시작하며
배우면 배울수록 통계학은 정말 어렵지만 그럼에도 재미가 느껴지는 묘한 매력이 있는 것 같다.
모평균 검정
- 단일표본 t-검정
- 검정통계량
- 모분산을 알면(표준정규분포)
- 모분산을 모르면(대체로 사용)
- 검정통계량
- 대응표본 t-검정
- 검정통계량
- 모분산을 알면(표준정규분포)
- 모분산을 모르면(대체로 사용)
- 검정통계량
두 집단의 분포 비교
sns.kdeplot(data=df1, x='before', label='Before')
sns.kdeplot(data=df1, x='after', label='After')
plt.axvline(x=df1['before'].mean(), color='blue', linestyle='-')
plt.axvline(x=df1['after'].mean(), color='orange', linestyle='--')
plt.legend()
plt.show()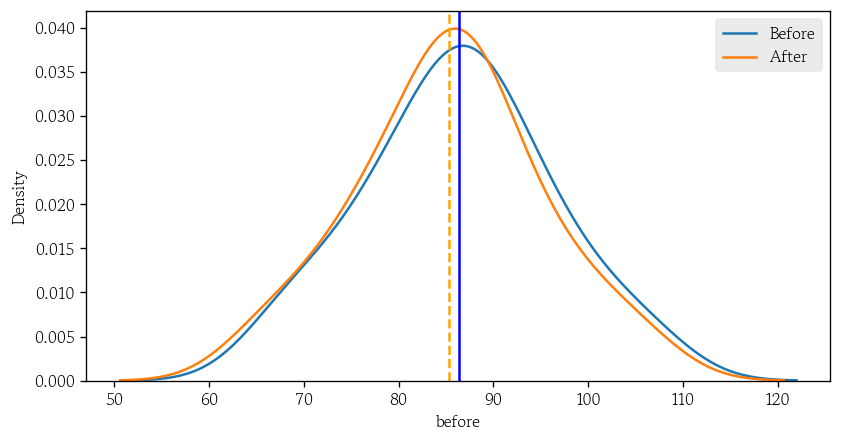
단일표본 t-검정
ttesty 매개변수에 하나의 값을 지정하면 단일표본 t-검정 실행
alternative- 기본값 : 양측검정
- 단측검정 : less(작다)
- 단측검정 : greater(크다)
- 정규성 검정
pg.normality(df1['before'])
# W pval normal
# before 0.985883 0.951249 True- 양측검정
pg.ttest(x=df1['before'], y=90)
- 단측검정
pg.ttest(x=df1['before'], y=90, alternative='less')
대응표본 t-검정
ttestpaired매개변수에 True 지정 시 대응표본 t-검정 실행
- 정규성 검정
pg.normality(df1['after'])
# W pval normal
# after 0.985143 0.9396 True- 양측검정
pg.ttest(x=df1['before'], y=df1['after'], paired=True)
- 단측검정
pg.ttest(x=df1['before'], y=df1['after'], paired=True, alternative='greater')
분산분석
- 세 개 이상의 집단 간 평균이 같은지 여부를 확인할 때 실행
- 일원배치 분산분석은 하나의 요인에 속한 수준별 변동을 이용
- 요인에 속한 모든 수준의 결합을 처리하고 함
- 요인의 수준이 2개일 때, 분산분석과 t-검정 실행 결과가 같음
- 요인의 수준이 3개 이상일 때, t-검정을 여러 번 실행한 결과와 다름
- 사후검정으로 확인
분산분석 자료구조
- 요인
- 요인에 따른 값(처리) =
- 요인별 값( = 행 번호) =
- 처리별 수준 평균 =
- 전체 평균 =
- 총변동 =
- 집단 간 변동 =
