오늘은 2017년 CVPR에 발표된 Xception(Xception: Deep Learning with Depthwise Separable Convolutions)에 대해서 알아보도록 하겠습니다.
우선 이 Xception의 경우 전에 설명 드렸던 Inception 설명(GoogLeNet)과 매우 연관되어 있습니다. 만약 Inception(GoogLeNet)에 대한 기초적인 지식이 부족하시다면, 해당 링크를 통해 사전 지식을 미리 익히시고 들으시는 것을 추전 드립니다.
Inception Module
우선 Inception을 처음 고안한 GoogLeNet의 구조부터 먼저 보도록 하겠습니다.
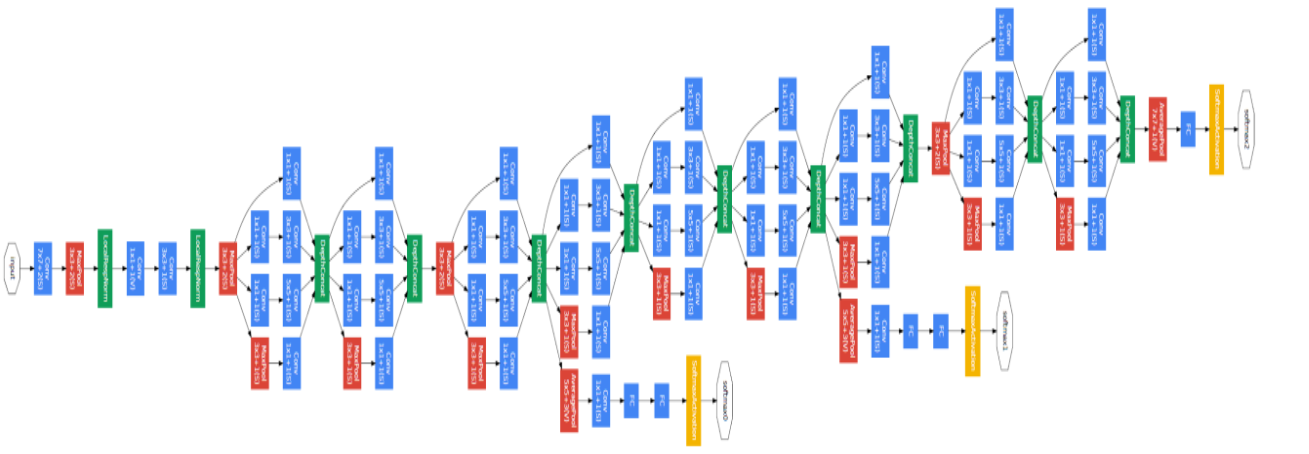
그림1. GoogLeNet 구조
반면 Xception은 성능 향상을 위해 극단적인 방법을 사용한 구조입니다.
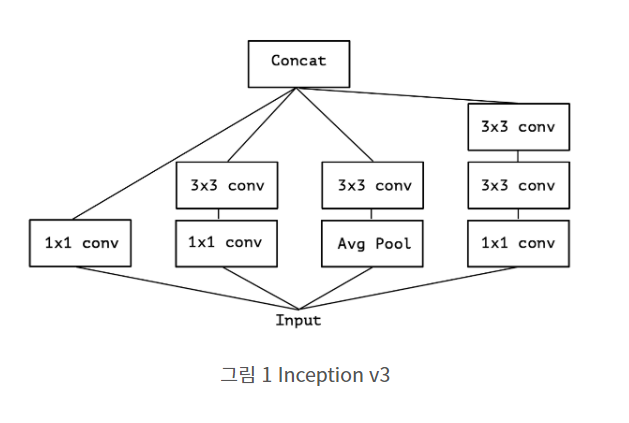
그림2. Inception Module
위의 그림은 Inception Module(Inception V3)입니다. 하지만 우리가 이전에 GoogLeNet에서 본 것과는 조금 다르게 생겼습니다. 우리가 보았던 것은 바로 Inception V1이었기 때문인데요. 여기서 5x5 filter가 3x3 + 3x3 Filter로 바뀐것을 알 수 있습니다. 이는 5x5 filter를 사용하는것보다 3x3 filter를 2번 사용하는 것이 Parameter 측면에서 더욱 더 효과적이기 때문입니다.
