Self-supervised Image Denoising with Downsampled Invariance Loss and Conditional Blind-Spot Network
GIST 동계 인턴

안녕하세요❗️
이번에 리뷰하고자 하는 논문은 바로 Self-supervised Image Denoising with Downsampled Invariance Loss and Conditional Blind-Spot Network 입니다. 해당 논문의 경우, AP-BSN의 후속 연구로도 볼 수 있으며 두 가지 주요 한계를 극복하고자 제안된 논문입니다.
먼저, 중앙 픽셀 정보가 완전히 배제되어 성능의 제한이 존재한단 점과 실제 카메라 노이즈는 공간적으로 상관된 특성을 가지고 있으므로 기존 BSN 방식이 잘 작동하지 않는 한계를 극복하고자 합니다.
본 논문에서 제안하는 핵심 구성 요소는 두 가지 측면에서 확인할 수 있습니다.
- Downsampled Invariance Loss: Downsampling 연산을 통해 입력 이미지의 노이즈 공간 상관성을 감소시키고, 그 결과 실제 노이즈에서도 효과적인 self-supervised loss가 되도록 이론적으로 upper band를 유도합니다.
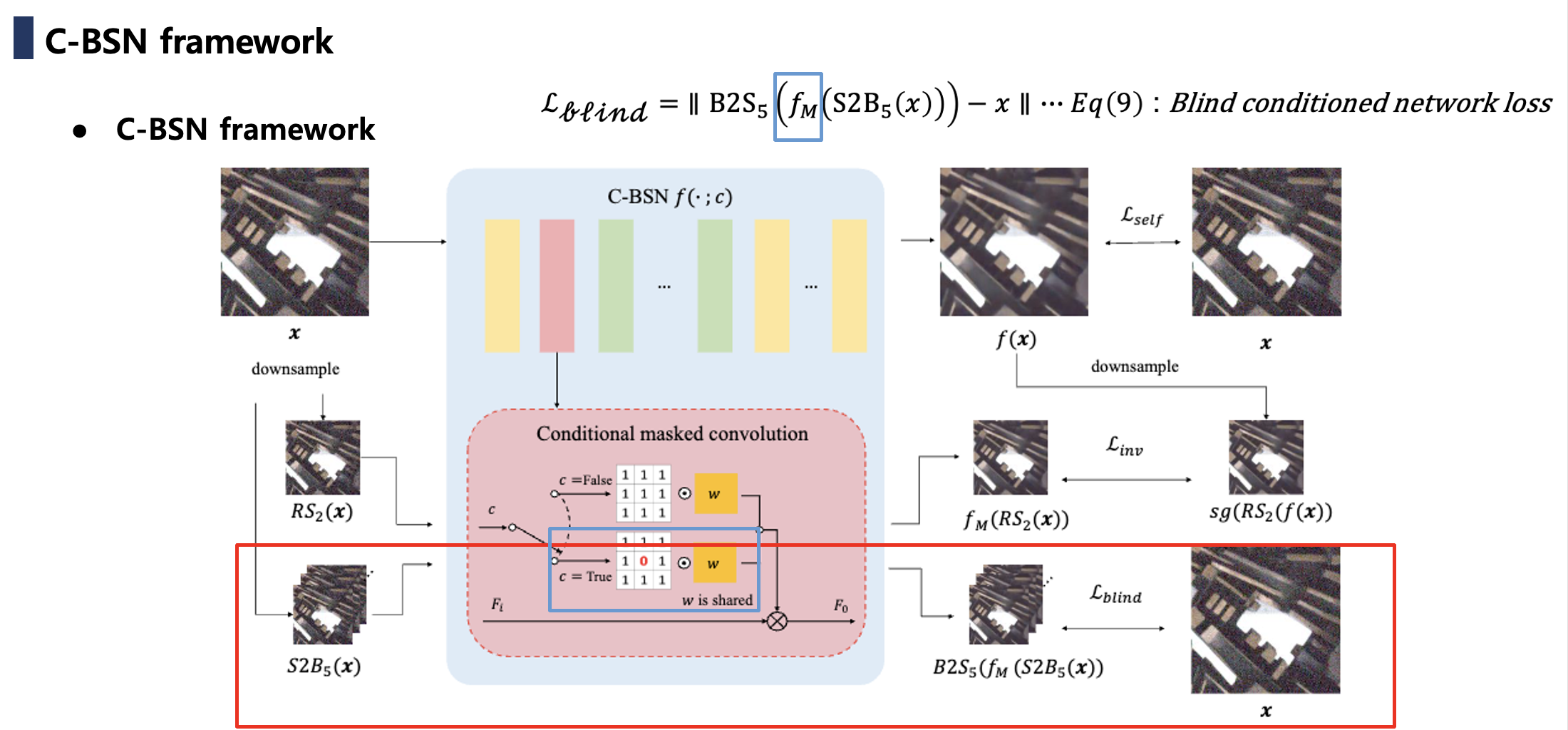
- Conditional Blind-Spot Network (C-BSN): 기존의 BSN은 항상 blind-spot 구조이지만, C-BSN은 네트워크가 조건에 따라 blind-spot을 켜거나 끌 수 있도록 설계되었습니다. 또한 랜덤 서브샘플러(random subsampler) 를 도입해 downsample 과정에서 visual artifact를 줄이고, real noise correlation 문제를 개선했습니다. 즉, BSN은 blind-spot 설계로 인해 출력 위치의 중심 정보가 항상 제외되어 denoising upper bound가 제한된 것을 조건적으로 해결하였습니다.
이제 본격적으로 논문 리뷰를 시작하겠습니다.
Abstract
Deep neural networks를 사용하는 많은 Image Denoisier는 Conventional model 기반 method보다 뛰어난 성능을 보여왔습니다. 최근에는 supervised learning을 위한 대규모 real noise dataset을 구축하는 것이 엄청난 부담이기 때문에 Self-supervised learning이 주목받고 있습니다. 가장 대표적인 Self-supervised learning Denoiser는 RF의 중심 픽셀을 제외하는 blind-spot network에 기반합니다. 그러나 입력 픽셀을 제외하는 것은 정보의 일부를 포기하는 것이며, 특히, Target으로 선정한 pixel의 정보를 제외할 때 더욱 중요한 정보의 일부를 포기하게 됩니다. 또한, standard BSN은 독립적으로 분포된 Synthetic noise는 성공적으로 제거하지만, pixel-wise independent noise 때문에 실제 카메라 노이즈를 줄이는 데 실패합니다. 따라서 더 실용적인 Denoiser를 구현하기 위해, 실제 노이즈를 제거할 수 있는 새로운 Self-supervised learning framework를 제안합니다. 이를 위해, 다운샘플링된 블라인드 출력에 의해 네트워크가 지도 학습 손실의 이론적 upper bound를 유도합니다. 또한, blindness를 컨트롤하여 중심 픽셀 정보를 사용할 수 있도록 하는 conditional blind-spot network, C-BSN를 설계합니다. 더 나아가, Random subsampler를 활용하여 노이즈를 공간적으로 상관시키지 않음으로써, C-BSN이 다운샘플링 기반 방법에서 자주 보이던 시각적 아티팩트 문제를 해결하고자 합니다. 광범위한 실험을 통해 제안된 C-BSN이 Self-supervised learning Denoiser로서 실제 데이터셋에서 최첨단 성능을 달성하며, post-processing이나 refinement 없이 질적으로 만족스러운 결과를 보여줌을 입증합니다.
Introduction
Image denoising은 손상된 이미지로부터 깨끗한 이미지를 복원하는 것을 목표로 합니다. 최근에는 CNN을 이용한 image denoisers들은 기존의 연구들보다 훨씬 뛰어난 성능을 달성했습니다. 이러한 Method들은 Network 출력과 실제 깨끗한 이미지 간의 차이를 최소화함으로써 네트워크를 학습시켰습니다.(Supervised learning) 초기 연구에서는 카메라 노이즈를 AWGN으로 가정하고 Supervised learning을 위해 많은 수의 clean-noisy image pair를 생성했습니다. 그러나 AWGN으로 학습된 Denoiser의 경우, 가우시안 분포와 실제 노이즈 분포 간의 차이 때문에 실제 카메라 노이즈에 대해서 일반화하지 못합니다. 특히, 실제 노이즈는 단순한 가우시안보다 더 복잡한 분포를 따르며, Demosaicking과 같은 인접한 픽셀을 이용한 계산을 수행하는 ISP를 통과하면 공간적이고 색채적으로 더 상관관계를 갖게 됩니다.
