
이번 포스팅은 최종 모델로 선정된 LinearSVC 모델링 과정을 설명해보려고 합니다.
미해결 과제로 남았던 '클래스 불균형'을 SMOTE를 통한 리샘플링으로 해결하였고, TF-IDF Vectorizer과 GridSearchCV, LinearSVC를 이용하여 모델링을 진행했습니다.
SMOTE
SMOTE는 불균형 데이터(imbalanced data) 처리를 위한 샘플링 기법으로, 오버 샘플링에 속합니다.
불균형 데이터를 처리해야만 했던 이유는 무엇일까요?불균형 데이터란 정상 범주의 관측치 수와 이상 범주의 관측치 수가 현저히 차이나는 데이터입니다. 만약, 불균형 데이터를 처리하지 않고 그대로 모델에 적용하여 예측을 진행한다면 어떻게 될까요?
예를 들어, 0과 1 두가지 클래스가 존재할 때 데이터 샘플 수의 비율이 99:1이라고 가정해봅시다. 이런 불균형 데이터에 대해 분류 모델을 훈련시킨 후 예측을 하면 모든 데이터를 ‘0’ 이라고 분류한다고 했을 때의 정확도(accuracy)는 99%가 됩니다. 정확도만 보고 모델 성능 평가를 해보면 잘 만들어진 모델같지만 '1'이라는 클래스는 제대로 분류를 해내지 못했으므로 성능이 안좋은 모델이라고 할 수 있습니다.
이러한 이유로, 저는 불균형 데이터를 처리해서 balanced data로 만들어줘야 했습니다.
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
# SMOTE를 사용하기 위해서 예측 변수, 설명 변수 모두 인코딩
encoder_X = OneHotEncoder()
encoded_X = encoder_X.fit_transform(data['posts'].to_numpy().reshape(-1, 1))
encoder_y = LabelEncoder()
encoded_y = encoder_y.fit_transform(data['type'].to_numpy().reshape(-1, 1))데이터셋을 SMOTE에 적용시키기 위해서는 숫자로 매핑을 하는 과정이 필요합니다.
Encoding
처음에는 One-hot encoding으로 예측 변수, 설명 변수를 모두 인코딩하였는데, 가진 데이터셋의 예측 변수가 16개의 클래스로 이루어져 있기 때문에 벡터의 차원이 커지는 것을 방지하고자 예측변수 인코딩만 Label encoding으로 변경하여 진행했습니다.
One-hot encoding이란?
원핫 인코딩은 주어진 범주(category)를 나타내는 변수를 0과 1로 이루어진 이진 벡터로 변환하는 방식입니다. 각 범주에 대해 하나의 새로운 이진 변수를 만들어 해당 범주에 해당하는 위치에 1을, 다른 위치에는 0을 할당합니다. 이를 통해 각 범주 간의 상호 관계가 없다는 것을 나타낼 수 있습니다.
예를 들어, ['사과', '바나나', '오렌지']와 같은 세 가지 과일 범주가 있을 경우:
- '사과'는 [1, 0, 0]
- '바나나'는 [0, 1, 0]
- '오렌지'는 [0, 0, 1]
이런 식으로 변환됩니다. 원핫 인코딩은 주로 범주형 변수가 상대적으로 작을 때 사용되며, 범주의 개수가 많아질수록 벡터의 차원이 커지는 단점이 있습니다.
제가 가진 데이터셋으로 생각하면, 16개의 범주이기 때문에 [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] 이런 식으로 차원이 아주 커지게 되는 거죠.
Label encoding이란?
라벨 인코딩은 각 범주에 대해 순차적인 정수 값을 할당하는 방식입니다. 이 방식은 범주 간의 순서나 관계를 전제로 하기 때문에 순서가 중요한 변수에 주로 사용됩니다.
예를 들어, ['저학년', '중학년', '고학년']과 같은 학년 범주가 있을 경우:
- '저학년'은 1
- '중학년'은 2
- '고학년'은 3
이런 식으로 변환됩니다.
unique_array=np.unique(encoded_y)
print(unique_array)출력값: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
이렇게 0~15까지의 정수형으로 16개의 클래스가 제대로 맵핑된 것을 확인할 수 있었습니다.
SMOTE 적용
import sklearn
from imblearn.over_sampling import SMOTE
# SMOTE 적용
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(encoded_X, encoded_y)뒤에서 사용할 TF-IDF Vectorizer에 적용시키기 위해서 SMOTE를 통해 불균형한 데이터를 처리한 뒤, 인코딩한 데이터들을 디코딩해줘야 합니다.
