 있는 이미지를 타겟으로 활용했을 때, 기존의 방식보다 더 나은 성능을 제공할 수 있음에 대해서 시사하고 있습니다.

순서대로 Ground truth, Input, Our, Comparison을 의미하고 있으며 해당 Comparison은 BM3D로 수행한 결과입니다.
Other Synthetic Noises
해당 실험은 N2N이 단순한 가우시안 노이즈가 아닌 다양한 유형의 합성 노이즈에 대해서도 효과적으로 동작하는디에 대해서 다루고자 합니다. 학습 성정은 이전에 수행한 가우시안 노이즈에 대한 연구와 동일하게 이어지고 있으며 평가 데이터셋으로는 KODAK, BSD300, SET14 데이터셋을 사용했습니다.
포아송 노이즈
먼저, 포아송 노이즈에 대해서 확인하고자 합니다. 포아송 노이즈의 경우, 사진에서 주로 발생하는 노이즈로, 신호에 따라 크기가 변하여 이들의 평균은 0입니다. 동일하게 해당 경우에도 손실 함수로 L2 loss를 활용하고자 합니다.
clean targets (노이즈 없는 원본 이미지)로 학습했을 때와 noisy targets (노이즈 있는 이미지)로 학습했을 때 PSNR 성능이 거의 동일합니다 (각각 30.59 dB, 30.57 dB). 더불어 학습 수렴 속도도 유사함을 확인 할 수 있었습니다. 더구나 기존 방법인 Anscombe transform(이는 포아송 노이즈를 가우시안 노이즈로 변환한 다음 BM3D로 Denosing)보다 더 높은 성능을 보입니다.

베르누이 노이즈
그 다음으로는 Multiplicative Bernoulli Noise, 베르누이 노이즈에 대해서 알아보도록 하겠습니다. 해당 연구에서는 유효한 픽셀은 1, 삭제되거나 누락된 픽셀은 0으로 무작위 마스크를 생성하여 노이즈를 주입합니다. 해당 연구에서는 조금 수정된 L2 loss를 활용합니다. 누락된 픽셀에서 역전파되는 기울기를 방지하기 위해 손실 계산에서 해당 픽셀을 제외하여 활용하고자 하며 수식은 다음과 같습니다.
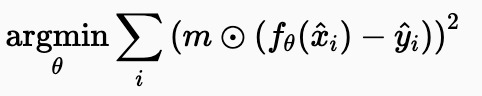
즉, 베르누이 노이즈 이미지를 복원 시, 손실된 픽셀로부터 그래디언트가 역전파되는 것을 방지하기 위해서 변형된 수식입니다. 여기서 m은 mask를 의미하며 이진 벡터를 의미합니다. 즉, 픽셀이 유효하다면 1로 손실 및 결측이라면 0으로 둬 손실된 픽셀의 위치를 표시합니다. 아다마르 곱 또는 element-wise 곱셉으로 마스크의 각 요소가 손실 값의 해당 픽셀에 곱해집니다. 정리하자면 m 마스크를 사용하여 결측(missing) 픽셀의 영향을 제거하는 것이 특징입니다. 일반적인 L2 손실은 모든 픽셀에 대해 예측값과 타겟값의 차이 제곱을 최소화합니다. 하지만 Bernoulli 노이즈의 경우, 일부 픽셀은 완전히 손실되어 아무런 정보도 담고 있지 않습니다. 이러한 픽셀에 대한 오차를 계산하고 역전파하는 것은 모델 학습에 방해가 될 수 있습니다.
따라서 마스크 mmmm을 곱함으로써, m이 0인 픽셀(즉, 손실된 픽셀)에 대해서는 오차 값이 0이 되어 해당 픽셀로부터의 그래디언트가 손실 함수에 영향을 미치지 않게 됩니다. 이는 신경망이 유효한(손실되지 않은) 픽셀에만 집중하여 학습하도록 유도합니다.

