
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
해당 글은 혼자 공부하는 머신러닝+딥러닝 책의 실습 내용의 일부를 담고 있습니다.
K 최근접 이웃 회귀에서 한계점으로 인접한 이웃만 뽑아냈기에 값이 비슷하지 않으면 아무리 멀어도 항상 같은 이웃들을 가져왔었다.
그래서 이번 내용은 머신러닝의 기반이되는 아주 중요한 선형회귀(Linear Regression) 다.
1. 단순 선형 회귀(Simple Linear Reggresion)
데이터의 "값"을 예측하는 회귀 분석
목표변수(Y -> 숫자 -> 회귀)
1.1. 농어 무게 선형 회귀 분석
지난 KNR에서의 농어의 길이(설명변수)로 농어의 무게(목표변수)를 예측했었는데, 똑같이 이를 선형회귀로 진행한다.
먼저 필요한 라이브러리 먼저 import.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rc("font", family="Malgun Gothic")
plt.rcParams["axes.unicode_minus"]=False
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression1.1.1. 데이터 로드
X와 Y는 다음과 같다.
#입력데이터: 농어 길이 (설명변수)
perch_length=np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0,
21.0, 21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5,
22.5, 22.7, 23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5,
27.3, 27.5, 27.5, 27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0,
36.5, 36.0, 37.0, 37.0, 39.0, 39.0, 39.0, 40.0, 40.0, 40.0,
40.0, 42.0, 43.0, 43.0, 43.5, 44.0])
#정답데이터: 농어 무게 (목표변수)
perch_weight=np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0,
110.0, 115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0,
130.0, 150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0,
197.0, 218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0,
514.0, 556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0,
820.0, 850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0,
1000.0, 1000.0])print(perch_length.shape, type(perch_length))
print(perch_weight.shape, type(perch_weight))(56,) <class 'numpy.ndarray'>
(56,) <class 'numpy.ndarray'>이는 지금 numpy배열형이다.
하지만 훈련을 진행할때 fit 메서드는 2차원을 받기 때문에 2차원이나 DataFrame형태로 넣어줘야한다.
따라서 후에 훈련, 테스트 데이터 세트를 나누고 설명변수를 2차원으로 reshape를 해주자.
(Y는 어차피 1열만 나오면 되기 때문에 건드리지 않는다)
이제 scalling을 해야하는데, 두 집단의 크기를 비교할때는 scalling이 필요한데 이는 한 집단이기 때문에 scalling이 필요없다.
그리고 이미 나뉘어져 있기 때문에 설명변수와 목표변수도 나눌 필요가 없다.
데이터셋만 7:3으로 나누면 된다.
1.1.2. 데이터 셋 - train/test
X_train, X_test, Y_train, Y_test=train_test_split(perch_length, perch_weight, random_state=42)이제 나눴으니 2차원으로 바꾸자.
X_train=X_train.reshape(-1,1)
X_test=X_test.reshape(-1,1)
X_train.shape, X_test.shape((42, 1), (14, 1))1.1.3. 선형 회귀 모델 훈련 및 평가
lr=LinearRegression() # 생성자
lr.fit(X_train, Y_train) # fit 메서드를 통해 전달하고 학습시킴
print("학습: ", lr.score(X_train, Y_train))
print("일반화: ", lr.score(X_test, Y_test))학습: 0.939846333997604
일반화: 0.8247503123313558약간 과대적합(over)이지만 괜찮다.
이제 학습을 시켰으니 새로운 데이터를 넣어 예측을 해야보자.
print(lr.predict([[50]]))
print(lr.predict([[100]]))[1241.83860323]
[3192.69585141]이렇게 KNR에서는 값이 똑같이 나왔지만, 선형회귀에서는 값이 다르게 나옴을 알 수있다.
그렇다면 KNR에서는
d, i=knr.kneighbors([[100]])
d, i을 이용해서 주변에있는 i와 index값을 뽑아왔다면, 선형회귀는 기울기와 절편을 뽑아내보자.
print("기울기: ", lr.coef_)
print("절편: ", lr.intercept_)기울기: [39.01714496]
절편: -709.01864495354771.1.4. 예측 시각화
새로운 데이터를 넣어 예측한 것을 시각화하면 다음과 같다.
