Abstract
언어, 멀티모달, 액션 등의 큰 범위는 인공지능의 핵심 단계이다. Multimodal Large Language Model인 KOSMOS-1을 제시한다. 웹에서 스크랩치로 학습을 진행하였으며 제네럴한 모달리티를 인지하고, 문맥을 학습하며 지시를 따른다. zero-shot, few-shot, COT 등 다양한 세팅에서 평가를 진행한다. 언어적 이해, 생성 그리고 OCR 없이 언어를 인지한다. 또한, language에서 multimodal로의 지식 전이와 그 반대에서의 benefit을 얻을 수 있음을 보인다. MLLM의 비언어적 추론 능력을 진단하는 Raven IQ 테스트 데이터 셋을 제시한다.
Introduction
LLM은 다양한 언어 테스트에서 특정 목적으로 성공해왔다. input, ouput을 텍스트로 변환함에 따라 다른 테스크로 변형할 수 있다. 예를 들어 요약의 인풋은 문서이고 아웃풋은 요약문이다.
LLM의 성공으로 다양하게 적용되고 있으나, 여전히 멀티모달에서는 제약이 많다. 일반적인 세상의 지식을 위해서는 멀티모달이 필수적이다. 인풋이 제한되어 있지 않다면 로봇, 문서 이해등 다양한 영역으로 넓혀갈 수 있다.
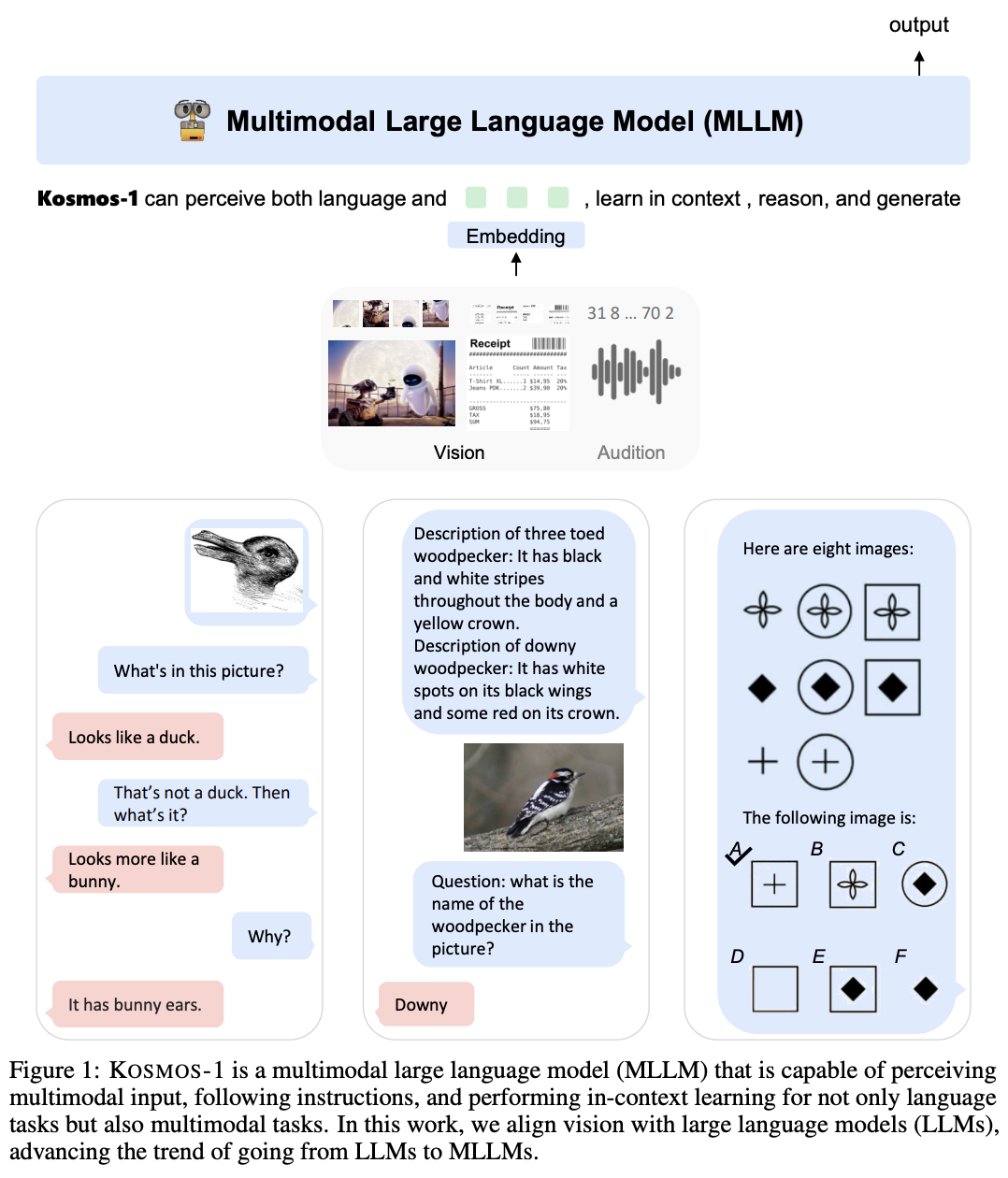
KOSMOS-1(MLLM)을 제시하며 이는 제네럴한 모달리티와 zero-shot learning, few-shot learning을 수행한다. 목표는 모델이 보고 말할 수 있도록 언어 모델에 얼라인 시키는 것이다.Transforemr기반의 모델은 제네럴한 목적으로 중점을 두며 인지 모델은 언어 모델로 수행된다. 웹 단위 규모에 멀티모달 데이터를 학습시키고 instruction-following 능력을 언어 데이터로만 조정한다.
