[Deep Learning] Convolutional Pose Estimation, 논문 리뷰
Deep Learning

논문 링크: https://arxiv.org/abs/1602.00134
Convolutional Pose Estimation, CPM 논문 리뷰
: Pose Estimation에 대해 공부하면서, 이 주제에 대해 처음 다루었던 논문이다. CV에 대해 Object Detection에 대해 조금 간보듯이 공부했던 터라, 처음에 봤을 때 이건 뭐지?! 싶었던 것 같다..
일단 정리한 논문 리뷰를 velog에 올려본다! 시간나면 다시 수정하지 않을까 싶다.
Abstract
용어 정리- part : 사람의 관절
- belief map(=heat map) : 이미지 내 한 픽셀이 part에 위치할 확률 → 각 part 당 1장씩 할당
- : confidence map을 출력하는 multi-class classifier
- : feature extraction function
-
confidence map에 동작시키는 convolutional networks를 기존 pose machine에서 추가하였고, 이로 인해 각 part 좌표를 탐지하는 성능이 좋아짐!
-
receptive field를 local 영역에서 global 영역으로 확대하여 다른 부위와의 관계를 고려함
Introduction

- 선행 연구인 Pose Machine에서 CNN을 추가해서 Pose Estimation을 진행함.
- 범위가 넓은 종속성을 가지는 변수들 사이, 포즈 추정과 같은 구조화된 예측 작업을 수행하는 모델을 모델링 하는데 기여함

-
Belief map: 사람 신체부위를 확률적 포인트로 표시하는 역할을 하는 plot
- Belief map이 이후 stage에 각 관절에 대한 공간불확정성에 대한 표현적인 비모수 encoding을 제공함
- 부분간의 관계의 이미지 의존 공간 모델을 학습할 수 있도록 함
-
그래픽 모델 스타일에 대한 추론 없이 구조화된 예측 작업을 위한 이미지 특징과 image-dependent spatial model을 위해 이전 stage의 brief map에서 convolutional network를 통해 task를 수행함.
-
Intermediate supervision(중간 관리자)을 통해 Vanishing Gradient를 일부 해결
- 기존에는 Classification 류에서만 해당 되던 것을 구조화된 예측 작업(Pose Estimation)으로 가져와서 해결한 것!
-
Receptive Field을 Local한 영역에서 Global한 영역으로 넓혀 전체적인 맥락을 파악해 Pose Estimation을 진행함
- 이전 단계에서 예측된 신체부위 좌표를 토대로 다시 예측을 하면 단계의 모호성을 줄일 수 있으므로 단계가 거듭될수록 정확도는 높아짐
Related Works
pictorial structures
Hierarchical models
Non-tree models
sequential prediction
convolutional architectures
Method
2.1 Pose Machines

x : image feature extractor for stage 1
g : classifier
x’ : feature extractor for stages (≥2)
b : belief maps
psi : converts belief maps into better features for next stage classifier
Part Location, = Classifier-Part predict
의 part에 대한 feature map
belief map을 feature map으로 바꾸는 함수
각 단계 에서 는 로 표시된 의 이미지에서 추출된 특징과 단계 의 각 주변 이웃의 이전 분류기의 상황 정보에 기초하여 각 부분 , 모두 에 위치를 할당하기 위한 belief를 예측함.
-
Stage 1
첫번째 단계에서, 의 classifier가 각 pixel에 대해 p번째 관절에 대한 확률값들을 plot으로 그린 belief map을 생성함.
- 각 part의 score
- 같이 각 파트마다 belief map이 구성되어있음
- 여기서 +1은 background, 배경을 의미
- 각 part의 score
-
Stage ≥ 2
이미지 데이터 특징과 선행 classifier에서의 context 정보를 가지고 belief를 예측,
번째 classifier가 각 pixel에 대해 번째 관절에 대한 확률값을 plot으로 그린 belief map을 생성함.
이때 ′와 를 참고하여 belief map을 생성함
- ′: stage1과 다른 feature map - 동일한 feature map을 사용하지 않도록 하기 위함!
- input을 각 stage에서 받음
- : 이전 belief map을 context feature로 mapping 해주는 함수
- stage ≥ 2부터는 input image와 belief map 받아옴
- ′: stage1과 다른 feature map - 동일한 feature map을 사용하지 않도록 하기 위함!
