시작하며
오늘은 시계열 데이터의 마지막 Prophet과 머신러닝, 딥러닝을 사용한 시계열 데이터 예측을 배웠다.
구조적 통계 모형 Prophet
Prophet 개요
- 전통적 통계 모형인 ARIMA는 자기상관 구조를 정교하게 적합할 수 있다는 장점이 있음 → 정합성 판단, 차수 선택, 계절성 처리 등의 사전 판단이 필요하다는 한계가 있음
- Prophet은 일부 사전 판단 과정을 단순화하여 빠르고 안정적인 예측을 목표로 개발된 알고리즘
- 시계열 데이터를 구성요소(추세, 계절성, 이벤트, 잡음)로 분해한 뒤 다시 결합하여 예측
추세 모델링
- Prophet에서 추세는 시간에 따라 변화하는 평균 수준
- 기본적으로 선형 추세 또는 로지스틱 성장 모형을 사용
- 현실 시계열 데이터의 추세가 바뀌는 구조를 반영하기 위해 변화점 개념 도입
- 변화점 : 추세의 기울기가 바뀌는 시점
계절성 모델링
- Prophet은 계절성을 주기적으로 반복되는 패턴으로 정의
- 계절성을 주기 함수의 선형 결합으로 표현하기 위해 푸리에 급수를 사용
Prophet의 장점과 한계
| 장점 | 한계 |
|---|---|
| • 차수 선택이나 정상성 판단과 같은 복잡한 사전 분석 절차 없이도 쉽게 적용할 수 있음 | • Prophet은 기본적으로 가법 구조를 가정 |
| • 주간, 연간과 같은 다중 계절성을 자동으로 고려할 수 있어 모델 설계 부담이 적음 | • 시계열 수준이 증가할수록 변동폭이 증가하는 패턴을 충분히 반영하기 어렵습니다. 이 경우 로그 변환 또는 승법 구조를 적용 |
| • 결측치와 이상치에 비교적 강건 | • 자기상관 구조를 직접 모델링하지 않기 때문에 단기 예측 성능이 낮을 수 있음 |
| • 모델 생성 및 예측 코드가 간결하며, 기본적인 시각화 기능을 함께 제공 | • 급격한 구조 변화 및 복잡한 비선형 패턴을 충분히 반영하지 못하는 경우가 있음 |