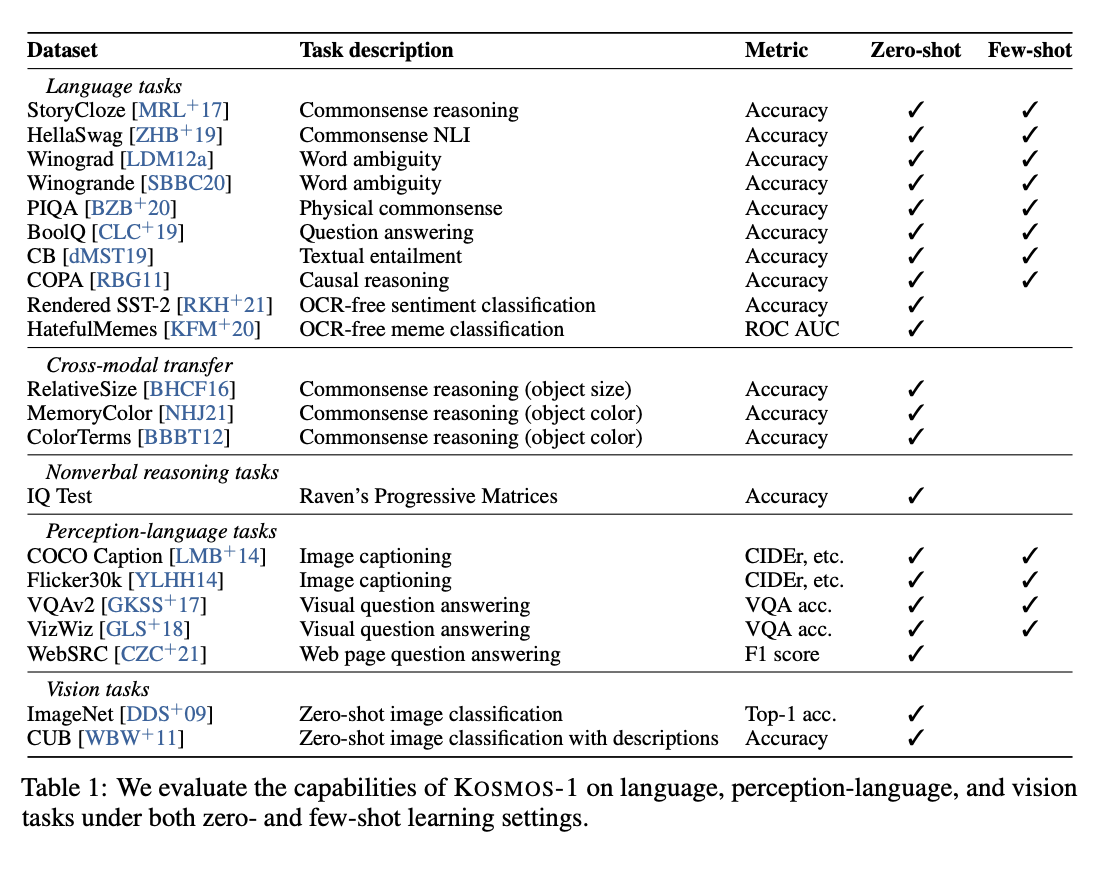

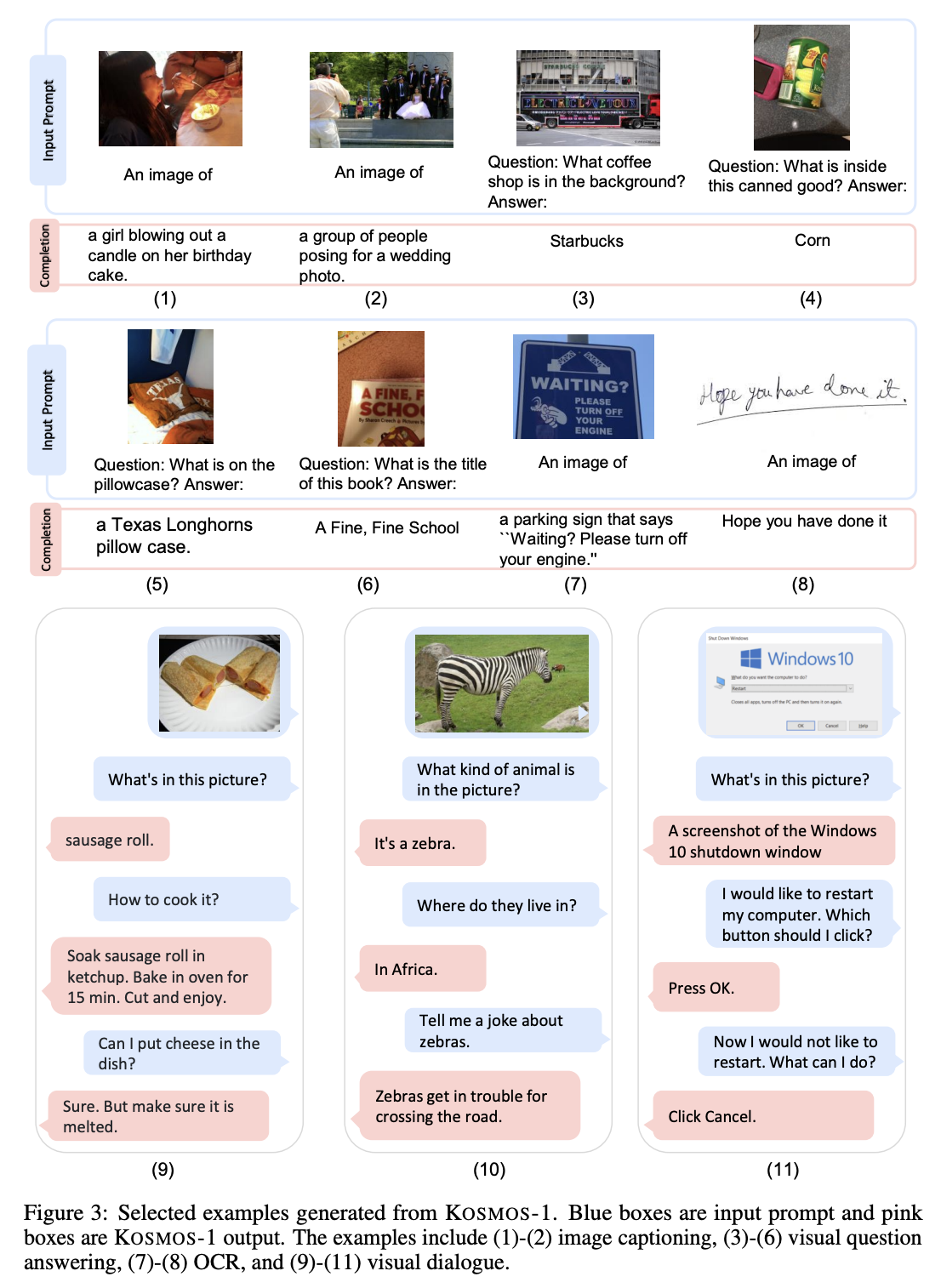
테이블 1에서, KOSMOS-1은 language, 언어 이해 그리고 비젼 테스크를 지원한다. Figure2&3에서 예시를 보여준다. 이미지 설명, 이미지 질문, 캡셔닝, 간단한 수학, OCR, zero-shot 분류등을 수행할 수 있다. 그리고 제작한 IQ benchmark를 보였고, 이는 MLLM을 새롭게 적용할 수 있는 테스크로 여겨진다. MLLM이 LLM보더 더 많은 지식을 얻을 수 있는 것을 보인다.
From LLMs to MLLMs
적절히 인식하는 법을 다루는 것은 일반적인 인공지능을 위한 중요한 단계이다. 멀티모달 인풋의 이해는 LLM에 크리티컬하다. 멀티모달 데이터는 LLM이 텍스트를 뛰어넘는 정보를 습득하게 한다. 그리고 이는 로봇, 문서 이해 등 더 많은 확장된 테스크를 가능케 한다. 언어와 이미지를 이해하는 것은 사용자와 더 자연스러운 소통을 하게 한다. 이를 위해 웹에서의 멀티모달 데이터를 수집하여 사용한다.
Language models as general-purpose interfaces
METALM에서 제안된 방식에 따라, 언어 모델을 광범위한 테스크 레이어로 여긴다. 아웃풋의 방식이 정해져있지 않기 때문에 다양한 테스크의 예측을 텍스트로 할 수 있다. 게다가 언어 지시나 action의 연속은 언어 모델로 다룰 수 있다. 복잡한 테스크에서의 인지또한 가능케하여 제네럴한 능력을 지닌다.
New capabilities of MLLMs
테이블 1에서, 이전 LLM과 달리 MLLM은 새로운 가능성을 지닌다. zero&few-shot 학습을 언어 지시로 가능케 한다. 사람의 능력을 평가하는 Raven QI test를 통해 비언어적 추론 능력을 확인한다. 여러 모달리티로 일반적인 소통을 지원한다.(멀티턴)
KOSMOS-1: A Multimodal Large Language Model
