
- 전체보기(148)
- 모두의연구소(136)
- 데이터사이언티스트(136)
- python(27)
- pandas(22)
- sql(20)
- 통계(19)
- projects(16)
- DL(16)
- ML(16)
- scikit learn(15)
- Time Series(13)
- customer segmentation(11)
- tableau(10)
- BigQuery(9)
- machine learning(9)
- matplotlib(8)
- numpy(8)
- AARRR(7)
- XGBoost(7)
- seaborn(7)
- LightGBM(6)
- git(5)
- github(5)
- NLP(4)
- Timeseries(3)
- langChain(2)
- kaggle(2)
- rag(2)
- LLM(2)
- AIFFELthon(2)
- 회고(2)
- prompt engineering(2)
- 추천시스템(1)
- tensorflow(1)
- AI(1)
- google sheets(1)
- Preporcessing(1)
- scipy(1)
- react native(1)
- Linear Regression(1)
- OS(1)
- Classfication(1)
- pipeline(1)
- regression model(1)
- Gradient Descent(1)
- Regression(1)
- plotly(1)
- Data Collecting(1)
- linux(1)
- datathon(1)
- 로그 데이터(1)
- confusion matrix(1)
[아이펠톤] LLM 토론 시스템 도입: DEEVO, DReaMAD 연구 분석
LLM 토론 시스템을 도입해야 하는 이유: DEEVO와 DReaMAD 연구 분석
[아이펠톤] 프롬프트 엔지니어링: 도메인 지식 내장형 CoT로 과학 추론 강화하기
Integrating Chemistry Knowledge in Large Language Models via Prompt Engineering (Liu et al., 2024)
[추천시스템] 딥러닝과 추천 시스템
추천 시스템의 중요성과 딥러닝을 접목함으로써 생기는 이점을 시작으로, 딥러닝 기반 추천 시스템의 실제 사례와 평가 지표를 통해 좋은 추천 시스템이란 무엇일지 이해하고 정리해 보았다. 실제로 서비스에 추천 시스템을 적용하기 위해 무엇을 고려해야 할지 생각해 보자.
💊 영양제 Check! 프로젝트 회고
이번 프로젝트는 "영양제 추천 서비스 만들기" 가 아니라, LLM이 어떻게 더 신뢰성 있게 정보를 전달할 수 있을까에 대한 고민과 실험이었다고 할 수 있다. 그 과정에서 배우고 느낀 점들을 정리해 보려고 한다.

로그 데이터 수집 자동화 환경 구축하기
날씨앱을 개발하고 서비스하면서 사용자 경험을 더 정교하게 만들고 싶다는 욕심이 생겼다 🌤️ 복잡한 서버 연동 없이 앱 단에서 수집할 수 있는 구조를 만들고자 했고, 그 결과 Google Sheets 를 활용하여 경량-무서버 로그 수집 시스템을 구성하게 되었다.
[DL] 토큰에 의미 부여하기
기계는 숫자 연산을 통해 데이터를 인지한다. 그렇다면 텍스트로 이루어진 문장을 어떻게 숫자로 바꾸고, 또 의미를 담게 할 수 있을까?
[DL] Tokenization: 기계가 텍스트를 다루려면
자연어 처리를 위해서는 토큰화(Tokenization)를 이해해야 한다. 문장을 기계가 이해할 수 있는 형태로 바꾸기 위해서는 먼저 문장을 잘게 쪼개는 작업이 필요하다.
