[논문리뷰] Adversarial explanations for understanding image classification decisions and improved neural network robustness
XAI / Object Detection

Paper: arxiv.org
Code: github.com
본 글과 본 논문의 구성은 다릅니다.
또한, 정리하기 위한 글이 아닌 개인 메모를 위해 썼던 글이기에 글이 난잡할 수 있습니다.
해당 논문은 Full version과 Lite version 모두 공개하고 있으므로, Lite Version을 먼저 보는 것을 추천드립니다.
0. Abstract
의학 분야나 사기 감지와 같은 몇 몇 민감한 분야의 문제에서 NN(Neural network, 신경망 모델)의 채택은 신뢰도 등의 문제 때문에 굉장히 더뎠고, 이런 상황은 신경망 모델의 예측에 대해 설명하는 알고리즘들의 개발을 촉진했다. 또한 이런 신경망 모델들은 adversarial example이라 불리는 (인지할 수 없는) 일련의 공격에 취약함(모델이 제대로 판단하지 못함)이 드러났다. 우리는 이런 공격들이 NNs(신경망 모델들)을 설명하는 이전의 시도들을 무력화할 수 있는 것과 robust한 네트워크들에서는 그런 공격들 자체가 모델 관련해 꽤나 좋은 신용도를 갖는 ‘설명’으로서의 역할을 할 수 있다는 것을 보여줄 것이다. 우리는 또한 Lipschitz constraint로부터 아이디어를 얻어서 신선한 regularization 기법의 도입이, half-Huber 활성화 함수를 포함해 다른 개선 사항들과 함께, NNs이 adversarial examples에 대한 저항력을 키울 수 있다는 것 또한 보여줄 것이다. ImageNet classification task에서 0.0053의 accuracy-robustness area(ARA)를 갖는 network를 나타냈다(기존 최신 모델의 2.4배). NN의 결정에 대해 이해하는 데 쓰이는 메커니즘이 민감한 분야에서 신뢰도(trust)를 쌓고 NN의 반응에 대해 이해력이 높아지는 데에 중요한 방향이 될 것이다.
1. Introduction
의학적인 연구들은 인간 전문가들을 능가하는 시스템(주로 딥러닝 모델)이 있음을 보였지만, 여전히 통계적 상관관계 그 이면에 있는 통찰에 대해서 증명하는 데에는 어려움을 겪었다. 머신러닝 기반 시스템은 input의 변화에 너무나도 민감하게 움직인다(성능이 좋은 만큼). 이에 따라 다양한 머신러닝 알고리즘을 개발했지만, 우리는 neural networks에 집중하였다.
NN decision 뒤에 있는 이유에 대해 설명하는 최신 기법들은 보통 output에 대해 두드러진 특징을 가진 input의 영역을 히트맵의 형태로 발생시키는 데에 집중해왔다(예를 들어, GradCAM)