| • 비전문가도 짧은 시간 안에 실무 데이터에 적용 가능한 수준의 결과를 얻을 수 있음 | • 장기 예측으로 갈수록 불확실성이 빠르게 증가하는 경향이 있음 |
Prophet 실습
from prophet import Prophet- Prophet 형식으로 변환
train = train.reset_index().rename(columns={'RENT_DT': 'ds', 'USE_CNT': 'y'})- Prophet 기본 모형 적합
pp_basic = Prophet()
pp_basic.fit(train)- 미래 기간 생성
n_test = len(test) # 시험셋 크기 생성
pp_basic_future = pp_basic.make_future_dataframe(n_test, 'D') # 시험셋 크기만큼 미래 날짜 생성- Prophet 기본 모형 예측값 생성
pp_basic_yhat = pp_basic.predict(pp_basic_future) # 기본 모형의 예측값 생성
pp_basic_pred = pp_basic_yhat.set_index('ds').loc[test.index, 'yhat'] # df를 인덱스로 설정 후 예측값만 할당- Prophet 기본 모형 잔차 시각화
pp_basic_resid = test['USE_CNT'] - pp_basic_pred # 기본 모형 잔차 생성
sns.lineplot(x=test.index, y=pp_basic_resid, color='0.8')
plt.axhline(y=0, color='red', linestyle='--')
plt.show()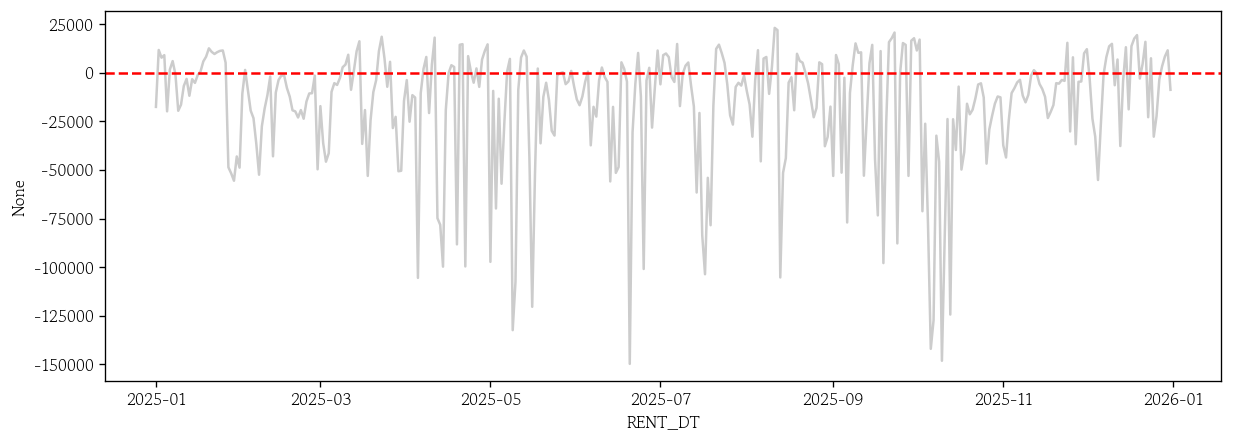
- Prophet 기본 모형 잔차 자기상관 시각화
from statsmodels.graphics.tsaplots import plot_acf
