시작하며
오늘부터 시계열 데이터 파트가 시작되었다. 오늘은 시계열 예측에 앞서 시계열 데이터에 대해서 배우고 데이터 자체를 다뤄보는 시간을 가졌다.
시계열 데이터의 이해
시계열 데이터 개요
- 시계열 데이터 : 시간의 흐름에 따라 순차적으로 관측된 데이터
- 관측값이 독립적이지 않고, 이전 시점 값과 밀접한 관계를 가짐
- 시계열 데이터 분석에서는 시간 순서가 매우 중요한 의미를 갖음
- 데이터의 순서를 임의로 섞거나 무작위로 분할하면 데이터의 구조가 깨져 결과에 오류가 포함되거나 성능이 과대평가될 수 있음
- 모든 분석 과정은 시간 순서를 유지하는 것을 전제로 진행
시계열 데이터의 특징
- 시계열 데이터는 일반적으로 추세, 계절성, 불규칙성으로 구성
- 추세 : 장기적으로 증가하거나 감소하는 방향성
- 계절성 : 일정한 주기를 가지고
- 불규칙성(변동성, 잡음) : 설명되지 않는 랜덤한 변동
- 시계열 데이터의 구조(시간 간격, 결측, 자기상관 등)를 파악하는 것이 중요
시계열 데이터의 구성 요소
| 구분 | 상세 내용 |
|---|---|
| 추세 | • 단기적 변동과 구분되는 개념으로, 데이터 전체를 관통하는 방향성을 나타냄 • 추세를 고려하지 않으면 단기 변동을 과대해석하거나 전체 흐름을 잘못 이해할 위험이 있음 |
| 계절성 | • 일정한 주기를 두고 유사한 패턴이 반복되는 현상을 의미 • 평일/주말 소비 차이, 계절별 에너지 사용량 차이 등이 대표적 • 이를 고려하지 않으면 반복 패턴을 이상치로 오해할 수 있음 |
| 불규칙성 | • 정책 변화, 사회적 사건, 외부 요인 등 예측하기 어려운 우연적 변동을 의미 • 이러한 불규칙성은 시계열 예측 문제를 더욱 복잡하게 만드는 주요 요인 |
| 비정상성 | • 데이터의 통계적 성질(평균, 분산 등)이 시간에 따라 변하는 경우를 의미 • 통계 기반 시계열 모형을 적용하기 전에 반드시 점검하고 해결해야 할 핵심 개념 |
계절성 예시
| 구분 | 상세 내용 |
|---|---|
| 일간 | • 전력 사용량, 대중교통 이용량, 도로 교통량, 카페 매출, 주식 거래량 등 |
| 주간 | • 음식 배달 주문, 영화관 관객 수, 소매 매출, 병원 외래 환자 수, 택배 발송량 등 |
| 월간 | • 각종 공과금(세금, 보험료, 통신요금 등) 납부 금액, 기업 예산 집행 금액 등 |
| 연간 | • 여름/겨울 냉난방 사용료, 기상, 패션 의류 판매량, 여행(호텔, 항공권) 수요 등 |
횡단면 데이터
- 횡단면 데이터 : 동일 시점(구간)에 여러 개체를 동시에 관측하는 것
- 개별 샘플의 순서를 섞어도 분석 결과에 큰 영향을 주지 않는 경우가 많음
시계열 예측 문제 정의
- 시계열 예측 문제는 미래 값을 맞추는 것이 아니라 과거 데이터로부터 이후 시점의 값을 합리적으로 추정하는 문제
- 예측 시점 기준으로 어떤 정보를 이용할 수 있는지를 명확히 정의하는 것이 중요
- 모형에 입력되는 변수는 반드시 예측 시점 이전에 관측된 값으로 구성
- 시간 축을 기준으로 한 정보의 가용 범위를 정의하는 문제
- 시간의 흐름을 유지한 상태에서 학습 데이터와 검증 데이터를 구분
시계열 데이터 분석의 핵심 원칙
