Abstract
(1) Vision & Language only model 에 대한 강력한 연결
(2) Visual & Text data가 끼워들어간 Sequence에 대한 처리
(3) Image & Video를 input으로 사용함으로써 웹의 멀티모달 데이터를 학습해 few-shot learning 능력을 가짐
open-ended(ex.vqa) task를 포함한 다양한 이미지와 비디오 테스크에 대한 성능 측정을 수행하였을 때, Flamingo model은 few-shot 학습으로 특정 태스크에서 수천번을 전이 학습한 모델보다 성능이 뛰어남을 보임.
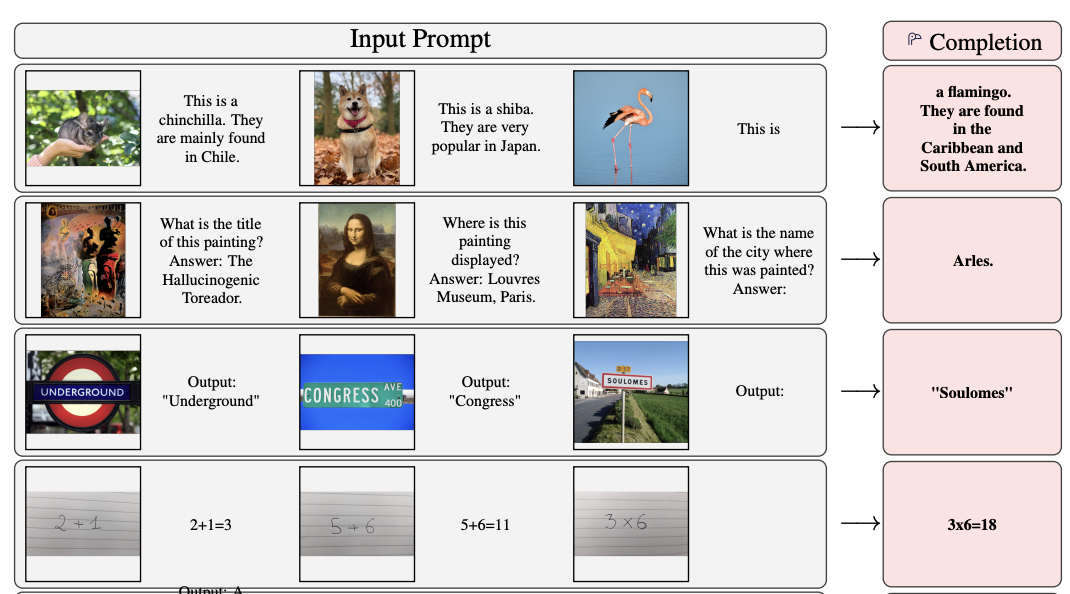

Introduction
지능에 중요한 측면은 짧은 지식을 주었을 때 빠르게 능력을 배우는 것이다. 초기 비젼 모델은 많은 양을 지도학습으로 수행한 다음에 특정 테스크 데이터에 대해 fine-tunning하는 방식을 수행하는 것이다. 그러나 fine-tunnning은 수천 개의 라벨 데이터를 요하는 경우가 많다. 또한, 하이퍼파리미터 튜닝과 자원 소모를 요구한다
최근에는 CLIP에서 contrastive learning을 통하여 fine-tunning 없이 새로운 테스크에 대하여 제로 샷이 가능해졌다. 다만 CLIP은 similarity score만을 제공하며 이는 분류라는 한정된 방식에만 사용 가능하다.
Flamingo는 많은 테스크를 수행할 수 있을 뿐더러, 실험한 16개의 fine-tuned task 중 6개에서 sota를 달성한다.
