시작하며
오늘은 시계열 데이터 2일차로 기준선 모형과 ARIMA 모형에 대해서 배웠다. 이론적으로 상당히 어려운 하루였다.
기준선 모형
기준선 모형 학습의 필요성
- 기준선 모형은 학습을 거의 하지 않는 규칙 기반 예측
- 시계열 데이터의 구조적 특성이 얼마나 예측 가능한지를 판단하기 위한 최소 기준
- 아무리 복잡한 딥러닝 모델을 사용해도 기준선 모형보다 성능이 나쁘면 해당 모델은 실패
- 시계열 예측은 다음 사실에서 출발
- 과거 값 자체가 이미 매우 강력한 정보
- 단순한 예측이 의외로 잘 맞음
- 복잡한 모형은 기준선을 상회해야 의미가 있음
기준선 모형의 종류
| 구분 | 공식 | 상세 내용 |
|---|---|---|
| 단순 기법 Naive Method | 단순 기법의 기본 개념은 '내일은 오늘과 같다' 랜덤 워크 데이터에서는 단순 기법이 이론적으로 최적 | |
| 이동 평균 Moving Average | 이동 평균 예측은 최근 k일의 평균을 사용 전체 평균 예측은 추세가 있는 데이터에서 적절하지 않음 | |
| 단순 회귀 Linear Regression | 단순 회귀 예측은 시간에 따라 직선의 추세가 있다고 가정하고 시간을 숫자로 간주하여 회귀 모형을 학습 | |
| 표류 기법 Drift Method | 표류 기법은 단순 기법에 평균적인 변화 방향을 더하는 예측 방법 |
시계열 예측 문제의 정의
- 시계열 예측 문제는 다음과 같이 정의
- t 시점까지 관측된 데이터만을 사영하여 미래 시점(t + h)의 값을 추정
- 시계열 예측 문제의 규칙
- 미래 정보 사용 X
- 시간 순서 보존
1-step vs multi-step 예측
- 1-step 예측은 미래의 한 시점만을 예측
- multi-step 예측은 미래의 여러 시점을 예측
- multi-step은 direct(직접)와 recursive(순차 예측)이 있음
- 단순 회귀 기반 예측은 직접 방식
실습 데이터셋 분할
std_date = '2025-01-01' # 기준일자 설정- 훈련셋과 시험셋 분할
train = df.loc[:std_date].iloc[:-1]
test = df.loc[std_date:]훈련셋과 시험셋 정수 인덱스 생성
n_train = len(train) # 훈련셋 크기 생성
train_idx = np.arange(n_train).reshape(-1, 1) # 훈련셋 인덱스를 수치형으로 변환
n_test = len(test) # 시험셋 크기 생성
test_idx = np.arange(n_train, n_train + n_test).reshape(-1, 1) # 시험셋 인덱스를 수치형으로 변환기준선 모형
- 단순 기법 예측
nm_pred = pd.concat(objs=[train, test])['value'].shift(1).loc[test.index]
nm_pred.head()
# date
# 2025-01-01 112.18
# 2025-01-02 111.60
# 2025-01-03 101.77
# 2025-01-04 111.94
# 2025-01-05 81.24
# Freq: D, Name: value, dtype: float64- 이동 평균 예측
ma_pred = pd.concat(objs=[train, test])['value'].rolling(window=7).mean().shift(1).loc[test.index]
ma_pred.head()
# date
# 2025-01-01 103.960714
# 2025-01-02 104.509286
# 2025-01-03 103.600714
# 2025-01-04 103.499286
# 2025-01-05 101.275714
# Freq: D, Name: value, dtype: float64- 단순 회귀 기반 예측
from sklearn.linear_model import LinearRegressionmodel = LinearRegression()
model.fit(X=train_idx, y=train['value'])
lr_pred = pd.Series(data=model.predict(X=test_idx), index=test.index)
lr_pred.head()
# date
# 2025-01-01 121.615984
# 2025-01-02 121.670329
# 2025-01-03 121.724673
# 2025-01-04 121.779017
# 2025-01-05 121.833362
# Freq: D, dtype: float64- 표류 기법 예측
y_1, y_t = train['value'].iloc[[0, -1]] # 훈련셋 첫 번째 값과 마지막 값 생성
drift = (y_t - y_1) / (n_train - 1) # 전체 기간의 평균 일별 변화량 계산
h = np.arange(1, n_test + 1) # 각 시점까지 일수 차이 계산
dm_pred = pd.Series(data=y_t + h * drift, index=test.index)