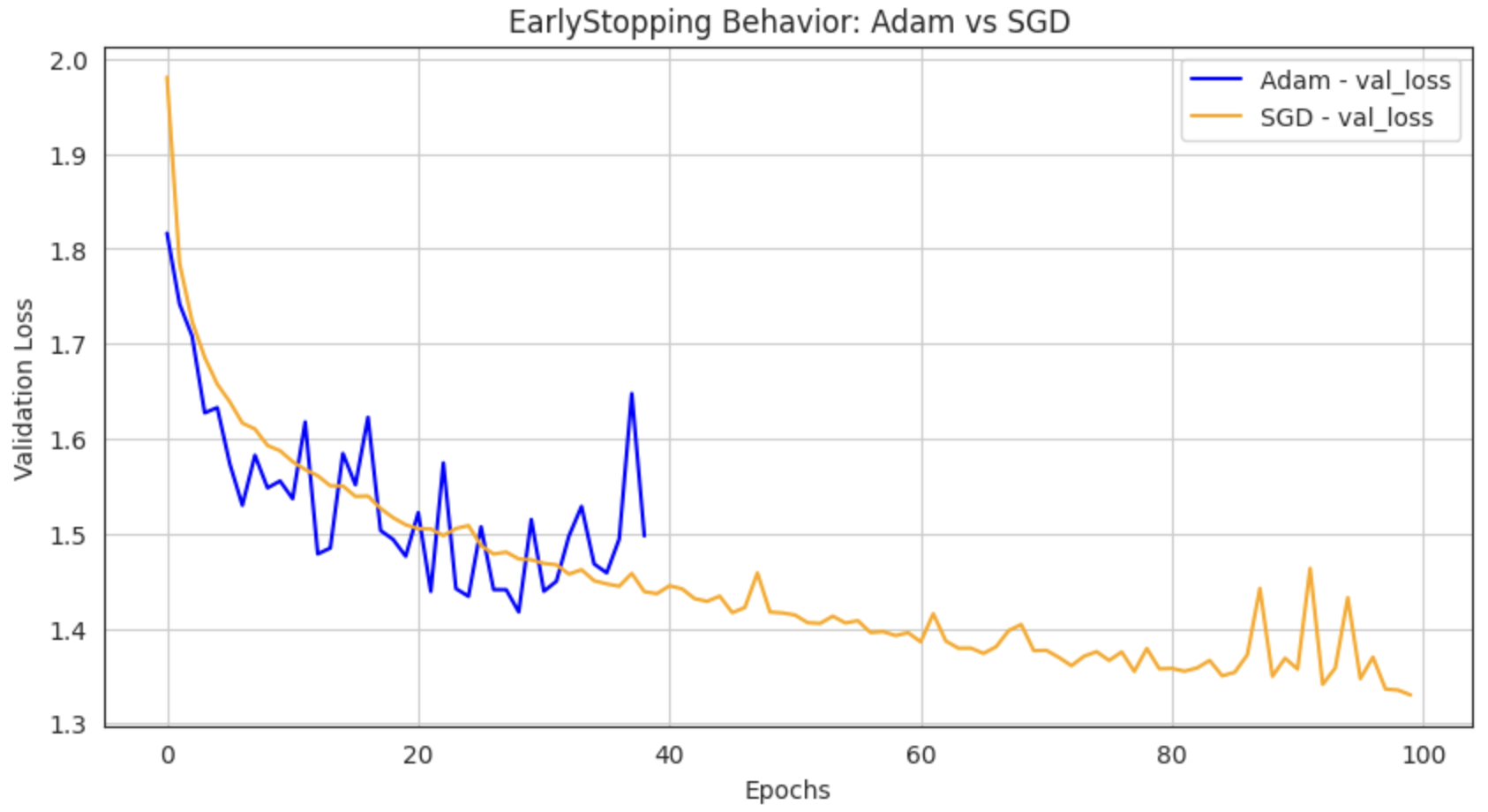
[DL] Adam vs. SGD로 보는 EarlyStopping 작동 원리
딥러닝 학습 중 EarlyStopping 콜백 동작에서 의문이 하나 생겼다. " 은 모델, 같은 학습 조건인데 .. Adam을 쓰면 중간에 멈추고, SGD를 쓰면 끝까지 100 epoch 다 돌아버리네?"