Text Removal (텍스트 제거)
이미지 위에 무작위로 문자열이 다양한 크기와 색상으로 중첩되어 노이즈가 더해진 상황입니다. 오버레이 된 텍스트 색상과 크기가 이미지와 무관하기 때문에 L2 loss를 사용하게 되면 평균값을 추정하기 때문에 텍스트로 인해서 이상치가 되고 이에 대해서 너무 큰 영향을 받기 때문에 L1 loss를 활용하여 픽셀이 원본 색상을 유지할 수 있도록 선형적으로 반영하여 median을 활용하게 됩니다. 그렇기에 L1 loss를 통해 임의의 텍스트 오버레이를 성공적으로 제거하며, L2 loss와 달리 이미지의 평균 텍스트 색상으로 치우치지 않고 원본 이미지를 잘 복원한 것을 확인할 수 있었습니다.

Random-valued impulse noise
다음으로는 임펄스 노이즈에 대해서 다뤄보도록 하겟습니다. 일부 픽셓을 무작위 색상으로 교체하여 각 픽셀의 색상 분포는 워본 색상에서의 Dirac 델타 함수와 무작위 균일 분포와 혼합으로 구성합니다. 해당 임펄스 노이즈의 경우, L2 loss를 활용하여 평균을 활용하든가 L1 loss를 활용하여 중앙값을 활용하든 모두 올바른 복원 결과를 제공하지 못합니다. 이러한 상태에서 새로운 손실 함수를 정의하게 되고 결과적으로 해당 손실 함수는 최빈값(mode)을 추정하는 것을 목표로 합니다. 즉, 가장 빈번하게 나타나는 원래 픽셀 색상을 찾는 것입니다.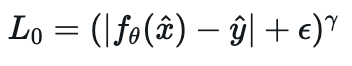

논문의 부록을 보시게 되시면 해당 L0 loss가 최빈값을 의미하는 것은 아닙니다. L0 손실 함수가 수학적으로 최빈값을 정확히 찾는 것이 아니라, 최빈값과 관련된 분포의 힐베르트 변환(Hilbert transform)의 영점(zero-crossing)을 찾는다고 설명합니다. 하지만 실제 실험에서는 이 방법이 최빈값에 매우 근접한 결과를 제공하는 것으로 나타났습니다. 이는 임펄스 노이즈 상황에서 원래 픽셀 값을 효과적으로 복원하는 데 이 손실 함수가 유용함을 의미합니다.
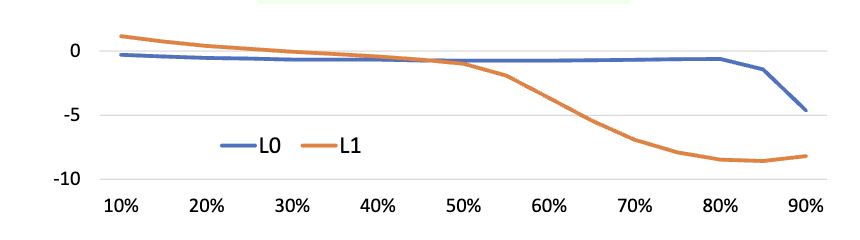
이 그래프는 "Random-valued impulse noise"에 대해 L0 및 L1 손실 함수를 사용하여 노이즈가 있는 타겟 이미지로 네트워크를 학습했을 때, "깨끗한(clean) 타겟 이미지"로 학습했을 때와 비교하여 PSNR(Peak Signal-to-Noise Ratio)이 얼마나 변화하는지 보여줍니다.
X축 (가로축): 타겟 픽셀이 무작위 RGB 임펄스 노이즈에 의해 손상된(corrupted) 비율을 나타냅니다. 10%부터 90%까지 변화합니다.
Y축 (세로축): "깨끗한 타겟 이미지"로 학습했을 때의 PSNR과 비교한 PSNR 변화량(dB)입니다.