- 시계열 데이터 분석에서 가장 흔하게 발생하는 오류는 시간의 흐름을 고려하지 않는 것
- 예측하는 해당 시점 이후에 관측된 데이터를 학습 또는 예측 과정에 포함 → 예측 시점에서는 알 수 없는 정보를 미리 사용하는 문제 발생 → 데이터 누수
- 시차 변수, 이동 통계량과 같은 파생 변수를 생성할 때 계산 시점을 엄격하게 관리
- 예측하는 해당 시점 이후에 관측된 데이터를 학습 또는 예측 과정에 포함 → 예측 시점에서는 알 수 없는 정보를 미리 사용하는 문제 발생 → 데이터 누수
시계열 데이터 분석 프로세스
- 문제 정의 및 목표 설정
- 시계열 데이터의 구조 이해
- 시간 순서와 연속성 확인
- 데이터 누수 방지
- 시계열 데이터 전처리
- 예측 모형 적용
시계열 데이터 분석 프로세스 상세 내용
| 구분 | 상세 내용 |
|---|---|
| 문제 정의 및 목표 설정 | • 특정 시점의 값을 예측할 것인지, 향후 일정 기간의 평균이나 누적 값을 예측할 것인지, 또는 특정 이벤트 발생 여부를 판단하는 분류 문제나 이상 탐지 문제로 확장 가능 • 예측 시점과 활용 목적을 사전에 명확히 설정하지 않으면 모형을 적합하는 과정 전체가 흔들릴 수 있으므로 가장 중요한 단계라 할 수 있음 |
| 시계열 데이터의 구조 이해 | • 시간 변수의 형식을 확인하고, 적절한 날짜시간 형태로 변환하여 데이터의 시간 단위와 간격이 일정한지 여부를 파악 • 예측 대상 변수와 함께 활용 가능한 외생변수의 존재 여부를 확인하고 데이터에 포함된 추세, 계절성, 불확실성 등을 탐색 |
| 시간 순서와 연속성 확인 | • 데이터가 시간 기준으로 올바르게 정렬되어 있는지 확인하고, 누락된 시점이 존재하는지 점검 • 필요에 따라 리샘플링을 수행하거나 결측값을 보완해야 하며, 이 과정에서 미래 정보를 사용하지 않도록 주의 |
| 데이터 누수 방지 | • 시계열 데이터는 반드시 특정 시간 기준으로 학습 데이터와 검증 데이터를 분리해야 하며, 과거 데이터를 기반으로 특성을 생성 • 시차 변수나 이동 평균을 생성할 때 미래 시점의 정보가 포함되지 않도록 주의해야 하며, 표준화/정규화 등은 학습 데이터 기준으로만 수행 |
| 시계열 데이터 전처리 | • 결측값은 이전 시점 값이나 보관법 등으로 처리하고, 이상치는 통계적 기준을 활용하여 제거하거나 보정 • 필요에 따라 로그 변환이나 차분을 통해 데이터의 안정성을 확보하고, 시차 변수, 이동 통계량, 날짜 기반 파생 변수 등을 생성하여 모형이 패턴을 학습할 수 있도록 함 |
| 예측 모형 적용 | • ARIMA, SARIMA, Prophet과 같은 통계 기반 모델부터, XGBoost, LightGBM과 같은 머신러닝 모델을 활용하며, 필요에 따라 RNN이나 LSTM과 같은 딥러닝 모델도 적용할 수 있음 • 모델의 성능을 평가할 때 일반적인 랜덤 분할이 아닌 시간 순서를 유지하는 방식의 검증을 사용해야 하며, 예측 목적에 맞는 평가 지표를 선택하는 것이 중요 |
시계열 예측의 활용
- 시간 흐름 속에서 변화하는 패턴을 기반으로 미래 의사결정을 정량화하는 도구
- ARIMA, Prophet 같은 통계 모형은 추세, 계정설, 잡음으로 분해
- 머신러닝 모델은 특성 공학으로 제공
