오늘 알아볼 논문리뷰는 MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Application입니다. 다들 Mobile이라는 단어에 대해서 들어보셨을 것이라 생각하는데요. Mobile이라는 뜻은 "움직(이동)일 수 있는"의 의미를 가지고 한국에서는 모통 Mobile이라 함은 휴대용 핸드폰을 부르는 대명사이기도 합니다. 즉 MobileNet은 매우 경량화된 CNN 모델입니다. 앞서서 알아봤던 Xception의 경우 Depthwise separable convolution을 활용해 감소한 파라미터 수 많큼 층을 쌓아 올리면서 성능을 높이는데 집중했습니다. 반면 MobileNet은 경량화에 집중하였는데, 어떻게 모델 경량화를 이룰 수 있었는지 알아보도록 하겠습니다.
먼저 MobileNet은 왜 경량화에 집중하였을까요?
그 이유는 바로 핸드폰이나 임베디드 시스템 같이 저용량 메모리환경에 딥러닝을 적용하기 위해선 모델 경량화가 필요하기 때문입니다. 메모리가 제한된 환경에서는 MobileNet을 최적으로 맞추기 위해 두 개의 파라미터를 소개합니다. 두 파라미터는 Latency와 Accuracy의 균형을 조절합니다. 우선적으로 MobileNet의 경량화를 성공을 알기 위해서는 Depthwise separable convolution의 이해가 필요합니다. 우선 Depthwise separable convolution에 대해서 알아보도록 하겠습니다.
Depthwise Separable Convolution
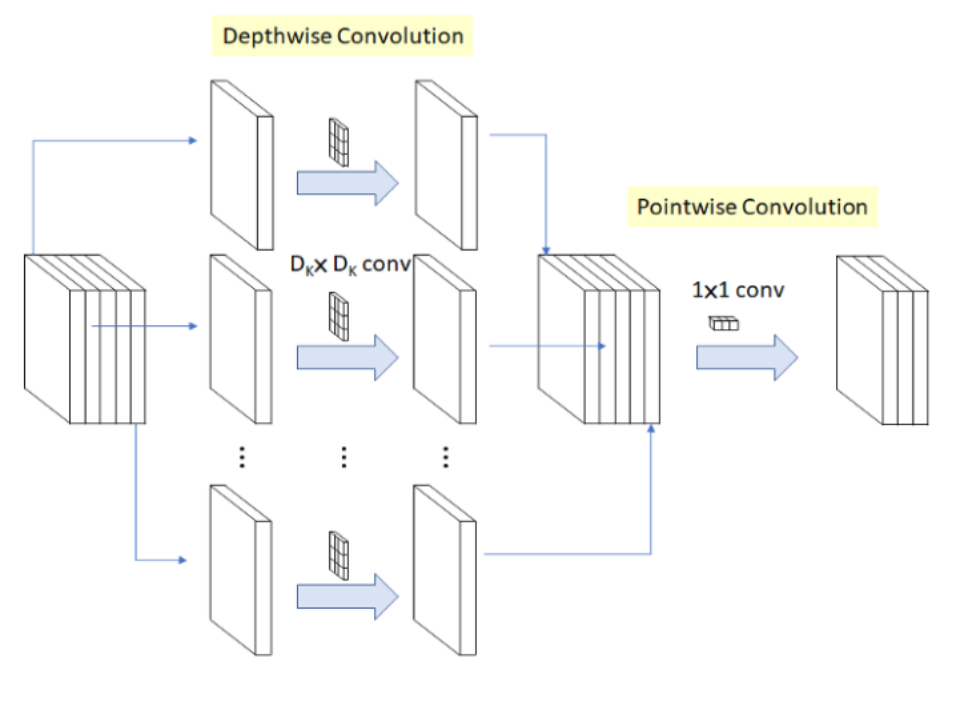
Depthwise Separable Convolution은 Depthwise Convolution 이후에 Pointwise Convolution을 결합한 것입니다. 아래 그림을 살펴보겠습니다.
그림1. Depthwise Separable Convolution
Depthwise Convolution
Depthwise Convolution의 경우 각 입력 채널에 대하여 3x3 Conv 하나의 필터가 연산을 수행하여 하나의 피쳐맵을 생성합니다. 입력 채널 수가 M개이면 M개의 피쳐맵을 생성하는 것이죠. 각 채널마다 독립적으로 연산을 수행하여 Spatial Correlation을 계산을 하는것이죠. 예를들어 10개의 채널의 입력값이 입력되었다면, 10개의 3x3 Conv가 각 채널에 대하여 연산을 수행하고, 10개의 Feature Map을 생성합니다.