- 요인으로 설명 가능
- 집단 내 변동 =
- 요인으로 설명 불가능
분산분석표
- 관측값 는 번째 수준의 평균()과 오차()의 합으로 표현 가능
- 총변동은 수준으로 설명 가능한 부분과 설명 불가능한 부분의 합계
- 총변동(SST) :
- 설명할 수 있는 부분(SSR) :
- 설명할 수 없는 부분(SSE) :
평균 제곱합(MS)
F-통계량
분산분석의 가정
- 독립성, 정규성, 등분산성 가정을 만족하야 함
- 정규성 가정은 사피로-윌크 검정 실행
- 정규성 가정을 만족하지 못하면 크루스칼-왈리스 순위합 검정 실행
- 등분산성 가정은 레벤 검정을 실행
- 등분산 가정 =
pg.anova - 이분산 가정 =
pg.welch_anova
- 등분산 가정 =
세 집단의 기술통계량 확인
pvt = pd.pivot_table(
data=df, values='Price', index='FuelType',
aggfunc=['count', 'mean', 'std']
)
pvt.columns = pvt.columns.droplevel(1)
pvt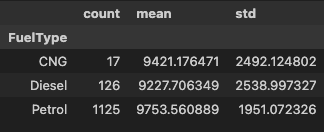
- 정규성 검정
pg.normality(data=df, dv='Price', group='FuelType')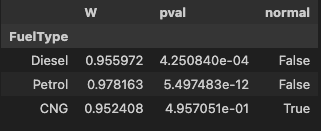
- 등분산성 검정
pg.homoscedasticity(data=df, dv='Price', group='FuelType')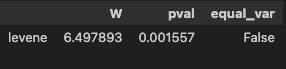
- 분산분석
pg.welch_anova(data=df, dv='Price', between='FuelType')
- 비모수 검정
pg.kruskal(data=df, dv='Price', between='FuelType')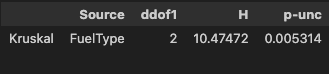
검정을 반복하면 안 되는 이유
- 같은 데이터로 검정을 반복하면 적어도 하나의 가설에서 제 1종 오류가 발생할 가능성이 증가
- 검정을 n번 반복하면 개별 검정에서 1종 오류가 발생하지 않을 확률(신뢰수준)을 n번 곱한 값으로 감소
- 으로 증가
사후검정(다중비교)
import scikit_posthocs as spTukeyHSD- 집단 개수가 6 이상일수록 선호
- 모든 집단의 차이를 비교
sp.posthoc_tukey(a=df, val_col='Price', group_col='FuelType')Scheffe- HDS보다 검정력이 낮음
- 복잡한 비교에서는 HDS보다 검정력이 높음
sp.posthoc_scheffe(a=df, val_col='Price', group_col='FuelType')Dunnett- 하나의 대조군을 다양한 실험군과 비교 결과를 제시
