
- 전체보기(108)
- aws(25)
- python(18)
- spark(16)
- kubernetes(16)
- 네이버 클라우드 플랫폼(15)
- Naver Cloud Platform(15)
- 쿠버네티스(12)
- GCP(9)
- docker(8)
- lambda(8)
- EMR(7)
- NKS(6)
- airflow(5)
- Google Cloud Platform(5)
- emr on eks(5)
- eks(5)
- ec2(4)
- 자격증(3)
- Lambda url(3)
- linux(3)
- Database(3)
- Delta Lake(3)
- 데이터분석(2)
- medium(2)
- Databricks(2)
- GLUE(2)
- dataForm(2)
- vpc(2)
- ubuntu(2)
- Pubsub(2)
- BigQuery(2)
- shell script(2)
- Trino(2)
- helm(2)
- AWS CDK(2)
- dotenv(1)
- Naver Cloud Platofrm(1)
- ncp(1)
- UV(1)
- Spark Streaming(1)
- hive(1)
- devops(1)
- step functions(1)
- error(1)
- ssh(1)
- PostgresSQL(1)
- pandas(1)
- gcs(1)
- polars(1)
- pyspark(1)
- DuckLake(1)
- Optuna(1)
- Cloud SQL(1)
- SQLAlchemy(1)
- mysql(1)
- CloudTrail(1)
- microk8s(1)
- 2023(1)
- 데이터시각화(1)
- data(1)
- kafka(1)
- DuckDB(1)
- github(1)
- DCA(1)
- furiko(1)
- lake formation(1)
- dockerfile(1)
- 회고(1)
- Grafana Loki(1)
- 도커(1)
- Severless(1)
- sql(1)
- ORM(1)
- scala(1)
- assume role(1)
- DNS(1)
- NAS(1)
- GitLab(1)
- IAM(1)
- dataset(1)
- serverless(1)
- SQS(1)
- MLflow(1)
- dataclass(1)
- route53(1)
- quicksight(1)
- computeengine(1)
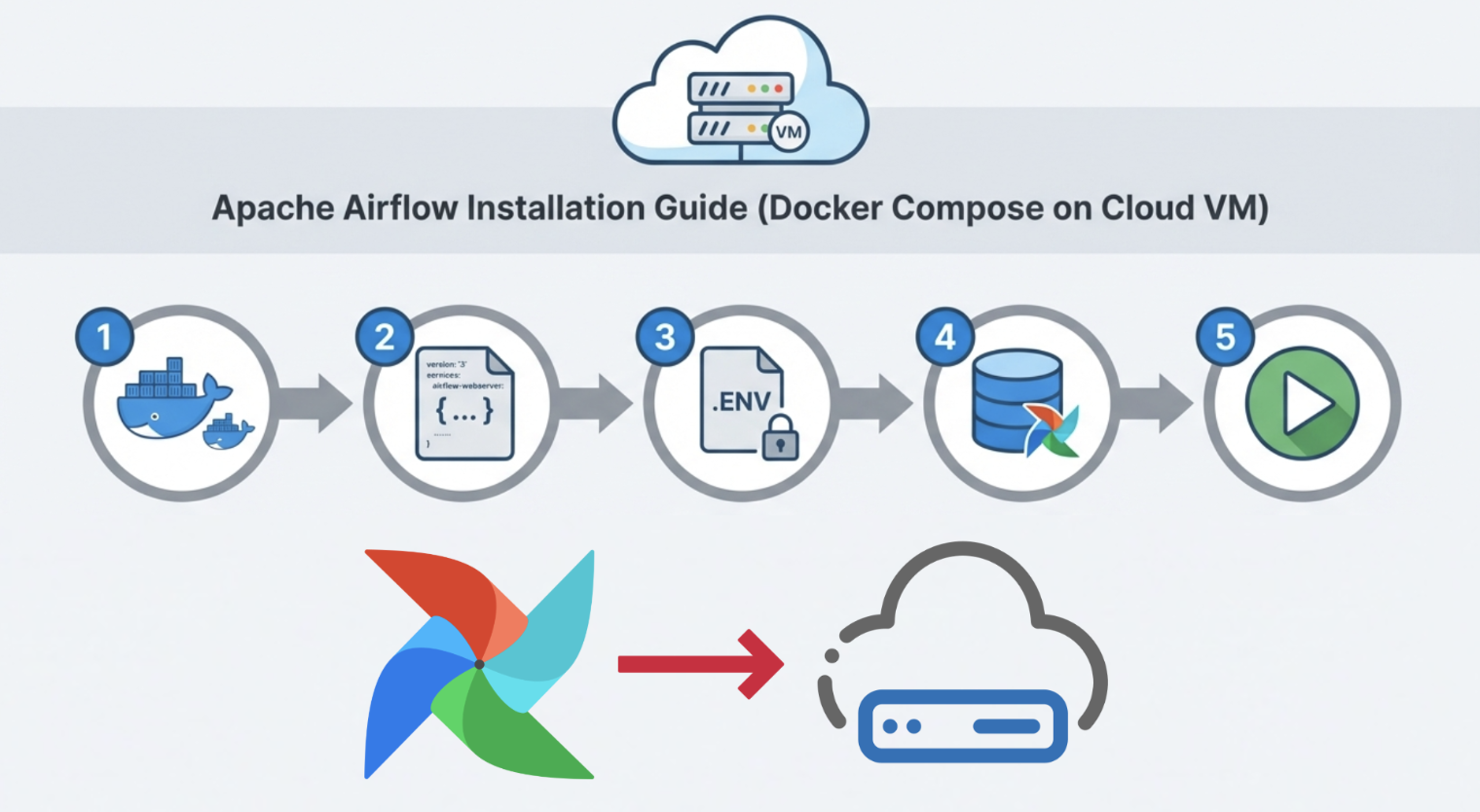
Cloud VM에 Apache Airflow 설치하기
👉 공식 문서Airflow는 여러 컨테이너(Webserver, Scheduler, DB, Redis 등)가 함께 동작하기 때문에, VM 리소스가 너무 작으면 설치는 되더라도 실행이 불안정할 수 있습니다.VM에 Docker 및 Docker Compose 플러그인을 설치
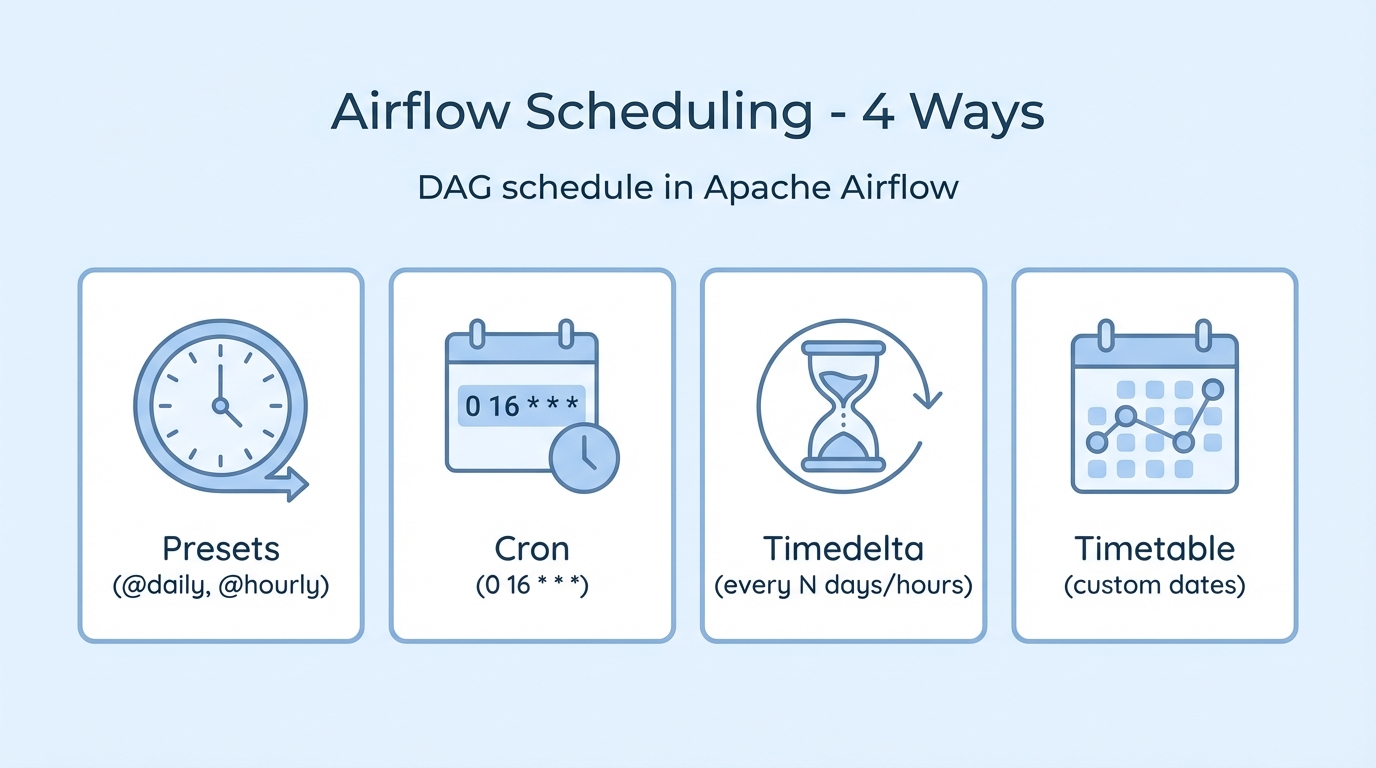
Airflow의 다양한 스케줄링 방식 총정리!
