생성형 인공지능 (Generative AI)
1.[일단 박죠] NVDIA의 GET3D를 활용한 아바타 자동 생성 #1
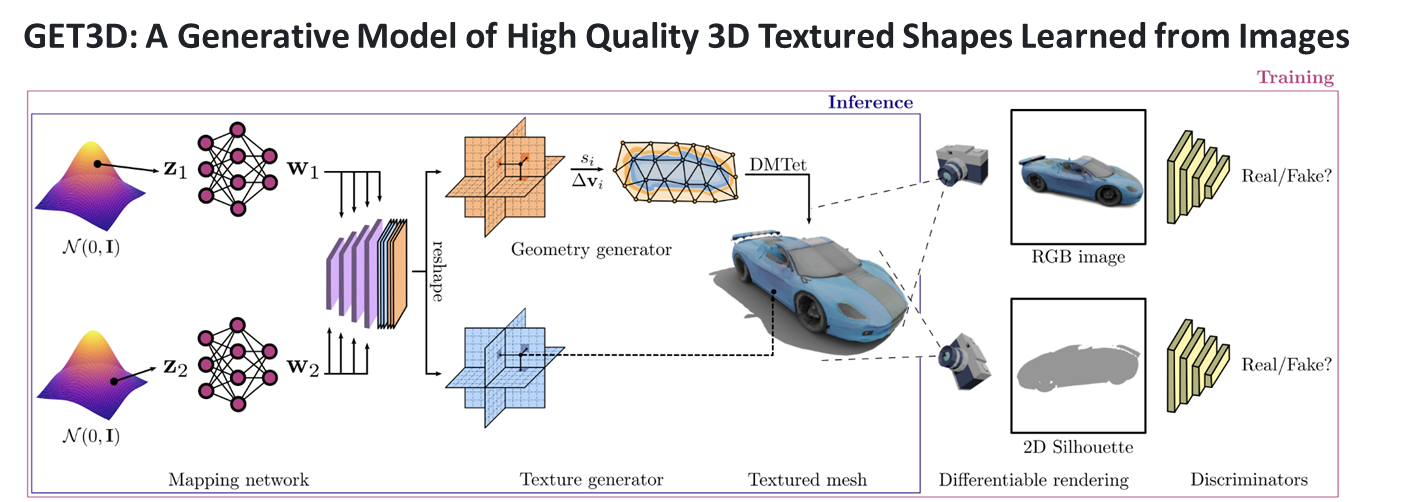
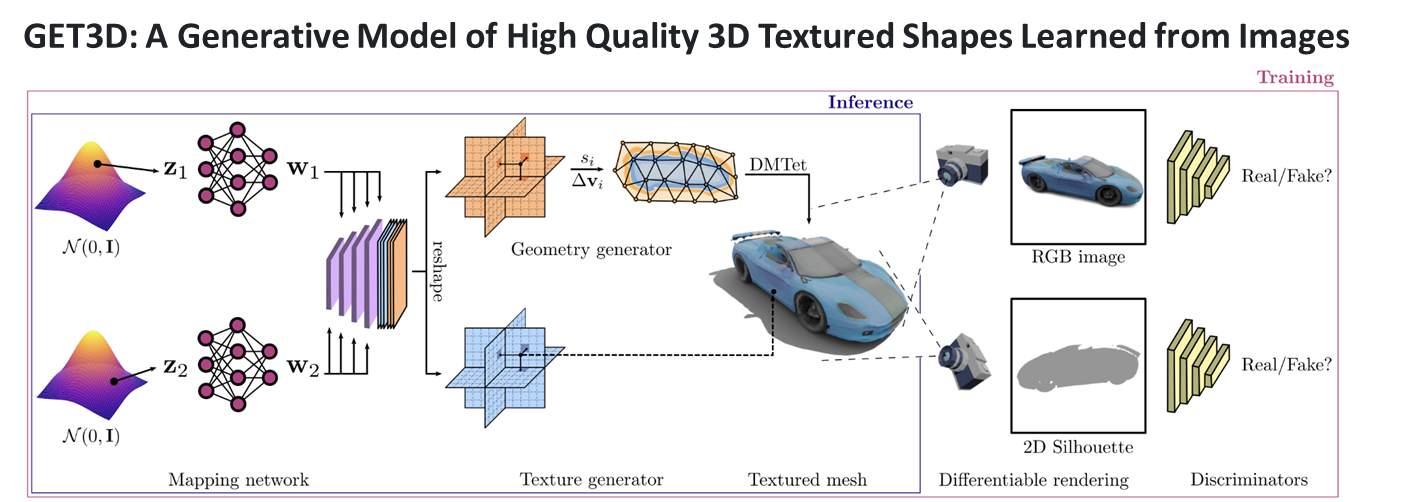
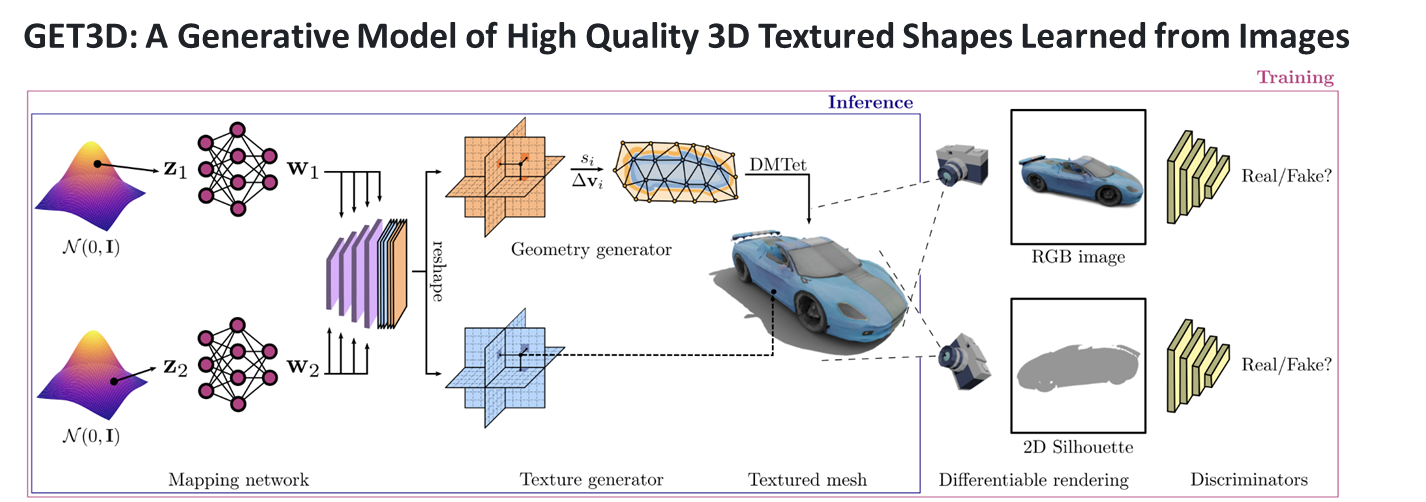
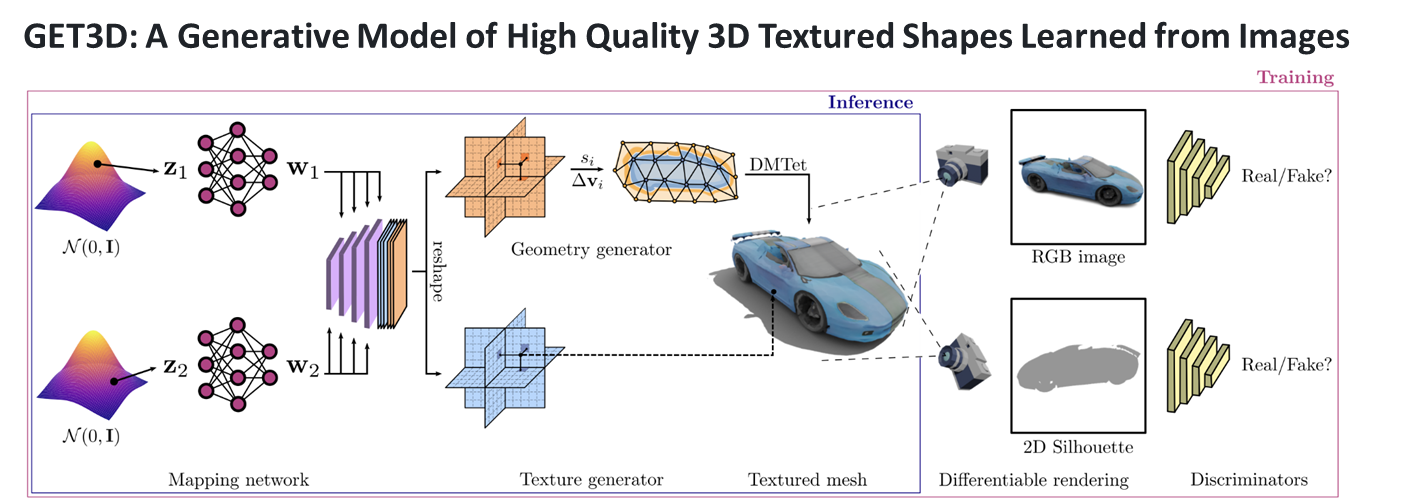