KOSMOS-1은 그림 1과 같이 다양한 모달리티를 인식하고, 지시를 따르며, 문맥을 학습하고, 출력을 생성할 수 있는 멀티모달 언어 모델이다. 이 모델은 주어진 문맥을 기반으로 텍스트를 오토리그레시브 방식으로 생성하도록 학습된다. KOSMOS-1의 백본은 Transformer 기반의 인과적 언어 모델이며, 텍스트 외의 다른 모달리티 또한 임베딩되어 언어 모델에 입력된다. Transformer 디코더는 멀티모달 입력에 대한 범용 인터페이스 역할을 한다. KOSMOS-1은 단일 모달 데이터, 크로스모달 페어 데이터, 그리고 모달리티가 뒤섞인 데이터 등 다양한 멀티모달 말뭉치로 학습되며, 학습이 완료된 후에는 언어 과제와 멀티모달 과제 모두에 대해 제로샷 또는 퓨샷 설정으로 바로 평가가 가능하다.
Input Representation

Transformer 디코더는 통합적인 방식으로 제네럴 모달리티를 이해한다. 인풋을 연속적으로 spectial token과 나열한다.
특히 <s>, </s>를 스타트와 끝으로 사용한다.
<image>, </image>를 이미지 임베딩의 끝으로 사용한다.
ex. (<s> paragraph <image> Image Embedding </image> paragraph </s>)
임베딩 모듈은 텍스트 토큰과 다른 모달리티를 벡터로 변경한다. 그리고 디코더에 넣는다. 모달리티의 연속적인 시그널은 구별 가능하도록 인풋으로 표현되어 사용가능하다. 비젼 인코더를 이미지 임베딩으로 이용하고 플라밍코의 Resampler로 토큰수를 조정한다.
Multimodal Large Language Models (MLLMs)
인풋 시퀀스의 임베딩을 얻고 난 후, decoder에 전달한다. left-to-right 모델은 이전 토큰 기반으로 생성하는 auto-regressive 방식으로 진행한다. masking은 일반적으로 이후 토큰들에 사용된다. softmax classifier가 토큰을 생성하기 위해 사용된다.
MLLM은 언어와 멀티모달에 상호작용 가능하게 제공한다. 전부 vector로 표현함으로써 이를 가능케 한다. LLM은 자연스럽게 in-context learning과 instruction following을 지닌다. 멀티모달 데이터를 학습함으로써 얼라인을 맞춘다.
