
📌 사용 환경
Python 3.10.2
conda 24.9.0
JupyterLab 4.2.5
드디어 머신러닝이다.
지금까지 해온 프로그램은 컴퓨터가 정해진 기준대로 일을 한다.
예를들어 if문을 사용할때
age=int(input("나이를 입력해주세요: "))
if age >= 20 :
print("성인입니다.")이와 같이 20살이 넘으면 성인이라는 정해진 방식대로 일을했다.
그런데 머신러닝은 특징들을 주어주고 학습을 통해서 규칙을 찾는다.
예를들어, 음주여부나 대학생인지, 고등학생인지 등에 대한 특징들을 x변수에 주고
규칙을 찾아 y값을 내는 것이다.
즉 하나의 패턴을 찾는 거다.
지금은 간단한 예시였지만, 이런 데이터를 수없이 많이 받고 여기서 패턴을 찾는다.
그리고 이런 패턴을 찾기위해 컴퓨터가 학습을 한다.
예를들어 인간은 한달내내 강아지 사진을 보고 특징을 골라내는 게 불가능하다.
그런데 컴퓨터는 이게 가능하다.
인간은 다방면으로 다 하고 노하우가 쌓여서 전문가가 되는데,
머신러닝은 하나만 정확하게 가르쳐서 엄청나게 학습해서 그것에 전문가가 된다.
인간을 뛰어넘는다.
이게 머신러닝이다.
1. 머신러닝의 종류
그렇다면 머신러닝의 종류에 대해 알아보자.
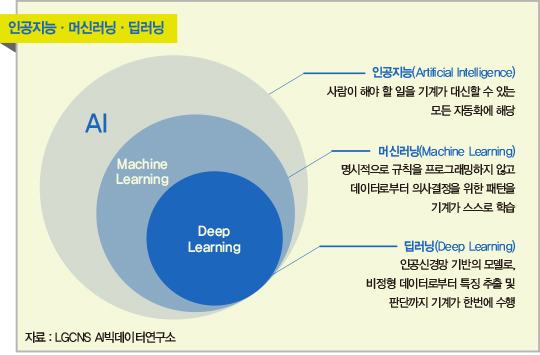
사실 머신러닝은 AI라는 학문 중 하나다.
그리고 머신러닝에는 수많은 알고리즘이 있는데 그 중 하나가 딥러닝이다.
이런 머신 러닝에는 크게 3가지 종류가 있는데,
지도 학습(Supervised Learning)과 비지도 학습(Unsupervised Learning), 강화 학습(Reinforcement Learning)이 있다.
(참고로 준지도학습(Semi-Supervised Learning) 이라는 것도 나왔다.)
그중 지금까지 지도 학습이 가장 많이 쓰이고 있고, 비지도와 강화학습은 연구의 단계에 있다.
따라서 지도학습 위주로 다루고 비지도에 대해서는 가볍게 다룰 예정이다.
따라서 딥러닝은 지도학습의 딥러닝이 있는 것이고, 비지도학습의 딥러닝이 있는 것이다.
이 모든 알고리즘을 다 배우지는 않고 몇개만 골라서 정리하겠다.
2. 지도학습(Supervised Learning)
지도학습은 정답이 있는 것을 말한다.
반대로 비지도학습은 정답이 없는 것이다.
기온이 30도일때 아이스크림이 10개가 팔렸고, 20도일때 5개가 팔렸고, 35도일때 15개가 팔렸다는 데이터가 있다.
그러면 이를 학습하여 40도일때는 몇개가 팔릴지를 "예측"하는 것이다.
이 예측하는 값을 목표변수(Y)라고 하며,
이 예측에 사용되는 값이 설명변수(X)이다.
즉 지도학습이란 이 목표변수(Y)와 설명변수(X)를 수식화해서, 새로운 설명변수(X)에 대해 목표변수(Y)를 예측하거나 분류하는 것이다.
이때 목표변수(Y)는 두가지로 나뉘는데,
연속형(숫자)의 값을 회귀(Regression) 라고 하며,
범주형(문자)의 값을 분류(Classification) 라고 한다.
지도 학습의 절차는 다음과 같다.
- 데이터 전처리
- 데이터 수집 및 정제: 데이터 구조 파악, 결측치 및 이상치 처리
- 데이터 변환: 정규화
- 데이터 분할: 훈련 데이터 및 검증 데이터
- EDA 시각화
- PDA, 학습 및 평가
- 훈련 데이터 생성: X, Y
- 알고리즘 선택
- 학습
- 평가
- 예측
2.3. 이진 분류 알고리즘
생선의 데이터를 학습하여 새로운 데이터를 주어 도미인지 빙어인지를 구분하는 이진 분류 알고리즘을 실습해보자.