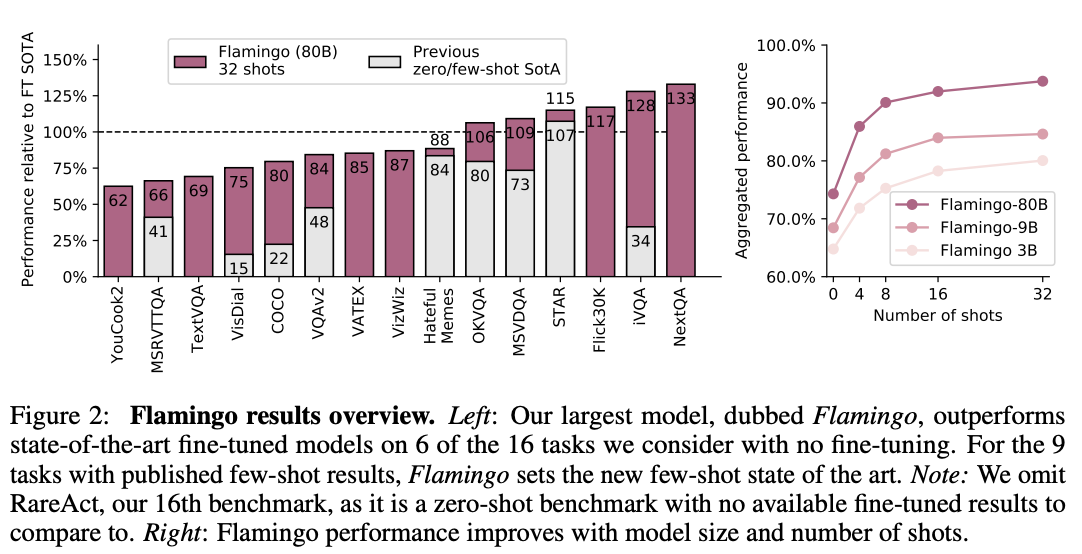
간단히 요약하자면
(a) 다양한 멀티모달을 수행하는 VLM인 FLAMINGO MODEL을 제시한다.
(b) few-shot learning으로 학습한 FLAMINGO MODEL을 정량적으로 제시한다. 하이퍼 파리미터를 검증하는데 사용되지 않은 벤치마크 데이터가 있으며 이를 통해 성능을 제시한다.
(c) FLAMINGO MODEL은 테스크 당 32개 만을 학습하여 16개 중 6개에서 sota를 달성한다.
Approach
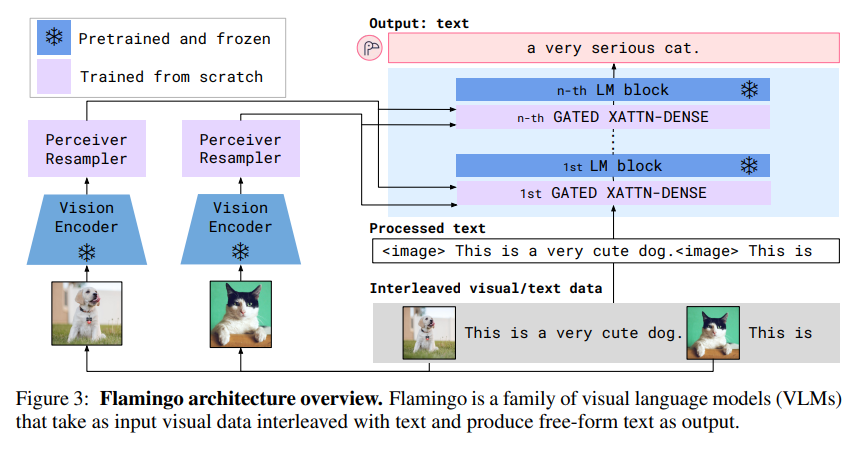
Visual processing and the Perceiver Resampler
사전학습(pretraining)을 할 때는, 이미지와 텍스트 쌍을 가지고 contrastive learning 방식으로 학습함. 이미지의 경우: 2D 공간상의 특성 맵을 1D 시퀀스 형태로 평탄화해서 출력
비디오의 경우: 초당 1프레임(FPS)씩 샘플링, 각 프레임을 독립적으로 NFNet으로 인코딩, 시간 축 정보를 표현하기 위해 "temporal embeddings"를 추가함. 결과적으로 3D spatio-temporal 특성 맵을 만들어서 마찬가지로 1D로 평탄화
Vision Encoder에서 나온 시퀀스는 길이가 가변적이다. visual, text attention에 대한 효율성을 위해 고정적인 64 token을 뽑기 위해 Perceiver Resampler가 처리한다. 이 방식인 Transformer와 MLP보다 성능이 좋았다.