먼저 전체를 그리고 각각 marker를 다르게하여 표현한다.
sns.scatterplot(x=X_train[:, 0], y=Y_train) # x, 전체 행의 0번째 컬럼
sns.scatterplot(x=[50], y=[1241], marker="^", s=100)
sns.scatterplot(x=[100], y=[3192], marker="D", s=100)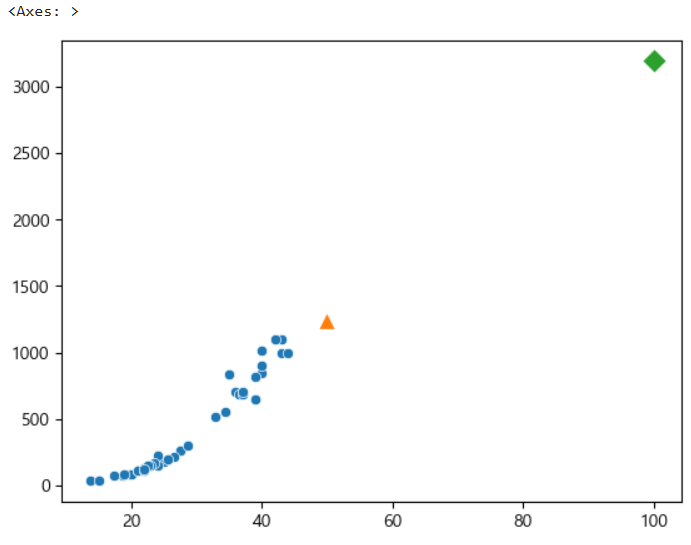
1.1.5. 기울기와 절편
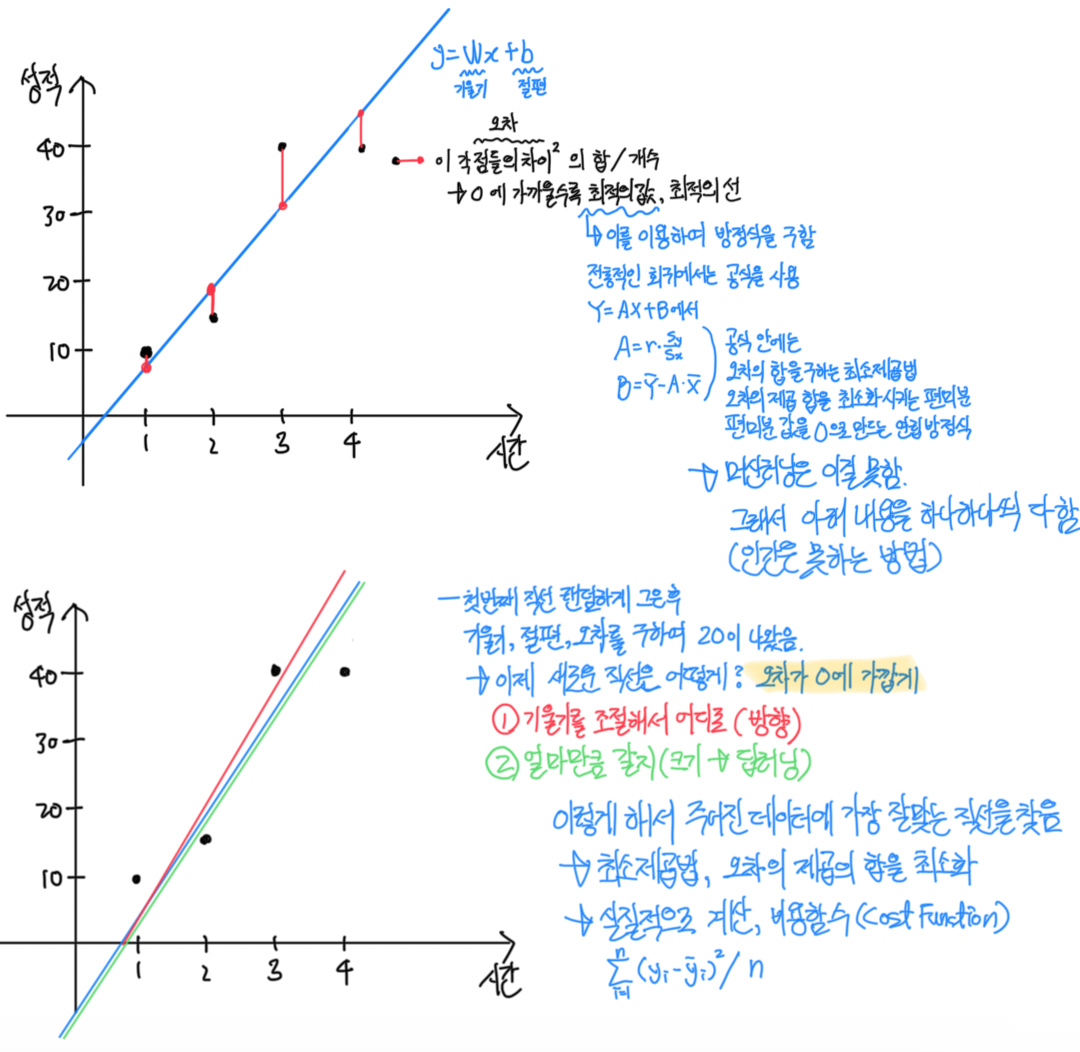
하나하나 계산이 불가능하기에 인간은 공식을 만들었고, 컴퓨터는 이게 안되기 때문에 하나하나 만들었다.