Convolition Layer의 경우 Filter를 가지고 3차원 공간(Height , Width, Channel)을 모두 학습하려고 하는데, 이때 하나의 Kernel(filter)로 Cross-Channel Correlation(입력 채널들 간의 관계 학습)과 Spatial Correlation(filter와 특정 채널 사이의 관계 학습 => 공간적 특성 학습)을 동시에 Mapping 해줘야 한다는 것입니다.
Inception 모듈의 아이디어는 이 프로세스를 Cross-channel Correlation과 Spatial Correlation을 독립적으로 살펴볼 수 있게 함으로써 프로세스의 효율을 올린다는 것입니다. 즉 일반적인 Inception 모델의 경우 먼저 1x1 convoltion 연산을 통해 Cross Channel Correlation을 살펴보게 되고, 입력 데이터를 원래의 공간보다 작은 3~4개의 별도의 공간에 Mapping하여 이 작은 3차원 공간의 모든 상관관계를 3x3, 5x5 convolution 연산을 통해 Mapping 합니다.
Single Convoltuon Kernel 하나가 하려는 것을 Spatial Correlation 분석을 해주면서 Cross channel Correlation으로 두가지 역할을 잘 분산해주기 때문에 Xception의 저자는 Inception이 잘 된것이라고 주장합니다.
즉 여기서 Cross-Channel-Correlation과 Spatial Correlation의 Mapping은 완전히 분리될 수 있다고 가설을 세울 수 있습니다. 이는 Inception 구조의 기초가 되는 가설의 더욱 더 강력한 버전이 되기 때문에 Extreme Inception을 뜻하는 Xcetion이라고 하는것이죠.
A simplified Inception module
먼저 하나의 크기에 Convolution 연산만 사용하고 Average Pooling을 포함하지 않는 단순화된 Inception Module을 만들어준 다음에 아래의 과정을 진행합니다.
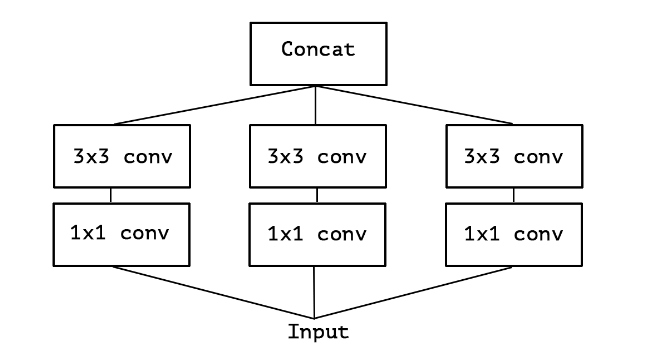
그림3. 간소화된 Inception 모듈
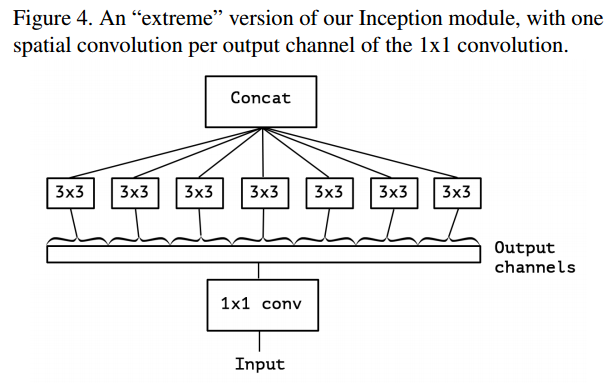
An "extreme" version of Inception module
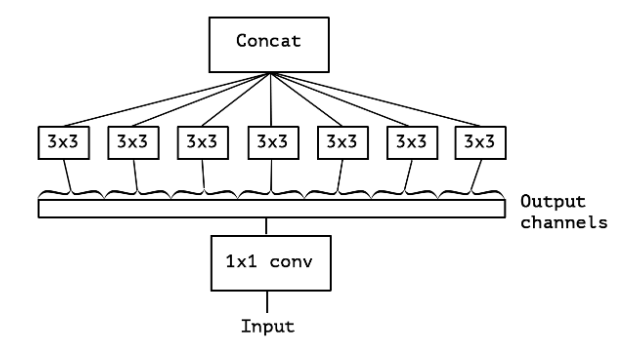
그림4. Extreme 버전의 Inception 모듈
이 Inception module은 대규모 1x1 convolution 연산으로 재구성하고 output channel이 겹치지 않는 부분에 대한 spatial convolution이 오는 형태로 재구성될 수 있습니다. 즉, input에 대해 1x1 convolution을 거친 후에, 모든 channel을 분리시켜서 output channel당 3x3 convolution을 해주는 것입니다. 이렇게 되면 두 방향(channel wise, spatial)에 대한 mapping을 완전히 분리할 수 있습니다.