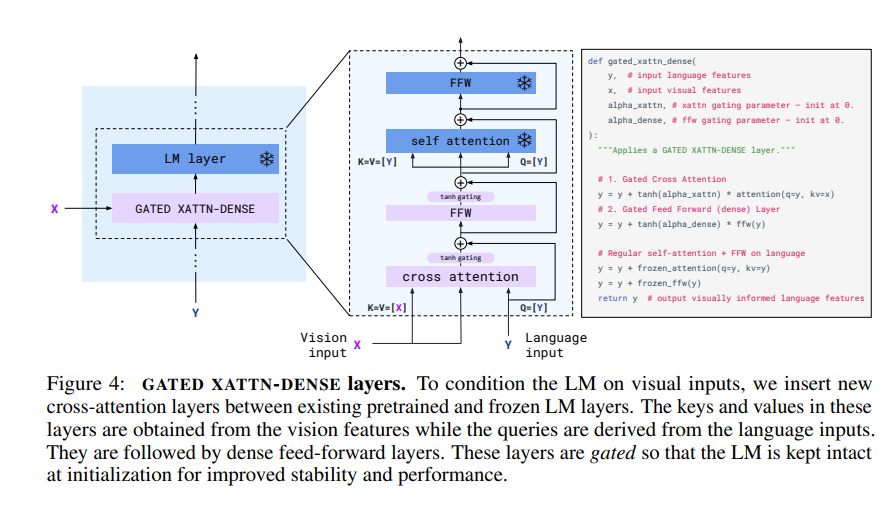
Conditioning frozen language models on visual representations
visual 정보로 부터 디코더에서 생성을 잘하기 위해 사전학습된 LM을 사용하였고 cross-attention을 학습할 때 고정시켰다.
Multi-visual input support: per-image/video attention masking
Flamingo는 텍스트와 이미지/비디오가 번갈아(interleaved) 들어오는 입력을 처리함.
그런데 텍스트가 나올 때마다, "어떤 이미지 정보를 보고 이 단어를 예측할지" 정하는 게 중요함.
언어 모델의 cross-attention은 기본적으로 모든 시각 토큰을 참고할 수 있음.
그런데 Flamingo는 "그 텍스트 바로 앞에 등장한 이미지/비디오에만" attention을 주도록 마스킹(masking)을 적용함. Image1, Image2는 직접적으로는 보지 않음.
단, 자기 회귀적인 self-attention 구조 덕분에, 이전 텍스트를 통해 간접적으로는 반영됨.
학습에 사용한 이미지 수가 적어도,
추론 시 더 많은 이미지/비디오 쌍을 처리할 수 있음. 학습할 때는 최대 5개 썼지만, 평가할 땐 32쌍까지 사용 가능.
확장성이 좋음: 이미지 수에 관계없이 동작함. 학습 중 본 적 없는 개수의 이미지/비디오가 있어도 잘 작동함.
직관적인 cross-attention 구조: 텍스트는 항상 "바로 앞의 이미지"와 연결됨. 이 구조가 모든 이미지와 연결되는 방식보다 성능이 더 좋았음 (Section 3.3에서 입증함).
Training on a mixture of vision and language datasets
M3W: Interleaved Image and Text Dataset, 4,300만 개의 웹페이지의 HTML을 분석하여 웹페이지에서 텍스트와 이미지가 섞여 있는 형태의 데이터를 수집. HTML의 DOM(Document Object Model)을 이용해 텍스트와 이미지의 상대적 위치를 파악함.
이미지가 등장하는 위치에 태그를, 문단 끝에는 (End Of Chunk) 토큰을 삽입함. 전체 문서 중 256개 토큰(L) 길이의 부분을 랜덤으로 샘플링하고, 최대 5개 이미지(N)까지만 포함함. 나머지는 계산량 절약을 위해 버림.
