ABSTRACT
GPT-4는 텍스트를 기반으로 웹사이트를 생성하고 이미지내 유머러스 요소를 캐치하는 등 뛰어난 멀티모달 능력을 증명한다. 이러한 기능은 이전 VLM에서는 찾을 수 없었다. GPT-4의 기술적 요소는 공개되지 않았다. 아마 정교한 LLM의 활용으로 부터 해당 능력이 있는 것으로 예상한다. 이러한 부분을 조사하기 위해 고정 이미지 인코더를 하나의 layer로 고정된 언어 인코더에 할당하는 MINIGPT-4를 제시한다. 처음으로 시각적 기능을 최신 언어 모델과 연게하면 다양한 멀티모달 기능을 사용할 수 있음을 보인다. 게다가, 이미지로부터 영감을 받아 글을 쓰거나 시를 씨고 음식 사진으로 부터 어떻게 요리를 하는지 등의 기능도 확인한다. 이미지와 짧은 캡션으로 학습할 경우 잘못된 생성을 하는 것도 확인한다. 이러한 문제를 해결하기 위해 모델을 파인튜닝하는 과정에서 데이터에 대한 curation을 진행하면 모델의 성능을 증진시킨다.
INTRODUCTION
최근 LLM은 급속한 발전을 이루며 zero-shot의 능력이 있다. GPT-4는 거대한 멀티모달 모델로 이해와 생성에 뛰어난 능력을 보여준다. GPT4는 정말 뛰어난 능력을 보이고 있는데, 이는 OPENAI의 미스테리로 남아있다. 아마 뛰어난 최신 LLM의 능력으로 보인다. 이러한 능력은 visual 능력으로도 이루어질 수 있을 것으로 보인다.
가설을 증명하기 위해 MiniGPT-4를 제시한다. LLAMA를 기반으로 한 Vicuna LLM을 언어 디코더로 사용하고 ChatGPT의 90%의 성능을 달성한다. 시각적 모델은 BLIP-2에서의 EVA-CLIP으로 구성된 같은 pretrained 방식을 사용한다. MINIGPT-4는 언어와 시각적 모델을 고정시키고 한개의 project layer를 visual features에 사용한다. 4개의 A100 GPU에서 256batch로 20,000번의 학습을 진행한다. LAION, Conceptual Captions, SBU 데이터 셋을 이용했는데 단순히 시각 정보를 언어 모델에 align 시키는 것은 챗봇과 같은 언어 대화 능력에 불충분하다. image-text 쌍의 노이즈의 존재는 언어 출력 수준을 낮게 한다. 그래서 3500개의 또 다른 이미지 설명 쌍을 대화 템플릿에 맞게 파인 튜닝을 위해 사용한다.
실험에서 MINIGPT-4가 GPT-4와 유사한 능력을 많이 가짐을 보인다. 예를 들어, 정교한 이미지 설명을 생성하고 텍스트 지시로 웹사이트를 제작하며 희귀한 시각 현상을 설명하다. 게다가 GPT-4에서 하지 못한 것들도 할 수 있는데 음식 사진으로 부터 레시피를 만들어내고 이미지로부터 시와 이야기를 만들고 제품의 광고를 제작 사진 내에 문제를 풀고 솔루션을 제시한다. 이러한 능력은 언어 모델의 능력 부족으로 이전 VLM인 KOSMOS-1과 BLIP-2에서는 보여주지 못하였다. 이러한 것은 시각적인 특징을 좋은 언어 모델에 결합하는 것이 VLM에서 포인트임을 보여준다.
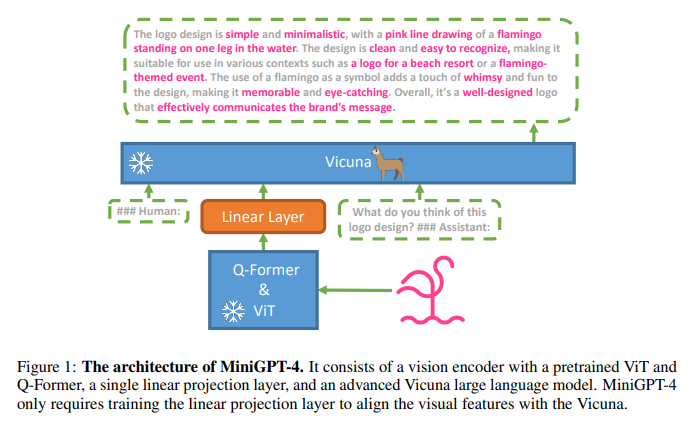
- Vicuna와 같은 뛰어난 언어 모델에 시각 특징을 결합하는 방식이 뛰어남을 보이고, MINIGPT-4가 GPT-4에서 보인 multimodal 능력보다 뛰어남을 보인다.
