CNN(Convolution Neural Network)
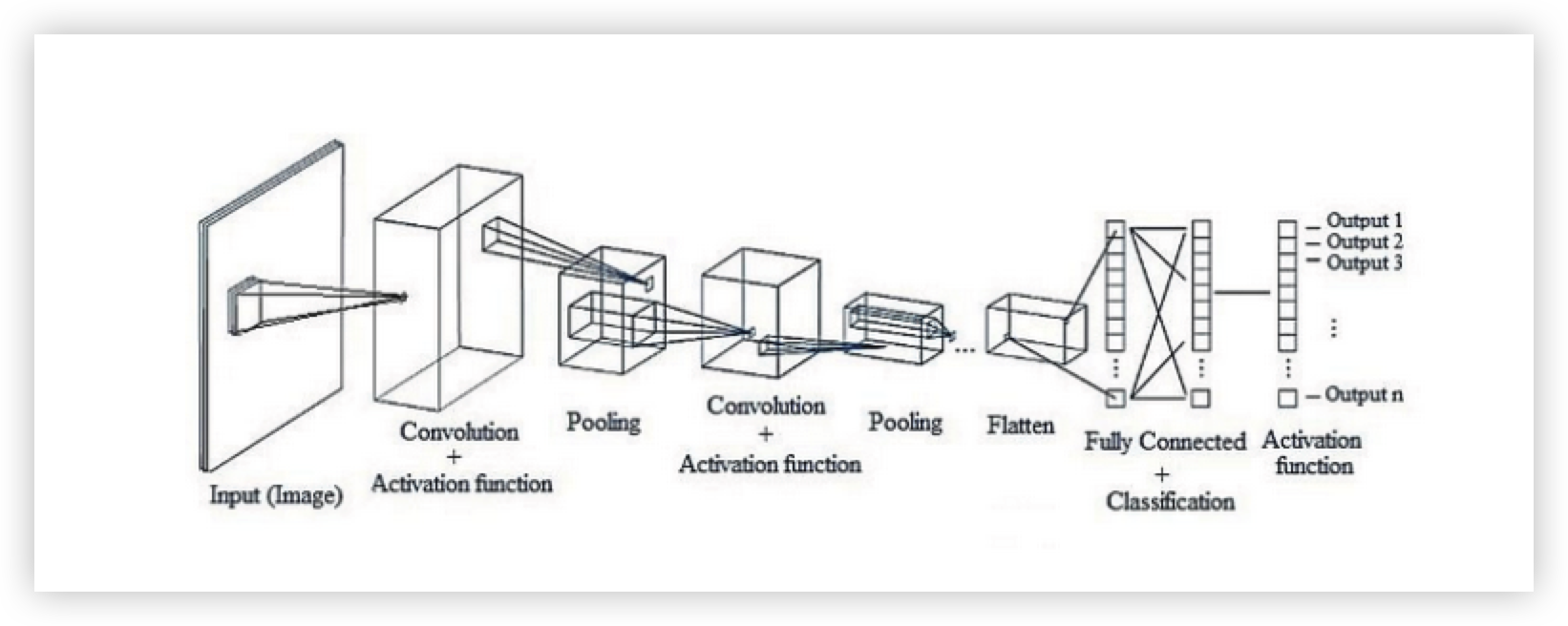
이미지 분류 Task 에서 주로 사용하지만 음성인식, NLP 사용하는 경우도 꽤 많다.
목차
- 이미지에서 Fully-Connected Layer 의 문제점
- CNN 모델의 학습 방법
- CNN 의 전체적인 아키텍처
이미지에서 Fully-Connected Layer 의 문제점
CNN은 이미지 공간정보를 유지하면서 이미지의 특징 또는 패턴을 학습하는 방법으로 모델링 되었다.
이미지에 숫자가 적혀있는 데이터를 분류하는 모델을 학습한다고 예를 들어보겠다.

기본적인 퍼셉트론 모델 Fully Connected Layer 에서 이미지를 학습한다고 했을 때, Fully Connected Layer 에서는 1차원 데이터만 입력으로 받을 수 있기 때문에
2차원 이미지 벡터를 1차원으로 flatten 시켜서 입력레이어에 입력시킨다.
하지만 이미지 데이터를 2차원에서 1차원으로 변형시키면 아래 그림과 같이 전혀 알 수 없는 형태가 입력으로 들어간다.
즉 2차원 이미지를 1차원으로 변경시켜서 학습시키면 이미지의 모양과 위치정보를 학습하는게 아니라, 5 * 5 px 에 존재하는 개별적인 값들을 학습하기 때문이다.
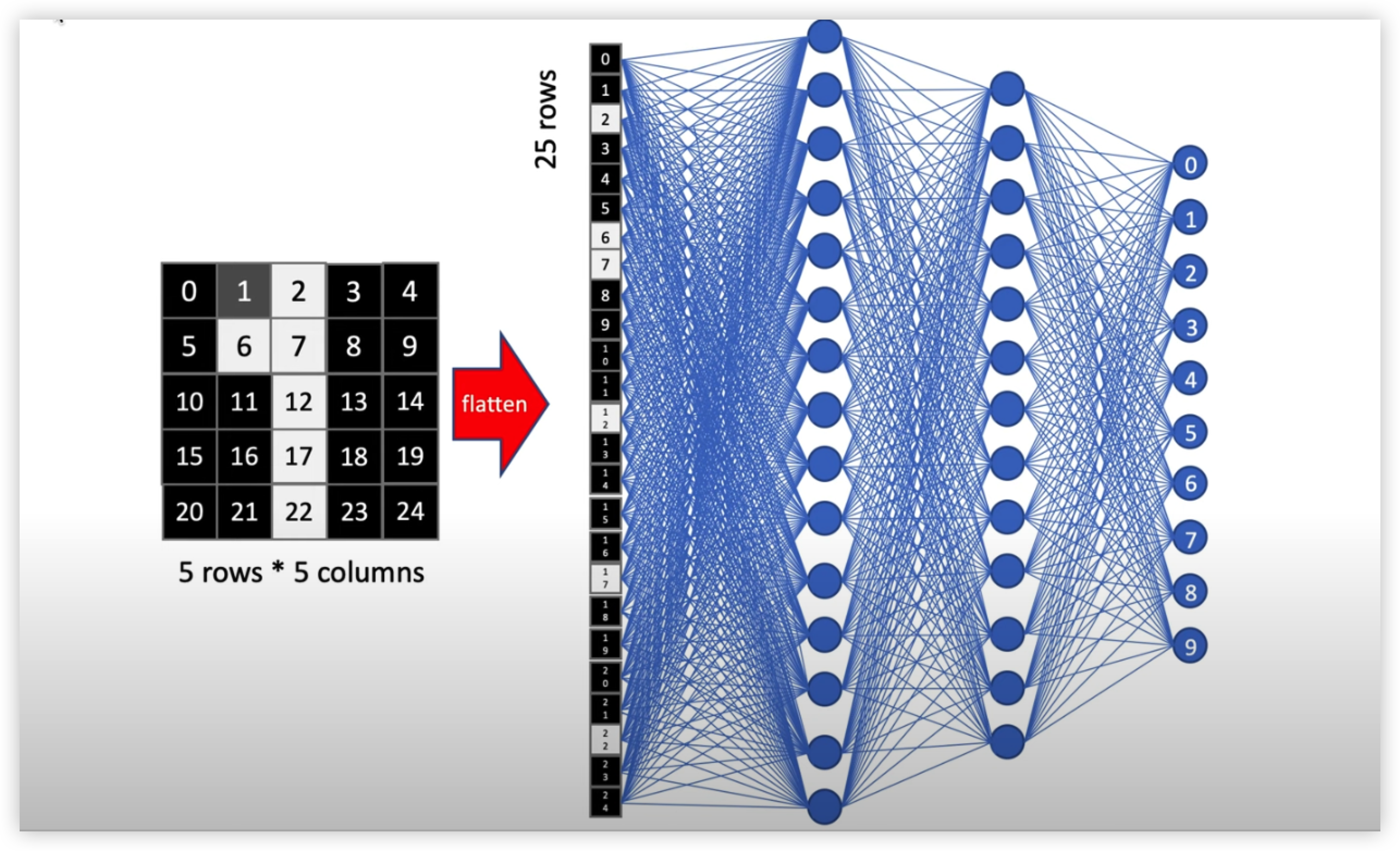
만약 이렇게 학습시킨다면 학습시켰던 데이터와 위치 정보나 모양이 조금만 noise 가 있어도 학습된 인공지능은 굉장히 헷갈려할 것이다.
