Abstract
VLM의 사전학습 비용은 거대 모델들의 end-to-end 학습 때문에 매우 커졌다. 해당 논문에서는 사전학습된 이미지와 언어 모델을 고정시킨 상태에서 모델을 bootstrap하는 BLIP-2를 제시한다. BLIP-2는 두 모달리티의 차이를 두 단계의 lightweight Querying Transformer를 이용하여 연결시켜준다. 첫 번째 stage에서는 고정한 이미지 인코더 모델을 기반으로 vision-languauge 표현을 향상시킨다. 두 번째 stage에서는 언어 모델을 고정시킨 채 vision-to-language 생성 능력을 향상시킨다. BLIP-2 모델은 기존 방식보다 학습 파라미터를 현저하게 줄임에도 sota를 달성한다. 예시로, Flamingo80B 모델보다 54분의 1 정도 학습 파라미터를 가지며 8.7%의 성능 우위를 지닌다.
Introduction
vision-language-pretraining 연구는 근래 계속해서 크기를 키워가며 발전핸왔다. 많은 sota모델들이 사전학습을 위해 큰 계산 비용을 소모한다. Vision-Language 연구는 vision과 language간의 연구로 기존 각각의 연구에서 얻어낼 수 있다. 우리는 bootstrapping 기반으로 일반적이고 효율적인 방식을 제시한다. 비젼 모델은 시각적 특징을 표현하고 언어 모델은 언어 생성 기능과 general 특징을 지닌다. 비용 문제와 catastophic forgetting를 해결하기 위해 통합 사전 모델은 고정된다.
각각의 사전 모델을 잘 이용하는 것은 cross-modal에 대한 align을 맞춰주는 것이다. 그러나 LLM은 학습하며 이미지를 본적이 없다. FLAMINGO는 이 문제를 해결하기 위해 image-to-text generation loss를 사용하였으나 modality gap을 극복하는데 역부족이었다.
우리는 two-stage로 사전학습된 Q-Former로 이를 해결한다. Q-Former는 고정된 이미지 특징으로 부터 학습하는 쿼리 벡터를 이용한다. 이는 시각적 특징을 LLM이 유용하게 쓸 수 있도록 반환한다. 첫 stage에서 Q-Former가 언어 모델이 잘 받아들이는 시각적 이미지를 내보내도록 학습을 하고 두 번째 stage에서는 Q-Former를 LLM에 연결하여 Q-Former를 다시 학습한다.
-
BLIP-2는 Q-Former를 이용하여 이미지 모델과 언어 모델을 고정시켜 효율적으로 이용한다.
-
강력한 LLM에 따라, BLIP-2는 언어 지시에 따라 이미지 이해를 기반으로 텍스트를 생성한다.
-
BLIP-2는 고정된 모델과 효율적인 Q-Former를 기반으로 가벼우면서 SOTA를 달성한다.
Related Work
BLIP-2 논문에서는 기존의 vision-language pretraining 방식들을 크게 두 가지로 나누어 설명한다. 각각의 방식은 시각 정보와 언어 정보를 얼마나 잘 연결하고, 기존 사전학습된 모델들을 얼마나 효율적으로 활용하는지를 기준으로 나뉜다.
2.1 End-to-End Vision-Language Pre-training
End-to-end vision-language pretraining은 대규모 이미지-텍스트 쌍 데이터를 이용해 멀티모달 모델을 처음부터 통합적으로 학습하는 방식이다. 이 방식은 다양한 downstream task에서 좋은 성능을 내는 멀티모달 foundation 모델을 만드는 것을 목표로 한다.
대표적인 모델 구조는 다음과 같다:
Dual-encoder: 이미지와 텍스트를 각각 독립적으로 인코딩 (ex. CLIP)
Fusion-encoder: 이미지와 텍스트를 결합해 함께 인코딩
Encoder-decoder: 이미지로부터 정보를 추출하고 텍스트를 생성
Unified transformer: 하나의 Transformer로 이미지와 텍스트를 통합 처리
학습 목표로는 아래 세 가지가 대표적이다:
이미지-텍스트 대조학습 (contrastive learning)
이미지-텍스트 매칭 학습 (matching)
텍스트 생성 기반의 (마스킹된) 언어 모델링 (MLM)
이러한 방식은 학습 효율성과 성능 측면에서 발전해왔지만, 몇 가지 한계도 존재한다.
