안녕하세요. 이번에 리뷰 해볼 논문은 SqueezeNet(SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size) 입니다. Squeeze라는 단어에서 알 수 있듯이 해당 논문은 모델 압축에 초점을 둔 모델입니다. 해당 논문에서는 1x1 filter를 잘 활용항녀 Squeeze와 Expand 기능을 만들어 내었고, 그 기능이 들어간 fire module 이라는 것을 이용해 AlexNet과 비슷한 성능을 내면서 parameter는 50배 이상 줄인 효과적인 모델입니다. 해당 논문은 기존에 CNN의 성능 발전에 맞춰서 리뷰한 ResNet ,DenseNet과는 방향이 다른 모델입니다. 왜냐하면 AlexNet(SqueezeNet과 비슷한 정확도를 가지고 있기 때문에)이 2012년에 발표되어 기존의 방법들을 제치고 매우 큰 차이로 ImageNet Challenge에서 우승을 하였지만, SqueezeNet이 발표된 2017년에는 그렇게 정확도가 높지는 않았습니다. 하지만 모델의 가벼울수록 정확도가 떨어질 수 밖에 없다는 것이라 생각합니다.
또한 SqueezeNet은 매우 적은 수의 파라미터를 사용했단 것 뿐만 아니라, 하이퍼 파라미터의 조합에 따라 성능과의 상관관계를 확인한 것 또한 큰 의미가 있다고 생각합니다. 그렇다면 SqueezeNet이 어떻게 이렇게 적은 파라미터 수로 AlexNet만큼의 성능을 낼 수 있었는지 알아보도록 하겠습니다.
Background
먼저 SqueezeNet이 탄생하게 된 배경을 살펴보자면, 시간이 지날수록 딥러닝 네트워크의 Accuracy 성능이 좋아지고 있는 반면 모델의 사이즈는 점점 커지는 문제가 있었습니다. 하지만 PC레벨이 아닌 다양한 어플리케이션에서 딥러닝 모델을 사용하려면 사이즈가 클 경우 사용하기 어렵다는 문제가 있습니다. 이러한 배경속에서 quantization이나 모델 경량화 쪽으로 Focus가 맞춰지게 되었습니다.
Related Works
Micro Architecture
- 1x1 convolution
해당 논문에서는 1x1 convolution filter가 channel 방향의 multi-layer perceptron과 같은 역할을 한다고 합니다. 1x1 convolution의 경우 각각의 채널에 element-wise로 multiplication 한 후에 합하게 되므로 이 연산은 채널 방향의 multi-layer perceptron 즉, FC layer와 같다는 뜻입니다.
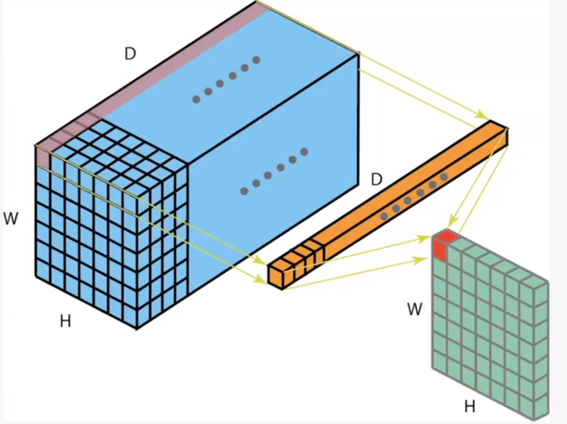
그림1. 1x1 conv filter의 channel방향의 multi-layer perceptron 역할 - 3x3 convolution
그 이후로 어떤 필터를 사용할 것인가 연구가 진행되었는데, 5x5 convolutional filter가 4개의 3x3 convolution filter로 분해된다는 뜻입니다.
해당 방법의 효과는 1개의 layer의 5x5 filter가 2개의 3x3 filter로 대체될 수 있다는 것입니다.
