
NRU의 유입 경로
게임을 처음으로 설치하고 실행했을 때 유입된 신규 유저UA 진행 시 투입 비용 대비 얼마나 많은 유저가 유입되었는가를 측정할 때 가장 초기에 확인하는 지표주로 광고나 마케팅 캠페인 이외의 경로를 통해 유입된 유저유저의 필요에 의해 들어왔기 때문에 리텐션율의 지표가 Pa
게임 데이터 지표
DAU(Daily Active Users) : 일일 활성 사용자수 MAU(Montly Active Users) : 월간 활성 사용자 수DNU(Day New Users) : 당일 신규 사용자 수ACU(Average Concurrent Users) : 평균 동시 온라인 사
✏️ 2025. 02. 11 TIL
기본적으로 태블로는 차원에 따라 데이터를 자동 집계LOD 활용 시 사용자가 원하는 수준에서 데이터 집계 가능LOD 3가지 유형 FIXED : 특정 차원에 대해 집계 고정INCLUDE : 현재 뷰의 차원 + 추가 차원을 포함하여 집계EXCLUDE : 특정 차원을 제거한
✏️ 2025. 02. 10 TIL
추출 필터: 데이터 소스에서 추출된 데이터 필터링 (데이터 연결을 추출로 선택했을 때만 사용 가능)데이터 원본 필터: 데이터 원본 소스에서 일부 데이터만 필터링컨텍스트 필터: 특정 값에 대한 데이터만 필터링차원 필터: 차원을 기준으로 데이터 필터링측정값 필터: 측정값을
✏️ 2025. 02. 07 TIL
BI(Business Intelligence)조직이 데이터 기반 의사결정을 좀 더 빠르게 할 수 있도록 서포트하는 비즈니스 분석, 데이터 마이닝, 데이터 시각화, 데이터 도구를 의미BI 워크 플로우데이터 인프라 : 데이터 레이크 → 데이터 웨어하우스 → 데이터 마트
✏️ 2025. 01. 20 TIL
1\. API를 활용하여 데이터 불러오기Steam 플랫폼에서 출시된 게임들의 데이터를 조회해보고 싶어서 관련 API를 찾아봤다. 우선, Steam 공식 API인 Steam Web API를 살펴보았다. 하지만.. 요 데이터만 가지고는 인사이트를 도출해내기 어려울 듯 싶어
[MySQL] 문자열 일부 잘라내기
문자열의 일부를 잘라내기로 추출하는 함수문자열 일부를 왼쪽부터 잘라내어 반환하는 함수문자열 일부를 오른쪽부터 잘라내어 반환하는 함수구분자와 구분자의 숫자만큼 잘라내어 반환하는 함수
