자료구조와 알고리즘
1.자료구조와 알고리즘
자료구조: 메모리를 효율적으로 사용하며 빠르고 안정적으로 데이터를 처리하는 것이 궁극적인 목표로 상황에 따라 유용하게 사용될 수 있도록 특정 구조를 이루고 있다. 자료구조의 종류는 Stack, Queue, Graph, Tree 등 종류가 다양하다.알고리즘: 특정 문제를
2.자료구조의 종류
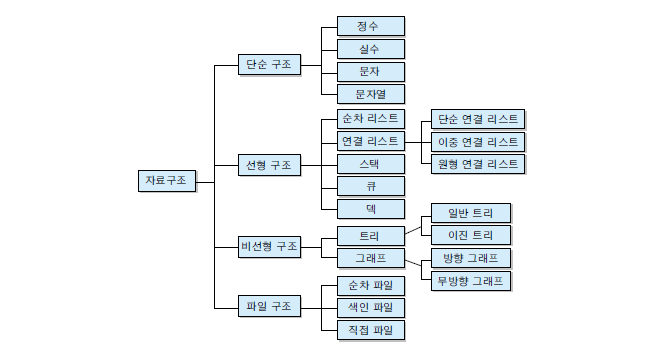
전산화의 예시를 들 수 있다.예를 들어, 현실에 존재하는 영화 예매를 어떻게 컴퓨터로 옮길 것인가?현실에서 수행되는 프로세스는?1\. 고객은 어떤 영화를 볼지 고른다.2\. 고객은 영화를 예매하기 위해 줄을 선다.3\. 고객은 차례가 왔을 때 좌석을 선택한다.4\. 고
3.시간 복잡도
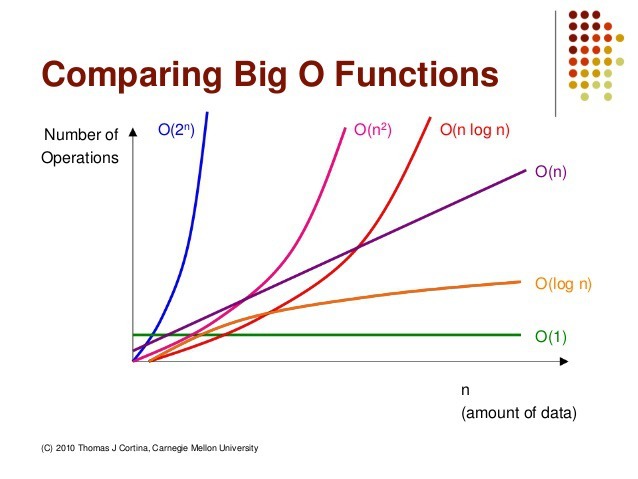
프로그램의 성능을 정확히 파악할려면 어떤 것을 고려해야 할까?1\. 입력으로 들어오는 데이터의 크기2\. 프로그램이 동작하는 하드웨어의 성능3\. 프로그램을 실행/관리하는 운영체제의 성능4\. 프로그램을 빌드하는 컴파일러의 성능5\. 비동기 로직이들을 활용해 프로그램의
4.배열(순차 리스트)
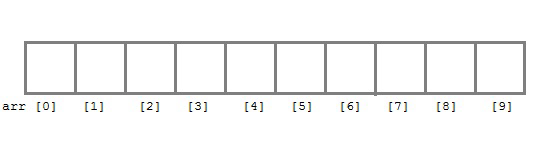
배열이란, 연관된 데이터를 연속적인 형태로 저장하는 복합 타입을 말한다. 일반적으로 변수를 선언하면 메모리상에 기록되는데, 우리는 이 메모리에 저장된 변수를 꺼내 쓸 수 있다. 이때 여러 개의 변수를 메모리에 기록하려면 배열이라는 자료구조를 사용하면 된다. 배열은 연관
5.연결 리스트란?