(다양한 히트맵 기반 예시들)
하지만 이런 히트맵 기반 기법들은 간결한 실루엣 뒤에 있는 본질에 대해 정보를 교환하지 않으며, 이는 일반적인 영역 내에 있는 구체적인 특성에 대해 추론하는 것을 어렵게 만든다.
또한 매우 비선형적인 네트워크의 선형화에만 의존할 뿐더러 정확한 input에 해당하는 디테일들만 포착하는 문제 또한 존재한다.
Adversarial attcks 또는 adversarial examples로 불리는 몇몇 마이너한 perturbation(간섭) 들은 임의로 NN’s output을 변경할 수 있다. 
더욱이, 적대적 공격으로부터 얻어진 input의 perturbation은 최신 설명 기법에 의해 생성된 heatmap과도 일치하지 않는다. 다시 말하면, adversarial attack에 견고함이 없다면 NN’s decision을 설명하는 시도(기존의 기법들) 제한적인 타당성을 가질 것이다.
우리는 적대적 설명(AEs)을 허용하는 일련의 새로운 기술에 기여하고, 분류 문제에서 두드러진 특징들을 보여 줄 뿐더러 NN’s의 결정에 더욱 믿을 만 한 설명 방법을 제공할 것이다.
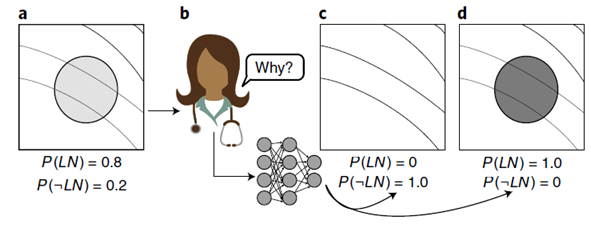
AE process는 아래와 같다.
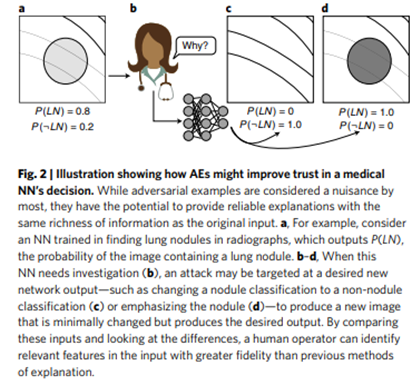
(adversarial example이 대체로 영향을 많이 받는다면, 설명 또한 믿을만하게 제공된다. )
(만약, 위 그림처럼 lung nodule(폐 결절)을 탐색해야 하는 상황에서, 해당 특징을 0 또는 1로 만드는 게 최종 목표. 또한 minimally change가 수반되어야 함.)
기존의 최신 기법들과는 달리, 네트워크 비선형성과 함께 시행되는 AEs는 heatmap이 제공할 수 있는 것보다 더욱 높은 신뢰도로 NN’s decision surface(결정 경계)를 표현한다. 고품질의 AEs를 제공하는 기법은 엔드 투 엔드 모델의 Lipschits constraint를 최소화 하는 것을 중점으로 하고 있으며, 이전에는 많이 탐구되지 않았던 Lipschits regularization의 변형이라 볼 수 있다.
새로운 정규화(regularization)은 현존하는 robustness 기법들과 잘 맞으며, 특히 이 중에 adversarial training과 잘 맞는다. 시각적으로 꽤나 풍부한 설명을 제공하는 것 외에도 우리 기법은 adversarial example이 있는 경우 분류 성능 측면에서 최첨단 기술을 능가하는 강력한 NN을 만든다(ILSVRC 2012 challenge의 분류 모델이 최신 기법들보다 2.4배 높은 accuracy-robustness area(ARA)를 기록).
추가로, 이 연구에서 요약된 방법론은 강력한 네트워크에 대한 적대적 공격을 통해 설득력 있는 설명을 생성하는 가능성을 보여준다.
※ 엔드 투 엔드
- 처음부터 끝까지 일관적인 (기법이 적용되는) 모델. 혹은 Input과 Output을 한 번에 다루는 모델
※ 립시츠 정규화
- 후술
2. Method
2.1. Interpreting AEs
GradCAM과 우리의 AEs에 대한 비교는 아래 그림에서 나타난다. Highest attack ARA 를 가진 CIFAR-10 모델을 이용해 나타냈다(adversarial attack에 대한 방법의 견고함을 포착하는 방법.

위의 그림은 4개의 input 이미지에 대해 1,2위의 (가능한) 예측을 보여준다. 둘 중 하나는 참 값이다. Grad-CAM은 이 1,2위의 가능한 예측에 대해 두드러진 input의 위치를 나타냈다. 위의 그림에서 Cat과 Truck과 같은 매우 배타적인 클래스의 경우에도 Grad-CAM의 설명은 대부분 비슷한 설명을 제공하는 것을 볼 수 있다. 또한 결정에 영향을 끼친 texture나 shape를 나타내는 데도 큰 역할을 하지 않는다. 위 그림의 오른 쪽 절반은 가능성 기준 상위 2개의 예측 클래스에 대한 positive explanations을 보여준다(original input과 adversarial image의 차이와 adversarial image 그 자체).
Ex1의 고양이는 약간 오히려 설명력이 약화되지 않았나. 오히려 고양이는 몸을 보고 판단하는 게 모델에게 유리한 것.