[MySQL] 그룹화된 데이터를 하나로 문자열로 결합
GROUP_CONCAT : 여러 행의 데이터를 그룹화하여 하나의 행에 문자열로 통합 가능DISCINCT : 중복된 값을 제거하고 연결column_name : 연결할 컬럼 이름 지정ORDER BY : 연결된 값 순서 지정SEPARATOR : 각 값 사이에 삽입할 구분자
[MySQL] 시간 사이의 간격 계산
TIMESTAMPDIFF : 두 날짜 또는 시간 간의 특정 단위로 간격 반환unit : 반환할 간격의 단위 지정 (예: SECOND, MINUTE, HOUR, DAY, WEEK, MONTH, YEAR)datetime1 : 시작 시간datetime2 : 끝 시간결과 :
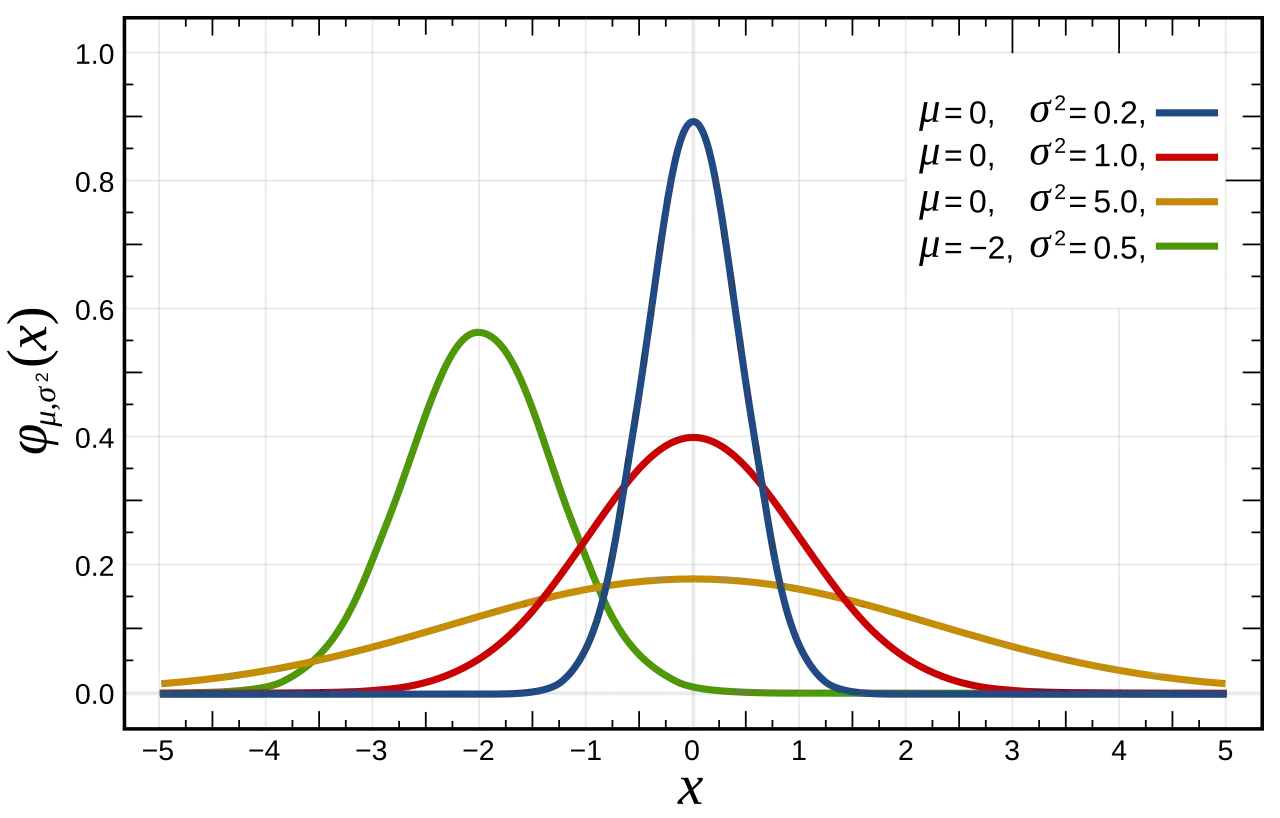
✏️ 2025. 01. 08 TIL
numpy.random.normal : 정규분포를 따르는 난수 생성loc : float 정규분포의 평균 기본값 : 0.0scale : float 정규분포의 표준편차 기본값: 1.0 size : int / tuple of ints 출력 배열의 크기 = 데이터 개수기본값:
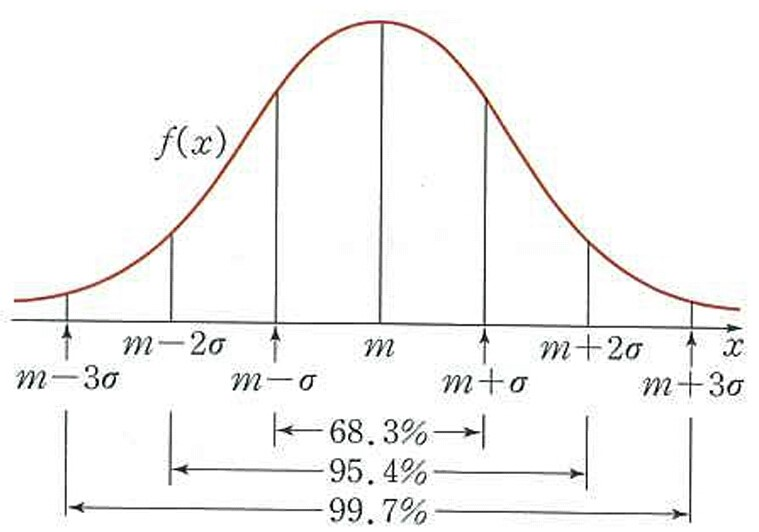
✏️ 2025. 01. 07 TIL
▶ 통계학 라이브세션 : 1회차 통계학 수식 $X$ : 확률 변수 $x$ : 확률 변수의 실제 값 $\sum$ : 데이터의 합 $\mu$ : 모집단의 평균 자료형의 종류 범주형 자료 명목형 자료 : 순서가 의미없는 자료 순서형 자료 :
[Python] np.arange
Numpy 라이브러리에서 제공하는 함수지정된 범위 내에서 일정 간격으로 배열을 생성하는 데 사용Python의 range와 비슷하지만, 정수 뿐만 아니라 부동소수점 간격도 지원한다는 점에서 더 유용함start (optional)생성할 배열의 시작 값 지정기본값 = 0st
[Python] f-string 소수점 포맷팅
▶ 기본 형식 ▶ 예시 소수점 자리수 포맷팅print(f'변수: {변수명: .nf}'): 변수를 소수점 n번째 자리까지 반올림하여 표시백분율print(f'변수: {변수명: .n%}')소수점 2자리까지 % 형태로 출력부동 소수점 출력print(f'변수: {변수명: g}'