dm_pred
# date
# 2025-01-01 112.227425
# 2025-01-02 112.274849
# 2025-01-03 112.322274
# 2025-01-04 112.369699
# 2025-01-05 112.417123
# ...
# 2025-12-27 129.300301
# 2025-12-28 129.347726
# 2025-12-29 129.395151
# 2025-12-30 129.442575
# 2025-12-31 129.490000
# Freq: D, Length: 365, dtype: float64기준선 모형의 시각적 비교
sns.lineplot(x=test.index, y=test['value'], label='Actual', color='0')
sns.lineplot(x=test.index, y=nm_pred, label='Naive Method', color='0.8')
sns.lineplot(x=test.index, y=ma_pred, label='Moving Average', color='blue')
sns.lineplot(x=test.index, y=lr_pred, label='Linear Regression', color='red')
sns.lineplot(x=test.index, y=dm_pred, label='Drift Method', color='green')
plt.title(label='기준선 모형 비교', fontweight='bold')
plt.legend()
plt.show()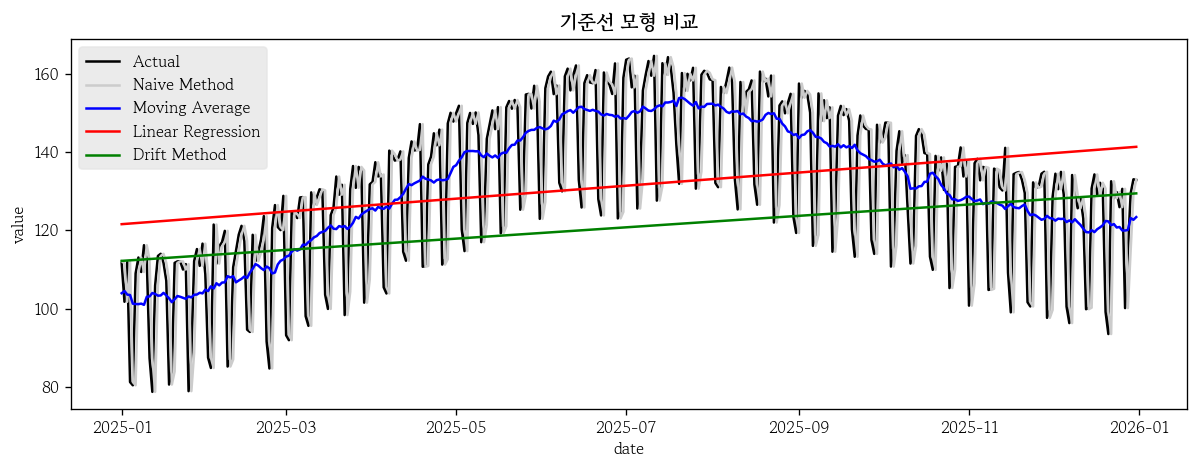
시계열 예측에서 기준선 모형 선택 기준
| 데이터 특징 | 예시 데이터 | 공식 |
|---|---|---|
| 랜덤 워크 | 주가 데이터 (기업별, 시점별로 크게 변함) | 단순 기법 Naive Method |
| 잡음 많음 | 센서 데이터 (측정 오차, 노후화 등) | 이동 평균 Moving Average |
| 추세 있음 | 고객 수, 매출액 등 (장기 변화 데이터) | 단순 회귀 Linear Regression |
| 추세 + 랜덤 워크 | 환율 데이터 (장기 상승 또는 하락 + 충격) | 표류 기법 Drift Method |
기준선 모형 예측 성능 평가
- 단순 기법
hds.stat.regmetrics(y_true=test['value'], y_pred=nm_pred).loc[[2, 6], ['metric', 'score']].reset_index(drop=True)
# metric score
# 0 RMSE 16.595267
# 1 MAPE 0.090108- 이동 평균
hds.stat.regmetrics(y_true=test['value'], y_pred=ma_pred).loc[[2, 6], ['metric', 'score']].reset_index(drop=True)
# metric score
# 0 RMSE 13.931236
# 1 MAPE 0.100994- 단순 회귀
hds.stat.regmetrics(y_true=test['value'], y_pred=lr_pred).loc[[2, 6], ['metric', 'score']].reset_index(drop=True)
# metric score
# 0 RMSE 19.784532
# 1 MAPE 0.131419- 표류 기법
hds.stat.regmetrics(y_true=test['value'], y_pred=dm_pred).loc[[2, 6], ['metric', 'score']].reset_index(drop=True)