Tamhane’s T2- 등분산을 가정하지 않는 경우에 사용하는 방식
sp.posthoc_tamhane(a=df, val_col='Price', group_col='FuelType')Nemenyi: 비모수- 순위 데이터를 사용하는 크루스칼-왈리스 검정 이후에 사용하는 방식
sp.posthoc_nemenyi(a=df, val_col='Price', group_col='FuelType')카이제곱 검정(교차분석)
- 입력변수의 범주별 목표변수 실제값과 기대값 차이가 클수록 카이제곱 통계량이 커짐
- 카이제곱 통계량이 커질수록 유의확률은 감소
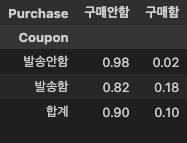
pd.crosstab(
index=df2['Coupon'],
columns=df2['Purchase'],
margins=True,
margins_name='합계',
normalize='index'
)
pg.chi2_independencecorrection: 연속형 보정 적용 여부 지정
- 교차분석 결과 기대값 행렬, 관측값 행렬 및 카이제곱 검정 결과를 원소로 갖는 튜플
test = pg.chi2_independence(data=df2, x='Coupon', y='Purchase', correction=True)
test[2]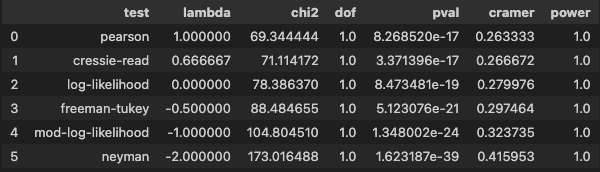
피셔의 정확검정
- 표본 개수가 매우 적거나 교차테이블에서 기대도수가 5미만인 값이 존재 → 카이제곱 분포로의 근사가 부정확하여 신뢰하기 어려움 → 피셔의 정확검정 실행
모비율 검정
from statsmodels.stats.proportion import proportions_ztestproportions_ztest(count=30, nobs=1000, value=0.02)
# (np.float64(1.8537599944001615), np.float64(0.06377350427039058))- 모비율 차이 검정
proportions_ztest(count=[30, 45], nobs=[1000, 1500], value=0.0)
# (np.float64(0.0), np.float64(1.0))선형 회귀
통계기반과 머신러닝의 차이
- 통계기반모형 : 관계 해석용(설명)
- Fitting(적합)
- 머신러닝모델 : 예측용(성능)
- Training(훈련, 학습)
선형 회귀의 개요
- 입력변수와 목표변수 간의 관계를 정량적으로 분석하기에 적합한 모형
- 회귀식 :
- : 잔차
- : y절편(특별한 경우가 아니면 꼭 추가할 것)
- : 다른 입력변수를 고정한 상태에서 입력변수가 1단위 증가할 때 목표변수에 미치는 크기
- 결정계수() : 목표변수의 변동을 설명할 수 있는 크기
- 단순 선형 회귀일 때,