즉 Overfitting 이 일어나기 굉장히 좋은 조건이 된다.
예를 들어 아래와 같은 A 이미지를 학습시켰다고 가정했을 때,
아래 비슷한 이미지 데이터셋을 아주 많이 학습시켰다고 해도

만약 아래의 A그림처럼 조금만 모양과 위치가 다른 이미지를 테스트 한다면 상당히 낮은 성능을 보여줄 것이다.

정리하자면 FC Layer 로 이미지를 학습했을 때의 문제점은 이미지의 위치나 형태의 특징을 학습할 수 없기 때문에 Overfitting이 일어날 확률이 높아진다.
그렇다면 CNN 은 어떻게 이미지를 학습하길래 FC Layer보다 높은 성능을 낼 수 있을까 ?
CNN 모델의 학습 방법
CNN은 이미지를 2차원으로 유지한 다음 이미지 위치와 특징(패턴)등을 학습한다.
즉 2차원에서 1차원으로 이미지가 변환시키면 사라졌는 특징들이,
2차원 데이터를 유지시킨다면 그 특징들을 잘 추출할 수 있는 것이 핵심이다.
그렇다면 CNN은 어떤 방법으로 특징데이터를 추출할까 ?
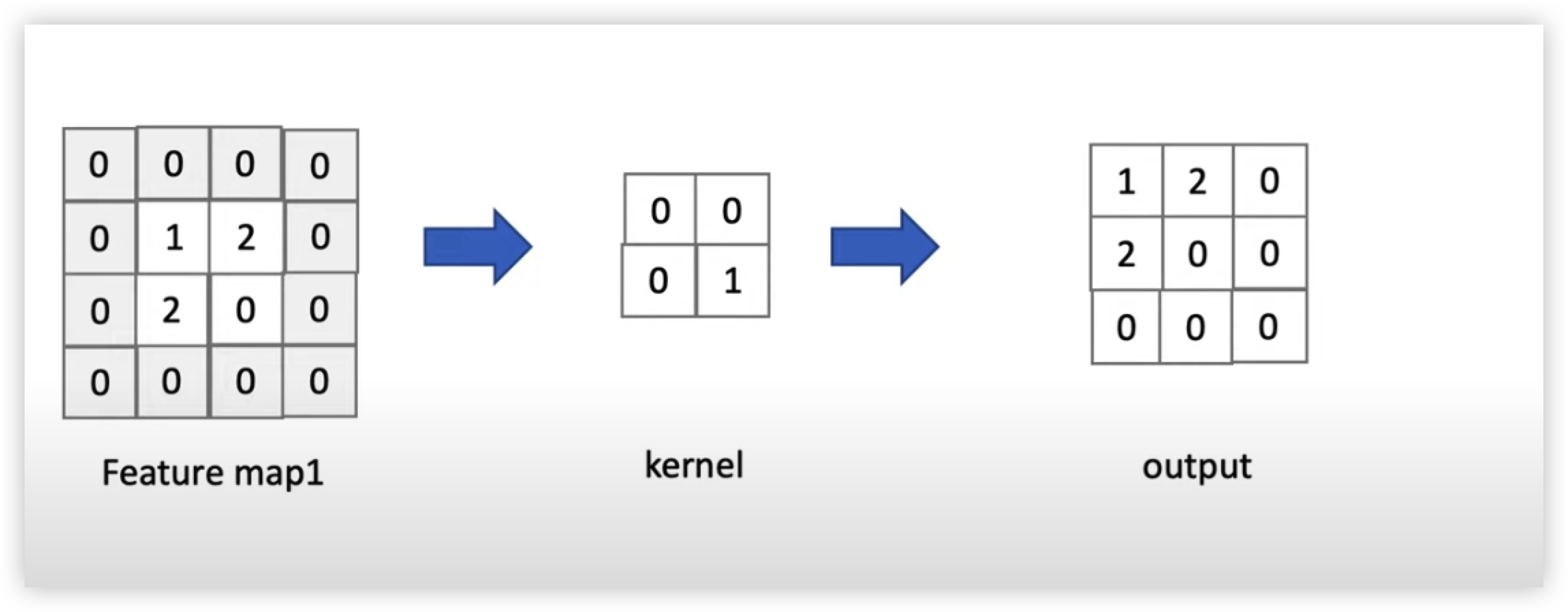
CNN에서는 커널을 이미지 데이터에 내적(Inner Product)해 feature맵을 추출해 이미지 패턴들을 학습한다.