# metric score
# 0 RMSE 22.509184
# 1 MAPE 0.137104탐색적 데이터 분석(따릉이 이용 현황 실습)
데이터 전처리
df['RENT_DT'] = pd.to_datetime(arg=df['RENT_DT'], errors='coerce') # 날짜시간형으로 변환
df = df.set_index('RENT_DT').sort_index() # 날짜시간형 컬럼은 인덱스로 설정시계열 인덱스 확인
df.index.duplicated(False).sum() # 중복건 확인
# 0
full_idx = pd.date_range(df.index.min(), df.index.max(), freq='D') # 인덱스의 최솟값과 최댓값으로 기대 인덱스 생성
full_idx.difference(df.index).size # 누락 인덱스 개수 확인
# 6
df = df.reindex(full_idx).rename_axis(index='RENT_DT') # 누락 인덱스를 행으로 추가결측값 처리
df.loc[df['USE_CNT'].isna()] # 결측인 행 확인
# USE_CNT
# RENT_DT
# 2021-06-25 NaN
# 2021-06-26 NaN
# 2021-06-27 NaN
# 2021-06-28 NaN
# 2021-06-29 NaN
# 2021-06-30 NaN- 연속 6일 동안 결측 발생 -> 단순 일시적 누락이 아닌 구조적 결측 가능성 높음
df = df.dropna() # 결측인 행 모두 삭제일별 이용 현황 데이터 시각화
sns.lineplot(data=df, x=df.index, y='USE_CNT', color='royalblue', linewidth=0.5)
plt.show()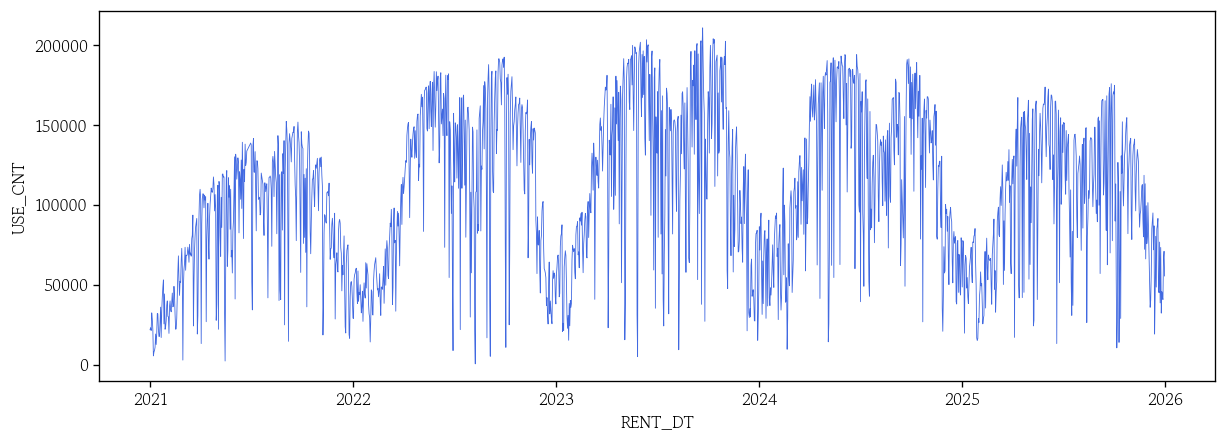
시계열 분해
from statsmodels.tsa.seasonal import seasonal_decomposeresult = seasonal_decompose(x=df['USE_CNT'], model='additive', period=7)
result.plot();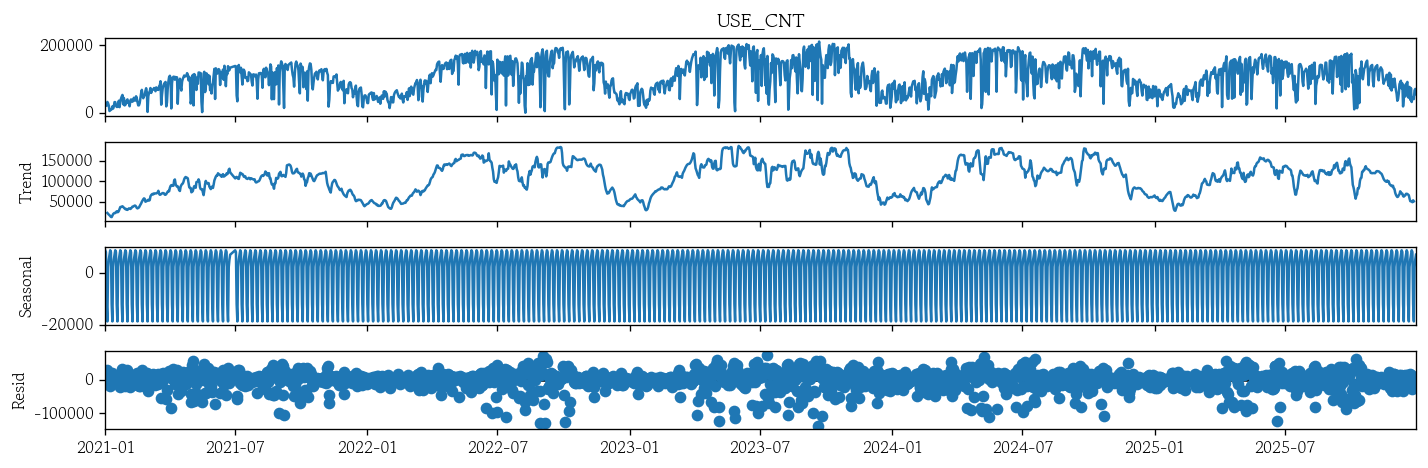
실습 데이터셋
- 데이터셋 분할
std_date = '2025-01-01' # 훈련셋과 시험셋으로 분할하는 기준일자 설정
train = df.loc[:std_date].iloc[:-1]
test = df.loc[std_date:]- 정수 인덱스 생성
n_train = len(train) # 훈련셋 크기 생성
train_idx = np.arange(n_train).reshape(-1, 1) # 인덱스를 수치형으로 변환
n_test = len(test) # 시험셋 크기 생성
test_idx = np.arange(n_train, n_train + n_test).reshape(-1, 1) # 인덱스를 수치형으로 변환기준선 모형
- 단순 기법 예측
nm_pred = pd.concat(objs=[train, test])['USE_CNT'].shift(1).loc[test.index]- 이동 평균 예측
ma_pred = pd.concat(objs=[train, test])['USE_CNT'].rolling(window=7).mean().shift(1).loc[test.index]- 단순 회귀 기반 예측
from sklearn.linear_model import LinearRegression