선형 회귀의 기본 가정
- 목표변수와 입력변수는 직선의 관계(상관관계)를 가져야 함
- 산점도로 확인
- 피어슨 상관분석을 실행하여 확인
- 잔차 산점도를 그려 잔차 패턴 확인
- 입력변수끼리 강한 상관관계가 없어야 함
- 다른 입력변수에 종속된 입력변수는 다중공선성 문제를 일으키는 변수
- 목표변수에 대한 설명력을 다른 입력변수와 나누어 가짐
- 회귀계수의 설명력이 낮아져 문제 변수를 일부 제거해야 함 → 예측력 감소(머신러닝에서는 다중공선성 취급X)
선형 회귀 모형 진단 : 잔차 가정
- 잔차는 평균이 0이고 표준편차가 인 정규분포를 가정 - 정규성
- 모든 입력변수 값에서 동일한 분산을 가짐 - 등분산성
- 잔차는 서로 독립이어야 하므로 자기 상관이 없어야 함 - 독립성
- 잔차의 산점도를 그렸을 때 일정한 패턴이 없어야 함 - 잔차의 패턴
선형 회귀직선은 입력변수의 전체 영역에서 목표변수와의 관계를 설명하는 유일한 직선(Global Model)
이상치(영향점)가 있으면 전체 관계를 왜곡시킬 수 있으므로 영향 여부를 판단
선형 회귀 프로세스
탐색적 데이터 분석 → 목표-입력변수 관계 확인 → 회귀계수 추정(최소제곱법)
→ 유의성 검정(모형(분산분석), 계수(t-검정)) → 회귀진단(그래프, 검정) → 다중공선성 해결(VIF)
범주형 입력변수의 더미 변수 변환
- 범주형 → 수치형
- 명목형 : 원-핫 인코딩, 더미변수
- 서열형 : 오디널 인코딩
- 타겟 인코딩
pd.get_dummiesdata매개변수에
- 시리즈 → 더미 변수 변환
sr1 = pd.Series(data=['A', 'B', 'O', 'AB'])
pd.get_dummies(data=sr1, dtype=int, drop_first=True)
# AB B O
# 0 0 0 0
# 1 0 1 0
# 2 0 0 1
# 3 1 0 0- 데이터프레임 → 더미 변수 변환
df = pd.get_dummies(data=df, dtype=int, drop_first=True, prefix='', prefix_sep='')
df.head()
# Price Age KM HP MetColor Doors Weight Petrol
# 0 13500 23 46986 90 1 3 1165 0
# 1 13750 23 72937 90 1 3 1165 0
# 2 13950 24 41711 90 1 3 1165 0
# 3 14950 26 48000 90 0 3 1165 0
# 4 13750 30 38500 90 0 3 1170 0입력변수 행렬과 목표변수 벡터로 분리
yvar = 'Price'
X = df.drop(columns=yvar)
y = df[yvar].copy()
display(X)
display(y)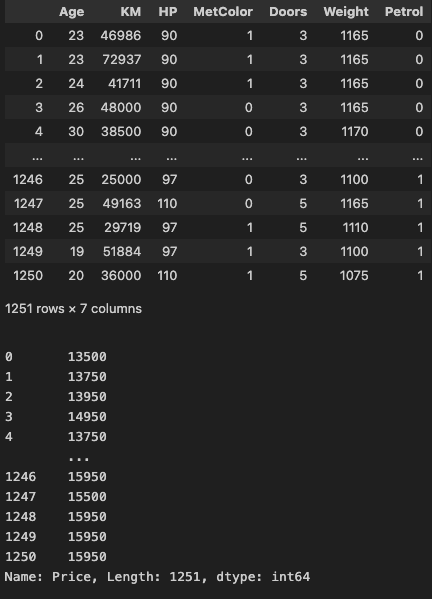