먼저 필요한 라이브러리들을 import한다.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rc("font", family="Malgun Gothic")
plt.rcParams["axes.unicode_minus"]=False
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler
from sklearn.preprocessing import LabelEncoder, OneHotEncoder2.3.1. 데이터 전처리
2.3.1.1. 데이터 수집 및 정제
- 전처리 (통계에서 해온 DDA)
- 데이터 수집 및 정제: 데이터 구조 파악, 결측치 및 이상치 처리
- 데이터 변환: 정규화(normalization)
- 데이터 분할: 훈련 데이터 및 검증 데이터
- + EDA 시각화
fish_data=pd.read_csv("./data/mulgogi_data.csv")
fish_data.shape(49, 3)fish_data.head()| Species | Length | Weight | |
|---|---|---|---|
| 0 | Bream | 25.4 | 242.0 |
| 1 | Bream | 26.3 | 290.0 |
| 2 | Bream | 26.5 | 340.0 |
| 3 | Bream | 29.0 | 363.0 |
| 4 | Bream | 29.0 | 430.0 |
이제 이들을 학습하여
길이와 무게를 기준으로 이게 도미인지 빙어인지를 맞추는 것이다.
이들의 자료형을 보자.
fish_data.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 49 entries, 0 to 48
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Species 49 non-null object
1 Length 49 non-null float64
2 Weight 49 non-null float64
dtypes: float64(2), object(1)
memory usage: 1.3+ KB이상치가 있는지 통계량도 보자.
fish_data.describe().T| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Length | 49.0 | 27.055102 | 10.242804 | 9.8 | 14.3 | 31.0 | 34.5 | 41.0 |
| Weight | 49.0 | 444.500000 | 328.143233 | 6.7 | 19.7 | 500.0 | 700.0 | 1000.0 |
fish_data.describe(include="object").T| count | unique | top | freq | |
|---|---|---|---|---|
| Species | 49 | 2 | Bream | 35 |
fish_data["Species"].value_counts()Species
Bream 35
Smelt 14
Name: count, dtype: int64종류가 2개가 있는데 도미가 더 많다.
2.3.1.2. 시각화
그러면 이들의 시각화를 해보자.
sns.countplot(data=fish_data, x="Species")<Axes: xlabel='Species', ylabel='count'>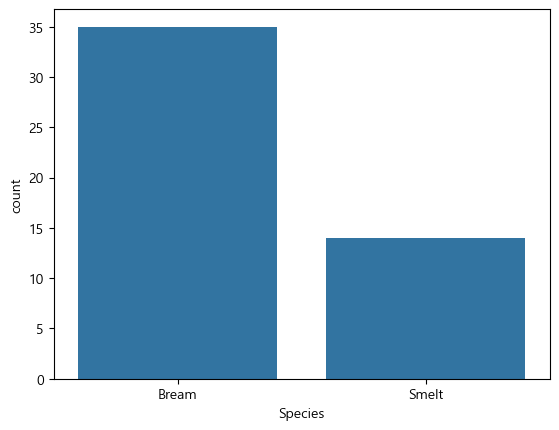
이렇게 도미가 빙어보다 많은 것을 알 수 있고,
sns.scatterplot(data=fish_data, x="Length", y="Weight", hue="Species")<Axes: xlabel='Length', ylabel='Weight'>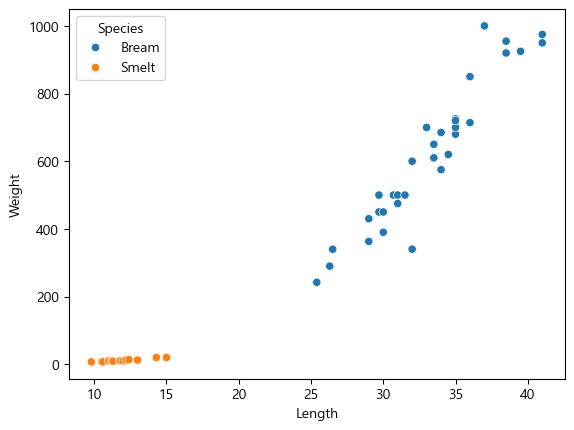
빙어가 더 작고, 빙어가 더 크다는 것을 알 수 있다.
그리고 빙어도 조금 씩 증가하는 거 같긴하지만,
도미를 보니 확실하게 길이가 증가하면 무게도 증가한다는 것을 알 수 있다.
fishdata를 좌표로 그리는데, 실제 머신러닝에서는 x값이 많다.
(지금은 Length와 Weight 두개다._)
Length를 X1, Weight를 X2라고 했을때, 목표변수인 Species Y를 구하는 것이다.
그러면 이는 3차원이 된다. (X3부터는 그리지 못한다.)
근데 3차원 좌표를 그릴 수 없으니 scatterplot에서 hue를 이용하여 Length가 X1, Weight가 X2, 각 점들을 Y로 표현한 것이다.