(더욱 더 상세한 디테일, 긍정적인 기여를 한 부분과, 사라진 부분을 나타내고 있다)
Fig.1b: cat class의 신뢰도는 고양이의 얼굴보다는 검정색 몸과 함께할 때 더욱 높았다. Body는 positive contribution으로 주석이 달린 반면, 적대적 이미지는 body를 변화시키고, 그 지역의 전체적인 구조를 유지했으며 대조를 증가시켰다.
반면에, 고양이의 face는 적대적 이미지에서 거의 삭제됐으며, 이는 cat 분류에 대해 반대되는 방향으로 기여했음을 알 수 있다. 이는 NN이 cat에 속할 때 해당 환경에서 face를 인식하는 데 필요한 logic을 가지지 않았음을 나타낸다(아마 이미지에서 너무 작은 feature이기 때문에?).
Fig. 1c: 트럭에 대한 설명은 중앙 cat의 틀이 훈련에 쓰인 많은 트럭 이미지들의 그림을 모방하는 것을 볼 수 있다. 다시 말하면, 이미지의 가장자리 모양들이 매우 잘 인식됐다(특히 우측 상단이 트레일러와 하늘의 경계로 변한다). 설명의 일부로 포함된 트럭의 경우 원본 이미지에는 없기 때문에, counter-indicator로 볼 수 있다.
하지만 원본 이미지와 적대적 예제 사이의 많은 간섭은 둘 다 공통적으로 나타난다. – 트럭은 세밀해서 더 쉽게 눈에 띄는 반면, 고양이의 몸은 더 높은 가능성의 고양이 분류를 위해 더욱 더 어두운 색을 선호한다.
또한, AEs에 있어서 final class confidence는 0.31과 0.57인데, 이는 L_2 space에서 input이 cat manifold보다 truck manifold에 더 가깝다는 것(b,c에서).
AEs와 함께라면 우리는 네트워크의 역할을 통해 정보를 얻는데, 수정될 필요가 있는 input features에서 뿐만 아니라, ‘resulting class confidences’를 통해서도 얻을 수 있다(manifold)에 관한 얘기.

D: car를 우한 AE는 앞 유리의 기둥의 기울기를 조금 완화시켰고, 바퀴 근처의 색을 많이 없앴다. 두 가지 모두 원래의 INPUT에는 존재했지만 cars에서는 존재하지 ㅏㅇㄶ는 특징들이다. 차 뒤의 trailer가 눈에 띄지 않는 변화도 있다.

E: 왜 원래의 input이 트럭으로 판별되지 않았는지(0.35 vs 0.34)를 보여준다. 즉, 트레일러와 차의 앞 부분의 차이를 메꿔준 것이다.
등등.
F,g: 최종 confidence가 개구리 0.27, 개 0.19밖에 안 되는 걸 보면 아마 이 이미지는 original training data들의 manifold와 꽤나 먼 것을 알 수 있고, 네트워크가 frog class가 applicable한다는 것을 확신하는 데 있어서 그저 얼굴에 ‘그림자’가 생긴 frog-skin만 소유하고 있음을 예상할 수 있다.