데이터 파이프라인을 운영하다 보면 "매일 새벽에 ETL을 돌리고 싶다", "평일 오후에만 리포트를 생성하고 싶다", "3일마다 한 번씩 배치를 돌리고 싶다" 같은 요구가 생깁니다. Apache Airflow에서는 DAG의 schedule 파라미터로 이런 실행 주기를 정

Databricks 플랫폼 아키텍처 상세 가이드
Databricks를 처음 사용하는 개발자나 관리자에게 가장 혼란스러운 부분 중 하나는 "데이터가 어디에 저장되는가?", "컴퓨팅 리소스는 어디서 실행되는가?", "보안은 어떻게 구성되는가?"와 같은 아키텍처 관련 질문입니다. Databricks는 전통적인 단일 계정
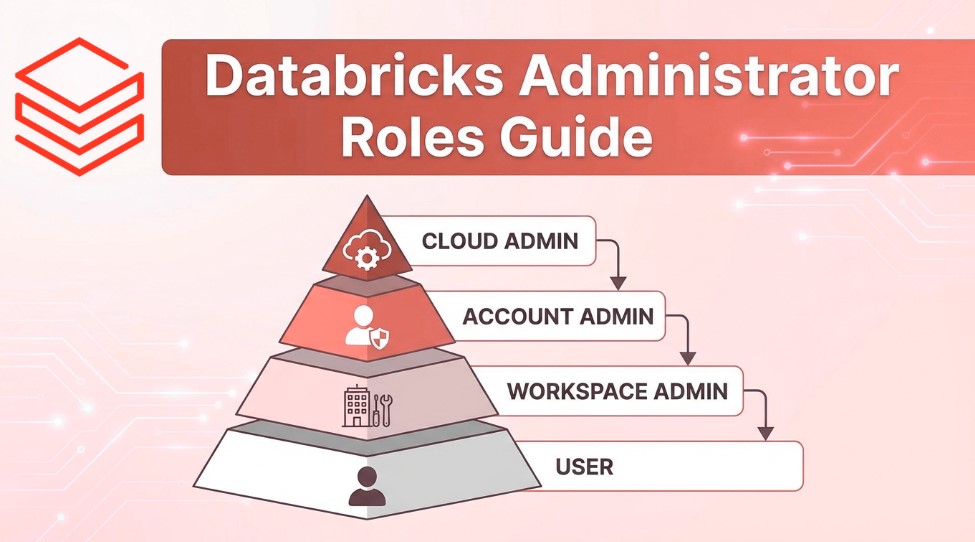
Databricks 사용자 역할 완전 가이드: 누가 무엇을 관리하는가?
Databricks를 처음 도입하거나 운영하는 조직에서 가장 자주 마주치는 질문 중 하나는 "누가 어떤 권한을 가져야 하는가?"입니다. Databricks는 엔터프라이즈급 데이터 플랫폼으로, 다양한 관리자 역할을 제공하여 조직의 보안과 운영 효율성을 보장합니다.각 역할
Airflow XCom으로 데이터를 주고받는 5가지 방법
0. INTRO 모든 워크플로우 자동화 도구가 그렇듯, Apache Airflow에서도 테스크(Task) 간에 데이터를 주고받아야 하는 상황이 빈번하게 발생합니다. Airflow에서는 이를 위해 XCom(Cross-Communication)이라는 메커니즘을 제공합니다. XCom이란? XCom은 Airflow의 메타데이터베이스에 저장되는 작은 데이터 조각...

🧱 Databricks Unity Catalog(UC) 완벽 정리 가이드
0. INTRO 데이터 플랫폼이 커질수록 가장 먼저 복잡해지는 것은 데이터 자체가 아니라 데이터의 관리 방식입니다. 여러 팀이 같은 데이터 레이크를 공유하고, 수많은 테이블·파일·모델이 쌓이기 시작하면 “이 데이터는 누가 만들었는가?”, “누가 접근할 수 있는가?”, “어디에 저장되어 있는가?” 같은 질문에 명확히 답하기 어려워지죠.😅 Databric...