또 단일 변수는 histplot으로 볼 수 있는데, 하나하나 뽑지말고 pairplot으로 보자.
sns.pairplot(data=fish_data, hue="Species")<seaborn.axisgrid.PairGrid at 0x22079dcdd00>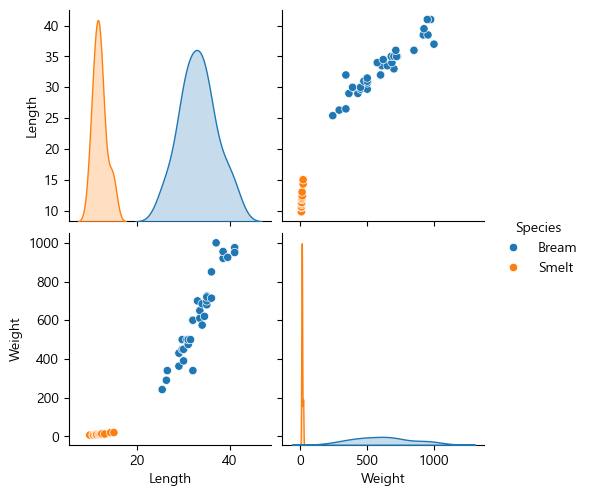
이제 목적은 길이와 무게를 이용해서 이게 도미인지 빙어인지를 맞추는 예측문제를 하는거다.
그런데 모든 예측문제를 할떄, 모든 데이터들은 이렇게 전처리를 해야한다.
이런 데이터를 가져와서 이런 형태의 그래프르 모양으로 가져왔고,
그렇다면 이제 도미인지 빙어인지를 맞추려면 먼저 상관성이 있는지 알아야한다.
fish_data_num=fish_data.select_dtypes(include="number")
fish_data_num.corr().round(2)| Length | Weight | |
|---|---|---|
| Length | 1.00 | 0.96 |
| Weight | 0.96 | 1.00 |
서로 연관성이 굉장히 강하다.
따라서 이를 가지고 예측을 할 수 있겠다. 라고 생각하면 된다.
DDA, EDA, CDA를 배웠는데,
CDA에서의 검증을 했었는데 머신러닝은 이게 아니다.
머신러닝은 검증이 필요할때만 하고, 셈플데이터를 가지고 모집단을 잘 추론하는가가 분석이지만,
주어진 데이터를 가지고(샘플이던, 모집단이건) 얼마나 예측을 잘하는지가 목적이다.
즉 CDA는 필요할때만 진행한다.
이제 PDA, 예측을 해야한다.
2.3.2. 학습 및 평가 - PDA
- 데이터 훈련 -> 학습 -> 평가 -> 예측
- 훈련 데이터 생성: X, Y
- 알고리즘 선택 -> 분류: KNN -> 학습(훈련)
- 평가 -> 정확도(%) -> 90% -> 0.9
- 예측 -> 새로운 데이터를 넣어줌
head()를 찍어보니
fish_data.head().T이거를 학습하는 거다.
나오는 species가 y가 되고 길이와 무게가 x1, x2가 된다.
그러면 먼저 여기서 설명변수(x)와 목표변수(y)를 나눠줘야한다.
훈련 데이터: training data -> fish_data: x / y
X=fish_data[["Length", "Weight"]] # 설명번수, input, 입력데이터
Y=fish_data["Species"] #목표변수, output , target, 정답(출력) 데이터
X.shape, Y.shape, type(X), type(Y)((49, 2), (49,), pandas.core.frame.DataFrame, pandas.core.series.Series)2.3.2.1. ⭐ K-Nearest Neighbors
- KNeighborsClassifier(): k-최근접 이웃 분류 모델을 만드는 사이킷런 클래스
- n_neighbors: 이웃의 개수 지정
- p: 거리 재는 방법 (default: 유클리디안 거리(2)
맨해튼 거리(1):
유클리디안 거리(2):- 공통적으로 사용되는 함수들
- fit(): 훈련 / 모델 훈련시 사용하는 메서드
- score(): 성능 / 훈련된 모델의 성능 측정시 사용하는 메서드 (정확도)
- predict(): 예측 / 모델 훈련하고 예측시 사용하는 메서드
- API 문서: https://scikit-learn.org/stable/api/index.html
그러면 이제 분류 알고리즘 중에 KNN을 사용할 것이다.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScalerknn=KNeighborsClassifier(n_neighbors=5) # 하이퍼 파라미터 -> 개발자가 직접 정함
# 학습 또는 훈련
knn.fit(X, Y) # X는 DF, Y는 Series로 들어갔음 / numpy아니면 pandas로 들어감
# 정확도
knn.score(X, Y) # (정확히 맞힌 개수) / (전체 데이터 개수)1.0이제 예측을 한다.
훈련시 X와 Y를 pandas로 넣어주었기 때문에 예측부분에도 이를 맞춰야한다.
new_df=pd.DataFrame(data=[[30,500]], columns=["Length","Weight"])
new_df| Length | Weight | |
|---|---|---|
| 0 | 30 | 500 |
knn.predict(new_df)array(['Bream'], dtype=object)그럼 이를 시각화해보면 다음과 같다.
sns.scatterplot(data=fish_data, x="Length", y="Weight", hue="Species")
sns.scatterplot(data=new_df, x="Length", y="Weight", marker="o", color="red", s=100)<Axes: xlabel='Length', ylabel='Weight'>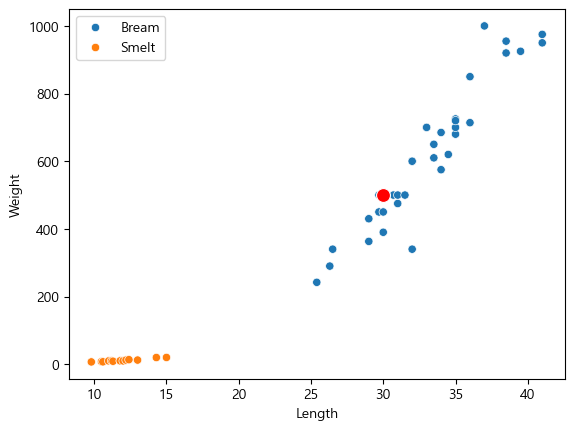
이 주위의 5개가 Bream이기 때문에 Bream으로 분류된다.