이미지의 상단부는 bird의 face와 굉장히 유사했고, 하단부의 실제 dog pixels은 조금 부드러워 졌다(bird와 반대되는 부분)
동시에 i에서는 만약 옷의 하얀 부분이 더욱 쓸어내려 진다면, 강아지와 비슷한 얼굴을 함을 알 수 있다.
Supple에 LSVRC2012 버전이나 이전의 최신 설명 기법들과의 비교가 존재한다.
2.2. AE Generation and evaluation
목표
1. 분류 정확도를 낮춘다
2. 분류 설명을 생성한다
모델의 ARA 평가를 위한 적대적 공격 생성은 아래와 같다.
Gradient step을 그들의 크기(Norm)에 의해 normalizing 하는 방법을 활용.
(두 개의 논문을 기반으로 함 - attack에서 normalizing 하는 이유, ROBUST를 평가하는 전반적인 알고리즘)
IEEE Xplore
CVPR 2019
※ Why do they use L2 norm?
- 거리는 중요하지만…
※ Why do normalize?
기존의 L2 norm 왜곡 공격은 너무 느려서, 효율적으로 사용하기 위해서. 또한 느린 이유는 gradient norm이 크게 변하기 때문에 적절한 학습률을 찾기도 어려워 단위 벡터로 만들어버리는 것. 또는 모델의 결과가 1에 가깝거나(학습이 완료됐으므로, adversarial example을 찾는 동안 급격하게 cross entropy가 증가해, gradient norm에도 영향을 끼치는 것).
대강 예시를 든 아래의 그래프를 보자.
그림 출처 : 왜 크로스 엔트로피를 쓸까? - 머신러닝/딥러닝을 위한 수학 - 제이미 (postype.com)
(KL발산과 크로스엔트로피의 관계)
(확률 분포 간의 모사도를 크로스 엔트로피로 환산 가능한 것 + 젠센부등식..)



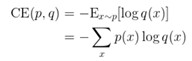

Target loss를 증가시키고, L_2 error를 최소화 하는 것 사이에서 변경하는 것은 그걸 동시에 추구하는 것보다(if else를 사용해) 그 2개의 에러 사이에서 번 갈아가며 자동적인 균형을 허용했고, 이로 인해 더 작은 noise’s NORM을 발견할 수 있다. 기존의 논문에서 제안된 공격과는 다르게 (target 분류 에러가 도달하기 전에는), magnitude refinement를 시작하지 않는다. 아래 알고리즘에서 임계값은 minimizing the correct class’s post-softmax prediction (true class와 멀어지게 하기 위해서)와 minimizing the attack magnitude 사이에서 변화하는데, 이는 로 정의된다.
INPUT
: 목표 함수, attack의 output이 true class t와 다를 때 true 반환
: balacing term between categorical-loss and MSE-loss
OUTPUT
: 를 만족시키고 가장 작은 벡터의 길이를 가지는 적대적 노이즈
Magtitude: norm, 원점부터 벡터 좌표까지의 거리
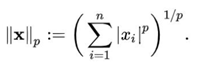

5: clipping의 표기
8: true class와 attack class가 다를 때 or 그 외의 기준…
13: true class와 attack class가 일치할 때는 (결과가 true class와 일치하므로)를 편미분한다. 이는 (input+노이즈)의 result에 대한 영향력을 알기 위함이고, gradient의 magnitude 또한 고정해준다.
즉,
8 : MSE-loss, 노이즈 벡터의 거리(길이)를 최소화
13: categorical-loss(softmax), 분류 정확도 최소화.
위의 알고리즘에서 는 두 가지를 제안한다.
하나는 기존에 많이 잘 알려진 adversarial attack metric이며, 탑1 정확도가 줄어드는 경계를 나타낸다.
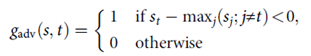
소프트맥스는 벡터를 결과로 반환할텐데, true class보다 크기가 큰 다른 요소가 있다면 g가 활성화되는 것(굳이 소프트맥스에 대해 거리를 벌릴 필요보다는 단순히 노이즈의 norm을 줄이는 것을 목표로 함.
해당 robust NNs을 이용한 결과는 아래와 같다.
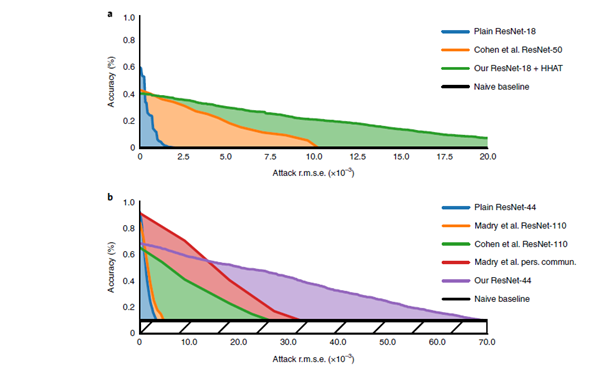