# 인코딩한 변수들을 다시 문자열로 디코딩하는 함수 정의
def text_inverse_transform_X(encoded_data, encoder):
decoded_data = encoder.inverse_transform(encoded_data)
return decoded_data
def text_inverse_transform_y(encoded_data, encoder):
decoded_data = encoder.inverse_transform(encoded_data)
return decoded_data# 예측 변수, 설명 변수 디코딩
X_data = text_inverse_transform_X(X_resampled, encoder_X)
y_data = text_inverse_transform_y(y_resampled, encoder_y)y_data다음과 같이 예측변수가 제대로 디코딩 되었는지 확인했습니다.

X_data설명변수 또한 디코딩이 제대로 수행되었습니다.
from collections import Counter
Counter(y_data)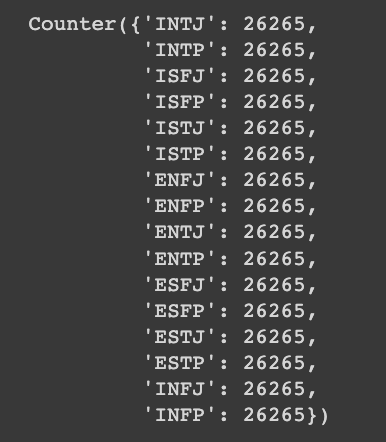 사진과 같이 y_data의 각 클래스별 샘플 수를 확인해보면, SMOTE가 잘 적용된 것을 볼 수 있습니다.
사진과 같이 y_data의 각 클래스별 샘플 수를 확인해보면, SMOTE가 잘 적용된 것을 볼 수 있습니다.
TF-IDF Vectorizer
TF-IDF(Term Frequency-Inverse Document Frequency)는 자연어 처리에서 널리 사용되는 텍스트 피처 추출 방법 중 하나로, 문서 내에서 단어의 중요성을 평가하는 데 도움이 되는 기술입니다.
- TF(Term Frequency) : 특정 단어가 등장하는 횟수
- IDF(Inverse Document Frequency) : 특정 단어가 몇 개의 Document에서 등장하는지의 역수
- TF-IDF = TF*IDFTF-IDF를 통해 벡터화를 하는 경우,
1. 단어의 중요성 강조: TF-IDF는 단어의 빈도와 문서 내에서 얼마나 널리 분포되어 있는지에 기반하여 단어의 중요성을 평가합니다. 단어가 특정 문서에서 높은 빈도로 등장하면서 동시에 다른 문서에서는 드물게 등장할수록 해당 단어는 그 문서의 특징을 잘 나타내는 단어로 간주됩니다.
2. 차원 감소: 텍스트 데이터는 일반적으로 고차원의 특성을 가지며, 이로 인해 차원의 저주(curse of dimensionality)와 관련된 문제가 발생할 수 있습니다. TF-IDF는 단어의 빈도를 기반으로 하지만, IDF(Inverse Document Frequency)의 역할로 인해 빈도가 높지만 모든 문서에 공통적으로 등장하는 단어들의 가중치는 낮아집니다. 따라서 흔한 단어들이 너무 큰 영향을 끼치지 않게 되어 차원을 상당히 감소시킬 수 있습니다.
# 변수가 바이트 형식이라면 utf-8로 디코딩
X_decoded = [x.decode('utf-8') if isinstance(x, bytes) else x for x in X_data]
y_decoded = [y.decode('utf-8') if isinstance(y, bytes) else y for y in y_data]
# data split
X, X_test, y, y_test = train_test_split(X_decoded, y_decoded, test_size=0.2, random_state=1)
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=1)from sklearn.feature_extraction.text import TfidfVectorizer
# 벡터화
tfidf = TfidfVectorizer(lowercase=False)