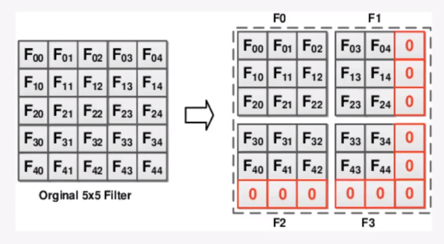
그림2. 5x5 필터의 3x3 필터로의 인수분해 - skip connection
마지막으로 skip connection의 관점은 앞서 살펴본 ResNet과 Segmentation에서 볼 수 있습니다. Segmentation에서의 skip connection을 살펴보면 resolution 정보가 굉장히 중요한데 depp layer로 내려갈수록 resolution 정보가 맞지 않는 문제가 있습니다. 이러한 문제를 해결하기 위해 skip connection을 이용하여 deep layer에도 resolution 정보를 전달해 줍니다. ResNet에서 같은 컨셉으로 사용되었고 특히 layer가 깊어질수록 발생할 수 있는 vanishing gradient 문제를 skip connection을 통하여 개선한 것이 의미가 있습니다.
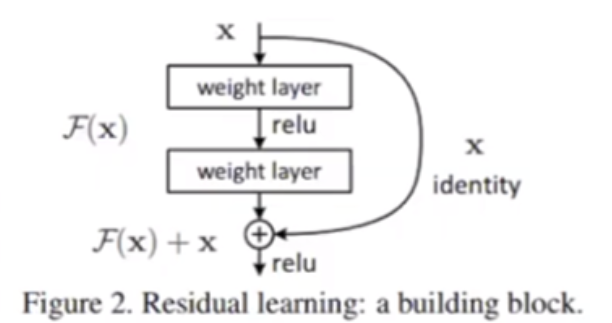
그림3. ResNet의 Skip connection
Macro Architecture
- block
인셉션, 모바일넷, 셔플넷 등에서 어떤 단위의 block들을 쌓아서 네트워크 전체를 구성하는 것과 같이 스퀴즈넷에서도 유사한 개념이 사용됩니다.
Architecture
- 3x3 filter를 1x1 filter로 대체
=> 파라미터 수를 9배로 절약 - 3x3 filter의 input channel 수를 줄임
=> 3x3 filter 개수 뿐만 아니라, input channel도 줄여서 파라미터 수를 줄이는 방법
Conv Layer의 파라미터 계산 공식
(kernel) x (kernel) x (number of input channel) x (number of filter) - Conv layer가 큰 넓이의 Activation Map을 가지도록 Down Sample을 늦게 수행함
일반적인 CNN Network는 Pooling으로 downsampling하면서 이미지의 정보를 압축해 나감
- 큰 activation map을 가지고 있을수록 정보 압축에의한 손실이 적어 성능이 높음
- 정보 손실을 줄이기 위해 네트워크 후반부에 downsampleing을 수행
전략 1번과 2번은 정확도를 유지하면서 파라미터 수를 줄이는 방법입니다. 전략 3번은 제한된 파라미터 내에서 정확도를 최대한 높이기 위한 방법입니다.
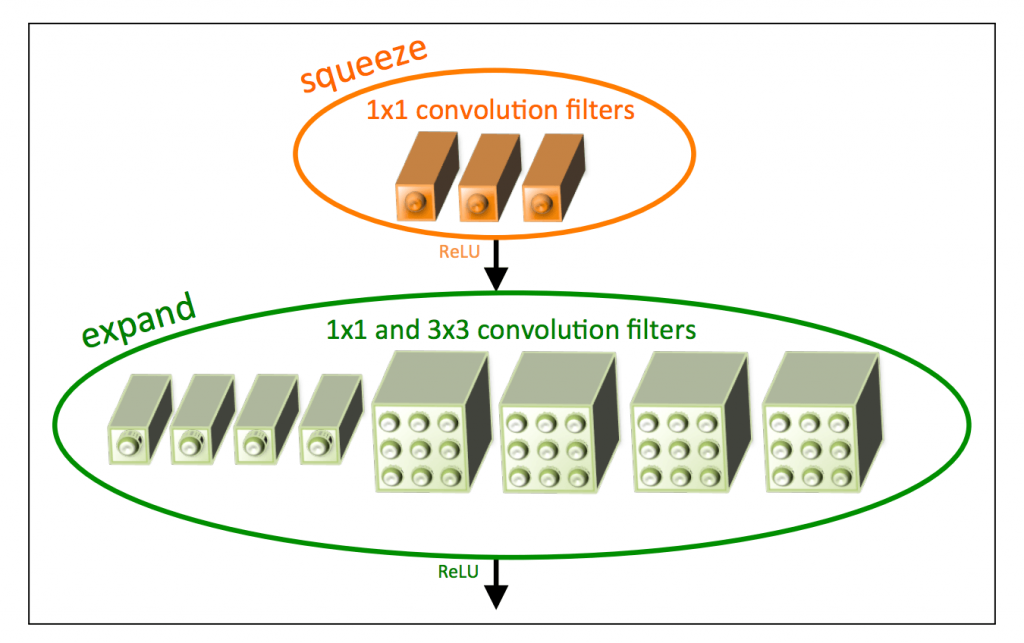
논문에서는 설계 전략을 바탕으로 SqueezeNet을 구성할 하나의 블록인 Fire 모듈이 제안합니다.