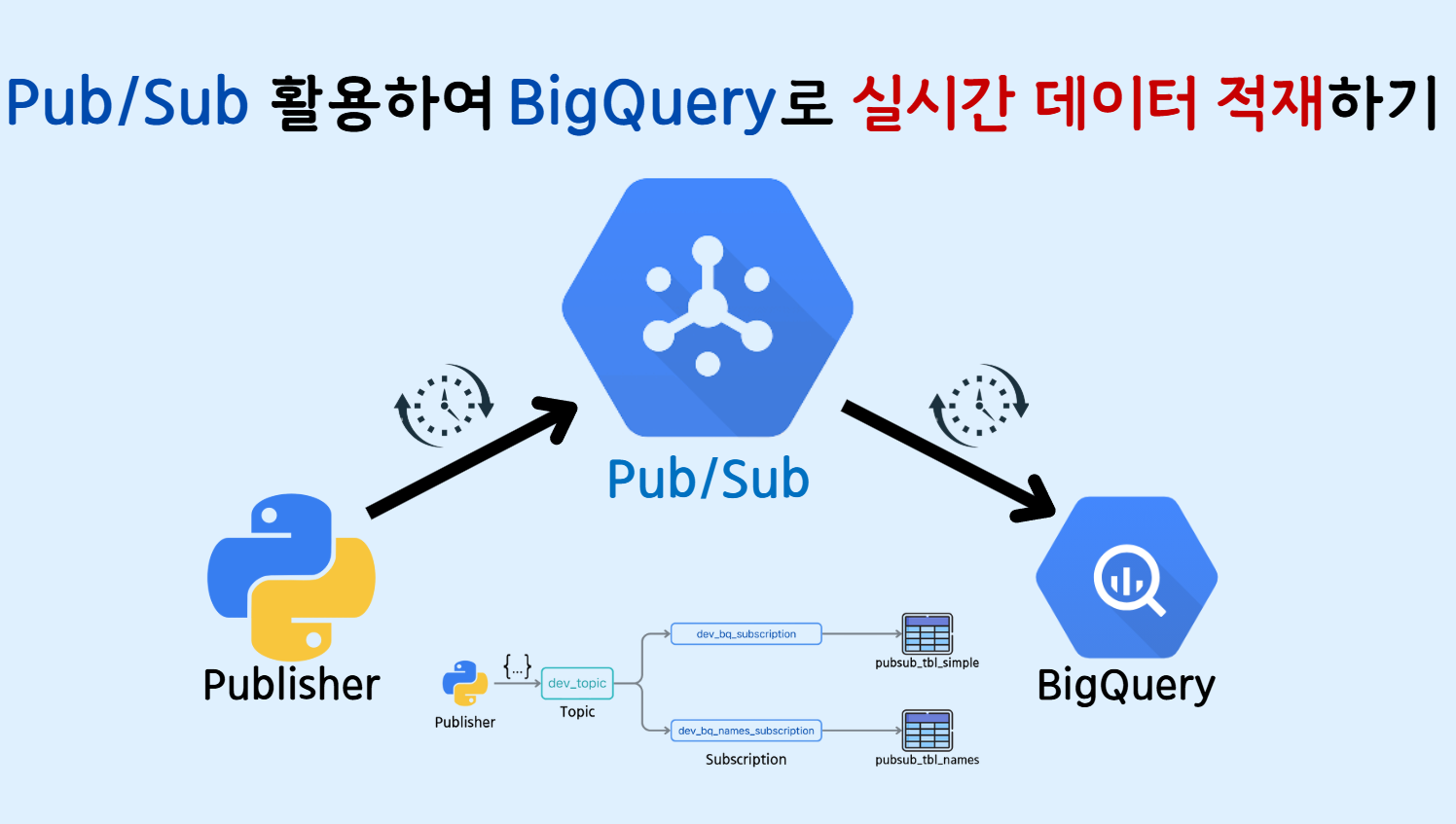
[GCP] Pub/Sub을 활용하여 BigQuery 테이블에 실시간으로 데이터 적재하기.
🔹 0. INTRO 이전 글 'Google Cloud Pub/Sub 서비스의 핵심 개념과 실습 튜토리얼'에서는 Pub/Sub 서비스의 기초적인 내용을 살펴보았습니다. 이번 글에서는 Pub/Sub 토픽으로 전송된 메시지를 읽어 BigQuery 테이블에 직접 저장하는 방법을 다뤄보겠습니다. 🔹 1. BigQuery 테이블 생성 ▪ 1) 단일 스키마 토픽...