plot_acf(x=pp_basic_resid, lags=30);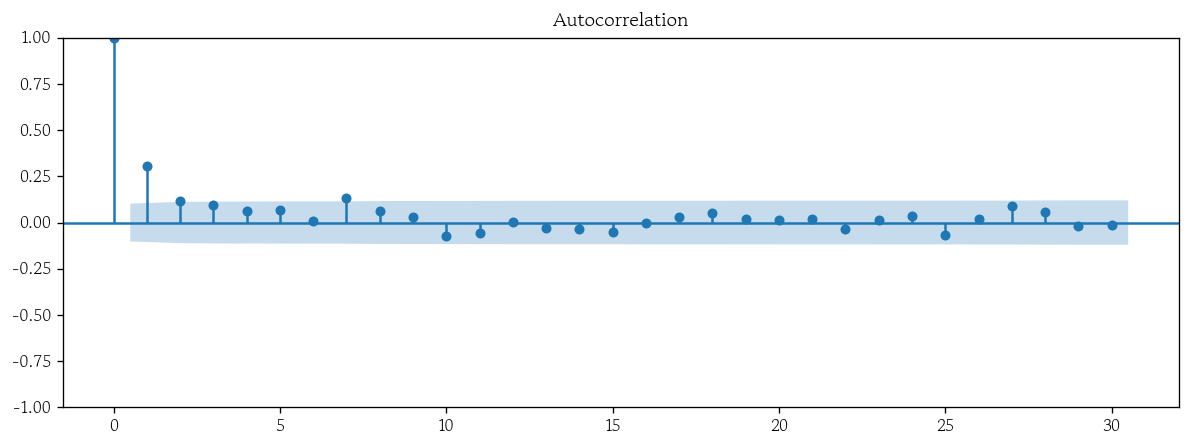
- Prophet 기본 모형 예측값 시각화
sns.lineplot(x=test.index, y=test['USE_CNT'], color='0.8')
sns.lineplot(x=test.index, y=pp_basic_pred, color='red');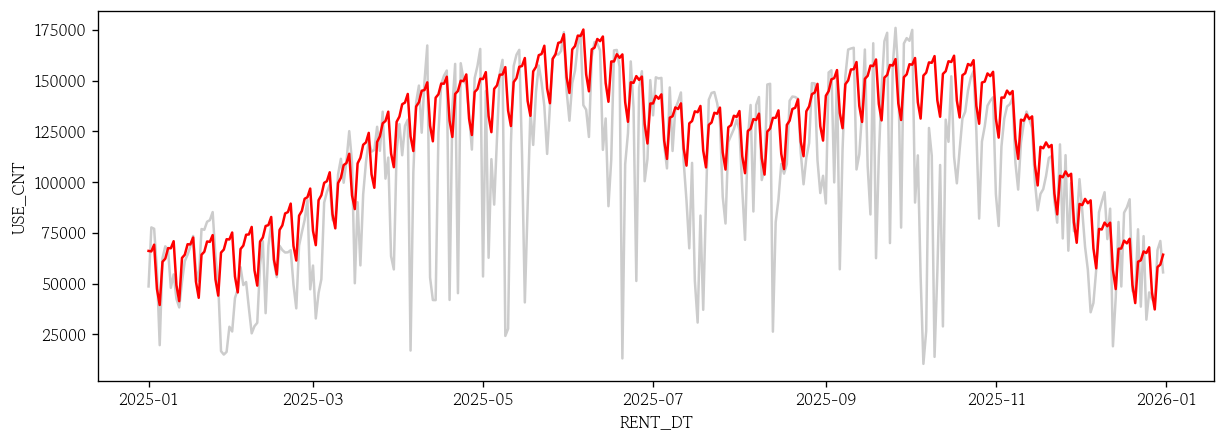
- Prophet 기본 모형 전체 예측 및 구성 요소 분해
pp_basic.plot(pp_basic_yhat, figsize=(12, 4)); # 기본 모형 전체 예측 시각화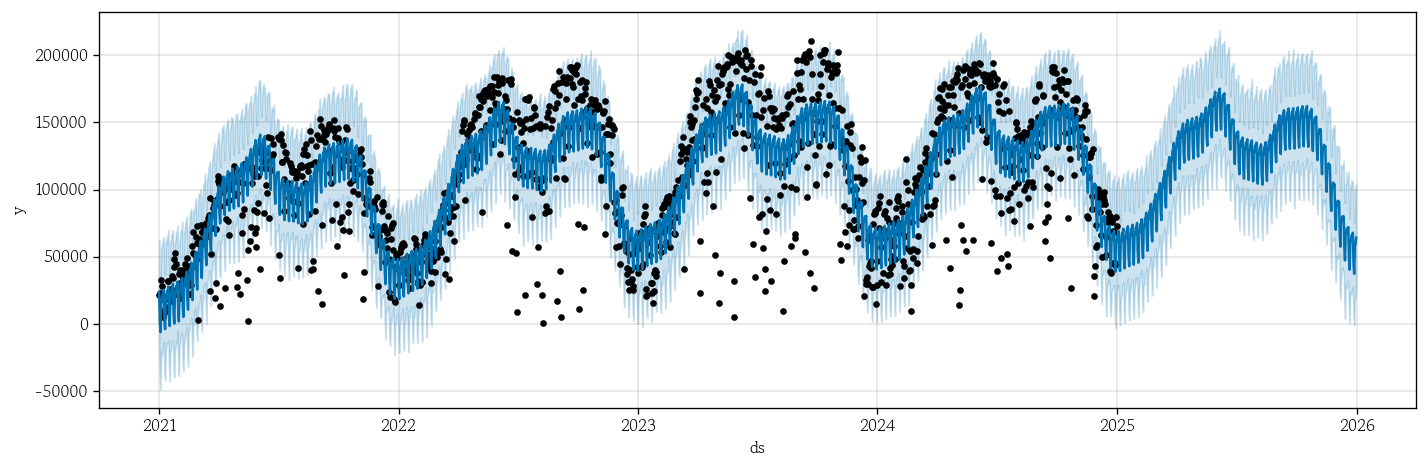
pp_basic.plot_components(pp_basic_yhat, figsize=(8, 8)); # 기본 모형 구성 요소 시각화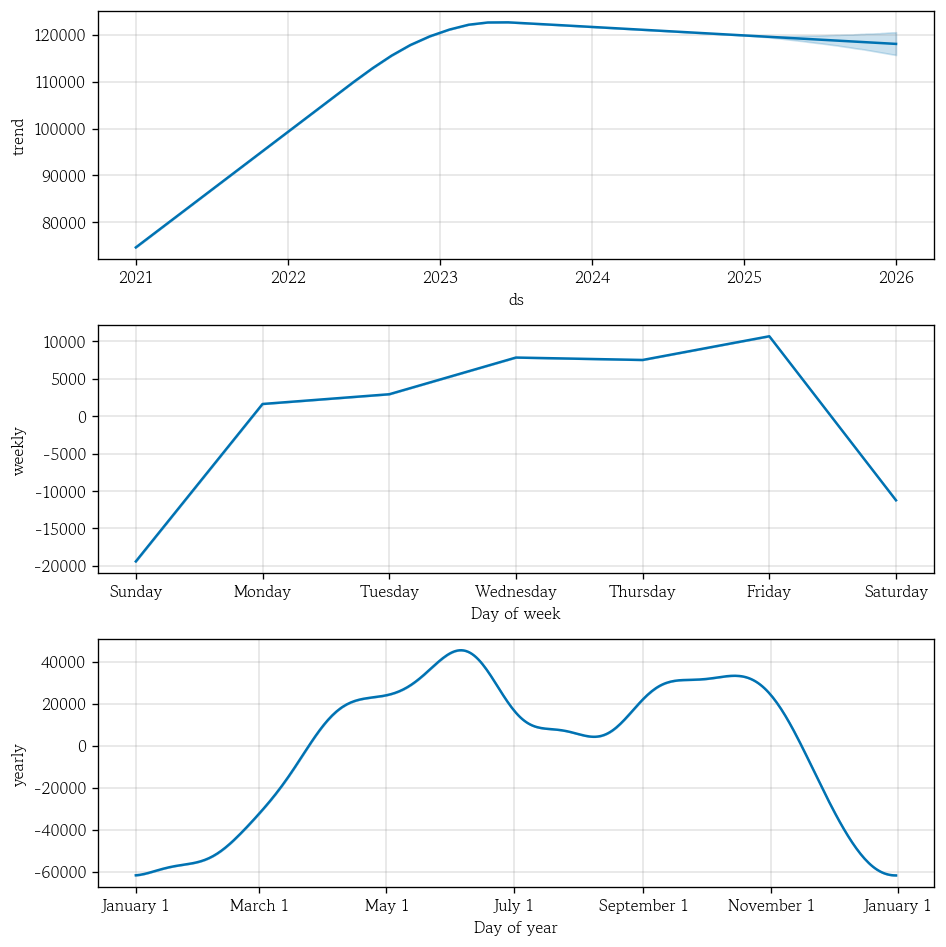
- Prophet 기본 모형 예측 성능 확인
hds.stat.regmetrics(y_true=test['USE_CNT'], y_pred=pp_basic_pred).loc[[2, 6], ['metric', 'score']].reset_index(drop=True)
# metric score
# 0 RMSE 35219.377690
# 1 MAPE 0.483998- Prophet 훈련셋에 외생변수 추가
train = pd.merge(left=train, right=exog_train, how='left', left_on='ds', right_on=exog_train.index)- Prophet 외생변수 모형 적합
pp_exog = Prophet() # 외생변수 모형 생성
# 외생변수 모형에 외생변수 추가
pp_exog.add_regressor('ta_max')
