[논문리뷰] Opportunities and Challenges in Explainable Artificial Intelligence (XAI): A Survey
XAI / Object Detection
Paper:arxiv.org
0. Abstract
-
XAI는 고품질의 해석 가능하고, 직관적이고, 인간이 이해 가능한 AI 결정에 대한 설명을 생성하게끔 도구, 기법, 알고리즘들을 장려하는 한 분야이다.
-
XAI에 대한 폭 넓게 살펴보고, 일부는 수학적 지식도 포함한다.
우선, 알고리즘의 이면에있는 설명, 방법론을 기반으로 XAI 기법들을 분류하고, 해석 가능하고, 스스로 설명 가능한 가치 있는 딥러닝 모델을 구축하는 데 도움이 될 설명 레벨과 쓰임새에 대해다뤄보자. 우리는 그리고 XAI 연구의 주된 원리를 기술하고, 역사적인 타임라인을 살펴볼 것이다(XAI의, 2007년부터 2020년).
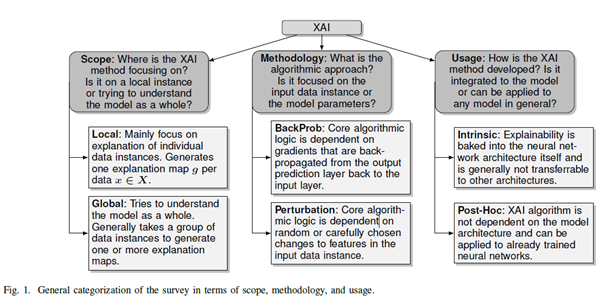
전역적으로 살펴볼 것이냐, 지역적으로 살펴볼 것이냐. 또는, 역전파를 기반으로 하는 모델의 Parameter에 중점을 둘 것이냐, Perturbation(섭동)을 기반으로 input data instance의 feature에 임의로, 또는 조심스럽게 선별된 변화에 대해 의존할 것이냐. XAI가 일반적인 모델에 다 적용될 수 있는지, 아니면 특정 모델에 통합되는지? 즉, 설명성이 신경망 네트워크에 baked into 되어 일반적으로 다른 구조에는 적용될 수 있거나(Intrinsic), 이미 훈련이 완료 된 신경망 네트워크에도 적용될 수 있거나(Post-Hoc).
또한, XAI를 위한 여러 평가 테크닉 또한 특정 XAI 기법들의 한계와 미래 방향을 다루면서 다루어질 것이다. 위의 분류 모델을 기반으로 논문이 전개될 것이다.
3. DEFINITIONS AND PRELIMINARIES
A. Why Is Research on XAI Important?
-
헬스케어, 신용점수, 대출 수락 등 많은 분야에서 설명을 필요로 한다(윤리적인, 법적인, 그리고 안전에 관한 이유 등으로)
-
단, 본 논문은 1) 신뢰도(trustability), 2) 투명성(transparency), 3) 편향과 공평(bias and fairness)로 요약한다.
-
모델 이전에 이에 관한 논의를 할 게 아니라, 학습이 끝나고 하자는 거.


Original data인 panda(57.7%로 판별) + 0.07*선형동물(8.2%로 판별) -> 긴팔원숭이(99.3%로 판별)
이렇듯, 인간이 보기에는 비슷한 이미지임에도 컴퓨터는 다르게 판별하곤 한다.
아무튼, highly non-linear deep learning algorithms with millions of parameters 에 관해서라면, XAI는 다음과 같은 요소들을 개선 할 필요가 있다.
- Improves Transparency
- 충분히 인간이 이해 가능하게 표현된다면 딥러닝 모델은 transparent 하다고 한다. 모델 분해나 시뮬레이션을 통해서 일 수도 있고, 알고리즘 그 자체에서 행해질 수 있다.
- Improves Trust
- Scientific한 설명이나, logical한 추론이 있다면 더욱 믿음직한 모델이 될 것.
- Improves Model Bias Understanding and Fairness
- XAI는 공정함(fairness – 특정 input을 선호하면 안 됨)를 증진하고, input datasets이나 좋지 못한 신경망 모델에 의해 AI 결정에 스며든 편향(biases)를 완화하는 데 도움이 되어야 한다.