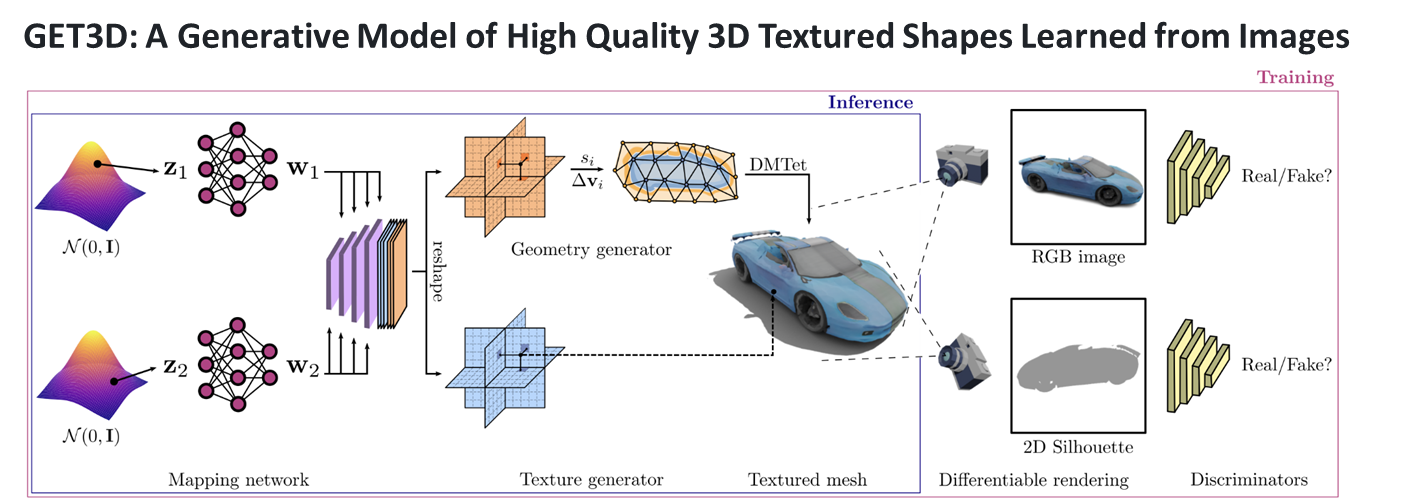
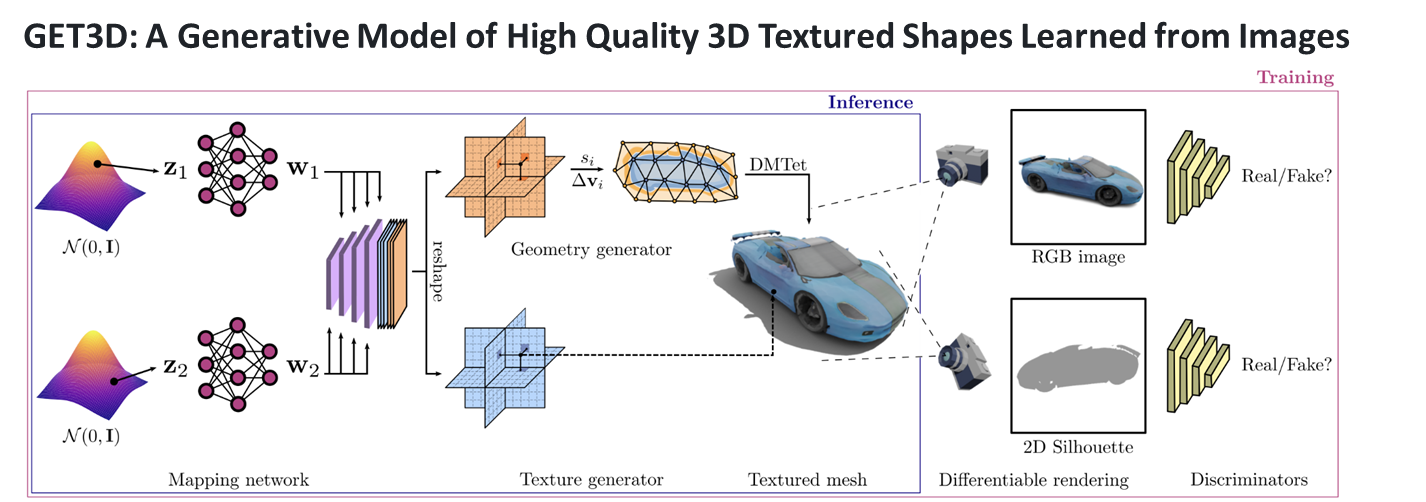
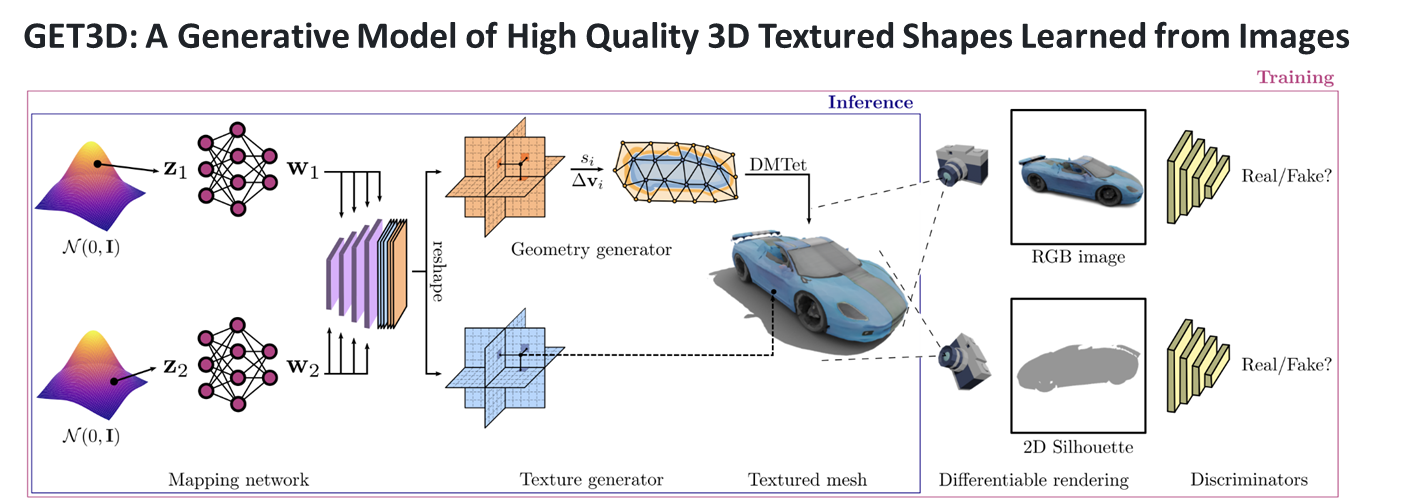
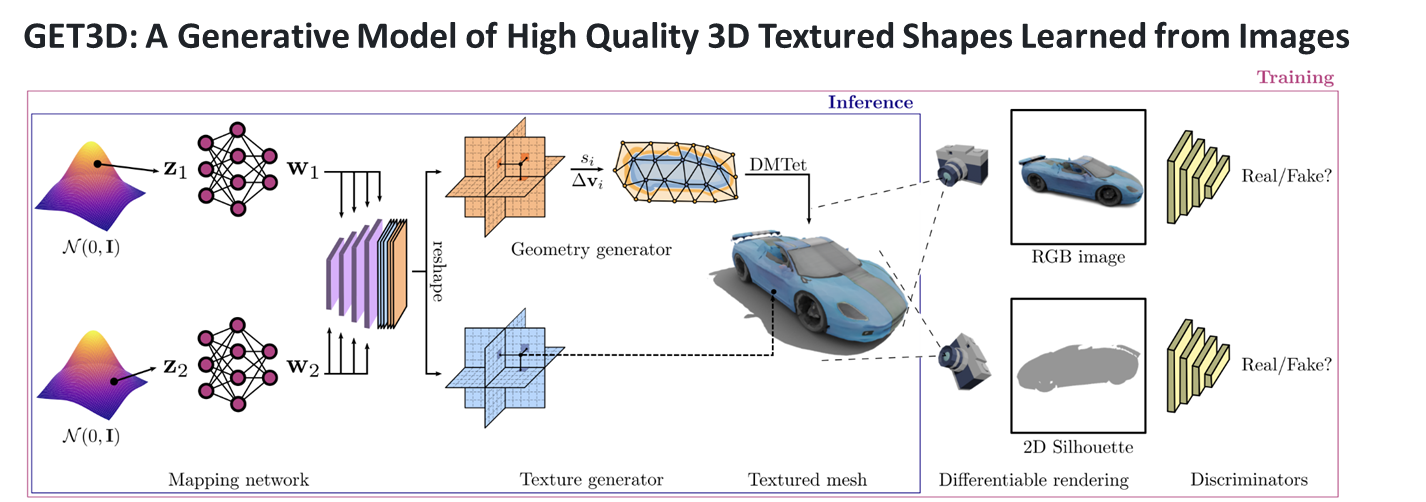
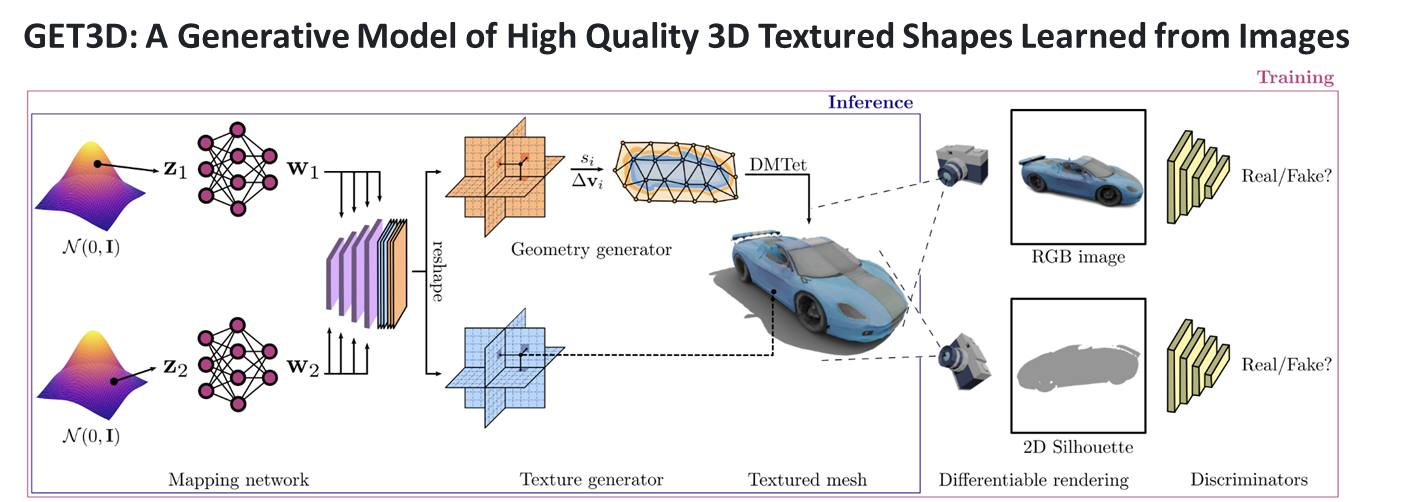
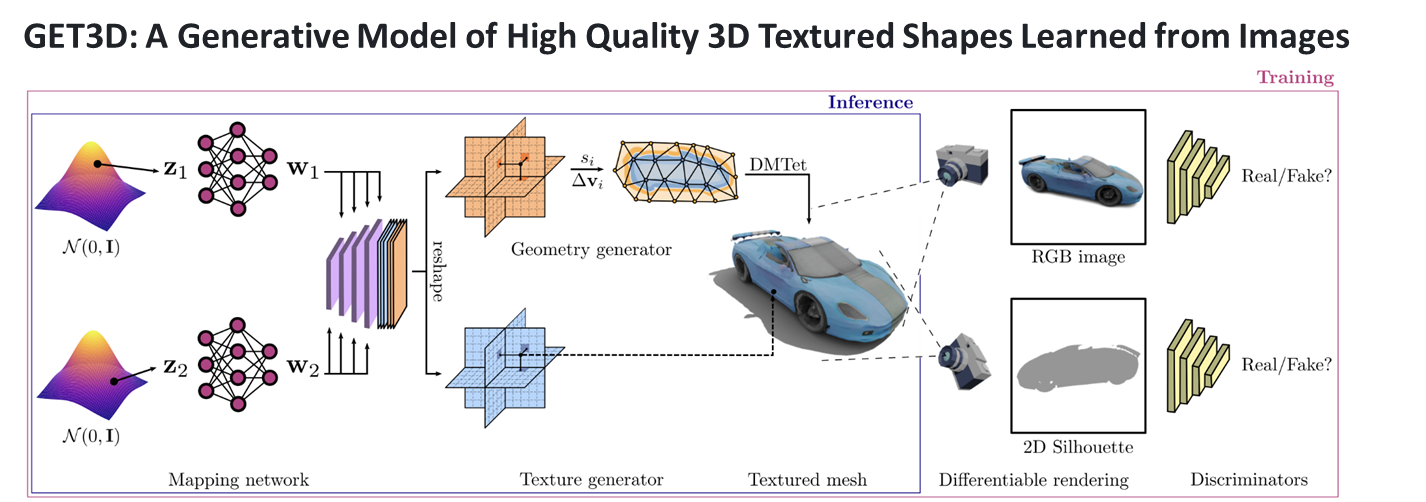
