
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
해당 글은 혼자 공부하는 머신러닝+딥러닝 책의 실습 내용의 일부를 담고 있습니다.
0. ⭐ Imbalanced Data Sampling
- 데이터 비율 맞추기
- Under Sampling: 적은 쪽으로 줄이기
- Over Sampling: 많은 쪽으로 늘리기
- SMOTE(Synthetic Minority Over-sampling Technique)
KNR에 대해 들어가기 전에 전 글에 이어 반드시 알아야할 내용이 추가로 있어서 정리하고 간다.
Imbalanced Data Sampling으로 분류 모델에서 데이터의 비율이 깨진 경우, 많은 쪽이나 적은 쪽으로 맞추는 기법이다.
이 Imbalanced Data Sampling은 크게 두개로 Under Sampling과 Over Sampling이 있는데,
그 중 Over Sampling의 기법 중 하나인 SMOTE를 사용해보자.
pip install imblearn 으로 설치가 필요하다.
from imblearn.over_sampling import SMOTE지난번에 빙어와 도미를 분류하는데 사용한 데이터를 사용한다.
fish_data=pd.read_csv("./data/mulgogi_data.csv")
fish_data.shape(49, 3)그렇다면 비율을 보자.
fish_data["Species"].value_counts()Species
Bream 35
Smelt 14
Name: count, dtype: int64이는 사실 비율이 깨졌다고 할 수는 없지만 실습을 위해 그냥 진행하자.
어찌됐든 이 Smelt를 over sampling이기때문에 Bream과 맞게 35로 늘려주는 것이다.
X=fish_data[["Length", "Weight"]]
Y=fish_data["Species"]
X.shape, Y.shape((49, 2), (49,))이렇게 목표변수와 설명변수를 나눴다.
지금은 35+14로 49개가 나온다.
이제 스케일을 조절해서 학습을 했었는데, 이전에 비율을 맞추는 것이다.
smote=SMOTE(random_state=1234)
X_over, Y_over=smote.fit_resample(X, Y)
X_over.shape, Y_over.shape((70, 2), (70,))이렇게 35+35로 70개로 데이터가 늘어난 것을 볼 수 있다.
한번 DataFrame으로 만들어서 확인해보자.
over_df=pd.DataFrame(data=X_over, columns=["Length", "Weight"])
over_df["Species"]=Y_overover_df["Species"].value_counts()Species
Bream 35
Smelt 35
Name: count, dtype: int64어찌됐든 이제 이렇게 over sampling으로 데이터를 늘렸으니
이에 이어서 스케일 조절하고 학습하고 평가(report)하고 예측하면 된다.
뒷 부분은 생략한다.
1. K-Neighbor Regressor
이번에는 Y 결과값을 분류하는게 아닌, 숫자로 나오는 회귀다.
1.1. 농어 무게 예측
길이를 이용해 농어의 무게를 예측해보자.
#입력데이터: 농어 길이 (설명변수)
perch_length=np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0,
21.0, 21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5,
22.5, 22.7, 23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5,
27.3, 27.5, 27.5, 27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0,
36.5, 36.0, 37.0, 37.0, 39.0, 39.0, 39.0, 40.0, 40.0, 40.0,
40.0, 42.0, 43.0, 43.0, 43.5, 44.0])
#정답데이터: 농어 무게 (목표변수)
perch_weight=np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
1000.0, 1000.0])perch_length.shape, perch_weight.shape((56,), (56,))둘 다 1차원 배열이다.