일부 연구자들은 실제 노이즈를 다루기 위해 보다 더 현실적인 노이즈 모델을 찾으려고 시도했습니다. Raw image의 경우, 노이즈는 Heteroscedastic Gaussian과 같이 비교적 간단한 분포로 모델링 될 수 있습니다. 따라서, 이러한 합성 노이즈가 추가된 원본 이미지는 카메라의 ISP를 통과하여 현실적인 노이즈가 포함된 sRGB 이미지를 생성합니다. 다른 연구들은 Generative model을 사용하여 realistic noise를 합성했습니다. 또 다른 접근 방식은 DND, SIDD와 같은 실제 noise dataset을 구축하는 시도들도 이루어졌습니다. 해당 연구에서는 실제 noise dataset으로 supervised learning을 수행하여 실제 카메라의 노이즈가 성공적으로 감소했습니다. 그러나 노이즈가 있는 이미지에 해당하는 clean image의 pair를 구성하기 위해서는 동일한 장면의 정적인 사진이 필요합니다. 즉, 엄격하게 제어된 촬영과 복잡한 post-processing이 필요하기 때문에 의료 영상과 같이 일부 경우에는 비용이 많이 들거나 불가능할 수도 있습니다. 또한, 실제 노이즈를 캠처하기 위해 특정 환경에서 여러 카메라를 사용했기 때문에, 카메라의 종류에 따라, 촬영 환경에 따라 서로 다른 노이즈 분포를 가질 수 있습니다.
대규모의 pair 한 데이터셋의 필요성을 완화하기 위해, 노이즈가 있는 이미지만 활용하는 Self-supervised Denoising method가 제안되었습니다. 가장 대표적인 방법들은 BSN에 기반하는데, 여기서 각 출력 픽셀을 제외하고 주변 노이즈 픽셀로부터 해당 출력 픽셀을 추정하게 됩니다. 이는 동일한 노이즈 이미지가 입력과 타겟으로 모두 사용되는 Self-supervised loss를 사용하여 네트워크가 학습할 수 있도록 합니다. BSN의 아이디어는 네트워크가 Identity mapping으로 수렴하는 것을 방지합니다. BSN은 noise의 기대값이 0이고 pixel-wise independent하다는 가정하에 깨끗한 이미지로 수렴하는 것으로 나타났습니다. BSN의 다양한 연구들은 입력 이미지를 마스킹하거나 중앙 픽셀을 RF에서 구조적으로 제외하는 네트워크 설계를 함으로 네트워크에 Blindness를 부여했습니다. 그러나 BSN 기반 self-supervised 알고리즘에는 두 가지 한계가 존재합니다.
- 네트워크는 가장 많은 정보를 담고 있는 중앙 픽셀을 활용할 수 없습니다.
- sRGB 영역에서 noise는 pixel-wise spatial correlation을 갖기 때문에 BSN을 실제 노이즈에 적용할 수 없습니다.
본 논문에서는 Blind-spot 없이, 즉 중앙 픽셀 정보를 사용하여 실제 노이즈를 제거할 수 있는 새로운 self-supervised Denoising framework를 제안합니다. 해당 프레임워크는 새로운 Downsampled invariance loss function을 유도함으로써 위에서 언급한 한계를 극복합니다. Downsampled invariance loss는 새로운 conditional blind-spot network, C-BSN)와 랜덤 서브샘플러(random subsampler)를 사용합니다. 구체적으로, C-BSN은 기존의 masked convolution을 switching 함으로써 blindness(중앙 픽셀을 보지 못하는 성질)를 조건부로 제어합니다. 이렇게 함으로써, 네트워크는 자신의 blind-spot에 의해 regularization을 받게 되고, 그 결과 trivial solution(자기 자신을 그대로 출력하는 해, Identity mapping) 을 방지할 수 있습니다. 또한, 시각적 아티팩트를 유발하지 않으면서 노이즈의 상관관계를 약화시키기 위해 랜덤하게 다운샘플링된 서브이미지에 loss를 적용합니다. 추가적으로 학습을 안정화하기 위해 blind self-supervised loss를 사용합니다. 제안된 프레임워크를 평가하기 위해 광범위한 실험이 수행되었으며, 이는 C-BSN이 기존의 self-supervised Denoiser와 심지어 실제 노이즈 데이터셋으로 학습된 일부 지도 학습 방법보다 우수함을 입증합니다.
우리 방법의 기여는 다음과 같이 요약됩니다:
-
Blind-spot 없이 처리될 수 있는 새로운 self-supervised Denoising 프레임워크를 제안합니다. self-supervised loss의 상한을 Downsampled invariance loss로, 이론적으로 유도하며, 이는 마스킹 없이 denoisied image의 정규화로서 마스킹된 출력을 활용합니다. 또한, 제안된 방법은 post-processing이나 noist statistics를 필요로 하지 않습니다.
-
Downsampled invariance loss를 적용하기 위해, 네트워크의 blindness를 조건부로 제어하는 새로운 conditional blind-spot network(C-BSN)을 제안합니다. 실제 카메라 노이즈의 spatial correlation을 처리하기 위해, 시각적 아티팩트를 피하기 위한 Random Subsampler를 제안합니다.
-
C-BSN은 실험에서 확인할 수 있듯이 실제 sRGB 벤치마크 DND, SIDD에서 최첨단 성능을 보여줍니다.
Related Works
Deep Image Denoising
CNN 기반 Image denoisers는 기존의 모델 기반 알고리즘보다 더 뛰어난 성능을 보여왔습니다. 초기 연구에서는 Synthetic Gaussian Noise로 손상된 clean-noisy pair 대규모 데이터셋으로 Deep image denoiser를 학습시켰습니다. DnCNN은 Batch nomalization 및 residual learning을 갖춘 CNN Denoiser를 제안했습니다. 그러나 Synthetic Gaussian noise로 학습된 Denoiser는 실제 노이즈가 있는 이미지를 Denoising 하는 데 잘 일반화되지 못했습니다. 이 문제를 완화하기 위해 CBDNet은 Heteroscedastic Gaussian Noise를 합성하고 이를 카메라 ISP 모델을 통해 처리했습니다. 일부 연구는 GAN 또는 flow-based 방법을 사용하여 현실적인 노이즈를 시뮬레이션했습니다. 실제 sRGB 데이터셋의 개발과 함께, 최근 Denoiser들은 이러한 실제 sRGB 데이터셋에서 학습 및 테스트되었으며, 실제 노이즈가 있는 이미지가 성공적으로 노이즈 제거될 수 있음을 보여주었습니다. 또한, 이전 Denoiser들도 이러한 실제 sRGB 데이터셋으로 재학습하면 더 잘 작동할 수 있다는 것이 입증되었습니다. 그러나 대규모 데이터셋을 수집하는 것은 노동 집약적이고 비용이 많이 듭니다. 더욱이, 특정 데이터셋으로 학습된 네트워크는 데이터셋에 포함되지 않은 다른 카메라로 캡처된 이미지나 의료, 전자, 초음파와 같은 다른 도메인의 이미지에서는 제대로 작동하지 않을 수 있습니다.
Self-supervised Deep Image Denoising
real noisy-clean image pair의 부족을 극복하기 위해, 오직 noisy image로만 학습시키는 self-supervised Denoiser가 제안되었습니다. Lehtinen 연구 등은 학습 pair가 동일한 장면의 두 노이즈 이미지인 N2N을 제안했습니다. Noise2void와 Noise2self는 RF의 중심 픽셀을 마스킹하여 단일 노이즈 이미지만 필요한 Self-supervised Denoiser를 도입했습니다. 입력 픽셀을 마스킹하지 않고, Laine 등은 RF의 반을 활용하는 U-nets의 연결을 갖춘 구조적으로 blind-spot network를 제안했습니다. Wu 등은 마스크 된 컨볼루션 다음에 Dilated Convolution과 1x1 convolution을 사용하여 RF에서 중심 픽셀을 엄격하게 제외하는 D-BSN을 도입했습니다. Self2Self는 Bernoulli dropout을 적용하여 단일 노이즈 이미지로 Denoiser를 학습시켰습니다. Neighbor2Neighbor는 두 개의 서브샘플링된 이미지 간의 Self-supervised loss를 제안했습니다. 또한, 알려진 노이즈 특성을 가정하고 NAC와 Noiser2noise는 노이즈 이미지에 적절한 노이즈를 추가하고 pair를 구성하여 학습 세트로 활용했습니다. Recorrupted2Recorrupted는 가우시안으로 손상된 학습 이미지 쌍을 생성했습니다. 일반적으로 sRGB 도메인의 실제 노이즈는 알려지지 않거나 비정상적인 통계를 가지며 공간적으로 상관되어 있어 위의 방법들을 적용하기 어렵게 만듭니다.