모델 크기 증가에 따라 계산 비용이 매우 높아진다.
기존의 강력한 단일 모달 사전학습 모델(특히 LLM)을 재활용하기 어렵다.
즉, end-to-end 방식은 강력하지만 융통성이 떨어진다는 단점이 있다.
2.2 Modular Vision-Language Pre-training
반면 modular 방식은 기존에 잘 학습된 모델들을 활용하는 방향이다. 이 방식은 필요한 부분만 학습하고 나머지는 freeze하여 학습 비용을 절감하고 유연성을 높인다.
일부 방법은 이미지 인코더만 freeze하고, 예를 들어 object detector로부터 추출한 피처를 활용한다. 최근에는 LiT처럼 CLIP의 이미지 인코더를 freeze한 방식도 등장했다.
다른 방법은 LLM을 freeze하여 자연어 생성을 담당하게 하고, 이미지 정보를 그에 맞게 정렬(alignment)한다.
예를 들어:
Frozen은 이미지 인코더를 LLM의 soft prompt로 사용하도록 학습한다.
Flamingo는 LLM에 cross-attention layer를 삽입하여 시각 정보를 받아들이게 한다.
이 방식의 핵심 과제는 시각 피처를 언어 모델이 이해할 수 있도록 정렬하는 것이다.
BLIP-2는 이러한 접근을 한 단계 더 발전시켰다.
이미지 인코더와 LLM 모두 freeze된 상태에서 효율적인 정렬을 수행할 수 있도록 Q-Former를 도입하였다.
별도의 heavy한 end-to-end 학습 없이도 다양한 vision-language task에서 높은 성능을 적은 계산 비용으로 달성할 수 있도록 설계되었다.
BLIP-2는 기존의 모델 구조 및 학습 방식의 한계를 인식하고, 모듈화된 설계로 효율성과 성능을 모두 잡았다는 점에서 의의가 크다.
Method
Model Architecture
고정된 Image Encoder 와 Frozen LLM의 연결을 학습하기 위한 Q-Foremr를 제안한다. 이는 독립적인 이미지의 인코더로 부터 고정된 피쳐 차원을 뽑는다.Q-Former는 self-attention-layers를 공유하는 두 개의 서브 모듈로 구성된다.
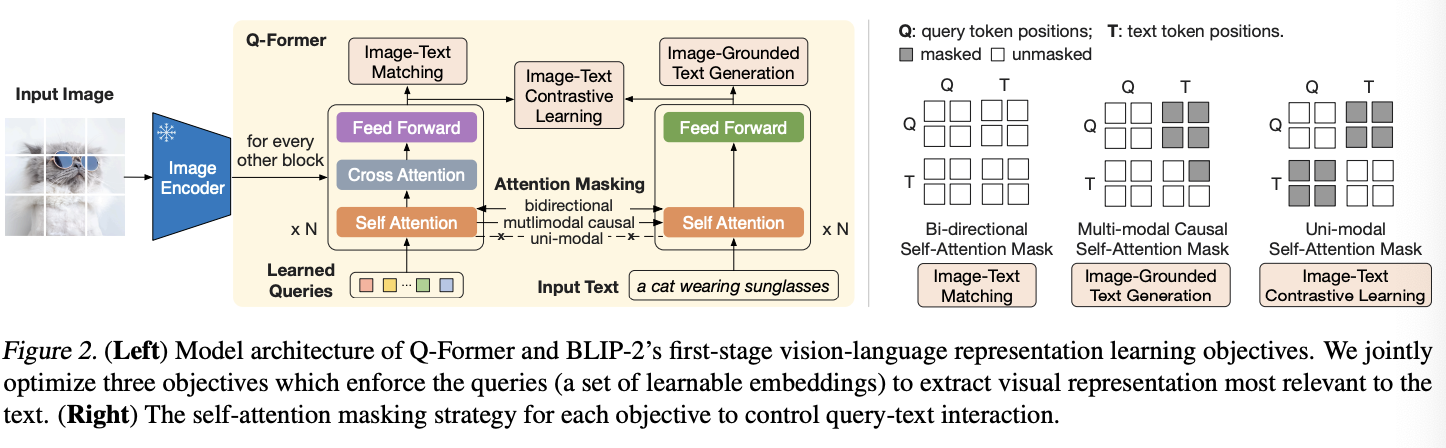
(1) image transformer는 시각 정보를 추출하기 위해 이미지 인코더와 상호작용한다.