Timelines
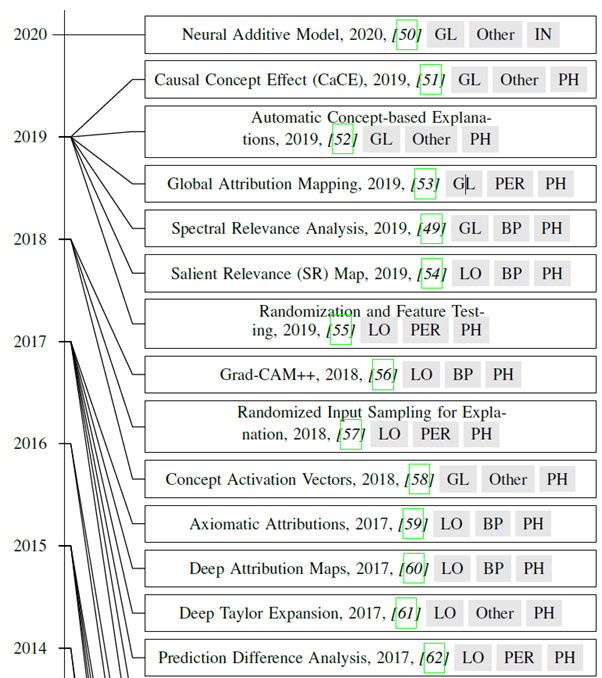
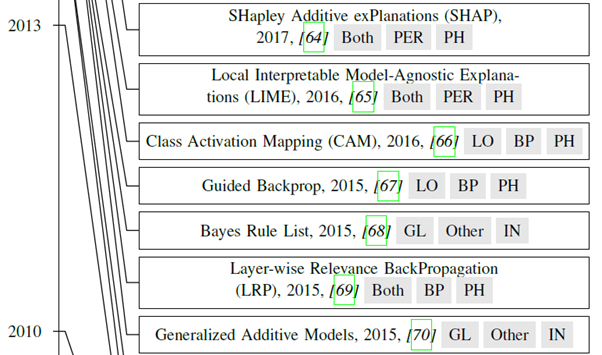
Abbreviation
4. SCOPE OF EXPLANATION
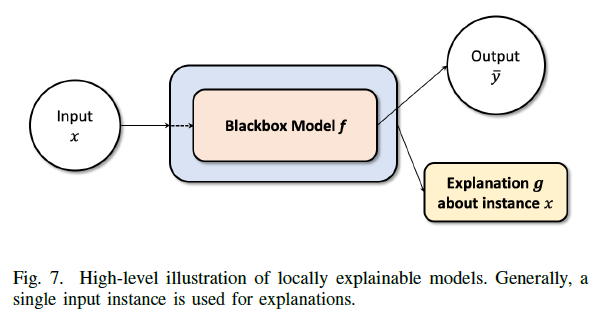
A. LOCAL

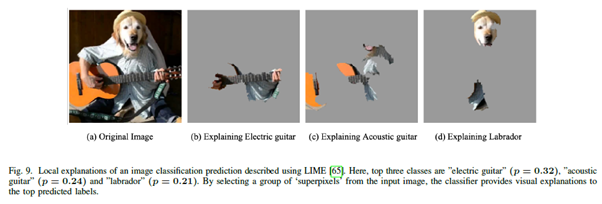
- LIME을 활용한 모델, 단, LOCAL 특화
B. GLOBAL
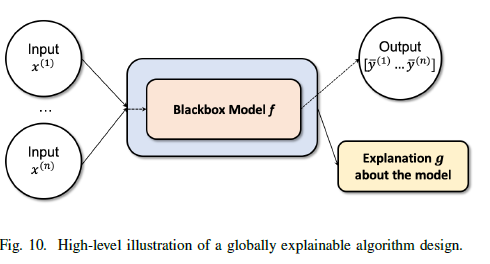

- Class-model visualization 방법을 이용함. Deep dream으로 불리기도 함(사진 보면 알겠지만)
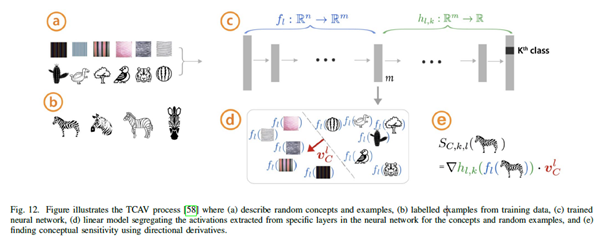
- CAVs는 global한 xai 방법인데, 신경망 네트워크 내부의 상태를 인간 친화적인 분야에서 해석하는 모델이다.