그 중에 랜덤으로 그어서 회귀선을 찾을때 두가지를 생각해야하는데,
어느 방향으로 갈지와, 얼마만큼 이동할지 크기의 문제 둘이다.
(이중 크기의 문제는 딥러닝에서 다룬다.)
방향의 문제는 오차가 0에 가까워야 한다.
그런데 0에 가까울 일은 거의 없다. 따라서 오차를 최소화해야 한다.
그래서 그를 최소제곱법이라고 한다.
실제 데이터와 그은 선과 비교해서 차이를 제곱해서 합한 후 개수만큼 나눠준다.
이를 다른 말로 비용함수(Cost Function)이라고한다.
오차 또는 잔차의 차이를 제곱해서 합해서 나누는 것을 최소제곱법이라고 하며, 실질적으로 계산하는 것을 비용함수라고 한다.
1.2. Kaggle 매체별 광고 판매량 분석
데이터: https://www.kaggle.com/datasets/ashydv/advertising-dataset
캐글에 있는 데이터로, 광고에 따라 매출이 올라가는지에 대한 분석을 한다.
1.2.1. 데이터 전처리
데이터를 불러오자.
advertise=pd.read_csv("./data/advertising.csv")
advertise.shape(200, 4)advertise.head()| TV | Radio | Newspaper | Sales | |
|---|---|---|---|---|
| 0 | 230.1 | 37.8 | 69.2 | 22.1 |
| 1 | 44.5 | 39.3 | 45.1 | 10.4 |
| 2 | 17.2 | 45.9 | 69.3 | 12.0 |
| 3 | 151.5 | 41.3 | 58.5 | 16.5 |
| 4 | 180.8 | 10.8 | 58.4 | 17.9 |
TV를 230번 내고, 라디오를 37번, 뉴스를 69번 내니 판매량이 22가 나왔다.
이렇게 데이터를 불러와서 데이터 타입 및 결측치가 있는지 확인하고
advertise.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 200 entries, 0 to 199
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 TV 200 non-null float64
1 Radio 200 non-null float64
2 Newspaper 200 non-null float64
3 Sales 200 non-null float64
dtypes: float64(4)
memory usage: 6.4 KBadvertise.isna().sum()TV 0
Radio 0
Newspaper 0
Sales 0
dtype: int64기술통계량을 확인하여 이상치가 있는지 확인한다.
advertise.describe().T.astype(int)| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| TV | 200 | 147 | 85 | 0 | 74 | 149 | 218 | 296 |
| Radio | 200 | 23 | 14 | 0 | 9 | 22 | 36 | 49 |
| Newspaper | 200 | 30 | 21 | 0 | 12 | 25 | 45 | 114 |
| Sales | 200 | 15 | 5 | 1 | 11 | 16 | 19 | 27 |
1.2.2. 시각화
sns.histplot(data=advertise, x="Sales", kde=True)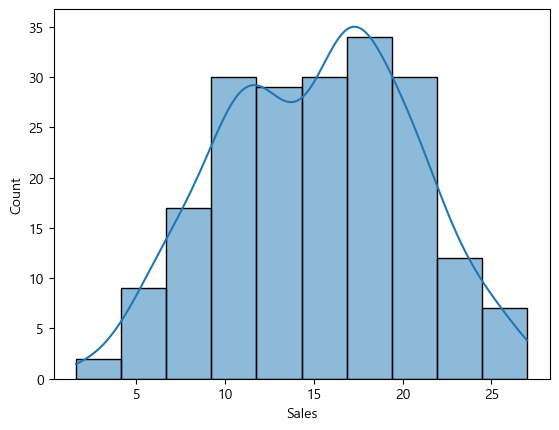
TV와 Sales의 관계를 보자.