이를 실제 거리로 보면,
d, i=knn.kneighbors(new_df)
print("가장 가까운 이웃과의 거리 계산 값:", d)
print("가장 가까운 이웃의 인덱스:", i)가장 가까운 이웃과의 거리 계산 값: [[ 0.3 0.7 1. 1.5 25.01999201]]
가장 가까운 이웃의 인덱스: [[ 6 9 11 12 10]]그러면 이 각 인덱스를 찾아가면 X1, X2 값이 있는 것이다.
이를 시각화 할 수 있다.
sns.scatterplot(data=fish_data, x="Length", y="Weight", hue="Species")
sns.scatterplot(data=new_df, x="Length", y="Weight", marker="o", color="red", s=100)
for idx in i:
sns.scatterplot(data=fish_data, x=fish_data.loc[idx, "Length"], y=fish_data.loc[idx, "Weight"], marker="^", color="green")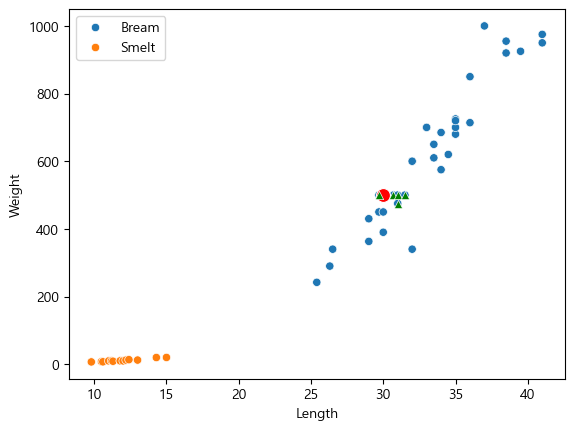
2.3.2.2. 데이터 분할
훈련 세트와 테스트 세트
- train_test_split
- test_size=0.3 # 테스트 사이즈 (default)
- shuffle=True # 무작위로 섞기 (default)
- random=stat=1234 # 결과를 동일하게 유지
방금은 30, 500의 데이터를 넣어서 확인했는데, 이렇게 한개만 본다고 예측을 잘했다고 할 수 있을까? 아니다, 여러 값들을 넣어줘야한다.
그런데 예측 할때마다 데이터를 새롭게 넣고 그럴 수는 없다.
따라서 데이터셋을 이용해야한다.
지금 데이터는 49개가 있다.
fish_data.shape()(49, 3)이 데이터를 다 훈련데이터로 썼다.
그런데 학습결과가 100%가 나왔다.
그런데 이게 잘 분류하는지를 확인할때 매번 new_df로 만들어서 테스트할 수는 없다.
그래서 49개를 훈련데이터와 테스트 데이터로 나눈다.
만약 100개라면 70개 30개로 나눠서 각각 훈련데이터와 테스트 데이터로 나누는 것이다.
이 비율은 사용자가 정하며 보통 훈련데이터의 비율이 더 크다.
이제 만약 8:2로 나누겠다고 정했다.
그런데 이를 과연 어떻게 나눌까? 테스트 데이터와 트레이닝 데이터가 골고루 잘 섞여야한다.
도미와 빙어가 골고루 섞여야한다.
따라서 이를 랜덤하게 섞어주는 함수가 있다.
train_test_splot(X, Y)
이는 값(X와 Y)을 총 4개로 반환한다.
훈련X, 훈련Y, 테스트X, 테스트Y값으로.
from sklearn.model_selection import train_test_splitX_train, X_test, Y_train, Y_test=train_test_split(X, Y, random_state=1234, test_size=0.2)
X_train.shape, X_test.shape, Y_train.shape, Y_test.shape((39, 2), (10, 2), (39,), (10,))traintest_split이 이렇게 4개의 값을 튜플로 반환하여 unpacking되어 각각 할당된다.
(나중에 DL에서는 검증 data인 validation data라는 것도 있다._)
이제 분류 알고리즘을 이용하여 학습 및 정확도를 평가해보자.
# 분류 알고리즘
knn=KNeighborsClassifier()
# 학습
knn.fit(X_train, Y_train)
정확도를 평가하자.
knn.score(X_train, Y_train) # 학습1.0이번에는 테스트 데이터로 일반화 정확도를 확인하자.
knn.score(X_test, Y_test) # 일반화1.0지금은 데이터문제로 다 100이 나오는데,
실제로는 다르는데, 학습이 98이면 일반화가 70일 수는 없다. 거의 비슷해야한다.