최근에는 위의 BSN 기반방법들의 한계를 극복하기 위한 몇 가지 연구가 제안되었습니다. 실제 노이즈를 spatial correlation을 완화하기 위해 AP-BSN은 Asymmetric PD를 활용했습니다. 학습 중에 노이즈의 독립성을 보장하기 위해 큰 스트라이드(s = 5)를 활용하여 네트워크를 학습시키고 테스트 중에는 더 많은 픽셀 정보를 보존하기 위해 낮은 스트라이드(s = 2)를 사용했습니다. CVFSID는 real-world noisy input에서 clean image와 signal-dependent noise를 분리했습니다. 중심 픽셀의 정보를 활용하기 위해 Laine 등은 베이즈 접근 방식을 활용하여 노이즈 모델을 갖춘 사후 확률로 denoise 된 출력을 post-processing을 수행했습니다. Noise2Same은 blind-spot을 도입하지 않고 self-supervised loss의 upper band를 도출했습니다. Blind2Unblind는 blind-spot을 다시 보이게 하는 revisible loss를 제안했습니다. 그러나, self-supervised image Denoising을 위해 blind-spot과 spatial correlation 처리라는 두 가지 문제를 모두 다룬 연구는 없었습니다.
Method
Overview
Real-world RGB 이미지를 denoise하기 위한 새로운 self-supervised learning framework를 소개하며, 이는 아래 사진과 같습니다.
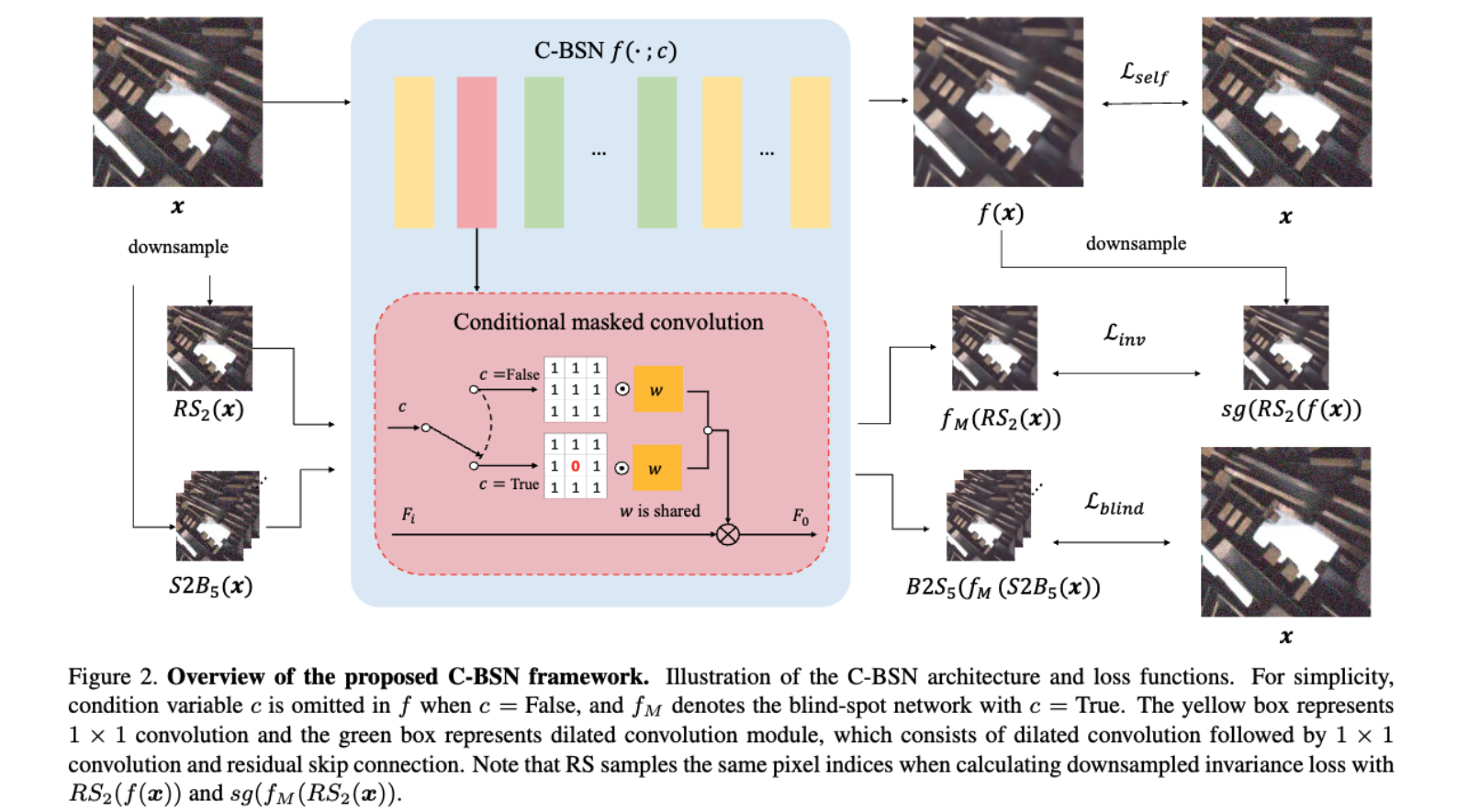
정보 손실 없이 입력 이미지에서 직접 최적화될 수 있는 새로운 loss function을 제안합니다. 이는 Self-supervised loss와 blindness를 제어하는 Downsampled invariance loss를 제안합니다. Downsampled invariance loss의 주요 아이디어는 blind-spot network가 네트워크 파라미터를 보존하면서 동일한 네트워크의 정규화 역할을 하도록 하는 것입니다. 이를 위해 RF에서 중심 픽셀을 선택적으로 마스킹하기 위해 Conditional BSN을 제안합니다. 또한, Spatial correlation을 해제하기 위한 Random Subsampler(RS)를 도입합니다. Pixel-shuffle downsampling(PD)도 노이즈의 공간적 상관 관계를 완화하지만, 심각한 Checkerboard artifacts를 생성합니다. 반대로 본 논문에서 제안하는 RS는 각 gird에서 무작위로 픽셀을 추출하므로 이러한 아티팩트를 생성하지 않습니다. 노이즈 입력 이미지를 x로, clean image를 y로 나타냅니다. 간결성을 위해 채널 차원은 생략하여 표기하고, 공간 차원은 벡터화합니다. 즉, 입니다.
Revisiting Noise2Same
노이즈가 평균이 0이고 pixel-wise independent라는 가정 하에, Noise2Self 에서는 J-invariant이면 self-supervise loss가 supervised loss와 동등하다는 것을 증명했습니다.
J-invariant란?

Define 1. 차원 집합 {1, ..., m}을 분할한 집합을 라고 하고, 부분집합을 라고 합니다. 함수 가 J-invariant라는 것은, 출력 의 해당하는 부분 가 입력 x의 부분 값에 의존하지 않는다는 의미로 즉, 위치의 출력은, 위치 입력을 직접 보지 않는다는 의미입니다. 모든 에 대해서 J-invariant라고 하면, 함수 f는 J-invariant라고 합니다. 즉, J를 예측할 때, 자기 자신의 입력에 의존하지 않음을 의미합니다. 이 때, 는 벡터 를 J에 해당하는 좌표만 남긴 것을 의미합니다.
Noise2Same 논문은 엄격한 한 함수는 Denoiser에 대해 최적이 아니라는 것을 분석했습니다.
이 때, 완전한 는 출력이 자기 위치 입력을 절대로 보지 않음을 의미합니다. 이는 이론적으로 안전하지만, 실제 denoising에서는 정보 손실이 너무 큰 한계가 발생합니다. 이로 인해서 Oversmoothing, 디테일 손실, 성능의 한계로 이어집니다.