Fire Module
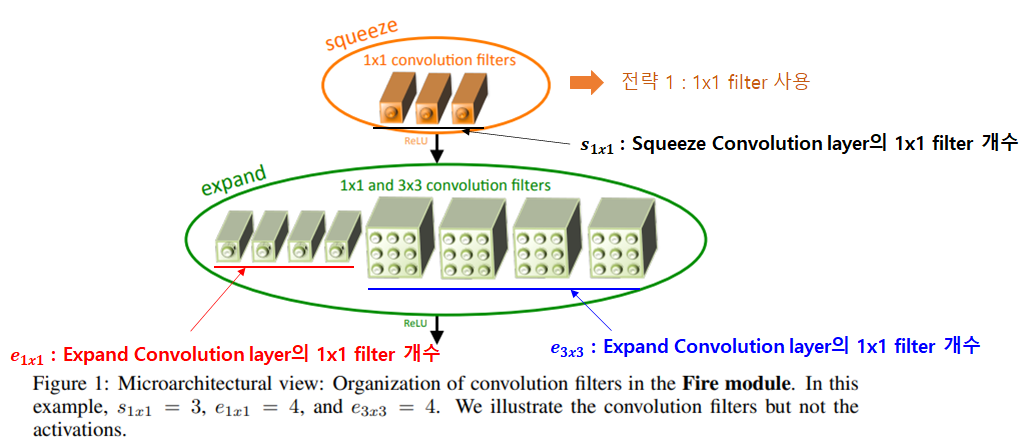
그림4. Fire Module
위 그림은 Fire Module에 대한 그림입니다.
Fire 모듈은 크게 두 단계로 나누어져 있으며, 1x1 Convolution을 활용하는 Squeeze Convolution layer와 1x1/3x3 Convolution을 함께 사용하는 Expand convolution layer로 구성되어 있습니다.
Squeeze Convolution layer는 설계전략 1번을 적용해 1x1 Conv filter로만 구성되어 있습니다. 1x1 filter만 사용함으로 써 필터 수를 낮출 수 있습니다.
Expand Convolution layer는 1x1 filter와 3x3 filter를 함께 사용합니다.
Fire module는 각 convolutional filter의 개수를 조절해 가면서 모듈의 크기를 조절할 수 있는 세 개의 하이퍼 파라미터를 제안합니다.
: Squeeze 에서 1x1 Convolution filter의 개수
: Expand 에서 1x1 Convolution filter의 개수
: Expand 에서 1x1 Convolution filter의 개수
Fire module을 설계할 때 설계전략 2를 적용하기 위해 다음과 같은 수식을 설정합니다.
< () + ()
위 수식에 의해 squeeze의 필터 수가 expand보다 크지 않도록 제한하여 전체 필터의 개수를 제한합니다.
전체적인 구조는 다음과 같습니다.
먼저 squueze layer는 1x1 convolution filter를 통하여 채널을 압축하고 expand layer는 1x1 convolution filter와 3x3 convolution filter를 통하여 다시 팽창시켜주는 역할을 하게 됩니다.
activation은 주로 ReLU를 사용하였습니다.