- 위 사진은 임의의 개념과 예시를 묘사하고(a) 학습 데이터로부터 예시에 라벨링을 하고(b), 모델을 학습하며(c), 특정 개념과 예시에 대해 신경망의 특정 레이어로부터 추출한 activation을 분리하는 선형모델(d), 방향도함수(그래디언트 기반 방법과 비슷한)를 통해 conceptual sensitivity를 찾는 것(e)로 이루어져 있다
5. DIFFERENCES IN THE METHODOLOGY
A. Pertubation-Based
- LIME, SHAP, RISE, IRT, OSFT 등
B. Gradient-Based
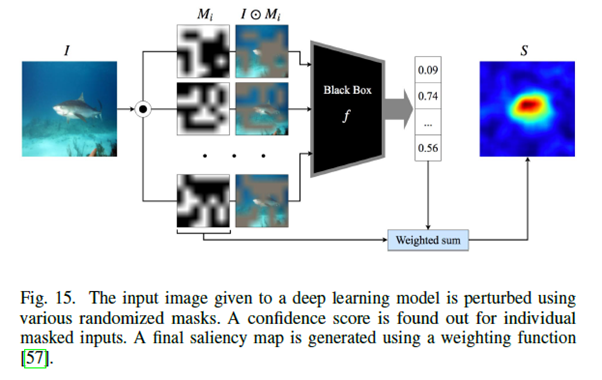
- Pertubation-based 방법들은 주로 개별 feature의 속성(output으로의)을 설명하기 위해 input feature space의 변화에 초점을 둔다.
- CAM, SR, Saliency Map 등.
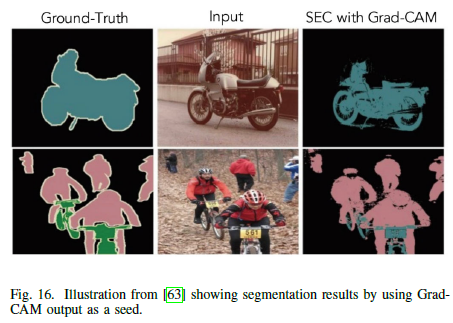
- CNN의 뉴런의 활동을 Localizing 하는 class-discriminative attribution 기법이다(Grad-Cam).
- 이미지 분류에서 분류기를 설명하거나, image segmentation, visual question answering 등에 성공적으로 적용되었다.
- Ground-Truth는 아마 아마존의 태그 서비스?
6. MODEL USAGE OR IMPLEMENTATION LEVEL
A. Model intrinsic
- 모델에 내재되어 있는가?
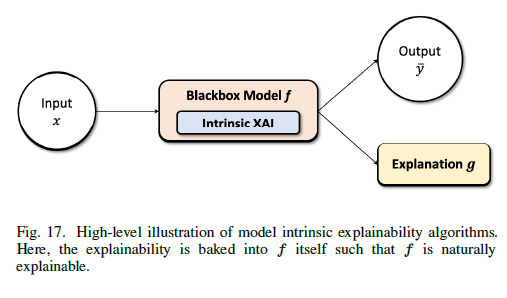
이럴 때 모델은 근본적으로 설명가능하다.
- Trees and Rule-based Models.
- Generalized additive models(GAMs)
수백만개의 결정 트리가 종종 필요하다고 한다. - LDA, Discriminant Analysis, SPDA, FMRI 등
B. Post-Hoc
- 모델에 내재되어 있지 않는가?
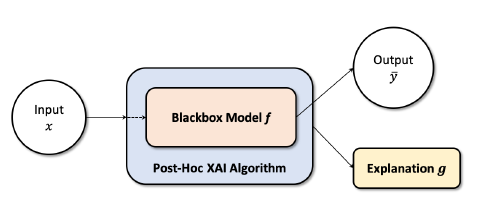
- 이미 훈련 된 분류기의 결정에 대해 설명하려면 AI를 black or white로 보는 알고리즘이 필요하다. 블랙박스는 내부 operation을 알 수 없으며, 화이트 박스에서는 모델의 구조와 레이어 구조를 알고 있어야 한다.
- 이미 정확도가 높은 모델이 설명성까지 부엽다을 수 있다는 점으로부터 유용함.
- XAI 알고리즘은 어떠한 네트워크 구조에서나 쓰일 수 있다는 모델 불가지론.
- Deconvolution network, Saliency maps, most attribution based method 등이 네트워크를 화이트 또는 블랙박스로 여기는 데 쓰일 수 있다.