(RMSE기준 보다 큰 간섭을 인내할 수 있게 된다. 눈으로 인지할 수 있을 정도)
(Attack RMSE: 1000개의 데이터에 대해, 공격을 받았을 때
norm: L2 NORM은 이상치에 민감하기 때문에 최소화한다면 이상치가 사라지려는 거 아닌가? no, L1 NORM보다는 그래도 이상치를 강조할 것)
ARA 값을 추정할 때는 random validation으로 하거나, 1000개의 이미지가 옳게 분류될 때까지 테스트한다. 또한 이로부터 (각각의 이미지가 원래 올바른 correct classification을 보존할 때의)RMSE의 list를 뽑아내고, Algorithm1에 의해 최소화 된다.
해당 RMSE 리스트는 예측을 잘못했을 때 각 이미지마다 zero를 확장하였다. 즉, 모델이 수정되지 않은 이미지에 대해 70%의 분류를 달성한다면, 최종 RMSE의 LIST를 얻는데, 이는 1429 길이의 리스트일 것이다(1429X0.7=1000). 그 후 이 RMSE 리스트는 ‘다른 레벨의 RMSE’에서 ACCURACY가 평가되고, 순진한 BASELINE 위에 있는 ARE를 Attack ARA metric이라 정의한다. 이 과정을 통해 ARA는 분류기의 Predict power와 adversary를 극복하는 능력 두 가지를 측정한다. (클수록 좋다)
만약 두개의 NN이 동일한 clean accuracies를 기록할 때, ARA가 3배 큰 모델은3배더많은 노이즈를 갖는 adversary에 대해서도 예측력을 보존한다(ARA가 낮은 모델은 예측력을 보존할 수 없다).
우리는 N=450, o:SGD(0.01, momentum 0.9, 에타 0.55)를 사용했다. 그 결과가 아래이다.

:전통적인 방법, :true class를 10%까지 줄이는 방법
CIFAR-10은 10개의 Class기 때문에, Better than random, 즉 true class의 softmax값이 0.1보다 크다면 확률을 낮추게끔 경사 상승법이 적용되고, 0.1보다 작다면 noise의 RMSE를 줄인다).
위 그림은 (행 기준으로) 전통적인 non-robust NN(노이즈가 많을 때 버틸 수 없는), adversarial training NN, adversarial training NN+,
물론 또한 결정경계가 두드러진 특징을 표현할 수 있을 만큼 data point에서 멀어지지 못한다는 단점 또한 있었다. 대신에, 간섭의 모양을 output에 최대한 영향을 끼치는 방향으로 최적화하여, input과 explanation 사이의 인지적인 차이를 두는 데 목표를 뒀다.
이는 를 경계 RMSE(ρ)까지 따르게 함으로써 수행됐는데, 그 경계에서 RMSE는 최소화되며, 그 때 알고리즘 1과 유하나 tick-tock method와 비슷하지만 약간 다른 경계 기준을 대체함으로써 달성되었다.
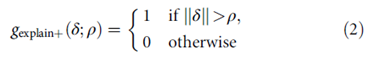
noise vector가 일정 이상의 RMSE를 가질 때, 노이즈를 줄인다. 즉, 노이즈를 특정 경계로 유지하는 것.
는 그저 selected class를 최대화 하는 쪽으로 Algorithm1을 변경하면 된다(최소화하는 게 아니라).