ALIGN: 18억 개의 이미지와 해당 alt-text, LTIP: 자체 수집한 고품질 데이터셋, 총 3억 1,200만 개의 이미지-텍스트 쌍. 더 길고 자세한 설명을 담고 있음. VTP : 자체 수집한 데이터. 약 2,700만 개의 짧은 비디오(평균 22초)와 해당 설명으로 구성됨. 텍스트에는 이미지와 마찬가지로 와 태그를 붙여 M3W와 형식을 맞춤.
Flamingo는 위의 여러 데이터셋을 동시에 사용해 학습함.
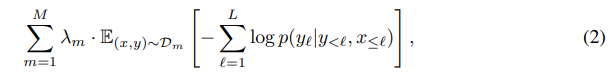
우리는 in-context learning 이라는 빠르게 새로운 테스크에 적응하는 능력을 테스트한다. Flamingo 모델을 few-shot 각 32개의 학습의 결과를 보임.
Experiments
Flamingo는 이미지/비디오 + 텍스트가 결합된 멀티모달 학습 문제에 강해야 함.
이를 검증하기 위해 총 16개의 대표적인 멀티모달 벤치마크를 사용함.
모델 설계 실험과 하이퍼파라미터 튜닝을 위해 5개의 데이터셋을 사용했으며 평가를 위해서 11개의 데이터 셋을 실험함. 이미지/비디오 캡셔닝, 비디오 질의응답, 시각적 대화 (visual dialogue), 객관식 QA (multi-choice QA) 등의 task가 포함됨.
Few-shot learning on vision-language tasks
3.1에서는 Flamingo 모델의 vision-language 태스크에 대한 few-shot 학습 성능을 다룸. Table 1의 결과에 따르면 Flamingo는 총 16개의 벤치마크에서 기존의 zero-shot 및 few-shot 방법들을 큰 차이로 능가함. 이는 태스크당 단 4개의 예시만 사용했음에도 달성된 성과로, Flamingo가 새로운 비전 태스크에 효과적으로 적응할 수 있음을 보여줌.
특히 Flamingo는 수십만 개의 어노테이션을 통해 파인튜닝된 state-of-the-art(SotA) 방법들과도 성능이 비견될 만큼 강력함. 일부 태스크에서는 단 32개의 예시만으로 파인튜닝된 SotA 성능을 초과하기도 했으며, 이는 동일한 가중치로 모든 태스크에 대응한 결과임.
또한 DEV 벤치마크만을 기준으로 설계했음에도, 그 외의 벤치마크에서도 좋은 일반화 성능을 보임. 이는 Flamingo 접근 방식의 범용성을 뒷받침함.
모델 크기와 샷 수에 따른 성능 스케일링도 분석함. Figure 2에 따르면 모델이 클수록 few-shot 성능이 향상되며, shot 수가 많을수록 성능이 증가하는 경향을 보임. 특히 가장 큰 Flamingo 모델은 더 많은 예시를 활용할수록 성능이 크게 향상됨. 흥미롭게도, 학습 시에는 한 시퀀스에 최대 5장의 이미지만 포함됐음에도 불구하고, 추론 단계에서는 최대 32개의 이미지나 비디오로부터도 성능 향상을 이끌어냄. 이는 Flamingo 구조가 다양한 수의 이미지나 영상을 유연하게 처리할 수 있음을 보여줌.
Fine-tuning Flamingo as a pretrained vision-language model
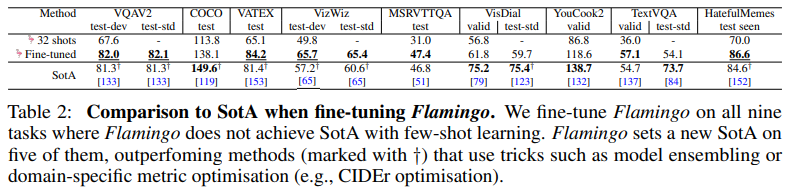
실험은 가장 큰 모델인 Flamingo를 대상으로, 어노테이션 비용에 제한이 없는 상황에서 진행함. 학습 방식은 짧은 학습 스케줄과 작은 learning rate로 파인튜닝을 수행하며, 입력 해상도를 높이기 위해 비전 백본까지 언프리징함(자세한 내용은 Appendix B.2.2 참고). 그 결과, 기존에 in-context few-shot 학습으로 제시했던 성능보다 향상된 결과를 얻었으며, VQAv2, VATEX, VizWiz, MSRVTTQA, HatefulMemes 등 다섯 개 태스크에서 새로운 state-of-the-art를 달성함.