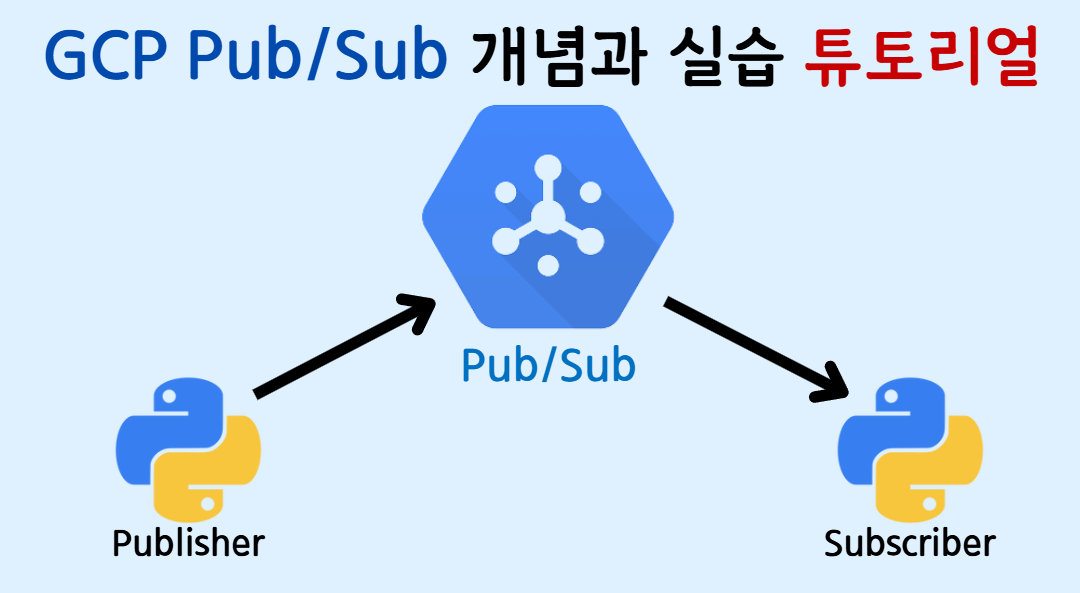
[GCP] Google Cloud Pub/Sub 서비스의 핵심 개념과 실습 튜토리얼 (UI / Python)
GCP PubSub 서비스에 대한 개념 및 python을 통한 실습 튜토리얼!
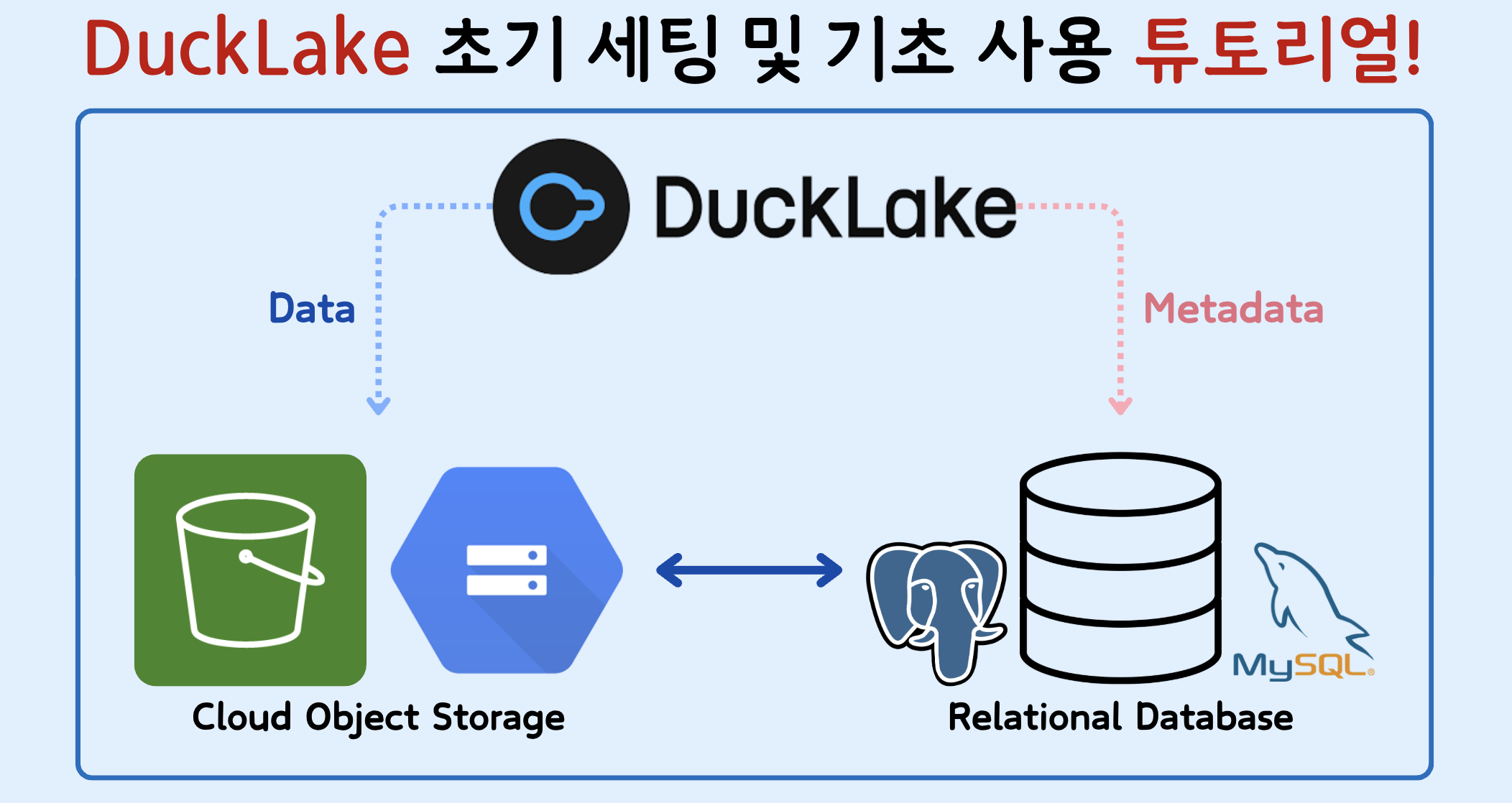
DuckLake 초기 세팅 및 기초 사용 튜토리얼! (PostgreSQL/MySQL + 클라우드 객체 저장소)