대신 Noise2Same은 를 엄격한 제약으로 강제하지 않고, supervised loss의 upper bound를 최소화하는 방식으로 제약을 완화하여 적용합니다. 즉, 이를 강제로 유도하는 것이 아닌 페널티로 추가하여 를 하지 않으면 손해를 보게 하는 방식으로 완화된 를 적용합니다.
여기서 는 평균이 0이고 표준 편차가 1이 되도록 정규화된 입력 이미지입니다. 첫 번째 항은 self-supervised loss이고 두 번째 항은 f가 얼마나 이어햐 하는지를 제어합니다.
첫 번째 항(self-supervised loss)은 출력 가 입력 에서 너무 멀어지지 않도록 하며 Ground Truth인 Clean signal을 구할 수 없기 때문에 를 사용한 self-supervised loss입니다.
두 번째 항( 조절 항)은 와 는 J 위치 입력만 다른 두 입력으로 만약 f가 라면 이 차이를 줄이는 것을 목표하며 이를 강제하는 것이 아니라 를 통해 의 정도를 조절합니다.
Noise2Same은 "출력이 자기 자신을 그대로 복사하지 못하게 하기 위해 라는 개념을 도입하되, 이를 절대적인 제약으로 강요하지 않고 supervised loss의 upper bound를 줄이는 방향으로 얼마나 할지를 부드럽게 조절하는 Method 입니다."
해당 는 참고해주세요.
Downsampled Invariance Loss
Noise2Same upper bound는
에서 가 와 상관 관계가 없을 때 성립합니다. AWGN과 같은 pixel-wise independent noise는 해당 제약 조건을 만족하지만, 실제 노이즈는 공간적으로 상관되어 있어 를 더 이상 적용할 수 없습니다. 이를 해결하기 위해 부분 집합 J를 random하게 샘플링하는 대신, 이전 연구를 따라 correlation을 줄이기 위해 다운샘플링된 이미지를 샘플링합니다.
Proposition 1. 는 정규화된 (zero-mean, unit variance) 노이즈 이미지이며 clean image y가 주어졌을 때의 조건부 기대값이 입니다. 이는 self-supervised denoising에서 가장 기본적인 가정을 의미하고 있습니다.
해당 가정을 통해서 L2 loss에서 기대값을 최소하면 clean으로 수렴한다는 논리가 성립하게 됩니다. 이는 이전에 리뷰한 N2N에 정리된 내용이 있습니다.
는 임의의 다운샘플링 연산이라고 하며, 는 stride s factor로 다운샘플링된 픽셀들의 집합을 의미합니다. 즉, stride s factor를 활용한 downsampled sub image를 라고 하며 이는 pixel-wise independent를 만족하며 그리고 은 blind-spot network를 가정합니다.
그래서 이제 해당 수식에 대해서 다시 한번 더 해석해 보도록 하겠습니다.
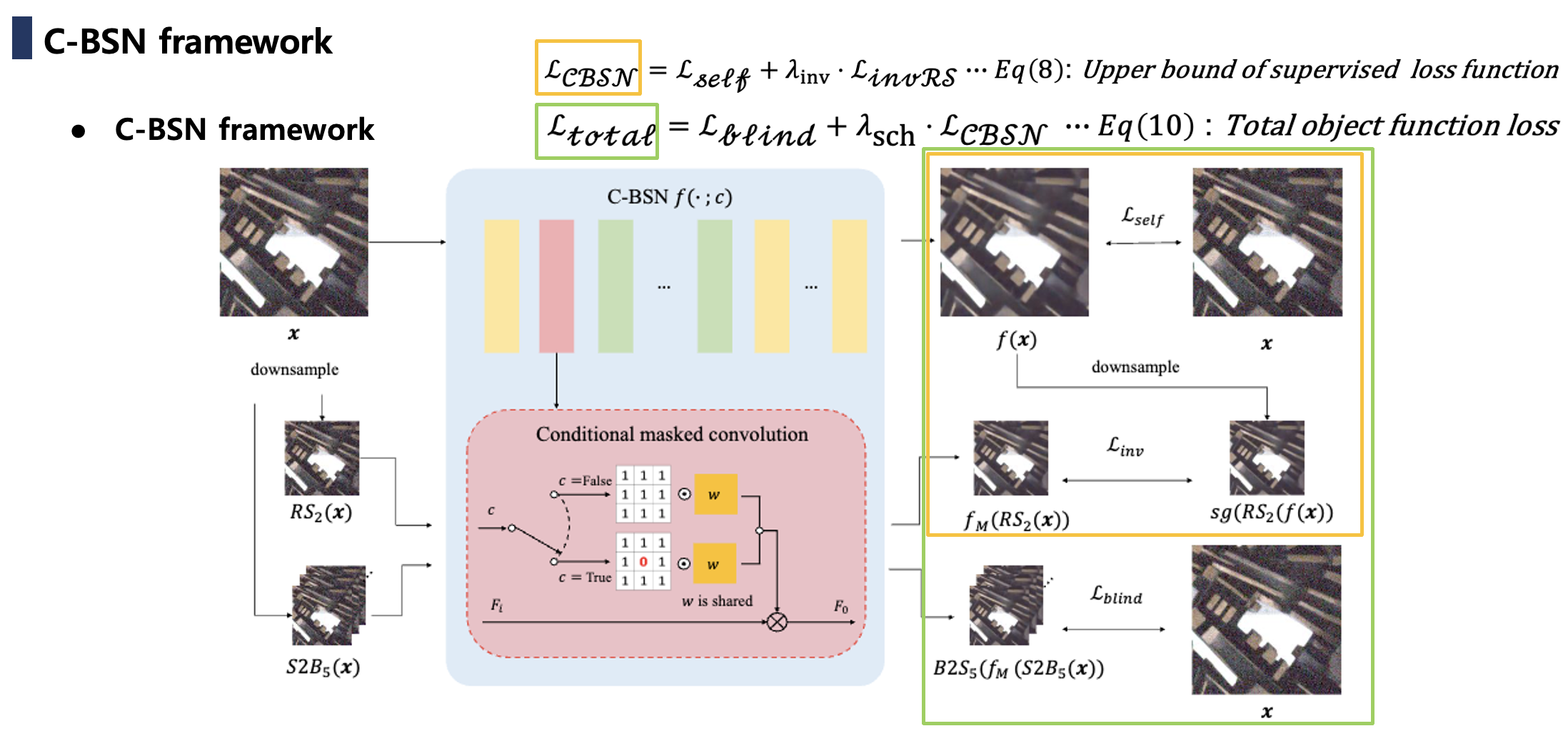
해당 수식이 이야기하는 것은 Supervised loss 는 self-supervised loss와 다운샘플 공강에서의 blind inavariance loss로 Upper bound를 잡을 수 있습니다.
- : 전체 출력 를 다운 샘플
- : 다움샘플된 입력을 blind-spot 네트워크로 복원
위 두 가지의 결과가 서로 비슷해야 합니다. 즉, 어떤 해상도, 샘플링에서 보든, 네트워크의 예측이 서로 모순이 되면 안 됨을 의미합니다. - : 다운샘플 공간과 원본 공안의 차원 수가 각각과 이기 때문에 차원 보정을 위한 스케일링 보정의 역할
Proposition 1은 self-supervised loss와 Downsampled output과 Downsampled input의 blind 출력 간의 정규화 항을 사용해 supervised loss의 상한을 제공합니다. 보충 자료에서 Eq. (1)의 가 와 상관 관계가 없는 로 대체될 수 있음을 증명합니다.이는 두 번째 항을 새로운 다운샘플링 불변 손실로 단순화합니다.
여기서 는 stop-gradient 연산입니다. Proposition 1을 사용하여 Eq. (2)의 오른쪽 항을 최소화함으로써 디노이징 네트워크를 최적화할 수 있습니다.
Conditional Blind-Spot Network
Eq.(3)은 network 의 파라미터가 blind-spot에 관계없이 공유되어야 함을 요구합니다. Noise2Same의 경우, Network 구조가 아닌 입력 픽셀 마스킹으로 인해 blindness가 발생하므로 네트워크는 변경되지 않습니다. 그러나 마스킹은 입력의 train-test의 불일치를 야기하고, 손실이 마스크 된 픽셀을 통해서만 역전파될 수 있기 때문에 훈련 효율성을 저해합니다. 반면에 D-BSN과 같은 네트워크는 아키텍처에 의해 중심 픽셀을 제외합니다. 이것은 blindness를 제거할 수는 없지만, 모든 단일 픽셀을 통해 최적화될 수 있습니다. D-BSN 아키텍처로 blindness를 조건부로 제어하려면, 훈련 파라미터를 공유하면서 network 구조를 변경해야 합니다. 이를 위해, 입력 이미지를 마스킹하지 않고 blind-spot을 만들기 위한 Conditiional blind-spot(C-BSN)을 제안합니다.