- 딥러닝은 모델이 스스로 패턴을 학습
- 시계열 분석의 결과는 단순 보고용이 아닌 실제 행동을 유도하는 기준으로 사용
개인화 및 서비스 최적화
- 플랫폼 서비스에서는 시간에 따른 선호 변화와 활동 패턴을 모델링
- 추천 시스템은 사용자의 정적인 취향을 맞추는 문제 → 사용자의 현재 상태와 의도를 추정하는 동적 예측 문제
- 추천 시스템은 사용자 행동을 단순한 데이터의 집합이 아닌 순서가 있는 데이터로 해석
- 행동의 순서, 최근성, 변화 속도를 기반으로 의사결정을 수행
시계열 데이터의 형태
| 구분 | 세부 항목 | 상세 내용 |
|---|---|---|
| 변수 축 | 단변량 | • 시간에 따라 하나의 변수만 관측한 데이터 • 예 : 주가 또는 매출액 등 |
| 다변량 | • 시간에 따라 여러 변수가 동시에 관측한 데이터 • 예 : 매출액, 광고비, 날씨 등 | |
| 개체 축 | 단일 | • 하나의 개체에 대해 시간에 따른 값을 관측한 데이터 • 예 : 특정 매장의 매출액 등 |
| 다중 | • 여러 개체에 대해 각각의 시계열을 동시에 관측한 데이터 • 예 : 여러 매장별 매출액, 상품별 판매량 등 |
단변량과 다변량 시계열 분석
- 단변량 시계열 : 하나의 변수만을 사용하여 미래 값을 예측하는 문제
- 다변량 시계열 : 외생변수를 함께 사용하여 미래 값을 예측하는 문제
- 다변량 시계열이 더 많은 정보를 활용할 수있어 모형 성능이 향상될 수 있음
- 외생변수는 예측 시점에서 사용 가능한 정보인지 반드시 확인
- 잘못된 변수를 사용하면 데이터 누수로 이어질 수 있음
단일 시계열과 다중 시계열 분석
- 각 시계열 특성이 크게 다른 경우 모델은 개별적인 차이를 충분히 반영하지 못함
- 평균적인 패턴만 학습하여 예측 성능 저하
- 시계열 간 유사성을 사전에 평가하고 개체별 특성을 입력 변수로 추가
로컬 모델과 글로벌 모델
- 로컬 모델 : 각 시계열별로 모델을 학습하는 방식
- 각 시계열의 고유한 패턴과 변동성을 세밀하게 반영
- 학습 데이터가 부족해지기 쉬움 → 모델의 일반화 성능이 낮아질 수 있음
- 글로벌 모델 : 여러 시계열을 하나의 모델로 동시에 학습하는 방식
- 다양한 시계열에서 공통적으로 나타나는 패턴을 학습
- 데이터 활용 효율이 높음
- 시계열간 이질성을 충분히 반영하지 못하면 평균적인 패턴만 학습 → 개체를 구분할 수 있는 식별자나 특성 정보를 입력 변수로 포함
시계열 데이터 전처리
- 시간 구조를 올바르게 설정하는것이 중요
- 타입 확인
- 정렬 후 간격 확인
- 날짜시간 변수를 인덱스로 설정하는 것이 일반적
- 인덱스 기준으로 정렬하면 관측값의 순서와 연속성을 자연스럽게 유지
- 인덱스를 기준으로 샘플링(재구성), 결측값 및 이상치 처리 등의 작업을 수월하게 해결
- 결측값은 흐름을 단절시킬 수 있음 → 시간적 연속성을 최대한 유지하는 방향으로 처리
시간 정보의 역할
- 시계열 데이터에서 시간 정보는 데이터의 구조를 정의하는 핵심 축으로 작용
- 날짜시간형으로 변환하면 시간 기준 정렬, 기간 단위 집계, 주기적 패턴 추출과 같은 분석이 일관된 방식으로 가능
시간 단위 재구성
- 분석 목적에 따라 시간 단위를 재구성할 수 있음