값이 0에 가까울수록 노이즈가 있는 타겟 이미지로 학습한 결과가 깨끗한 타겟 이미지로 학습한 결과와 유사하다는 것을 의미합니다. 값이 음수이면 깨끗한 타겟으로 학습한 것보다 성능이 떨어진다는 것을 의미합니다.
L1 loss의 경우, 손상 비율이 50%를 초과하면서 PSNR이 급격히 감소하는 것을 볼 수 있습니다. 이는 L1 loss이 50% 이상의 노이즈에는 취약하며, 이미지를 회색 쪽으로 편향되게 만들 수 있기 때문입니다. 이는 원본 텍스트 제거 실험(Figure 3)에서도 설명되었듯이, 중앙값을 찾는 L1 loss의 특성 때문입니다.
L0 loss은 노이즈가 있는 타겟 이미지로 학습했음에도 불구하고 거의 모든 손상 비율에서 깨끗한 타겟 이미지로 학습했을 때와 유사한 성능(PSNR delta가 0에 매우 가깝거나 약간의 변동만 있음)을 유지하는 것을 보여줍니다. 특히, 50%를 초과하는 극심한 노이즈 상황(예: 90% 손상)에서도 L1 loss에 비해 훨씬 안정적인 성능을 보입니다. 이는 실제 픽셀 값이 여전히 가장 흔한(최빈값) 분포이기 때문에 L0 loss이 효과적으로 작용할 수 있음을 의미합니다.
즉, N2N은 크게 두가지의 장점을 제공합니다.
다양한 노이즈 유형에 대한 강건성: 적절한 손실 함수(여기서는 L0)를 사용하면 매우 높은 수준의 무작위 임펄스 노이즈가 있는 데이터에 대해서도 깨끗한 데이터를 사용한 학습에 필적하는 성능을 달성할 수 있습니다.
학습 데이터 확보의 용이성: 깨끗한 이미지를 확보하기 어려운 실제 시나리오에서, 노이즈가 있는 이미지만으로도 효과적인 이미지 복원 모델을 훈련할 수 있다는 점을 입증합니다.

Monte Carlo Rendering
Monte Carlo Rendering이란 가상 환경에서 물리적으로 정확한 이미지를 생성하는 기술입니다. 광원과 가상 센서를 연결하는 무작위적인 Light paths를 샘플링하여 픽셀의 강도를 계산합니다. 각 픽셀의 강도는 이 무작위 샘플링 과정의 기대값이므로, 샘플링 노이즈의 평균은 0이 됩니다. Monte Carlo Rendering의 노이즈 제거는 크게 3가지 측면에서 어렵습니다. 먼저, 복잡하고 비정상적인 분포로 MC 노이즈는 픽셀마다, 장면 구성마다, 렌더링 파라미터마다 분포가 매우 복잡하며 임의로 다중 모드일 수도 있습니다. 특정 조명 효과는 매우 긴 꼬리를 가진 분포와 흔하지 않은 밝은 이상치를 유발합니다. 더불어 가우시안 노이즈처럼 수학적으로 분석하여 특성화하기 어려운 문제점도 함께 존재합니다. 다음으로 HDR(High Dynamic Range) 문제가 있습니다. 이는 렌더링된 이미지의 휘도 값이 매우 넓은 범위를 가질 수 있습니다.
위와 같은 문제점으로 인해서 loss를 L2 loss로 활용하게 되면 이미지 내의 밝은 이상치에 의해서 학습이 수렴하지 않을 수도 있습니다. 더불어 tone mapping 연산은 비선형적이기 때문에 보조 정보와 함께 HDR 손실 함수를 따로 설계해야 합니다. 이 때 보조 정보로 denoiser의 입력으로 단순히 픽셀 휘도 값뿐만 아니라, 평균 알베도(albedo, 표면 색상)와 각 픽셀에서 보이는 표면의 법선 벡터(normal vector) 같은 보조 정보를 함께 사용하게 되며 손실함수의 경우 다음과 같습니다.
