안녕하세요. 이번 논문리뷰는 DenseNet(Densely Connected Convolutional Networks)입니다. DenseNet은 2017년에 발표된 논문으로 CVPR에 best paper를 받아았습니다. 그러면 DenseNet이 어떻게 best paper를 받을 수 있었는지, 그리고 어떤 구조와 특징을 가지고 있는지 논문을 통해 살펴보도록 하겠습니다.
Back Ground
우선 2017년 논문이 발표 될 시기의 CNN들의 특징들에 대해서 살펴보자면, 당시 CNN의 연구가 구조적으로 더 깊고(예를 들어 VGG), 더 정확한 성능을 낼 수 있는 방법에 대해서 input layer와 output layer가 direct하게 연결 될 수 있는 shorter connection(ResNet) 개념에 집중하여 효율적인 훈련하는 방식으로 발전하고 있었습니다. 따라서 이 논문은 당시 연구주제에 초점을 맞추어 feed forward 방식에서 각 레이어들이 모든 다른 레이어와 connect를 두는 DenseNet을 소개합니다. 이제까지는 layer가 그 다음 하위 레이어와의 연결 구조를 갖는 CNN과는 달리 DenseNet은 L(L+1)/2개의 direct connection을 갖는 새로운 구조입니다. 즉 앞 layer에서 얻은 모든 feature map은 계속해서 뒤 layer의 입력으로 입력되는 구조입니다.
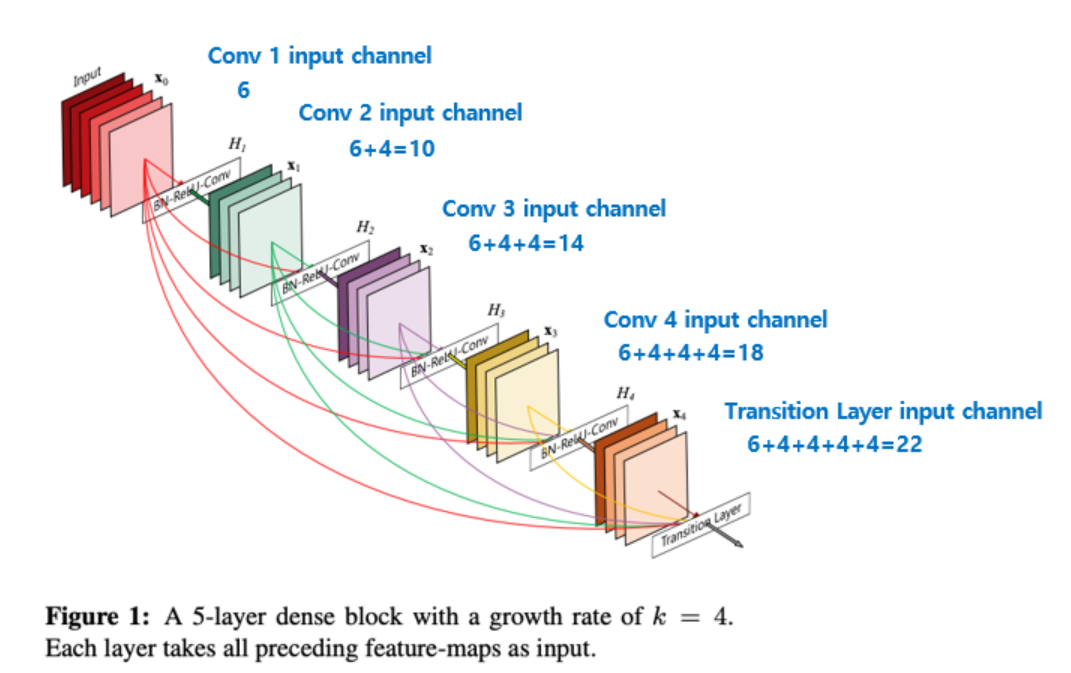
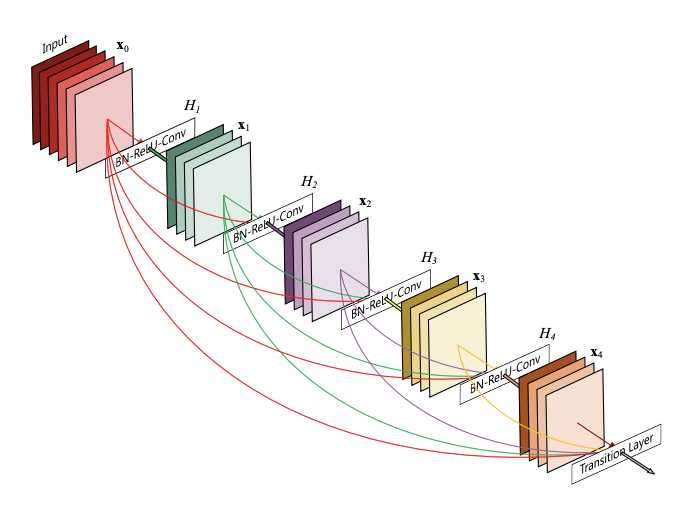
그림1. DenseNet 구조
기존 ResNet의 문제점
전통적인 Convolution Network의 모델을 식으로 표현 해 보자면
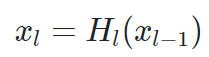
이라고 할 수 있습니다.