(2) text transformers는 텍스트 인코더와 디코더로 작동한다.
고정된 숫자의 학습 가능한 쿼리 임베딩을 이미지 트랜스포머에 주입한다. 해당 쿼리 임베딩은 각각의 self attention layer에서 상호작용한다. 해당 쿼리는 추가로 text에서 같은 self attention layer로 작동한다. 사전 학습 단계에 따라, 다른 query-text 작용을 조정하기 위해 다르게 마스킹이 작동된다. Q-Former는 BERT의 가중치로 사전초기화해서 진행한다. 반면 cross-attention layer는 랜덤 가중치 초기화를 사용한다. 총, Q-Former는 188M 파라미터를 지닌다. Learned Query 또한 모델 파라미터로 여겨진다.
우리는 32개의 768차원을 가지는 쿼리를 사용하고 이미지 특징의 결과 차원도 동일하다. 사전학습 목적함수는 쿼리가 시각적 정보를 텍스트에 잘 반영할 수 있도록 학습이 진행된다.
Bootstrap Vision-Language Representation Learning from a Frozen Image Encoder
표현 학습(1-stage)에서 Q-Former는 고정된 이미지 인코더에 Q-Former를 연결하고 사전학습을 진행했다. BLIP(이전 version.1) model에서 착안하여 같은 인풋 형식과 모델 파라미터를 공유하는 3개의 목적함수를 사용하낟. 각각의 목적함수는 다른 attention masking 전략을 사용한다.
Image-Text Contrastive Learning : 이미지와 텍스트 표현의 align을 맞추기 위해 학습을 진행한다 이미지와 텍스트 표현의 유사도를 통해 학습을 진행한다. image transformer Z와 text transformer의 t를 비교한다. t는 CLS 토큰의 임베딩을 사용한다. 이미지 쿼리는 다수이기 때문에 모든 쿼리와 유사도를 계산하고 가장 높은 유사도를 선택한다. 정보 손실을 피하기 위해 self-attention mask를 이용하여 text와 image가 서로 참조하지 못하게 사용한다. 고정된 이미지 인코더로 인하여 GPU마다 더 많은 샘플을 학습할 수 있게 되었다. (이미지 인코더를 학습 진행하지 않으므로 GPU마다 각각의 인코더를 돌려서 더 많은 데이터를 학습할 수 있게 되었다?)
Image-grounded Text Generation : ITG loss는 Q-Former가 주어진 이미지에 따라 텍스트를 생성하는 훈련을 담당한다.Q-Former는 직접적으로 이미지 인코더와 텍스트 토큰을 상호작용시키지 않기 때문에 쿼리에 의해 생성된 정보가 텍스트 토큰으로 간다. 그러므로, 쿼리는 텍스트 정보에 대한 정보를 잘 포착하는 시각 정보를 추출하게 한다. multimodal casual self-attention mask를 query-text 작용을 위해 이용한다. 쿼리는 서로에 대해 관여할 수 있지만 텍스트 토큰 끼리는 아니다. 각각의 텍스트 토큰은 모든 이미지 쿼리 정보를 이용한다.
Image-Text Matching : ITM은 이미지와 텍스트에 자세한 표현 align에 집중한다. image-text 쌍이 긍정이지 부정인지를 예측하는 분류이다. 모든 쿼리와 텍스트에 대해 관여하는 양방향 self-attention mask를 이용한다. 쿼리 임베딩 z는 멀티모달 정보를 포착한다. 그리고 쿼리 임베딩은 이진 분류 linear classifier로 들어가 logit을 얻고 모든 쿼리에 대한 평균이 매칭 스코어로 사용된다.