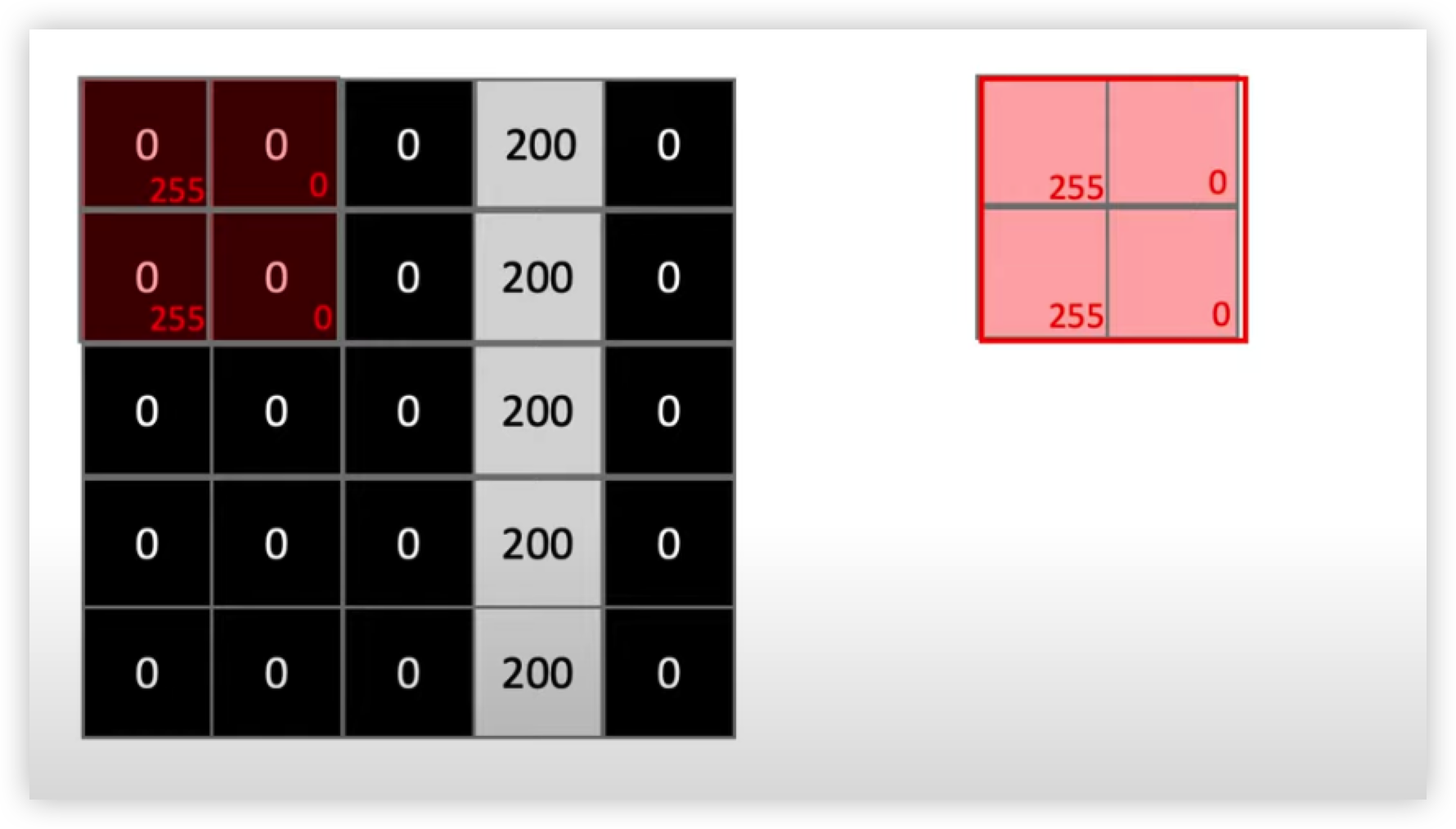
위 그림 오른쪽에 보이는 네모 모양인 2x2 행렬은 커널(=필터)이고
이를 왼쪽에 보이는 숫자 1 이 들어간 5x5 행렬은 이미지 데이터이다.
CNN은 커널(=필터)을 왼쪽에서 오른쪽으로 내적(Inner Product)해서 feature Map 을 만든다.

순차적으로 커널(=필터)과 데이터를 내적해 Feature Map을 만들면 아래 그림과 오른쪽 Matrix와 같은 Feature Map 이 만들어질 것이다.

추가적으로 설명하면
위에서 학습한 커널(=필터)은 Vertical Straight 형태의 특징을 가진 커널(=필터)이다.
이 커널을 숫자 1이 들어간 이미지와 내적해 Feature Map 을 만드는 것은 커널(=필터)의 이미지 패턴 matrix 가 가지고 있는 패턴이 얼마나 포함하는지 그 정도를 계산해 Map 을 만드는 것이다.
만약 해당 커널(=필터)을 가지고 숫자 1이 들어간 train 이미지 데이터의 Feature Map 을 만든다면 모두 완벽하게 똑같진 않겠지만 얼추 비슷하게 Feature Map Matrix 가 나올 것이다.
CNN에서의 가중치 파라미터 (Weight) 이해
현재까지는 커널(필터)와 이미지를 순차적으로 내적해 Feature Map을 추출했었는데 사실 Feature Map을 추출할려면 한가지 과정(bias 를 더해주고 Activation Function을 곱해주는 과정)을 더 수행해야한다.
CNN에서의 가중치 파라미터, 즉 학습해야할 가중치 파라미터는 바로 커널(필터)이다.
다시말해 CNN은 커널을 이미지에 담긴 특징들을 잘 추출할 수 있도록 모델을 학습시키는 것이다.
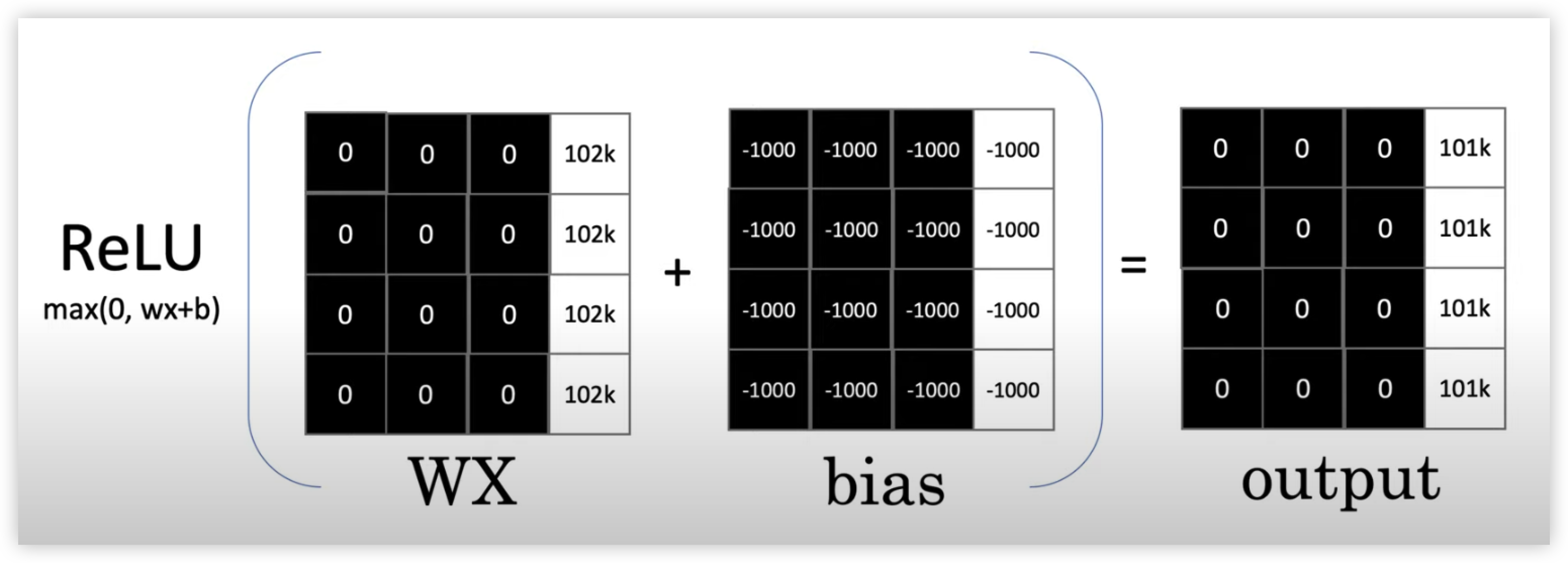
위 그림을 보면 CNN이 출력값(Feature Map)을 만들어내는 식을 볼 수 있는데
WX, W인 Kernel과 X인 이미지 사진을 내적한 것과 bias를 더해준 후 Activation Function(ReLU)을 곱해줘서 출력값(Feature Map)을 만들어낸다.