pp_exog.add_regressor('rn_sum')
pp_exog.add_regressor('hm_avg')
pp_exog.add_regressor('ss_sum')
pp_exog.fit(train) # 훈련셋으로 외생변수 모형 적합- 미래 기간 생성
pp_exog_future = pp_exog.make_future_dataframe(n_test, 'D')
exog = exog.reset_index().rename(columns={'date': 'ds'}) # 인덱스 초기화 후 컬럼명 통일하여 재할당
set(pp_exog_future.columns) & set(exog.columns) # merge 이전 중복 컬럼 확인
pp_exog_future = pd.merge(left=pp_exog_future, right=exog, how='left') # 왼쪽 병합 후 재할당- Prophet 외생변수 모형 예측값 생성
pp_exog_yhat = pp_exog.predict(pp_exog_future) # 외생변수 모형의 예측값 생성
pp_exog_pred = pp_exog_yhat.set_index('ds').loc[test.index, 'yhat'] # ds 인덱스 설정 후 예측값만 할당- Prophet 외생변수 모형 잔차 시각화
pp_exog_resid = test['USE_CNT'] - pp_exog_pred # 외생변수 모형의 잔차 생성
sns.lineplot(x=test.index, y=pp_exog_resid, color='0.8')
plt.axhline(y=0, color='red', linestyle='--')
plt.show()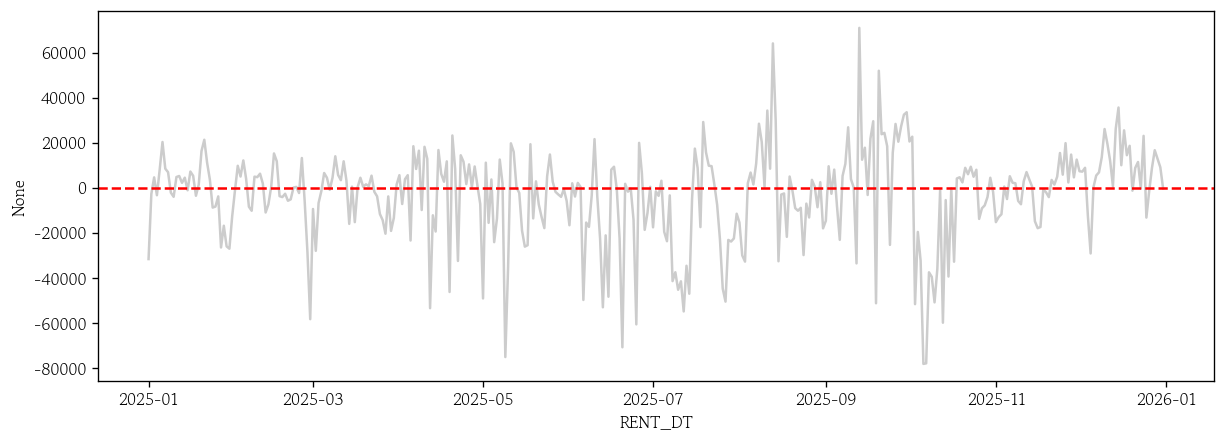
- Prophet 외생변수 모형 잔차 자기상관 시각화
plot_acf(x=pp_exog_resid, lags=30);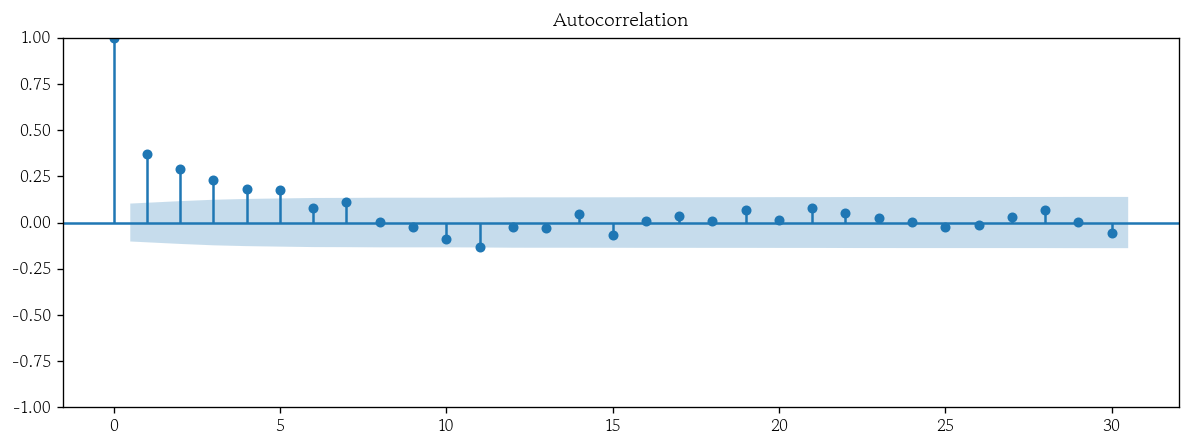