model = LinearRegression() # 단순 선형 회귀 모형 생성
model.fit(X=train_idx, y=train['USE_CNT']) # 훈련셋으로 모형 학습
lr_pred = pd.Series(data=model.predict(X=test_idx), index=test.index) # 단순 회귀 기반 예측- 표류 기법 예측
y_1, y_t = train['USE_CNT'].iloc[[0, -1]] # 훈련셋의 첫 번째 값과 마지막 값을 생성
drift = (y_t - y_1) / (n_train - 1) # 평균 일별 변화량 계산
h = np.arange(1, n_test + 1) # ㅣ험셋의 일수 차이 계산
dm_pred = pd.Series(data=y_t + h * drift, index=test.index) # 시험셋으로 표퓨 기법 예측값 생성시각적 비교
sns.lineplot(x=test.index, y=test['USE_CNT'], label='Actual', color='0')
sns.lineplot(x=test.index, y=nm_pred, label='Naive Method', color='0.8')
sns.lineplot(x=test.index, y=ma_pred, label='Moving Average', color='blue')
sns.lineplot(x=test.index, y=lr_pred, label='Linear Regression', color='red')
sns.lineplot(x=test.index, y=dm_pred, label='Drift Method', color='green')
plt.title(label='기준선 모형 비교', fontweight='bold')
plt.legend(loc='upper left')
plt.show()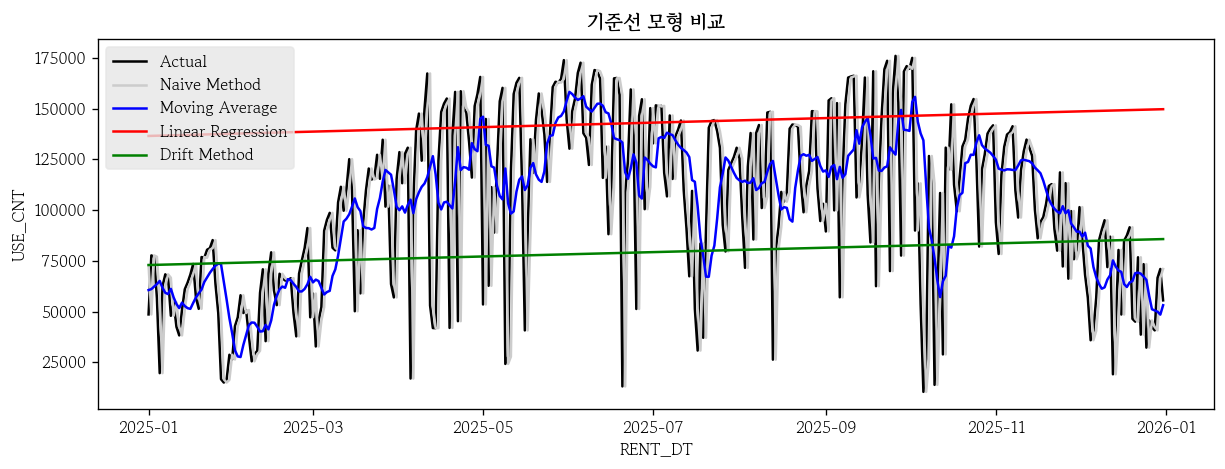
모형 예측 성능 평가
hds.stat.regmetrics(y_true=test['USE_CNT'], y_pred=nm_pred).loc[[2, 6], ['metric', 'score']].reset_index(drop=True)
hds.stat.regmetrics(y_true=test['USE_CNT'], y_pred=ma_pred).loc[[2, 6], ['metric', 'score']].reset_index(drop=True)
hds.stat.regmetrics(y_true=test['USE_CNT'], y_pred=lr_pred).loc[[2, 6], ['metric', 'score']].reset_index(drop=True)
hds.stat.regmetrics(y_true=test['USE_CNT'], y_pred=dm_pred).loc[[2, 6], ['metric', 'score']].reset_index(drop=True)인덱스에 freq 설정
train = train.asfreq('D')
test = test.asfreq('D')전통적 통계 모형 ARIMA
자기상관의 의미
- 시계열 데이터에서 각 관측값은 독립적이지 않으며, 현재 값을 예측하는 가장 강력한 정보는 과거의 자기 자신
- 현재 값과 과거 값은 강하게 연결 → 자기상관(Auto-Correlation)
- 단순 기법이 잘 작동한다는 것 → 시차 1의 자기상관이 매우 강하다는 뜻
- 단순 회귀 및 표류 기법은 계절성이 강한 시계열 데이터에 적합한 모형이 아님