이전 레이어에서 Conv layer을 포함한 합성함수의 Output을 다음 레이어로 넘기는 형태입니다.
ResNet은 기존 Conv layer가 너무 많이 쌓이게 되면 필터를 너무 많이 거치게 되어서 모델이 한참 이전의 레이어와 이후의 레이어 간의 의미있는 논리를 합해서 전개하지 못한다는 것을 해결하기 위해 이전 레이어에서 다음 레이어를 바로 이어주는 추가적인 Connection을 만들어 주었습니다.
ResNet은 이를 식으로 다음과 같이 표현하였습니다.
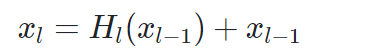
하지만 이전 레이어의 output을 다음의 레이어의 output과 합해서 더한다는 점에서, 정보들이 이후의 레이어들로 온전히 흘러가는 것을 방해할 수 있다는 약점이 있었습니다.
DenseNet의 해결책
DenseNet은 앞서 말한것 처럼 기존의 CNN구조와 달리 Direct connection을 사용해서 위의 문제들을 해결할 수 있었습니다.
해당 논문에서는 DenseNet이 4가지 장점이 있다고 소개했습니다.
1. vanishing gradient를 방지할 수 있다.
2. feature propagation을 강화할 수 있다.
3. feature의 재사용이 권장된다.
4. 파라미터 수를 많이 줄일 수 있다.
먼저 1,2,3번 장점부터 한번에 살펴보도록 하겠습니다.
기존의 CNN 모델은 처음 레이어의 피쳐맵이 다음 레이어의 입력값으로 전달됩니다. 많은 레이어를 통과하여 신경망의 끝에 다다르면, 처음 레이어의 피쳐맵에 대한 정보는 사라질 수 있습니다. 이것을 feature reuse 문제라고 합니다. DenseNet은 처음 레이어의 피쳐맵을 마지막 레이어의 피쳐맵까지 연결합니다. 따라서 정보가 소실되는 것을 방지합니다. 오차 역전파법을 진행하다 보면 초기의 gradient는 소실될 수 있습니다. 초기 값을 마지막으로 직접적으로 전달하므로 오차 역전파를 진행할 때도, 값이 직접적으로 전달됩니다. 따라서 기울기 소실 문제도 완화합니다. 다양한 레이어의 피쳐맵을 연결해서 학습되기 때문에 정규화 효과도 있다고 합니다.
다음은 4번 장점입니다.
DenseNet은 적은 채널수를 이용합니다. 각 레이어의 피쳐맵을 연결하여 다음 레이어로 전달하면, 적은 채널 수의 피쳐맵을 생성합니다. 그리고 이 피쳐맵은 이전 레이어의 피쳐맵과 결합하여 다음 레이어로 전달됩니다. 따라서 파라미터 수가 적습니다.
DenseNet구조
1. ResNet connectivity
DenseNet을 ResNet과 비교하여 설명합니다. ResNet의 l번째 레이어 출력값은 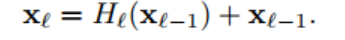 이 됩니다. H()는 conv, bn, relu 함수의 연산을 의미합니다. 그리고 + xl-1은 skip connection에 의한 덧셈입니다. 이 경우에 레이어의 입력값이 출력값에 더해져 gradient flow가 직접적으로 전달됩니다. 하지만 덧셈으로 결합되기 때문에 신경망에서 정보 흐름(information flow)이 지연될 수 있다고 합니다.
이 됩니다. H()는 conv, bn, relu 함수의 연산을 의미합니다. 그리고 + xl-1은 skip connection에 의한 덧셈입니다. 이 경우에 레이어의 입력값이 출력값에 더해져 gradient flow가 직접적으로 전달됩니다. 하지만 덧셈으로 결합되기 때문에 신경망에서 정보 흐름(information flow)이 지연될 수 있다고 합니다.
2. Dense connectivity
DenseNet은 이전 레이어를 모든 다음 레이어에 직접적으로 연결합니다. 따라서 정보 흐름(information flow)가 향상됩니다.