-
예측하는 classifier: Random forest
-
feature 매핑 함수: by hand-crafted
2.2 Convolutional Pose Machines
기존 Pose Machines에서는 예측(Random forest)과 특징 계산() 모듈이 지정되어 있었는데, CPM에서는 CNN 아키텍쳐를 사용해서 이미지 및 상황별 특징 표현을 데이터에서 직접 학습하도록 함.
CNN 아키텍쳐를 사용하기 때문에 end-to-end 학습이 가능해지는 장점도 얻을 수 있음.
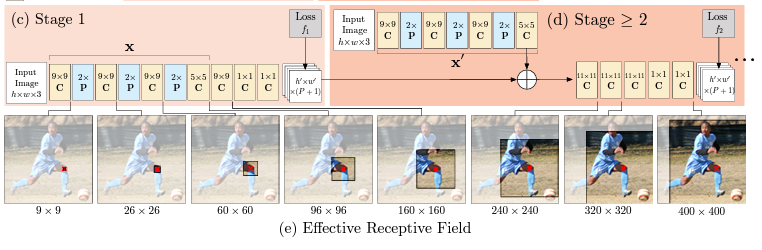
P - Pooling layer, C - Convolutional layer
-
stage 1
- 5개의 convolutional layer, 2개의 convolutional layer
- belief 예측을 오로지 local image evidence에서만 진행
- local: receptive field를 출력 픽셀 위치 주변의 작은 패치로만 제한 시켜둠
- small receptive field, examine locally
-
stage ≥ 2
- 동등한 receptive field를 계속 증가시킴
- large receptive field는 풀링층과 컨볼루션 층의 개수 증가로 만들 수 있음
- downscaled heatmaps
-
stage 1에서는 local 정보만을 활용하여 부정확하게 탐지함
→ stage를 지날 수록
receptive field가 넓어져 더 정확하게 관절을 인식함
이미지 특징 맵에 대해 유사한 구조 반복하여 Pose Machine 구조에 따라 공간 컨텍스트가 이미지 의존적이고, 오류 보정이 되는 모습을 확인.
정확도가 receptive field의 크기에 따라 향상됨을 확인함.
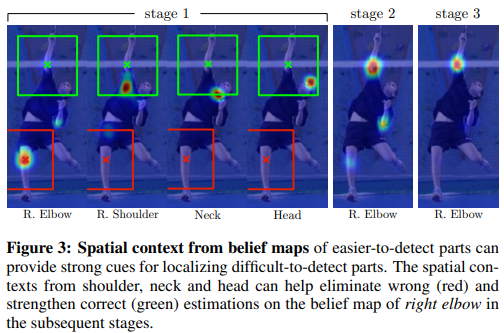 머리, 어깨, 목 같은 고정적인 부분은 검출이 잘 되는데, 팔, 다리 등 움직임이 많고 변화가 큰 부분은 검출이 어려움. 머리, 어깨, 목 같은 고정적인 부분은 검출이 잘 되는데, 팔, 다리 등 움직임이 많고 변화가 큰 부분은 검출이 어려움. | 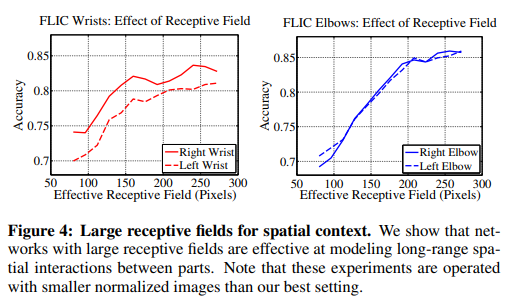 오른쪽으로 갈수록 accuracy 상승, 즉 receptive field가 넓을 수록 정확도가 높아진다는 것을 알 수 있음 오른쪽으로 갈수록 accuracy 상승, 즉 receptive field가 넓을 수록 정확도가 높아진다는 것을 알 수 있음 |
|---|
- (왼쪽) 파트 간의 'consistent geometry'가 있어서 고정적인 부분(오른쪽 어깨)이 변동적인 부분(오른쪽 팔꿈치) 검출하는 'cue'를 제공함.
- stage 1에서는 local 정보만을 활용하여 부정확하게 탐지함 → stage를 지날 수록 receptive field가 넓어져 더 정확하게 관절을 인식하게 됨!
Belief map에서 큰 receptive field은 먼거리의 공간적인 관계의 학습이나 정확도에 중요한 역할을 한다.
- Loss Function각 파트의 ground truth belief map과 추정한 belief map의 L2 norm를 손실함수로 설정!
