
- 전체보기(182)
- 코테(19)
- 딥러닝(14)
- 자바(14)
- 알고리즘(14)
- 프로그래머스(13)
- JVM(9)
- 인공지능(7)
- 객체지향(7)
- Java(7)
- 인터페이스(6)
- 공식문서(5)
- 백준(5)
- 음악 딥러닝(5)
- 데이터 전처리(5)
- 스프링부트(5)
- 프로젝트(4)
- 수학(4)
- 교재(4)
- AI(4)
- DDD(3)
- 음악(3)
- NAS(3)
- TDD(3)
- 선형대수학(3)
- 책(3)
- 추상화(2)
- librosa(2)
- 최적화(2)
- 스프링(2)
- JPA(2)
- 네이버 클라우드(2)
- 개발(2)
- ncp(2)
- 책 리뷰(2)
- 배포(1)
- 테킷(1)
- http(1)
- 광주(1)
- di(1)
- 멋쟁이 사자처럼(1)
- 프레임워크(1)
- 멋쟁이사자처럼(1)
- 네이버(1)
- 13기(1)
- 머신러닝(1)
- SSAFY(1)
- Neural Architecture Search(1)
- 디자인패턴(1)
- 싸피(1)
- 코딩자율학습(1)
- 확률론적 머신러닝(1)
- 코딩테스트(1)
- 다형성(1)
- c언어(1)
- 디자인 패턴(1)
- IB(1)
- 인텔리제이(1)
- 경량화(1)
- Mel-spectrogram(1)
- 트러블 슈팅(1)
TDD를 부숴주마 - setup과 구현 부산물
assert문을 제외한 부분은 단위 테스트에서 setup이다.이 부분은 구현 부산물이라서 의미론적으론 테스트에서 중요하지 않다.하지만 테스트를 작성 할 때 신경써야하는 부분이 setup 과정이다.흔히 말하는 flaky test의 경우 setup 과정의 문제이기 때문에
TDD를 부숴주마 - 테스트와 TDD에 대한 오해
벨로그에서 글을 쓰기 전에 인기글을 읽는 편이다. 근데 회고를 보는데 TDD 얘기가 있더라.개발 블로그 글 볼 때 TDD는 진짜 하루에 한 번씩은 보는 것 같다.그때마다 열 받는다. 오늘도 벨로그 글은 안 쓰려고 했는데 TDD 글을 봐서 열 받아서 쓴다.테스트 목적은
TDD를 부숴주마 - 어떻게 테스트 하는가?
테스트는 “구현체”가 아니라 계약(인터페이스) 을 검증한다.그래서 계약만 잘 정의되어 있으면 구현체가 아직 없어도 테스트를 먼저 만들 수 있다.관계는 이렇다.인터페이스(계약) --- 테스트(검증서)인터페이스(계약) --- 구현체(실제 동작)즉, 테스트는 구현체가 아니라
TDD를 부숴주마 - 무엇을 테스트 하는가?
무엇을 테스트 할 지 모르기 때문이다.무엇을 테스트 할 지 모르기 때문에 TDD가 유행했다고 생각한다.TDD는 레드-그린-리팩토링과 같은 잘못된 방법을 설파한다.Red (실패): 구현하고자 하는 기능의 테스트 코드를 먼저 작성한다. 테스트는 실패해야 한다.Green (
TDD를 부숴주마 - 이 모든것은 인터페이스 때문이다
원래는 차근차근 빌드업 쌓고 결론을 뒤에 박으려고 했다.근데 그냥 시작할 때 박아두고, 시리즈 내내 반복해서 때리기로 했다.테스트는 계약을 검증하는 살아있는 검증문서이다.이 한 줄만 제대로 이해하면, TDD가 왜 그렇게까지 신성시될 필요가 없는지 바로 보인다.테스트 작
TDD를 부숴주마 - 개요
유튜브나 인터넷에 TDD 자료를 보다가 열 받아서 만들었다TDD는 구리다, 왜 구린지 시리즈에서 설명하고 테스트의 목적TDD의 올바른 해석, 내가 생각하는 좋은 테스트 순서대로 연재하겠다.시리즈 초반엔 테스트와 관계 없어 보이는 내용이 포함되는데 인내심을 가지고 시리즈
1. 저작권을 설정하자
당연히 오픈소스 프레임워크를 만드는데 저작권이 중요하다.나는 인간을 믿지 않으며 인간은 짐승과 같다는 생각을 하기 때문에 저작권도 방어적으로 초반에 설정할 것이다.Apache-2.0 license는 절충안이다. MIT license는 전부 여는것이기 때문에 오픈소스 그
0. 들어가기
내 생각엔 개발자는 각자의 철학을 가져야한다.개발을 공부하며 요구사항, 계약, 객체지향이 중요하다고 생각하게 되었다.이 세계관을 가지고 있기 때문에 모든 코드엔 내 철학이 묻게 되었다.어떤 세계관을 가지고 있는지는 저번 시리즈를 통해서 밝혔으니 참고바란다.https&#
객체지향 해석(7) - DI는 별거없다
요구사항, 계약, 메시지 객체지향을 설명하면서 강조했던 세 가지이다. 세 가지가 독립적인 게 아니고 유기적으로 연결되어 있다는 걸 이제는 잘 알 것이다. 이 글 시리즈의 내용 또한 세 가지의 유기적인 흐름을 그대로 보여주었을 뿐이다. 인터페이스와 다형성은 그냥 갈아
객체지향 해석(6) - 인터페이스, 다형성? 그냥 갈아 끼우기
나는 파인만을 좋아한다. 물리학과를 나오면 파인만의 빨간책이란 걸 읽는데 읽다보면 그의 전기도 읽는게 보통이다. 파인말 왈 쉽게 표현하면 되는데 뭐하러 어렵게 표현하나.그래서 파인만은 이론도 그림으로 다이어그램 만들어서 노벨상탐아무튼 내가 하고 싶은 말은 객체지향 설명
객체지향 해석(5) - 추상화??
추상화?? 추상화를 대표하는 학문은 수학이다. 수학의 추상화는 정말 어렵다. 수학의 추상화를 즐길 수 있다면 그게 수학 재능이다. 수학의 추상화가 너무 악명이 높기 때문에 프로그래밍의 추상화 또한 어려울 것이라고 생각한다. 수학의 추상화와 프로그래밍의 추상화는 같다
객체지향 해석(4) - 계약과 TDD
보통 TDD는 다음과 같은 절차를 가진다.RED: 실패하는 테스트 코드를 먼저 작성한다.GREEN: 테스트 코드를 성공시키기 위한 실제 코드를 작성한다.BLUE: 중복 코드제거, 일반화등의 리팩터링을 실행한다.내가 TDD를 싫어하는 이유다.하지만 나는 TDD를 사랑한다
객체지향 해석(2) - 요구사항과 계약
개인적으로 소프트웨어에서 중요하다고 생각하는건 돈을 버는 것이라고 생각한다.사용자든 고객이든 만족시켜서 돈을 버는것이 중요하므로 소프트웨어에서 가장 중요한 건 요구사항을 이끌어내고 만족시키는 것이다.요구사항과 객체지향은 아주 근접해있다. 사실 소프트웨어의 거의 모든 것
객체지향 해석(1) - 분업
보통 컴퓨터의 역사에서 절차지향과 객체지향이 나온 동기를 이해하며 객체지향을 배운다.나는 이런 기본이 부족하기 때문에 내 식대로 객체지향을 해석할 것이다.나의 사상은 이렇다. 소프트웨어는 순수하게 사람이 만든 것이기 때문에 소프트웨어의 모든 것엔 의도가 존재한다. 나의
음악 분류 딥러닝을 만들자(42) - Bayesian, gaussian, VAE 등을 위한 사전 준비
이제 적용할 기법은 bayesian, guassian, MCMC, VAE, Diffusion등 확률론과 관련된 기법들을 적용할 것이다.이 모든 기법은 베이지안 통계학을 기초로 하고 있어서 베이지안에 대한 내용을 학습해야한다.이미 2020년 정도에 BANANAS란 경량화