ARIMA 모형의 개요
- ARIMA 모형은 시계열 데이터에 존재하는 자기상관 구조를 수학적으로 표현한 전통적 통계 모형
- ARIMA 모형의 세 가지 구성 요소
- 자기회귀 모형(Autoregressive, AR)
- 과거의 관측값이 현재 값에 직접적인 영향을 미치는 구조
- 자기회귀 모형의 차수 : p
- 이동 평균 모형(Moving Average, MA)
- 과거에 발생한 오차가 이후 시점의 값에 영향을 미치는 구조
- 이동 평균 모형의 차수 : q
- 차분(Integrated, I)
- 추세 등 비정상 시계열을 AR과 MA 모형이 적용 가능한 형태로 변환하는 과정
- 차분의 차수 : d
- 비정상성 데이터 → 정상성 데이터
- 자기회귀 모형(Autoregressive, AR)
자기회귀 모형
- AR 모형은 과거 값이 현재 값을 설명한다는 가정을 수학적으로 표현한 것
- : 자기회귀 계수
- : 불확실성을 나타내는 오차
- : 중심을 잡아주는 위치
이동 평균 모형
- 과거 값으로 설명할 수 없는 오차가 이후 시점에 영향을 미치는 경우가 있음
- MA 모형은 현재 값을 과거 오차들의 선형 결합으로 표현한 것
- : 시계열의 평균 수준
- : 이전 시점에서 발생한 오차가 현재 값에 얼마나 강하게 반영되는지
자기상관 함수 : Auto-Correlation Function
- 시계열 데이터에 자기상관이 존재한다는 것은 과거 정보를 통해 미래를 추측할 수 있다는 것
- ACF는 현재 값과 여러 과거 값들 사이의 상관관계를 시차별로 계산한 값
- ACF 플롯을 통해 과거의 영향이 얼마나 오래 지속되는지, 특정 주기로 반복되는 패턴이 있는지 확인
부분 자기상관 함수 : Partial Auto-Correlation Function
- PACF는 중간 시차의 영향을 제거하고 시차가 k일 때의 직접적인 관련성을 계산
- PACF는 현재 값에 직접적인 영향을 미치는 과거 시차가 어느 지점까지인지 판단
자기상관 함수 정리
- AR(p) : 과거값이 현재 값에 영향을 미침
- ACF : Tail-off
- PACF : p 이후 단절
- MA(q) : 현재 오차와 과거 오차의 선형결합이 현재값에 영향을 미침
- ACF : q 이후 단절
- PACF : Tail-off
| 구분 | ACF | PACF |
|---|---|---|
| AR(p) | 서서히 감소(Tail-off) | p 이후 단절 |
| MA(q) | q 이후 단절 | 서서히 감소(Tail-off) |
차분 전 데이터로 ACF, PACF 시각화
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf- ACF 시각화
plot_acf(x=df, lags=30);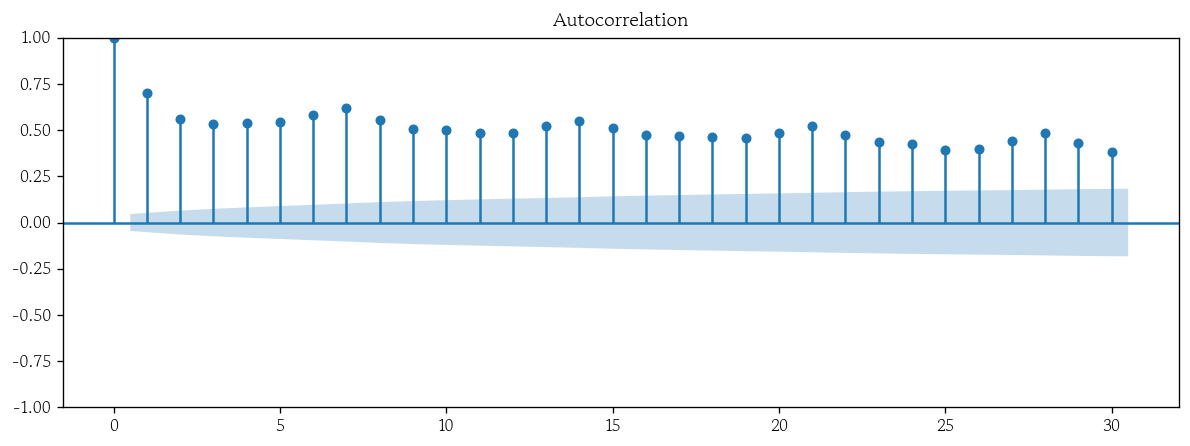
- PACF 시각화
plot_pacf(x=df, lags=30);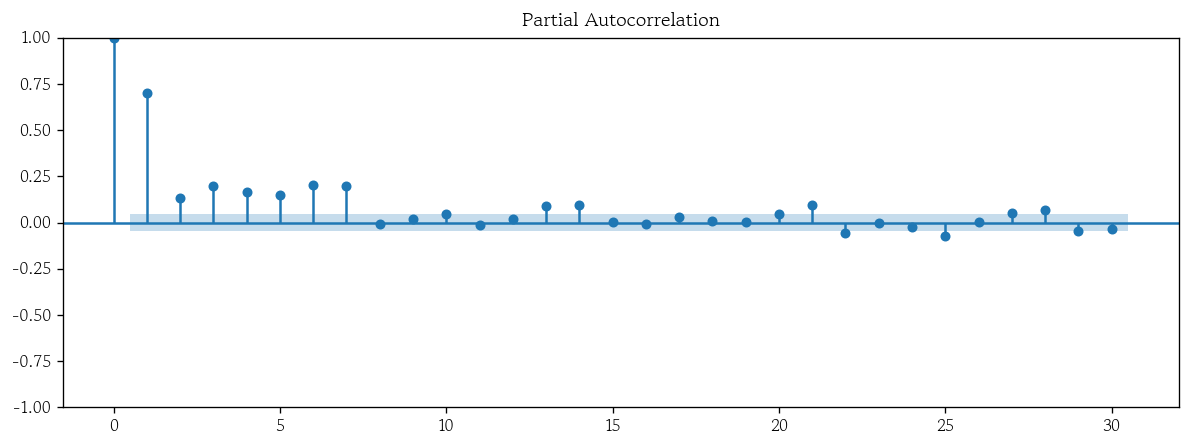
차분 : Integrated
- AR과 MA 모형에서는 ‘시계열의 평균과 분산이 시간에 따라 안정적이다’라는 전제가 있음 → 실제 데이터에서는 추세가 존재하거나 평균 수준이 시간에 따라 변하는 경우가 많음
- 추세가 있는 데이터는 자기상관이 인위적으로 크게 나타남
- 구조를 정확히 파악하기 어려워 데이터 변화량을 관찰하는 것이 중요
- 1차 차분은 연속된 시점 간의 차이를 계산 → 추세를 제거한 효과를 갖음
- 차분은 추세 제거가 목적