그리고 숫자형이기 때문에 histplot으로 시각화해보자.
sns.histplot(x=perch_length, kde=True)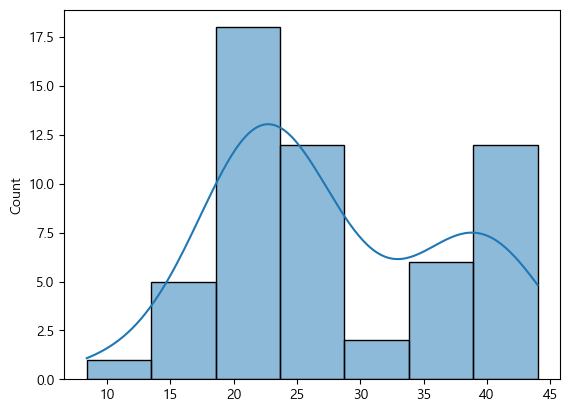
sns.histplot(x=perch_weight, kde=True)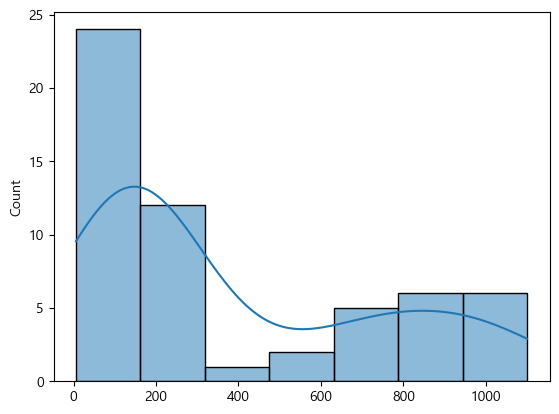
이들을 보니 정규분포는 아닌거 같다.
그러면 scatterplot도 보자.
sns.scatterplot(x=perch_length, y=perch_weight)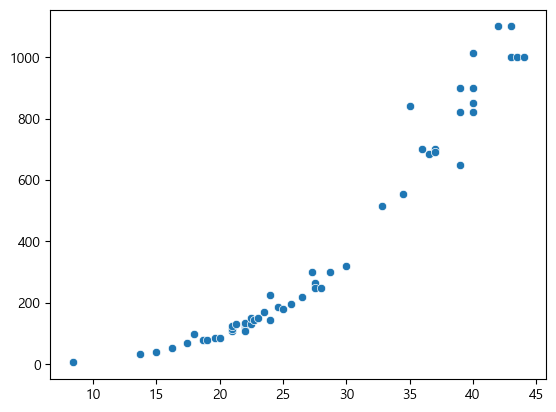
이렇게 길이가 늘어날수록 무게가 늘어난다는 것을 볼 수 있다.
즉 연관이 있다.
그렇다면 상관분석을 해서 이게 정말 연관이 있는지 보자.
import scipy.stats as stats
from sklearn.neighbors import KNeighborsRegressor
stats.normaltest(perch_length)NormaltestResult(statistic=6.423810381723155, pvalue=0.040279799416983)stats.normaltest(perch_weight)NormaltestResult(statistic=10.4456856014929, pvalue=0.005391978996182582)정규분포가 아니기 때문에 spearman을 사용한다.
stats.spearmanr(perch_length, perch_weight)SignificanceResult(statistic=0.9866394004320461, pvalue=3.061101998942074e-44)pvalue 0.00...306 < 0.05 유의수준 이므로 대립가설이 참이고 귀무가설이 기각된다.
따라서 상관이 있음을 알 수 있다.
1.2. 훈련 및 데이터 셋
먼저 훈련 데이터와 테스트 데이터를 나누자.
X_train, X_test, Y_train, Y_test=train_test_split(perch_length, perch_weight, random_state=42)
X_train.shape, X_test.shape, Y_train.shape, Y_test.shape((42,), (14,), (42,), (14,))다 1차원 배열이다.
X_testarray([ 8.4, 18. , 27.5, 21.3, 22.5, 40. , 30. , 24.6, 39. , 21. , 43.5,
16.2, 28. , 27.3])
1.2.1. 2차원 배열로 수정
회귀는 X를 2차원으로 넣어줘야한다.
따라서 2차원 배열로 수정하자.
X_train=X_train.reshape(-1, 1)
X_test=X_test.reshape(-1, 1)
X_train.shape, X_test.shape((42, 1), (14, 1))X_testarray([[ 8.4],
[18. ],
[27.5],
[21.3],
[22.5],
[40. ],
[30. ],
[24.6],
[39. ],
[21. ],
[43.5],
[16.2],
[28. ],
[27.3]])
이렇게 2차원으로 바뀐 것을 확인할 수 있다.
