
- 전체보기(174)
- 쿠버네티스(53)
- 스프링 부트(20)
- 트러블슈팅(15)
- 프로메테우스(15)
- pod(13)
- 구름(12)
- API(8)
- 구름부트캠프(6)
- deepdive(6)
- KDT후기(6)
- 부트캠프후기(6)
- 구름서포터즈(6)
- docker(6)
- 코딩테스트(6)
- 구름딥다이브(5)
- html(5)
- 테스트코드(5)
- argocd(4)
- 그라파나(4)
- helm(4)
- volume(4)
- 컨테이너(4)
- JPA(3)
- network(3)
- kubectl(3)
- policy(3)
- eks(2)
- OCR(2)
- ClusterIP(2)
- cd(2)
- HDFS(2)
- Thymeleaf(2)
- PromQL(2)
- 메트릭(2)
- IntelliJ(2)
- 스프링부트(2)
- K6(2)
- hadoop(2)
- kafka(2)
- Cordon(2)
- JuiceFS(2)
- REST API(2)
- ci(2)
- cni(2)
- aws(2)
- PV(1)
- Recording Rule(1)
- virtualbox(1)
- lvm(1)
- http통신(1)
- 풀패킷(1)
- 파티션(1)
- 메트릭 수집 방법(1)
- servicemonitor(1)
- DaemonsSet(1)
- PodMonitor(1)
- 세션하이재킹(1)
- 세그먼트(1)
- livenessprobe(1)
- 비동기(1)
- vpn(1)
- VLAN(1)
- 노드포트(1)
- exporter(1)
- dpi(1)
- 프록시(1)
- 소켓통신(1)
- 스위치미러(1)
- Drain(1)
- Affinity(1)
- HPA(1)
- 디플로이먼트(1)
- 튜닝(1)
- 방화벽(1)
- sidecar(1)
- WAS(1)
- 스위치(1)
- 패킷(1)
- HeadlessIP(1)
- limitrange(1)
- Kube State Metrics(1)
- hikari(1)
- githubactions(1)
- ExternalName(1)
- WebServer(1)
- readinessProbe(1)
- 디지털포렌식(1)
- mysql-exporter(1)
- 빈 디렉토리(1)
- CSS(1)
- Configmap(1)
- secret(1)
- shmget(1)
- NameNode(1)
- 메타데이터(1)
- 포트포워딩(1)
- datanode(1)
- 스토리지(1)
- metrics-server(1)
- anti-affinity(1)
- 스테가노그래피(1)
- networkpolicy(1)
- 업링크포트(1)
- NCPS(1)
- RAID(1)
- kubernetes(1)
- node exporter(1)
- 스니핑(1)
- IPS(1)
- Statefulset(1)
- 스케줄러(1)
- NodePort(1)
- 리눅스(1)
- 컨트롤러(1)
- 컨테이너런타임(1)
- HAR(1)
- Ids(1)
- 영속성 컨텍스트(1)
- 레이블(1)
- Adapter(1)
- blackbox(1)
- session(1)
- terraform(1)
- 스푸핑(1)
- fabric(1)
- Uncordon(1)
- 미러링탭(1)
- ambassador(1)
- ingress(1)
- Harbor(1)
- hostPath(1)
- RBAC(1)
- cadvisor(1)
- 백엔드(1)
