
프로그래머스 - 퍼즐 게임 챌린지 (그런데 OOP를 곁들인)
이 글의 풀이는 효율보다는 객체 지향적 코드 작성에 의의를 두고 작성한 풀이입니다. 실제 업무에서 유지보수 및 개선을 염두하는 느낌으로 작성했습니다. 그리고 문제에서 보장한 입력 조건에 대해선 검증을 하지 않습니다. 질문과 피드백은 언제나 환영합니다! 문제: 퍼즐 게
프로그래머스 - 동영상 재생기 (그런데 OOP를 곁들인)
이 글의 풀이는 효율보다는 객체 지향에 의의를 두고 작성한 풀이입니다.실제 업무에서 유지보수 및 개선을 염두하는 느낌으로 작성했습니다.그리고 문제에서 보장한 입력 조건에 대해선 검증을 하지 않습니다.질문과 피드백은 언제나 환영합니다!문제 링크: https://
코테 리팩토링) [3차] 방금그곡
목표기존에 푸는데만 집중했던 문제들을 클린 코드, 객체 지향 방식으로 리팩토링완벽한 효율보다는 다양한 스타일로 작성코테 문제) https://school.programmers.co.kr/learn/courses/30/lessons/17683네오는 자신이 기억한
코테 리팩토링) 할인 행사
목표기존에 문제를 푸는데만 집중해서 풀었던 문제들을 클린 코드, 객체 지향 방식으로 리팩토링완벽한 효율보다는 다양한 스타일로 작성코테 문제) https://school.programmers.co.kr/learn/courses/30/lessons/131127정현
코테 리팩토링) 문자열 압축
목표 기존에 문제를 푸는데만 집중해서 풀었던 문제들을 클린 코드, 객체 지향 방식으로 리팩토링 완벽한 효율보다는 다양한 스타일로 작성 문제 코테 문제) https://school.programmers.co.kr/learn/courses/30/lessons/60057
코테 리팩토링) 디펜스 게임
목표기존에 문제를 푸는데만 집중해서 풀었던 문제들을 클린 코드, 객체 지향 방식으로 리팩토링완벽한 효율보다는 다양한 스타일로 작성코테 문제) https://school.programmers.co.kr/learn/courses/30/lessons/142085준호
Python Multiprocessing
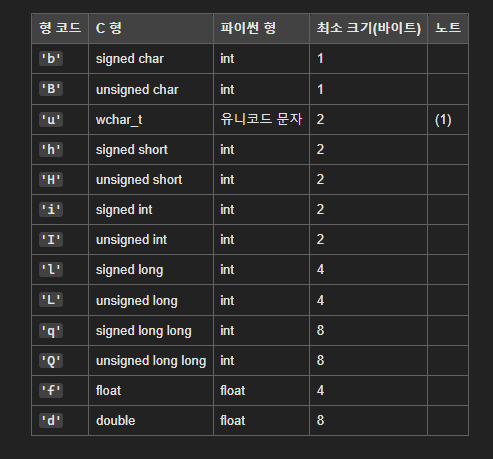
Process, Thread 차이 독립된 메모리(프로세스), 공유메모리(스레드) 많은 메모리 필요(프로세스), 적은 메모리(스레드) 좀비(데드)프로세스 생성 가능성, 좀비(데드) 스레드 생성 쉽지 않음 오버헤드 큼(프로세스), 오버헤드 작음(스레드) 생성/소멸 다소 느
Python Threading
파이썬 threading 정리 logging 활용 기본적으로 스레드는 디버깅이 어렵기 때문에 logging을 통해 실행 과정을 잘 표현하는 것이 중요하다. >#### 로그 레벨 DEBUG: 가장 낮은 레벨. 상세한 정보를 기록할 때 사용 INFO: 일반적인 정보를
Descriptor
객체의 속성에 대한 접근을 제어하는 메커니즘을 뜻한다. 기본적으로 디스크립터는 클래스의 속성에 대한 접근을 커스텀하게 제어할 수 있는 특별한 종류의 객체이다. 디스크립터를 통해서 개발자는 속성에 접근하거나 속성을 설정할 때 특정 코드를 자동으로 실행시킬 수 있다.디스크
Meta Class