- Prophet 외생변수 모형 잔차 예측값 시각화
sns.lineplot(x=test.index, y=test['USE_CNT'], color='0.8')
sns.lineplot(x=test.index, y=pp_exog_pred, color='red')
plt.show()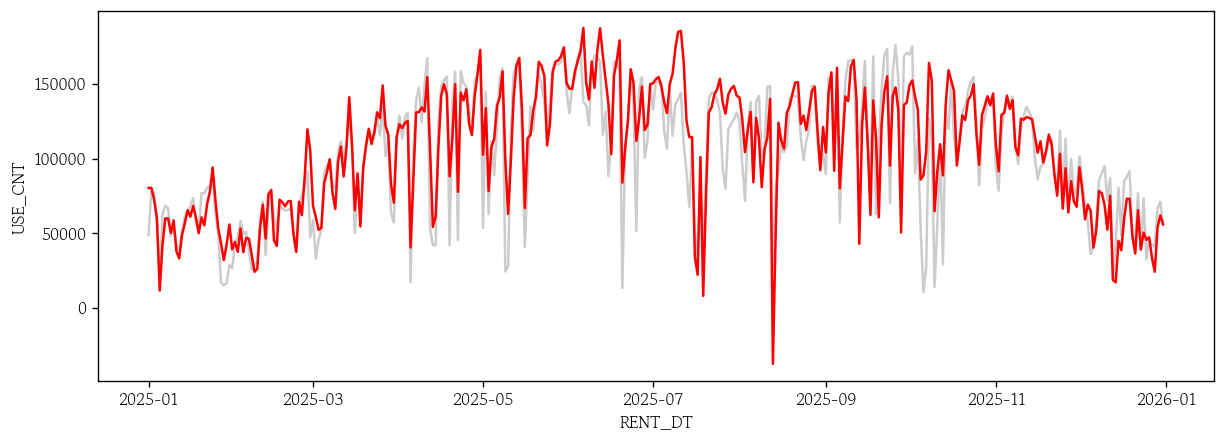
- Prophet 외생변수 모형 전체 예측 및 구성 요소 분해
pp_exog.plot(pp_exog_yhat, figsize=(12, 4))
plt.title('Prophet 외생변수 모형 전체 예측', fontweight='bold');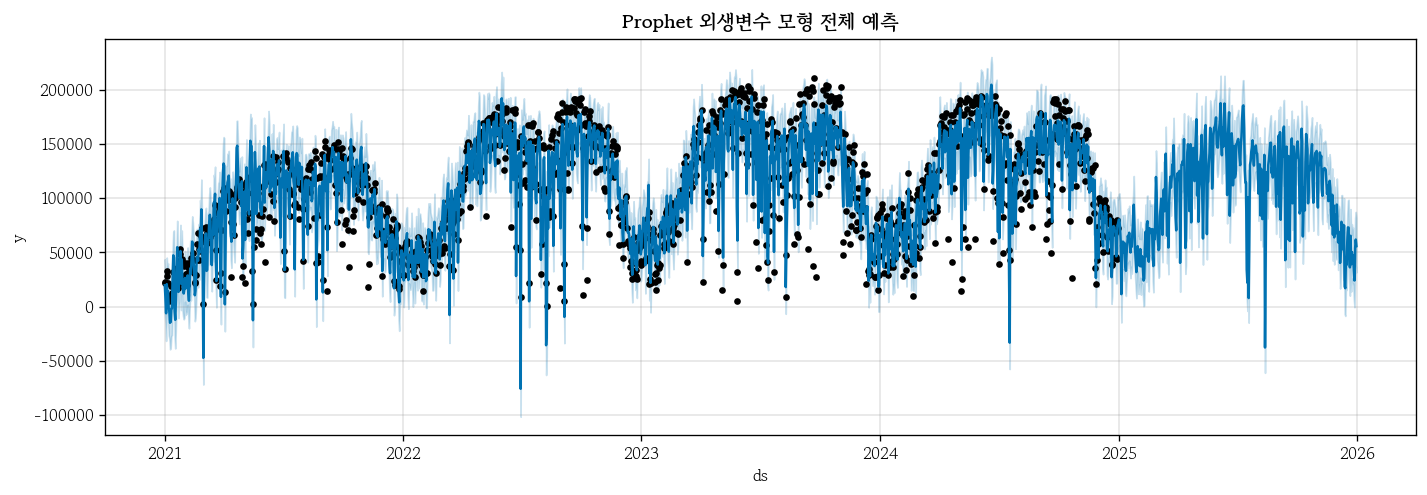
fig = pp_exog.plot_components(pp_exog_yhat, figsize=(8, 8))
fig.suptitle('Prophet 외생변수 모형 구성 요소', fontweight='bold', y=1.02);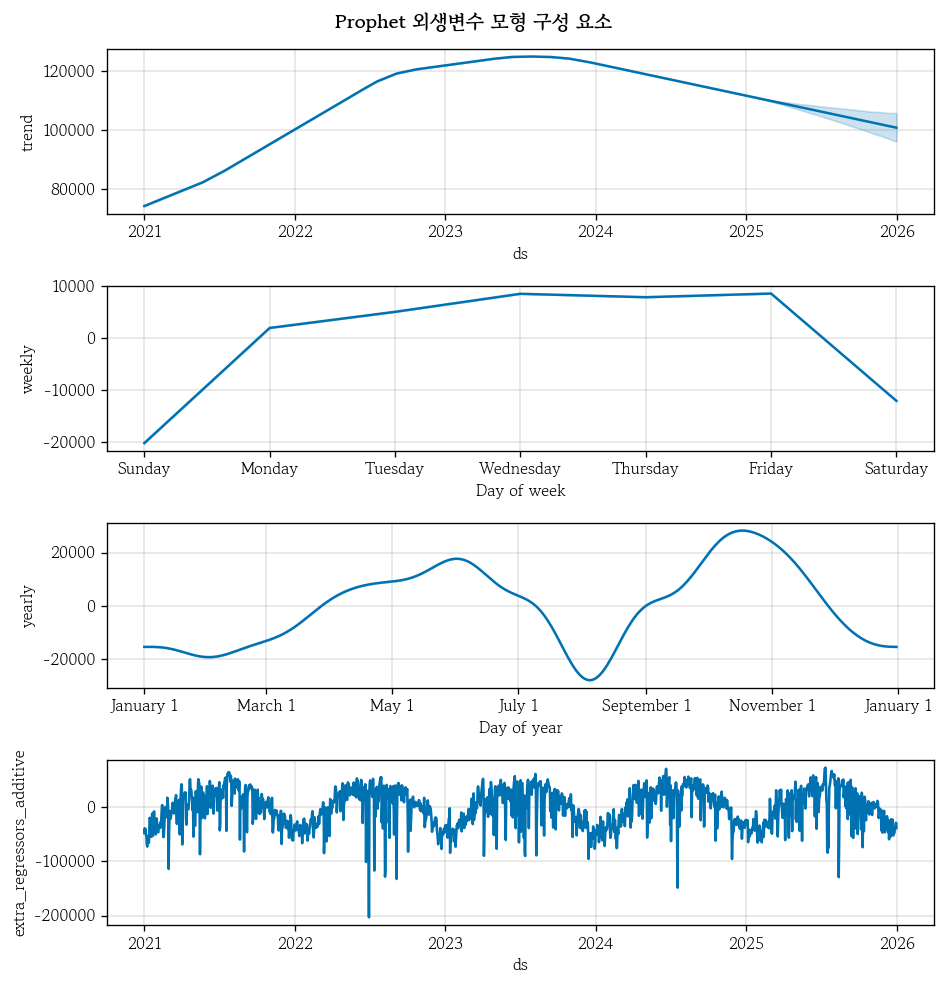
- Prophet 외생변수 모형 전체 예측 성능 확인
hds.stat.regmetrics(y_true=test['USE_CNT'], y_pred=pp_exog_pred).loc[[2, 6], ['metric', 'score']].reset_index(drop=True)
# metric score
# 0 RMSE 20827.527963
# 1 MAPE 0.247694머신러닝 모델
시계열 예측에서 머신러닝의 활용
- 머신러닝은 과거 데이터의 자기상관 구조와 외부 요인의 영향을 동시에 학습하여 예측
- 시차 변수와 이동 통계량, 시간 파생 변수 등을 통해 간접적으로 구조를 학습
- 비선형 관계를 효과적으로 포착하여 복잡한 패턴이 존재하는 시계열 데이터에 강점