- apigateway(1)
- 동기(1)
- 레이블 매처(1)
- ORM(1)
- 로드밸런서(1)
- StartupProbe(1)
- dma(1)
- resourcequota(1)
- ole(1)
- DNS(1)
- NAS(1)
- S3(1)
- elasticsearch(1)
- 쿠키(1)
- PVC(1)
- django(1)
- yarn(1)
- RollingUpdate(1)
- redis-exporter(1)
- volumeClaimTemplates(1)
- kustomize(1)
- 허브(1)
- 부하테스트(1)
보안 엔지니어 신입의 기록 - 허브부터 VLAN까지 네트워크 기초
허브란 여러 PC를 연결해주는 네트워크 장비이다. 그러나 허브는 MAC 주소를 저장하지 않기 때문에 패킷이 들어오면 연결된 모든 포트에 뿌려버린다.허브는 반이중 방식을 사용한다. 반이중이란 한 번에 한 방향으로만 데이터를 전송할 수 있는 방식이다.무전기와 똑같다. 말할
하둡(Hadoop) 완전 정복 - 신입 엔지니어의 질문 모음
하둡(Hadoop)이란 대용량 데이터를 여러 서버에 나눠서 저장하고 처리하는 오픈소스 분산 처리 프레임워크이다.여기서 오픈소스란 단순히 무료라는 의미가 아니라, 소스코드가 공개되어 있어 우리 환경에 맞게 커스터마이징이 가능하다는 의미이다. 실제로 오픈소스이지만 유료인
보안 엔지니어 신입의 기록 - 파티션, 프록시 그리고 DMA
파티션이란 하나의 디스크를 논리적으로 나눈 구역이다. 물리적으로는 디스크 1개인데 여러 개처럼 사용하는 것이다.디스크를 어떻게 나눌지 구역을 설정하는 것이다.이점운영체제랑 데이터 분리 → OS 날아가도 데이터 안전파티션별로 파일 시스템 다르게 설정 가능특정 파티션만 포
보안 엔지니어 신입의 기록 - DPI, 세션, 소켓통신 그리고 shmget
각종 개념 정리 풀패킷 캡처 vs 일반 패킷 수집이란? 패킷을 수집하는 방식에는 두 가지가 있다. 일반 패킷 수집 풀패킷 캡처 저장 내용 헤더만 (IP, 포트, 프로토콜) 헤더 + 내용(payload) 전부 예시 "A가 B한테 보냈다" "A가 B한테 이런 내용을 보냈

보안 엔지니어 신입의 기록 - 네트워크부터 분산 저장까지 (Raid, 미러링, NCPS 등)
ojt때 사내 솔루션에 대한 교육을 듣는데, 중간 중간 들은 내용들에서 모르는 기초 개념들이랑 헷갈리는 개념들이 많아 이 글을 통해 정리하고자 작성하게되었다. RAID(Redundant Array of Independent Disks)란 여러 개의 디스크를 묶어서 하나

DB 하나만 쓰면 안될까? Hadoop, Kafka, Redis, S3 등 한번에 정리
데이터 인프라 핵심 개념 정리 (Hadoop, Kafka, Elasticsearch 등) > 보안 회사에 입사 후 이것저것 개념을 배우게 되었는데, Hadoop, Kafka, DB, Elasticsearch 등 각각의 개념은 알고 있었지만 이것들이 실제로 어떻게 상호

보안솔루션 엔지니어가 알아야 할 네트워크 장비와 보안 개념 정리
보안 솔루션 엔지니어로 새롭게 취업하게 되었다. 그동안 배워왔던 클라우드/인프라 개념과는 결이 조금 다른, 네트워크 장비와 보안 기술들을 이번 기회에 한번 제대로 정리해보았다.
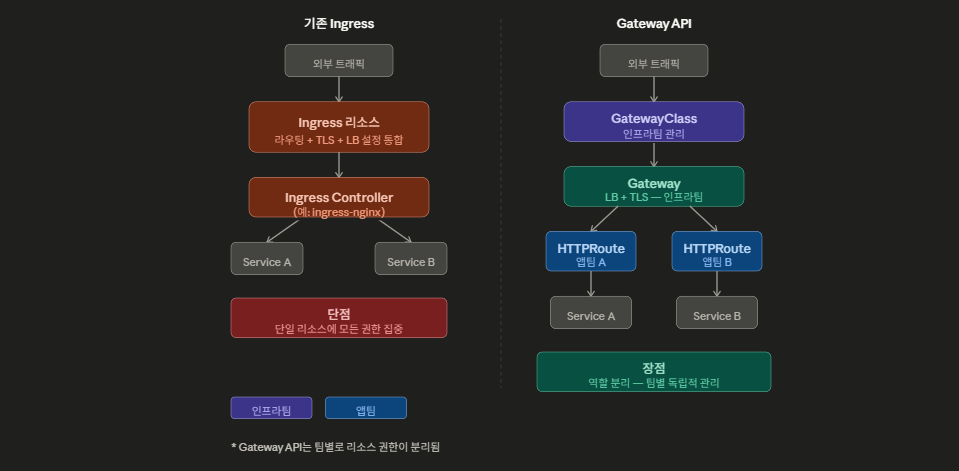
ingress 정책이 종료된다는데, Api Gateway랑 무슨 차이일까?