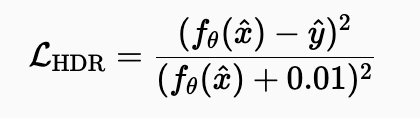
이와 함께 tone mapping 전략으로 입력 이미지에만 톤 매핑을 적용하고, 네트워크는 톤 매핑되지 않은(선형 스케일) 휘도 값 v를 출력하도록 학습하여 기대값의 정확성을 유지합니다.
이러한 Monte Carlo Rendering에서 N2N은 깨끗한(clean) 이미지를 생성하는 비용이 매우 높기 때문에 (예: 131k spp 이미지는 40분 소요), 노이즈가 있는 타겟 이미지를 사용하는 Noise2Noise 학습 방식이 매우 효율적임을 보여줍니다. 실험 결과를 보면 Noise2Noise는 깨끗한 타겟을 사용하는 방식과 유사하거나 (약 0.5dB 차이) 심지어 더 나은 성능을 보여주며, 특히 학습 데이터 생성 속도 면에서 2000배 이상 빠르다는 장점을 강조합니다. 이러한 효율성은 제한된 데이터 예산 내에서 더 많은 '노이즈 샘플(noisy realizations)'을 확보하여 학습할 수 있게 합니다.
즉, N2N은 노이지 이미지의 쌍으로 통계적으로 분석하기 어려운 복잡한 노이즈에서도 효과적으로 적용시킬 수 있습니다.

Tone mapping의 경우, Target에 적용하는 경우 오히려 성능 저하에 영향을 미치며 Noisy Input image에 활용하는 것이 더 좋은 전략입니다.

MRI Restoration
Noise2Noise 학습 방식이 자기공명영상(MRI) 재구성 문제에 어떻게 적용될 수 있는지를 설명합니다. 핵심 아이디어는 손상된(노이즈가 있는) MRI 데이터만을 사용하여 노이즈 없는 이미지를 재구성하는 방법을 학습할 수 있다는 것입니다.
MRI 영상의 원리의 경우, MRI는 생체 조직의 부피 이미지(volumetric images)를 생성하며, 이는 기본적으로 신호의 푸리에 변환(k-space)을 샘플링하여 얻어집니다. 최신 MRI 기술은 속도를 높이기 위해 종종 압축 센싱(Compressed Sensing, CS)을 사용합니다. 이는 k-space의 일부만을 샘플링(undersampling)하고, 이미지의 희소성(sparsity)을 활용하여 비선형 재구성을 통해 왜곡(aliasing)을 제거하는 방식입니다.
먼저, 신경망이 노이즈가 있는 입력 이미지를 받아 예측한 출력 이미지를 푸리에 변환합니다. 이 푸리에 변환된 결과는 이미지의 주파수 정보를 담고 있는 'k-space' 형태입니다. 여기서 중요한 단계는 'R'로 표시된 부분인데, 이것은 입력 이미지를 통해 이미 샘플링되어 우리가 알고 있는 주파수 정보(즉, 0이 아닌 값들)를 신경망의 푸리에 변환된 결과에 '대체'하는 연산입니다. 이는 신경망이 아무리 잘 예측하더라도, 이미 측정된 신뢰할 수 있는 주파수 값은 절대로 바꾸지 않고 그대로 유지하도록 강제하는 역할을 합니다. 즉, 이미 알고 있는 사실은 반드시 보존하면서 학습하도록 지시하는 것입니다. 이렇게 보정된 주파수 정보를 다시 역 푸리에 변환하여 이미지 형태로 되돌립니다. 마지막으로, 이렇게 보정된 재구성 이미지와 다른 독립적인 언더샘플링을 통해 얻은 노이즈가 있는 타겟 이미지 사이의 차이를 계산하고, 이 차이의 제곱을 최소화하는 방향으로 신경망을 학습시킵니다.