DuckLake에 대한 간략한 설명 및 Python을 통해 DuckLake 환경 세팅하는 방법을 차근차근 알려드립니다!

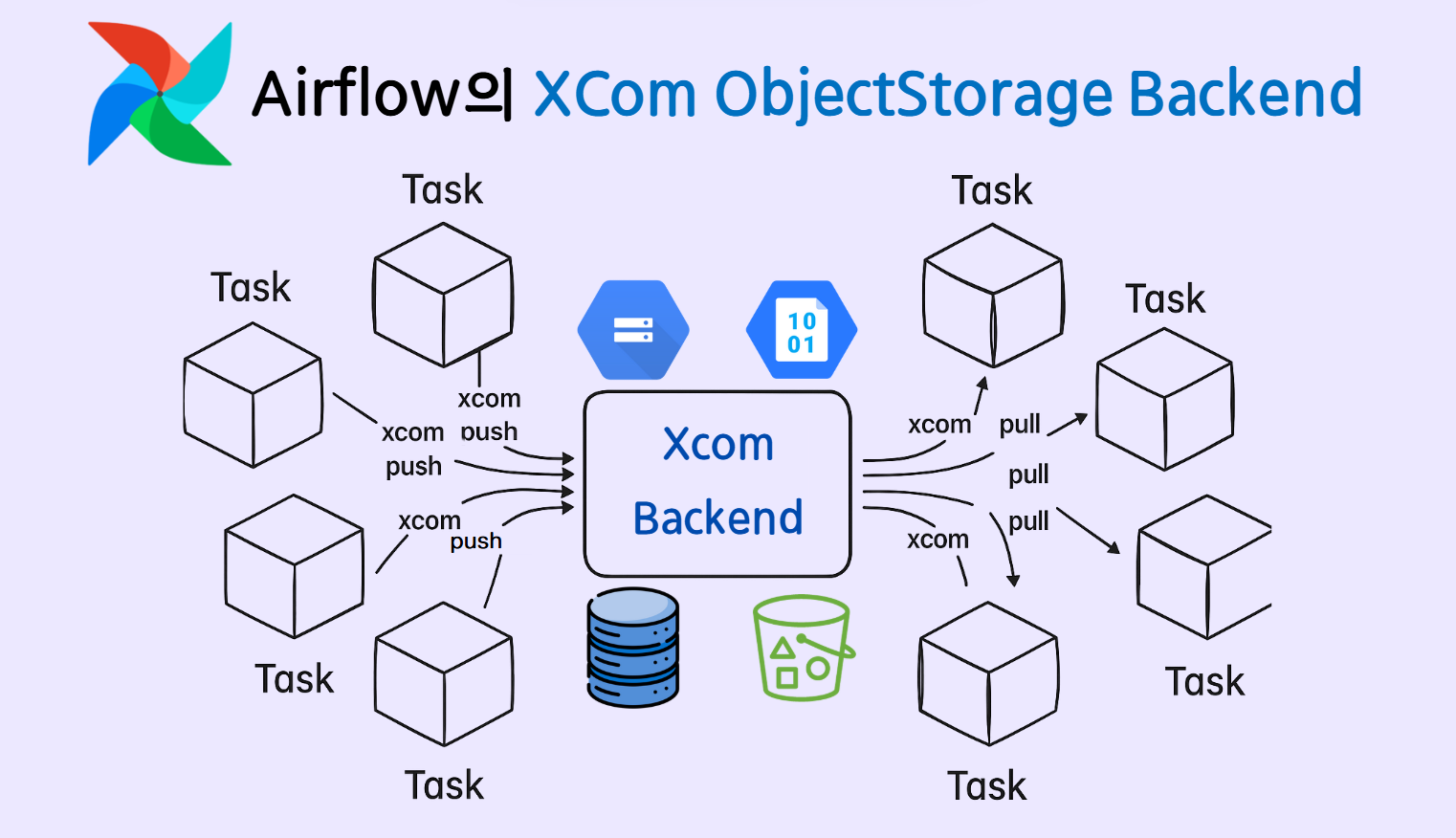
AIRFLOW 3.0, 클라우드 객체 스토리지를 Xcom 저장소로 설정하기(xcom backend)
Airflow의 XCom ObjectStorage Backend 설정하는 방법에 대하여 (AWS S3, Google Cloud Storage)