cloudbro에서 이런 글을 보았다. 쿠버네티스 최신 근황에 대한 것이었다. https://www.cloudbro.ai/t/kubernetes-ingress-nginx-retirement-gateway-api/3149/7
[구름 서포터즈] 구름 부트캠픙와 뽀시래기 프로젝트 회고
2026년 05월 20일. 오늘을 기점으로 6개월간의 구름 부트캠프를 수료하게 되었다.아직 발표만을 남은 시간이지만 뽀시래기 프로젝트에 대한 회고를 써보려 한다.깃허브 주소 : https://github.com/Goorm4I/pposiraegi-ecommerc
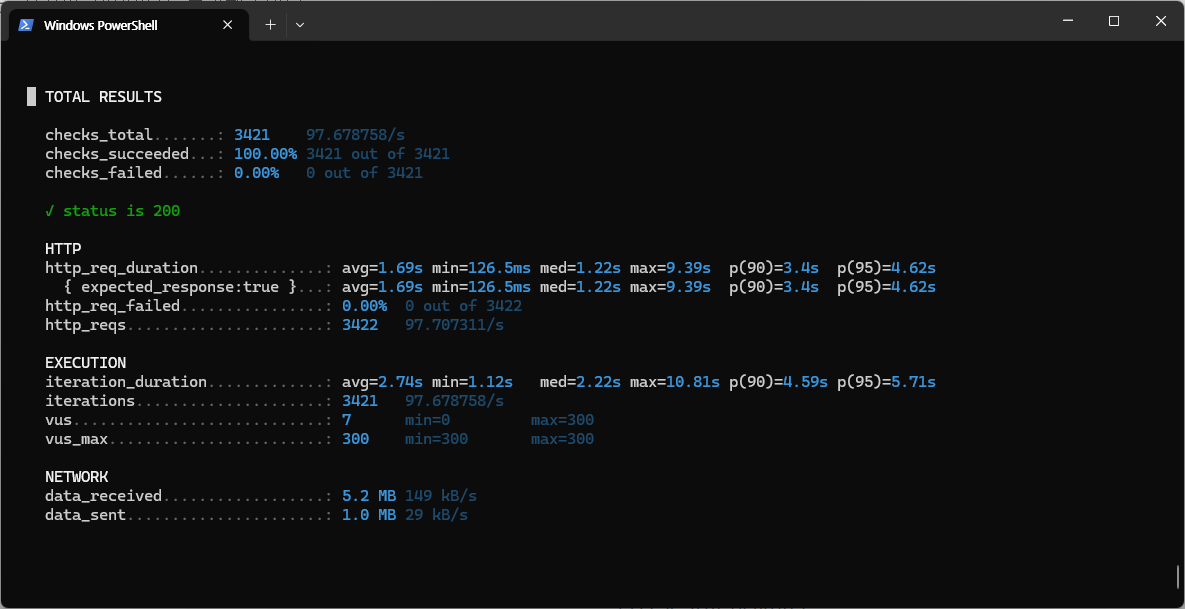
Hikari Connection Pool 튜닝으로 p95 응답시간 60% 개선하기