즉, Flamingo는 few-shot 설정에서도 강력하지만, 필요 시 파인튜닝을 통해 성능을 더욱 끌어올릴 수 있는 유연한 구조를 가지고 있음.
Ablation studies
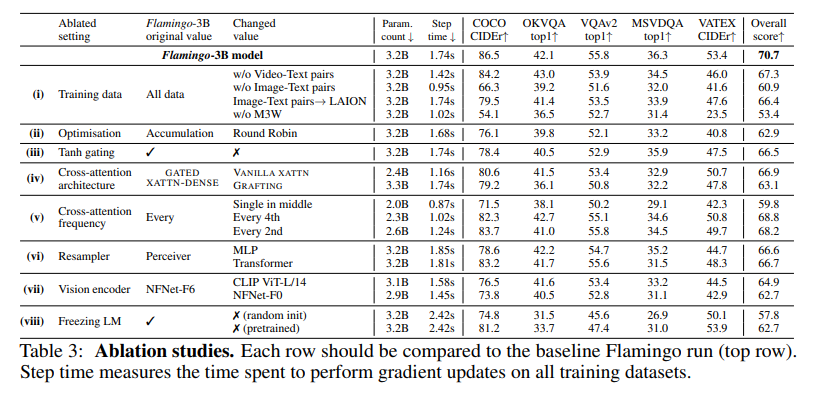
Flamingo-3B 모델에 대한 ablation 실험은 5개의 DEV 벤치마크에서 4-shot 조건으로 수행되었으며, 모델 설계 요소가 성능에 미치는 영향을 정량적으로 분석했다. 전체 점수는 각 벤치마크 점수를 해당 태스크의 최신 SOTA 성능으로 나눈 뒤 평균하여 계산하였다. 실험은 소규모 배치 사이즈와 짧은 학습 스케줄 하에 진행되었다.
먼저, 학습 데이터 구성의 중요성을 확인했다. interleaved image-text 데이터를 제거하면 성능이 17% 이상 하락하였고, 일반적인 image-text pair를 제거했을 때도 약 9.8%의 성능 감소가 있었다. 이는 다양한 형식의 데이터셋이 모델 성능에 필수적임을 보여준다. video-text 데이터 역시 비디오 관련 태스크 성능에 결정적인 영향을 주었고, 자체 image-text pair를 LAION-400M으로 대체한 경우에도 소폭의 성능 저하가 있었다.
학습 전략 측면에서는 gradient accumulation 방식이 기존의 round-robin 업데이트보다 성능 면에서 우수함이 확인되었다. 또한, frozen language model(LM)에 시각 정보를 주입할 때 사용한 0으로 초기화된 tanh gating 구조를 제거하면 전체 점수가 4.2% 감소했으며, 학습 불안정성도 증가하였다. 다양한 cross-attention 구조 중에서는 GATED XATTN-DENSE 방식이 가장 안정적이고 성능이 높았다.
계산 효율성도 고려하여 GATED XATTN-DENSE 블록의 삽입 빈도를 실험하였다. 모든 층에 삽입할 경우 성능은 가장 높았지만 연산량이 크게 증가했다. 이에 따라 Flamingo-9B에는 4층마다, Flamingo-80B에는 7층마다 삽입하는 전략을 택해 연산량을 줄이면서도 성능 손실은 최소화하였다. 또한, 시각 피처 샘플링 모듈로 Perceiver Resampler를 사용할 경우, MLP나 기본 Transformer보다 성능과 속도 모두에서 뛰어났다.