- 단순한 하나의 projection layer가 pretrainer vision encoder와 거대 언어 모델 align에 효과적임을 보인다. 단지 10시간 동안 4개의 A100으로 학습했다.
- 거대 언어 모델에서의 간단한 align 방식에서 짧은 이미지 캡션을 쓰는 것은 모델에게 불충분하며 자연스럽지 못한 언어 생성을 보임을 보인다. 그러나 적지만 상세한 이미지 설명은 이러한 한계를 극복하고 성능을 향상시킨다.
Related Works
Large language models
초기 LLM들: BERT, GPT-2, T5 등이 자연어 처리(NLP)의 성능 향상을 이끌었고, GPT-3는 175B 파라미터로 많은 벤치마크에서 획기적인 성과를 보여줌.
이 흐름을 따라 Megatron-Turing NLG, Chinchilla, PaLM, OPT, BLOOM, LLaMA 등의 대규모 모델이 등장.
특히, Wei et al. (2022)은 LLM에서 모델 크기가 커지면서만 나타나는 emergent abilities를 발견함. InstructGPT, ChatGPT는 인간의 의도에 맞춰 LLM을 조정함으로써 대화형 상호작용이 가능해졌고, 이는 실사용 가능성을 크게 확장함. 이후 Alpaca, Vicuna 등의 오픈소스 모델도 등장하며 성능을 입증함.
Leveraging Pre-trained LLMs in Vision-Language Tasks
최근에는 LLM을 디코더로 활용하는 비전-언어 태스크 방식이 각광받음. 이미지나 비디오와 텍스트의 결합된 지식을 공유하며 cross-modal 성능을 극대화.
VisualGPT, Frozen: 사전 학습된 LLM을 활용한 디코딩의 효과 입증
Flamingo: 게이티드 크로스 어텐션으로 비전 인코더와 LLM을 정렬, 수십억 이미지-텍스트 쌍으로 학습 → 강력한 few-shot 학습 성능 발휘
BLIP-2: Q-Former와 Flan-T5를 통해 이미지와 언어의 정렬을 효율적으로 수행
PaLM-E: 562B 파라미터 규모로, 실제 센서 데이터를 LLM과 통합하여 현실 세계와 언어를 연결
GPT-4: 대규모 이미지-텍스트 데이터로 사전 학습되어 시각적 이해 능력이 크게 향상됨
최근에는 LLM이 다양한 비전 모델들과 협업하는 형태도 시도됨.
Visual ChatGPT, MM-REACT: ChatGPT가 다양한 비전 모델을 조정(coordinator)하여 협력 수행
ChatCaptioner: ChatGPT가 질문자 역할, BLIP-2는 시각 정보 응답 → 다단계 대화로 이미지 내용 요약
Video ChatCaptioner: ChatCaptioner를 비디오로 확장
ViperGPT: LLM과 여러 비전 모델을 결합해 복잡한 시각적 쿼리를 프로그래밍 방식으로 해결
MiniGPT-4: 외부 비전 모델 없이 시각 정보를 직접 LLM에 정렬해 다양한 태스크 처리
METHOD
FIRST PRETRAINING STAGE
CURATING A HIGH-QUALITY ALIGNMENT DATASET FOR VISION-LANGUAGE DOMAIN.
SECOND-STAGE FINETUNING
Experiments
UNCOVERING EMERGENT ABILITIES WITH MINIGPT-4 THROUGH QUALITATIVE EXAMPLES
QUANTITATIVE ANALYSIS
ANALYSIS ON THE SECOND-STAGE FINETUNING
ABLATION ON THE ARCHITECTURE DESIGNS
LIMITATION ANALYSIS
Discussion
🔗 관련 글