전 포스팅에서 k6로 300 VUs 부하테스트를 돌렸더니 평균 응답시간이 4초가 넘게 나왔다. 원인을 찾아보니 application-prod.yaml에 Hikari 설정 자체가 없어서 기본값인 10으로 돌아가고 있었다. 문제 300명이 동시에 주문하면 DB 연결이
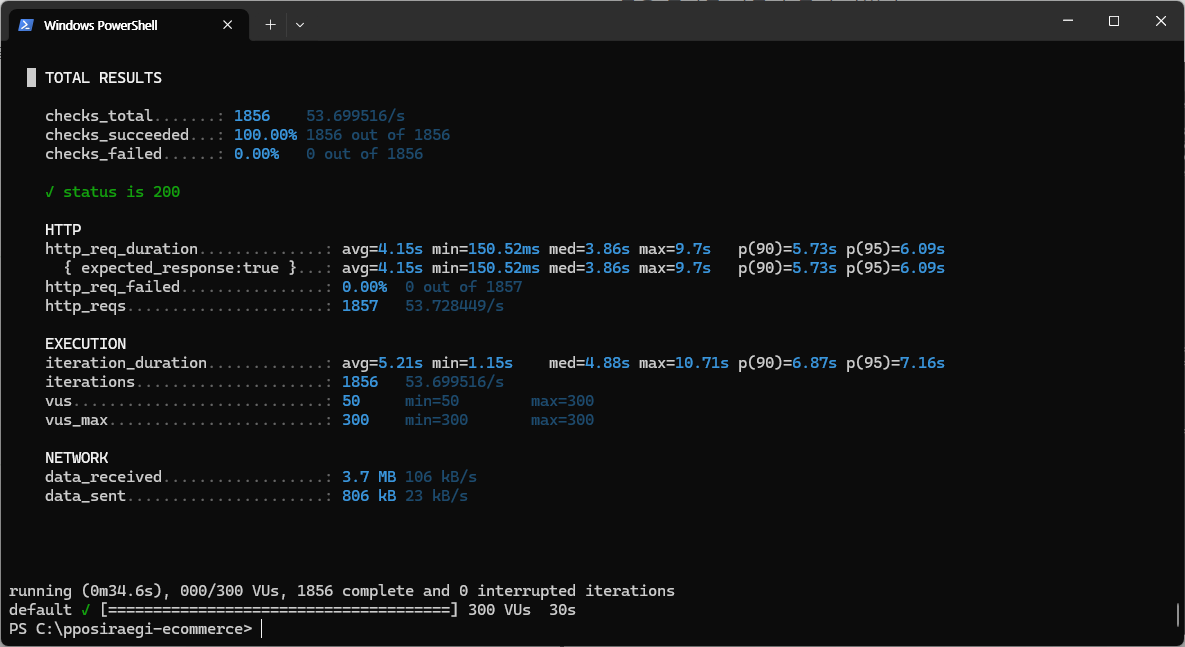
k6로 재고 부하테스트하기
현재 부트캠프에서 뽀시래기라는 프로젝트를 진행하고 있다.도메인은 https://pposiraegi.cloud/login 인데, 타임딜 서비스이기 때문에 순간적인 트래픽이 폭증하는 상황도 연출하고 그걸 버티는 상황인지 테스트를 해야하기 때문에 k6를 통해 테스트
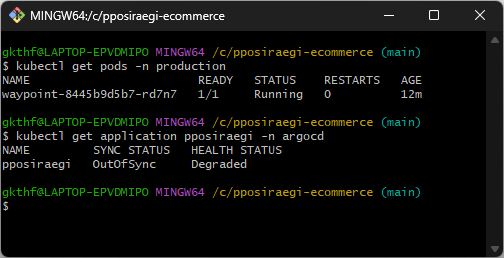
[CI/CD 삽질기3] ArgoCD CD 고치기
GitHub Actions도 고치고, 부트스트랩도 정상 실행됐는데 이번엔 ArgoCD가 CD(배포) 과정에서 문제가 생겼다. ArgoCD는 Git 저장소를 바라보며 Kubernetes 클러스터에 자동으로 배포해주는 도구인데, 이 단계에서 또 막혔다.위처럼 OutOfSy