- 일별 → 주별 / 월별 : 단기적인 변동성이 완화, 잡음을 줄이고 장기적인 추세를 보다 명확하게 파악
- 시간 단위 세분화 : 변동 구조를 더 정밀하게 관찰 → 단기 패턴이나 이상 징후를 탐지하는 데 유리
- 과도한 집계는 중요한 변동 정보를 제거할 수 있다는 점에 유의
시계열 결측값 처리
- 센서 오류, 시스템 장애, 수집 지연 등의 이유로 결측값이 빈번하게 발생 → 데이터 연속성 훼손 주요 요인
- 단순 제거하면 시간 간격이 불규칙해지고 시계열 흐름이 단절 → 분석이나 모델링 과정에 오류 유발
- 시간 순서를 유지한 상태에서 결측값을 적절하게 보정
- 결측값 처리 방법
- 전방 채우기 : 직전 관측값으로 결측값을 채우는 방법
- 선형 보간 : 관측값이 연속적으로 변화하는 경우에 적합
- 결측 구간이 길거나 급격한 변화가 존재할 때 선형 보간은 패턴을 왜곡할 수 있음 → 이동 평균 사용
시계열 이상치 처리
- 일반적인 분석에서는 이상치를 제거하는 것이 기본
- 시계열 데이터는 이상치가 의미 있는 이벤트일 가능성이 있어 잡음 여부를 확인 후 처리
- 시각화, 이동 통계량, z-score, IQR 등의 방법으로 탐지
- 이상치는 제거하기보다 인접 시점 값을 활용한 보간, 이동 평균 기반 대체, 특정 기준값으로 조정하는 방식으로 처리
- 처리 전후의 데이터 분포와 패턴을 반드시 비교
자기상관과 시차
- 자기상관 : 과거 값과 현재 값 사이의 통계적 관계를 의미
- 특정 시점 값이 이전 시점 값에 의해 얼마나 설명되는지
- 시차 : 시간 의존성을 정량적으로 반영하기 위해 사용하는 개념
- 특정 시점 이전의 값을 현재 시점의 설명 변수로 사용하는 방식
- 대부분의 시계열 모형은 시차 변수를 활용하여 현재 값을 예측하는 구조를 가짐
시계열 변환
- 시계열 데이터는 원본 값을 그대로 사용하는 대신 목적에 맞는 변환을 적용
- 이전 시점과의 차이를 계산하는 차분은 데이터의 변화량을 강조하여 추세를 제거, 변동 구조를 안정화
이동 평균
- 일정 구간의 평균을 계산하여 시계열 데이터의 단기 변동을 완화 → 전반적 흐름을 부드럽게 만드는 방법
- 일정 구간 : window
- 불규칙한 잡음을 줄이고 추세와 같은 구조적 패턴을 보다 명확하게 파악
- 구간의 길이에 따라 해석이 달라짐
- 짧은 구간의 이동 평균은 최근 변화에 민감하게 반응하여 단기 패턴을 반영
- 긴 구간의 이동평균은 변동성을 크게 줄여 보다 안정적인 장기 흐름을 제공
- 예측 모델의 입력 변수로 사용할 경우 반드시 현재 시점 이전의 값만을 포함하여 계산
시계열 데이터 다루기
DatatimeIndex
- DatatimeIndex는 날짜와 시간을 인덱스로 사용하는 판다스의 인덱스 구조
- 각 행이 어떤 시점의 관측값인지를 명확하게 정의하는 기준 축
- 시간 정보를 데이터프레임의 구조 자체에 포함 → 시계열 데이터 분석을 쉽게 처리할 수 있음
날짜 범위 데이터 생성
pd.date_rangename: 인덱스 이름 지정freq: 간격 지정(기본값‘D’)
dates = pd.date_range(start='2024-01-01', end='2025-12-31', name='date')