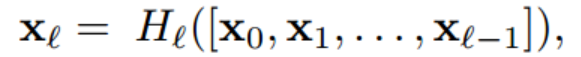
위 수식 처럼 이전 레이어 x0,,,,xl-1가 다 결합되어 H() 연산을 수행합니다. DensNet에서 H() 함수는 BN, ReLU, 3x3 conv입니다. pre-activation resnet의 순서를 따랐습니다.
3. Dense Block
연결(concatenation) 연산을 수행하기 위해서는 피쳐맵의 크기가 동일해야 합니다. 하지만 피쳐맵 크기를 감소시키는 pooling 연산은 conv net의 필수적인 요소입니다. pooling 연산을 위해 Dense Block 개념을 도입합니다. Dense Block은 여러 레이어로 구성되어 있습니다. Dense Block 사이에 pooling 연산을 수행합니다. pooling 연산은 BN, 1x1conv, 2x2 avg_pool로 수행합니다. 그리고 이를 transition layer이라고 부릅니다.
transition layer에는 theta 하이퍼 파라미터가 존재합니다. theta는 transition layer가 출력하는 채널 수를 조절합니다. transition layer의 입력값 채널 수가 m이면 theta * m 개의 채널수를 출력합니다. 1x1 conv에서 채널 수를 조절하는 것입니다. 논문에서는 theta=0.5를 사용하여 transition layer의 출력 채널 수를 0.5m으로 합니다. 즉, transition layer는 피쳐 맵의 크기와 채널 수를 감소시킵니다.
아래 그림을 보면 DenseNet은 3개의 Dense Block과 2개의 transition layer로 이루어져 있습니다.

그림2. DenseNet의 Block과 Trainsition layer
4. Growth rate
Dense Block 내의 레이어는 k개의 피쳐 맵을 생성합니다. 그리고 이 k를 Growth rate라고 부르는 하이퍼파라미터 입니다. 논문에서는 k=12를 사용합니다. l번째 레이어는 k0 + k * (l-1) 개의 입력값을 갖습니다. k0은 입력 레이어의 채널 수 입니다. 이 Growth rate는 각 레이어가 전체에 어느 정도 기여를 할지 결정합니다.
5. Bottleneck layers
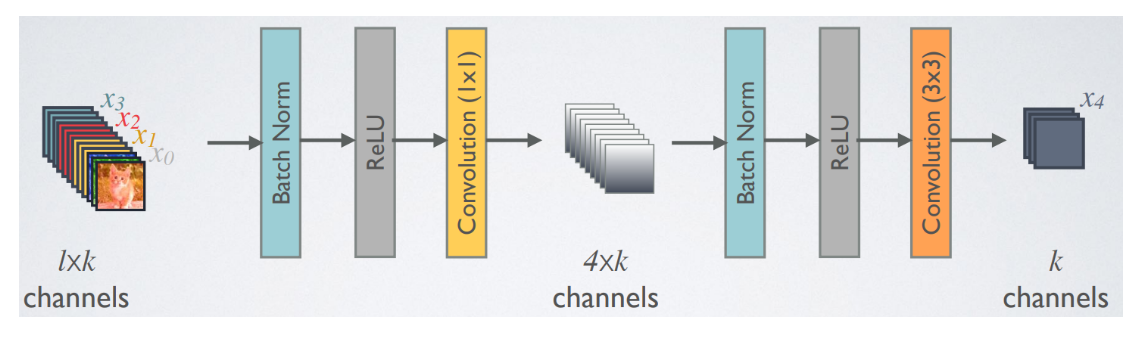
DenseNet은 Bottleneck layer를 사용합니다. 보틀넥 레이어는 3x3 conv의 입력값 채널을 조절하여 연산량에 이점을 얻기 위해 사용됩니다. 1x1 conv는 3x3 conv의 입력값을 4k로 조절합니다. 그리고 3x3 conv는 k개의 피쳐맵을 생성하고 이전 레이어와 연결됩니다.
3x3 convolution 전에 1x1 convolution을 거쳐서 입력 feature map의 channel 개수를 줄이는 것 까지는 같은데, 그 뒤로 다시 입력 feature map의 channel 개수(위 그림의 예에서는 256개) 만큼을 생성하는 대신 growth rate 만큼의 feature map을 생성하는 것이 차이 점이며 이를 통해 computational cost를 줄일 수 있다고 합니다.
또한 구현할 때 약간 특이한 점이 존재하는데 DenseNet의 Bottleneck Layer는 1x1 convolution 연산을 통해 4*growth rate 개의 feature map을 만들고 그 뒤에 3x3 convolution을 통해 growth rate 개의 feature map으로 줄여주는 점이 특이하다.(256개가 아닌 k개, 앞에서 한번 언급했었음) Bottleneck layer를 사용하면,_ 사용하지 않을 때 보다 비슷한 parameter 개수로 더 좋은 성능을 보임을 논문에서 제시하고 있습니다.
