CNN 등장 배경
FC Layer(Fully, Connected Layer, Fully Connected Neural Network)의 경우 피쳐맵에 대해서 모든 텐서에 대해 내적을 하게 된다. 모든 텐서에 대해서 파라미터가 사용되기 때문에 1) 파라미터 개수가 증가하는 한계점이 있다. 그리고 가중치 맵을 시각화할 수 있는데 이와 비슷하지 않은 (완전 다름 이미지 or 비슷하지만 cropped된 이미지) testset 이미지에 대해서 분류를 못하는 문제점 이 있다.
- FC Layer 한계점
- 파라미터 개수 많다.
- 훈련 데이터에서 보지 못한 이미지를 잘 처리하지 못한다.
Locally Connected Neural Network는 피쳐 맵의 모든 영역이 아닌 일부 국소 영역 즉 local 영역에서만 내적을 계산해 특징을 추출하는데, 이는 파라미터 개수가 그만큼 적어지는 장점이 있다. CNN은 Fully Connected Neural Network 기반으로 local 한 영역만 추출한다. 다른 점은 local 영역을 하나의 커널(가중치)를 통해 모든 피쳐맵의 영역에서 동일한 파라미터를 사용하게 된다. 요약하자면 CNN은 Local feature learning 기반으로 local한 영역의 특징을 추출하는데, 동일한 파라미터(커널, 가중치)를 통해 이미지 전체 영역에 대해서 내적 값을 계산하는 네트워크이다.
CNN에서 Receptive Field
Receptive Field란 input 단에서 부터 추출된 피쳐맵의 하나의 픽셀이 영향받은 영역을 의미한다. 하나의 Conv 레이어를 통과한 피쳐맵의 텐서 값 하나는 이전 피쳐맵의 커널 사이즈 크기 영역을 바탕으로 계산된 값인데 이때 커널 사이즈가 Receptive Field이다. 일반적으로 input 단까지 거슬러 올라가 계산한다.
- KxK conv filters with stride 1, a pooling layer of size PxP → (P+K-1)x(O+K-1)
CNN 기반 Architecture 배경
- AlexNet
- VGG
AlexNet과 VGG 모델이 등장한 이후로도 Image Classification task에서는 파라미터 개수를 줄임과 동시에 네트워크 깊이를 계속해서 깊게 쌓는 것에 집중을 했다. 네트워크를 단순히 깊게 구성할 때 발생하는 문제점은 다음과 같다.
- 네트워크 층 깊을 경우 발생하는 문제점
- Gradient Vanishing / Exploding
- Computationally complex
- Degradation problem → overfitting 문제보다는 최적화 문제로 볼 수 있다. ex) gradient vanishing/exploding
위와 같은 문제점을 보완하면서 성능을 높이는 모델에는 GoogleNet, ResNet, DenseNet 등이 존재한다.
AlexNet
기존 모델에 존재하던 모델보다 층을 더 깊게 쌓고, 규모가 큰 ImageNet 데이터셋에 대해서 높은 성능을 보였다.
- 기존 모델(Ovrall architecture) : Conv - Pool - Conv - Pool - FC - FC
- Convolution : 5x5 filters with stride 1
- Pooling : 2x2 max pooling with stride 2
- AlexNet : Conv-Pool-LRN-Conv-Pool-LRN-Conv-Conv-Conv-Pool-FC-FC-FC
- 7 hidden layers, 60M Params
- Tranining ImageNet
- ReLU, Dropout
- LRN(Local Respose Normalization) → Batch normalization
- LRN의 경우 현재 자주 사용되지 않는다.
AlexNet 모델과 같이 Conv를 통해 3차원의 Tensor 정보가 FC layer로 입력될 때는 벡터 형태로 변환해야 한다. 이는 nn.AdaptiveAvgPool2d, torch.flatten 함수를 이용한다.
VGG
AlexNet과 같은 기존의 모델보다 층이 16, 19와 같이 더 깊고 simple한 모델이다. 3x3 conv와 같이 커널 사이즈가 작은 커널을 여러번 사용한 특징이 있다. 크기가 큰 커널 하나를 사용하는 것보다 크기가 작은 커널을 여러번 사용하는 것이 더 좋다는 연구 결과가 나온 논문이다. 5x5 filter 대신 3x3 두 번 사용하게 되면 Receptive Field는 동일하면서, 파라미터 개수는 줄어든다. 추가로 nonlinear 함수를 더 빈번하게 거치게 된다.
GoogleNet
- depth가 아닌 width에 주목한다.
- 1x1, 3x3, 5x5 convolution의 3가지 filter를 통해 피쳐맵을 형성한다. → filter concatenation
- 1x1 convolution을 활용하여 dimension reduction(channel)을 진행한다.
- Auxiliary classifier를 통해 gradient vanish 문제를 보완한다.
- training 과정에서만 사용되며, gradient가 소실되는 것을 대비하여 중간 과정에 추가된 분류기이다.
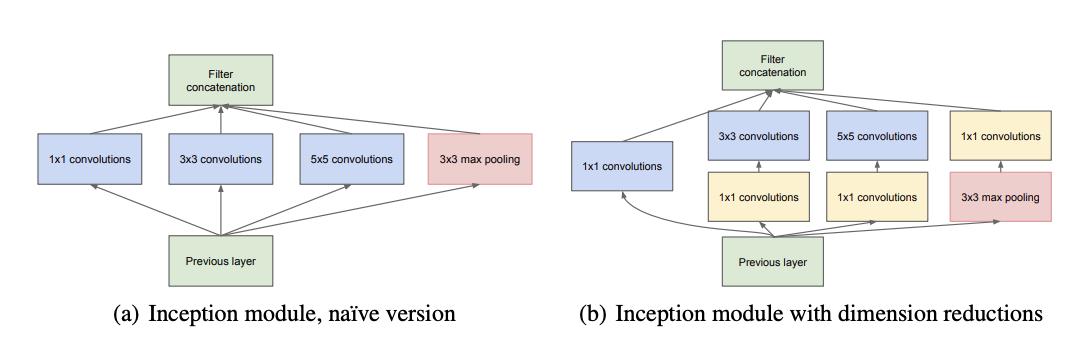
Ref : [Szegedy et al., CVPR 2015]
ResNet
Degradation problem
- 네트워크를 깊게 구성할 때 overfitting 문제가 아닌 degrade 문제가 발생하는 것을 확인한다.