XGBoost
- XGBoost 모델용 함수 정의
def make_xgb_features(target, exog=None):
df = target.copy()
df['lag_1'] = df['USE_CNT'].shift(1)
df['lag_7'] = df['USE_CNT'].shift(7)
df['roll_avg_7'] = df['lag_1'].rolling(window=7).mean()
df['roll_std_7'] = df['lag_1'].rolling(window=7).std()
df['month'] = df.index.month
df['dayofweek'] = df.index.dayofweek
if exog is not None:
df = pd.merge(left=df, right=exog, how='left', left_index=True, right_index=True)
return df- 학습 데이터 생성
xgb_train = make_xgb_features(target=train, exog=exog_train)
xgb_train = xgb_train.dropna() # 결측값 제거- 특성 행렬과 타겟 벡터로 분리
yvar = 'USE_CNT'
X_train = xgb_train.drop(columns=yvar)
y_train = xgb_train[yvar].copy()- XGBoost 회귀 모델 학습
from xgboost import XGBRegressor
xgb_model = XGBRegressor( # 회귀 모델 생성
n_estimators=100, max_depth=3,
learning_rate=0.1, subsample=0.8,
colsample_bytree=0.8, random_state=0
)
xgb_model.fit(X=X_train, y=y_train) # 모델 학습- 순차 예측 함수 정의