sns.scatterplot(data=advertise, x="TV", y="Sales")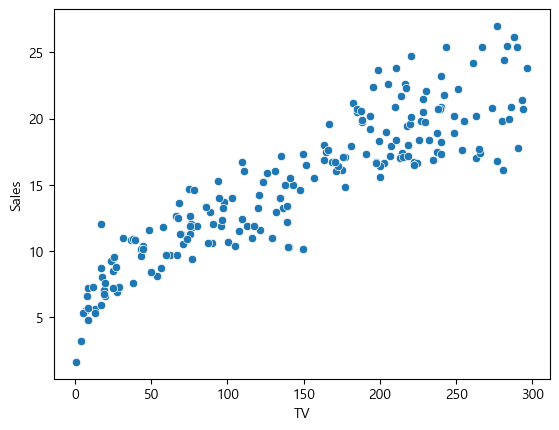
Sales와 매체들의 관계들을 다 함께 보려면 다음과 같다.
sns.pairplot(data=advertise, x_vars=["TV", "Radio", "Newspaper"], y_vars="Sales")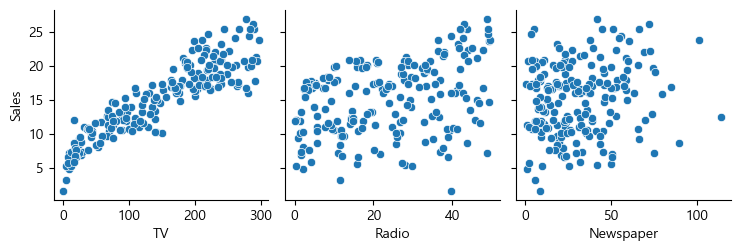
다른 것들은 예측율이 떨어질 것이지만 TV의 경우만 직선을 긋고 선형 회귀를 하기에 적합해보인다.
1.2.3. 상관관계
그렇다면 상관관계를 확인해보자.
round(advertise.corr(),2)| TV | Radio | Newspaper | Sales | |
|---|---|---|---|---|
| TV | 1.00 | 0.05 | 0.06 | 0.90 |
| Radio | 0.05 | 1.00 | 0.35 | 0.35 |
| Newspaper | 0.06 | 0.35 | 1.00 | 0.16 |
| Sales | 0.90 | 0.35 | 0.16 | 1.00 |
sns.heatmap(advertise.corr(), annot=True)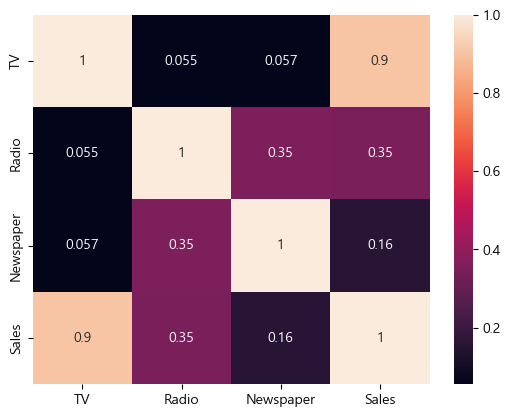
이를 보니 TV가 판매량에 미치는 영향이 가장 큼을 알 수 있다.
이제 보면 X값이 여러갠데, 다중 선형 회귀는 나중에 배울예정이니 단일 선형 회귀를 해보자.
가장 상관성이 높은 X를 TV로 두고, Y를 Sales로 두면 된다.
1.2.4. 데이터 셋 - train/test
먼저 설명 변수와 목표변수를 가져오자.
이때 설명 변수는 훈련때 fit을 위해 reshape를 해서 가져오자.
# Series -> 2차원
advertise_input=advertise["TV"].values.reshape(-1,1)
advertise_target=advertise["Sales"].values
print(advertise_input.shape, type(advertise_input))
print(advertise_target.shape, type(advertise_target))(200, 1) <class 'numpy.ndarray'>
(200,) <class 'numpy.ndarray'>X_train, X_test, Y_train, Y_test=train_test_split(advertise_input, advertise_target, random_state=42)
X_train.shape, Y_train.shape, X_test.shape, Y_test.shape((150, 1), (150,), (50, 1), (50,))이렇게 훈련세트와 테스트세트를 나눴다.