모델을 학습시키면 모델이 알아서 최적의 W와 bias 값으로 학습한다.
학습전에 개발자가 지정해줘야 할 것은 필터 및 커널의 갯수 및 크기, 초기값 정도이다.
컬러가 있는 이미지는 ?
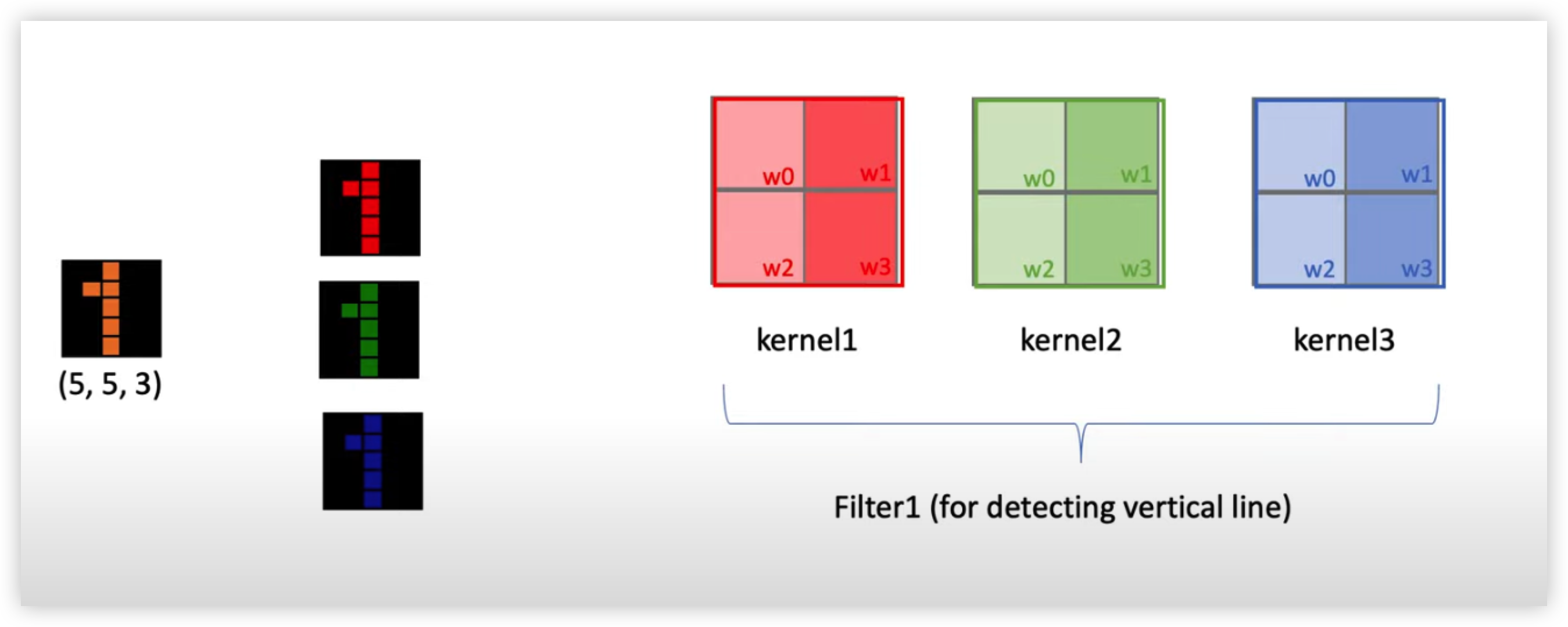
만약 컬러가 있는 이미지 데이터가 입력으로 들어왔다면 차원이 3차원이다.
컬러 이미지는 한장의 이미지 같지만 실제론 R, G, B 의 세가지 이미지가 겹쳐서 만들어진 이미지다. 다시 말해 컬러이미지는 3차원 이미지로, 세가지 channel로 구성되어 있다고 말한다.
Filter 와 Kernel 의 차이를 이해
이전 예제인 흑백 이미지에서는 Kernel과 Filter가 같은 의미로 쓰였다면, 컬러 이미지에선 Filter와 Kernel이 다르다는 것을 이해해야한다.
- Filter는 한가지 특징을 찾기 위한 개념. Filter에는 하나 이상의 Kernel로 이루어져있다.
- 한 개의 Filter에는 Red, Green, Blue 이미지를 돌아다닐 3개의 Kernel이 필요. 즉 Image Channel 의 수와 Filter의 채널의 수, 즉 Kernel의 수는 같아야한다.
