
- 전체보기(10)
- VISION(3)
- linux(2)
- CV(2)
- 3d pose(2)
- CNN(1)
- Camera Calibration(1)
- Multimodal(1)
- ros2(1)
- Human Pose Estimation(1)
- 연구실(1)
- segmentation(1)
- docker(1)
- 자율주행(1)
- 3d depth(1)
- transformer(1)
프로젝트 팀원 의견 충돌 : 조율(1)
대학원 한 연구실의 랩장(팀장)이 되기 전까지는 원래 듣기보다는 학부 및 외부 프로젝트 및 과제 모든 면에서 팀장을 많이 하다보니까 의견을 듣기 보다는 말하는 입장이었다. 하지만, 연구실에서 랩장이 되면서 내가 아는 사실은 팩트 기반으로 전달하기 위해서 누군가의 의견을

차량 AI - segmentation
object detection과 다르게 도로에 레이블을 지정하기 위해 경계 상자를 사용하지 않는다는 차이점이 존재한다.detection은 카테고리가 어떤 boundary내에서 이루어 진다면 segmentation은 all pixel에 카테고리를 정해준다. sematic

자율주행 개발을 접하다...
현재 구현되어있는 차량에서의 기능으로는 LKAS (Lane keeping Assist system)을 사용하고 있지만, 현재 우리가 전동차를 통해서 구현한 내용은 LKS (Lane keeping system)입니다.단, 우리 시스템에서 현재 아직까지는 Route Pla

Docker와 ROS2의 만남
docker 설치하기 이전에 설치될 수 있었던 데이터들을 미리 제거하고 설치를 하는 과정이다.아래와 같이 나오면 설치가 성공한 것이다.https://docs.docker.com/desktop/install/ubuntu/해당 url에서 DEB package 클릭
RAM 용량 확인 및 swap 증가
ROS2, AI 추론이 동시에 사용하기 때문에 모델을 경량화시키지않는다면, 우리가 제공하는 교육 코드는 많은 메모리 사용을 하게 된다. 이러한 문제 중에서 가장 큰 문제는 다음과 같았다. 모든 노드를 동작시키면서 구글 크롬을 실행시키는 과정 속에서 PC가 멈추는 현상이

Camera Calibration
카메라의 파라미터(parameters)를 추정하는 과정을 카메라 캘리브레이션3차원 점들이 영상에 투영된 위치를 구하거나 역으로 영상좌표로부터 3차원 공간좌표를 복원할 때에는 이러한 내부 요인을 제거해야만 정확한 계산이 가능내부 요인의 파라미터 값을 구하는 과정 = ca