예를 들어 위와 같이 인풋이 128 채널이 들어오면 1x1을 통해서 16 채널로 줄였다가 다시 1x1 채널로 64개, 3x3 채널로 64개를 만듭니다. 이것을 concatenate를 하여 다시 128 채널의 아웃풋을 만듭니다.
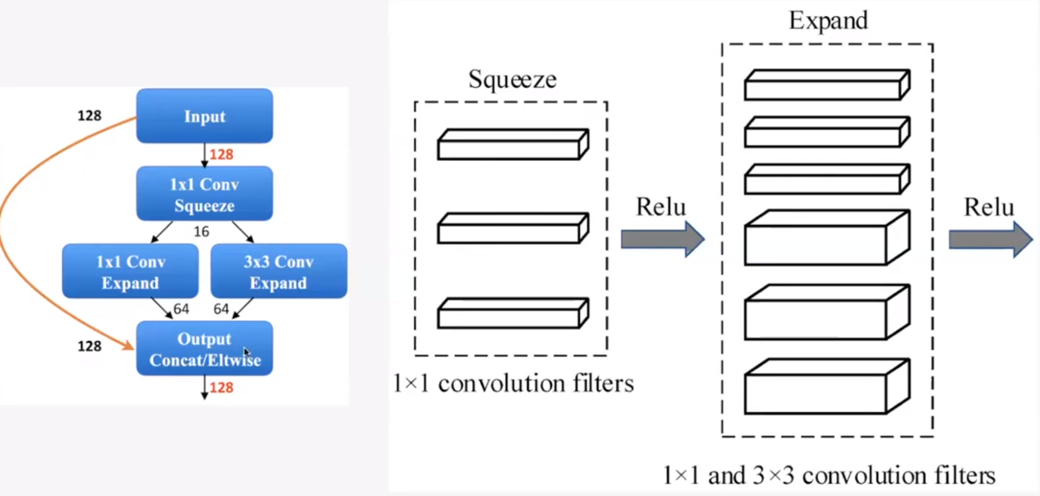
그림5. SqueezeNet 전체 구조
Result
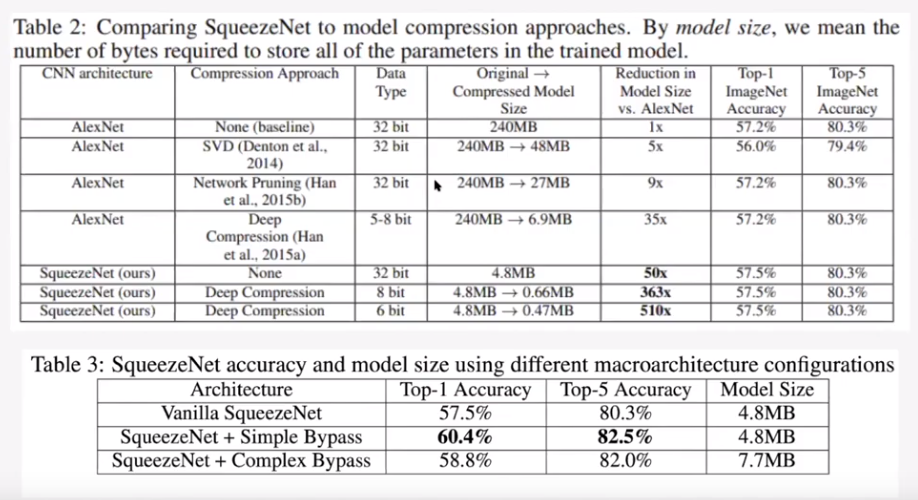
그림6. Result
마지막으로 알렉스 넷과의 비교 결과를 살펴보겠습니다.
- 결과적으로 보면 파라미터의 수는 50배 이상을 줄일 수 있으며 accuracy 성능은 알렉스넷과 유사하게 나올 수 있었습니다.
- 그 중 simple skip connection을 해본 모델의 성능이 가장 잘 나왔습니다. - 여기서 squeeze layer와 expand layer의 비율에 따라서 성능이 어떻게 변하는 지 또한 실험을 하였으며 논문을 통해 확인하실 수 있습니다.
참고
underflow101님 티스토리
metar님 티스토리
woojinn8님 벨로그
gaussian37님 블로그
SqueezeNet Paper