1.2.5. 선형 회귀 모델 훈련 및 평가
이제 선형회귀 알고리즘을 선택하고 훈련(fit)시켜주면 된다.
lr=LinearRegression()
lr.fit(X_train, Y_train)
이게 알아서 기울기와 절편을 다 구하고 최소제곱법 등을 다 한다.
그러면 이제 학습이 잘 됐는지 확인하자.
print("학습: ", lr.score(X_train, Y_train))
print("일반화: ", lr.score(X_test, Y_test))학습: 0.811194552365148
일반화: 0.7971876919875108이제 기울기와 절편을 확인하면,
print("기울기: ", lr.coef_)
print("절편: ", lr.intercept_)기울기: [0.05538653]
절편: 7.0988536801182751.2.6. 예측 시각화
이제 테스트 데이터로 예측을 하고 시각화하면 다음과 같다.
Y_test_pred=lr.predict(X_test)
sns.scatterplot(x=X_test[:,0], y=Y_test, label="실제값")
sns.scatterplot(x=X_test[:,0], y=Y_test_pred, color="red", label="예측값")
sns.lineplot(x=X_test[:,0], y=Y_test_pred, color="red")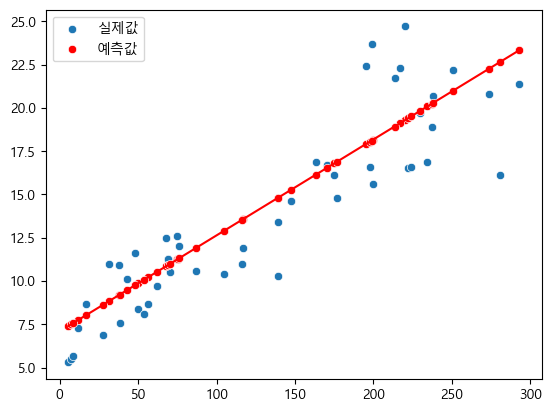
이렇게 80%정도로 직선을 잘 찾아냈다.
1.2.7. 평가 지표
- 목표변수(숫자형): 회귀
- 종류: R Square, MSE, RMSE, MAE
- 결정계수 : 회귀선이 데이터를 얼마나 잘 대변하는가 0~1
- 총변동, 회귀변동, 오차변동
여기 평가부분을 조금 알아야하는데, 분류는 평가지표가 정확도, 정밀도, 재현율, f1-score가 있었다.
선형회귀도 R Square, MSE, RMSE, MAE의 4개가 있다.
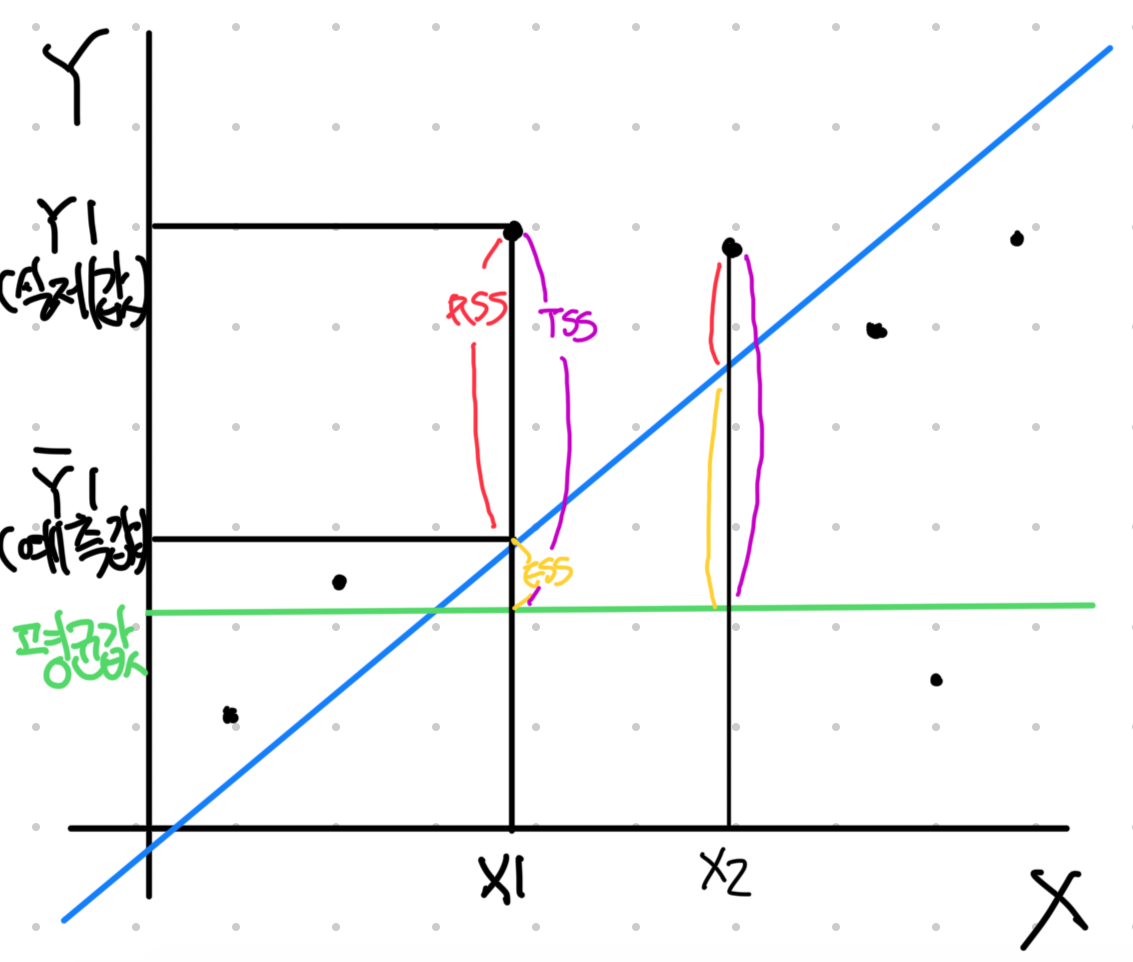
- R Square (결정계수 R): 설명변수를 얼마나 설명을 잘헀냐를 말함
- TSS: 총변동으로
- RSS: 오차변동으로
- ESS: 회귀변동으로 이며 회귀 변동이 클 수록 정답에 가까움
- MSE(Mean Square Error): 예측 값과 실제 값 간의 차이를 제곱하여 평균을 낸 값으로, 값이 작을수록 예측 성능이 좋음
- RMSE(Root Mean Square Error): 모델의 예측이 실제 데이터와 얼마나 차이가 나는지를 나타냄