그렇다고 양적인 attack ARA가 항상 AE’s의 질적인 설명을 나타내는 것은 아닌데, 예를 들어 트럭과 자동차가 주로 헷갈린다면 이는 각각의 클래스에 대한 untargeted attack에서 magnitude가 감소할 것이기 때문이다.
(원래 큰 차이가 나지 않으므로)
이 둘을 구별할 수 있는 모델의 능력의 관점에서라면 g_adv는 좋은 방법일 것이다. 하지만, 분류기가 관련 없는 클래스들로부터 이 둘을 구별하는 거라면, 이 둘에 해당하는 s_j 값은 아마 합심지어 높아질 것이다. (0.49, 0.44, 0.02…)
이 문제는 아래 그림에서 드러난다.
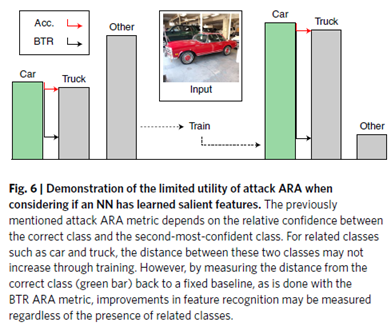
(BTR이 훨씬 감소 폭이 크다)
두 CLASS 사이의 거리가.
기존의 서술된 ARA 메트릭은 Correct class와 second-most-confident class 사이간의 관계를 나타낸다.
(second-most-confident :
이 상황은 모델이 ‘다른 나머지 클래스들에 비해’, 자동차와 트럭으로 구분하는 능력이 뛰어나다는 거지) attack magnitude가 여전히 쉽게 혼동될 수 있기 때문에 attack magnitude는 줄어들지 않을 것이다(노이즈가 매우 커야 할 것, 는 보다 가 더 클 때, 즉 자동차보다 트럭이 더 클 때 감소한다). 제 3자가 크게 중요한 것은 아니다. 기반으로는 공격 크기를 (attack magnitude를) 더 이상 개선할 수 없는 것이다.
이런 문제를 해결하기 위해 분류기의 클래스 기반 특징의 지식을 측정하기 위해 better than random (Btr)를 고려할 수도 있다.
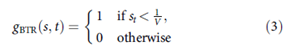
: 예측에 쓰이는 클래스들
가 순진한 예측보다 낮다면 활성화 된다. ()
즉, threshold가 0.44에서 0.1 등으로 감소한 것. 기존에는 보다 이 작기만 하면 됐었다.
Soft max output 이전의 출력을 0으로재설정하면 필요 조건이 달성되므로 BTR 제약 조건을 충족하는 NN 출력이 존재할 가능성이 높다. 즉, BTR 제약이 잘 만족된다.
3. Details
3.1. 립시츠(Lipschitzs)
Adversarial robustness를 위한 Lipschitz minimization
AE의 질은 NN’s의 adversarial attack에 대한 robustness와 크게 관련된다.

(맨 처음의 AE algorithm to non-robust NN은 각 AE panel에 대해 no intelligible feature를 보여준다.)

