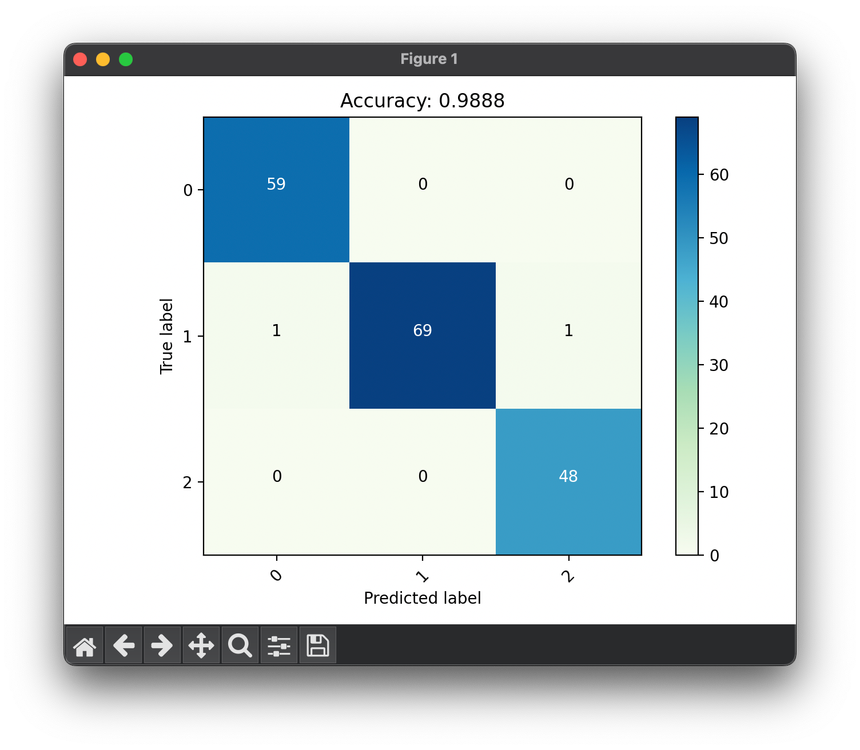
Accuracy
Introduction
Accuracy is one of the most intuitive and widely used performance metrics for evaluating classification models in machine learning. It measures the proportion of true results (both true positives and true negatives) among the total number of cases examined. To put it simply, it answers the question: "Of all the predictions made by the model, how many of them were correct?"
Background and Theory
Accuracy is defined mathematically as the ratio of correctly predicted observations to the total observations. This metric is most useful in binary and multiclass classification problems, where the goal is to predict which of two or more classes a given data point belongs to.
The formula for accuracy is given by:
where:
- (True Positives) is the number of positive instances correctly classified,
- (True Negatives) is the number of negative instances correctly classified,
- (False Positives) is the number of negative instances incorrectly classified as positive,
- (False Negatives) is the number of positive instances incorrectly classified as negative.
Procedural Steps
To calculate the accuracy of a machine learning model, follow these steps:
- Model Prediction: Generate predictions using the machine learning model for the dataset you have.
- Confusion Matrix Computation: Create a confusion matrix by comparing the actual labels with the predicted labels. This matrix will help in identifying , , , and .
- Calculate Accuracy: Use the formula for accuracy to compute the metric.
Mathematical Formulation
Given the elements of a confusion matrix, accuracy can be mathematically formulated as:
This formula highlights the simplicity of accuracy as a metric, focusing solely on the proportion of correct predictions.
Applications
Accuracy is used across a wide range of classification tasks in machine learning, including but not limited to:
- Medical diagnosis
- Spam detection
- Image classification
- Sentiment analysis
Strengths and Limitations
Strengths
- Intuitiveness: Accuracy is straightforward to understand and interpret, making it accessible to people with non-technical backgrounds.
- Broad Applicability: It can be applied to any classification problem without the need for modification.
Limitations
- Imbalanced Classes: In cases where class distributions are highly imbalanced, accuracy can be misleading. For example, in a dataset where 95% of the instances are of one class, a naive model that always predicts the majority class will have a high accuracy of 95% despite not having learned anything meaningful.
- Lack of Detail: Accuracy does not distinguish between types of errors. It treats false positives and false negatives equally, which may not be appropriate for all applications.
Advanced Topics
For a more nuanced understanding of model performance, especially in cases of imbalanced datasets, other metrics like Precision, Recall (Sensitivity), F1 Score, and ROC-AUC are often used in conjunction with, or in place of, accuracy.
References
- Powers, David M. W. "Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation." Journal of Machine Learning Technologies 2.1 (2011): 37-63.
- Fawcett, Tom. "An introduction to ROC analysis." Pattern recognition letters 27.8 (2006): 861-874.