# DatetimeIndex(['2024-01-01', '2024-01-02', '2024-01-03', '2024-01-04',
# '2024-01-05', '2024-01-06', '2024-01-07', '2024-01-08',
# '2024-01-09', '2024-01-10',
# ...
# '2025-12-22', '2025-12-23', '2025-12-24', '2025-12-25',
# '2025-12-26', '2025-12-27', '2025-12-28', '2025-12-29',
# '2025-12-30', '2025-12-31'],
# dtype='datetime64[ns]', name='date', length=731, freq='D')DatetimeIndex의 Frequency 문자열
| 구분 | 상세 내용 | 구분 | 상세 내용 |
|---|---|---|---|
| B | 영업일(월요일~금요일) 단위 | W-MON | 매주 월요일(요일 앵커 사용) |
| D | 일 단위 | YE-JAN | 매년 1월 말일(월 앵커 사용) |
| W | 주 단위(일요일 기준 주간 집계) | h | 매시 단위 |
| ME, MS | 매월 말일, 매월 시작일 | bh | 영업일 기준 매시 단위(09~16시) |
| BME, BMS | 영업일 기준 매월 말일, 매월 시작일 | min | 매분 단위 |
| QE, QS | 분기 말일, 분기 시작일 | s | 매초 단위 |
| BQE, BQS | 영업일 기준 분기 말일, 분기 시작일 | ms | 천 분의 1초 단위 |
| YE, YS | 연도 말일, 연도 시작일 | us | 백만 분의 1초 단위 |
| BYE, BYS | 영업일 기준 연도 말일, 연도 시작일 | ns | 십억 분의 1초 단위 |
시계열 요소 설정
n = len(dates)
trend = np.linspace(100, 140, n) # 완만한 증가 추세 설정
yearly = -20 * np.cos(2 * np.pi * np.arange(n) / 365) # 연간 계절성 설정
weekly = np.where(dates.dayofweek < 5, 10, -20) # 주간 계절성 설정
noise = np.random.normal(loc=0, scale=3, size=n) # 불확실성 설정
dates = dates.astype(str) # 문자열로 변환가상의 시계열 데이터 생성
df = pd.DataFrame(data={'date': dates, 'value': trend + yearly + weekly + noise})누락 및 중복 시점 생성
drop_dates = ['2024-01-05', '2024-02-10', '2024-03-20'] # 삭제할 날짜 리스트 생성
df = df.loc[~df['date'].isin(drop_dates), :].copy() # 선택한 행 삭제
dup_dates = ['2024-01-15', '2024-03-31', '2024-04-25'] # 중복 추가 날짜 시르트 생성
dup_rows = df.loc[df['date'].isin(dup_dates), :].copy() # 선택한 행 삭저가상의 시계열 데이터 변형
df = pd.concat(objs=[df, dup_rows], ignore_index=True) # 행 방향으로 결합 후 재할당