😎 부트캠프 6주차 WIL
팀 프로젝트 때문에 정신 없었던 한 주 였다...분석 작업 하느라 기록하는 걸 뒷전으로 했었는데, 다음부터는 효율적으로 작업해서 꼭 중간 과정을 기록할 수 있도록 해야겠다.주어진 데이터에 대해 계속 고민하고 논리적인 오류가 없는지 점검한 점. 앞으로 계속 유지해야 하는
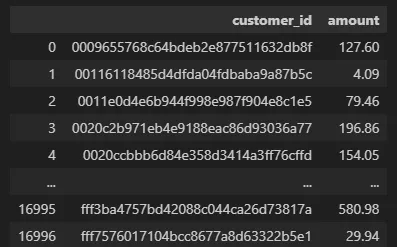
✏️ 2024. 12. 30 TIL
1\. 고객별 지출 비용 환산customer_id의 유니크 값 기준으로 총 지출 group결과 테이블값 분포 그래프2\. 지출 구간 Group화 진행100달러 단위로 구간을 나누고 총 매출 대비 매출 비율 계산특정 구간의 고객들이 전체 매출에서 얼마나 많은 비중의 매출
[Python] max()
주어진 반복 가능한 객체나 인자들 중에서 가장 큰 값을 반환하는 파이썬 내장함수1\. 첫 번째 사용법(iterable)max()는 반복 가능한 객체(iterable)에서 가장 큰 값 반환선택적으로 key 매개변수를 사용하여 사용자 정의 기준에 따라 비교 가능비어있는 i
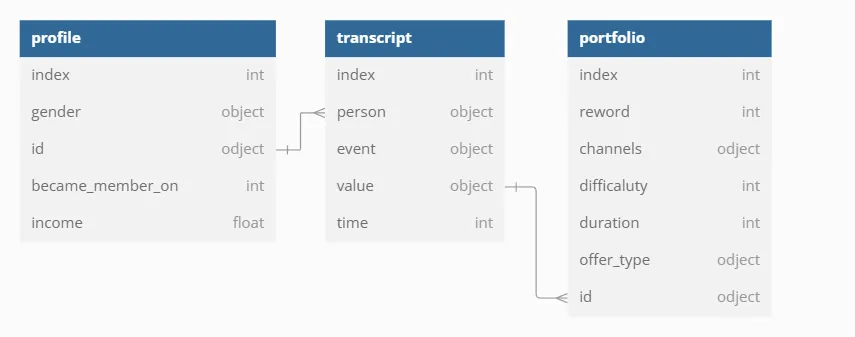
✏️ 2024. 12. 26 TIL
스타벅스 프로모션 제안 관련 고객 데이터 총 3개의 테이블로 프로모션 정보를 담은 portfolio 테이블, 고객 행동 기록 데이터를 담은 transcript 테이블, 고객 정보를 담은 profile 테이블로 구성✅ Portfolio 테이블 설명 → 프로모션 정보 테이
[Python] 코드카타 문제 풀이
📅 TO DO 📝 MEMO ▶ 코드카타 오답노트 > 문제 ▶ 프로그래머스 링크 길이가 같은 두 1차원 정수 배열 a, b가 매개변수로 주어집니다. a와 b의 내적을 return 하도록 solution 함수를 완성해주세요. 이때, a와 b의 내적은 a[0]b[0
[Python] 코드카타 문제 풀이
문제 문자열 내림차순으로 배치하기문자열 s에 나타나는 문자를 큰것부터 작은 순으로 정렬해 새로운 문자열을 리턴하는 함수, solution을 완성해주세요.s는 영문 대소문자로만 구성되어 있으며, 대문자는 소문자보다 작은 것으로 간주합니다.문자열 s를 list()로 형 변