- Degradation problem → 네트워크 깊게 쌓았을 때 정확도 또는 error가 기존의 더 적은 레이어를 탑재한 네트워크보다 낮은 성능에 머무르는 현상을 설명하는 듯하다.
- 56-layer의 training erorr가 20-layer보다 높기 때문에 overfitting 문제라고 볼 수는 없다.
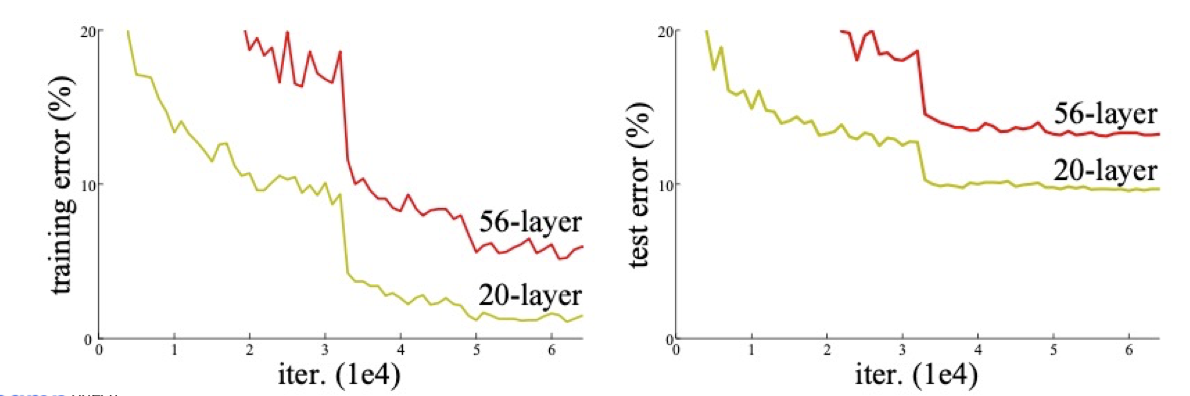
Ref : [He et al., CVPR 2016]
skip connection 사용
- 이전의 값을 다음 레이어의 출력에 더해준다.
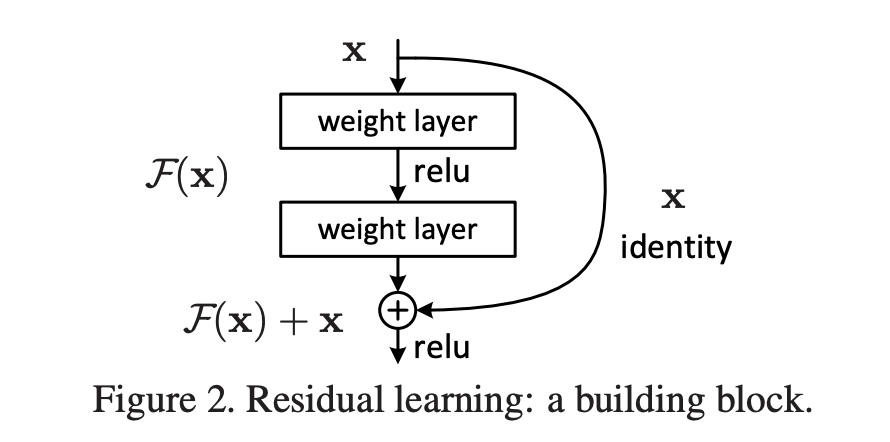
- 일반적인 출력값과 이전 출력값의 차이인 만 학습하도록 구성한다.
- Target Function :
- Residual Function :
skip connection을 사용하지 않은 기존의 방식은 레이어를 통과한 결과값인 이며, 이때 Target Function은 와 같이 정의된다. 이때 Target Function 를 이전 입력값인 와 출력값 의 합으로 구성하게 되면, 의 경우 기존에 알고 있는 값이기 때문에 만을 학습하게 된다. 즉 학습하려는 대상 부류에 기존의 값 를 보존하려는 부분은 없어도 되는 것이다. 결과적으로 입력과 출력간의 차이만 학습하기 때문에 더 효율적이라고 볼 수 있다.
- Gradient가 Backpropagation 과정에서 흘러가는 path가 으로 다양해진다고 볼 수 있다.
- 더 다양한 경우로 Gradient가 흘러갈 수 있기 때문에 학습할 수 있는 범위가 넓어진다고 볼 수 있다.
DenseNet
- 모든 이전 레이어의 channel을 이후 레이어에 concatenate 하는 구조로 구성된다.
- width가 넓어지는 것을 다시 줄이기위한 구조가 구성되어 있다.
SETNet
- Attention 방법이 channel을 구할 때 적용된다.
EfficientNet
width, scaling, depth scaling, resolution scaling 방식을 모두 적용한 compund scaling 방법을 이용하였다.
- Image classficiation 모델 발달 구조
- width scaling → googlenet, densentet
- depth scaling → resnet
- resolution scaling
Deformable convolution
- 특정 이미지 영역 부분을 receptive field로 설정한 구조이다.