def xgb_recursive_forecast(train, test, exog_train, exog_test, model):
history = train.copy() # 원본 훈련셋 얕은 복사
preds = [] # 모델 예측값을 하나씩 저장할 빈 리스트 생성
for date in test.index: # 시험셋 인덱스 기준으로 반복 실행
na_row = pd.DataFrame(data={'USE_CNT': [np.nan]}, index=[date])
target_cur = pd.concat([history, na_row])
exog_cur = pd.concat([exog_train, exog_test.loc[:date]])
feat_cur = make_xgb_features(target=target_cur, exog=exog_cur)
X_cur = feat_cur.loc[[date], model.feature_names_in_].fillna(0)
yhat = model.predict(X=X_cur)[0]
preds.append(yhat)
history.loc[date, 'USE_CNT'] = yhat
xgb_pred = pd.Series(data=preds, index=test.index, name='yhat')
return xgb_pred- XGBoost 회귀 모델 예측값 생성
xgb_pred = xgb_recursive_forecast(
train=train, test=test,
exog_train=exog_train,
exog_test=exog_test,
model=xgb_model
)- XGBoost 회귀 모델 잔차 시각화
sns.lineplot(x=test.index, y=xgb_resid, color='0.8', linewidth=0.5)
plt.axhline(y=0, color='red', linestyle='--')
plt.show()