다만 4 * growth rate의 4배 라는 수치는 hyper-parameter이고 이에 대한 자세한 설명은 하고 있지 않고있습니다.
6. Composite Function
DenseNet은 ResNet의 구조에 대해 분석한 “Identity mappings in deep residual networks, 2016 ECCV” 논문에서 실험을 통해 제안한 BatchNorm-ReLU-Conv 순서의 pre-activation 구조를 사용하였다.(이 부분은 ResNet에서 사용했었던 것과 동일하다.)
7. DenseNet Architecture
앞서 설명한 부분을 한번에 보여준다.

위 그림은 최초 input으로부터 하나의 Dense Block과 Transition Layer을 거칠 때까지의 구조입니다.
Dense Block에서 초록색 사각형과 검은색 사각형이 Bottleneck layer를 만들며 그림에서는 Bottleneck layer가 3개가 모여있다. Dense Block내의 Bottleneck layer는 깊이가 깊어질수록 concatenation되는 것을 볼 수 있습니다.
Dense Block이 끝나고 Transition Layer가 연결되어 있음을 알 수 있습니다.
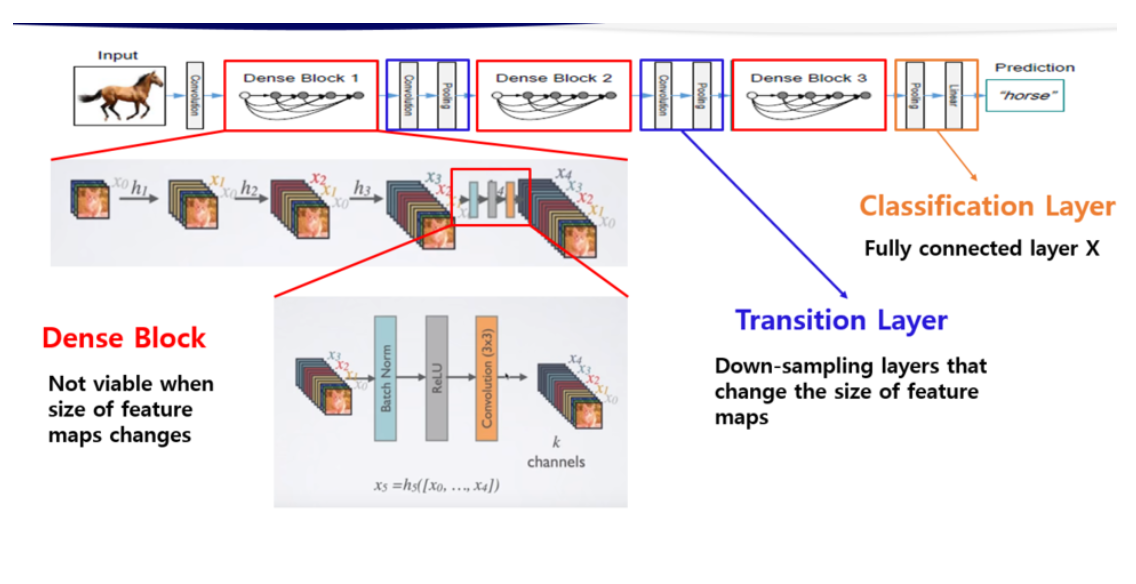
위 그림은 DenseNet 전체의 구조를 나타내었다. Input이 있고 Dense block 다음에 Transition layer가 연결되어 있으며 마지막 Dense block 다음에는 Transition layer가 아닌 Classification layer가 연결되어 있는 것을 알 수 있다. Classification layer를 거쳐서 최종적인 output인 예측값이 나온다.
Dense block에는 이전 layer의 input 정보들이(h0 ~h1) concatenation되고 있는 것을 볼 수 있고, Dense block내의 layer들은 Composite function에 의해 Batch Norm.-ReLU-Conv로 구성되어 있다. 그림에는 적용이 안되어져 있는데 Bottleneck이 적용이 되면 Batch Norm.-ReLU-Conv(1X1)-Batch Norm.-ReLU-Conv(3X3)의 구조가 된다.
아래 그림처럼 될 것이다.
마무리
오늘은 이렇게 DenseNet에 대해서 알아보고 살펴보았습니다. 처음에 DenseNet의 아이디어를 보고 어떻게 파라미터수가 줄일 수 있었던 것인지 의아했는데, 논문리뷰를 하면서 잘 이해할 수 있었던것 같습니다.
참고
csm-kr님 티스토리
lighthouse97님 벨로그
gaussian37님 블로그
inhovation97님 티스토리
딥러닝 공부방 티스토리
논문