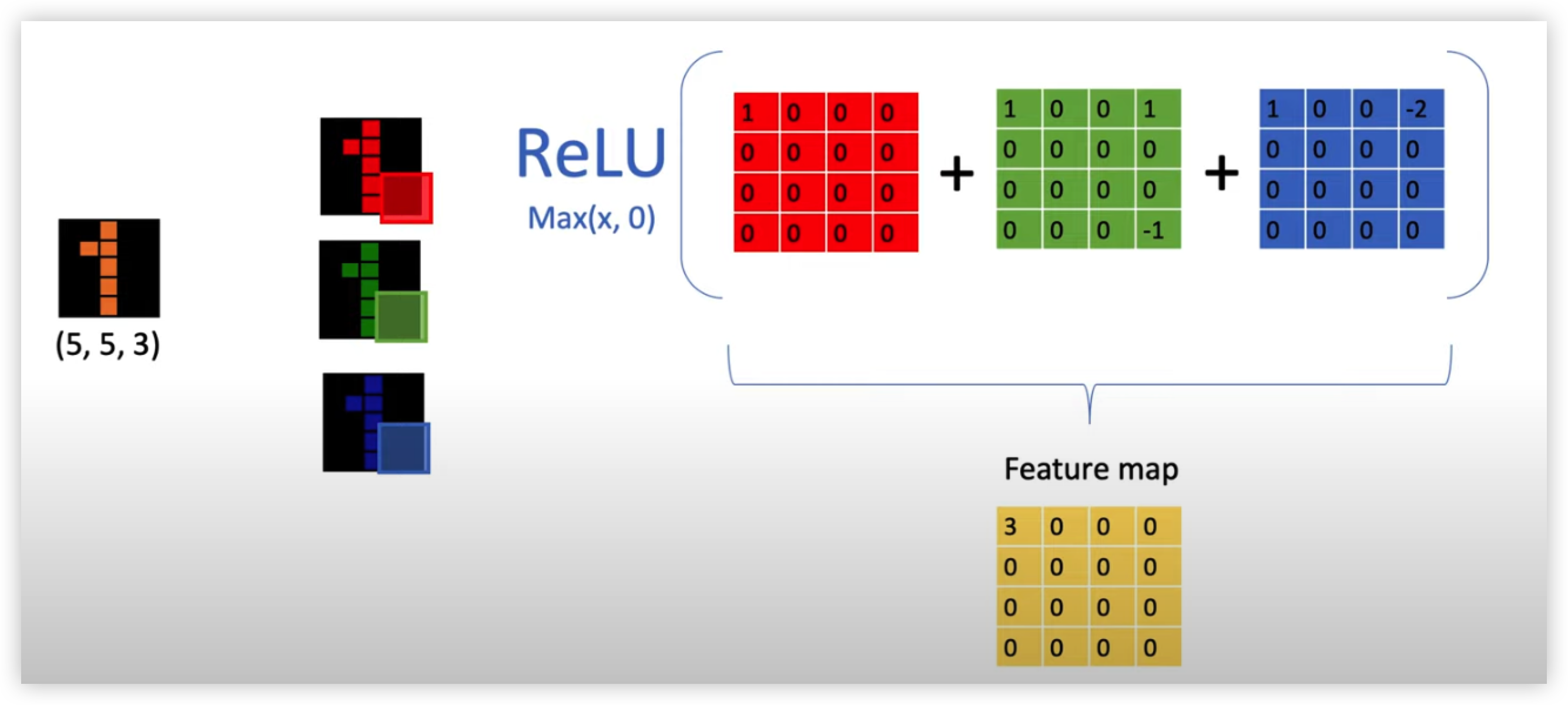
이렇게 위 그림처럼 커널과 해당 채널 이미지를 순차적으로 내적해서 나온 값들을 모두 더하고 그림에서는 생략 되었지만 bias 까지 더해줘서 Activation Function 을 곱해져서 나온 출력값이 해당 필터의 Feature Map이 된다.
CNN의 전체적인 아키텍처
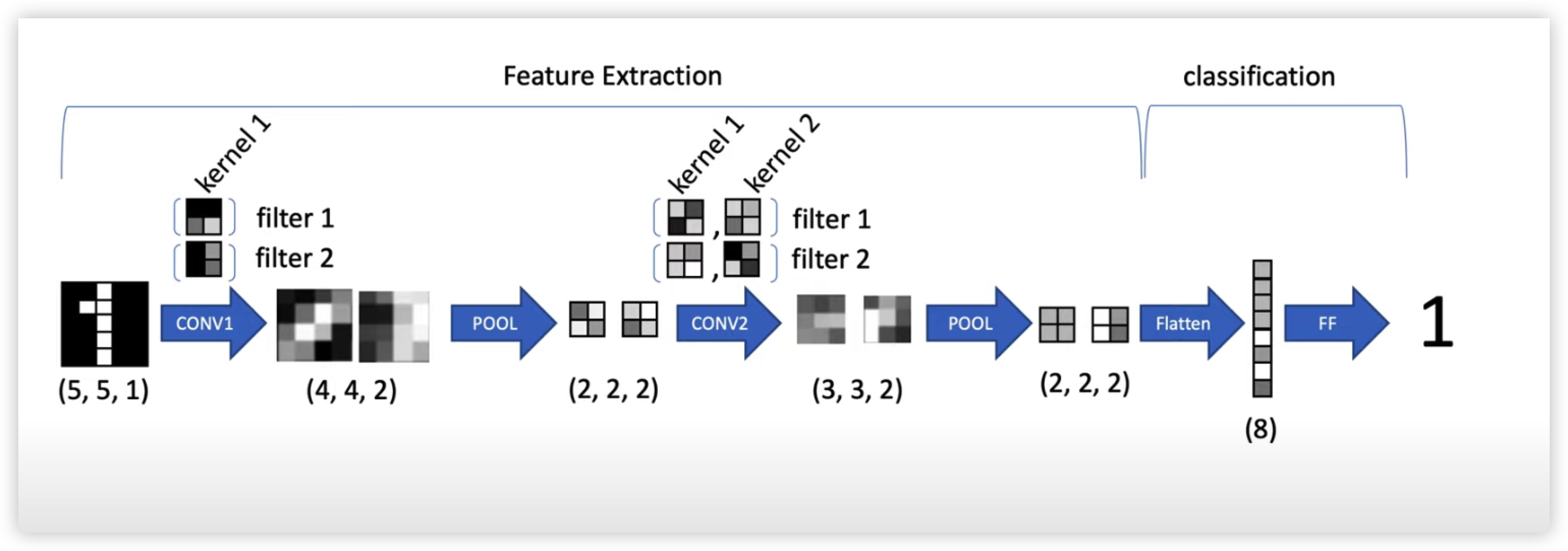
MNIST 숫자 분류
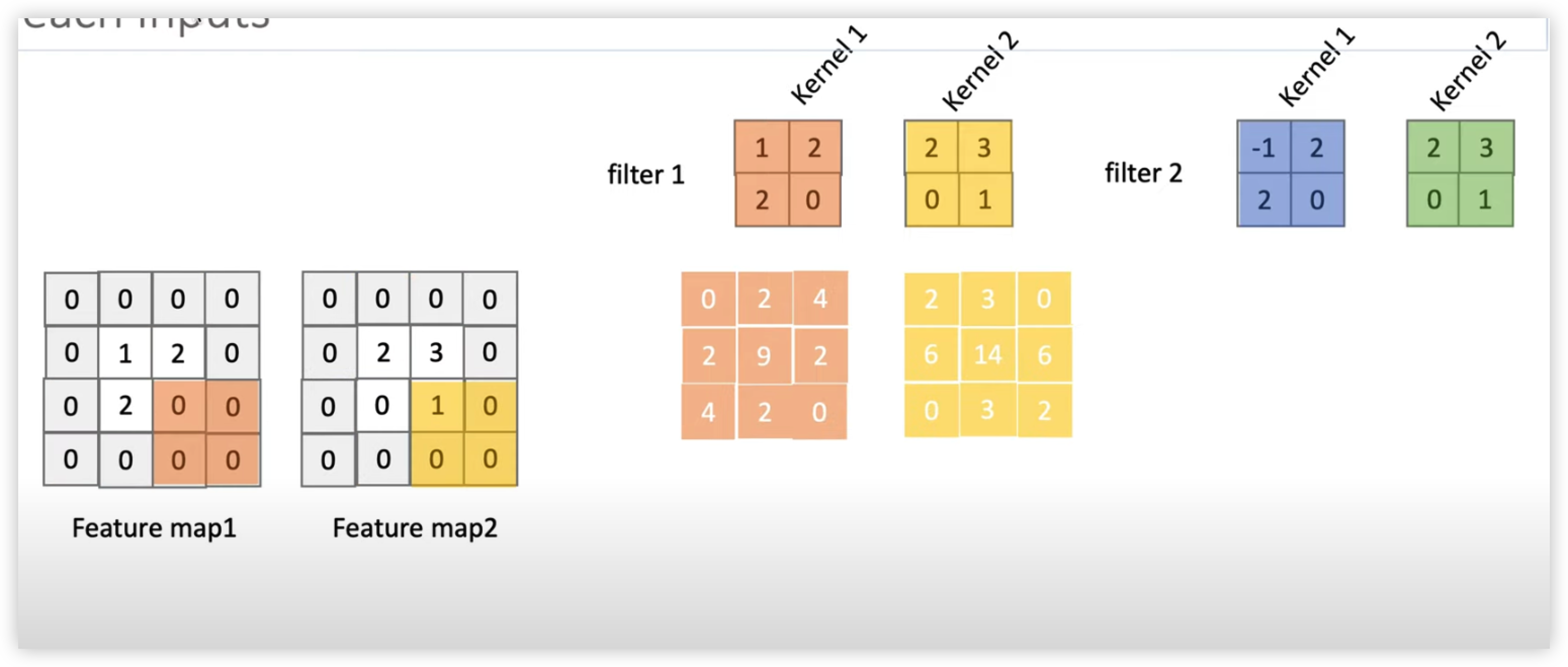
CONV Layer 1 :
각각 다른 2x2 Kernel을 가진 2개의 Filter 로 순차적으로 내적해주면서 만들어진 합성곱의 출력과 bias 를 더해준 후 Activation Function 을 곱해줘서 총 2개의 4x4 Matrix 인 Feature Map 을 만들어준다.