선형 회귀계수 추정 : 최소제곱법
- 회귀직선의 y절편과 기울기는 실제 목표변수 값과 모형이 추정한 값 간 오차를 최소화하도록 추정된 파라미터
- 입력변수가 1개인 단순 선형 회귀 모형
- 잔차 제곱합에 위 공식을 적용한 목적함수를 최소로 하는 회귀계수를 추정
- 위 식에서 미지수인 와 으로 편미분한 방정식 풀기
- 으로 편미분 방정식을 풀면 = y의 평균
- 으로 편미분 방정식을 풀면 기울기
선형 회귀 모형의 분산분석표
- 총변동은 회귀 모형으로 설명 가능한 회귀 제곱합과 설명 불가능한 잔차 제곱합의 합계
- 총변동(SST) :
- 회귀 제곱합(SSR) :
- 잔차 제곱합(SSE) :
평균 제곱합(MS)
F-통계량
선형 회귀 모형의 유의성 검정
- 회귀 모형이 의미를 가지려면 최소 한 개 이상의 회귀계수는 0이 아니어야 함
- 만약 모든 회귀계수가 0이면 입력변수의 값에 따라 목표변수의 추정값이 바뀌지 않으며 항상 목표변수의 평균을 반환
- 회귀 모형의 유의성 검정은 분산분석 결과로 확인
F-통계량의 유의확률 ≥ 유의수준 0.05
관측값 늘리기, 더 적절한 변수 추가 등 전처리 과정 수행
선형 회귀계수의 유의성 검정
- 회귀 모형에서 어떤 입력변수가 의미를 가지려면 회귀계수가 0이 아니어야 함
- 회귀계수의 유의성 검정은 t-검정 결과로 확인
결정계수
- 선형 회귀 모형의 적합도를 나타내는 지표
- 결정계수는 0~1의 값을 기지며 1에 가까울수록 적합도가 좋은 모형
- 단순 선형 회귀 모형의 결정계수는 입력변수와 목표변수 간 피어슨 상관계수의 제곱과 같음
- 입력변수와 목표변수 간 강한 상관관계를 가질수록 결정계수는 크게 증가
조정된 결정계수
- 선형 회귀 모형의 결정계수는 입력변수의 개수가 많아질수록 계속 증가(단조증가)
- 최적의 모형을 선택하는 기준으로 사용X
- 조정된 결정계수는 입력변수의 개루로 벌점을 부여
- : 행(관측값) 개수
- : 열(입력변수) 개수
- 0~1의 값을 가지며 분수 부분이 0에 수렴하면 1에 가까워짐
- 목표변수와 상관계수가 큰 입력변수를 추가하면 결정계수로 인해 분자가 감소
- 상관계수가 적거나 없는 입력변수를 추가하면 결정계수가 증가하지 않음
- 분자는 고정이나 분모가 감소
- 조정된 결정계수는 감소
선형 회귀 모형 적합 함수
statsmodels.api.OLSendog: 목표변수(내생변수)를 지정exog: 입력변수(외생변수)를 지정- 입력변수 행렬에 상수 1을 추가해야 함( )
model = hds.stat.ols(y=y, X=X)
model.summary()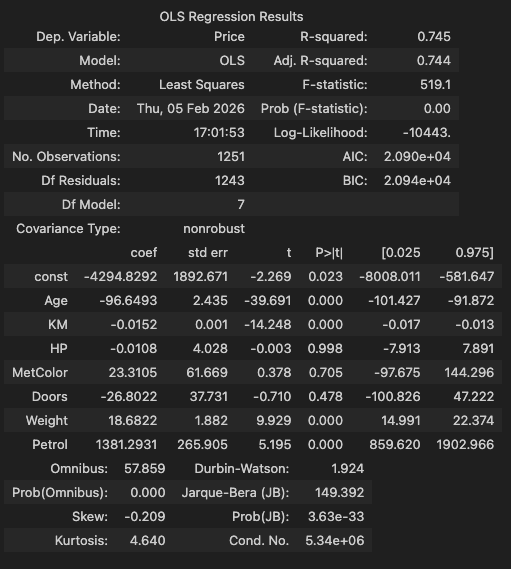
모형 요약 정보 확인
1. F-stat 의 P-val < 0.05 (1개)