MAGNETO
우리는 트랜스포머의 친구인 MAGNETO를 백본으로 사용하며 이는 학습 안정성과 모달리티에 대해 능력이 더 뛰어나다. extra LayerNorm을 각각의 sublayer로 유도한다. 이는 최적화를 향상시키는 이론적으로 초기화 방법을 가진다.
xPOS
포지션 인코딩과 관련된 xPOS는 긴 문맥 모델링에 도움을 준다. 해당 방식은 다른 길이를 제네럴하게 수행한다. 포지션 정보를 더 정밀하게 포착하기 위해 attention 해상도를 최적화한다. 이는 효율적인 보간 및 예측에 사용된다.
Training Objective
KOSMOS-1은 웹 스케일의 멀티모달 말뭉치를 활용해 학습되며, 이 말뭉치에는 단일 모달 데이터(예: 텍스트 코퍼스), 크로스모달 페어 데이터(예: 이미지-캡션 쌍), 그리고 이미지와 텍스트가 임의로 섞여 있는 인터리브드 멀티모달 데이터가 포함된다. 구체적으로는 단일 모달 데이터를 표현 학습에 활용하며, 텍스트 데이터를 활용한 언어 모델링을 통해 지시 따르기, 문맥 기반 학습, 다양한 언어 과제에 대한 사전학습이 이루어진다. 또한, 크로스모달 페어와 인터리브드 데이터를 통해 다양한 모달리티의 인식과 언어 모델 간의 정렬을 학습한다. 특히, 인터리브드 데이터는 멀티모달 언어 모델링 과제에 자연스럽게 부합하는 특성을 지닌다. 학습 데이터 수집에 대한 더 자세한 내용은 3.1절에서 설명된다.
모델은 다음 토큰 예측 과제를 통해 학습되며, 이는 주어진 문맥을 기반으로 다음 토큰을 생성하는 방식이다. 학습 목표는 예제 내 토큰들의 로그 가능도(log-likelihood)를 최대화하는 것이다. 학습 손실에는 텍스트 토큰처럼 이산적인 토큰만이 반영된다. 멀티모달 언어 모델링은 모델 학습을 위한 확장 가능한 접근 방식이며, 다양한 능력의 자연스러운 발현은 다운스트림 응용에서 매우 유리하게 작용한다.
Model Training
Multimodal Training Data
KOSMOS-1은 웹 스케일의 멀티모달 말뭉치를 기반으로 학습되며, 학습 데이터셋은 텍스트 코퍼스, 이미지-캡션 쌍, 이미지와 텍스트가 섞인 인터리브드 데이터로 구성된다.
텍스트 코퍼스는 The Pile과 Common Crawl(CC)을 활용하였다. The Pile은 대규모 언어 모델 학습을 위해 다양한 소스로부터 구축된 대용량 영어 텍스트 데이터셋으로, GitHub, arXiv, Stack Exchange, PubMed Central의 데이터는 제외하였다. Common Crawl 스냅샷(2020-50, 2021-04), CC-Stories, RealNews 등의 데이터도 포함되며, 모든 데이터는 중복 및 유사 문서를 제거하고 다운스트림 과제에 해당하는 데이터는 필터링되었다. 자세한 설명은 Appendix B.1.1에 수록되어 있다.
이미지-캡션 쌍은 English LAION-2B, LAION-400M, COYO-700M, Conceptual Captions 등의 데이터셋으로 구성된다. LAION 및 COYO 데이터는 Common Crawl 웹 페이지에서 이미지와 해당 alt-text를 추출하여 생성되었으며, Conceptual Captions 역시 인터넷 웹 페이지에서 수집된 데이터다. 세부 내용은 Appendix B.1.2에 설명되어 있다.
인터리브드 이미지-텍스트 데이터는 Common Crawl 스냅샷에서 수집되었다. 전체 약 20억 개의 웹 페이지 중 필터링을 통해 약 7,100만 개의 웹 페이지를 선별하고, 각 HTML 문서로부터 텍스트와 이미지를 추출하였다. 문서당 이미지 수는 5개로 제한하여 노이즈와 중복을 줄였으며, 이미지가 하나만 포함된 문서는 절반을 무작위로 제외하여 데이터 다양성을 확보하였다. 해당 수집 과정의 상세 내용은 Appendix B.1.3에 기술되어 있다. 이러한 코퍼스를 통해 KOSMOS-1은 텍스트와 이미지가 섞인 입력을 효과적으로 처리하고, 퓨샷 학습 능력을 향상시킬 수 있다.
Training Setup
멀티모달 언어 모델(MLLM) 구성은 총 24개의 레이어로 이루어져 있으며, 히든 차원은 2,048, FFN 중간 차원은 8,192, 어텐션 헤드는 32개로, 전체 약 13억 개의 파라미터를 가진다. 최적화 안정성을 위해 Magneto 초기화 방식을 사용하였다. 학습 수렴 속도를 높이기 위해 이미지 표현은 사전학습된 CLIP ViT-L/14 모델에서 추출하며, 해당 모델의 출력 특성 차원은 1,024이다. 학습 중에는 CLIP 모델의 마지막 레이어를 제외한 모든 파라미터를 고정(freeze)시킨다. 전체 KOSMOS-1 모델의 파라미터 수는 약 16억 개이며, 하이퍼파라미터에 대한 더 자세한 내용은 Appendix A에 설명되어 있다.
학습에는 총 120만 토큰의 배치 크기를 사용하며, 이 중 50만 토큰은 텍스트 코퍼스, 50만 토큰은 이미지-캡션 쌍, 나머지 20만 토큰은 인터리브드 데이터에서 추출된다. 총 30만 스텝 동안 학습이 진행되며, 이는 약 3600억 개의 토큰을 학습하는 양에 해당한다. 옵티마이저로는 AdamW를 사용하며, β는 (0.9, 0.98)로 설정하였다. weight decay는 0.01, dropout rate는 0.1로 설정되었으며, 학습률은 처음 375 스텝 동안 2e-4까지 선형 증가한 뒤 나머지 스텝에서는 선형 감소한다.