[DL] 딥러닝 모델 학습 기술: 이론
딥러닝 모델의 성능에 있어서 '학습 기술'이 중요하게 작용한다. 어떤 활성화 함수를 사용할지, 가중치는 어떻게 초기화할지, 학습률은 얼마나 줄지, 배치 단위는 어떻게 설정할지 등 세부적인 설정이 전체 결과를 결정짓게 된다.
[DL] 옵티마이저와 지표
모델 학습에서 손실 함수가 예측 성능을 수치화해준다면, 옵티마이저는 그 손실 값을 최소화하기 위해 파라미터를 어떻게 업데이트할지를 결정하는 역할을 한다. 학습 도중 혹은 완료 후 모델 성능을 평가할 때는 지표(metrics)를 사용한다.
[DL] 손실 함수 (Loss Function)
모델이 학습을 잘하고 있는지를 판단하려면 그 과정에 대한 지표가 필요한데, 손실 함수가 이 역할을 한다. 모델이 예측한 값과 실제 정답 사이의 오차를 수치로 나타내고, 이 값이 작을수록 예측이 정확하다는 뜻이다. 학습은 손실 함수를 최소화하는 방향으로 진행된다.
[DL] Keras 딥러닝 모델
딥러닝 모델을 구성하는 방법에는 여러 가지가 있다. 그중 Keras를 사용할 때는 대부분 3가지 방법 중 하나를 선택하게 된다. 각각의 방식이 어떤 구조와 개념적 배경을 갖고 있는지, 왜 그렇게 쓰이는지에 대해 이해하는 과정을 함께 담아보았다.
[DL] 딥러닝 구조와 레이어
딥러닝 모델을 만들기 위해서는 모델의 구성 요소들이 어떤 역할을 하고, 어떻게 연결되는지를 정확히 이해해야 한다. 이 글에서는 Keras에서 딥러닝 모델을 구성할 때 활용하는 주요 API 구조와 레이어의 개념, 종류, 특징, 실제 코드 사용법의 순서로 정리해 보았다.
[DL] Tensor의 개념과 구조
딥러닝을 이해하려면 텐서(Tensor)의 개념부터 정확히 짚고 넘어가야 한다. 이 글에서는 텐서의 구조와 연산 방식과 사용 함수들을 코드와 함께 정리하고, 실제 연산 결과를 통해 동작 원리를 직관적으로 이해하는 데 초점을 맞추었다.
[DL] 딥러닝의 구조와 발전
이러한 딥러닝의 중심에는 인공신경망(Artificial Neural Network)이라는 핵심 개념이 존재한다. 이 글에서는 인공신경망의 구조와 원리를 시작으로, 딥러닝 기술이 어떻게 발전해왔고 어떤 방식으로 작동하는지 정리해 보았다.
[DL] 퍼셉트론의 한계와 MPL
퍼셉트론은 입력과 가중치의 선형 결합을 바탕으로 이진 분류를 수행하는 가장 기본적인 인공 신경망 구조인데, 비선형적인 구조를 가진 문제는 해결하지 못하는 한계가 존재한다. 이러한 한계를 극복하기 위해 은닉층을 추가한 구조인 MLP가 등장하게 된다.
[DL] Artificial Neural Network
딥러닝에서 가장 먼저 이해해야 하는 개념이 인공신경망(ANN)이다. 핵심 원리는 생각보다 간단할 수 있다. 인간의 뇌 구조에서 영감을 받아 수학적으로 구현된 모델이기 때문이다.