D-BSN에서 blindness는 마스크 된 컨볼루션에 의해 유도되며, dilated convolution은 masked pixel 정보가 혼합되는 것을 방지합니다. 주어진 조건 에 따라 커널의 마스크를 변경하여 마스크 된 컨볼루션의 동작을 전환합니다.
여기서 는 컨볼루션 필터이고, 는 bias이며, 와 는 각각 inputs features, output features입니다. 는 는 Dirac delta kernel이고, 1은 모든 원소가 1인 matrix입니다. 간단히 하기 위해, 일 때 조건 변수 를 생략하고, blind-conditioned network만 로 표현합니다. 우리는 훈련 단계에서만 을 사용하며, 모든 테스트 이미지는 정보 손실 없이 non-blind network 로 추론됩니다.
conditional masked convolution을 적용하면 kernel의 중심이 c가 False일 때, 0으로 설정되므로 출력 특징의 분포를 변경할 수 있습니다. 그러나 masked pixel을 활용하기 위해 는 과 다르게 훈련되어야 합니다. 또한, 커널의 중심은 수정된 feature distribution을 기반으로 과 독립적으로 훈련됩니다. 따라서 사이의 정규화 없이 커널과 그 마스크를 사용합니다.
Random Subsampler
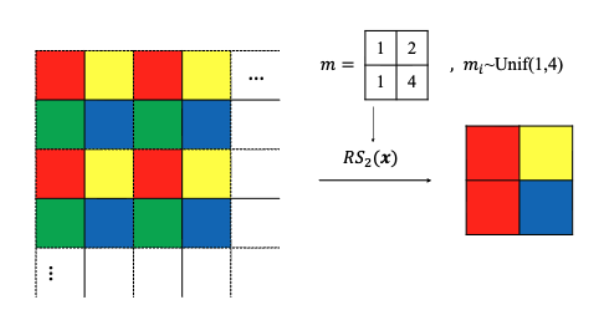
Downsampled Invariance Loss에서, 우리는 spatial correlation이 없는 이미지의 부분 집합을 추출하기 위해 invariance loss에 Downsampler를 도입했습니다. 해당 제약 조건은 pixel-wise synthetic noise에서는 보장이 되지만, 실제 노이즈는 이를 따르지 않습니다. Spatial correlation을 제거하기 위해, Zhou et al.과 Lee et al.은 Pixel-shuffle Downsampling(PD)을 활용했습니다. PD는 Pixel-shuffle의 역연산이며, 서브이미지의 모자이크를 생성합니다. 그러나 downsampled invariance loss에 PD를 직접 적용하는 것은 Eq. (2)의 기대값이 서브이미지 에 대해 계산되기 때문에 간단하지 않습니다. 이러한 노이즈의 상관관계를 끊어내기 위한 다른 접근 방식은 space2batch (S2B) 연산으로, pixel down-shuffled subimages가 채널 차원이 아닌 배치 차원을 따라 연결됩니다. 그러나 S2B를 단순히 적용하면 결과에 심각한 시각적 아티팩트가 발생합니다. S2B 이미지가 입력으로 사용될 때, 모든 서브이미지는 독립적으로 계산되며, 이는 batch2space (B2S) 업샘플링된 출력에서 checkerboard 패턴을 초래하여 에 잘못된 수렴 방향성을 제공합니다.
이 문제를 해결하기 위해, 우리는 checkerboard artifacts를 피하기 위한 다운샘플링 연산자인 랜덤 서브샘플러 를 제안합니다. 그림 3은 우리의 랜덤 서브샘플러의 세부 사항을 보여줍니다. 예를 들어, 스트라이드 2를 사용할 때, 입력 이미지는 그리드 셀로 나눕니다. 각 셀에서, 셀 내의 한 픽셀이 random하게 추출되어 배 다운샘플된 이미지를 만듭니다. 인접한 셀의 randome하게 다운샘플된 픽셀이 또한 인접한다면, 상관관계가 상당히 발생할 수 있습니다. 그러나 이 경우, 다른 주변 픽셀로부터의 평균 거리가 커지고, 서브샘플링된 픽셀 간의 예상 평균 거리는 여전히 s로 근사 될 수 있습니다. 따라서 PD와 마찬가지로, 랜덤 서브샘플러에 의해 예상 공간 상관관계가 약화됩니다.
Total Loss function
이 섹션에서는 전체 손실 함수를 제공합니다. 간단한 표기를 위해, 우리는 pixel-averaged norm을 나타내기 위해 ∥⋅∥를 사용합니다. self-supervised loss에서 MSE를 으로 대체합니다.
또한, Downsampled invariance loss의 제곱근 평균(RMS)을 L1 norm으로 대체하고, 다운샘플링 연산으로 랜덤 서브샘플러를 사용하는 것이 유익하다는 것을 발견했습니다.
섹션 3.3의 명제 1로부터, 우리는 지도 손실 함수의 상한을 최소화합니다.
여기서 는 downsampled invariance loss의 기여도를 제어하는 하이퍼파라미터입니다. 더 많은 공간 정보를 반영하기 위해 RS의 스트라이드를 2로 설정합니다.
또한, 훈련을 안정화하기 위해 blind2Unblind와 같이 블라인드 조건부 네트워크의 자기 지도 손실 를 도입합니다.
다운샘플 불변성 손실은 스트라이드 2를 활용하는 반면, Eq. (9)의 스트라이드는 이상적인 BSN이 가능한 한 적은 상관관계로 훈련되어야 하므로 5입니다.
블라인드 자기 지도 손실이 없으면, 훈련 초기 단계에서 는 무작위이므로 에 잘못된 지도를 제공합니다. 따라서 에서 로의 전환을 용이하게 하기 위해 에 블라인드 자기 지도 손실을 추가합니다. 추가적으로, 우리는 에 대한 warm-up scheduling을 채택합니다. Scheduling parameter 가 의 영향을 점진적으로 증가시킵니다. 이 모든 것을 고려할 때, 총 목적 함수는 다음과 같이 정의됩니다.
Experiments
Implementation Details
C-BSN은 real-world sRGB noisy image만으로 학습되며, test set만으로도 학습 가능한 완전 self-supervised denoising 모델이고, 테스트 시 downsampling 없이 단일 추론으로 동작한다
실제 sRGB 카메라 노이즈에 대해 훈련 및 테스트를 진행합니다. 본 연구의 모델은 두 가지 설정으로 훈련됩니다. 하나는 외부 데이터셋으로 훈련하고, 다른 하나는 테스트 세트로 직접 훈렵합니다. 외부 훈련 세트의 경우, 다섯 대의 스마트폰 카메라로 촬영된 real noisy-clean image pair 320개를 포함하는 SIDD medium set을 사용합니다. 훈련 샘플로는 noisy image만 사용하고 clean image는 사용하지 않습니다. 추가적으로, C-BSN은 훈련을 위해 노이즈 이미지만 필요하므로, C-BSN†는 테스트 세트 이미지에 대해서만 훈련합니다. DND는 4 대의 다른 카메라에서 촬영된 50개의 고해상도 노이즈 이미지로 구성됩니다. SIDD, DND benchmark 모두 PSNR 및 SSIM을 온라인으로 평가하여 GT 이미지를 제공하지 않습니다.
훈련 이미지에서 240 x 240 크기의 패치를 잘라내고 미니 배치 크기 4를 사용합니다. 각 이미지 패치에 대해 데이터 증강을 위해 90◦ 회전 및 좌우 반전을 무작위로 적용합니다.
입력 이미지는 평균이 0이고 표준 편차가 1이 되도록 정규화합니다.
0으로 나누는 것을 방지하기 위해 표준 편차는 다음 수식으로 계산됩니다.