- MAE(Mean Absolute Error): 절댓값을 사용해 예측 값과 실제 값 간의 차이를 더 직관적으로 알 수 있음
from sklearn.metrics import r2_score, mean_squared_error, root_mean_squared_error, mean_absolute_error(⭐ root_mean_squared_error는 scikit-learn 1.4 버전부터 사용가능)
Y_train_pred=lr.predict(X_train)
Y_test_pred=lr.predict(X_test)
# R^2 : 0~1 사이를 가지며, 1에 가까울수록 모델의 예측력이 좋다.
print("학습 R2: ", r2_score(Y_train, Y_train_pred)) # lr.score(X_train, Y_train)과동일
print("일반화 R2: ", r2_score(Y_test, Y_test_pred), "\n")
# 오차 평균 : 값이 낮을 수록 좋다. (10이하면 좋은 모델)
# 분류의 경우는 classification_report()를 사용하면 다 나왔지만 이는 하나씩 다 써줘야함
# 그래서 보통 이를 함수로 많이 만들어 놓음
print("학습 MSE: ", mean_squared_error(Y_train, Y_train_pred))
print("일반화 MSE: ", mean_squared_error(Y_test, Y_test_pred), "\n")
print("학습 RMSE: ", root_mean_squared_error(Y_train, Y_train_pred))
print("일반화 RMSE: ", root_mean_squared_error(Y_test, Y_test_pred), "\n")
print("학습 MAE: ", mean_absolute_error(Y_train, Y_train_pred))
print("일반화 MAE: ", mean_absolute_error(Y_test, Y_test_pred))학습 R2: 0.811194552365148
일반화 R2: 0.7971876919875108
학습 MSE: 5.136151288979386
일반화 MSE: 5.513351187165511
학습 RMSE: 2.2663078539729296
일반화 RMSE: 2.3480526372220685
학습 MAE: 1.8203818541994503
일반화 MAE: 1.8651146911099161이번 글에서는 선형회귀 중 단순 선형 회귀에 대해서 다뤘다.
다음 글에서는 다중 선형 회귀에 관해 간단하게 정리하겠다.
