
- 전체보기(81)
- 읽을거리(33)
- 논문리뷰(26)
- 클러스터링(5)
- 머신러닝(5)
- 생성형AI(3)
- chatGPT(3)
- GPT(3)
- 메타버스(3)
- 파이썬(3)
- 텍스트마이닝(3)
- 추천시스템(2)
- 코드인터프리터(2)
- 텍스트 마이닝(2)
- 코드(2)
- 문제해결(2)
- 알고리즘(2)
- 코드리뷰(2)
- 혼합방법론(2)
- 데이터리터러시(1)
- 시각화(1)
- 투자 전략(1)
- 성공요인분석(1)
- 지속사용의도(1)
- 스포츠 경기분석(1)
- Gemini(1)
- 신뢰구축모델(1)
- 회고(1)
- 헬스케어(1)
- 노인복지(1)
- 디자인사이언스방법론(1)
- 엔지니어링(1)
- S-O-R 모델(1)
- 병원모바일앱(1)
- 고객관계(1)
- 온라인 리뷰(1)
- 정보시스템성공모형(1)
- 쿼리 튜닝(1)
- HCI(1)
- 리스트(1)
- TV 프로그램 품질평가(1)
- 브랜드개성(1)
- 가상경험(1)
- 리스트컴프리핸션(1)
- 티빙&웨이브(1)
- Karlo(1)
- 설득(1)
- dbscan(1)
- copliot(1)
- 코파일럿(1)
- 연산자(1)
- 경기력 평가(1)
- 딥러닝(1)
- 코호트 분석(1)
- kmeans(1)
- 지속이용의도(1)
- 인용네트워크분석(1)
- 일본 백화점(1)
- ESG투자(1)
- 벤치마크(1)
- ux(1)
- 노션 이력서(1)
- 세그먼트(1)
- K2-Eval(1)
- Custom Instruction(1)
- 확장프로그램(1)
- 핀다(1)
- 오픈소스기여(1)
- ToRA(1)
- 개인방송(1)
- DALL-E 3(1)
- GPT서비스(1)
- mygpts(1)
- 기대일치모형(1)
- 마이데이터(1)
- 모바일 OTT(1)
- folium(1)
- AI서비스(1)
- 모태펀드 문화계정(1)
- transformer(1)
- 데이터분석가(1)
- 시나리오 기반 실험연구(1)
- 경기상황 변화(1)
- 포커스미디어(1)
- 커뮤니케이션(1)
- 자살예방(1)
- 열람실(1)
- Stable Diffsuion(1)
- 디지털시장(1)
- 브이튜버(1)
- 코테(1)
- 이진분류(1)
- 콜드메일(1)
- 롯데온(1)
- 랭킹화면(1)
- 방향그래프(1)
- 패션 디자이너 브랜드(1)
- Attention(1)
- 랭체인튜토리얼(1)
- 개발블로그(1)
- 프롬프트 엔지니어링(1)
- SOR프레임워크(1)
- 서비스스케이프(1)
- 챗봇(1)
- 초현실 가상인플루언서(1)
- 함수(1)
- 비즈니스(1)
- 직무 만족도(1)
- 생산성(1)
- 프라이버시 계산모형(1)
- 소비자특성(1)
- 백화점 위기 극복 전략(1)
- 계층별 군집(1)
- 이주이론(1)
- 가상세계(1)
- 기획(1)
- 자사주(1)
- 추천서비스(1)
- 현대(1)
- 편집샵(1)
- 여가제약모델(1)
- 데이콘(1)
- Gen AI(1)
- 패스네트워크(1)
- 데이터로 말해요(1)
- 자율성(1)
- UTAUT2(1)
- gs리테일(1)
- 건강추천시스템(1)
- ppm(1)
- 여기어때(1)
- 이미지생성(1)
- 비디오 클립(1)
- 클래스(1)
- reverse(1)
- 저니맵(1)
- 프롬프트엔지니어링(1)
- 논문읽기(1)
- 기술블로그(1)
- 패션브랜드(1)
- 스펙트럴(1)
- 계량분석(1)
- 가변인자(1)
- 상속(1)
- 이륜차 사고(1)
- 혐오발언탐지(1)
- 사회연결망분석(1)
- 서비스 평가 지표(1)
- 뇌파(1)
- COCoaH(1)
- CNN(1)
- 행동의도(1)
- 품질요인(1)
- 프롬프트(1)
- 어플리케이션(1)
- 평가지수(1)
- 언택트 서비스(1)
- joint Sentiment 토필모델링(1)
- 직원 경험(1)
- 데이터 분석(1)
- 고객가치(1)
- 브랜드선호(1)
- 오류역전파(1)
- 데이터 시각화(1)
- 애플리케이션 개발(1)
- Claude(1)
- 프로덕트(1)