이번 과제에서 내가 맡은 역할은 생성 AI 기반 면접 아바타 자동생성 부분이다. 해당 역할을 수행하기 위해서 NVIDIA의 GET3D를 활용해보기로 하였다.GET3D는 NVIDIA에서 개발한 실시간 3D 생성 및 조작 기술이다. 이 기술을 사용하면 2D 이미지나 비디오
2.[일단 박죠] NVDIA의 GET3D를 활용한 아바타 자동 생성 #2
앞에 게시글에서 언급했던 것과 같이 깃허브에서 제공하는 코드는 ShapeNetCore에 대한 코드들만 제공해준다... 그래서 아바타를 자동으로 생성하기 위해서는 열심히 굴러야한다.. 열심히 굴러보자!아래 링크는 GET3D의 논문의 링크이다.https://nv-
3.[일단 박죠] NVDIA의 GET3D를 활용한 아바타 자동 생성 #3
여러가지 사이트를 둘러보던 중 Mixamo라는 사이트를 알게 되었다.https://www.mixamo.com/위에 사진과 같이 쓸만한 아바타들을 구할 수 있었다. 해당 데이터만으로는 부족하다는 것을 알고있으나, 마땅한 데이터가 보이지않아 일단 다른 문제부터 해
4.[일단 박죠] Stable-DreamFusion를 활용한 아바타 자동 생성 #1

Stable-DreamFusion은 보는 것과 같이 텍스트 기반의 3D 모델링을 지원해준다. 해당 기능을 사용해서 면접 아바타를 자동 생성해볼 것이다. 아래는 Stable-DreamFusion의 깃허브 주소이다. https://github.com/ashawk