손실 함수의 효과만을 비교하기 위해 수정된 Masked convolution을 사용하여 AP-BSN의 구조를 따릅니다. Proposition 1에서 도출된 대로 를 2로 설정하고, 처음 200,000번의 반복 동안 0에서 1까지 선형적으로 증가하는 에 대한 warm-up 전략을 사용합니다. 초기 학습률 1e-4를 사용하여 Adam optimizer를 사용합니다. C-BSN은 400,000번의 반복 동안 optimize되고 학습률은 100,000의 반복마다 절반으로 줄어들고 2e-5로 제한합니다. C-BSN은 입력 이미지에 대한 단일 추론을 필요로 하며, 테스트 시에는 다운샘플링 연산이 수행되지 않습니다.
아래는 위의 내용을 Table로 정리한 내용입니다.
dataset & Train/Test setting
| 구분 | 내용 |
|---|---|
| Noise 유형 | Real-world sRGB camera noise |
| 학습 설정 | ① 외부 데이터셋 기반 학습 ② 테스트 세트 직접 학습 |
| 외부 학습 데이터셋 | SIDD Medium |
| SIDD 구성 | 5대 스마트폰 카메라로 촬영된 320 noisy-clean image pairs |
| 학습 데이터 사용 방식 | Noisy image만 사용, clean image는 사용하지 않음 |
| Test-set-only 학습 | C-BSN†는 테스트 세트 이미지로만 학습 |
| 평가 데이터셋 | DND, SIDD benchmark |
| DND 구성 | 4대 카메라에서 촬영된 50장 고해상도 noisy image |
| Ground Truth 제공 여부 | ❌ 없음 |
| 평가 방식 | PSNR / SSIM 온라인 평가 |
Data pre-processing & Augmentation
| 항목 | 설정 |
|---|---|
| Patch 크기 | 240 × 240 |
| Mini-batch size | 4 |
| Data augmentation | Random 90° rotation, 좌우 flip |
| 입력 정규화 | Mean = 0, Std = 1 |
| Std 계산식 | |
| Std 계산식 목적 | division by zero 방지 |
Network Architecture & Loss
| 항목 | 설정 |
|---|---|
| 기본 구조 | AP-BSN architecture |
| 구조 수정 | Masked convolution만 수정 |
| 비교 목적 | Loss function 효과만 비교 |
| 2 (Proposition 1 기반) | |
| Warm-up 적용 | |
| warm-up | 0 → 1 (초기 200,000 iterations) |
Optimization
| 항목 | 설정 |
|---|---|
| Optimizer | Adam |
| Initial learning rate | 1e-4 |
| Total iterations | 400,000 |
| Learning rate decay | 매 100,000 iterations마다 ½ |
| Minimum learning rate | 2e-5 (lower bound) |
inference setting
| 항목 | 설정 |
|---|---|
| Inference 방식 | Single forward pass |
| Test-time downsampling | ❌ 사용하지 않음 |
Comparison with state-of-the-art algorithms
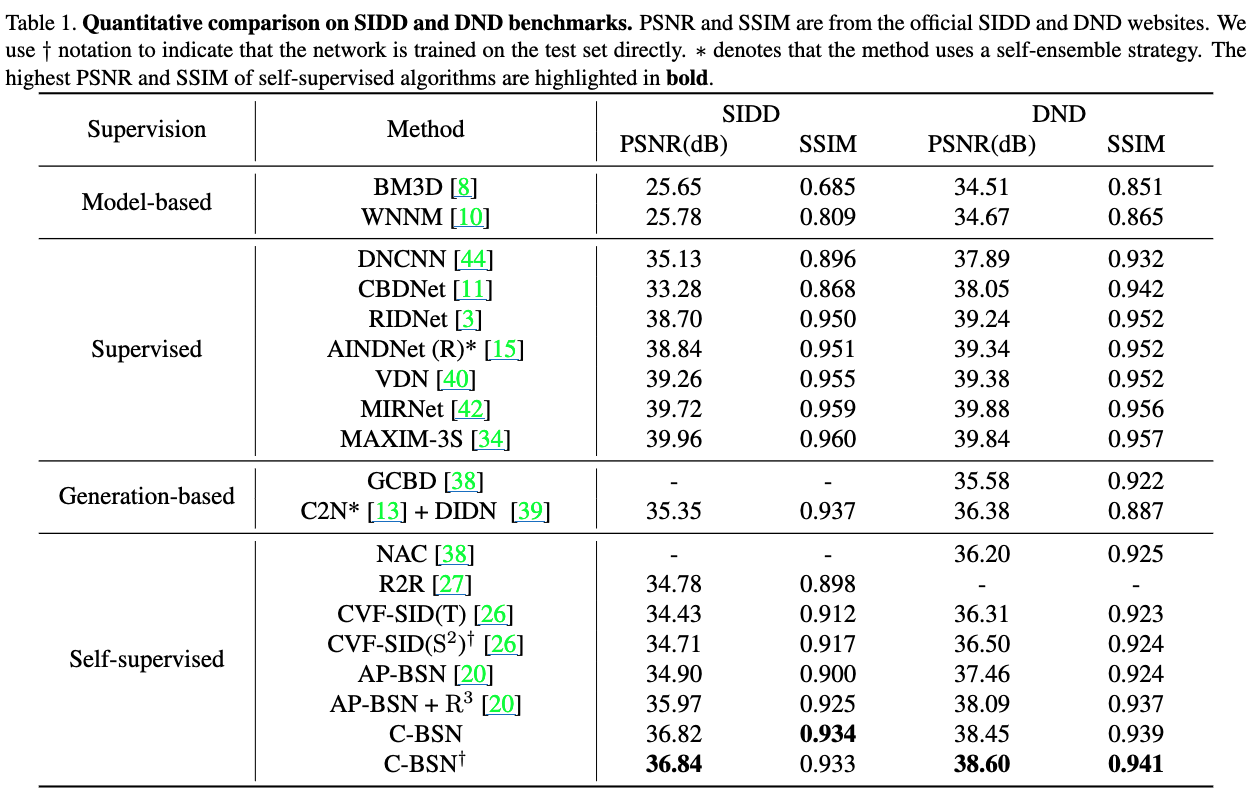
본 연구의 C-BSN을 supervised, generation-based, self-supervised 방법과 비교합니다. supervised model은 SIDD의 실제 noisy-clean pair로 훈련되며, generation-based modeldms realistic noise를 시뮬레이션하고 생성된 pair로 Denoiser를 훈련합니다. Self-supervised model은 노이즈 이미지만 사용하여 네트워크를 훈련합니다. Real-noise 제거를 목표로 하는 Self-supervised model만 비교하고자 합니다. Table1은 SIDD 및 DND benchmark에서의 PSNR 및 SSIM을 비교합니다. 제안된 C-BSN은 다른 self-supervised method들보다 큰 차이로 우수하며, 일부 supervised network보다 더 뛰어납니다. 테스트 데이터셋으로 훈련된 C-BSN†는 외부 데이터셋으로 훈련된 C-BSN보다 약간 더 높은 PSNR을 보입니다. 이는 테스트 세트와 동일한 노이즈 분포로 훈련하는 것이 네트워크 성능에 이점을 준다는 것을 보여줍니다(Self-supervised method의 이점을 시사함.). 구체적으로, C-BSN†는 CVF-SID (S2) 및 AP-BSN+보다 각각 2.13dB 및 0.51dB 더 높은 성능을 보여, 본 연구 프레임워크의 효과를 입증합니다. 제안된 downsampled invariance loss과 C-BSN 구조는 블라인드 스팟 정보와 전체 이미지 해상도를 사용한 단일 추론을 활용합니다.
Figs.1, 4, 및 5는 DND 및 SIDD 벤치마크에서 자기 지도 학습 방법들의 정성적 비교를 보여줍니다. CVF-SID의 출력은 여전히 노이즈가 많고 평탄한 영역에 얼룩을 보이는 것을 알 수 있습니다. AP-BSN은 체커보드 아티팩트에 취약하며 AP-BSN+는 이미지 디테일을 blur하게 만듭니다. 반면에, 저희 C-BSN은 성공적으로 노이즈를 줄이고 이미지의 구조를 보존하는 것을 볼 수 있습니다.
AP-BSN+ 및 CVF-SID(S2)는 네트워크의 여러 번의 실행을 요구하는 개선 기법을 활용한다는 점(Refinement)에 유의하십시오. AP-BSN+는 노이즈가 있는 픽셀을 무작위로 교체하고 무작위로 교체된 입력의 디노이즈된 결과를 평균냅니다. CVF-SID(S2)는 denoised 이미지를 새로운 학습 데이터셋으로 사용하여 두 번째 모델을 학습시키고 두 개의 연속적인 모델로 이중 디노이즈합니다. 반면에, 저희는 후처리 없이 단일 추론으로 최첨단 결과를 달성합니다.

