
[텍스트 임베딩] one-hot encoding의 한계점과 word2vec
텍스트 임베딩은 단어를 벡터로 변환하여 기계 학습 모델이 이해할 수 있도록 하는 중요한 과정입니다. 이 과정에서 사용되는 원-핫 인코딩(one-hot encoding)의 한계점과 word2vec의 장점은?One-hot encoding에서는 단어의 개수만큼 차원이 생깁니
임베딩레이어란? (embedding layer)
딥러닝에서 임베딩 레이어(embedding layer)는 텍스트나 범주형 데이터와 같은 이산형(discrete) 데이터를 연속적인 벡터 공간으로 변환해주는 역할을 합니다. 주로 자연어 처리(NLP)에서 많이 사용되며, 단어, 문장, 문서와 같은 텍스트 데이터를 수치화
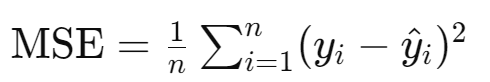
loss function 종류
딥러닝에서 손실 함수(loss function)는 모델의 예측값과 실제값 사이의 차이를 측정하여 모델이 얼마나 잘 작동하는지를 평가하는 데 사용됩니다. 대표적인 손실 함수들을 살펴보겠습니다.회귀 문제설명: 예측값과 실제값 사이의 차이의 제곱을 평균한 값입니다. 차이의
XGboost / LightGBM / CatBoost
XGBoost (2014), LightGBM (2017), CatBoost(2018)는 모두 그라디언트 부스팅(Gradient Boosting) 알고리즘을 기반으로 하지만, 각기 다른 최적화와 특징을 가지고 있습니다. XGBoost (Extreme Gradient Bo
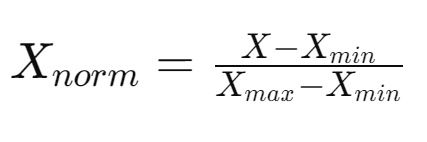
Min-Max정규화, Max정규화 차이
Min-Max 정규화와 Max 정규화는 데이터의 스케일을 조정하는 방법으로, 머신 러닝 모델의 성능을 향상시키기 위해 자주 사용됩니다.보통 Min-Max 정규화가 주로 사용되지만 어떠한 경우에 Max 정규화가 필요할까요?Min-Max 정규화는 데이터를 특정 범위로 조정