텍스트 토크나이징에는 SentencePiece를 사용하며, 입력 데이터는 “full-sentence” 포맷으로 전처리되었다. 이 포맷은 하나 이상의 문서에서 연속적으로 샘플링한 전체 문장 단위로 시퀀스를 구성하는 방식이다.
Language-Only Instruction Tuning
사람에 지시에 더욱 효과적으로 맞추기 위해, launguage-only 지시학습을 진행한다. 특별하게 우리는 지시 데이터를 계속해서 학습시킨다. 해당 데이터는 트레이닝과 섞인 언어만 있다. 튜닝 과정은 언어 모델링 과정에 포함된다. 지시와 인풋은 로스에 계산되지 않는다.
Unnatural Instruction과 FLANv2가 결합되어 지시 데이터로 사용된다. Unnatural Instruction은 LLM을 사용해 생성한 지시문이다. 68,478의 input, output, instruction triplet으로 구성된다. FLANv2는 54,000개를 랜덤으로 뽑아 사용했으며 여기는 읽기 이해, 추론, 답변 등이 포함된다.
Evaluation
Perception-Language Tasks
KOSMOS-1을 vision-language 세팅에서 이미지 캡셔닝과 VQA를 통해 zero-shot&few-shot 테스트를 진행한다. 캡셔닝은 이미지 내용의 언어 생성을 포함하며, VQA는 이미지에 대한 질문의 답변이다.
“An image of”이란 프롬프트를 기반으로 캡셔닝 테스트에 사용했다. (아마 clip기반의 비젼 인코더를 가지고 있어서 인가?) “Question: {question} Answer: {answer}” 을 기반으로 VQA 테스트에 사용한다.
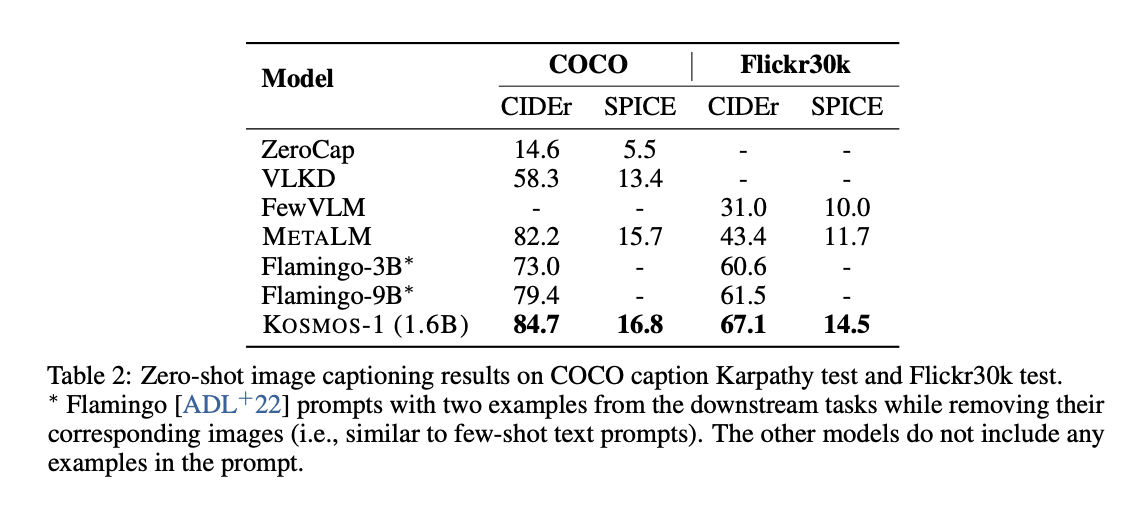
테이블 2에서 캡셔닝 zero-shot 결과를 확인한다. Flamingo model들보다 더 뛰어남과 동시에 모델 사이즈도 작다.
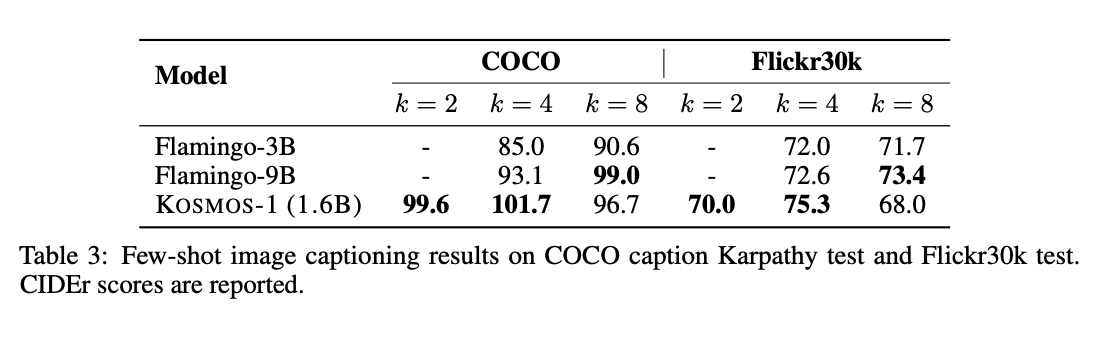
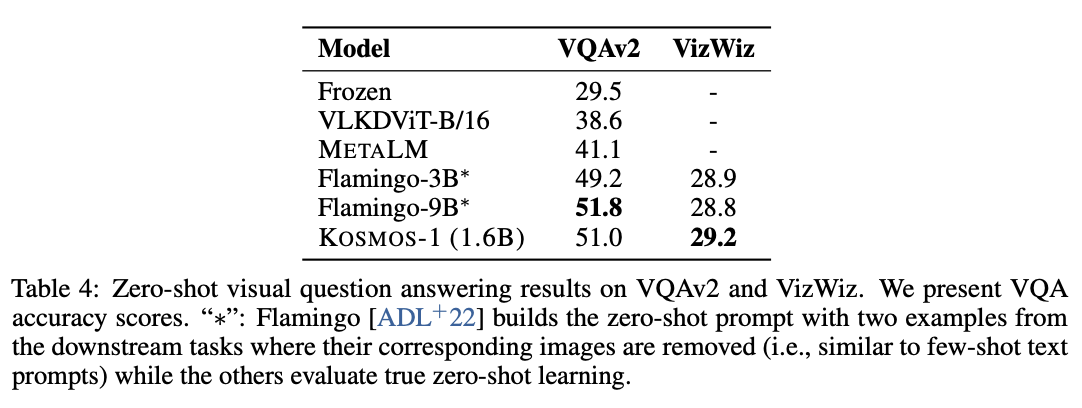
테이블 4는 VQA의 결과를 보인다. KOSMOS가 다양하고 복잡한 VizWiz 데이터셋에서 뛰어남을 보인다.