Bootstrap Vision-to-Language Generative Learning from a Frozen LLM
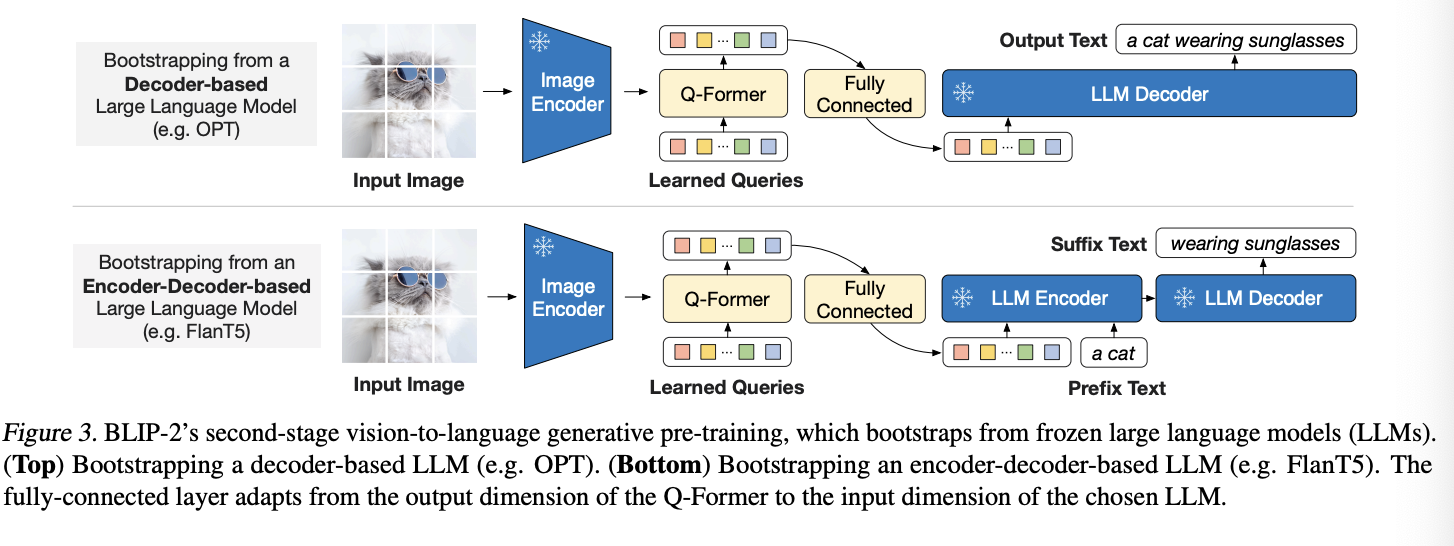
decoder-based LLM과 encoder-decoder-based LLM을 실험한다. 전자의 경우 텍스트를 생성하기 위한 언어 로스를 사용하고 후자의 경우는 prefix 언어 모델 로스를 사용하여 텍스트를 두 개로 구분하고 prefix 텍스트는 시각 표현 임베딩과 연결하여 인코더에 넣는다.
Model Pre-training
사전학습 데이터 구성
BLIP-2는 BLIP와 동일한 1억 2,900만 장 규모의 이미지-텍스트 데이터셋을 사용한다. 구체적으로는 COCO, Visual Genome, CC3M, CC12M, SBU, 그리고 LAION400M에서 가져온 1억 1,500만 장의 웹 이미지가 포함되어 있다.
웹 이미지에는 캡션이 정확하지 않을 수 있기 때문에 CapFilt라는 방법을 사용해 synthetic caption을 만든다.
BLIP의 대형 캡셔닝 모델(BLIP-Large)을 사용해 10개의 캡션을 생성하고,
이 캡션들과 기존 웹 캡션을 CLIP ViT-L/14 모델로 이미지-텍스트 유사도를 측정한 뒤,
상위 2개의 캡션을 남긴다.
학습 시에는 이 중 하나를 랜덤 샘플링해서 사용한다.
이렇게 하면 noisy한 웹 데이터에서도 비교적 신뢰도 높은 학습 데이터를 얻을 수 있다.
✅ 사전학습에 사용된 모델
BLIP-2는 이미지 인코더와 LLM을 모두 freeze한 상태에서 학습한다.
이미지 인코더는 두 가지 ViT 모델 중 하나를 사용한다:
CLIP의 ViT-L/14
EVA-CLIP의 ViT-g/14
여기서는 마지막 레이어 대신 두 번째 레이어의 출력 피처를 사용하는 것이 더 나은 성능을 보였다.