-
합성 손실 함수
-
Experiments
3.1 Analysis
Vanishing Gradient는 중간 손실 함수로 각 단계의 기울기를 다시 채우기 때문에 문제가 해결됨.
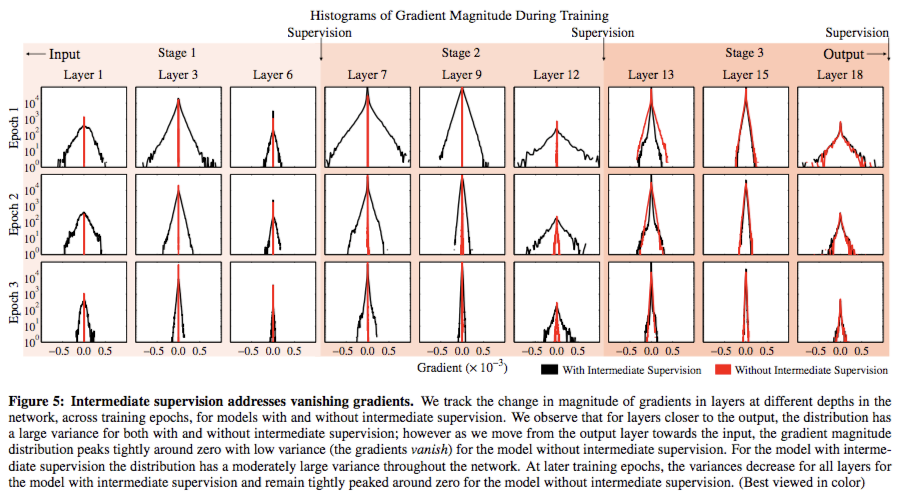
빨간색 그래프 - Intermediate Supervision이 없는 모델, 검은색 그래프 - Intermediate Supervision이 있는 모델
- 빨간색 그래프 폭은 매우 좁거나 0에 가까운 모습 - 기울기 소멸 문제로 학습이 중단된 것을 의미
- 초기 에포크에서 출력 레이어에서 입력 레이어로 이동할 때 중간 감독 없이 모델에 대해 관찰하면 기울기 분포가 소멸하기 때문에 0 주변에서 촘촘하게 최대화됨
- 검은색 그래프처럼 폭이 꽤 넓은 모습
- 기울기가 안정적으로 소멸하는 것으로 제대로 학습된 것을 의미!
- Intermediate Supervision 덕분에 모든 레이어에 걸쳐 훨씬 더 큰 분산을 가지고 있으며, 이는 학습이 실제로 Gredient가 모든 레이어에서 발생하고 있음을 시사함
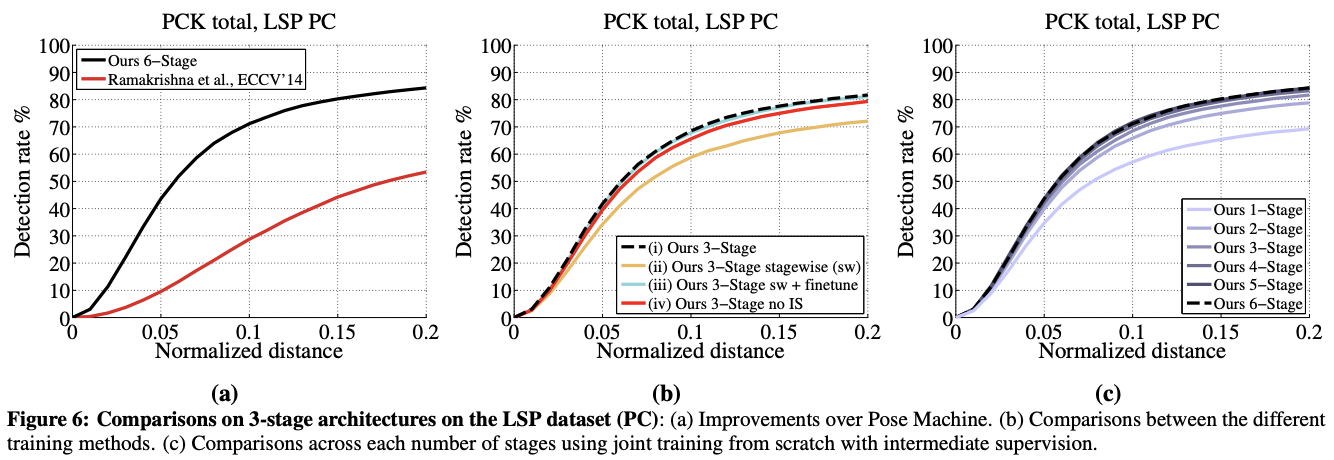
PCK: 특정 임계값보다 예측값과 True 사이 차이가 작다면 correct로 평가하여 맞춘 비율 계산
- end-to-end learning 이점 (Figure 6a)
- high precision regime(PCK@0.1)에서 이전 학습방식보다 42.4%,
- low precision regime(PCK@0.2)에서 이전 학습방식보다 30.9% 향상
- 훈련 계획에 대한 비교 (Figure 6b) 네트워크(i)가 다른 모든 훈련 방법보다 성능이 뛰어나고, 단계 간 Intermediate Supervision과 joint training이 실제로 좋은 성능을 달성하는 데 매우 중요하다는 것을 보여줌