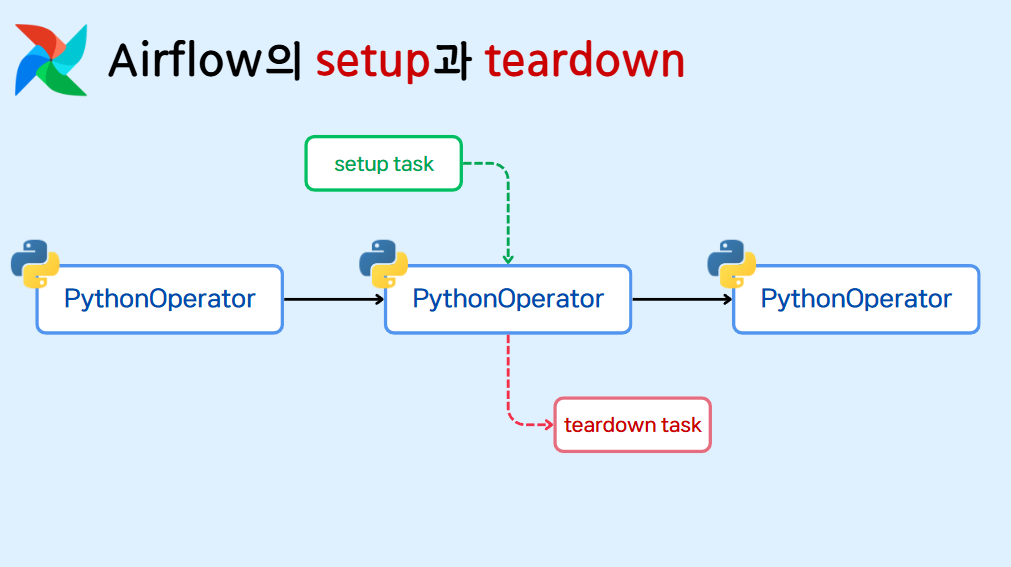
[AIRFLOW] Airflow의 Setup과 Teardown에 대해 알아보자!
airflow Task의 선행, 후행 작업을 설정할 수 있는 setup과 teardown에 대한 이해!
[GCP] BigQuery Dataform으로 증분(Incremental) 데이터 처리하기
GCS에 일정 간격으로 업로드되는 데이터를 BigQuery로 증분 처리하여 조회해보자!