df = df.sample(frac=1, random_state=1).reset_index(drop=True) # 순서를 임의로 섞어 정렬되지 않은 상태로 만들기
df.loc[df.sample(n=5, random_state=1).index, 'value'] = np.nan # 일부 값을 결측으로 처리날짜시간 데이터로 변환
df['date'] = pd.to_datetime(arg=df['date'], errors='coerce') # 날짜시간형으로 변환
df = df.set_index(keys='date').sort_index() # 인덱스 설정 후 오름차순 정렬하여 재할당날짜 파생변수 생성
df['year'] = df.index.year # 연도
df['quarter'] = df.index.quarter # 분기
df['month'] = df.index.month # 월
df['day'] = df.index.day # 일
df['dayofweek'] = df.index.day_name(locale='ko_KR') # 요일
df['is_weekend'] = (df.index.dayofweek >= 5) # 주말여부
df = df.filter(items=['value']) # 초기화시계열 데이터의 인덱싱 및 슬라이싱
df.loc['2024-01-01', :] # 인덱싱
df.loc['2024-01-01':'2024-01-10', :] # 슬라이싱
df.loc[['2024-01-01', '2025-01-01'], :] # 팬시 인덱싱
df.loc[df.index.month == 1, :] # 불리언 인덱싱중복 시점 확인
# 중복 여부 마스크 생성
dup_mask = df.index.duplicated(keep=False)- 중복인 행만 새로 할당
dup_rows = df.loc[dup_mask]
# value
# date
# 2024-01-15 94.75
# 2024-01-15 94.75
# 2024-03-31 88.10
# 2024-03-31 88.10
# 2024-04-25 120.32
# 2024-04-25 120.32- 그룹 설정 후 평균 계산하여 재할당
df = df.groupby(df.index)[['value']].mean()first(): 그룹별 첫 번째 행 선택last(): 그룹별 마지막 행 선택nth(): 그룹별 지정한 인덱서 행 선택- 정수 인덱스를 지정하면 n+1 번째 행을 반환
- 0 : first
- -1 : last
누락 시점 확인
reindex:method속성에 결측값 대체법 지정
full_idx = pd.date_range(df.index.min(), df.index.max()) # 기대 인덱스 생성 후 할당
miss_idx = full_idx.difference(df.index) # 누락된 인덱스를 생성 후 할당
df = df.reindex(index=full_idx) # 누락된 인덱스를 추가 후 재할당결측값 처리
- 결측행 확인
df.loc[df.isna()]
# 2024-01-05 NaN
# 2024-02-10 NaN
# 2024-03-20 NaN
# 2024-06-15 NaN
# 2024-09-09 NaN
# 2024-12-28 NaN
# 2025-10-10 NaN
# 2025-12-28 NaN
# Name: value, dtype: float64interpolate- 값이 연속적이거나 중간값이 의미가 있으면
linear - 인덱스 간격이 균일하지 않으면