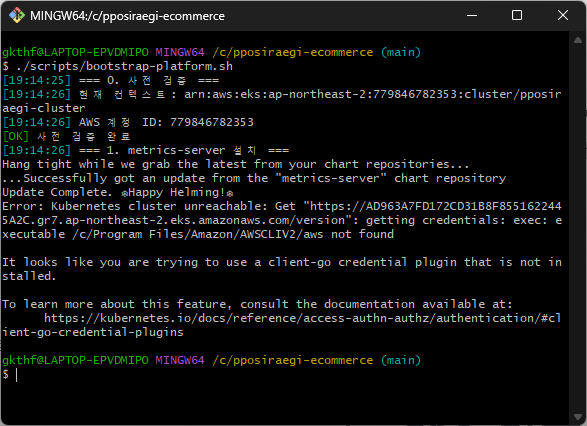
Windows에서 EKS 붙이기 — Git Bash, helm, kubeconfig 삽질 총정리 (경로/인증/권한)
Terraform apply와 GitHub Actions CI/CD까지 성공한 후, 이제 EKS 클러스터에 플랫폼 컴포넌트를 설치할 차례였다. 팀원이 만들어준 bootstrap-platform.sh 스크립트를 실행하면 ArgoCD, Karpenter, Istio 등을
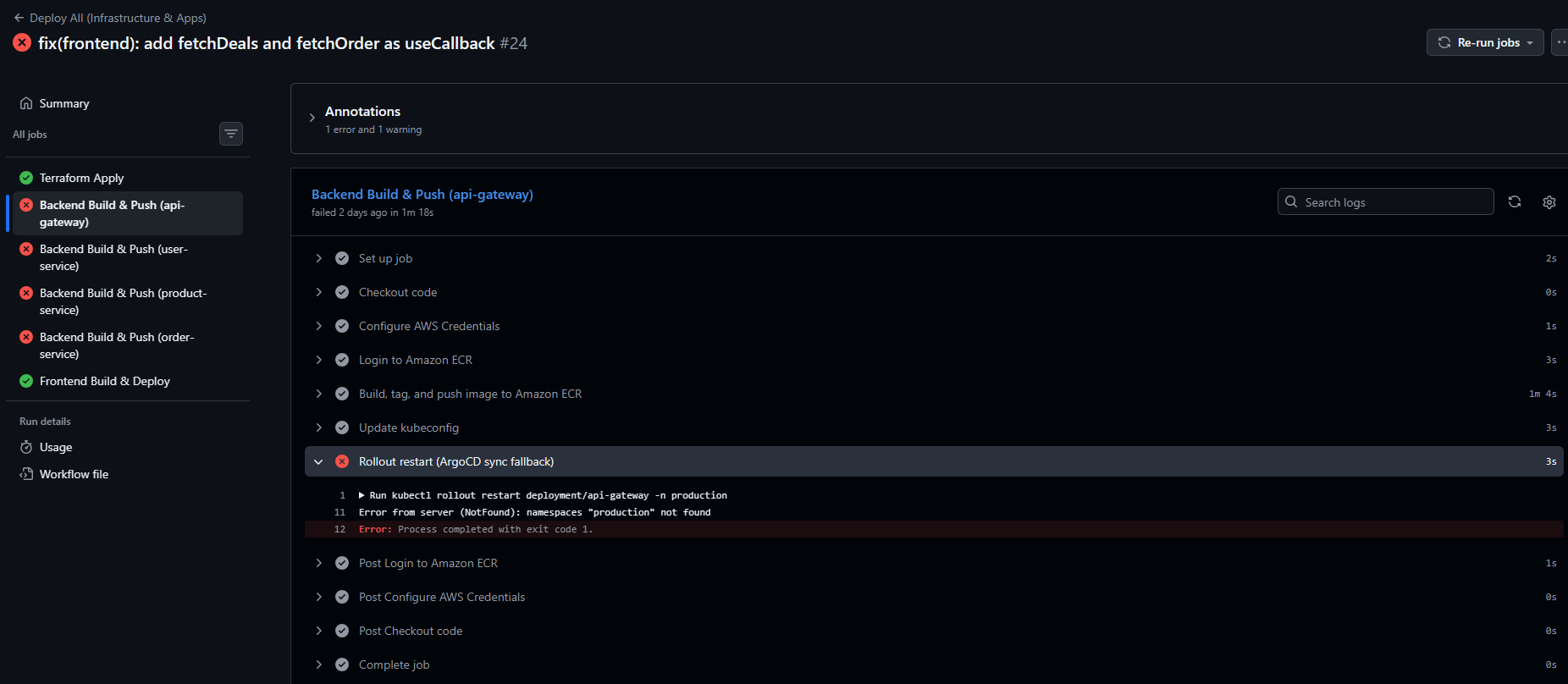
[CI/CD 삽질기2] GitHub Actions - backend쪽 고치기