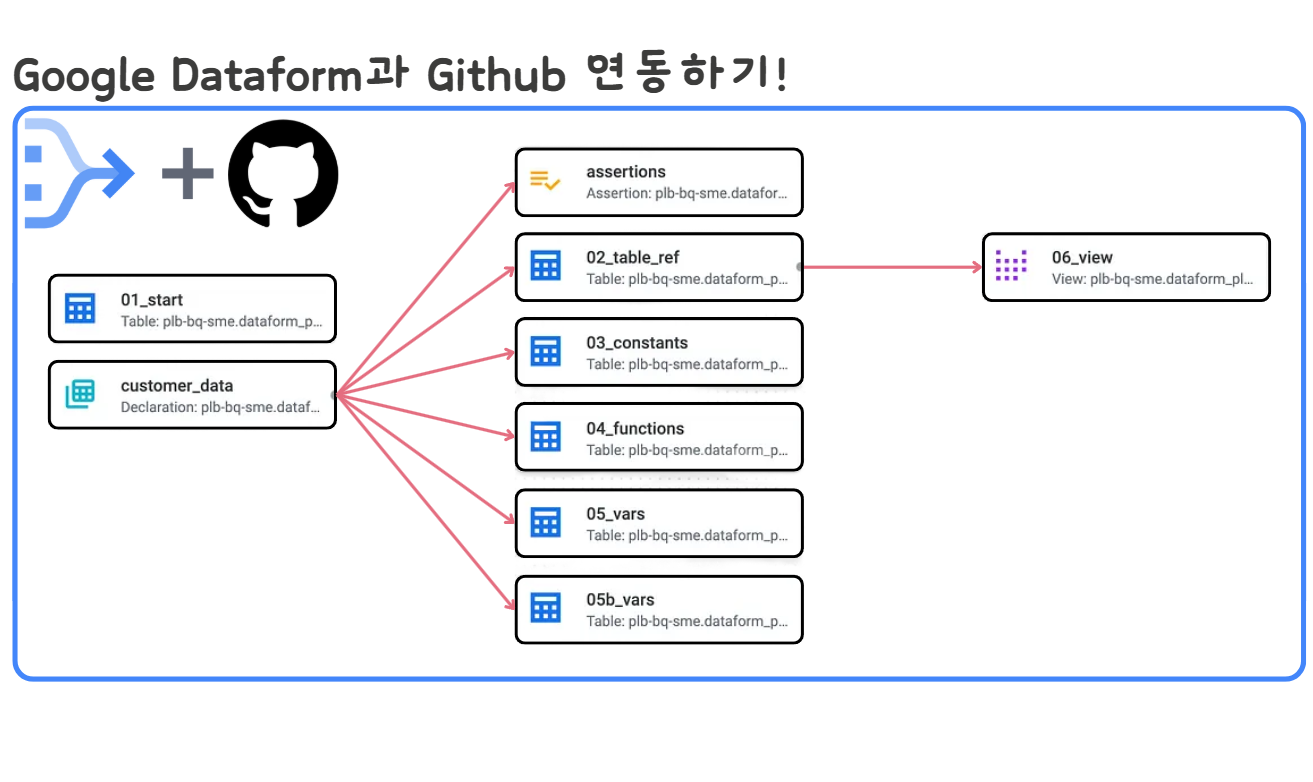
[GCP] BigQuery Dataform과 Github 연동하기( + 심화 내용)
🔹 0. INTRO 앞선 글(BigQuery Dataform으로 빅쿼리 데이터 플로우 자동화하기!)에서는 BigQuery에서 제공해주는 Dataform 이라는 서비스에 대해 알아보고 간단한 실습까지 진행해 보았습니다. 빅쿼리 데이터를 기반으로 자동화된 파이프라인을 만들어준다는 것 외에도 Dataform에는 매력적인 기능들이 많이 있는데요, 대표적인 것이 ...

🌊 Delta Lake 입문자를 위한 가이드 - 실전편(Part 2. delta-spark 라이브러리 활용)
🌊 Delta Lake 입문자를 위한 가이드 실전편! Part2! delta-spark 라이브러리 사용법 총 정리!!

📊 200+ 데이터 엔지니어 인터뷰에서 발견한 최상위 1%의 비결
(해당 글은 아래 명시한 출처의 글을 한글로 각색 및 요약한 내용입니다.)🔥 최상위 데이터 엔지니어들의 공통점이들은 데이터를 단순한 값이 아니라, 흐름(flow) 으로 봅니다.분산 시스템(HDFS, S3), 배치 vs. 스트림 처리 차이를 직관적으로 이해함.저장 포맷

🌊 Delta Lake 입문자를 위한 가이드 - 이론편
0. Delta Lake란 무엇인가? 1. Delta Lake가 등장한 배경 2. Delta Lake의 핵심 설계 원리 3. Delta Lake의 핵심 기능 4. 기존 DL&DW 와의 비교
❗데이터 엔지니어링의 현실, 화려함 뒤에 숨겨진 10가지 뼈 때리는 진실🤕
(해당 글은 아래 명시한 출처의 글을 한글로 각색 및 요약한 내용입니다.) ❗데이터 엔지니어링의 현실, 화려함 뒤에 숨겨진 10가지 뼈 때리는 진실🤕 대용량 데이터, 최첨단 기술, 실시간 분석, 멋진 대시보드…... 데이터 엔지니어링에 대한 이야기는 늘 화려하죠.