Ablation Study
Ablation Study란?
Ablation Study는 모델의 성능에 가장 큰 영향을 미치는 요소를 찾기 위해 모델의 구성요소 및 feature들을 단계적으로 제거하거나 변경해 가며 성능의 변화를 관찰하는 방법이며 모델의 핵심적인 구성요소와 하이퍼파라미터 등을 파악할 수 있습니다.
해당 섹션에서는 제안된 방법의 효과를 보여주기 위해 Loss function, Downsampler and blind loss에 대한 Ablation Study를 수행합니다. Training cost를 줄이기 위해, 120 x 120 patch size로 network를 학습시키고 SIDD validation set에서 평가합니다.
Ablation on loss function
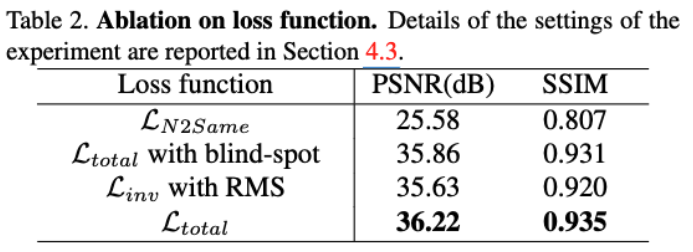
Downsampled invariance loss and conditional blind-spot network의 효과를 평가하기 위해 다양한 loss function을 분석합니다. Table2는 4가지 다른 loss function을 사용하여 SIDD validation dataset에서 PSNR을 보고합니다. 의 경우, 모든 조건 C를 False로 설정하여 네트워크가 블라인드 되지 않도록 하고, blindness는 Noise2Same과 같이 입력을 마스킹합니다. 으로 학습된 네트워크는 수렴에 실패하며, 이는 실제 노이즈 입력의 Spatial correlation을 줄이기 위해 downsampling operation이 필요함을 보여줍니다. 블라인드 스팟이 있는 은 원본 D-BSN으로 학습되며, 이는 블라인드 스팟을 제거할 수 없습니다. 다른 loss function은 그대로 유지하면서 네트워크를 Blind 하기 위해 모든 C를 True로 설정합니다. 이는 네트워크가 전체 이미지 해상도에서 에 의해 학습되기 때문에 AP-BSN 또는 D-BSN과 다르다는 점에 유의하십시오. C-BSN 구조 없이 PSNR이 크게 떨어지는 것을 볼 수 있으며, 이는 중심 픽셀 정보의 중요성을 검증합니다. 마지막으로, 와 는 Noise2Same에서와 같이 RMS를 사용하여 로 학습됩니다.의 L1 norm이 RMS로 대체될 때 성능이 저하되며, 이는 L1 norm이 출력 품질을 크게 향상시킬 수 있음을 보여줍니다.
Ablation on downsampler.


Downsampled invariance loss에서 다양한 Downsampler로 훈련된 네트워크를 평가하여, 두 개의 stride를 갖는 random sampler의 효과를 검증합니다. 두 개의 stride 값인 2와 5를 사용하여 3가지 Downsampler, 즉, PD, S2B, RS를 테스트합니다. 각 stride는 더 많은 정보를 위한 작은 stride와 실제 noise의 spatial independency를 위한 큰 stride를 나타냅니다. Table.3과 Fig.6은 각 다운샘플링 연산의 효과를 정량적 및 정성적으로 보여줍니다. Section 3.5에서 논의된 바와 같이 PD로 훈련된 네트워크는 S2B보다 성능이 떨어지며 s x s 크기의 시각적 아티팩트를 생성합니다. stride 5로 훈련된 모델은 이미지가 흐릿하고 가장자리 주변의 노이즈를 제거하지 못합니다. 이는 Downsampled invariance loss에서 작은 stride를 사용하여 입력의 saptial information을 유지하는 것이 유리함을 보여줍니다. stride와 관계없이 S2B, PD보다 우수하며, RS는 S2B보다 우수합니다. 두 개의 stride를 갖는 PD와 S2B는 Saptial correlation noise를 줄일 수 있지만, 심각한 Checkerboard artifacts도 생성합니다. 반면에 제안된 는 가장 높은 PSNR과 시각적으로 만족스러운 결과를 아티팩트 없이 달성하며, 각각 및 보다 0.90dB 및 0.20dB 더 나은 성능을 보입니다.
Ablation on the blind loss
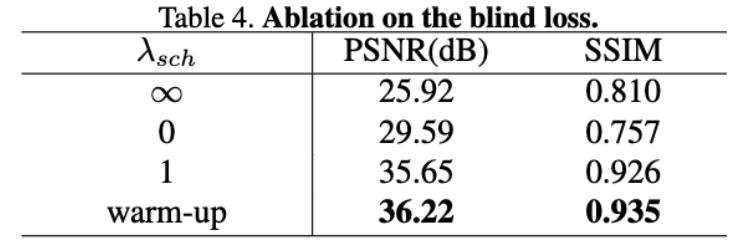
Blind loss, 의 효과를 조사합니다. 은 supervised loss의 upper band이지만, 없이는 훈련이 불안정합니다. Table.4와 같이 표 4와 같이 하이퍼파라미터 를 다른 조건으로 설정합니다. 일 때, blind loss를 사용하지 않고 만으로 C-BSN을 훈련합니다. 이 경우 네트워크는 Denoising을 학습하지 못하고 0을 출력하여 입력 평균값의 flat한 이미지를 생성합니다. 일 때, 손실함수 AP-BSN과 같은 입니다. 그러나 blind-spot 없이 원본 크기 입력으로 AP-BSN을 처리하면 심각한 아티팩트와 낮은 이미지 품질이 발생합니다. 일 때, warm-up에 대해 최적이 아닌 PSNR을 보이지만, 때때로 와 동일한 local optima로 수렴하기도 합니다. 제안된 warm-up scheduling은 약 0.57dB의 PSNR 개선을 가져오고 훈련 절차를 안정화합니다.
Conclusion
실제 카메라 노이즈 reduction을 위한 새로운 self-supervised Denoising 프레임워크인 C-BSN을 제시했습니다. Supervised loss의 upper band이며 blind-spot 없이 훈련을 가능하게 하는 downsampled invariance loss를 도출했습니다. C-BSN 구조는 blind-spot을 조건부로 제어하고, random-subsampler는 시각적 아티팩트를 도입하지 않고 노이즈를 분리합니다. post-processing 및 refinement 없이도, 제안된 C-BSN은 최근의 self-supervised denoisers보다 우수한 성능을 보입니다. AP-BSN + 및 CVF-SID는 네트워크의 여러 번 반복하는 Refinement를 활용하지만 본 논문의 경우 복잡한 post-processing이 필요하지 않습니다. AP-BSN + 은 노이즈가 있는 픽셀을 무작위로 교체하고 무작위로 교체된 입력의 Denoising 된 결과를 평균냅니다. CVF-SID()는 디노이즈된 이미지를 새로운 학습 데이터셋으로 사용하여 두 번째 모델을 학습시키고 두 개의 연속적인 모델로 이중 디노이즈합니다. 반면에, 저희는 후처리 없이 단일 추론으로 최첨단 결과를 달성합니다.
본 논문에 대한 구현과 관련 실습 코드는 github를 참고해주세요!
해당 논문의 주된 Contribution은 크게 다음과 같다고 생각합니다.
- masking을 수행하지 않고 full observation에서 Denoising을 수행했습니다.
- upper bound of supervised loss를 통해서 보조 네트워크 을 학습 시키고 이를 Anchor로 두고 궁극적으로 학습시키고자 하는 를 학습시켰습니다.
해당 논문 리뷰 세미나를 통해서 논문을 한줄 한줄 공부하는 것도 중요하지만 전반적인 흐름을 정리할 필요가 있다고 교수님께 조언을 받았습니다. 즉, 논문에서 언급된 기존의 선행 연구들은 어떤 Contribution이 있고 어떤 한계점이 있어서 이를 어떤 방식으로 해결하는지 흐름에 대한 정리를 할 필요가 있으며, 본 논문에서 제안하는 핵심 Contribution을 정리하는 것이 중요하다고 해주셨습니다.