time
- 값이 연속적이거나 중간값이 의미가 있으면
df['value_ffill'] = df['value'].ffill() # 직전값으로 채움
df['value_linear'] = df['value'].interpolate(method='linear') # 선형보간법으로 채움
df['value_time'] = df['value'].interpolate(method='time') # 시간 간격 비율을 고려한 선형보간법으로 채움- 처리 결과 확인
df.loc['2024-01-04':'2024-01-10', :]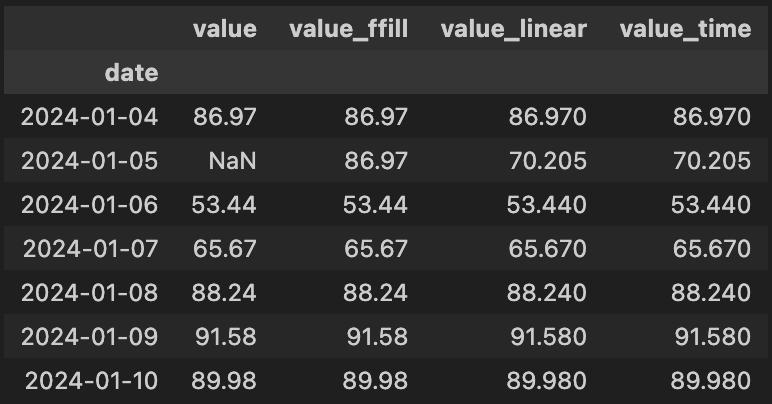
시차 변수 생성
# 아래로 값 이동
df['lag_1'] = df['value'].shift(periods=1)
df['lag_2'] = df['value'].shift(periods=2)
df['lag_3'] = df['value'].shift(periods=3)이동 평균 계산
df['roll_7_avg'] = df['value'].rolling(window=7, min_periods=1).mean() # 7일 이동 평균
df['roll_7_std'] = df['value'].rolling(window=7, min_periods=1).std() # 7일 이동 표준편차
df['expand_avg'] = df['value'].expanding().mean() # 처음부터 누적된 평균 계산변화량 기반 변수 생성
df['diff_1'] = df['value'].diff(periods=1) # 전일 대비 차분 계산
df['pent_1'] = df['value'].pct_change(periods=1) # 전일 대비 증감률 계산- 열 선택하여 초기화
df = df.filter(like='value')시간 단위 재구성
df.resample(rule='W-SUN')['value'].sum() # 주 단위로 합계 계산
df.resample(rule='W-SUN')['value'].sum().rolling(window=4).mean() # 주 단위 합계 4주 이동 평균 계산
df.asfreq(freq='W-FRI') # 특정 요일 선택하여 반환가상의 시계열 데이터 시각화
sns.lineplot(x=df.index, y=df['value'], color='royalblue', linewidth=1)
plt.show()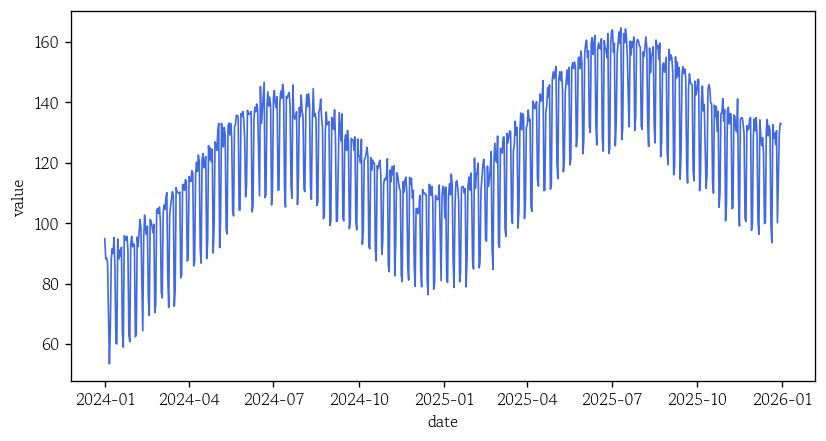
▫︎ 시계열 분해
from statsmodels.tsa.seasonal import seasonal_decompose- 데이터 분해
result = seasonal_decompose(x=df['value'], model='additive', period=7)
result.plot();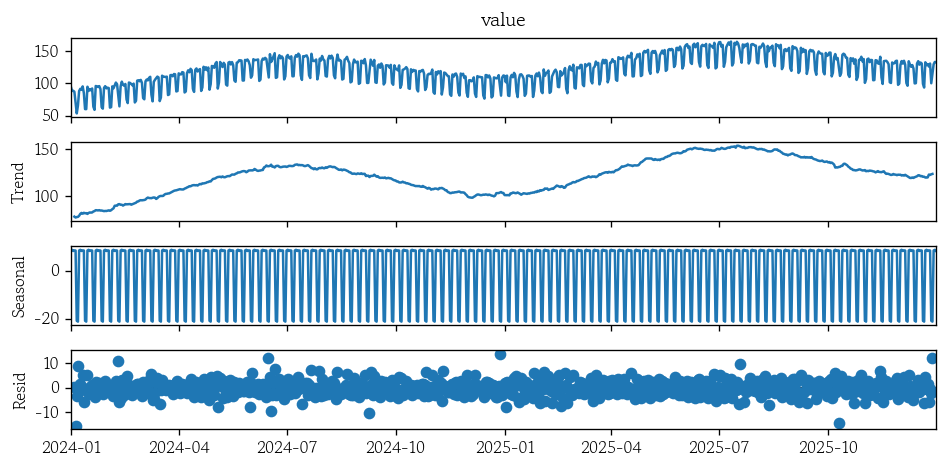
마치며
이론에 대해서 배우니까 역시나 분량이 엄청 많은 것 같다. 내일은 오늘 배운 시계열 데이터를 가지고 머신러닝과 다양한 예측 방법을 사용해서 실제로 예측을 해볼 것 같다.

Hello I'm TaeHyunAn, Currently Studying Data Analysis