LLM은 두 종류를 실험한다:
디코더 기반 LLM인 OPT 시리즈 (unsupervised pretraining)
인스트럭션 튜닝된 FlanT5 시리즈 (encoder-decoder 구조)
✅ 사전학습 세팅
사전학습은 두 단계(stage)로 나뉘며,
1단계: 25만 스텝
2단계: 8만 스텝 동안 진행된다.
배치 사이즈는 사용 모델에 따라 다음과 같다.
1단계: ViT-L은 2320, ViT-g는 1680
2단계: OPT는 1920, FlanT5는 1520
모델의 계산 효율성을 높이기 위해,
ViT와 OPT는 FP16,
FlanT5는 BFloat16으로 변환해 학습한다.
실험 결과, 32-bit 모델과 성능 차이는 없었다.
특히, 전체 모델이 freeze되어 있기 때문에 계산 비용이 매우 낮다.
예를 들어, 가장 큰 모델(ViT-g + FlanT5-XXL)을 학습해도
16개의 A100(40G) GPU로 약 6일 + 3일, 총 9일이면 학습이 완료된다.
✅ 하이퍼파라미터 설정
모든 모델은 동일한 사전학습 하이퍼파라미터를 사용한다.
Optimizer: AdamW (β1=0.9, β2=0.98, weight decay=0.05)
러닝레이트 스케줄링: Cosine decay, peak LR=1e-4, warmup=2k
2단계에서는 최소 러닝레이트 5e-5로 설정
입력 이미지 크기는 224×224이며, 랜덤 리사이즈 크롭과 수평 플립으로 augmentation을 적용한다.
Experiment


BLip-2는 LLM이 텍스트에 대한 이해 보존과 더불어 이미지를 이해하게 한다. 또한, 우리는 이미지와 텍스트로 프롬프트를 사용하여 시각 정보 기반 추론 등과 같은 여러 테스크를 보인다.
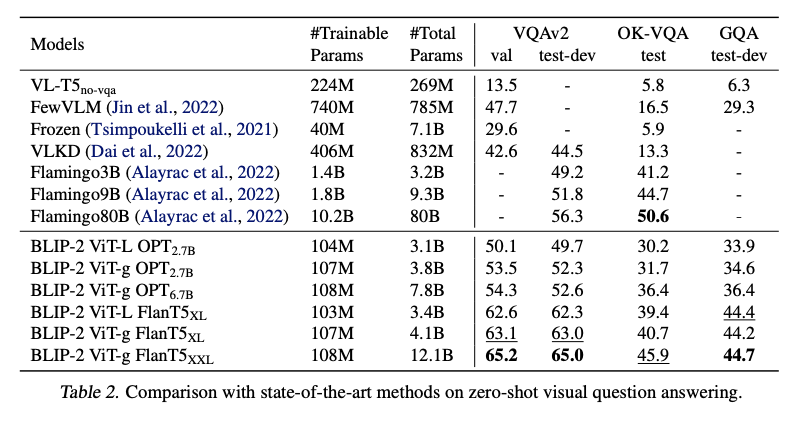
zero-shot VQA에서 OPT models의 경우, “Question: {} Short answer:”을 프롬프트로 사용한다. 생성하는 동안 beam 너비를 5로 두어 서치를 진행한다. 그리고 길이 패널티도 주어 짧은 답을 유도한다. 여기서는 PLAMINGO80B 모델 다음의 성능을 기록하였는데 이는 VQA가 더 많은 현실 지식이 필요하고 70B의 Chinchilla 모델이 더 많은 지식을 가지고 있어서 그런 것으로 보인다.
Effect of Vision-Language Representation Learning
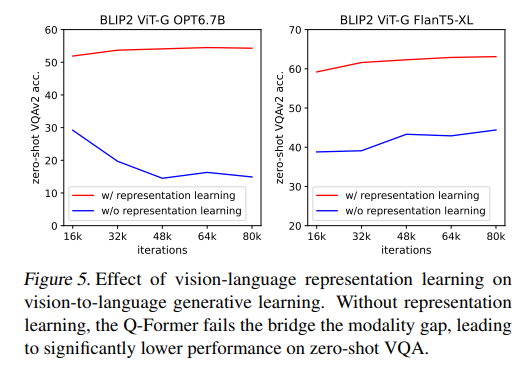
시각 정보를 언어 모델을 위한 정보로 맞춤으로써, 언어 모델은 학습의 짐을 덜었다. 그리고 이 역할을 Q-Former가 Flamingo의 Perceiver Resampler와 같이 담당을 하게 된다. Figure 5. 에서는 이러한 과정이 없을 때 LLM의 망각 현상에 의해 성능이 많이 하락함을 보인다.