입력 shape => (5, 5, 1) (row, column, channel length)
출력 shape => (2, 2, 2) (row, column, channel length)
POOL (1) :
pooling 은 CNN에서 많이 사용되고 있는 Max Pooling 을 진행해주겠다. (요즘은 Stride 기법을 더 많이 사용하는 추세)
Max pooling 은 바운더리 안에 있는 가장 큰값을 추출한다.
max pooling 을 사용하면 파라미터 개수를 줄일 수 있고 이를 통해 학습 시간을 줄일 수 있다. 또한 파라미터를 줄이면 Overfitting 을 막는 것을 도와줄 수 있다.
아래에 그림 예시를 보면 Max pooling 구현 방법을 빠르게 이해할 수 있다.
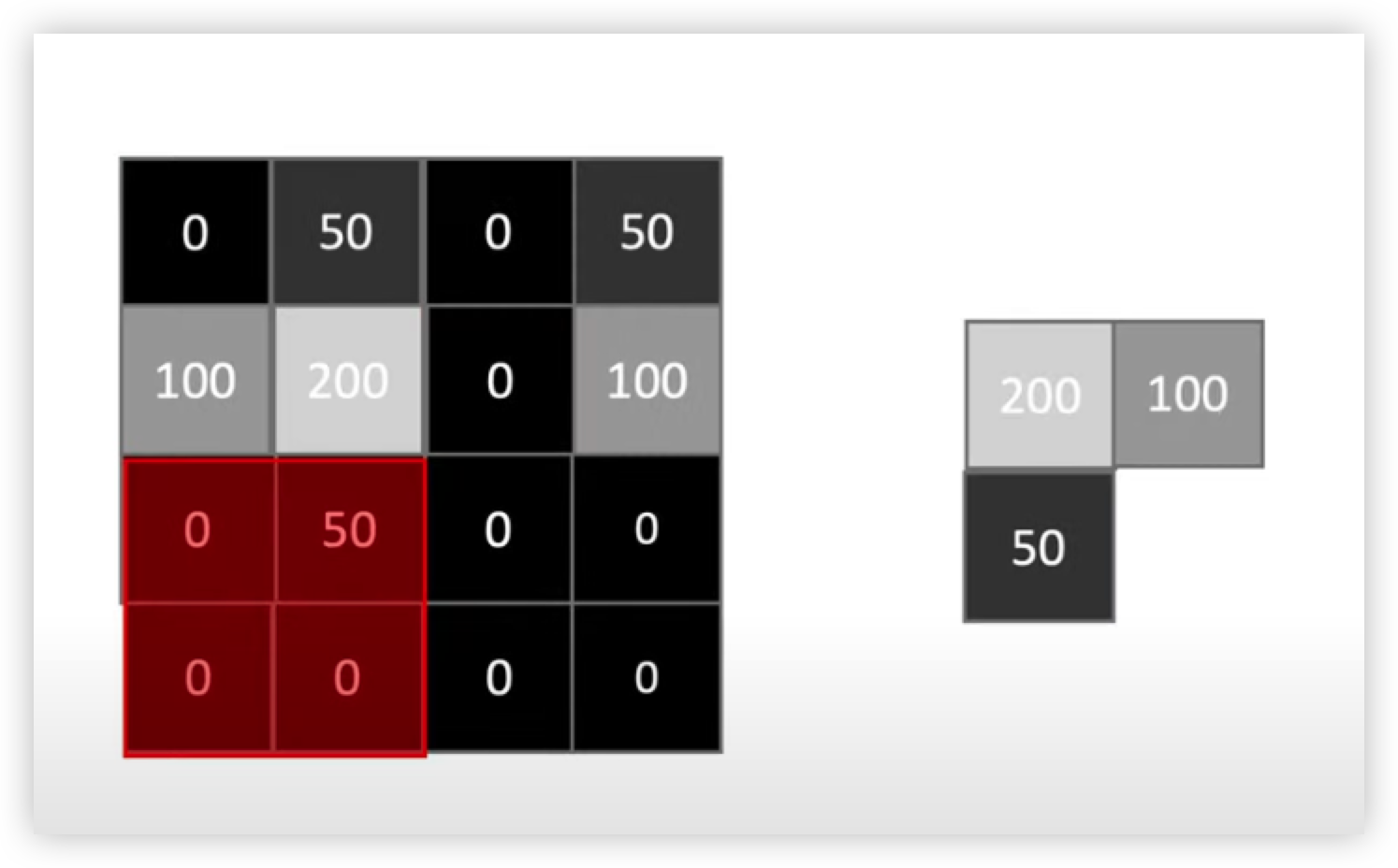
4x4 Feature Map 을 2x2 size 로 Max pooling 을 진행해주면 2x2 사이즈의 출력값으로 2x2 Matrix 2개가 출력된다.
출력 shape => (2, 2, 2) (row, column, channel length)
CONV Layer 2 :
이전 작업을 하면서 Feature Map Size가 너무 많이 줄어서와서 더 이상 합성곱을 진행할 수 없는 상태가 되었다.
이렇게 Feature Map 의 상태가 줄어드는 사태를 방지하기 위한 방법으로는 Padding 기법이 있다.
Padding 은 외곽에 0을 추가한다.
Padding 을 사용하면 2가지 장점이 있다.