- 차분 전 ACF가 천천히 감소하면 d = 1 고려
- 1차 차분 후 ACF가 빠르게 0으로 수렴하면 d = 1에서 멈춤
1차 차분 데이터로 시각화
use_diff_1 = df.diff(1).dropna()- ACF 시각화
plot_acf(x=use_diff_1, lags=30);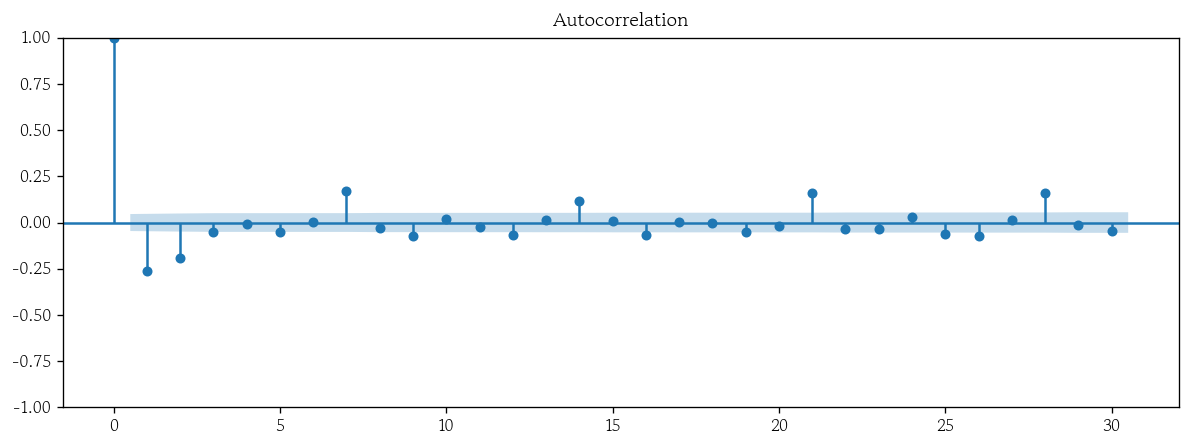
- PACF 시각화
plot_pacf(x=use_diff_1, lags=30);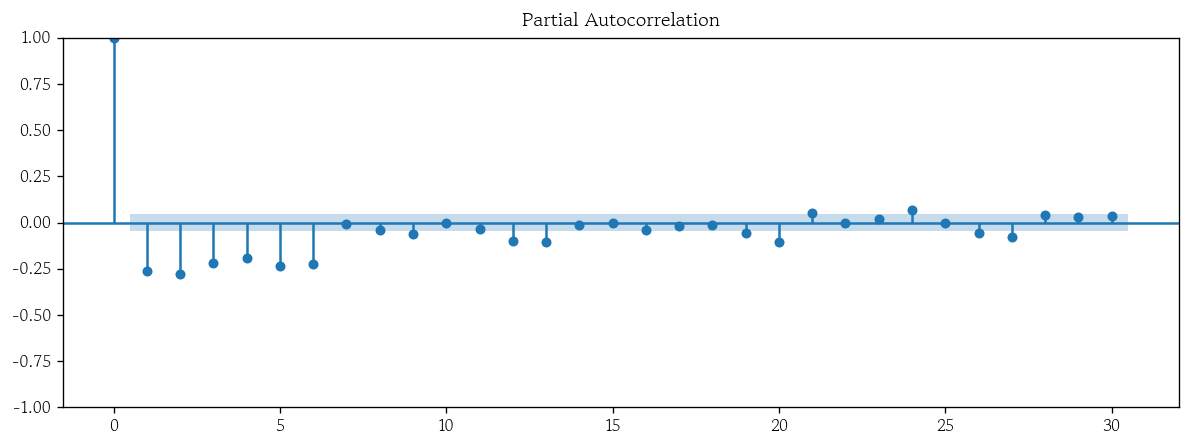
ARIMA 모형 생성
from statsmodels.tsa.statespace.sarimax import SARIMAXarima_model = SARIMAX(
endog=train,
order=(0, 1, 1),
enforce_stationarity=False,
enforce_invertibility=False
)- ARIMA 모형 적합 결과 확인
arima_result = arima_model.fit()
arima_result.summary()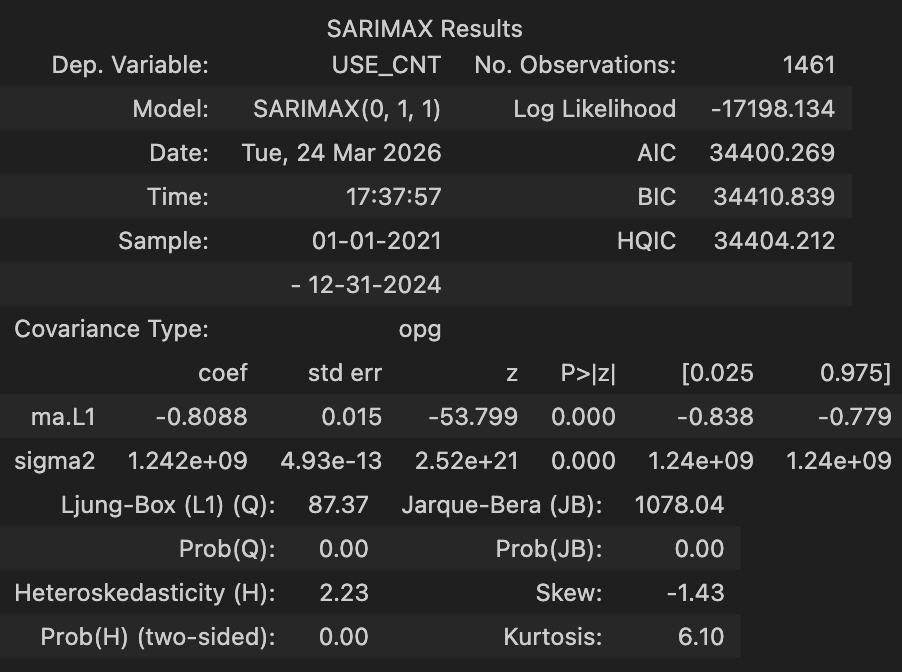
- ARIMA 모형의 적합도 확인
from statsmodels.stats.diagnostic import acorr_ljungboxarima_resid = arima_result.resid.dropna() # ARIMA 모형의 잔차를 생성
acorr_ljungbox(x=arima_resid) # 룽 박스 검정을 통해 잔차의 자기상관 여부 확인
# lb_stat lb_pvalue
# 1 87.246095 9.582431e-21
# 2 104.626705 1.908094e-23
# 3 138.091505 9.748678e-30
# 4 155.442875 1.387080e-32
# 5 163.480199 1.793442e-33
# 6 168.112718 1.130396e-33
# 7 201.420868 5.740250e-40
# 8 201.434694 3.185462e-39
# 9 212.201067 9.118374e-41
# 10 214.662629 1.398402e-40
arima_result.aic # ARIMA 모형의 AIC 확인
# 34400.26888872458ARIMA 모형 잔차의 자기상관 플롯 시각화
from statsmodels.graphics.tsaplots import plot_acfplot_acf(x=arima_resid, lags=30);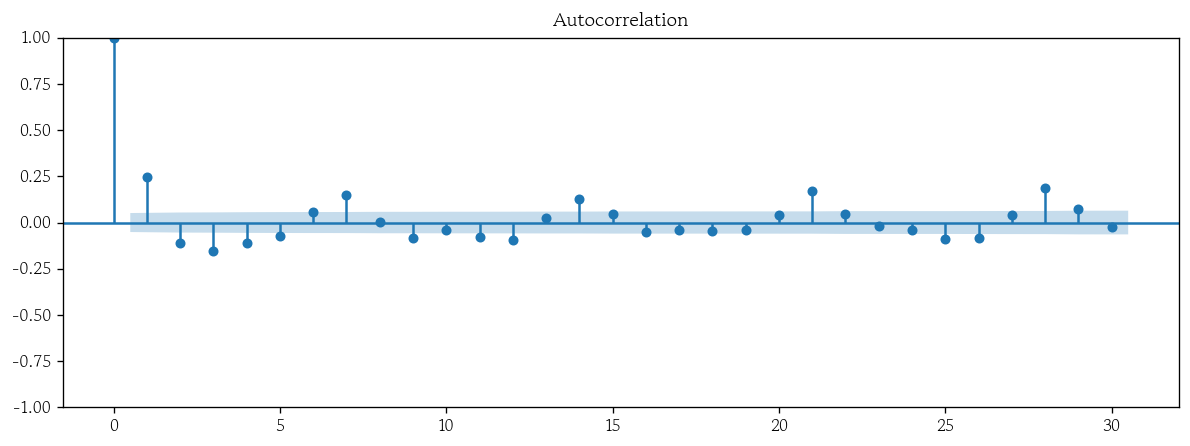
ARIMA 모형의 장기 예측값 생성
n_test = len(test) # 시험셋 크기 설정
arima_pred = arima_result.get_forecast(steps=n_test) # 시험셋 크기만큼 ARIMA 모형의 예측값 생성
arima_pred_avg = arima_pred.predicted_mean # ARIMA 모형의 예측값 평균 생성ARIMA 모형의 장기 예측값 시각화
sns.lineplot(x=test.index, y=test['USE_CNT'], color='0.8', linewidth=0.5)
sns.lineplot(x=test.index, y=arima_pred_avg, color='red')
plt.show()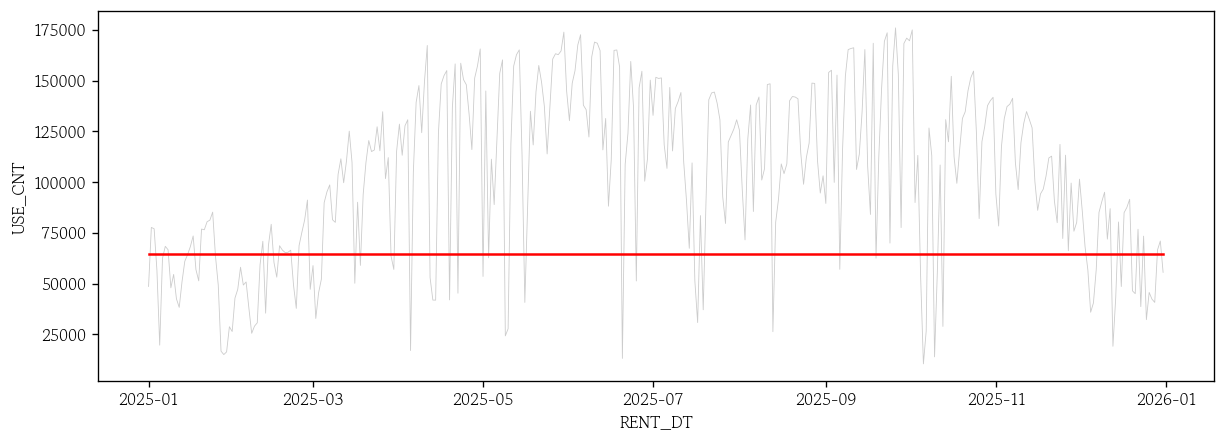
1-step Rolling 예측 함수 생성
def rolling_1step(model, test, exog=None):