KNR에서는 fit해줄때 x값은 2차원으로 들어가야한다.
그 전까찌는 열이 2개이상이었다.
2차원에 2차원이 들어갔으니 배열이든 dataframe이든 상관없었다.
그러나 이는 학습자체를 2차원으로 받아서 열이 하나니까 2차원으로 바꿔준것이다.
1.2.2. 모델 훈련 및 평가
이제 학습을 시켜보자.
knr=KNeighborsRegressor(n_neighbors=3)
knr.fit(X_train, Y_train)
print("학습: ", knr.score(X_train, Y_train))
print("일반화: ", knr.score(X_test, Y_test))학습: 0.9804899950518966
일반화: 0.974645996398760997이 97%의 정확도가 아니라, 설명변수에 대한 설명을 97에 가깝게 설명했다는 뜻이다.
1~0 사이의 값이 나온다.
이는 선형회귀에서 자세히 다루겠다.
예측을 해보자.
knr.predict([[16.8]])array([62.66666667])그런데 이게 잘 나온건지 안나온건지도 모르기 때문에,
테스트 데이터를 통째로 넣고,
예측한 값을 넣어서 비교해서 그려보자.
X_test_pred=knr.predict(X_test)
sns.scatterplot(x=X_test[:, 0], y=Y_test, label="실제값")
sns.scatterplot(x=X_test[:, 0], y=X_test_pred, marker="D", label="예측값")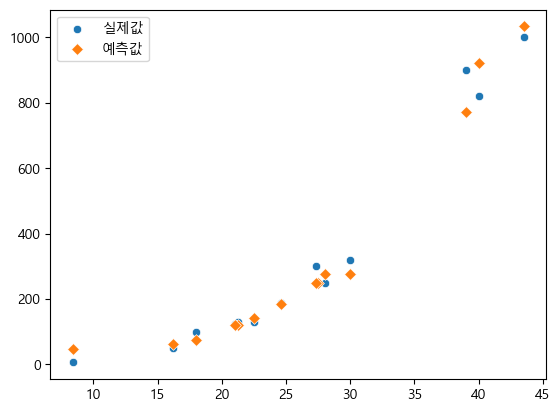
1.3. 일반화, 과대적합, 과소적합
일반화(generalization): 훈련 데이터와 새로운 데이터 모두 높은 성능을 보임
과대적합(Overfitting): 훈련 데이터에는 높은 성능을 보이지만, 새로운 데이터에 대해서는 일반화하지 못함
과소적합(Underfitting): 테스트 점수가 더 높거나 또는 두 점수 모두 낮음
knr=KNeighborsRegressor(n_neighbors=3)
knr.fit(X_train, Y_train)
print("학습: ", knr.score(X_train, Y_train))
print("일반화: ", knr.score(X_test, Y_test))학습: 0.9804899950518966
일반화: 0.9746459963987609이는 일반화가 잘됐다.
그렇다면 다음을 보자.
knr=KNeighborsRegressor(n_neighbors=5)
knr.fit(X_train, Y_train)
print("학습: ", knr.score(X_train, Y_train))
print("일반화: ", knr.score(X_test, Y_test))학습: 0.9698823289099254
일반화: 0.992809406101064지금 보면 테스트 점수가 더 높다.
이런 경우와 더불어
knr=KNeighborsRegressor(n_neighbors=33)
knr.fit(X_train, Y_train)
print("학습: ", knr.score(X_train, Y_train))
print("일반화: ", knr.score(X_test, Y_test))학습: 0.4752451966763833
일반화: 0.4834613125728193두 점수 모두 낮을때, 과소적합이라고 한다.
즉 이렇게 n, 하이퍼파라미터(Hyper Parameter)값을 잘 정해줘야한다.
default값이 5인데 3으로 정해준 값이 더 좋게 나왔다.