- Feature map 의 크기가 줄어드는 것을 방지
- 외곽에 대한 정보도 모델에 알려주는 효과
(Padding 예시 그림)
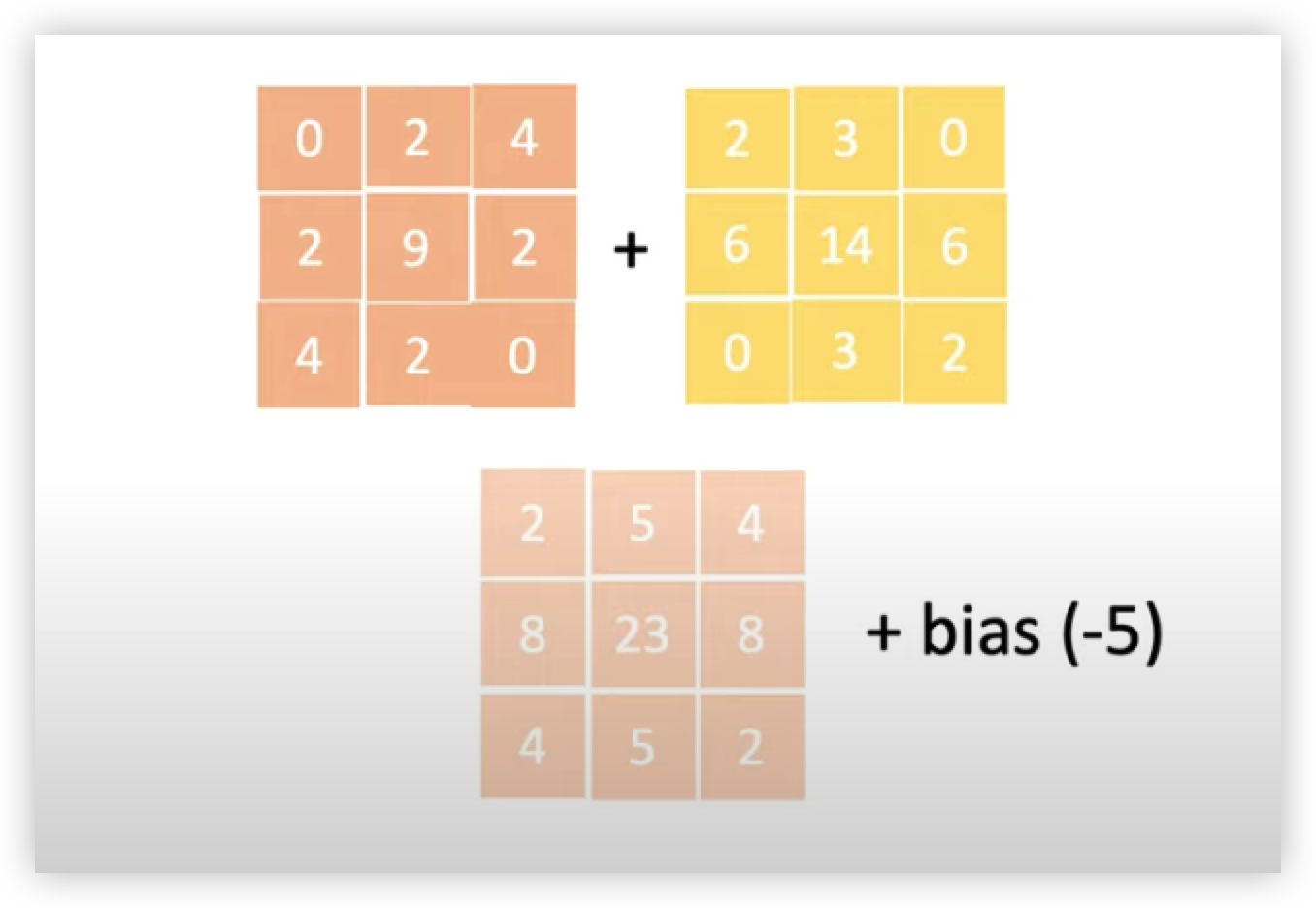
자 다시 CONV Layer2 로 돌아와서 연산을 진행해주면
Padding 을 진행해준 Feature Map 에 순차적으로 커널을 내적해줘서 나온 출력값들 (필터 1의 커널1과 커널2의 출력값)
을 아래의 그림과 같이 더해준 후 + bias
그 후 아래 그림과 같이 activation function 곱해줘서
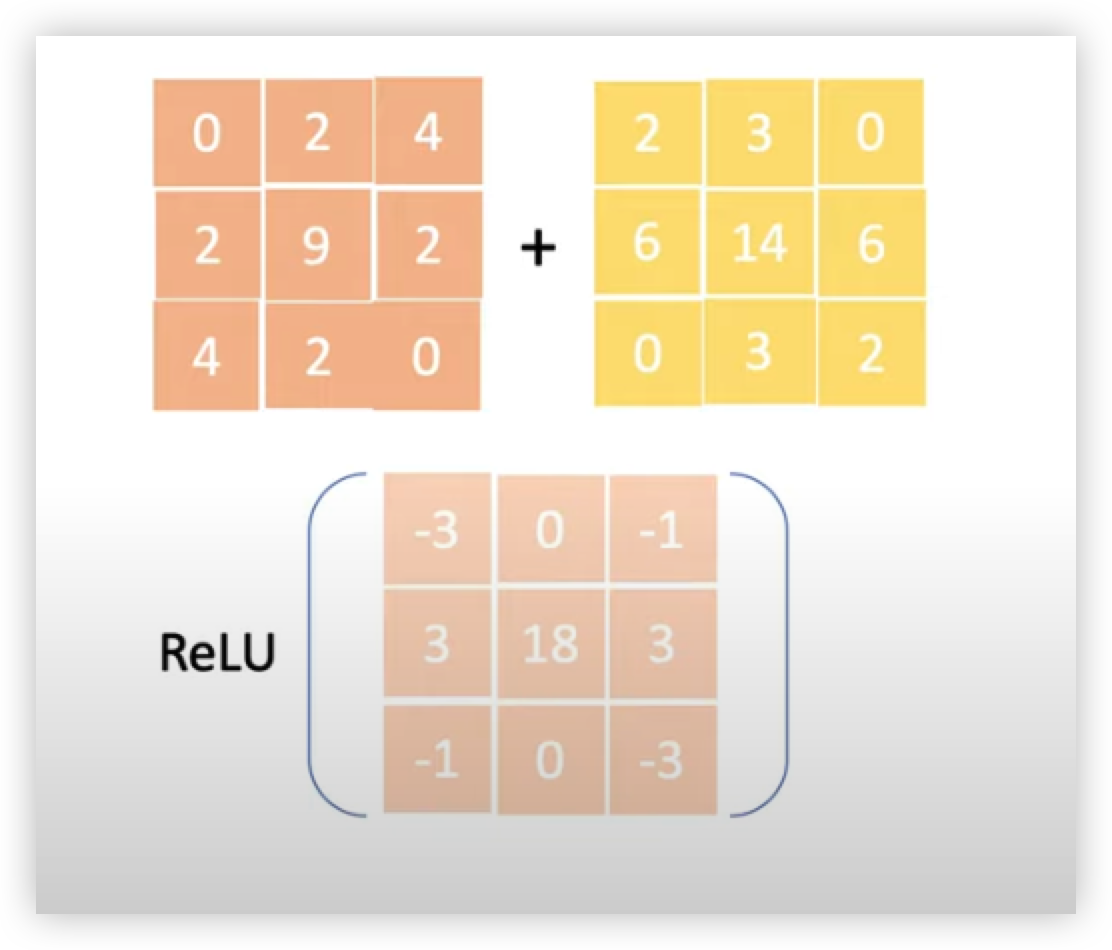
Filter 1 의 Feature Map 을 구해준다.