- 단계별 성능 비교 (Figure 6c)
- 후속 단계의 예측 변수는 이전 단계의 맵에서 부품과 배경 간의 혼동을 해결하기 위해 큰 수용 분야의 상황 정보를 사용하므로, 5단계까지 성능이 단조적으로 증가함을 보여줌
- stage를 계속 쌓아서 정확도를 올리는 것에는 한계가 있음을 나타냄,
→ stage 6이 되었을 때 정확도가 감소하는 결과를 보임
3.2 Datasets and Quantitive Analysis
MPII Human Pose Dataset.
Leeds Sports Pose (LSP) Dataset.
- person-centric (PC) annotations
- Percentage Correct Keypoints (PCK) metric
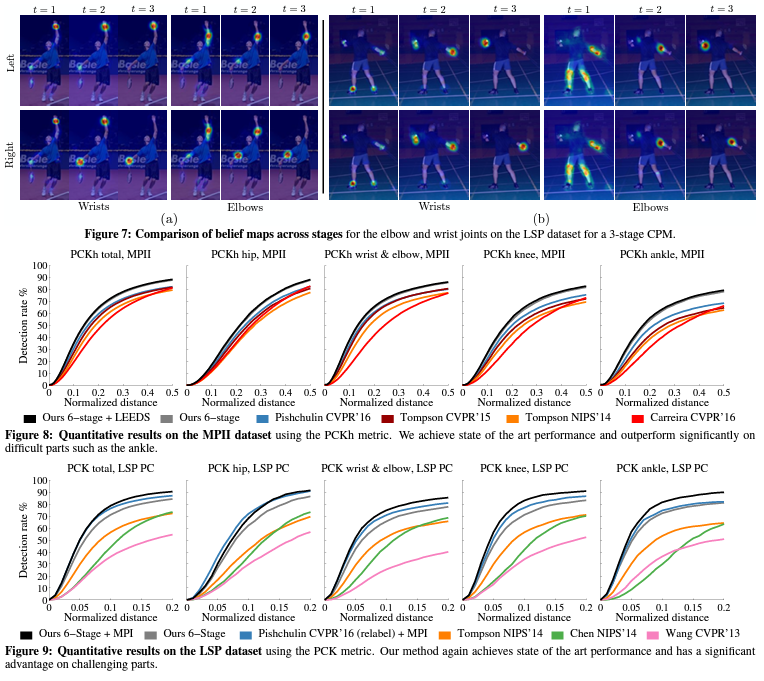
Conclusion
CPM, Convolutional Pose Machines
- 그래픽 모델 스타일 추론 없이 컴퓨터 비전에서 구조화된 예측 문제를 해결하기 위한 end-to-end 구조를 제공함
- convolutional networks 로 구성된 순차 구조가 단계 간에 점점 더 정제되는 uncertainty-preserving beliefs 을 전달함으로써 포즈를 위한 공간 모델을 암시적으로 학습할 수 있음
- 변수 간 공간 의존성 문제는 semantic image labeling, single image depth prediction, object detection 과 같은 여러 분야에서 발생하며 향후 작업에서는 이러한 문제로 구조를 확장할 것임
이 접근 방식은 모든 기본 벤치마크에서 최첨단 정확도를 달성하지만, 주로 여러 사람이 가까이 있을 때 실패 사례를 관찰함
⇒ single end-to-end 구조에서 여러 사람을 다루는 것도 어려운 문제이며 향후 작업을 위한 흥미로운 방법임