병원모바일앱 품질요인이 이용자의 지속이용의도에 미치는 영향: 정보시스템성공모형과 기대일치모형의 통합적 접근
논문 제목: 병원모바일앱 품질요인이 이용자의 지속이용의도에 미치는 영향: 정보시스템성공모형과 기대일치모형의 통합적 접근저자 정보:1저자: 김민수공동저자: 윤상혁, 이새봄교신저자: 양성병게재지: 서비스연구 (Journal of Service Research and Stu

An Odyssey into Virtual Worlds: Exploring the Impacts of Technological and Spatial Environments on Intention to Purchase Virtual Products
논문 제목: An Odyssey into Virtual Worlds: Exploring the Impacts of Technological and Spatial Environments on Intention to Purchase Virtual Products
K2-Eval로 한국어 LLM 벤치마크하기
최근 한국어에 특화된 LLM들이 속속 등장하면서, 이들을 평가할 수 있는 표준 벤치마크의 필요성이 커지고 있습니다. 이번 포스트에서는 한국어 벤치마크 데이터셋인 K2-Eval을 활용하여 다음 세 모델의 성능을 비교해보았습니다:yanolja/EEVE-Korean-Inst

사회연결망분석을 활용한 한국 남자축구대표팀 경기성과 분석: 벤투 감독 경기를 중심으로
영문 제목:Analyzing the Performance of the South Korean Men’s National Football Team Using Social Network Analysis: Focusing on the Manager Bento’s Matche

프로젝트 회고: 랭체인 튜토리얼 참여 후기
전에 했던 AI 휴먼 프로젝트에서 langchain을 사용하여 프로젝트를 잘 끝낼 수 있었어서 해당 오픈소스 프로젝트에 관심가지게 되어 참여하게 되었습니다. 2달간 랭체인 오픈 튜토리얼 프로젝트에 기존 개발과 신규 개발팀 동시에 참여하여, 기존에 Teddy 님이 제작하
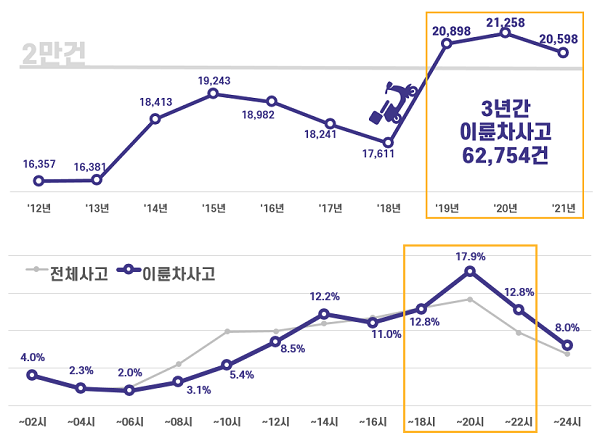
클러스터링 기법을 이용한 이륜차 사고의 특징 분류
논문 제목: 클러스터링 기법을 이용한 이륜차 사고의 특징 분류저자 정보:제1저자: 허원진공동저자: 강진호교신저자: 이소현게재 정보:게재지: 지식경영연구발행년도: 2024년DOI: 10.15813/kmr.2024.25.1.011연구 분야: 도시교통 및 안전, 데이터 애널
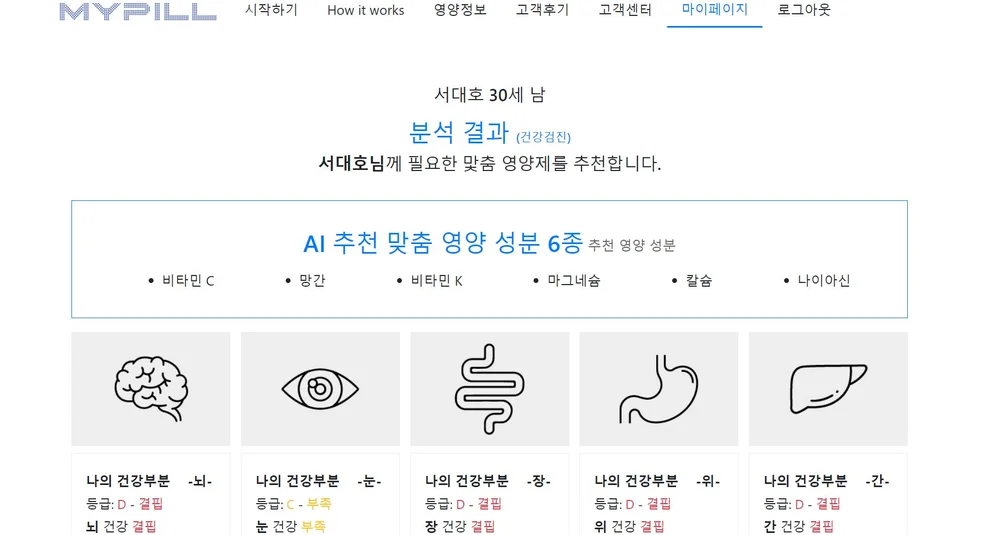
건강추천시스템(HRS) 연구 동향 인용네트워크 분석과 GraphSAGE를 활용하여
저자 정보:1저자: 장하렴공동저자: 유지수교신저자: 양성병게재 정보:게재지: Journal of Intelligent Information Systems발행년도: 2023년 6월DOI: 10.13088/jiis.2023.29.2.057연구 분야: 빅데이터, 건강관리 추