비전 인코더 비교 실험에서는 contrastive 학습으로 사전학습된 NFNet-F6가 CLIP ViT-L/14 대비 5.8%, 더 작은 NFNet-F0 대비 8.0%의 성능 향상을 보이며 강력한 backbone의 필요성을 입증했다.
마지막으로, 언어 모델의 파라미터를 동결하지 않고 학습하면 catastrophic forgetting이 발생하는 현상을 관찰했다. 언어 모델 전체를 처음부터 학습할 경우 성능이 12.9% 하락했고, 사전학습된 모델을 일부 fine-tuning하더라도 8.0%의 성능 저하가 있었다. 따라서, 언어 모델을 freeze한 상태로 사용하는 것이 성능 유지에 효과적이라는 결론을 얻었다.
이러한 실험을 통해 Flamingo 아키텍처의 각 구성 요소가 few-shot 성능에 어떤 영향을 미치는지 정량적으로 분석하고, 최적의 구조와 학습 전략을 도출하였다.
Related work
언어 모델링과 few-shot 적응은 Transformer의 등장 이후 큰 진보를 이룸. 현재는 대규모 데이터로 사전 학습(pretraining)한 후, downstream 태스크에 적응(fine-tuning or prompting)하는 방식이 표준으로 자리 잡음. 본 연구에서는 Flamingo 모델의 기본 언어 모델로 Chinchilla 70B를 사용함. 소수의 예제를 통해 언어 모델을 새로운 태스크에 적응시키는 다양한 기법이 제안되어 왔음. 예컨대, adapter 모듈 추가, 일부 파라미터만 미세 조정, prompt에 in-context 예시 제공, gradient 기반으로 prompt 자체를 최적화하는 방식 등이 있음. 본 연구에서는 metric learning이나 meta-learning 기반의 복잡한 접근보다는, in-context few-shot 학습 방식에 착안하여 간결한 방법론을 선택함.
이러한 언어 모델의 발전은 시각-언어 모델링 분야에도 큰 영향을 줌. 특히 BERT의 등장은 다양한 비전-언어 연구에 영감을 주었음. 그러나 Flamingo는 기존의 많은 연구들과 달리, 새로운 태스크에 대해 별도의 fine-tuning 없이도 동작함. 또 다른 접근인 contrastive learning 기반의 모델들과는 달리 Flamingo는 텍스트를 생성할 수 있다는 점에서 차별점이 있음. 다만, 비전 인코더 부분은 contrastive learning 기반 모델에서 차용함. Flamingo와 유사하게 autoregressive 방식으로 텍스트를 생성하는 VLM들도 존재하며, 여러 최신 연구들 역시 다양한 비전 태스크를 텍스트 생성 문제로 재정의하려는 시도를 진행 중임.
또한, 최근 연구에서는 사전 학습된 언어 모델의 가중치를 고정(freeze)하고 그 내부에 학습 가능한 층을 추가하는 방식이 제안되고 있음. 이 방식은 catastrophic forgetting 문제를 방지하는 데 효과적임. Flamingo 역시 Chinchilla LM의 가중치를 고정하고, 그 위에 학습 가능한 cross-attention 모듈을 삽입하는 구조를 따름. 그러나 Flamingo는 기존 연구들과 달리, 이미지, 비디오, 텍스트가 자유롭게 섞여 있는 입력 시퀀스를 처리할 수 있는 최초의 LM임.
데이터 측면에서도 차별성이 있음. 기존의 시각-언어 데이터셋은 수작업 라벨링 비용이 높아 10K~100K 수준의 비교적 소규모 데이터셋이 대부분이었음. 이를 해결하기 위해, 많은 연구들이 웹에서 자동으로 vision-text 쌍을 수집하여 대규모 데이터셋을 구성함. 본 연구에서는 이러한 paired 데이터 외에도, 이미지와 텍스트가 교차(interleaved)되어 있는 실제 웹페이지 전체를 하나의 멀티모달 시퀀스로 학습에 활용함. 동시 진행된 CM3 연구는 HTML 마크업 생성을 통해 웹페이지를 처리하지만, Flamingo는 이를 단순화하여 plain text만을 생성함. 또한, CM3는 주로 언어 중심의 zero-shot 혹은 fine-tuning 평가를 진행한 반면, Flamingo는 few-shot 설정에서 다양한 비전 태스크에 초점을 맞추고 있음.