간단하게, Lipschitz continuity는 함수 값의 bounding인데, 특정 두 점 사이에서 상수배 이상으로 함수 값이 변하는 걸 허용하지 않는 것을 말한다. 머신 러닝에서는 이전에 every layer의 bounding of derivatives로서 근사화 되어 왔다(whole network의 derivatives를 최소화하는 것 대신).
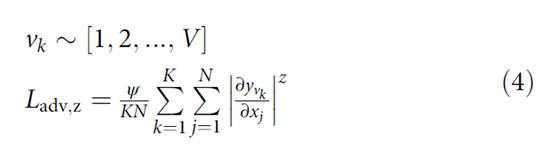
우리는 그 대신 분류 모델의 pre-softmax output과 intput 사이의 end-to-end 변화율을 aggressively 최소화하는 term인 new Lipschitz regularization term를 개발했다. 효율성을 위해 stochastic하게 만들어졌다. Input vector가 n차원의 x이고, output vector가 V차원의 y 인 NN에 대해, 손실 함수 L_(adv,z),strenth ψ를 통해 매 훈련 step을 regularizing하는 K차원의 random output을 선택한다.
위 식 (4)의 parameter에 대한 영향과 robustness에 영향을 끼치는 요소를 결정하기 위해 CIFAR-10 Dataset을 이용해 실험을 수행했다(디테일은 full-version의 method 1-3). Table 1은 여러 실험 집단의 결과를 보여준다.
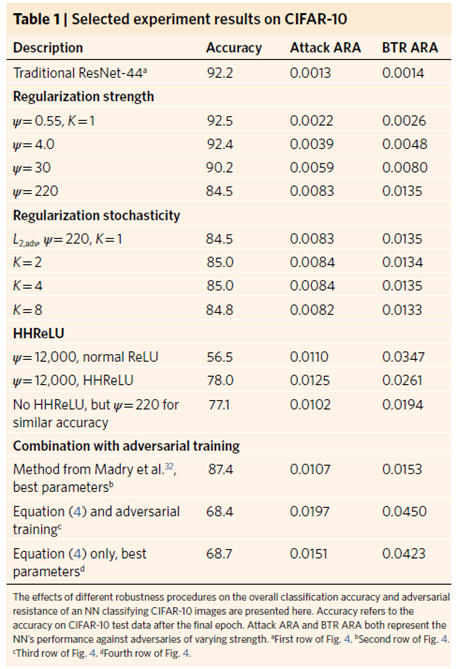
Table1의 다양한 시행에 대해 식 (4)의 효율성을 분석했을 때, 여러 quntities가 고려됐다. Accuracy는 분류 모델 NN의 clean data(AE가 없는)에 대한 accuracy이다. Attack ARA는 다양한 levels of pertubation에 따른 naïve classifier와 NN’s의 accuracy 차이에 대한 면적이다. BTR ARA는 ARA과 유사하지만, ‘accurate’하다고 여겨지는 network, 즉 true class에 대한 NN’s confidence가 random chance confidence보다 높을 때에만 해당한다.
대부분 true class에 대한 confidence는 random보다높지 않을지?
3.2. Regularization strength
우리는 원래 규제 중 strength ψ가 증가할수록 adversarial resistance 증가에 도움이 되는 것을 추구하였다. Table 1은 그 모습을 보여준다. 또한, 특정 level (ψ=4.0) 까지는 adversarial resistance 뿐만 아니라 classifier의 accuracy on clean data 또한 확보할 수 있었다. 그 후에는 adversarial resistance가 증가하되 accuracy는 감소했다. 따라서, ψ는 accuracy와 adversarial resistance 중에 무엇이 더 중요한지에 따라 변할 수 있다.
3.3. Half-Huber rectified linear unit

위 참고. ReLU는 연속이지만 미분 값이 불연속이다. 위의 규제 식 (4)는 미분 가능을 필요로 하기 때문에 HHReLU를 사용한다. 이는 Huber function의 rectified(정류) version이며, 우리의 필요와 맞는다.
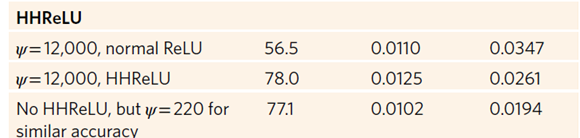
(비슷한 accuracy일 때 더 ARA 측면에서 높았다)
3.4. Combination with adversarial training
우리는 adversarial training을 평가했다. parameter들은 A. Madry와 personel communication에 맞추었다. Attack and BTR ARAs가 우리의 HHReLU NN보다 NN with adversarial training 일 때 더 낮았다(accuracy는 높았지만).
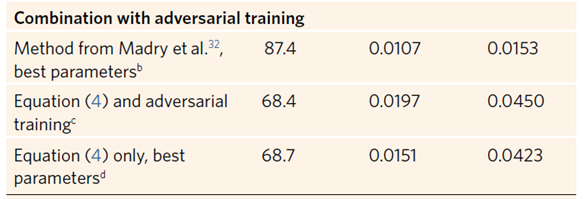
Adversarial training을 식 (4)와 합쳤을 때 우리의 best results를 보였다. Adversarial training에 식 (4)를 추가했을 때는 두 개의 ARA에 대해 많은 상승을 보였다. Adversarial training과 combined approach 두 개 사이의 accuracy에 관해서는 combined NN의 accuracy가 0.013의 r.m.s.e에 비해 더 높았다. (이는 지각할 수 없는 perturbation이다)