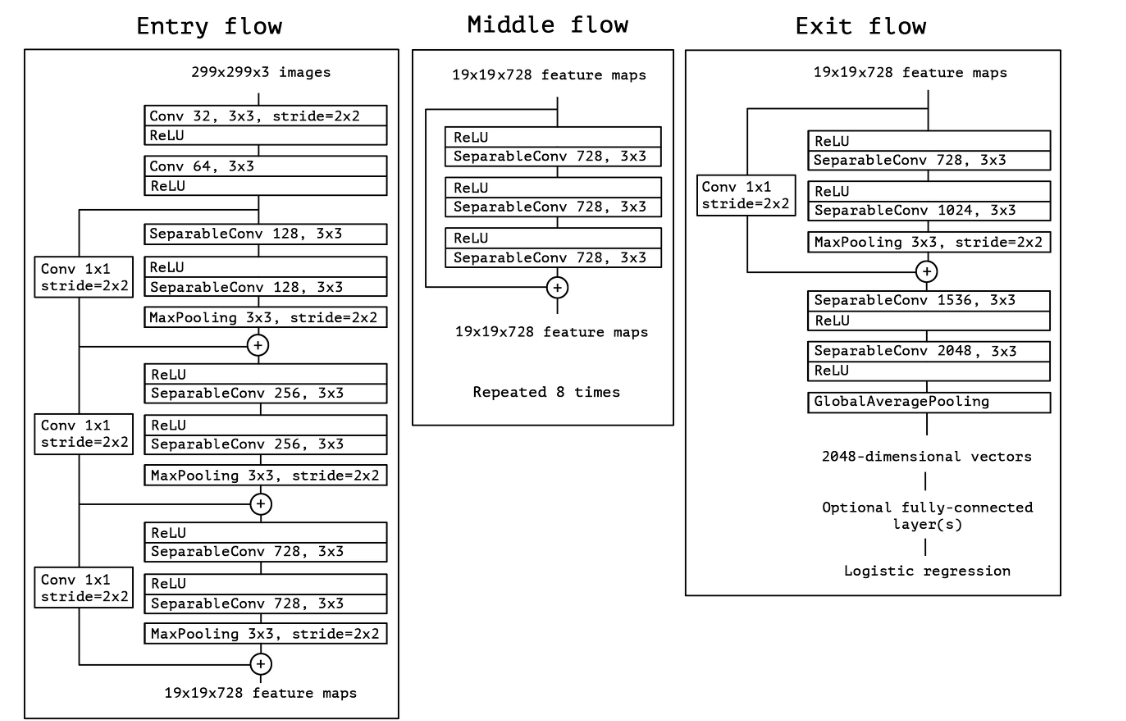
Xception with Depthwise Separable Convolution
-
The order of the operations (연산 순서의 사이)
Xception: 1x1 → 3x3
Depthwise: 3x3 → 1x1
Xception은 1x1 convolution이 먼저오고 3x3 convolution이 뒤따라 오지만 Depthwise separable convolution은 반대입니다.
-
The presence or absence of a non-linearity after the operation (ReLU와 같은 활성화 함수의 부재)
Xception: 1x1 → ReLU → 3x3
Depthwise: 1x1이랑 spatial convolution 사이에 ReLU 같은 활성화 함수가 들어가지 않습니다.
이렇게 XceptionNet에 대해서 알아보았습니다. 읽으면서 이해가 완벽히 되지 않는 부분도 있었고 부정확한 부분도 있었는데 다음 글에서는 더욱 정확하고 좋은 글로 만나뵙겠습니다.