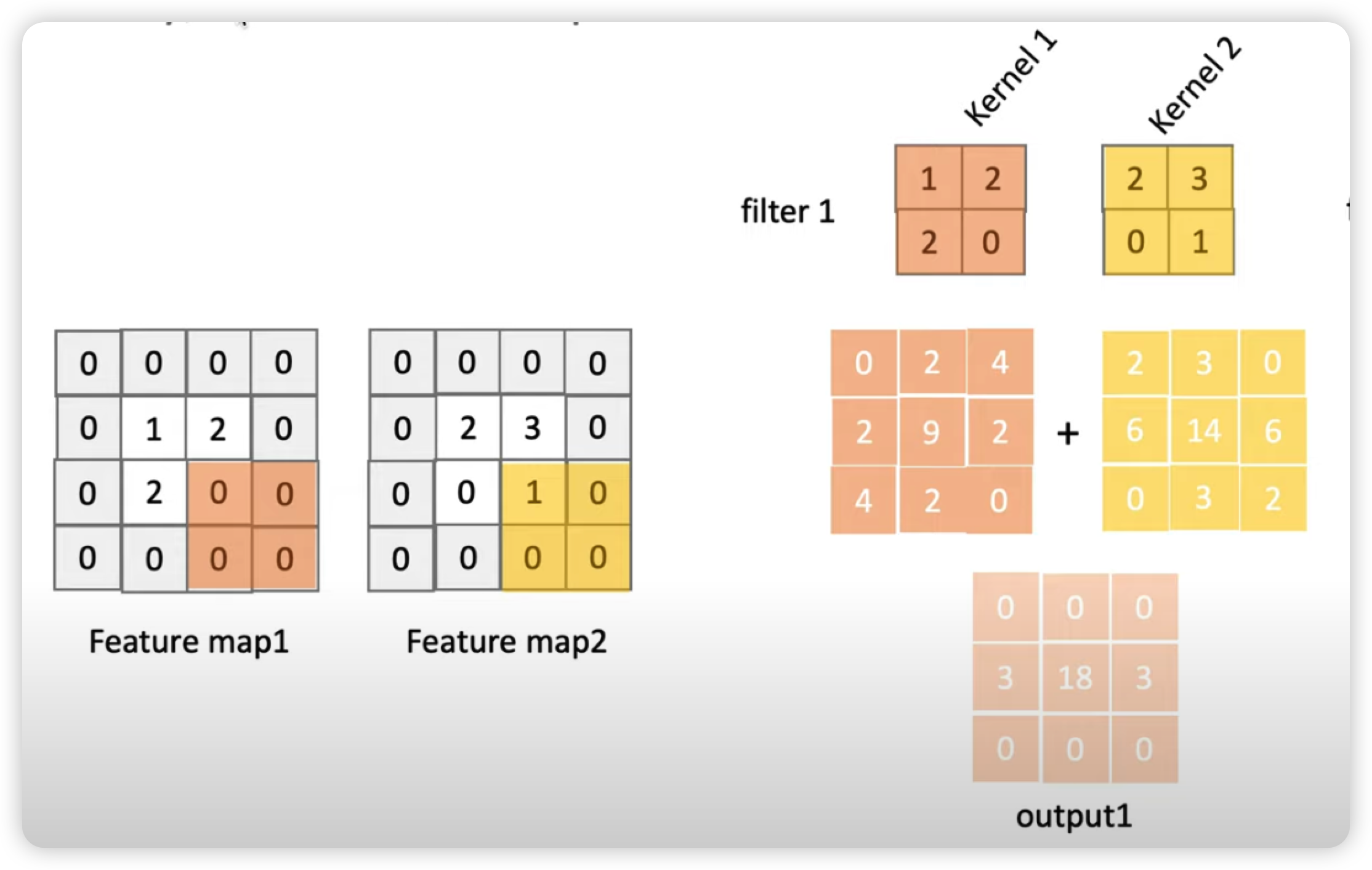
이와 같은 작업을 Filter 2 에도 해줘서 Filter 2 에 대한 Feature Map 도 얻어준다.
POOL (2)
다시 Max Pool을 진행해준다.
출력 => 2x2 Feature Map 2개를 출력 (2,2,2)
Flatten
마지막으로 2x2 Matrix 두개 (2,2,2)인 Feature Map 들을 분류를 하기 위해 FC Layer에 집어넣기 전 Flatten 을 진행해준다.
FC Layer 는 입력을 1차원으로 만들어줘야하기 때문에 2차원 배열인 Feature map 을 1차원으로 만들어줘야한다.
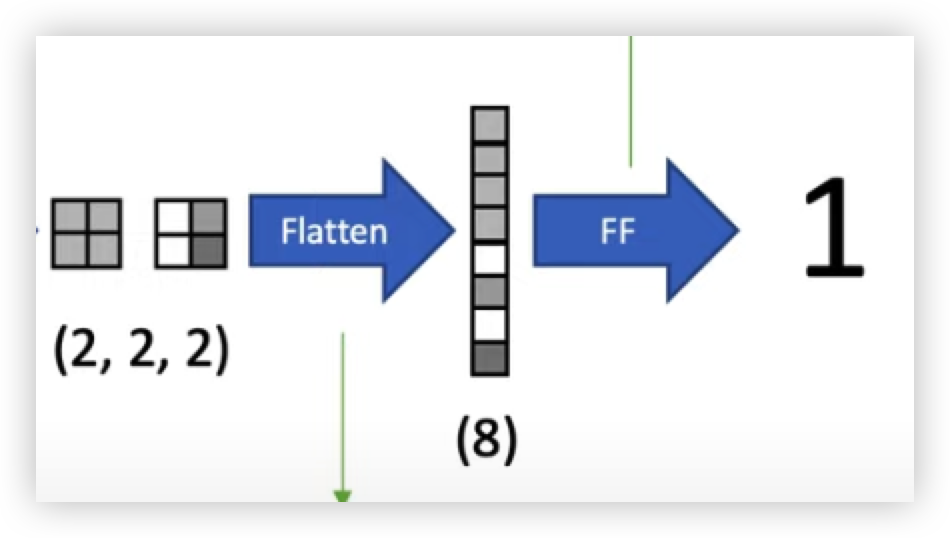
(flatten 예시)

FC Layer (Classification)
8차원을 입력을 받아 FC Layer 연산을 진행해준 다음 10개의 벡터를 출력해준다.
출력 벡터에 softmax 를 취해준 다음 가장 확률 값이 높은 출력 벡터인 y^ 을 뽑아준다.
그 후 Backpropagation을 해주면서 Parameter 를 Update 해주는 식으로 학습을 진행해준다.

참고