Depthwise Convolution의 연산량은 다음과 같습니다.
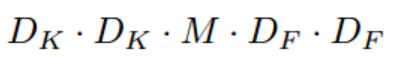
Dk: 입력값 크기
M: 입력 채널 수
DF : 피쳐맵 크기
Pointwise convolution
Pointwise convolution은 Depthwise convolution이 생성한 피쳐맵들을 1x1 Conv로 채널수를 조정하는 작업을 말합니다. 이 때 1x1 Conv 는 모든 채널에 대하여 연산하므로, Cross-channel Correlation을 계산하게 되는것이죠.
Pointwise convolution의 연산량은 다음과 같습니다.
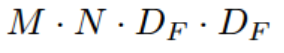
M: 입력 채널 수
N : 출력 채널 수
DF : 피쳐맵 크기
그렇다면 Depthwise Separable Convolution의 전체 연산량은 어떻게 될까요? 바로 Depthwise Convolution의 연산량과 Pointwise convolution의 연산량의 합이 되는 것입니다.
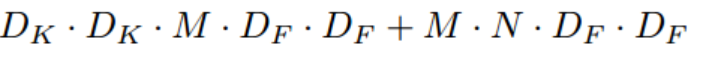
그림3. Depthwise Separable Convolution의 연산량
반면 일반적인 Conv연신을 하는 구조와 비교하였을 경우 연산량의 차이가 얼마나 날까요? Depthwise Separable Convolution은 기존 Conv연산과 비교하였을 때 약 8~9배(Dk을 3으로 사용하기 때문임) 적은 연산량을 가집니다. 이때 기존의 Conv 연산의 연산량은 다음과 같습니다.
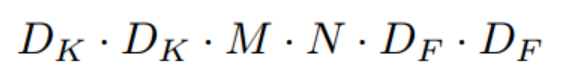
Depthwise Separable Convolutions 구조
아래에서 왼쪽은 일반적인 standard conv 이고 오른쪽이 논문에서 제시하는 depthwise separable conv 입니다.
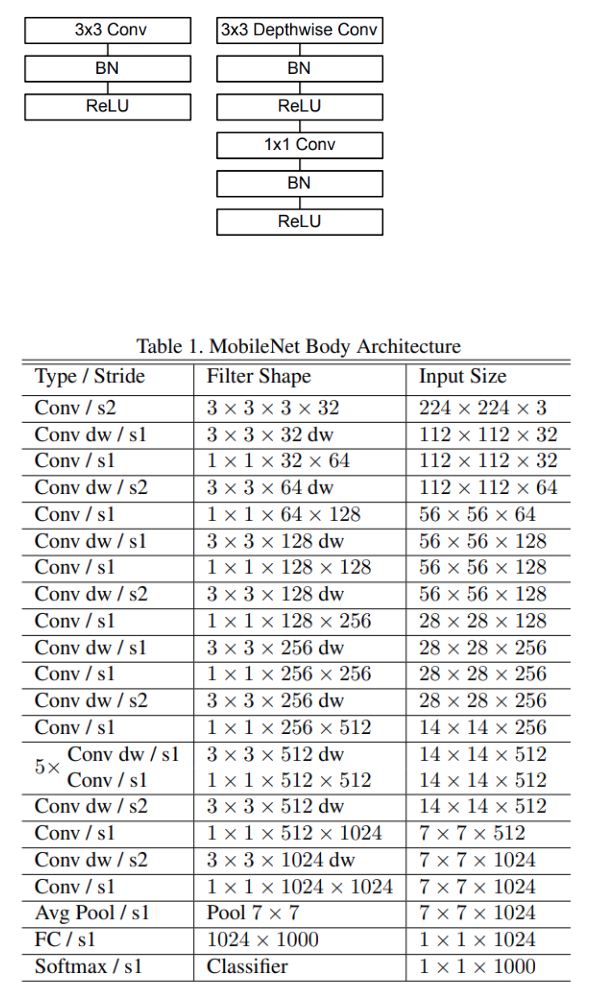
전체적인 구조를 살펴보면 224x224x3 이미지에 대해 첫번째 레이어는 standard conv를 사용하고 그 이후부터 depthwise conv 와 pointwise conv를 번갈아 가면서 수행합니다. feature-map의 사이즈는 S2(stride=2)로 해서 크기를 절반으로 줄여주고 채널수(필터의 수)는 pointwise conv 레이어에서 지정해줍니다.