저번 포스팅에서 프론트엔드 CI 쪽은 수정했지만, 백엔드 4개 서비스는 해결하지 못했다. 이번 포스팅에서는 백엔드 쪽 오류를 수정한 과정을 정리해보려 한다.이 에러는 production 네임스페이스가 존재하지 않아 발생하는 오류다.원인을 파악해보니, terraform
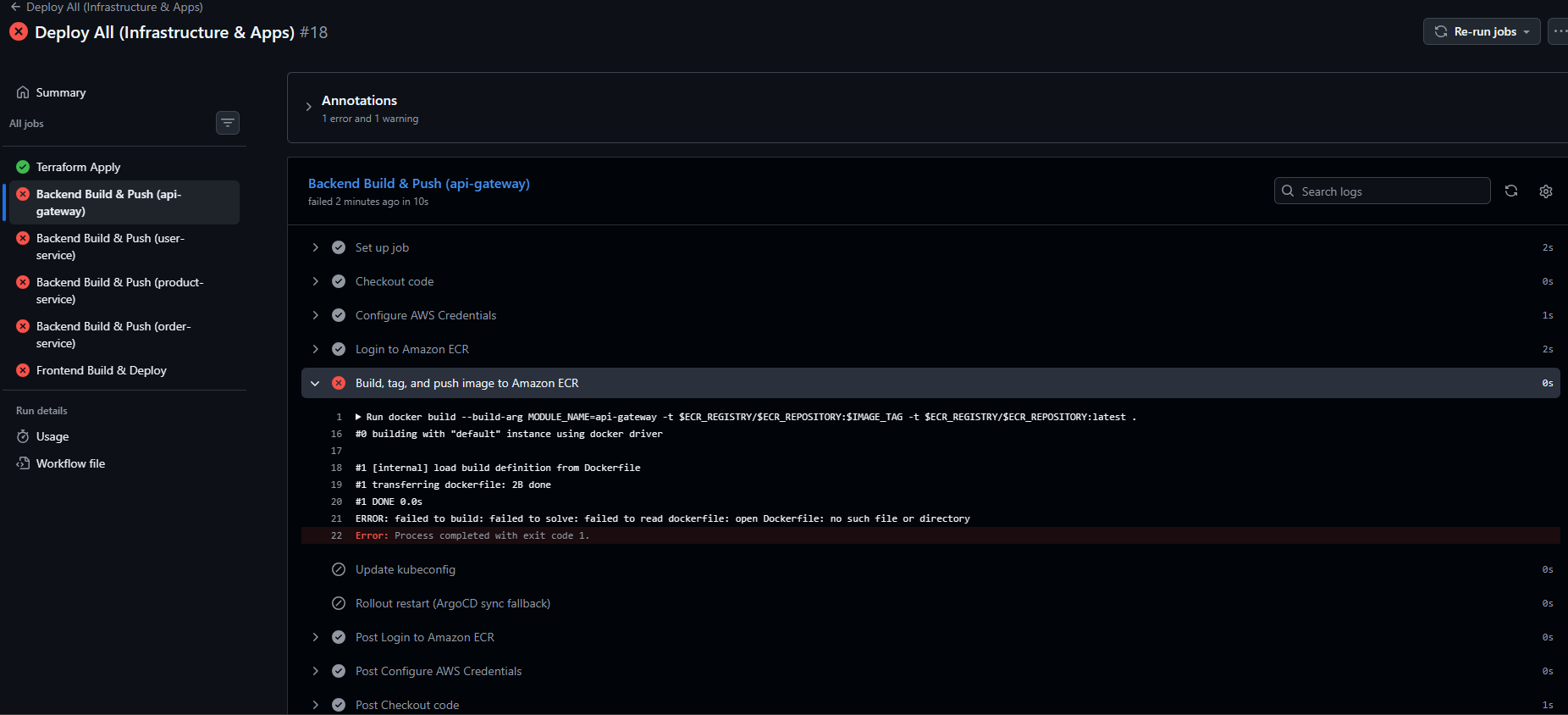
[CI/CD 삽질기1] GitHub Actions로 EKS 자동 배포 구축하며 만난 오류들
처음에 깃허브 argocd가 안되어서 왜 그런가 봤더니조직 레벨에서 외부 액션 사용이 막혀있어서 pnpm/action-setup@v3 같은 액션을 못 쓰는 문제가 생겼다.이거를 프로젝트 레포에서 보니 변경이 막혀있어서조직 Settings에서 "Allow all acti
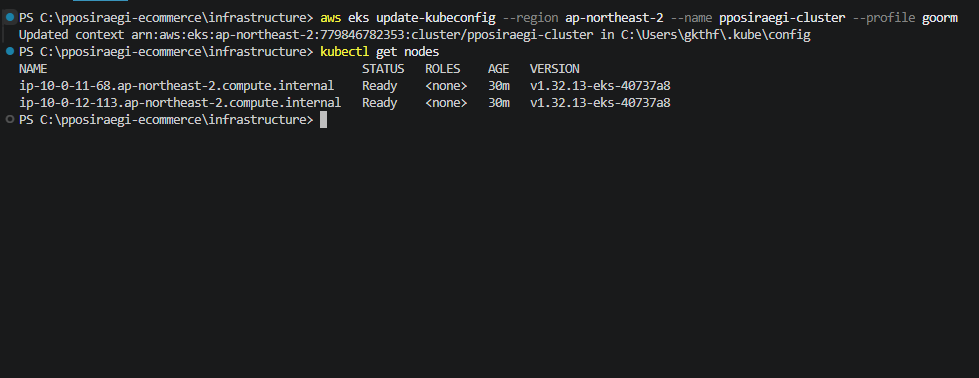
ArgoCD sync는 됐는데 Pod가 안 떠요 — 원인 추적기