그러면 이를 어떻게 잡아줄까?
for i in range(3, 20, 2): # 1은 자기자신이니까 항상 100% -> 제외
print(f"{i}일때")
knr=KNeighborsRegressor(n_neighbors=i)
knr.fit(X_train, Y_train)
print("학습: ", knr.score(X_train, Y_train))
print("일반화: ", knr.score(X_test, Y_test))3일때
학습: 0.9804899950518966
일반화: 0.9746459963987609
5일때
학습: 0.9698823289099254
일반화: 0.992809406101064
7일때
학습: 0.9761170732051527
일반화: 0.9781383949643516
9일때
학습: 0.9693310367551284
일반화: 0.9692647749722698
11일때
학습: 0.9515761381539326
일반화: 0.970279643030474
13일때
학습: 0.9413423450130075
일반화: 0.9639044643206888
15일때
학습: 0.930201118360776
일반화: 0.9554827691127018
17일때
학습: 0.9087778943199959
일반화: 0.9314058693169347
19일때
학습: 0.8782082893573573
일반화: 0.900993697623706이렇게 나중에 가면 최적화에 대한 부분을 배울 것인데,
어찌됐든 내부적으로 컴퓨터가 이런 과정을 처리하며 가장 최적의 값을 반환하고 그 값을 사용하는 것이다.
1.4. K-최근접 이웃 회귀의 한계
아이스크림 예시.
40도 일때 몇개가 팔릴지인데,
이걸 80~90퍼 정도 예측하는게 좋은 모델이다. 여기 까지는 OK인데.
여기에는 문제가 있다.
완전 다른 애를 예측하기 힘들다는 것이다.
다음을 보자.
학습에 없는 농어의 크기를 주고 무게를 예측해보자.
knr=KNeighborsRegressor(n_neighbors=3)
knr.fit(X_train, Y_train)
print(knr.predict([[50]]))[1033.33333333]이는 농어가 50cm일때의 무게를 확인한다.
그러면 이제 100cm일때는?
print(knr.predict([[100]]))[1033.33333333]그런데 이렇게 똑같은 결과가 나온다.
왜 이럴까? 이유는 다음과 같다.
50cm 농어의 이웃과의 거리와 인덱스를 확인하자.
d, i=knr.kneighbors([[50]])
d, i(array([[6., 7., 7.]]), array([[34, 8, 14]], dtype=int64))n=3으로 지정했으니 3개의 거리값을 계산한것과, 인덱스번호를 가져온다.
그렇다면 이제 산점도를 찍는다.
# 훈련 세트 전체
sns.scatterplot(x=X_train[:, 0], y=Y_train)
# 50cm 농어의 이웃
for idx in i:
sns.scatterplot(x=X_train[idx, 0], y=Y_train[idx], marker="D")
# 50cm 농어의 데이터
sns.scatterplot(x=[50], y=[1033], marker="^", s=100)
plt.xlabel("길이")
plt.ylabel("무게")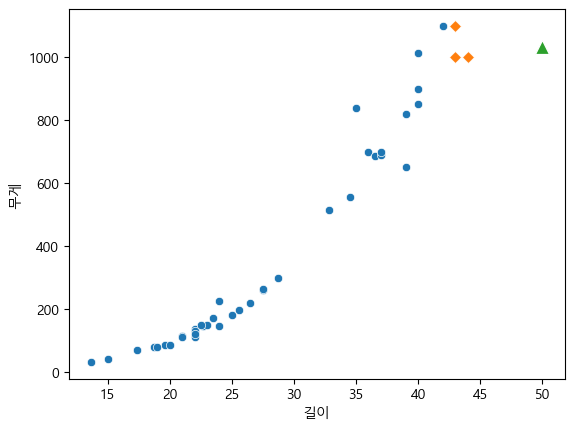
그러면 여기서 50cm 농어의 이웃을 3개 뽑으면
주황색 다이아몬드만 뽑게된다.
