3. 두괄식 결론
3.1. image Foundation Model 사용하는 방법도 가능
대부분의 접근법이 이 방법을 사용한다고 함- image Foundation Model 사용의 단점도 있지만, 448×448 해상도 등의 높은 해상도를 input으로 가져갈 수 있으므로
- 우리가 모은 풋살 골 데이터로 fine-tuning까지 해보고 성능을 파악해보는 것이 유의미 하겠다!
- TODO
- 최신의 성능 좋은 image Encoding Model은 어떤 것을 가져다 쓰면 좋을까? 2025년 1월 최신 논문을 봐도, 그냥 CLIP이나 SIGLIP 쓰는 것 같음.
3.2. Video Foundation Model을 사용하는 방법도 가능
- 224×224 사이즈보다 높은 해상도로 학습한 video foundation model을 사용해야함.
- TODO
- 이를 위해서는 2024년 3월 이후에 나온 최신 논문들을 스터디 하는 것이 필요
0. 개요
- 결국은 남이 잘 학습시켜놓은 pre-trained model에 fine-tuning을 하는게 좋아보인다.
- 왜냐? 우리는 축구 골 데이터 개수가 적으므로
- 접근 방법 2가지
- image Foundation Model을 가져다 쓰고, fine-tuning하는 방법
- Video Foundation Model을 가져다쓰고, fine-tuning하는 방법
- 위 2가지 방법의 장단점을 소개
1. Image Foundation Model 가져다쓰기?
1.1. "골 장면 추출" 에는 어떻게 활용해?
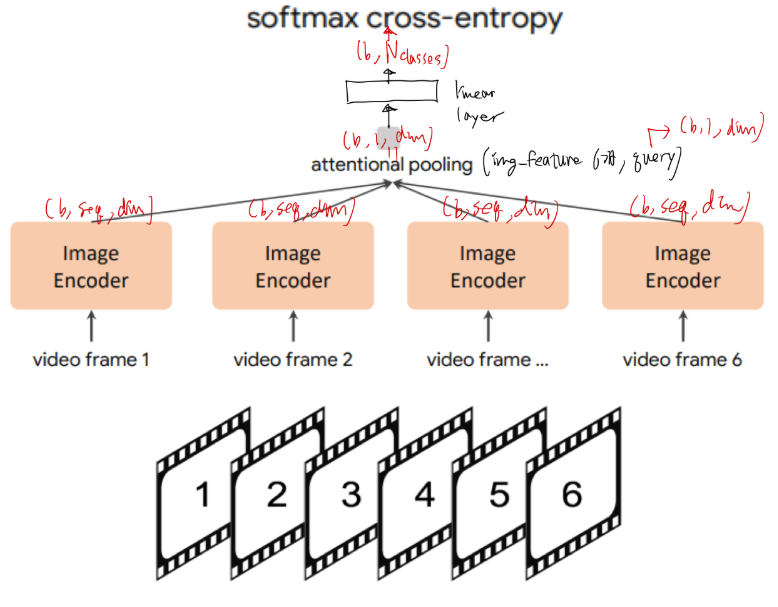
- 위 그림에서, Image Encoder 은 가져다 쓰고(frozen),
attentional polling/linear layer들만 추가로 학습시켜서 사용. - 위 그림에서 Image Encoder의 output shape이 (batch, seq, dim)으로 명시되어 있는데,
- seq는 아래의 것들이 가능하다.
- 이미지 패치 토큰의 갯수
- attentional pooling의 접근방법을 활용한 임의의 seq 값
- 이미지 1장을 대표하는 class token 개념으로 seq=1
축구 골장면은, 공과 골대의 위치가 중요하므로 부적합할수도
- seq는 아래의 것들이 가능하다.
1.2. Image Foundation Model 학습법
- 보통 아래 3가지 접근법을 씀
- masked autoencoder 방식으로 self-supervised learning
- text-image constrative learning
- image to text(caption) generative learning
- 관련 연구
- 장점
- Image Foundation Model에서는 대체로 384×384 또는 448×448 해상도를 많이 사용하여 학습. (비디오 분야에서는 224×224 로 많이 학습함)
- 단점
- Video Foundation Model이 아니다보니,
- 프레임 내
공간 patch token간 연관성 등은 잘 학습하지만, - 다른 프레임 사이에서의
공간 patch token간 연관성 등은 학습되지 못한 상태
- 프레임 내
- Video Foundation Model이 아니다보니,
1.3. 참고 사항 (VLM)
- "골 장면 생성" 에는 크게 도움이 안될 수 있지만, 추후 확장 가능성을 위해 아래 2편 논문 공유
- Visual Instruction Tuning: A.K.A llava
- Improved Baselines with Visual Instruction Tuning : A.K.A llava 1.5
2. Video Foundation Model을 가져다쓰기?
- 아래 pre-training 시, input을 여러 frame의 이미지로 이루어진 비디오로 넣는다는게 차이점
- masked autoencoder 방식으로 video self-supervised learning
- text-image constrative learning
- image to text(caption) generative learning
- 관련 연구들
- 다음 글에서 다룰 예정
- 장점
- 프레임 내 토큰 임베딩끼리만 고려하는게 아닌, 프레임 간 토큰 임베딩간 관계도 고려하여 학습한다.
- 단점
- 2024년 3월 논문까지는 224×224 이미지 사이즈로 학습하는 것 밖에 못봤음. (224×224로 풋살 비디오 이미지 해상도를 낮추니, 공이 잘 보이지 않더라.)

모든 의사 결정 과정을 지나칠 정도로 모두 기록하고, 나중에 스스로 피드백 하는 것