또 학습 정확도가 일반화 정확도보다 항상 커야한다.
이제 정확도도 잘 평가했으니 새로운 데이터를 넣어 예측을 해보자.
new_df=pd.DataFrame(data=[[30,500]], columns=["Length","Weight"])
knn.predict(new_df)array(['Bream'], dtype=object)2.3.2.3. 데이터 변환(Scalling) - 연속형
- Scalling: 연속형 데이터의 Scale을 맞추는 작업
- Standard Scaler: 정규분포일때, 데이터가 대략 대칭적일때, 이상치가 많지 않을때
- 모든 숫자 데이터를 평균을 0으로, 표준편차를 1으로 만듬
- Min Max Scaler: 비선형 모델, 신경망
- 모든 숫자 데이터를 최소값을 0으로, 최대값을 1으로 만듬
- Robust Scaler: 이상치가 많을때
- 모든 숫자 데이터를 중앙값을 0으로, IQR을 1로 만듬
필요한 것들 import
from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler
이중 표준화를 먼저 진행한다.
표준화란 기준을 맞추는 것이다.
우리나라 평균 키가 175이고, 네덜란드 평균 키가 190인데,
175라는 사람이 190측으로 가서 큰지 작은지 비교하는 것은? 맞지 않다. 스케일이 다르다.
따라서 이럴때 표준화라는 것을 해줘야 한다.
즉 두 집단간 차이가 있을 수 밖에 없는데 이럴때 제대로 예측할 수가 없다.
따라서 표준화를 해주는데, 표준화의 공식은 다음과 같다.
Z-score = (각 데이터-모집단평균)/표준편차
따라서 항상 두 집단간의 비교를 할때는? 표준화를 해줘야한다.
new_df=pd.DataFrame(data=[[25,150]], columns=["Length","Weight"])
knn.predict(new_df)array(['Smelt'], dtype=object)이 값이 제대로 예측했을까?
두 특성인 길이와 무게의 값이 놓은 범위가 다르기 때문에
Standard Scaler -> 표준화 평균은 0, 표준화 표준편차는 1
Z-score는 표준점수
X_train, X_test, Y_train, Y_test=train_test_split(X, Y, test_size=0.2, random_state=1234)
# 표준화 작업
scaler=StandardScaler() # 표준화 객체 생성
scaler.fit(X_train) # 평균과 표준편차
# Z-score
X_train_scaler=scaler.transform(X_train)
X_test_scaler=scaler.transform(X_test)
knn=KNeighborsClassifier()
knn.fit(X_train_scaler, Y_train)
print("학습: ", knn.score(X_train_scaler, Y_train))
print("일반화: ", knn.score(X_test_scaler, Y_test))학습: 1.0
일반화: 1.0즉 전체 순서는 이와 같다.
1. Pandas에서 학습해줄 X와 Y 값 뽑아오기
2. train_test_split으로 각각 학습데이터와 테스트데이터(_train, _test) 로 나누기
3. Scalling으로 X값을 바꿔주기
그렇다면 이제 앞서 다르게 나온 값을 다시 가져와서 예측해보자.
그런데 먼저 0~1로 Z-score로 바꿨으니까 이도 25,100을 바꿔서 스케일을 맞춰줘야한다.
new_df=pd.DataFrame(data=[[25,150]], columns=["Length","Weight"])
new_df_scaler=scaler.transform(new_df)
knn.predict(new_df_scaler)array(['Bream'], dtype=object)이렇게 제대로 예측한 결과가 나온다.
이번에는 MinMaxScaler와 Robust Scaler를 써보자.
설명변수 X
data={'계약기간': [12, 24, 36, 48, 60],
'비용': [10000000, 25000000, 50000000, 75000000, 100000000],
'연령': [20, 30, 40, 50, 80]}
df=pd.DataFrame(data)
df| 계약기간 | 비용 | 연령 | |
|---|---|---|---|
| 0 | 12 | 10000000 | 20 |
| 1 | 24 | 25000000 | 30 |
| 2 | 36 | 50000000 | 40 |
| 3 | 48 | 75000000 | 50 |
| 4 | 60 | 100000000 | 80 |
먼저 Standard Scaler다.
모든 숫자 데이터를 평균을 0으로, 표준편차를 1으로 만든다.
standard=StandardScaler()
standard_scaler=standard.fit_transform(df)
standard_scaler_df=pd.DataFrame(standard_scaler, columns=df.columns)
standard_scaler_df| 계약기간 | 비용 | 연령 | |
|---|---|---|---|
| 0 | -1.414214 | -1.286384 | -1.165543 |
| 1 | -0.707107 | -0.826961 | -0.679900 |
| 2 | 0.000000 | -0.061256 | -0.194257 |
| 3 | 0.707107 | 0.704448 | 0.291386 |
| 4 | 1.414214 | 1.470153 | 1.748315 |
이번에는 MinMaxScaler다.