IQ Test: Nonverbal Reasoning
개인의 IQ를 표현하는 비언어적추론 능력이다. Figure 4에서 예시를 보인다. 해당 테스트는 모델의 in-context learning과 유사하다. 답변을 위해서는 추상적인 컨셉을 이해하고 이미지에서 패턴을 풀어야한다. 그래서 IQ테스크는 비언어적 능력 테스트에 좋은 방식이다. “Here are three/four/eight images:”, “The following image is:”, “Is it correct?” 과 같은 프롬프트는 사용한다.
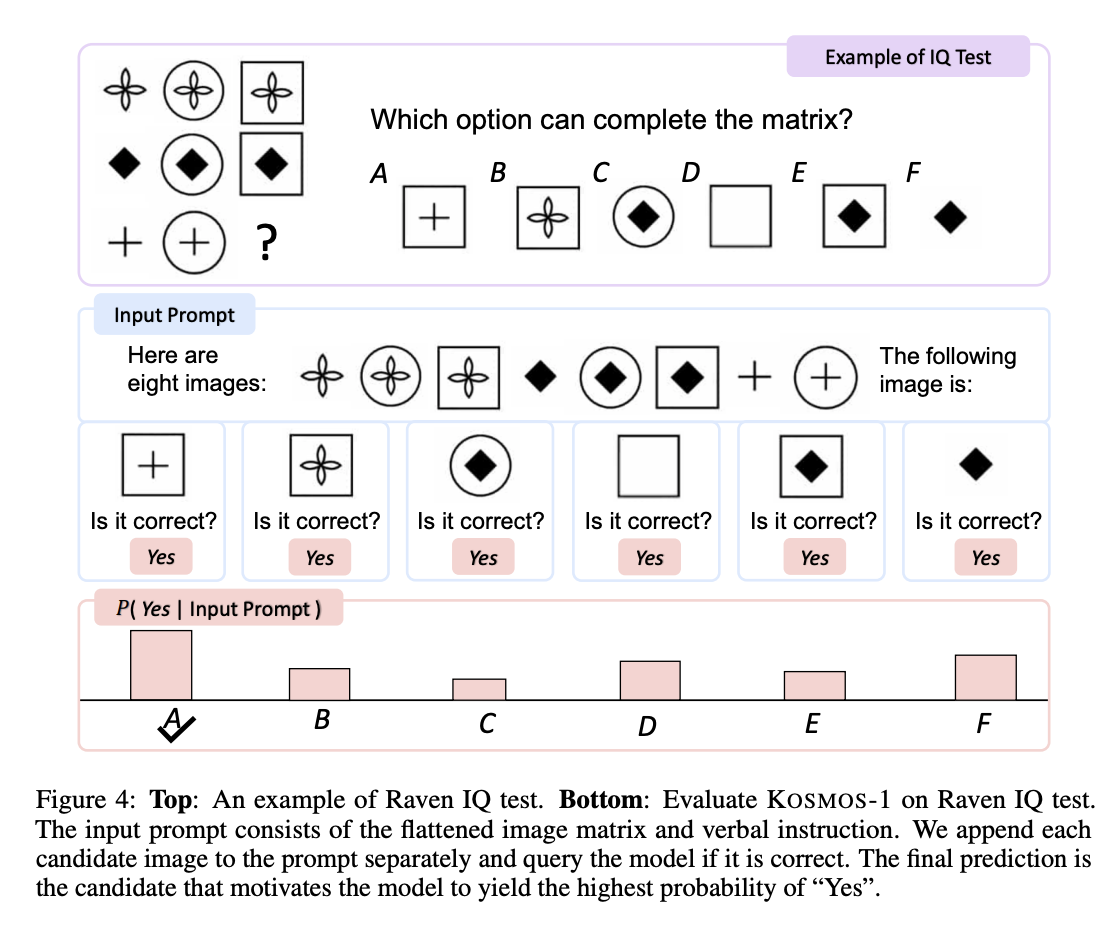

테이블 6는 IQ테스트의 결과이다. 랜덤 선택보다 5~9퍼센트 좋은 결과를 얻었다. 어른에 비하면 한참 모자르지만 MLLM의 가능성을 보인다.