메타클래스는 클래스의 클래스라고 표현한다.보통 클래스는 인스턴스를 생성하는 방법을 정의하는 것처럼 템플릿같은 용도로 사용한다.메타클래스는 그 대상이 클래스가 된다고 생각하면 된다. 클래스가 어떻게 생성되고 동작할 지 정의하는 역할을 한다. 기본적으로 모든 파이썬 클래스
Method Overloading (Type Checking)
오버로딩은 메소드 간 파라미터의 수, 타입, 순서에 의해 동일 이름의 여러 함수를 사용하는 개념이다. 이런 동작이 어떻게 가능한지 알려면 Type Checking에 대해 알고 넘어가야 한다.컴파일 시간에 타입 검사프로그램이 실행되기 전에 컴파일 시간에 변수의 타입 검사
Method Overriding
자식 클래스가 부모 클래스로부터 상속받은 메소드를 재정의(override)하는 것을 의미한다.이 때 자식 클래스는 상속받은 메소드와 동일한 이름, 매개변수를 가지지만, 구체적인 실행 내용은 변경할 수 있다.확장성 (Extensibility): 자식 클래스는 부모 클래스
Context Manager & Decorator
OS가 사용할 수 있는 자원은 한정되어 있기에 우리는 할당을 받았다면 다시 돌려줘야 원활한 자원 순환이 가능하다.간단하게는 다음과 같은 코드가 있다.이렇게 file.close()를 해서 자원을 돌려줘야 OS는 다시 자원을 다른 곳에 할당해줄 수 있다.흔히 사용하는 다음
mutable & immutable / Shallow & Deep copy
파이썬에서 선언을 할 때 기본 원리를 알아야 참조에 대한 실수가 없다.
Lambda, Map, Filter
파이썬은 데이터 분석과 파일을 읽는 등의 Sequence데이터를 자주 다루게 된다.이러한 데이터들을 핸들링하기 좋은 함수들에 대해 잘 알아두면 좋다는 것을 느낀다.lambda는 일회성 함수로 여겨지고 재사용할 함수가 아니라면 선언하는 편이다.힙 영역에서 사용 즉시 소멸
Variable scope
파이썬을 사용하다보면 함수를 정말 많이 만들게 된다. 특히 협업할 때는 수행할 일을 명확하게 전해주기 위해 인풋과 아웃풋을 알려주고 그것을 수행하는 함수를 작성하게 된다.이렇게 함수를 작성하다보면 변수 영역이 상당히 중요하다. 전역 변수인지, 로컬 변수인지, 데코레이터
배치 서빙
배치 서빙 머신러닝 모델을 사용하여 한 번에 대량의 데이터에 대해 예측을 수행하는 과정 데이터,모델 저장소에서 배치 서빙 파이프라인에 넣어주고 이를 통해 예측값을 얻는다. 데이터 저장소의 데이터는 주로 특정 시간 단위로 모아진 데이터와 같이 같은 종류, 다른 환경에서
모델 저장소
모델 저장소: 학습이 완료된 모델을 저장하는 장소 실험 관리+파일: 학습 데이터, 패키지, 파라미터 등을 함께 저장 MLflow 아키텍쳐 Backend Store (Remote host) 수치 데이터와 MLflow 서버의 정보들을 체계적으로 관리하기 위한 DB 저장
데이터 관리
머신러닝을 학습시킬 때의 데이터와 현실에서의 데이터는 차이가 있다.데이터를 학습하는 동안에도 현실의 데이터 분포가 바뀐다.학습한 모델을 서비스하는 동안에도 현실의 데이터 분포가 바뀐다.컨셉 드리프트(Concept Drift)예측 모델이 학습한 대상 변수의 조건부 분포가