모든 숫자 데이터를 최소값을 0으로, 최대값을 1으로 만든다.
min_max=MinMaxScaler()
min_max_scaler=min_max.fit_transform(df)
min_max_scaler_df=pd.DataFrame(min_max_scaler, columns=df.columns)
min_max_scaler_df| 계약기간 | 비용 | 연령 | |
|---|---|---|---|
| 0 | 0.00 | 0.000000 | 0.000000 |
| 1 | 0.25 | 0.166667 | 0.166667 |
| 2 | 0.50 | 0.444444 | 0.333333 |
| 3 | 0.75 | 0.722222 | 0.500000 |
| 4 | 1.00 | 1.000000 | 1.000000 |
RobustScaler다.
모든 숫자 데이터를 중앙값을 0으로, IQR을 1으로 만든다.
robust=RobustScaler()
robust_scaler=robust.fit_transform(df)
robust_scaler_df=pd.DataFrame(robust_scaler, columns=df.columns)
robust_scaler_df| 계약기간 | 비용 | 연령 | |
|---|---|---|---|
| 0 | -1.0 | -0.8 | -1.0 |
| 1 | -0.5 | -0.5 | -0.5 |
| 2 | 0.0 | 0.0 | 0.0 |
| 3 | 0.5 | 0.5 | 0.5 |
| 4 | 1.0 | 1.0 | 2.0 |
2.3.2.4. 데이터 변환(Encoding) - 범주형
Label Encoding
One Hot Encoding
지금까지는 이런 연속형인 숫자 데이터들을 처리했다.
그런데 만약 범주형이면 어떻게할까?
컴퓨터는 모든 데이터를 0과 1로 읽기때문에 범주형 데이터를 연속형 숫자 데이터로 변환해야한다.
이를 Encoding이라고 한다.
이 Encoding에는 Label Encoding과 One Hot Encoding이 있다.
그런데 이렇게 연속형으로 바꿀때, 등급을 가지면 안된다.
예를들어 남자와 여자라면 0과 1로 표현할 수 있다. 그리고 이를 Label Encoding이라고 하는데,
그런데 만약 이 종류가 여러가지라면,
장바구니에 사과, 블루베리, 바나나, 귤 등이 있을때, Label Encoding으로 하면 0,1,2,3 이런식으로 바뀌는데,
이렇게 등급을 가지면 안된다.
따라서 이럴때는 One Hot Encoding으로 바꿔야한다.
이때는 장바구니라는 컬럼에서 장바구니사과, 장바구니블루베리, 장바구니바나나, 장바구니귤과 같이 총 4개의 컬럼들로 바뀌고,
각각 자신에게 해당하는 부분만 1, 아닌부분은 0으로 바꿔준다.
⭐ CPU와 GPU
CPU 한대에 프로그램을 여러가지를 켜놨다.
줌, 주피터노트북, 디스코드 등..
그러면 이 CPU 는 이 작업을 동시에 하는 것이 아니라 스케쥴에 맞춰서 진행한다.
줌 한번, 주피터노트북 한번, 이런식으로. 이를 멀티테스킹이라고 한다.
근데 요즘에는 쿼드코어라고하여 4개가 하나씩 맡아서 진행한다. 이게 CPU의 역할이다.그렇다면 GPU는?
CPU를 통해서 주기억장치(RAM)에 a=10이라는게 들어가는데, CPU가 다리역할을 한다.
그러면 우리가 0과 1로 계속해서 계산하는데, 이걸 CPU가 계산하지 않는다.
바로 GPU가 진행한다.
이는 그래픽 드라이버에 있는데, 화면은 각 0~255의 값을 계속해서 구성하며 화면을 보여주는데,
따라서 연산이 빠르다. 그러니 0과 1을 계속 반복하니까 이를 GPU에서 진행한다.
이를 위해서도 라이브러리 import가 필요하다.
from sklearn.preprocessing import LabelEncoder, OneHotEncoderdata={
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Gender': ['female', 'male', 'male', 'male'],
'City': ['New York', 'Los Angeles', 'New York', 'Chicago']
}
person=pd.DataFrame(data)
person| Name | Gender | City | |
|---|---|---|---|
| 0 | Alice | female | New York |
| 1 | Bob | male | Los Angeles |
| 2 | Charlie | male | New York |
| 3 | David | male | Chicago |
여기서 보면 우선 이름은 학습시킬 일이 없고, 성별과 도시를 보자.
성별은 남성 여성이기에 Label Encoding, 도시는 One Hot Encoding으로 진행한다.
Gender컬럼을 지우고 0과 1로 치환해도 되는데 필드를 새로 만들어보자.
label=LabelEncoder()
person["Gender_label"]=label.fit_transform(person["Gender"])
person| Name | Gender | City | Gender_label | |
|---|---|---|---|---|
| 0 | Alice | female | New York | 0 |
| 1 | Bob | male | Los Angeles | 1 |
| 2 | Charlie | male | New York | 1 |
| 3 | David | male | Chicago | 1 |
이렇게 성별은 문제없이 진행했다.
그런데 City는 다음과 같다.
먼저 label encoding으로 바꿔준다.
city_label=label.fit_transform(person["City"])
city_labelarray([2, 1, 2, 0])이렇게 나왔는데 이렇게 순서를 가지면 안되기 때문에, One Hot Encoding을 해줘야하는데, 이는 2차원으로만 받는다.