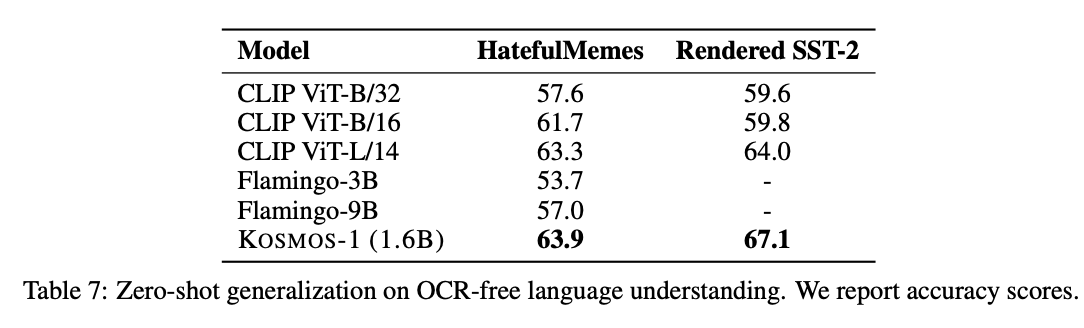
OCR-Free Language Understanding
OCR에 의존하지 않고 이미지와 언어 이해를 통해 OCR-Free 언어 이해를 수행한다. “Question: what is the sentiment of the opinion? Answer: {answer}” “Question: does this picture contain real hate speech? Answer: {answer}”를 수행한다.
Web Page Question Answering
웹 페이지 질문응답 과제에서 KOSMOS-1은 웹 페이지의 텍스트뿐만 아니라 이미지(레이아웃, 구조 포함)를 함께 활용해 정보를 이해한다. 기존 LLM보다 더 높은 성능을 보였으며, 이는 이미지가 구조적 정보 이해에 도움이 되었기 때문이다. 또한 텍스트 없이 이미지만 사용했을 때 성능이 떨어졌고, 텍스트 추가 시 EM 12.0, F1 20.7 만큼 성능이 향상되어 이미지와 텍스트의 결합이 핵심이라는 점이 드러났다. “Given the context below from web page, extract the answer from the given text like this: Qusestion: Who is the publisher of this book? Answer: Penguin Books Ltd. Context: {WebText} Q: {question} A: {answer} ”,
Multimodal Chain-of-Thought Prompting
KOSMOS-1은 Chain-of-Thought prompting 개념을 멀티모달 설정에 적용해, 복잡한 과제를 두 단계로 나누어 해결하는 방식을 제안한다. 먼저 이미지에 대해 설명(rationale)을 생성한 후, 이를 바탕으로 감정 분석 등의 최종 결과를 도출한다. Rendered SST-2 데이터셋 실험에서 이 멀티모달 CoT 방식은 기존보다 5.8점 높은 정확도(72.9)를 기록하며, 중간 추론 과정을 통해 이미지 속 텍스트 인식과 의미 추론이 개선됨을 보여준다.


Zero-Shot Image Classification
KOSMOS-1은 ImageNet에서 제로샷 이미지 분류 성능을 평가하였으며, 입력 이미지에 “The photo of the”라는 프롬프트를 붙여 카테고리명을 생성한다. 평가 결과, KOSMOS-1은 GIT 대비 제한된 조건에서는 4.6%, 비제한 조건에서는 2.1% 더 높은 정확도를 기록하며 우수한 성능을 보였다. 이는 텍스트 없이도 이미지 전체를 이해하고 정확히 분류할 수 있는 멀티모달 추론 능력을 보여준다.


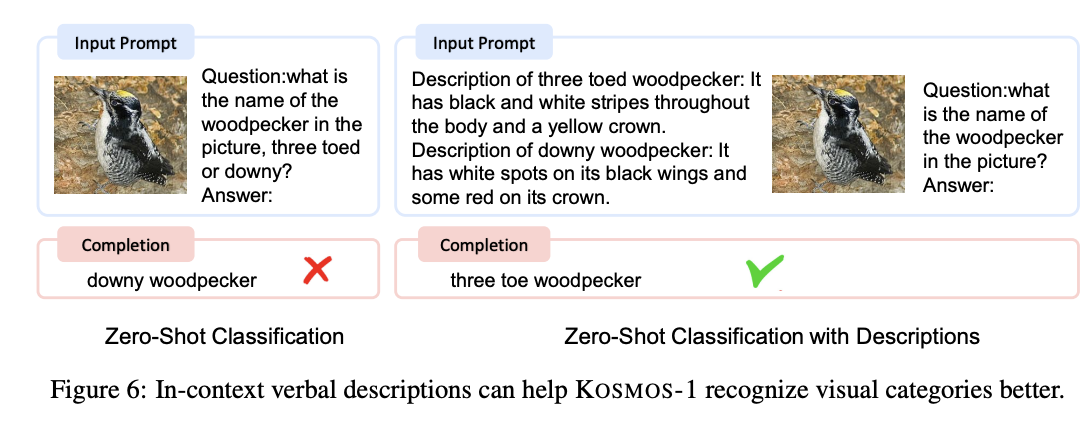
Zero-Shot Image Classification with Descriptions
KOSMOS-1은 자연어 설명을 활용하여 제로샷 이미지 분류를 개선할 수 있다. 특히, 복잡한 동물 아종 분류와 같이 사용자나 상황에 맞춘 분류 규칙을 적용할 수 있다. 평가에서, 두 특정 동물 카테고리에 대한 설명을 제공하여 이미지를 분류하는 방식으로 성능을 측정했다. 자연어 설명을 제공한 경우 이미지 분류 정확도가 크게 향상되었으며, 이는 KOSMOS-1이 언어적 지시를 잘 이해하고 시각적 특성과 잘 결합할 수 있음을 보여준다.