Discussion
Flamingo의 한계는 크게 세 가지 측면에서 드러남.
첫째, Flamingo는 사전학습된 언어 모델에 기반하기 때문에, 해당 모델이 갖는 약점들을 그대로 물려받음. 예를 들어, 언어 모델의 사전 지식은 일반적으로 유용하지만, 때때로 사실과 다른 정보(hallucination)나 근거 없는 추측을 유발할 수 있음. 또한 언어 모델은 학습 시 처리한 시퀀스보다 더 긴 입력에 대해 일반화 성능이 떨어지고, 학습 중 샘플 효율도 낮은 편임. 이러한 문제들을 해결하는 것이 VLM 발전에 중요한 열쇠가 될 수 있음.
둘째, Flamingo의 분류 성능은 contrastive learning 기반의 최신 모델들보다 낮음. 해당 모델들은 이미지-텍스트 검색이라는 특화된 목표에 최적화되어 있으며, 분류 태스크는 이 검색 문제의 한 특수 사례로 간주됨. 반면 Flamingo는 분류뿐 아니라 보다 광범위한 오픈엔디드 태스크도 수행 가능함. 따라서 두 접근법의 장점을 동시에 달성할 수 있는 통합적 방법이 향후 주요 연구 주제가 될 수 있음.
셋째, Flamingo가 사용하는 in-context learning은 gradient 기반의 few-shot 학습보다 구현이 간단하고 몇 개의 예시만으로도 효과적인 결과를 낼 수 있다는 장점이 있음. 특히, 하이퍼파라미터 튜닝 없이 추론만으로도 손쉽게 적용 가능하다는 점에서 실용성이 높음. 하지만 in-context 학습은 예시 구성에 매우 민감하고, 예시 수가 많아질수록 계산 비용이 증가하며 성능 향상도 한계가 있음. 따라서 다양한 few-shot 학습 기법을 결합하여 상호 보완적 이점을 활용하는 것이 바람직함. 보다 자세한 한계 논의는 Appendix D.1에 포함되어 있음.
사회적 영향 측면에서도 Flamingo는 장단점이 공존함. Flamingo는 소량의 데이터만으로도 다양한 태스크에 빠르게 적응할 수 있어, 비전문가도 고성능 시스템을 구현할 수 있게 해주는 장점이 있음. 이는 유익한 용도뿐 아니라 악용 가능성도 함께 내포하고 있음. 언어 모델이 가진 대표적인 위험, 예를 들어 혐오 발언, 편향 및 고정관념 재생산, 개인정보 유출 가능성 등이 Flamingo에도 적용됨. 더불어 Flamingo는 시각 정보를 다룰 수 있기 때문에, 입력 이미지의 성별, 인종 등에 대한 편향 가능성 또한 존재함. 이러한 문제는 기존 시각 인식 시스템들에서도 제기된 바 있음. 사회적 영향과 관련된 보다 포괄적인 논의와 위험 완화 전략은 Appendix D.2에 수록되어 있음. 특히 Flamingo의 few-shot 학습 능력이 이러한 편향 문제를 완화하는 데 도움이 될 수 있음.
결론적으로, 본 연구에서는 Flamingo라는 범용 모델을 제안함. Flamingo는 최소한의 태스크 특화 데이터로 이미지 및 영상 기반 태스크를 수행할 수 있으며, 정형화된 벤치마크 외에도 모델과의 "대화"와 같은 상호작용 능력까지 보여줌. 이러한 결과는 강력한 시각 모델과 사전학습된 대형 언어 모델을 결합하는 것이 범용적인 시각 이해 모델로 나아가는 중요한 단계임을 시사함.
🔗 관련 글