2. t-stat 의 P-val < 0.05 (p개)
3. , AIC, BIC
회귀진단 : 잔차 그래프
- 선형성 : 추정값과 잔차의 산점도에서 빨간색 직선의 패턴이 없는지 확인
- 정규성 : Normal Q-Q 그래프에서 모든 점이 45도 점선 위에 있는지 확인
- 등분산성 : 추정값과 표준화 잔차 제곱근의 산점도에서 두께가 일정해야 함
- 두께가 일정하지 않으면 등분산성 가정을 만족X
- 영향점 진단 : 쿡의 거리가 4/n을 초과하면 영향점으로 의심
- 특정 관측치가 전체 회귀식에 미치는 영향력을 종합적으로 나타내는 지표
hds.stat.regressionDiagnosis(model=model)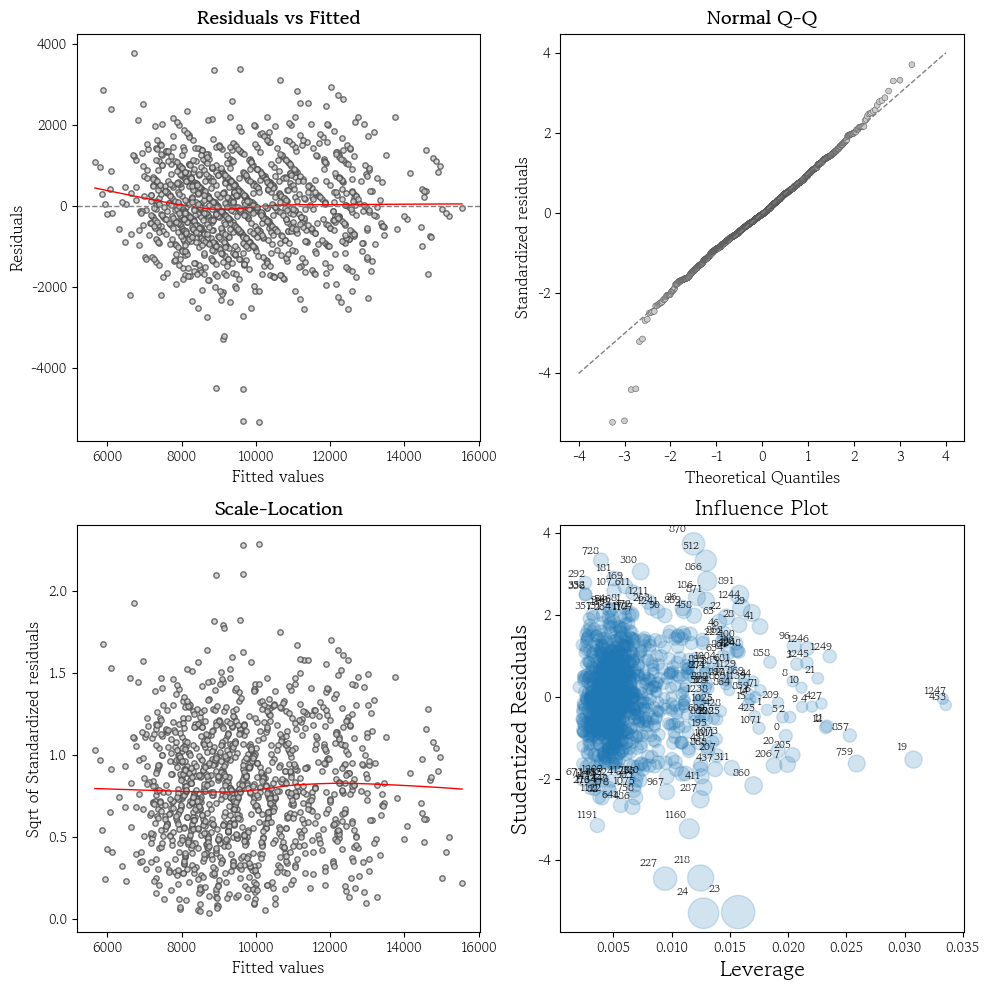
잔차의 분포 확인
rnorm_resid = stats.norm.rvs(loc=0, scale=model.resid.std(), size=10000, random_state=1)sns.kdeplot(x=model.resid, color='0', fill=True)
sns.kdeplot(x=rnorm_resid, color='red', fill=True)
plt.axvline(x=0, color='0.5', linestyle='--')
plt.show()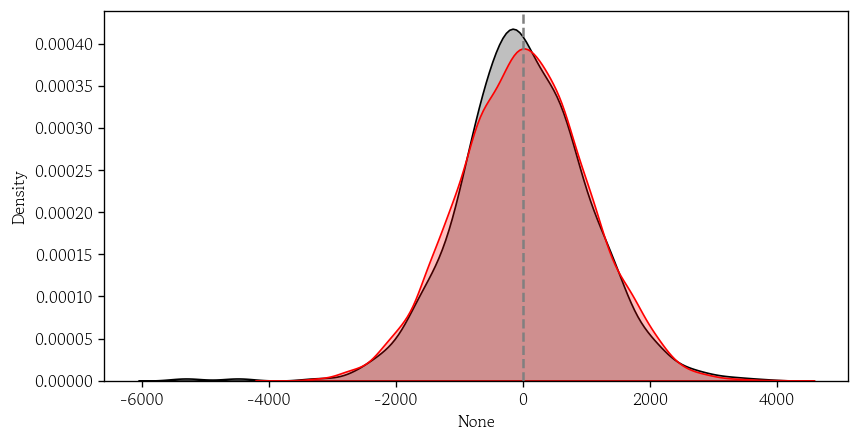
회귀진단 : 잔차 가정 확인
- 잔차의 정규성 및 독립성 가정 확인

Omnibus: 0에 가까우면 정규분포한다고 판단Prob(Omnibus)= P-val
- 왜도(Skew) : -2 ~ 2 사이면 정규분포한다고 판단
- 첨도(Kurtosis) : 1 ~ 5 사이면 정규분포한다고 판단
Durbin-Watson: 2에 가까울수록 자기상관이 없다고 판단- 1~4 사이의 값을 가짐
- 유의확률 확인X
Jarque-Bera: 유의확률이 작으면 정규성 가정 기각Condition Number: 값이 클수록 다중공선성 의심Breush-Pagan: 잔차의 등분산성 가정을 검정- 유의확률이 유의수준보다 커야함
hds.stat.breushpagan(model=model)
# Statistic P-Value F-Value F P-Value
# 0 69.137164 2.206962e-12 10.387656 1.014454e-12잔차의 독립성 검정
- 잔차의 독립성 가정은 잔치끼리 상관관계가 없어야 한다는 것을 의미
- 독립성 문제 시 시계열 자료로 판단
마치며
워낙 어려운 내용들이라 꾸준한 복습이 필요하지만 이번 주는 자격증 공부로 인해 자격증 시험에 나오는 내용들 정도만 복습을 하고 있어서 토요일에 시험이 끝나면 처음부터 단계별로 정리를 해볼 생각이다.

Hello I'm TaeHyunAn, Currently Studying Data Analysis