preds = pd.Series() # ARIMA 모형 예측값을 저장할 빈 시리즈 생성
for t in test.index: # test 매개변수의 인덱스를 바꿔가면서 반복문 실행
if exog is None: # 외생변수가 없는 모형으로 1-step Rolling 예측 실행
y_hat = model.forecast(1) # 다음 시점 예측값 생성
model = model.append(endog=test.loc[[t]], refit=False)
else: # 외생변수가 있는 모형으로 예측 실행
y_hat = model.forecast(1, exog=exog.loc[[t]])
model = model.append(endog=test.loc[[t]], exog=exog.loc[[t]], refit=False)
preds = pd.concat(objs=[preds, y_hat]) # preds에 y_hat 추가
return predsARIMA 모형의 단기 예측값 시각화
arima_roll = rolling_1step(model=arima_result, test=test) # ARIMA 모형에 대한 예측값 생성sns.lineplot(x=test.index, y=test['USE_CNT'], color='0.8', linewidth=0.5)
sns.lineplot(x=test.index, y=arima_roll, color='red')
plt.show()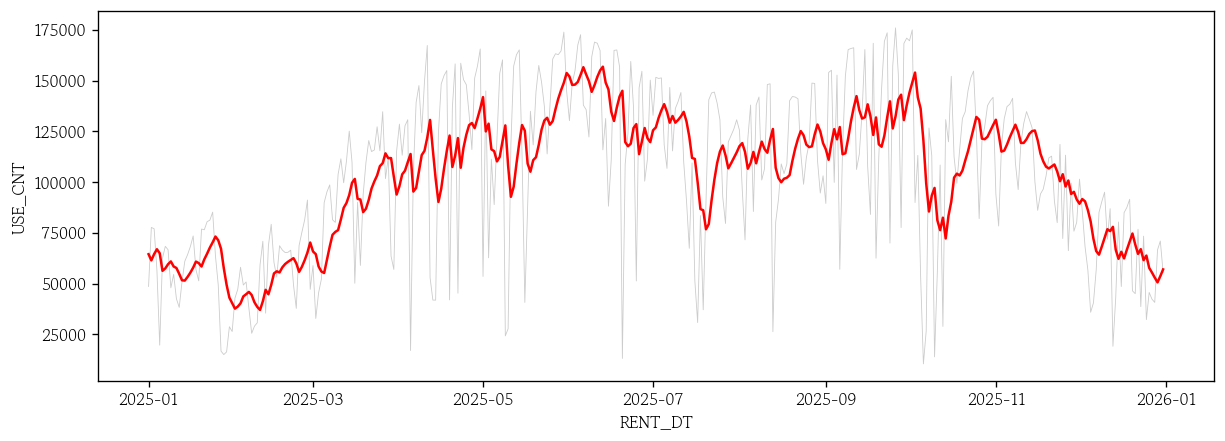
ARIMA의 한계
| 전제 조건 | 현실 데이터의 특징 |
|---|---|
| • 시계열은 자기 자신의 과거 값과 과거 오차로 설명할 수 있음 | • 명확한 주기적 패턴이 반복(요일 효과, 월별 패턴, 연간 계절성 등) |
| • 비정상성은 차분으로 제거할 수 있음 | • 차분만으로 충분히 설명되지 않는 경우가 많음 |
| • 계절성은 없거나 약함 | • 기온, 강수량, 이벤트, 정책 등 외생변수의 영향이 큼 |
| • 외부 요인의 영향은 고려하지 않음 | • ARIMA로는 잔차에 구조적인 패턴이 남음 |
SARIMA : 계절성을 포함한 ARIMA
| 비계절 ARIMA | 계절 ARIMA |
|---|---|
| AR(p) : 직전 1~p 시점의 값 영향 | SAR(P) : s 간격으로 떨어진 값의 영향 |
| I(d) : 전체 추세 제거용 차분 → | SD(D) : 계절 효과 제거용 차분 → |
| MA(q) : 직전 1~q 시점의 오차 영향 | SMA(Q) : s 간격으로 떨어진 오차의 영향 |
통계 모형 선택 기준
| 상황 | 추천 모형 |
|---|---|
| 계절성 없는 단변량 데이터 예측 | ARIMA |
| 강한 주기성이 있는 데이터 예측 | SARIMA |
| 외생변수가 중요한 데이터 예측 | ARIMAX |
| 계절성과 외생변수를 모두 고려 | SARIMAX |
| 추세, 계절성, 이벤트 등 구조가 자주 바뀜 | Prophet / ML |
SARIMA 모형
- 모형 생성
sarima_model = SARIMAX(
endog=train,
order=(0, 1, 1),
seasonal_order=(0, 1, 1, 7),
enforce_stationarity=False,
enforce_invertibility=False
)- 모형 적합
sarima_result = sarima_model.fit()
sarima_result.summary()- 모형 적합도 확인
