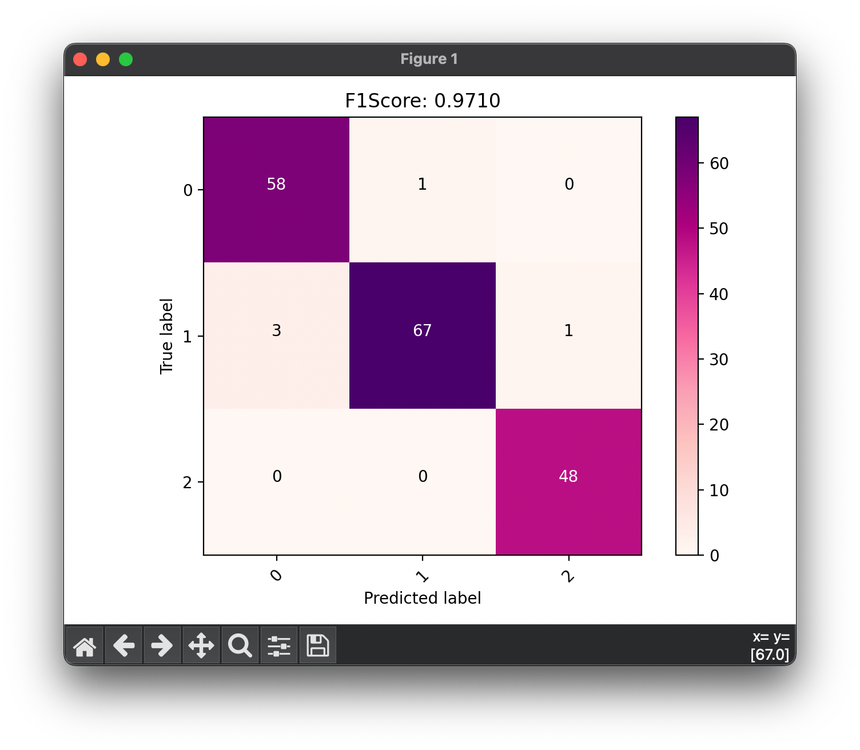
F1 Score
Introduction
The F1 Score is a widely used metric for measuring a model's accuracy on datasets where true negatives don't matter as much, blending the considerations of precision and recall into a single measure. It's particularly useful in situations where there's a need to balance the trade-off between precision (the quality of positive predictions) and recall (the model's ability to find all the positive samples).
Background and Theory
In the evaluation of classification models, especially in the context of imbalanced datasets or when the cost of false positives and false negatives varies significantly, neither precision nor recall alone may offer a complete picture of a model's performance. The F1 Score provides a harmonic mean of precision and recall, offering a balance between the two metrics. It's defined as:
This metric reaches its best value at 1 (perfect precision and recall) and worst at 0.
Procedural Steps
To calculate the F1 Score of a machine learning model, follow these steps:
- Compute Precision and Recall: Calculate both precision () and recall () for the model.
- Calculate F1 Score: Use the F1 formula to find the harmonic mean of precision and recall.
Mathematical Formulation
The F1 Score can be mathematically expressed as:
This equation illustrates how the F1 Score penalizes extreme values, encouraging models to maintain a balance between precision and recall.
Applications
The F1 Score is particularly valuable in fields and scenarios such as:
- Medical diagnosis: Where it's crucial to balance the detection of diseases (recall) with the accuracy of diagnosis (precision).
- Spam detection: To ensure that legitimate emails are not incorrectly marked as spam (precision) while catching as much spam as possible (recall).
- Fraud detection: Balancing the need to catch fraudulent transactions (recall) with minimizing false alerts (precision).
Strengths and Limitations
Strengths
- Balance Between Precision and Recall: By harmonizing precision and recall, the F1 Score provides a single metric to assess a model's performance when both false positives and false negatives are important.
- Useful in Imbalanced Datasets: Particularly beneficial in scenarios where positive cases are rare or when the costs of false positives and false negatives differ.
Limitations
- Not Always Intuitive: The harmonic mean might not be as intuitive as arithmetic mean for non-technical stakeholders, making it harder to explain.
- May Mask Model Biases: A high F1 Score might mask a model's tendency to perform well on one class at the expense of another, especially in highly imbalanced datasets.
Advanced Topics
The F1 Score is part of a broader family of F-Scores or F-Measures, where the F1 Score is the special case of the F-Beta Score with . The F-Beta Score allows for different weights between precision and recall, catering to specific application needs where one metric might be more important than the other.
References
- Van Rijsbergen, C.J. "Information Retrieval, 2nd ed." Butterworths, London, 1979.
- Powers, David M. W. "Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation." Journal of Machine Learning Technologies 2.1 (2011): 37-63.
