안녕하세요. 이번에 리뷰 해 볼 논문은 바로 SPPNet(Spatial Pyramid Pooling Network)입니다. 만약 Object Detection task에 대해서 공부를 해보신 분이라면 아마 들어 본 적 있으실거에요.
이번 포스트에서는 SPPNet이 무엇 인지와 그 특징들에 대해서 살펴보는 시간을 가지도록 하겠습니다.
SPPNet의 등장 배경
기존 심층 컨볼루션 신경망(CNN)에는 고정 크기(ex 224 x 224) 입력 크기가 필요합니다. 예를 들어 CNN 구조가 고정된 입력 이미지 크기를 입력으로 취하는데, 고정된 입력 크기를 맞추기 위해 , crop, wrap을 적용합니다. 참고로 crop, wrap은 Classification에서는 Data Augmentation, Detection에서는 Region Proposal(영역추정)을 입력 사이즈에 맞춰주기 위해이용합니다. crop을 적용하면 crop된 구역만 CNN을 통과시키기 때문에, 전체 이미지 정보가 손실이 발생합니다. 또, warp을 적용하면 이미지에 변형이 일어납니다.
이러한 요구사항은 매우 강제적이며 임의의 크기/스케일의 이미지 또는 하위 이미지에 대한 인식 정확도를 떨어 뜨리는 영향을 줄 수 있습니다. 그렇다면 CNN에서는 입력 이미지 크기가 고정으로 되어야 할까요? 그것은 바로 FC layer가 고정된 입력 크기를 필요로 하기 때문입니다. 참고로 Convolutional layer의 경우, 슬라이딩 윈도우 방식을 택하고 있기 때문에 고정된 사이즈가 필요하지 않습니다.
SPPNet에서는 다음과 같은 영향을 받지 않기 위하여 "Spatial Pyramid Pooling"을 사용합니다. SPP-Net이라고 하는 새로운 네트워크 구조는 이미지의 크기/스케일에 관계없이 고정 길이의 표현을 생성 할 수 있다는 특징이 있습니다.
이러한 특징으로 Pyramid Pooling은 개체의 변형에 잘 대응할 수 있다는 특징이 있습니다. 이러한 장점을 바탕으로 SPPNet은 일반적으로 모든 CNN 기반 이미지 분류 방법을 개선하였는데, ImageNet 2012(AlexNet이 등장 한 해)데이터 세트에서 SPPNet이 다양한 디자인에도 불구하고 높은 성능을 보였습니다.

그림1. CNN과 SPPNet의 흐름 차이
SPP layer
SPPNet은 Object Detection분야에서 널리 사용되기 때문에 RCNN과의 비교또한 가능합니다. RCNN의 경우 입력 이미지에서부터 Region Proposal 방식을 이용해, Candidate Bounding Box(후보군 바운딩 박스)를 선별하고 모든 Candidate Bounding Box애 대해서 CNN작업을 진행합니다. 만약 2000개의 Candidate Bounding Box가 나온다면, 2000번의 CNN 작업이 수행됩니다. 하지만 SPP-Net의 경우 입력이미지리를 먼저 CNN 작업을 진행하고, 다섯번째 도달한 Feature map을 기반으로 Region Proposal 방식을 적용해 candidate bounding box를 선별하게 됩니다. 이렇게 되면 CNN연산은 1번만 진행이 되며 RCNN과 비교하였을 때, 엄청난 시간차이가 날 수 밖에 없습니다.
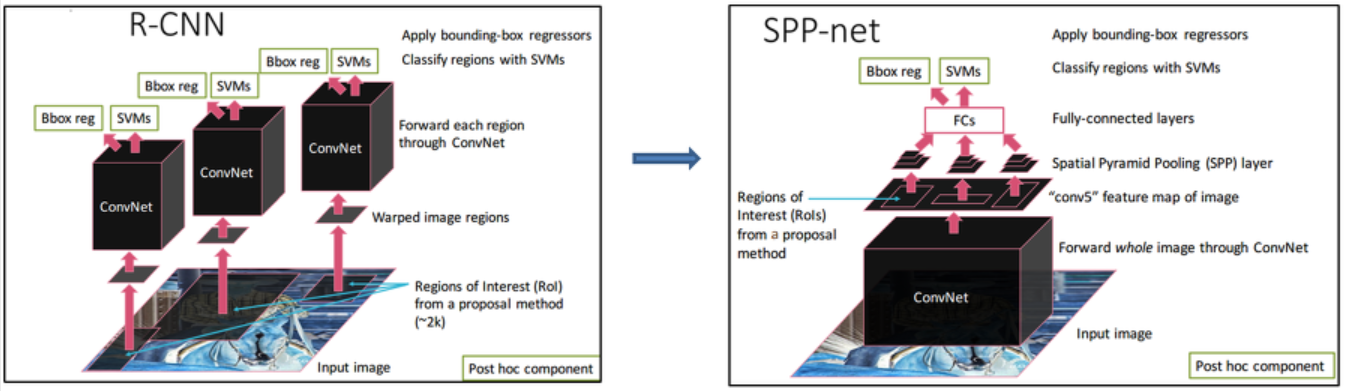
그림2. RCNN과 SPPNet 차이
SPPNet의 경우 총 5개의 Conv layer, 3개의 FC layer를 가집니다.