Image Captioning
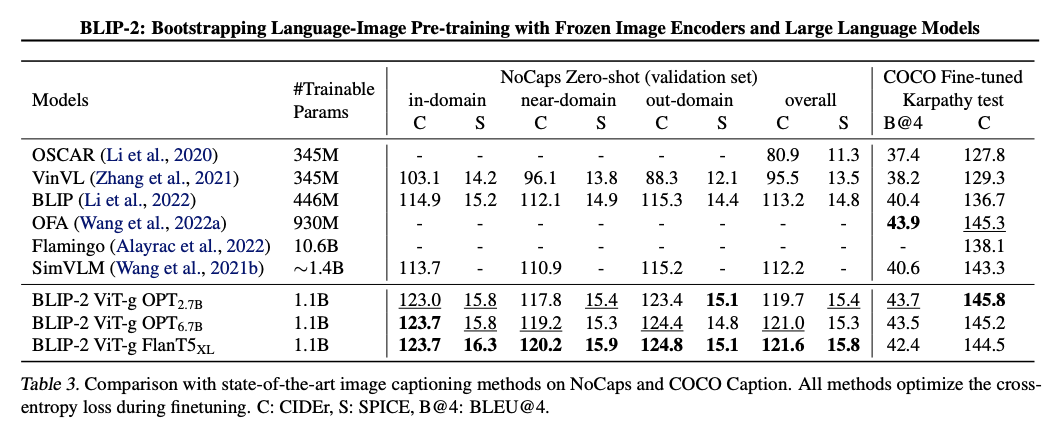
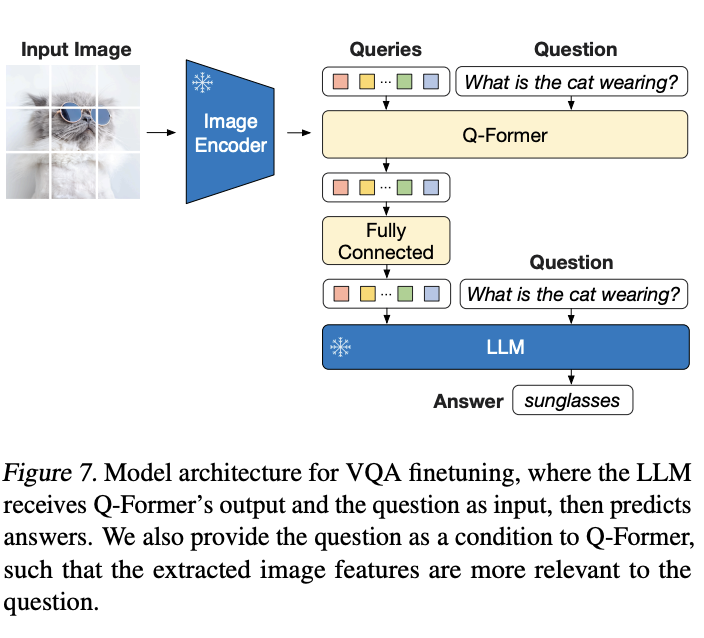
Visual Question Answering
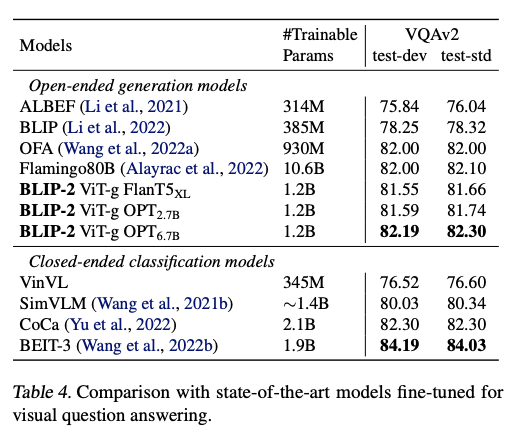
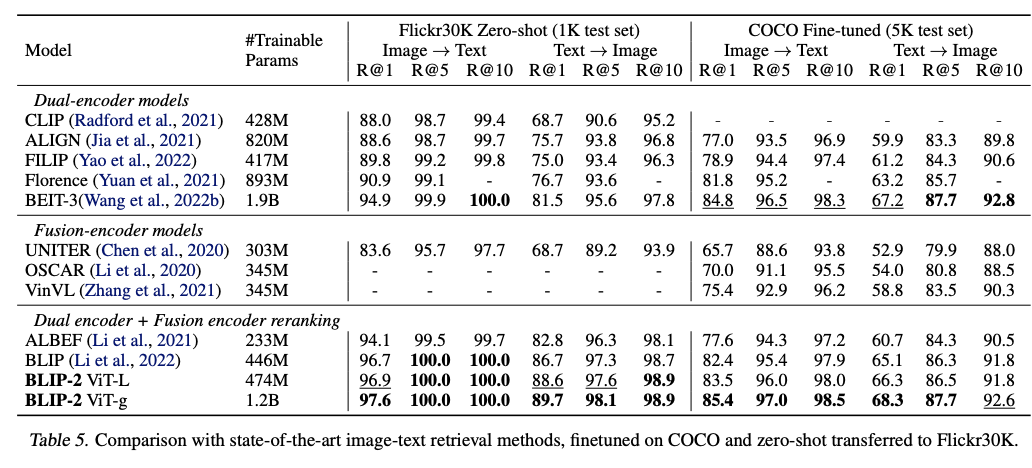
Image-Text Retrieval
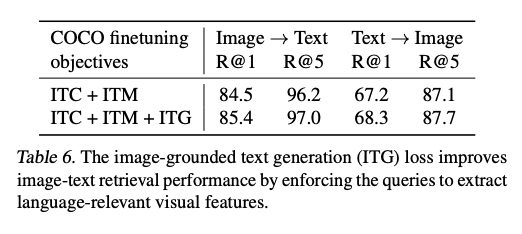
Limitation
근래 LLM은 few-shot으로 주어진 샘플에서 문맥 학습을 수행한다. 그러나 BLIP-2는 그러한 결과를 보이지 못한다. context-learning에 대한 능력을 사전 학습 데이터에 대해서 image-text 단일 쌍의 데이터만을 받아서 그런것으로 생각한다.
Conclusion
일반적이고 효율적으로 고정된 image encoder와 LLM을 이용하는 BLIP-2를 제시한다. BLIP-2는 적은 파라미터로 SOTA를 달성하며 zero-shot 기반의 생성 능력을 입증한다.
이전 FLAMINGO와 비교한다면?
더 효율적인 구조 (Stage-wise pretraining)
Stage 1: Q-Former를 학습하면서 vision-language alignment 확보