- XGBoost 회귀 모델 잔차 자기상관 시각화
from statsmodels.graphics.tsaplots import plot_acf
plot_acf(x=xgb_resid, lags=30);
- XGBoost 회귀 모델 예측값 시각화
sns.lineplot(x=test.index, y=test['USE_CNT'], color='0.8', linewidth=0.5)
sns.lineplot(x=test.index, y=xgb_pred, color='red');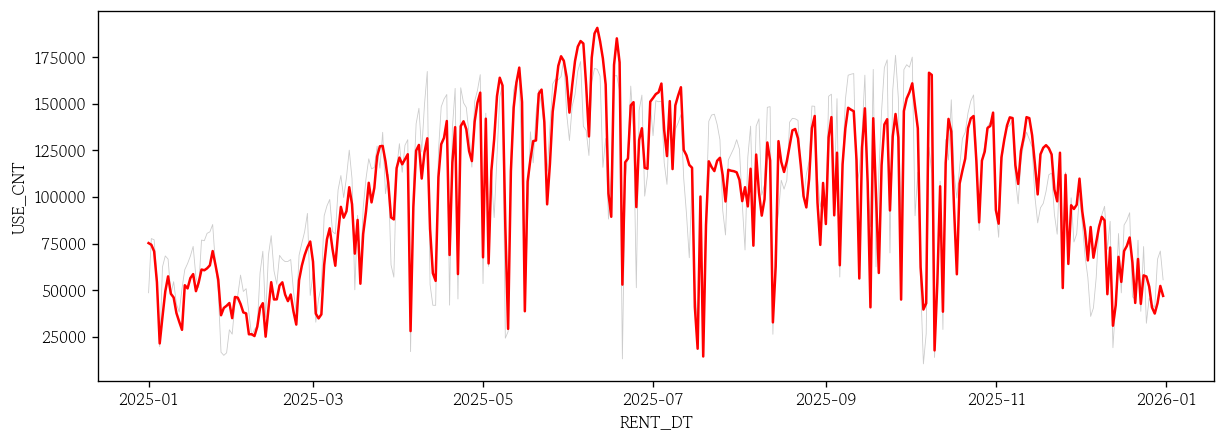
딥러닝 모델
시계열 데이터와 딥러닝 모델
- 딥러닝 모델은 입력 데이터의 순서를 그대로 유지한 채 학습
- 시간의 흐름 자체를 모델 내부에서 직접 학습
순환 신경망 - RNN
- 이전 시점의 정보를 현재 계산에 반영하는 구조를 가지는 신경망
- 현재 시점의 출력이 현재 입력과 이전 시점의 상태에 의해 결정
- 기울기 소실 문제가 발생하여 초기 시점의 정보는 거의 반영되지 않음
장단기 메모리 - LSTM
- 모든 정보를 기억하려 하지 않고, 필요한 정보만 유지 → 게이트 구조
- Forget Gate, Input Gate, Output Gate
딥러닝 모델의 시계열 입력 구조
- 머신러닝은 보통 2차원(샘플 수, 특성 수) 데이터를 입력
- 딥러닝 모델은 3차원(샘플 수, 시간 길이, 특성 수) 구조를 사용
딥러닝 기반 시계열 분석의 특징
- 충분한 데이터가 확보되지 않으면 모델이 과적합하기 쉬움
- 하이퍼파라미터 튜닝이 까다로움
마치며
오늘로 머신러닝, 딥러닝 파트가 모두 끝났다. 동시에 이번 교육을 함께한 강사님께서도 오늘이 마지막 수업이었다. 너무 좋은 강사님을 만나 정말 행운이었고 아쉬움도 큰 하루였다.

Hello I'm TaeHyunAn, Currently Studying Data Analysis