3번째가 combined approach, 2번째가 only adversarial training

또한, 식(4)는 adversarial training이 없다면 BTR ARA는 비슷하지만 attack ARA가 낮은 것을 볼 수 있다. 우리는 adversarial training이 loss function의 steepest ascent의 방향을 stabilize 하는 데 도움이 된다고 주장해본다. 왜냐면 우리의 regularization은 아래 그림처럼 entire loss를 stabilize 하기 때문이다. 두 기법의 정의가 이 차이를 제공하며, empirical(경험적) evidence가 이를 뒷받침한다.
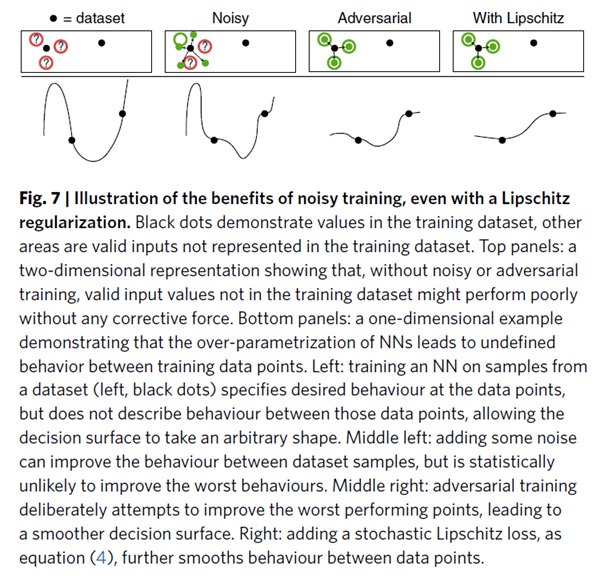
위의 panel은 noisy나 adversarial training이 없이, training dataset에 없는 valie input value가 corrective force없이 굉장히 성능이 형편없다는 것을 보여주는 2차원 표현이다.
아래의 panel은 1차원 표현으로, nn에서 over-parametrization이 training data points 사이에서 정의되지 않은 행동을 한다는 것을 보여준다.
1번째: black dots로 대표되는 dataset에서 나온 sample에 대한 학습은 data point에서의 desired behaviour를 구체화하지만, 그 data point 사이에 대해서는 묘사하지 않는다.
2번째: noise를 조금 더하는 것은 dataset sample들 사이의 행동에 대해서 성능을 향상시킬 수 있지만, 통계적으로는 wors behaviour를 향상시킨다고 보기는 힘들다.
3번째: adversarial trainign은 의도적으로 worst performing point의 성능을 향상시키려고 시도하므로, 더욱 더 부드러운 결정 경계를 내포한다. 4번째: stochastic Lipschitz loss(식 (4))를 더한다면 더욱 더 data points 사이에 있는 데이터에 대해서도 부드럽게 예측할 수 있다.
즉, input에 조금만 noise를 주더라도 난장판을 피우는 기본 모델에 비해 노이즈에 저항력을 가질 수 있다.
4. Discussion
우리는 adversarial example에 저항하는 능력을 향상하기 위해 Lipschitz constraint를 기반으로 하는 regularization 기법을 제안했다. 또한 이와 함꼐 HHReLU와 개선된 adversarial training 방법론을 제안했다.
ILSVRC 2012 data set에는 이 방법이 ARA를 (최신 기법에 비해) 2.4배 향상시켰고, 특히 clean data에 대한 accuracy 또한 보장했으며, network의 크기 또한 1/3밖에 안 됐다. 이 연구의 교리에 더 집중하면, 우리는 이 개선된 stability(robustness)가 adversarial example이 매우 discernible feature와 함께 생성된다는 것을 볼 수 있었다. 이 adversarial example들은 nonlinear explanation mechanism로서 사용될 수 있으며, 이 네트워크와 비선형성과 함께 작업하여 더욱 믿을 만한 설명을 제공한다.
또한 AEs는 개선된 adversarial resistance를 생성하기 위한 active learning pipeline의 일부로서 annotated될 수 있다. 우리는 이 연구가 adversarial resistance와 explain able machine learning에 대한 노력에 도움이 되길 바라고, biomedical applicatin이나 autonomous vehicle과 같은 설명성이 굉장히 중요한 산업 분야에 대해 algorithm이 더욱 믿을 만 해지길 기대한다.