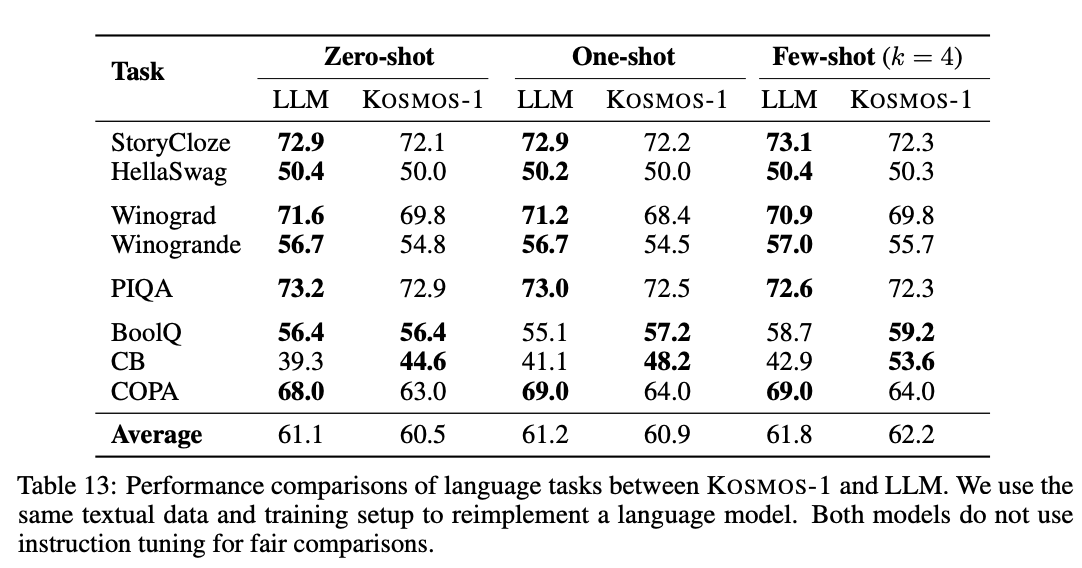
Language Tasks
KOSMOS-1은 언어 작업에서 zero-shot 및 few-shot 설정에서 평가되었으며, cloze 및 completion 작업, Winograd 스타일 문제, commonsense reasoning 등 다양한 언어 작업에서 LLM과 비교하여 유사하거나 더 나은 성능을 보였다. KOSMOS-1은 특히 few-shot(4-shot) 설정에서 더 우수한 성능을 보였으며, 이는 언어-only 작업에서 좋은 성과를 거두었음을 나타낸다. 또한, MLLM은 시각적 commonsense 지식을 더 잘 학습하는 경향이 있다.
Cross-modal Transfer
KOSMOS-1의 교차 모달 전이 능력을 평가하기 위해, 언어-모달 지시 튜닝의 효과를 COCO, Flickr30k, VQAv2, VizWiz와 같은 이미지 캡셔닝 및 시각적 질문 응답 데이터셋을 사용하여 실험하였다. 결과는 Flickr30k에서 1.9점, VQAv2에서 4.3점, VizWiz에서 1.3점 향상되었음을 보여주며, 언어 지시 튜닝이 모델의 다양한 모달리티에서 지시를 잘 따를 수 있는 능력을 크게 향상시켰다는 것을 의미한다. 이는 모델이 언어에서 다른 모달리티로 지시 수행 능력을 전이할 수 있음을 나타낸다.


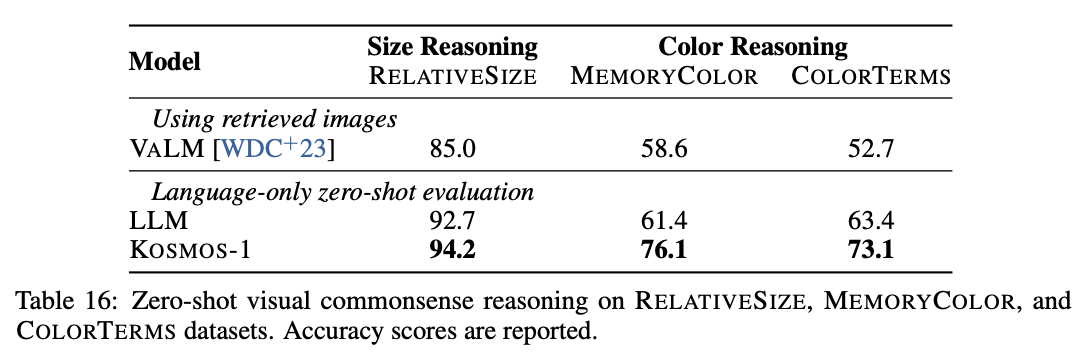
KOSMOS-1은 시각적 상식 추론 작업에서 언어 모델(LLM)보다 우수한 성능을 보였다. 세 가지 객체 상식 추론 데이터셋(RELATIVESIZE, MEMORYCOLOR, COLORTERMS)에서 KOSMOS-1은 각각 RELATIVESIZE에서 1.5%, MEMORYCOLOR에서 14.7%, COLORTERMS에서 9.7% 더 높은 정확도를 기록했다. 이 결과는 KOSMOS-1이 시각적 지식을 활용하여 해당 작업을 더 잘 수행할 수 있다는 것을 나타낸다. KOSMOS-1은 모달리티 전이 능력을 통해 시각적 지식을 언어 작업에 전이할 수 있는 반면, LLM은 텍스트 기반 지식에 의존해야 하므로 객체 속성에 대한 추론 능력이 제한된다.
Conclusion
context-learning을 수행하고, 지시를 수행하고, 일반적인 모달리티를 인지할 수 있는 MLLM인 KOSMOS-1를 제시한다. 모델은 web 규모의 멀티모달 데이터를 학습하여 광범위한 능력을 습득한다. LLM을 MLLM으로 향하게 하는 새로운 능력과 기회를 보여준다. 나중에는 모델의 크기를 키우고 오디오 능력도 같이 넣어보고자 한다. KOSMOS-1는 멀티모달 학습을 위한 통합된 인터페이스로 사용 가능하다.
🔗 관련 글