이를 기반으로 앞으로 읽을 논문들에 대해서 리뷰할 수 있도록 노력해보겠습니다!!
감사합니다❗️
Seminar 자료
해당 세미나를 준비하면서 사용했던 자료를 함께 업로드 하면 수식에 대한 이해나 의미들을 더 자세히 이해할 수 있을 것 같아 첨부합니다!!













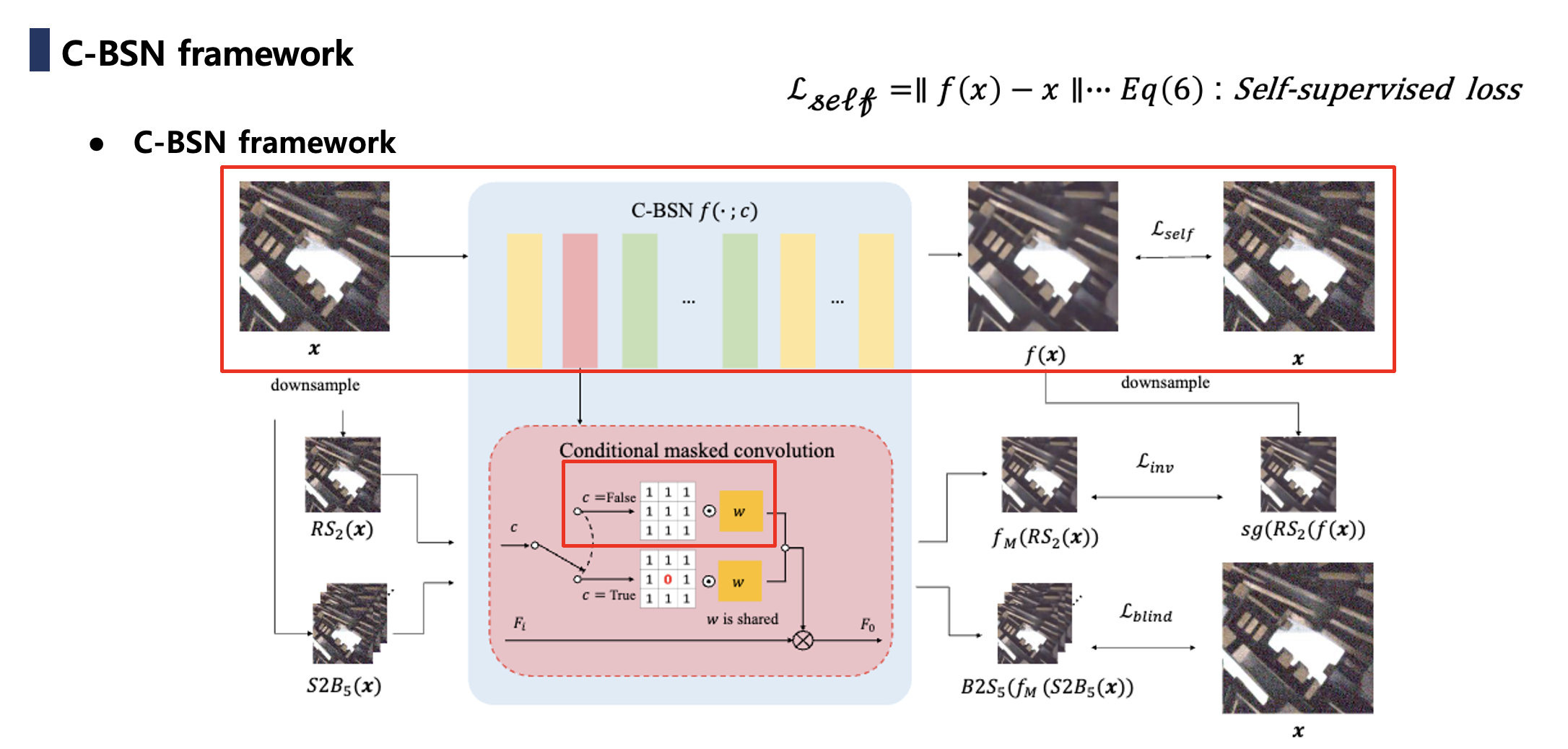
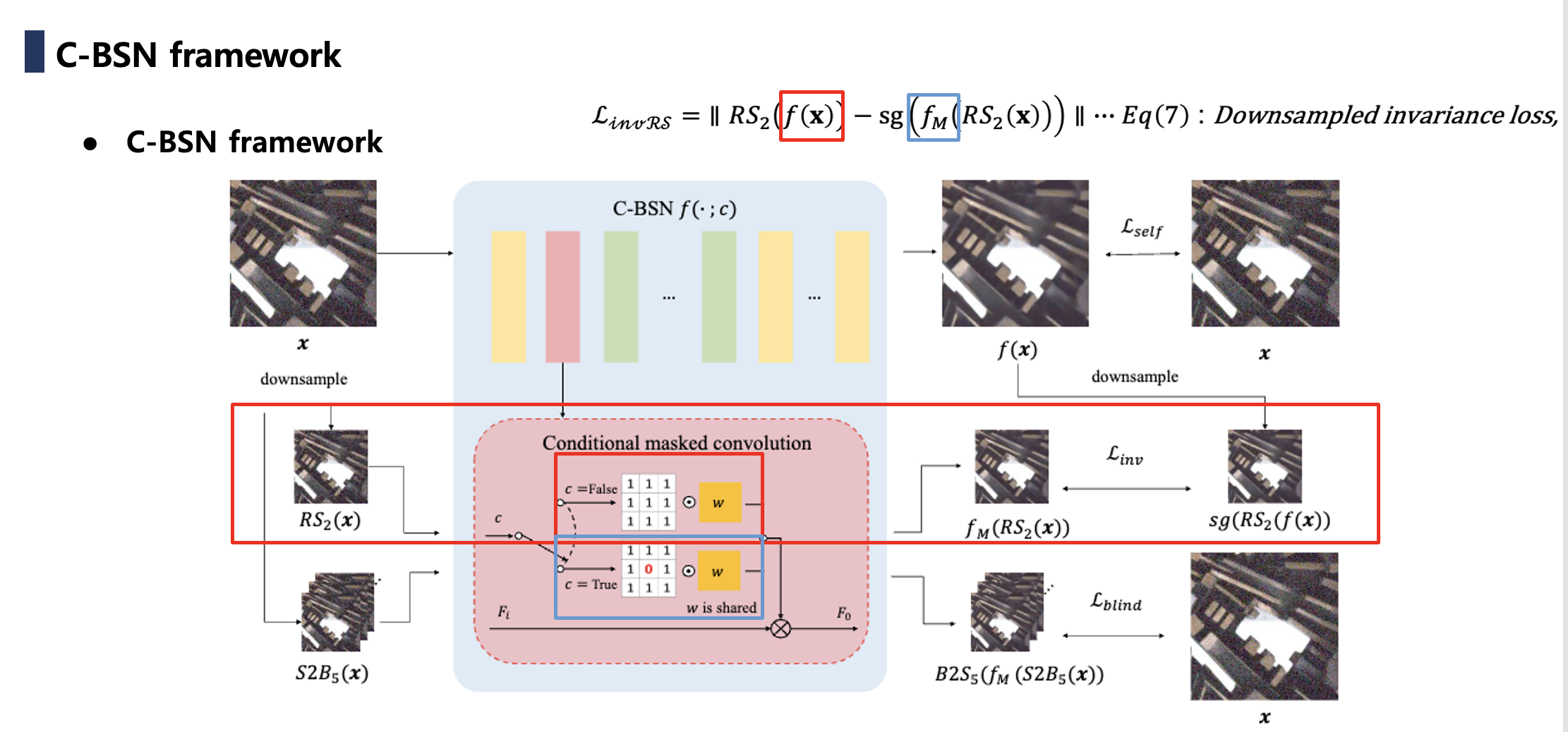
위 사진이 본 논문에서 가장 중요한 Contribution이라고 생각합니다. Downsampled invariance loss를 통해서 blind-spot network(conditiional = TRUE)를 Anchor로 두어 저희가 궁극적으로 학습하고자 하는 full observation을 입력으로 받는 를 따라 학습시킬 수 있게 되는 중요한 부분입니다.