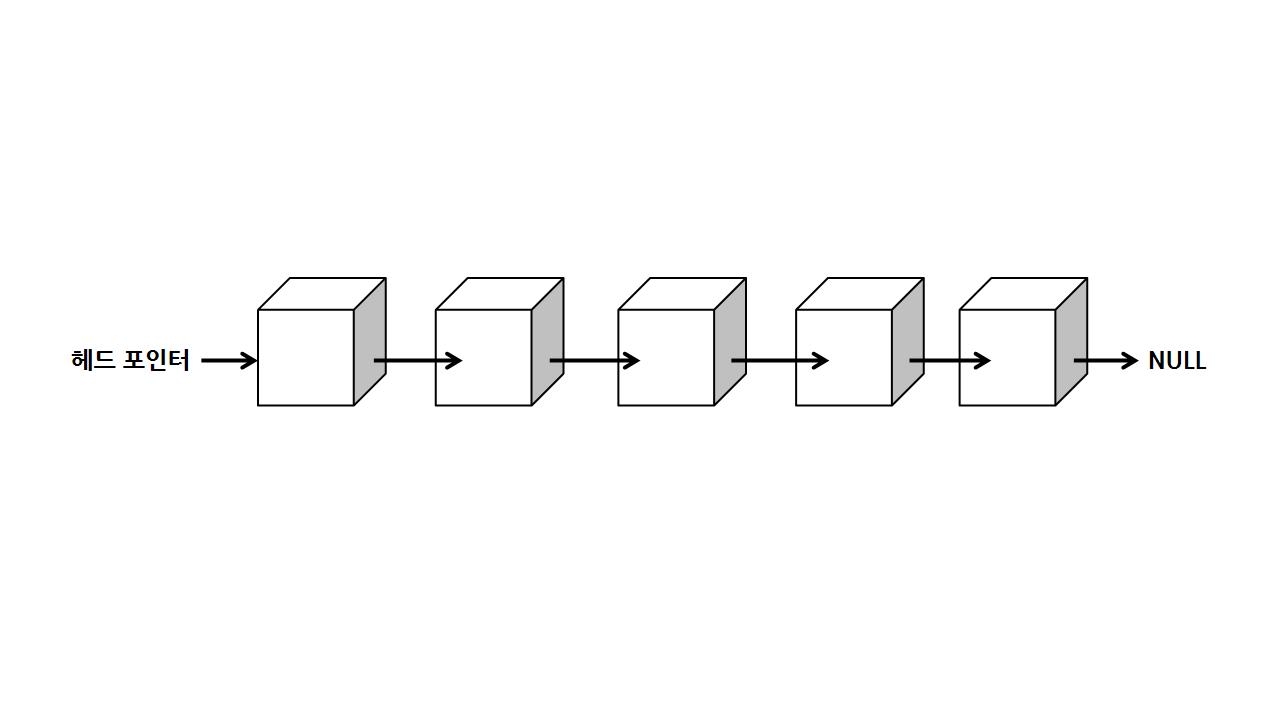
연결 리스트란, 연결 리스트는 각 요소를 포인터로 연결하여 관리하는 선형 자료구조다. 각 요소는 노드라고 부르며 데이터 영역과 포인터 영역으로 구성된다. 추가와 삭제가 반복되는 로직을 배열에 적용하면, 시간 복잡도가 상당히 커지게 된다.따라서, 추가와 삭제가 반복되는
6.연결 리스트의 종류
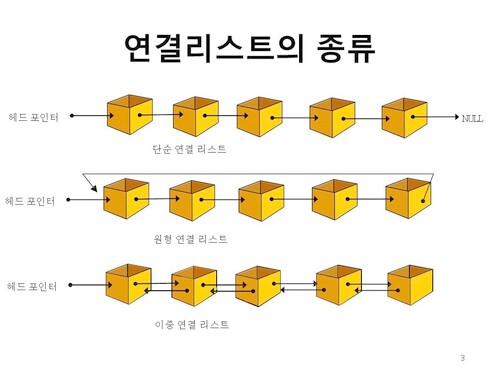
Head 에서 Tail 까지 단방향으로 이어지는 연결 리스트이며, 가장 단순한 형태인 연결 리스트이다. 여기서 Head 는 가장 첫번째 요소를 말하고 Tail 은 가장 마지막 요소를 말한다.요소 찾기에서 ‘4’를 찾는다고 하면 먼저 헤드 포인터에서 시작하여 각 요소의
7.스택(Stack)
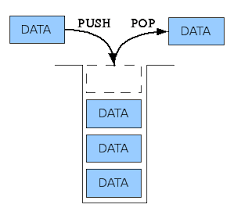
Last In First Out 이라는 개념을 가진 선형 자료구조이다.나중에 들어간 요소가 먼저 나오고, 먼저 들어간 요소가 나중에 나온다.흔히 상자에 물건을 넣으면 나중에 넣은 것이 위에 쌓이는 것과 같은 이치이다.여기서 상자에 물건을 넣는 것을 push, 물건을 빼
8.큐(Queue)
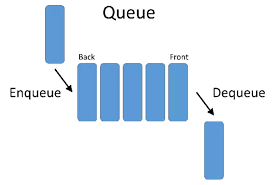
First In First Out 이라는 개념을 가진 선형 자료구조이다. 먼저 들어간 것이 먼저 나오는, 나중에 들어간 것이 나중에 나오는 개념이라고 보면 된다. 큐의 맨 앞을 front 라고 한다. 큐의 맨 뒤를 rear 라고 부르고 큐에 요소를 추가하는 것을 EnQ
9.해시 테이블
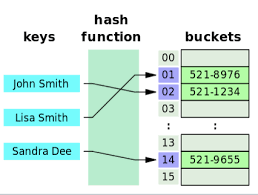
선형 자료 중에 하나인 해시 테이블은 키와 값을 받아 키를 해싱(Hashing)하여 나온 index 에 값을 저장하는 선형 자료구조로써, 삽입의 시간 복잡도는 상수시간 O(1) 소요되고 삭제, 탐색의 시간 복잡도는 키를 알고 있다면 상수 시간 O(1)이 소요된다. 고등
10.그래프(Graph)
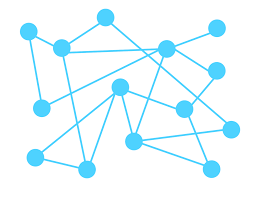
그래프는 정점과 정점 사이를 연결하는 간선으로 이루어진 비선형 자료구조이다. 정점 집합과 간선 집합으로 표현이 가능하다. 여기서 정점과 간선은 노드(Node) 와 엣지(Edge)라고 부른다.이런 그래프는 보통 인물 관계도에서 많이 볼 수 있다. 여기서는 정점이 인물이고
11.트리(Tree)
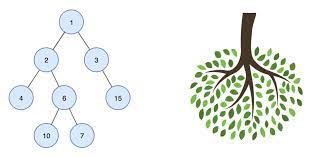