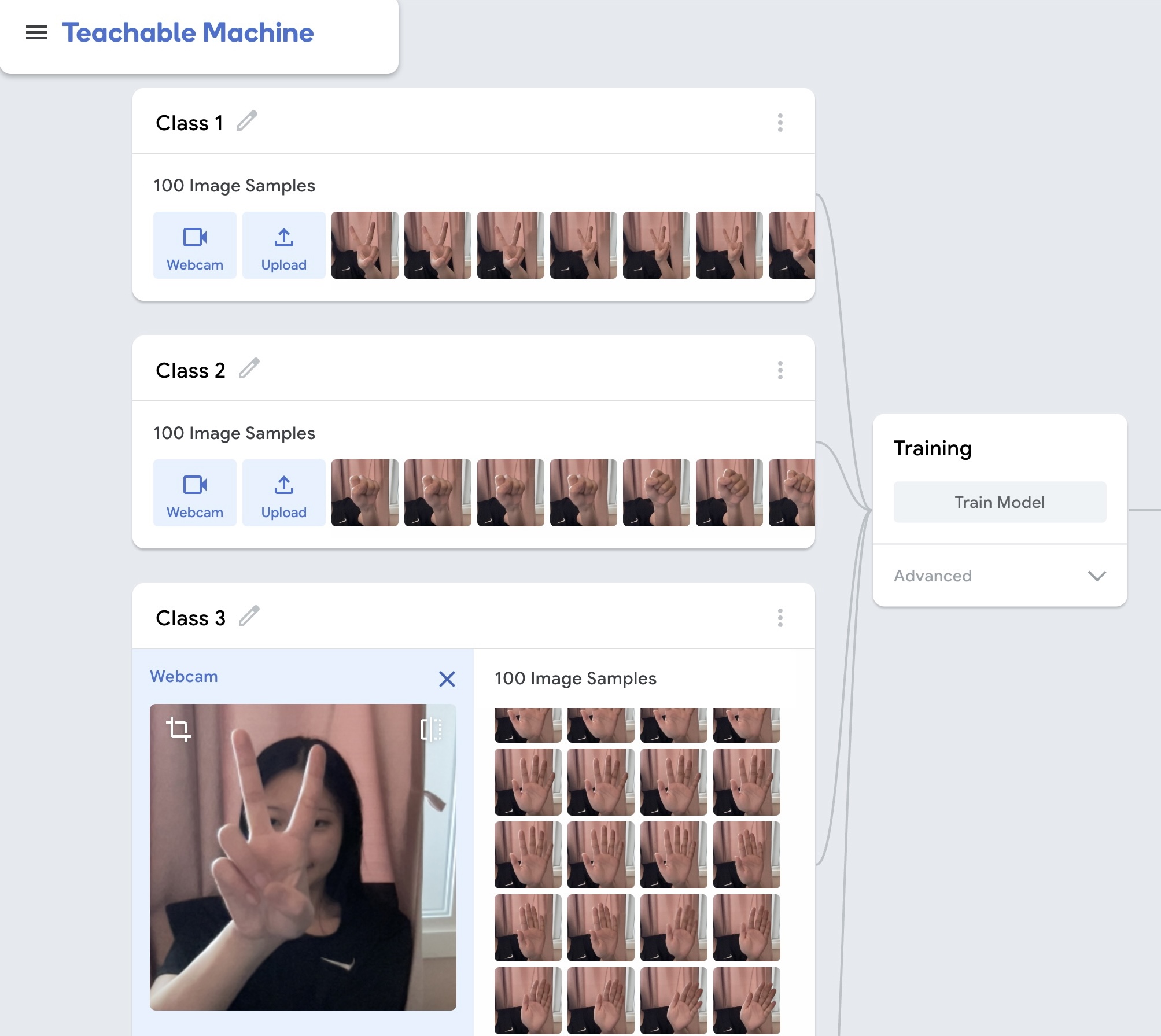
[DL] 가위바위보 이미지 분류: 웹캠으로 데이터 수집
웹캠을 이용해 가위, 바위, 보 이미지를 직접 촬영하고, 이를 바탕으로 딥러닝 모델을 학습시켜 분류기를 구현한다. MNIST 숫자 분류와 마찬가지로 데이터 수집 → 전처리 → 모델 훈련 → 평가 → 시각화 → 일반화 성능 점검까지의 전체 흐름을 살펴보았다.