그렇다면, 100이면?
d, i=knr.kneighbors([[100]])
# 훈련 세트 전체
sns.scatterplot(x=X_train[:, 0], y=Y_train)
# 100cm 농어의 이웃
for idx in i:
sns.scatterplot(x=X_train[idx, 0], y=Y_train[idx], marker="D")
# 100cm 농어의 데이터
sns.scatterplot(x=[100], y=[1033], marker="^", s=100)
plt.xlabel("길이")
plt.ylabel("무게")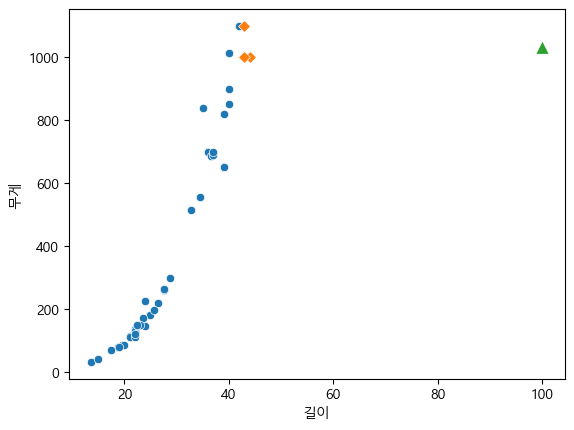
100일때도 역시 이웃 3개는 주황색 다이아몬드 3개다.
이게 바로 KNR의 한계다.
비슷한 애들사이에서의 예측만 가능하다.
💪 퀴즈
Q1. KNR에서 훈련 데이터와 테스트 데이터의 상관 관계를 설명하는 부분에 대한 설명으로 옳지 않은 것은?
1) 훈련 데이터에 대한 성능이 높으면 테스트 데이터에 대해서도 좋은 성능을 기대할 수 있다.
2) 과대적합은 훈련 데이터에는 높은 성능을 보이고, 테스트 데이터에서는 성능이 떨어지는 현상이다.
3) 과소적합은 훈련 데이터와 테스트 데이터 모두에서 성능이 낮은 현상이다.
4) 모델이 잘 학습되었으면 훈련 데이터에 대해서는 높은 점수를, 테스트 데이터에 대해서도 높은 점수를 기록한다.
A1. 1
Q2. KNR 모델을 학습시키고, 50cm 농어의 무게를 예측했을 때와 100cm 농어의 무게를 예측했을 때, 결과가 동일하게 나온 이유는?
1) 모델이 충분히 학습되었기 때문에 이웃을 기준으로 예측이 이루어졌다.
2) 모델이 50cm와 100cm 농어를 구분할 수 없을 정도로 학습이 부족하다.
3) KNR은 입력값이 훈련 데이터 내에 포함되지 않으면 예측이 불가능하다.
4) KNR 모델은 훈련 데이터에서 이웃값을 기준으로 예측하는데, 학습 데이터 범위를 넘어서는 값에 대해서는 예측을 할 수 없다.
A2. 4
Q3. KNR에서 n_neighbors 값을 조정할 때, 3일 때 가장 좋은 성능을 보였다고 할 때, 그 이유로 가장 적절한 설명은?
1) n_neighbors 값이 3일 때 과소적합을 방지할 수 있기 때문에
2) n_neighbors 값이 너무 작으면 과대적합을 초래할 수 있기 때문에
3) n_neighbors 값이 너무 커지면 과소적합을 초래할 수 있기 때문에
4) n_neighbors 값이 3일 때 모델이 가장 잘 일반화되기 때문에
A3. 4
Q4. KNR 모델을 학습시킨 후,
knr.score(X_train, Y_train)과 knr.score(X_test, Y_test)
의 값이 각각 0.98과 0.97로 나왔다.
이 경우, 모델의 평가 결과에 대해 가장 적절한 설명은?
1) 모델이 훈련 데이터에 대해서 과대적합된 것이다.
2) 모델이 테스트 데이터에 대해 과소적합된 것이다.
3) 모델은 훈련 데이터와 테스트 데이터에서 모두 우수한 성능을 보였다.
4) 모델이 과소적합되었지만, 훈련 데이터에서는 높은 성능을 보였다.
A4. 3