방향 그래프의 일종으로 정점을 가리키는 간선이 하나 밖에 없는 구조를 가지고 있다. 하나의 root 에서 하위로 뻗어나가는 구조를 가지고 있다. 용어 설명을 하자면 가장 상위에 존재하는 정점을 root 라고 부른다. 각 정점은 Node 라고 부르며 더 이상 자식이 없는
12.힙(Heap)
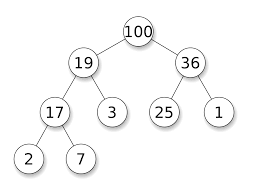
힙을 설명하기 전에 우선순위 큐에 대해서 알아보자.우선순위 큐는 FIFO 인 큐와 달리 우선 순위가 높은 요소가 먼저 나가는 큐를 말한다. 여기서 주의해야 하는 것은 우선순위 큐는 자료구조가 아닌 개념이다. 따라서 우선순위 큐를 구현하는 방법은 다양하게 존재할 수 있다
13.트라이(Trie)
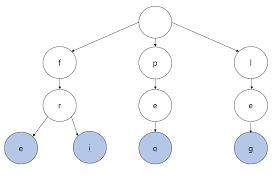
구글이나 네이버 같은 검색 서비스에서 자동 완성을 하려면 어떻게 해야 할까? 이런 경우에 사용하는 적합한 자료구조로 트라이가 있다. 트라이는 문자열을 저장하고 효율적으로 탐색하기 위한 트리 형태의 자료구조이다. 아래의 그림처럼 트리 구조로 되어 있어 간선은 이전 정점으
14.이진 탐색

정리가 안된 책장에서 원하는 책을 찾을려면 어떻게 하면 좋을까? 사람마다 다르겠지만 어느 방향이든 순차적으로 찾는 사람이 많을 것이다.이러한 탐색을 선형 탐색이라고 부른다. 순서대로 하나씩 찾는 탐색 알고리즘이기 때문에 O(n) 시간복잡도가 걸린다. 그리고 up and
15.정렬
만약에 우리가 구슬들을 크기별로 나열해야 한다면 어떻게 하면 될까? 제일 큰 것부터 찾을 수도 있고 일단 분류해서 정리하는 경우도 있을 것이다. 이러한 행동을 우리는 정렬이라고 부른다. 정렬은 앞서 살펴본 것처럼 요소들을 일정한 순서대로 열거하는 알고리즘이다. 정렬 알
16.BFS, DFS
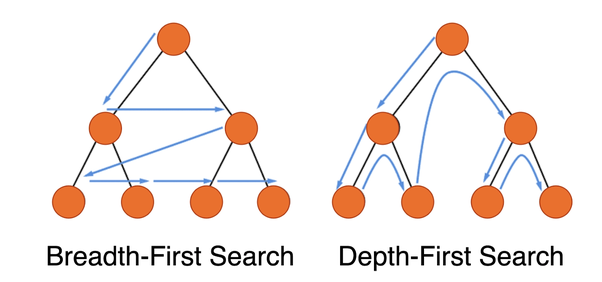
이 알고리즘은 각각 넓이 우선 탐색(Breadth-First-Search)과 깊이 우선 탐색(Depth-First-Search)이라고 부른다. 그림판의 페인트 툴은 어떻게 구현 될까? 그리고 만약 D에서 G로 가는 최단 거리는 어떻게 알 수 있을까? 넓이 우선 탐색과
17.그리디
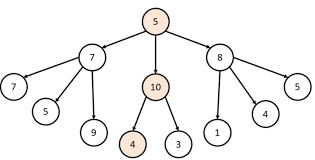
자판기는 남은 금액을 어떤 알고리즘을 반환할까? 그리고 마시멜로 실험에서 마시멜로가 하나 있고 30분을 참으면 마시멜로를 하나 더 준다고 가정할 때 아이들은 어떤 선택을 하는 것인가를 테스트 하는 실험이다.그리디 알고리즘은 매 선택에서 지금 이순간 최적인 답만을 선택