sarima_resid = sarima_result.resid.dropna() # SARIMA 모형의 잔차 생성
acorr_ljungbox(sarima_resid)- 장기 예측값 생성
sarima_pred = sarima_result.get_forecast(steps=n_test)
sarima_pred_avg = sarima_pred.predicted_mean- 장기 예측값 시각화
sns.lineplot(x=test.index, y=test['USE_CNT'], color='0.8', linewidth=0.5)
sns.lineplot(x=test.index, y=sarima_pred_avg, color='red')
plt.show()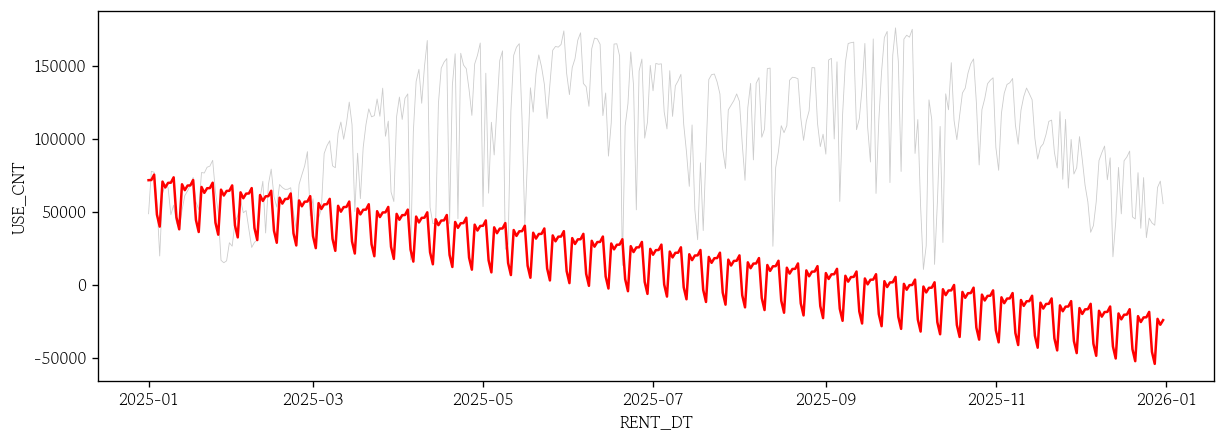
- 단기 예측 시각화
sarima_roll = rolling_1step(model=sarima_result, test=test)
sns.lineplot(x=test.index, y=test['USE_CNT'], color='0.8', linewidth=0.5)
sns.lineplot(x=test.index, y=sarima_roll, color='red')
plt.show()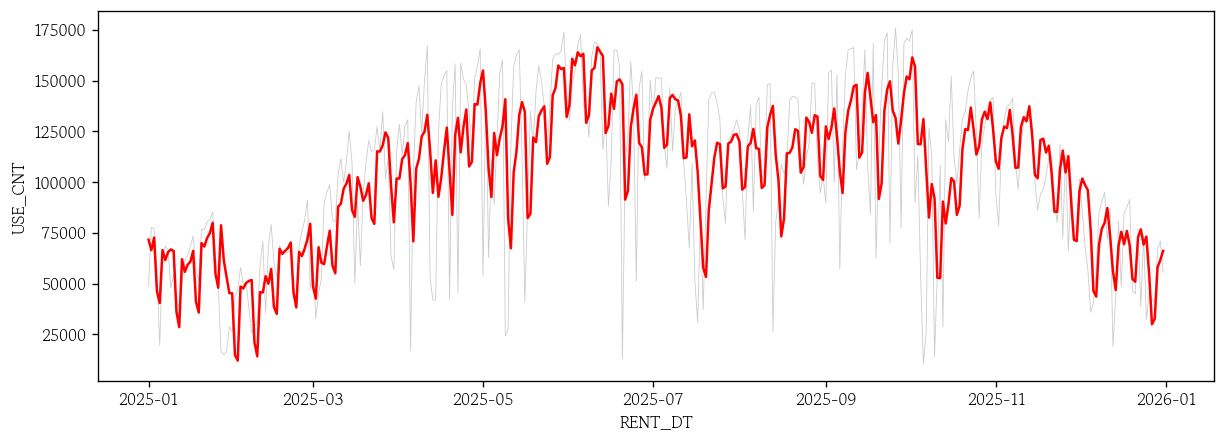
SARIMAX 모형
sarimax_model = SARIMAX(
endog=train,
exog=exog_train,
order=(0, 1, 1),
seasonal_order=(0, 1, 1, 7),
enforce_stationarity=False,
enforce_invertibility=False
)sarimax_result = sarimax_model.fit()
sarimax_result.summary()- 모형 적합도 확인
sarimax_resid = sarimax_result.resid.dropna()
plot_acf(x=sarimax_resid, lags=30);- 장기 예측값 생성
sarimax_pred = sarimax_result.get_forecast(steps=n_test, exog=exog_test)
sarimax_pred_avg = sarimax_pred.predicted_mean- 장기 예측 시각화
sns.lineplot(x=test.index, y=test['USE_CNT'], color='0.8', linewidth=0.5)
sns.lineplot(x=test.index, y=sarimax_pred_avg, color='red')
plt.show()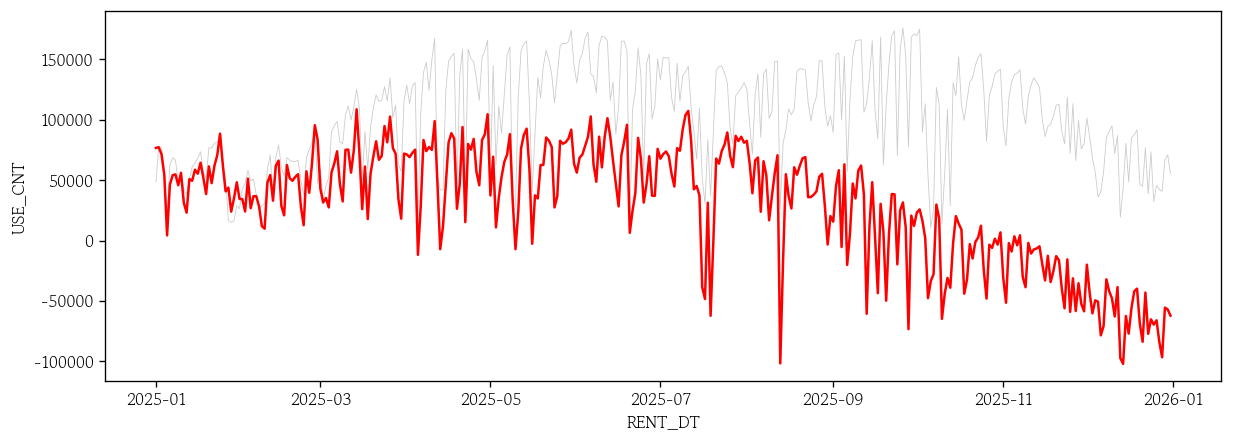
- 단기 예측 시각화
sarimax_roll = rolling_1step(model=sarimax_result, test=test, exog=exog_test)
sns.lineplot(x=test.index, y=test['USE_CNT'], color='0.8', linewidth=0.5)
sns.lineplot(x=test.index, y=sarimax_roll, color='red')
plt.show()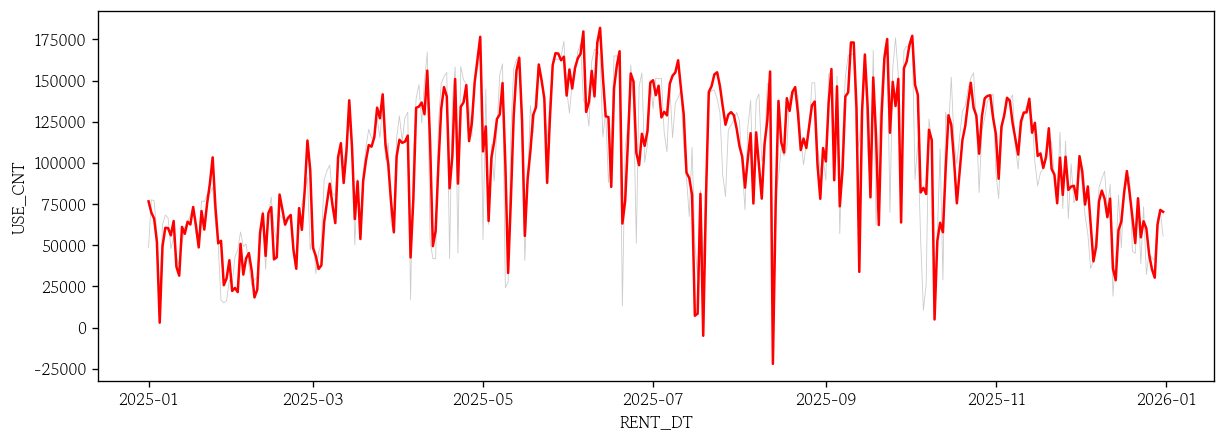
마치며
내일은 머신러닝, 딥러닝 파트의 마지막 날이다. Prophet부터 LSTM까지 간단하게 다뤄보는 것으로 알고 있는데 마지막 마무리까지 잘하면 좋겠다.

Hello I'm TaeHyunAn, Currently Studying Data Analysis