Summary
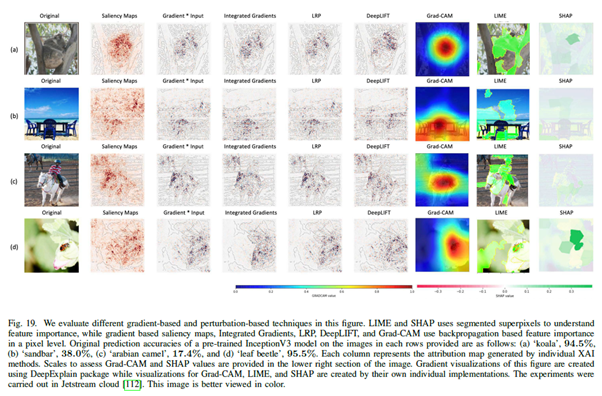
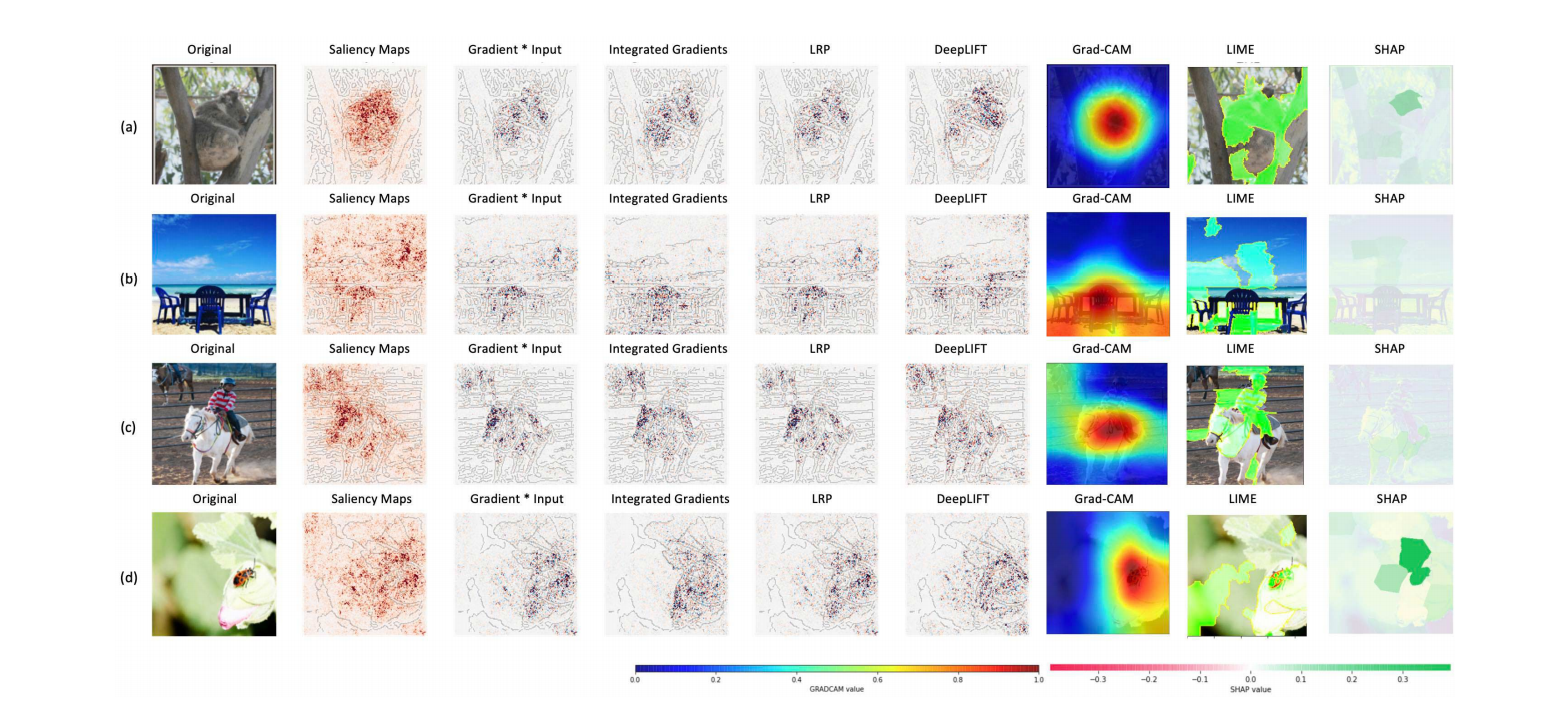
- LIME과 SHAP는 segmented superpixels(픽셀을 특정 조건을 따라 크게 합치는 것)을 사용하는 반면, 그래디언트 기반의 saliency map과 Integrated Gradient, LRP, DeepLIFT, Grad-CAM 등은 역전파 기반의 피쳐 중요도를 사용한다(픽셀단위)

- 약간의 간섭이 생긴다면 신뢰도는 크게 변하지 않는 반면 피쳐 중요도 map은 크게 영향을 받는다 -> Gradient based 기법의 단점.
Conclusion, and Future Direction
- 의사 결정을 위해 XAI 설명 맵을 추론하는 데 human-attention의 부족함.
- 정량적인 평가방식의 부재(완벽한지, 옳은지)
- …나머지는 위에서 다뤄진 모든 논문들의 개선점이 달려있다.