Stage 2: Frozen LLM에 적합한 multimodal representation 학습
각각의 모듈은 사전 학습된 모델을 최대한 활용하며, 전체 fine-tuning 없이도 높은 성능을 달성
Query-driven한 interaction (Q-Former)
LLM이 입력받을 수 있는 token 수는 제한돼 있음
Q-Former는 query attention을 통해 필요한 정보만 뽑아서 LLM에 전달
Flamingo의 Perceiver는 모든 정보를 압축하지만, BLIP-2는 더 선택적이고 task-specific한 정보를 전달함
범용성과 확장성
Q-Former 덕분에 다양한 vision encoder & LLM과의 연결이 쉬움
즉, 모듈화된 구조로 설계되어서 다양한 조합 실험과 응용이 가능함
Pretraining 없이도 높은 성능
BLIP-2는 LLM을 freeze한 상태에서도 높은 성능을 내므로 비용 측면에서도 효율적
Flamingo는 대형 모델을 통합해 few-shot 성능을 극대화한 시도에 가깝고,
BLIP-2는 vision과 language를 더욱 유기적으로 연결하기 위한 모듈화된 구조와 효율적인 학습 방식을 갖추어 실제로 범용성과 실용성 측면에서 한 발 더 나아간 모델이라고 볼 수 있음.
🔗 관련 글