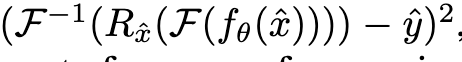
요약하자면, 이 손실 함수는 신경망이 재구성 과정에서 이미 확보된(샘플링된) 데이터의 정확성을 철저히 지키면서, 누락된 정보를 통계적으로 가장 타당한 방식으로 채워 넣도록 유도함으로써 노이즈가 있는 데이터만으로도 고품질의 MRI 이미지를 효과적으로 복원할 수 있게 합니다.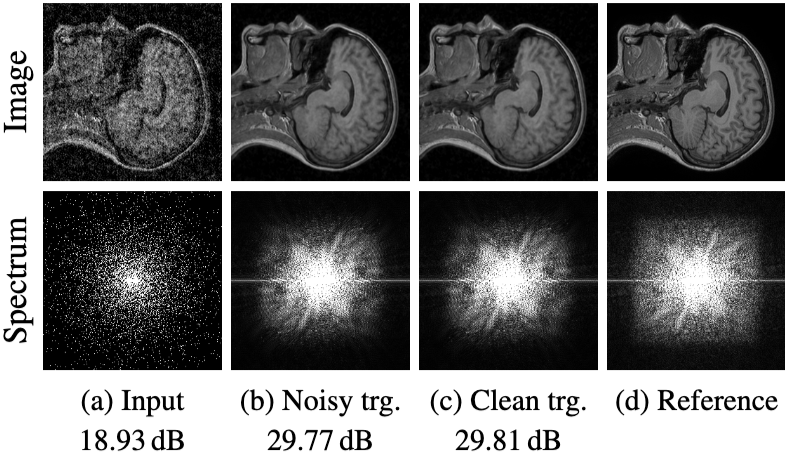
Conclusion
본 논문은 간단한 통계적 추론을 통해 딥러닝 기반 신호 복원(signal recovery) 분야에 새로운 가능성을 제시합니다. 가장 중요한 결론은 복잡한 노이즈(corruptions)가 있는 신호도 clean data(깨끗한 원본 데이터)를 관찰하거나 노이즈에 대한 명시적인 통계적 특성(explicit statistical characterization)을 알 필요 없이 복원할 수 있다는 것입니다. 심지어 clean target data를 사용한 학습과 동일하거나 그 이상의 성능을 달성할 수 있습니다. 이는 값비싸거나 어려운 clean data 수집의 필요성을 없애주어 많은 응용 분야에서 상당한 이점을 제공합니다.
해당 논문은 깨끗한 신호와 노이즈 신호를 쌍으로 수집하기 어려운 경우와 보다 더 복잡한 노이즈에서 적합한 loss를 설계하여 깨끗한 신호 없이 독립적인 노이즈 신호를 통해서 깨끗한 신호를 만들어낼 수 있는 것이 가장 큰 의의라고 생각합니다.
하지만 Noise2Noise는 clean image를 요구하지는 않지만, 동일한 underlying clean image에 독립적인 노이즈가 더해진 noisy image 쌍을 필요로 하며, 이러한 데이터 조건은 많은 실제 응용 환경에서 충족되기 어렵운 한계점을 같습니다. Noise2Void는 이 한계를 극복하기 위해 single noisy image만으로 완전한 single-image self-supervised denoising이 가능하도록 하였습니다. 하지만, 여기서 중요한 문제점이 발생합니다. 입력과 타겟이 같은 이미지라면 모델이 그냥 Identity를 배우게 되며 노이즈는 전혀 제거되지 않습니다. 즉, 예측하려는 픽셀은 입력에서 보지 못하게 막기 위해서 중앙 픽셀을 제거하고 주변 픽셀로만 입력하여 중앙 픽셀을 타겟으로 사용하는 SSL의 pretext task 문제로 학습을 수행하게 됩니다.
이상 N2N paper Review를 마치도록 하겠습니다!!
감사합니다!