# 문자열로 변환->X_train를 그대로 tfidfVectorizer로 벡터화하면 에러 발생
X_train_str = [str(x) for x in X_train]
# 훈련 데이터 벡터화
X_train_tfidf = tfidf.fit_transform(X_train_str)clf = LinearSVC()
clf.fit(X_train_tfidf, y_train)
# grid search를 이용해 최적의 하이퍼 파라미터 찾기
cv = GridSearchCV(clf, {'C': [0.1, 0.2, 0.3, 0.4, 0.5, 1.0]}, scoring = "accuracy")
text_clf = Pipeline([('tfidf',TfidfVectorizer()),('clf',cv)])
text_clf.fit(X_train_str, y_train)
C = cv.best_estimator_.Cprint("최적의 파라미터 C : ", C)최적의 파라미터 C : 1.0
모델 학습
#grid search를 통해 찾은 최적의 하이퍼 파라미터 적용
text_clf = Pipeline([('tfidf',TfidfVectorizer()),('clf',LinearSVC(C=1.0))])
text_clf.fit(X_train_str, y_train)X_valid_str = [str(x) for x in X_valid] # 타입에러로 인해 문자열로 변환
# valid 데이터의 mbti 예측
pred = text_clf.predict(X_valid_str)
# valid data에서의 정확도
accuracy_score(pred, y_valid)
from sklearn.metrics import classification_report
print(classification_report(y_valid, pred))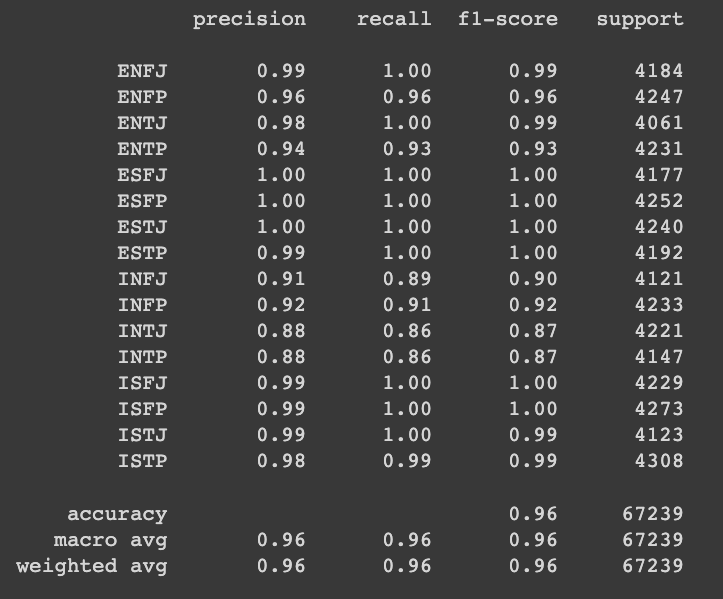
X_str = [str(x) for x in X]
X_test_str = [str(x) for x in X_test]
# 모든 설명변수 데이터 X 자연어처리
X_tfidf = tfidf.fit_transform(X_test_str)clf = LinearSVC()
clf.fit(X_tfidf, y_test)svc_clf = Pipeline([('tfidf',TfidfVectorizer()),('clf',LinearSVC(C=1.0))])
svc_clf.fit(X_str, y) # train/valid data 합쳐서 학습, test data로 예측
pred_svc = svc_clf.predict(X_test_str)accuracy_score(test_pred, y_test)
from sklearn.metrics import classification_report
print(classification_report(y_test, test_pred))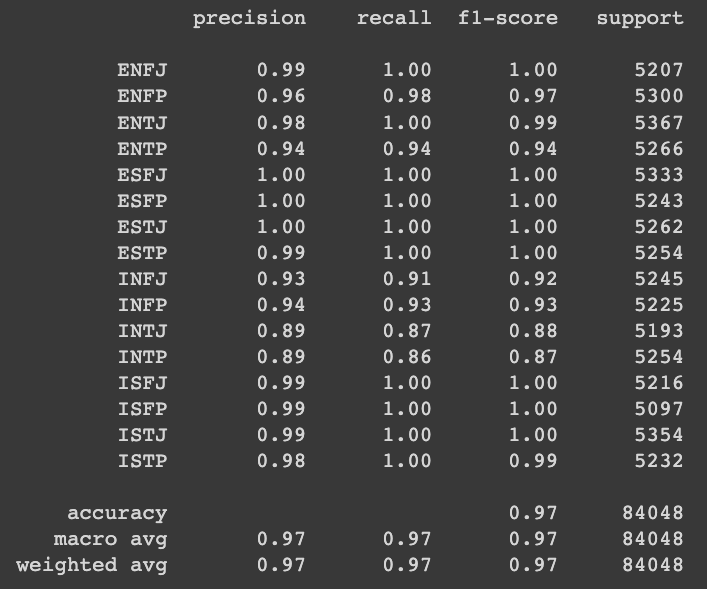 classification report를 보니, 여러 평가 지표를 모두 확인 했을 때 성능이 좋다는 것을 볼 수 있습니다.
classification report를 보니, 여러 평가 지표를 모두 확인 했을 때 성능이 좋다는 것을 볼 수 있습니다.
모델 저장
학습이 된 모델을 피클 파일로 저장합니다.
import pickle
with open('saved_model_result', 'wb') as f:
pickle.dump(svc_clf, f)마치며..
MBTIgram 프로젝트를 통해 '텍스트 데이터를 이용한 MBTI 예측 알고리즘'을 개발했습니다. 개발의 모든 단계를 누구의 도움없이 혼자만의 힘으로 해낸게 처음이라 더욱 뿌듯하고 기억에 오래 남을 것 같습니다. 많은 시행착오를 직면한 덕에 더 많은 것을 배울 수 있었습니다. 이번 프로젝트를 통해서 남은 아쉬움과 부족한 점들을 보완하여 더욱 성장할 수 있었으면 좋겠습니다😆