CoCoaH: 문맥과의 관계를 고려한 혐오 발언 탐지
1저자: 김나연공동저자: 김지안, 정우환교신저자: 정우환개제처: 2024 한국컴퓨터종합학술대회 논문집발행년도: 2024키워드: 혐오 발언 탐지, 문맥 정보, 인공지능, CoCoaH 모델, 텍스트 분석CoCoaH 모델의 성능이 데이터셋 별로 차이가 나는 이유는 무엇인가요
콘텐츠 산업 투자 필요분야 도출을 통한 모태펀드 문화계정 개선 방안 연구
논문 제목: 콘텐츠 산업 투자 필요분야 도출을 통한 모태펀드 문화계정 개선 방안 연구저자 정보:1저자: 양지훈공동저자: 홍무궁교신저자: 윤상혁게재 정보:게재지: 한국문화관광연구원 학술지발행년도: 2023DOI: 10.16937/jcp.2023.37.3.5연구 분야: 콘

What content and context factors lead to selection of a video clip? The heuristic route perspective
논문 제목: What content and context factors lead to selection of a video clip? The heuristic route perspective저자 정보:1저자: Sang-Hyeak Yoon공동저자: Hee-Woong Ki

텍스트 마이닝 통합 애플리케이션 개발: KoALA
논문 제목: 텍스트 마이닝 통합 애플리케이션 개발: KoALA저자 정보:1저자: 전병진공동저자: 최윤진교신저자: 김희웅게재 정보:게재지: 경영정보학연구발행년도: 2019DOI: http://dx.doi.org/10.14329/isr.2019.21.2.117연구

군인의 모바일 OTT 서비스 지속사용의도에 영향을 미치는 요인: 군복무형태의 조절효과를 중심으로
논문 제목:군인의 모바일 OTT 서비스 지속사용의도에 영향을 미치는 요인: 군복무형태의 조절효과를 중심으로저자 정보:1저자: 김정헌 (경희대학교 일반대학원 빅데이터응용학과 석사)공동저자: 권지윤, 양성병교신저자: 윤상혁 (한국기술교육대학교 산업경영학부 조교수)게재 정보

초현실 가상인플루언서에 대한 신뢰와 애착이 행동의도에 미치는 영향: 신뢰구축모델을 기반으로
논문 제목: 초현실 가상인플루언서에 대한 신뢰와 애착이 행동의도에 미치는 영향: 신뢰구축모델을 기반으로저자 정보:1저자: 학가위공동저자: 양성병교신저자: 윤상혁게재 정보:게재지: 정보시스템연구발행년도: 2022년 12월DOI: 10.5859/KAIS.2022.31.4.
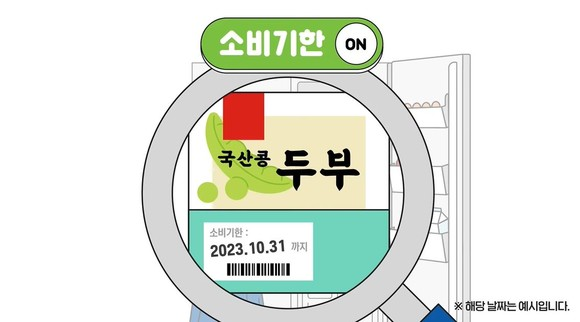
식품유형별 식품 유통기한 및 소비기한 표기방법에 대한 소비자 반응 분석: 시나리오 기반 실험연구
논문 제목:식품유형별 식품 유통기한 및 소비기한 표기방법에 대한 소비자 반응 분석: 시나리오 기반 실험연구저자 정보:1저자: 이소희 (경희대학교 경영대학원 경영학과)공동저자: 김나경 (경희대학교 일반대학원 빅데이터응용학과), 양성병 (경희대학교 경영대학 및 빅데이터응용
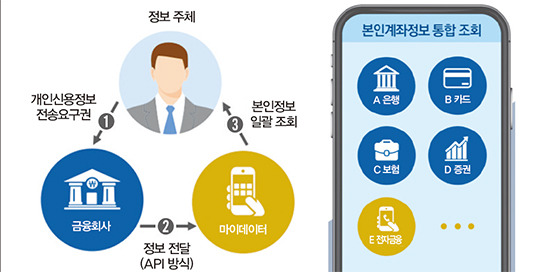
개인의 마이데이터 제공의도에 영향을 미치는 요인: 개인역량과 기관유형의 조절효과를 중심으로
논문 제목: 개인의 마이데이터 제공의도에 영향을 미치는 요인: 개인역량과 기관유형의 조절효과를 중심으로저자 정보:1저자: 박동근공동저자: 양성병교신저자: 윤상혁게재 정보:게재지: 지식경영연구발행년도: 2023DOI: 10.15813/kmr.2023.24.1.004연구