argocd 연결까지 완벽하게 끝냈는데 production pod를 연결하는 과정에서 crashloopback 오류가 떴다. 이를 해결하기 위해 시스템로그(/var/log/messages에 있는 로그)를 보고 그럼에도 안되면 dmesg 커널 메세지를 따보기로 하려 한
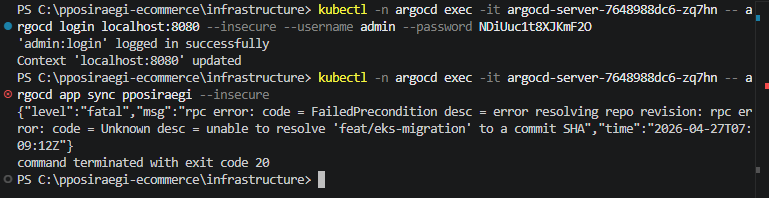
ArgoCD Sync 트러블슈팅 — 레포 오타부터 RDS 보안 그룹까지
이번 포스팅은 ArgoCD Sync를 시도하다가 연속으로 두 가지 문제를 맞닥뜨린 트러블슈팅 기록이다.결론부터 말하면 레포 이름 오타 → 폴더 경로 오류 → RDS 보안 그룹 차단 순서로 문제가 터졌고, 아직 완전히 해결 전 단계다.Sync 전에 RDS, ElastiC
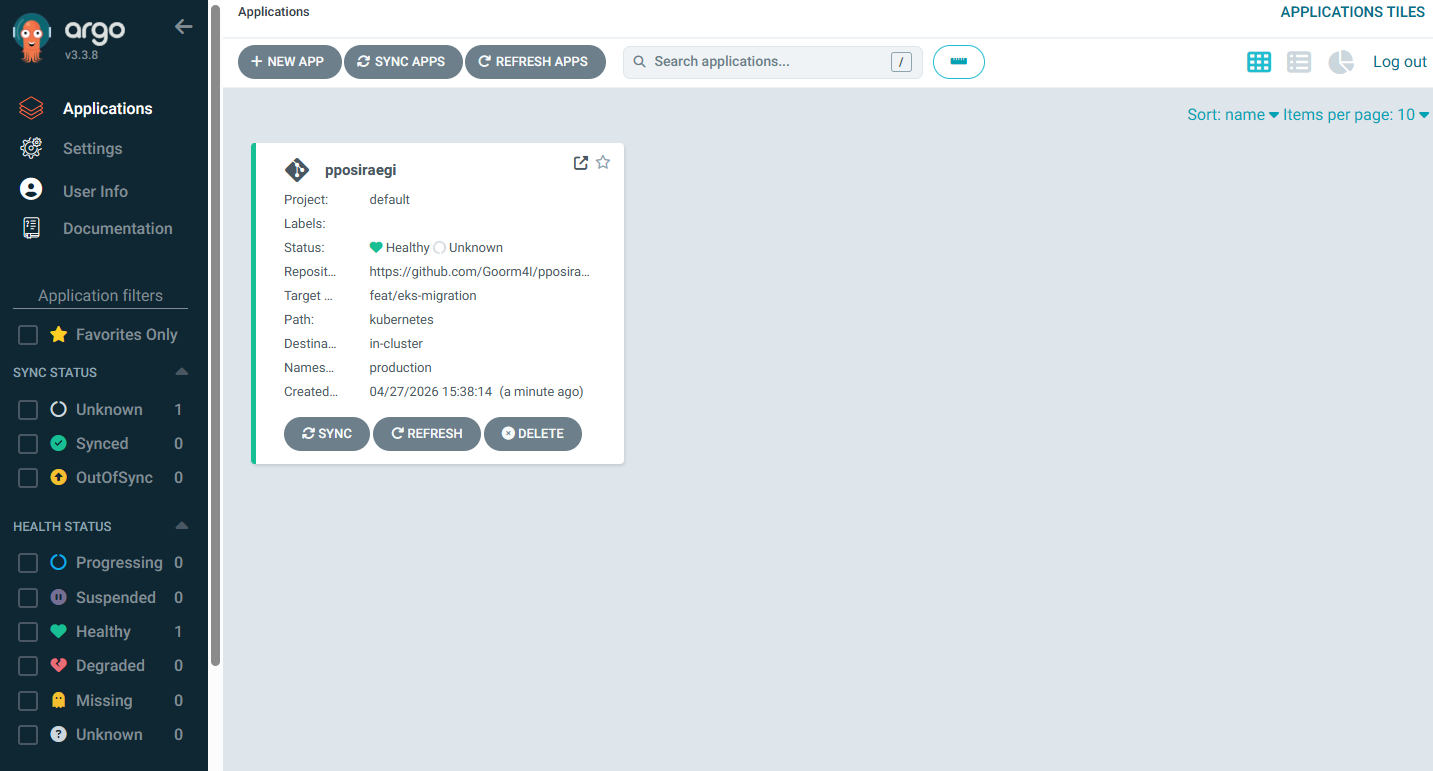
AWS EKS + ArgoCD로 자동 배포 파이프라인 만들기
이번 포스팅에서는 AWS EKS 클러스터에 ArgoCD를 설치하고, GitHub 레포지토리와 연동해서 자동 배포까지 설정하는 과정을 정리했다.

Terraform state가 어디갔지? S3 backend 설정 삽질 해결기
팀원이 tfstate s3 버킷을 지정하면서 오류가 생겨서 이거때문에 terraform apply가 안되는 오류가 발생했다.팀원이 보내준 사유는 다음과 같다현재 pposiraegi-ecommerce repo에서 Terraform/EKS 접근 문제가 있습니다.중요:파일

[구름 서포터즈] bastion 서버, 진짜 필요한가? SSM으로 갈아탄 이유
본 콘텐츠는 구름 서포터즈 활동으로 지원을 받아 작성된 교육생의 실제 경험 후기입니다.이전 게시물에서 프로젝트를 시작했을 때 포스팅을 남겨놓았다.그때는 기획 수준이었는데, 지금은 그때와는 다른 고민들을 하기 시작했다.CI/CD 파이프라인 구성이라든지, 자동 배포 전략은