SHAP 실습 – 보스턴 주택 가격에 대한 설명

DATA
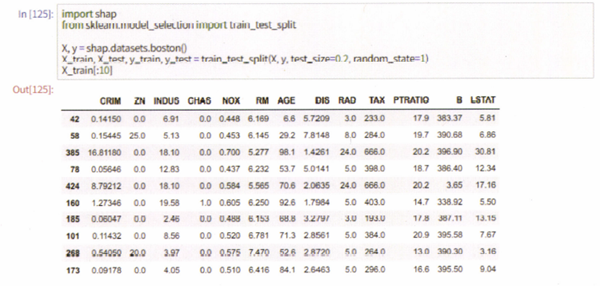
특정 Feature 간 상관관계
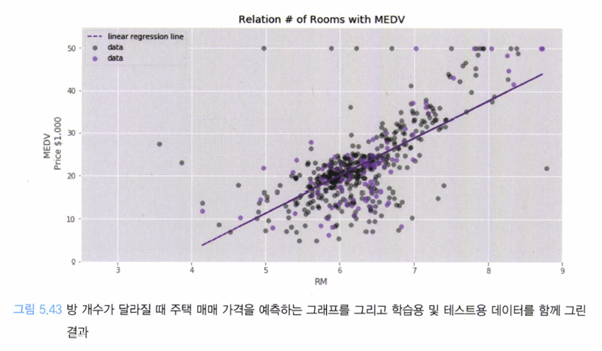
위와 같은 (단변수) 회귀 모델을 통해 예측을 진행할 수 있고, 이를 Test set에 적용하면 아래와 같은 loss가 나온다.

하지만, 일반적인 경우 위와 같은 Loss 값으로는 어떠한 구체적인 정보도 주지 못한다. 단순히 변수의 예측 값과 실제 값의 ‘거리’를 나타낼 뿐이다.
이는 다변수를 이용한 XGBoost를 이용했을 경우에도 크게 달라지지는 않는다.

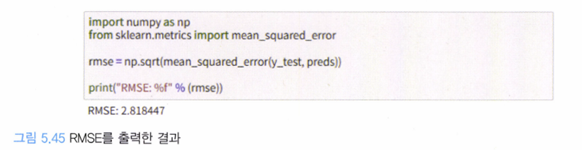
하지만 변수를 늘렸을 때 성능이 더욱 좋아졌기 때문에, 보다 많은 변수를 이용하는 것이 효과적이라고 할 수 있다. 이 경우에는, 집 값에 대한 예측 값은 알 수 있지만 대체 어떤 특성 때문에 집 값이 결정됐는 지 이해하기는 어려울 것이다. 이를 위해 SHAP 알고리즘을 적용해보도록 하자.


위와 같이 ‘하나’의 데이터에 대해 SHAP를 적용했을 경우 각각 특성의 평균적인 기여도를 계산할 수 있게 된다.
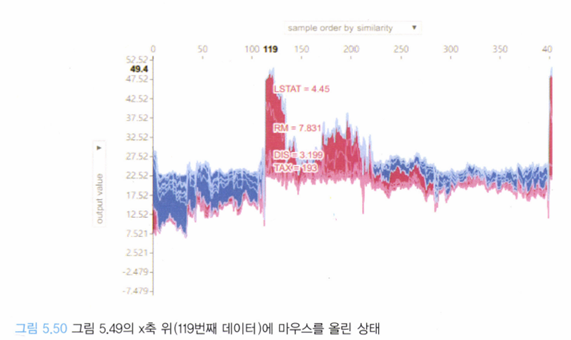
만약 데이터(집 값) 중에 아래와 같이 의심이 가는 데이터가 있다면, SHAP를 이용해 조사할 만 하다.
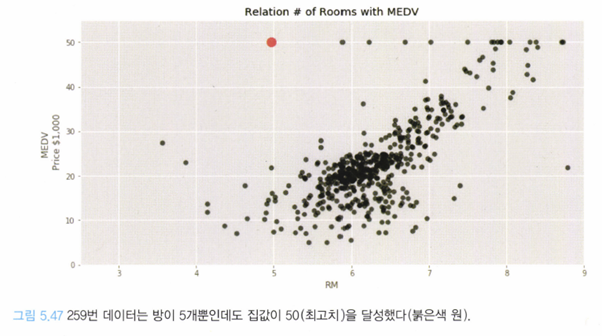