따라서 2차원으로 바꿔야한다.
city_label=city_label.reshape(-1, 1) # 2차원으로 변경
city_labelarray([[2],
[1],
[2],
[0]])onehot=OneHotEncoder()
city_onehot=onehot.fit_transform(city_label)
city_onehot<4x3 sparse matrix of type '<class 'numpy.float64'>'
with 4 stored elements in Compressed Sparse Row format>city_onehot=city_onehot.toarray().astype(int)
city_onehotarray([[0, 0, 1],
[0, 1, 0],
[0, 0, 1],
[1, 0, 0]])column_name=onehot.get_feature_names_out(["City"]) #컬럼값 뽑기
column_namearray(['City_0', 'City_1', 'City_2'], dtype=object)이제 이들을 결국에는 데이터프레임으로 변환해야한다.
city_onehot_df=pd.DataFrame(city_onehot, columns=column_name)
city_onehot_df| City_0 | City_1 | City_2 | |
|---|---|---|---|
| 0 | 0 | 0 | 1 |
| 1 | 0 | 1 | 0 |
| 2 | 0 | 0 | 1 |
| 3 | 1 | 0 | 0 |
이제 원본 데이터 프레임과 원핫인코딩 결과를 결합한다.
pd.concat([person, city_onehot_df], axis=1)| Name | Gender | City | Gender_label | City_0 | City_1 | City_2 | |
|---|---|---|---|---|---|---|---|
| 0 | Alice | female | New York | 0 | 0 | 0 | 1 |
| 1 | Bob | male | Los Angeles | 1 | 0 | 1 | 0 |
| 2 | Charlie | male | New York | 1 | 0 | 0 | 1 |
| 3 | David | male | Chicago | 1 | 1 | 0 | 0 |
굉장히 복잡하다.
그런데 이걸 한번에 해결해주는 것이 있다.
Pandas에서 제공하는 get_dummies()함수다.
그러니 One Hot Encoding의 내부 과정은 이해하고, 간편하게 판다스를 사용하면 된다.
person| Name | Gender | City | Gender_label | |
|---|---|---|---|---|
| 0 | Alice | female | New York | 0 |
| 1 | Bob | male | Los Angeles | 1 |
| 2 | Charlie | male | New York | 1 |
| 3 | David | male | Chicago | 1 |
person=pd.get_dummies(person, columns=["City"])
person| Name | Gender | Gender_label | City_Chicago | City_Los Angeles | City_New York | |
|---|---|---|---|---|---|---|
| 0 | Alice | female | 0 | False | False | True |
| 1 | Bob | male | 1 | False | True | False |
| 2 | Charlie | male | 1 | False | False | True |
| 3 | David | male | 1 | True | False | False |
이 결과로 컴퓨터 내부적으로 False는 0이고 True는 1이기 때문에 간단하게 해결가능하다.
💪 객관식 퀴즈
Q1. 지도 학습(Supervised Learning)의 특징으로 옳은 것은?
A) 정답이 없는 데이터를 사용하여 패턴을 찾는다.
B) 입력 값에 대해 출력 값을 예측할 수 있다.
C) 데이터가 너무 많을수록 학습의 정확도가 떨어진다.
D) 데이터의 목표변수(Y)가 범주형 값이 아닌 연속형 값일 경우 회귀 문제가 된다.
-
비지도 학습(Unsupervised Learning)에서 일반적으로 사용하는 알고리즘은 무엇인가요?
A) K-Nearest Neighbors (KNN)
B) Support Vector Machines (SVM)
C) K-Means Clustering
D) Random Forest
-
다음 중 "표준화(standardization)" 작업을 진행할 때 가장 중요한 이유는 무엇인가요?
A) 모델의 성능을 향상시키기 위해서
B) 데이터의 범위를 0과 1 사이로 변환하기 위해서
C) 서로 다른 범위의 특성 값들이 동일한 기준으로 비교 가능하도록 만들기 위해서
D) 데이터의 결측치를 처리하기 위해서
-
다음 중 K-Nearest Neighbors(KNN) 분류 알고리즘의 특징으로 옳지 않은 것은 무엇인가요?
A) 거리 기반으로 데이터를 분류한다.
B) 학습이 매우 빠르다.
C) 테스트 데이터와 훈련 데이터의 거리를 계산하여 분류한다.
D) 하이퍼파라미터로 'k' 값의 선택이 중요하다.
-
다음 중
train_test_split함수에서test_size=0.2로 설정했을 때, 전체 데이터 중 몇 퍼센트가 테스트 데이터로 사용되나요?A) 20%
B) 80%
C) 50%
D) 70%
-
다음 중 "One Hot Encoding"의 특징으로 옳은 것은 무엇인가요?
A) 범주형 변수를 0과 1로 변환한다.
B) 범주형 변수를 순서가 있는 숫자로 변환한다.
C) 각 범주를 독립적인 컬럼으로 나눈다.
D) 연속형 변수를 범주형으로 변환한다.