Human Pose Estimation
Pose estimation은 영상 속에서 human object 자세(pose)를 추정하는 것입니다. 사람의 자세를 구성하는 주요 관절을 key point or joint라고 한다. 그래서 특정 pose를 만들어내는 key-points들을 찾아내는 task입니다.✅
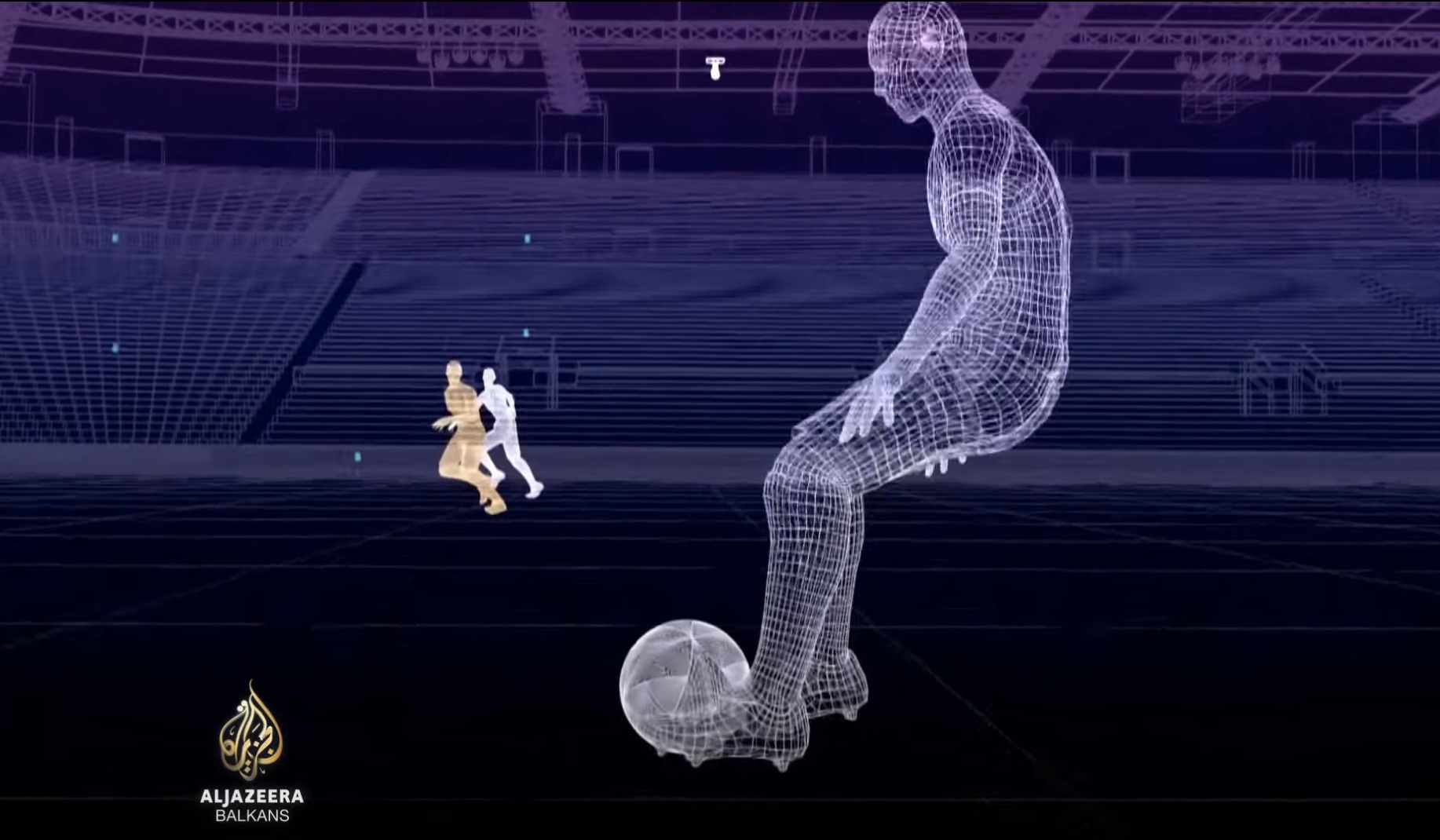
월드컵 기간에 바라보는 AI 심판?
2022년 카타르 월드컵이 한창 진행되고 있다. 지난 11월 22일에 아르헨티나는 사우디아라비아와 조별리그를 진행하였지만 패배를 했다. 오프사이드로 인해서 골 취소, 공 소유권 뺏기는 등으로 인하여 해당 결과가 발생했다. 그렇다면 2018년도와 2022년도 월드컵이 다
Vision-Language[multimodal]
Multimodal task들에 대해서 보다보면 인류 즉 인간이 어떠한 물체라는 것을 이해하기 위해서 시각 미각 촉각 문자까지 여러 개념을 통합해서 인식을 합니다. 그래서 처음 인식하고 나서는 그거에 대한 일부분만 봐도 이게 어떤 촉각이었고 미각은 어땠고 어떠한 설명이
CNN과 Transformer의 다른점
CNN은 input image의 공간정보를 유지한 채 학습을 합니다. 그리고 image 전체의 정보를 압축하기 위해 여러 개의 layer를 통과시킵니다. 그리고 transformer는 하나의 layer로 전체 Image 정보 압축합니다.⇒ 멀리 떨어져있는 정보를 통합하