위와 같은 영향도를 통해 해당 인공지능 모델은 ‘방 개수’는 크게 중요시 하지 않는다는 것을 알 수 있고, DIS(업무지 까지의 거리), LSTAT(하위 계층 사람들의 부재), CRIM(범죄율) 등의 요소가 집 값 상승에 큰 역할을 했음을 알 수 있다.
이러한 개별 데이터(Local)에 대한 분석은 전체 모델(Global)로도 확장될 수 있다.
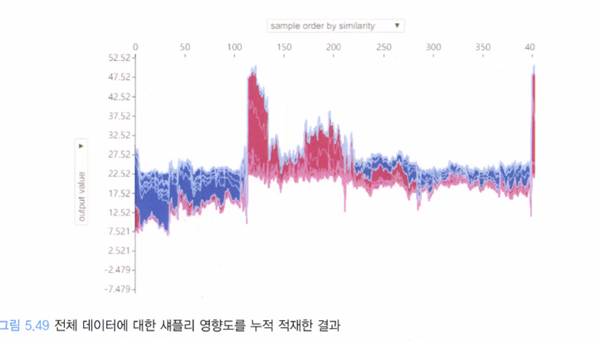
위의 라이브러리를 이용해 특정 ‘피처’의 영향도 또한 시각화할 수 있다.
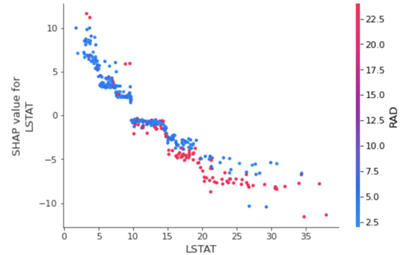
이는 저소득층 비율이 변함에 따라 달라지는 섀플리 값을 보여준다. X축은 저소득층 비율, Y축은 섀플리 값이다. 붉은색 데이터는 다른 피처들보다 저소득층 집값 변동이 큰 데이터고, 파란색 데이터는 저소득층 비율이 다른 피처들에 비해 적은 영향을 미치는 경우이다.
아래와 같이 전체 피쳐가 모델의 예측에 끼치는 영향도 살펴볼 수 있다. 파란색 점은 피처가 집 값을 결정하는 데 영향을 적게 미친 것이고, 붉은색 점은 해당 피처가 집 값을 결정하는 데 큰 영향을 미쳤다고 볼 수 있다.
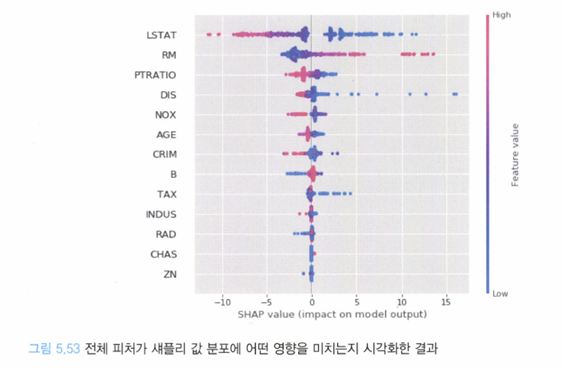
그림에서 보다시피 LSTAT과 RM, DIS가 분산이 크고, 붉은 점 또한 위 피처들에 많은 것을 보면 위 세개의 특성이 큰 역할을 하는 것을 알 수 있다. 물론 위와 같은 그림은 각 피처의 쓰임(예측에 미치는 영향도)을 표현하는 데 적합하지 않다고 느껴질 수 있다.
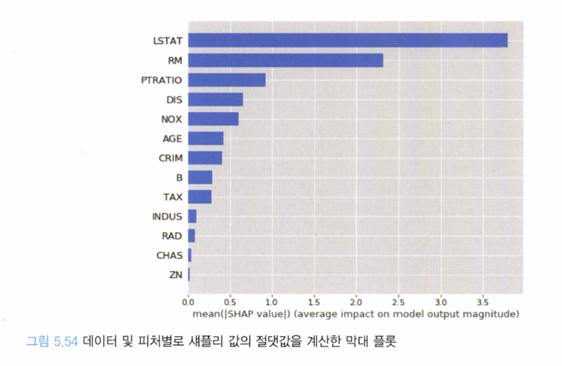
피처별로 섀플리 값을 살펴보면 LSTAT(저소득층 비율)이 집 값을 결정하는 데 가장 큰 요소인 것을 알 수 있다(인과관계는 뒤 바뀌었지만).
Ref
SHAP - in velog.io/@tobigs_xai
XAI, 설명 가능한 인공지능, 인공지능을 해부하다 (안재현. 2020)