13기 싸피 인터뷰에서 썰 풀다 합격한 썰 푼다
introduction 이래저래 벨로그 감성으로 썰 푸는건 못해서 글이 건조할 것 같다 내가 나름대로 세운 전략이 정확히 들어 맞았고 면접을 찟었기(?) 때문에 내 전략이 다음 기수 지원자들에게 도움이 됐으면 하는 바람으로 글을 적는다 참고로 비전공자다 상황 이

kevin p murphy의 probabilistic machine learning advanced topics 리뷰
책 링크 https://probml.github.io/pml-book/ 케빈 머피의 책은 크게 2가지 버전이 있다. “Probabilistic Machine Learning: An Introduction”과 “Probabilistic Machine Learning:
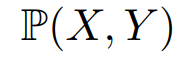
음악 분류 딥러닝을 만들자(41) - Predicting Neural Network Accuracy from Weights 논문 리뷰, accuracy, latency predictor
CNN 모델의 성능 평가 학습된 CNN의 모델 평가는 다양한 지표로 이루어지며 가장 직관적으로 사용되는 지표는 accuracy다. 딥러닝을 처음 배울 땐 accuracy, f1 score, precision, recall 이 4개를 평가지표로 배우고 accuracy

*음악 분류 딥러닝을 만들자(40) - evolution Nas
굉장히 주관적인 리뷰 사실 once-for-all 논문의 방법론에 Regularized Evolution for Image Classifier Architecture Search란 논문의 evolution nas를 이용했다고 해서 살펴보았다. 논문이나 글 들을 보면