헬스케어 서비스의 디지털 채널 전환에 영향을 미치는 요인: ICT 기반 원격진료(Telemedicine)를 중심으로
논문 제목: 헬스케어 서비스의 디지털 채널 전환에 영향을 미치는 요인: ICT 기반 원격진료(Telemedicine)를 중심으로저자 정보:1저자: 정옥경 (호서대학교 산업인공지능공학과 교수)공동저자: 박승범 (호서대학교), 윤상혁 (한국기술교육대), 박철 (고려대학교)
아날로그 방식이 적용된 모바일앱에서의 어포던스가 애착, 만족도 및 지속이용의도에 미치는 영향
논문 제목: 아날로그 방식이 적용된 모바일앱에서의 어포던스가 애착, 만족도 및 지속이용의도에 미치는 영향저자 정보:1저자: 오승묵 (경희대학교 경영대학원 경영학과 석사)공동저자: 양성병 (경희대학교 경영대학/빅데이터응용학과 교수)교신저자: 윤상혁 (한국기술교육대학교 산

스키리조트의 서비스스케이프에서 주요 고객가치 요인에 대한 연구
논문 제목:스키리조트의 서비스스케이프에서 주요 고객가치 요인에 대한 연구저자 정보:1저자: 김선규 (경기대학교 산업경영정보공학과)공동저자: 박지현 (경기대학교 산업경영정보공학과), 윤상혁 (한국기술교육대학교 산업경영학부)교신저자: 이소현 (경기대학교 산업경영정보공학과)
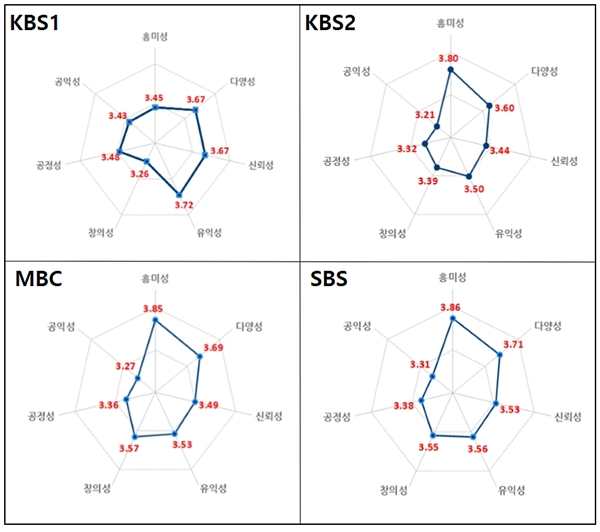
SNS 온라인 리뷰를 활용한 TV프로그램 품질평가 연구
논문 제목: SNS 온라인 리뷰를 활용한 TV 프로그램 품질평가 연구저자 정보:1저자: 윤상혁 (KAIST 경영대학 정보경영 석사, SBS콘텐츠허브/스마트미디어렙 과장)공동저자: 손지현, 고민삼, 김영걸교신저자: 손지현게재지: 방송통신연구 2015년 봄호 (통권 제90

브이튜버(Vtuber) 개인방송의 기술적 특성과 가상 크리에이터 특성이 즐거움, 시청만족도 및 유료후원의도에 미치는 영향: S-O-R 모델을 기반으로
논문 제목: 브이튜버(Vtuber) 개인방송의 기술적 특성과 가상 크리에이터 특성이 즐거움, 시청만족도 및 유료후원의도에 미치는 영향: S-O-R 모델을 기반으로저자 정보:1저자: 김성군 (경희대학교 일반대학원 경영학과)공동저자: 양성병 (경희대학교 경영학과/빅데이터응