-
다음 중 머신러닝의 '피처 엔지니어링(Feature Engineering)'의 주된 목적은 무엇인가요?
A) 데이터를 클러스터링하여 그룹을 나눈다.
B) 모델을 선택하고 하이퍼파라미터를 조정한다.
C) 모델에 사용할 특성(변수)을 선택하고 변환한다.
D) 학습 데이터를 테스트 데이터로 나눈다.
-
다음 중
StandardScaler가 수행하는 작업은 무엇인가요?A) 데이터의 모든 값을 최소값과 최대값 사이로 변환한다.
B) 데이터를 표준정규분포로 변환한다.
C) 결측치를 처리하고 이상치를 제거한다.
D) 각 특성의 단위 차이를 맞추기 위해 데이터를 변환한다.
-
다음 중
K-Nearest Neighbors(KNN)알고리즘에서 "k" 값을 너무 크게 설정하면 발생할 수 있는 문제는 무엇인가요?A) 모델이 과적합(overfitting) 된다.
B) 모델이 과소적합(underfitting) 된다.
C) 훈련 데이터에 비해 테스트 데이터의 정확도가 높아진다.
D) 학습 속도가 매우 느려진다.
-
다음 중 "훈련 데이터(training data)"와 "테스트 데이터(test data)"를 분리하는 주된 목적은 무엇인가요?
A) 훈련 데이터의 크기를 줄이기 위해서
B) 모델이 새로운 데이터를 얼마나 잘 예측할 수 있는지 평가하기 위해서
C) 모델의 정확도를 높이기 위해서
D) 훈련 데이터를 표준화하기 위해서
Q1. 설명변수(X)와 목표변수(Y)의 차이는?
1) 목표변수는 예측하려는 값이고, 설명변수는 그 값을 예측하기 위한 데이터다.
2) 목표변수는 데이터를 수집하는 값이고, 설명변수는 데이터 분석을 위한 값이다.
3) 목표변수는 데이터의 종류이고, 설명변수는 데이터의 크기다.
4) 목표변수는 연속적인 값만 포함하고, 설명변수는 범주형 값만 포함한다.
A1. 1
Q2. 회귀(Regression)와 분류(Classification)의 차이로 옳은 것은?
1) 회귀는 범주형 데이터를 예측하고, 분류는 연속형 데이터를 예측한다.
2) 회귀는 연속형 데이터를 예측하고, 분류는 범주형 데이터를 예측한다.
3) 회귀는 데이터를 분류하는 알고리즘이고, 분류는 데이터를 예측하는 알고리즘이다.
4) 회귀와 분류는 모두 연속형 데이터만 예측한다.
A2. 2)
Q3. KNN 알고리즘에서 k 값의 의미는?
1) 데이터셋에서 학습할 데이터의 비율을 나타낸다.
2) 예측할 데이터와 가장 가까운 k개의 이웃을 고려하여 예측을 수행한다.
3) 알고리즘이 예측한 정확도의 최소값을 나타낸다.
4) 학습 데이터의 크기를 나타낸다.
A3. 2
Q4. KNN 알고리즘의 특징으로 옳지 않은 것은?
1) 거리 기반으로 데이터를 분류한다.
2) 테스트 데이터와 훈련 데이터의 거리를 계산하여 분류한다.
3) 하이퍼파라미터로 k 값의 선택이 중요하다.
4) k값은 훈련 데이터의 크기를 나타낸다.
A4. 4
**Q5. StandardScaler에 대한 설명으로 옳은 것은?
1) 데이터의 각 변수들 간의 상관성을 최소화한다.
2) 데이터를 평균 0, 표준편차 1로 표준화한다.
3) 범주형 데이터를 연속형 데이터로 변환한다.
4) 이상치를 제거한다.
Q5. 2
Q6. 훈련 데이터와 테스트 데이터의 차이는?
1) 훈련 데이터는 모델을 평가하는 데 사용되고, 테스트 데이터는 모델 학습에 사용된다.
2) 훈련 데이터는 모델을 학습하는 데 사용되고, 테스트 데이터는 모델을 평가하는 데 사용된다.
3) 훈련 데이터는 범주형 데이터를 포함하고, 테스트 데이터는 연속형 데이터를 포함한다.
4) 훈련 데이터와 테스트 데이터는 동일한 데이터를 포함한다.
A6.: 2
Q7. One Hot Encoding의 특징은?
1) 범주형 데이터를 0과 1의 숫자 형태로 변환하고, 각 값은 숫자 순서대로 할당된다.
2) 범주형 데이터를 여러 개의 열로 나누어, 해당하는 범주에만 1을 부여하고 나머지는 0으로 표시한다.
3) 범주형 데이터를 표준화한다.
4) 연속형 데이터를 범주형 데이터로 변환한다.
A7.: 2
Q8. 훈련 데이터 생성에서 X와 Y의 역할은?
1) X는 모델의 학습 속도를 조정하고, Y는 모델의 정확도를 평가한다.
2) X는 설명변수이고, Y는 목표변수다.
3) X는 목표변수이고, Y는 설명변수다.
4) X와 Y는 모두 학습된 데이터로만 구성된다.
A8. 2