SPP layer의 경우 Conv5 layer 이후에 위치시킵니다.(위에서 말했듯 FC layer가 고정된 입력 크기로 전달해주기 위해)
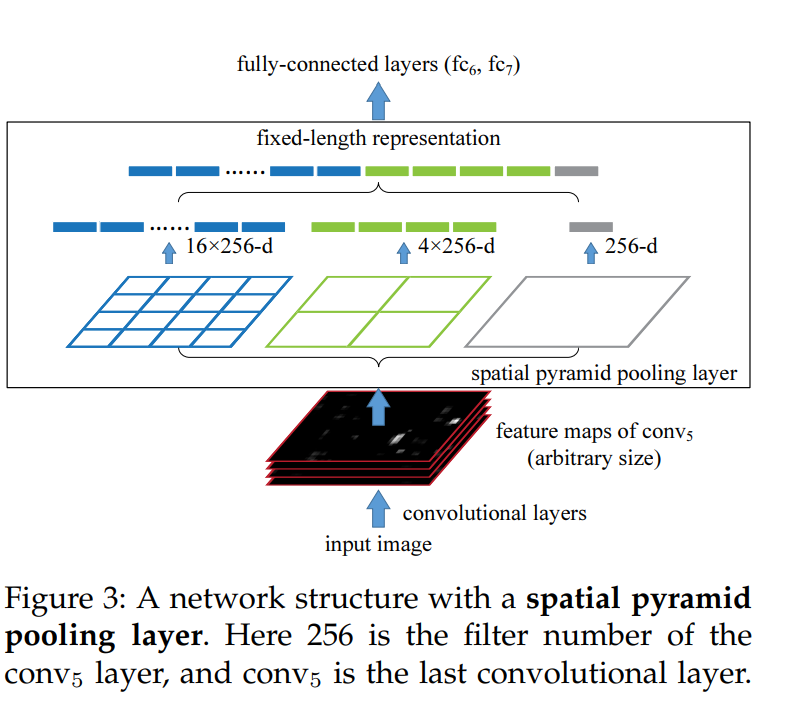
그림3. SPP layer의 모습
우선 spatial bins의 개수를 선정합니다.
예를 들어 50 bin = [6x6, 3x3, 2x2, 1x1], 30 bin = [4x4, 3x3, 2x2, 1x1] 을 생각해 볼 수 있습니다.
여기서 [6x6, 3x3, 2x2, 1x1]은 conv5의 feature map에 pooling을 적용하여 생성되는 출력 크기 입니다.
위 그림에서는 21 bin = [4x4, 2x2, 1x1] 인 경우입니다. 21 bin의 경우에 3개의 pooling 으로 이루어져있습니다. 각각의 pooling을 conv5 layer에 적용하여 특징을 추출하고 4x4, 2x2, 1x1의 크기를 출력합니다. 이를 일자로 피면 bin의 수가 되는 것입니다. 입력 사이즈가 다양하므로 conv5에서 출력하는 feature map의 크기도 다양하게 됩니다.다양한 feature에서 pooling의 window size와 stride 만을 조절하여 출력 크기를 결정합니다.
window size = ceiling(feature map size / pooling size)
stride = floor(feature map size / pooling size)
로 계산하면 어떠한 feature map 크기가 오더라도 고정된 pyramid size를 얻을 수 있습니다.
아래 그림은 13x13 feature map에서 각각의 pooling의 window size, stride를 계산한 표입니다.
[pool3x3] 의 window size = ceiling(13 / 3) = 5, stride = floor(13 / 3) = 4 로 설정되었습니다.

그림4.Conv layer에서 3-level pyramid pooling의 예
그리고 SPP layer의 출력 차원은 k * M 이 됩니다.
k는 conv5 layer에서 출력한 feature map의 filter 수 입니다. M은 사전에 설정한 bin의 수 입니다.
위 그림에서는 256개의 feature map, 21개 bin이므로 SPP layer는 256 * 21 차원 벡터를 출력합니다. 그리고 이 256 * 21 차원 벡터가 fc layer의 입력으로 통과합니다. feature map 크기와 관계 없이 bin과 feature map의 filter 수로 출력 차원을 계산하므로 고정된 차원 벡터를 갖게 됩니다. 이를 통해 다양한 입력 이미지 크기를 입력 받아 다양한 feature map size가 생성되고 SPP layer를 거쳐서 고정된 크기의 벡터가 생성됩니다.
이렇게 SPPNet 의 작동 방식에 대해서 알아보았습니다. SPPNet의 동작 방식을 다시 한번 요약해서 정리해보면 다음과 같습니다.
- Selective Search를 사용하여 약 2000개의 region proposals를 생성합니다.
- 이미지를 CNN에 통과시켜 feature map을 얻습니다.
- 각 region proposal로 경계가 제한된 feature map을 SPP layer에 전달합니다.
- SPP layer를 적용하여 얻은 고정된 벡터 크기(representation)를 FC layer에 전달합니다.
- SVM으로 카테고리를 분류합니다.
- Bounding box regression으로 bounding box 크기를 조정하고 non-maximum suppression을 사용하여 최종 bounding box를 선별합니다.
오늘은 이렇게 Object Detection과 CNN에서 좋은 성능을 보여줬던 SPP-Net에 대해서 알아보았습니다. 다음 포스트에서는 CNN 모델 중 Xception(2016)에 대해서 알아보는 시간을 가지도록 하겠습니다.
감사합니다.
참고
SPPNet 논문
딥러닝스터디님 티스토리
hsejun07님 티스토리
drip.me님 블로그
89douner님 티스토리