feature-map의 크기가 7 x 7 x 1024가 되면 global avg-pooling을 이용하여 1x1x1024 로 만들고 한개의 FC레이어와 softmax를 통해 최종적으로 1 x 1 x 1000이 됩니다. (1000은 ILSVRC 대회의 클래스(*라벨) 개수)
논문에서는 아래와 같이 위에 나온 구조의 각각의 레이어에 대한 파라미터 분포를 계산을 하였습니다. 초반에 일반적인 CNN구조에서는 FC layer가 전체 파라미터의 90%정도를 차지한다고 설명하였는데 아래를 보면 FC layer가 아닌 Conv 1 x 1 layer의 파라미터가 74.59%로 훨씬 많다는 것을 알 수 있고 이말은 즉슨 그만큼 파라미터 수가 줄어들었다는 의미가 됩니다.
Width Multiplier & Resolution Multiplier
논문에서는 Depthwise Separable Convolution 말고도 두가지의 옵션을 추가하였는데 바로 Width Multiplier 와 Resolution Multiplier 입니다.
1) Width Multiplier : Thinner Models
기본 MobileNet alchitecture은 이미 작고 지연시간이 짧지만 특장 사용 사례 또는 애플리케이션에 따라 모델이 더 작고 더 빨라야 하는 경우가 많습니다. 이러한 경우에는 Width Mulitplier α 라고 하는 매우 간단한 α매개변수 를 도입합니다. Width Muliplier 는 MobileNet의 두께를 결정합니다. conv net에서 두께는 각 레이어에서 필터수를 의미합니다. 이 width Multiplier α 는 더 얇은 모델이 필요할 때 사용합니다. 입력채널 M과 출력채널 N에 적용하여 αM ,αN 이 됩니다. 따라서 연산량은 다음과 같습니다.
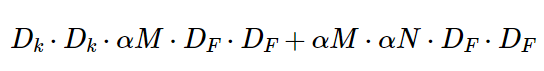
여기서 이며 1, 0.75, 0.5, 0.25가 일반적인 설정입니다.
기준 MobileNet은 α = 1이고 α < 1 이면 감소된 MobileNet입니다.
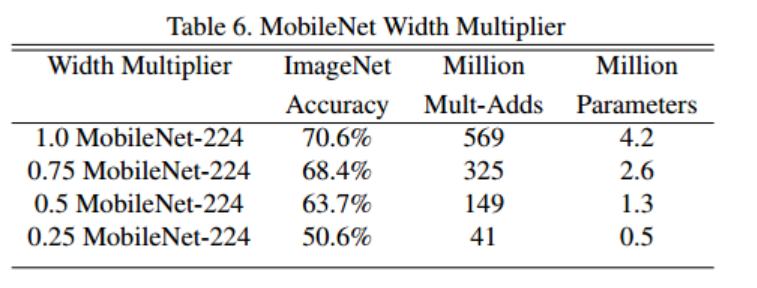
2) Resolution Multiplier : Reducted Representation
두 번째 Resolution Multiplier ρ는 신경망의 계산비용을 줄이기 위한 파라미터입니다. ρ는 입력 이미지에 적용하여 해상도를 낮춥니다. 범위는 ρ ∈(0,1]이고 네트워크의 입력 해상도는 224, 192, 160 또는 128입니다. MobileNet의 기준은 ρ =1 이고 ρ < 1은 축소 계산 MobileNet입니다.
Resolution multiplier은 ρ^2만큼 줄이는 효과가 있습니다.
다른 모델과 성능 비교
기본MobileNet, GoogleNet, VGG16과 비교해봅시다.
MobileNet은 VGG16만큼 정확성을 나타내지만 32배 더작고 27배 계산이 적습니다. 또한 GoogLeNet보다 정확하지만 더작고 계산량이 2.5배이상 적습니다.
α =0.5 , 해상도 160x160으로 감소된 MobileNet과 Squeezenet, AlexNet을 비교합니다.
축소된 MobileNet은 AlexNet보다 4% 더 우수하고 AlexNet보다 45배 작고 계산량이 9.4배 적습니다.
또한 Squeezenet은 동일한 크기지만 Squeezenet보다 4% 더 우수합니다.
마무리
오늘은 경량화 모델인 MobileNet이 Depthwise Separable Convolutions 과 Width Multiplier & Resolution Multiplier 파라미터를 사용해서 모델의 경량화를 이룰 수 있던것을 알아보았습니다. 개인적으로 이번 논문리뷰를 통해 Xception 논문리뷰를 할 때 헷갈리던 부분을 잫 이해 할 수 있는 그런 시간이 되어서 뿌듯합니다. 읽어주셔서 감사합니다.