5.[일단 박죠] Stable-DreamFusion를 활용한 아바타 자동 생성 #2

앞에 게시글에서 이야기했던대로 text만으로는 성능이 부족하기 때문에 이미지를 이용해서 3D로 만들어 볼 것이다. 깃허브에 나와있는대로 해당 명령어를 이용해서 이미지를 전처리 해준다.사용한 이미지는 앞에서 GET3D할때 사용했던 이미지를 재활용 하였다. ㅎㅎ 참고로 전
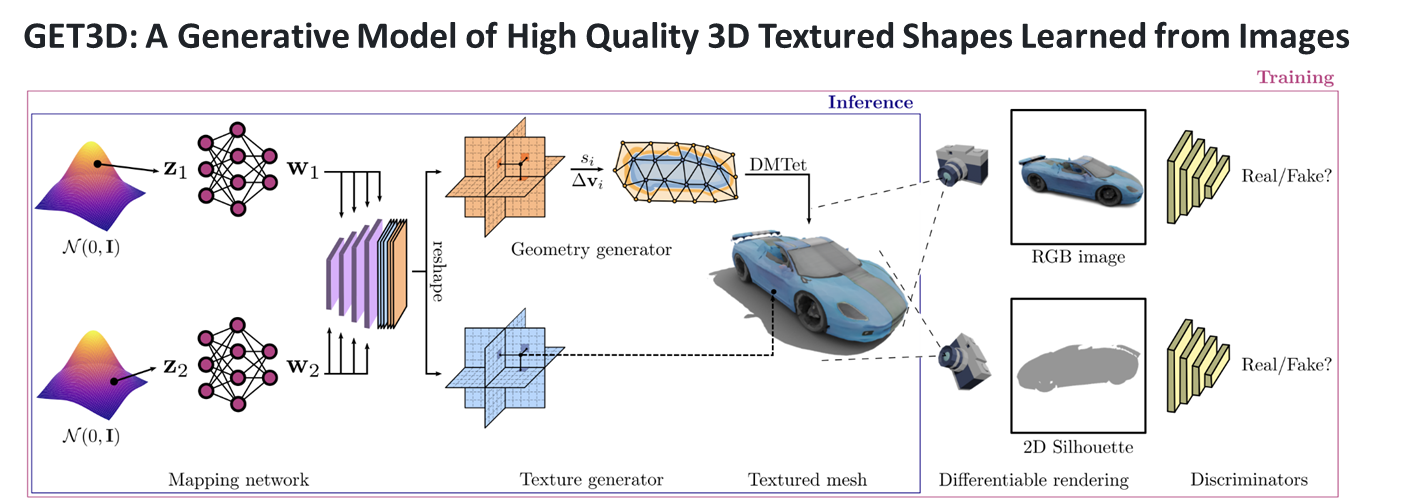
6.[일단 박죠] NVDIA의 GET3D를 활용한 아바타 자동 생성 #4
사실 GET3D는 정말 다시 하기 싫었다... ㅎㅎ 하지만 교수님이 한번 더 시도해보라고 하셔서.. 다시 해보기로하였다! ㅎㅇㅌ지금까지 진행상황은 OBJ파일 기반의 코드를 FBX로 수정하여 렌더링 하는 것 까지 성공하였다! 그래서 해당 렌더링 된 사진을 이용해서 모델을
7.[일단 박죠] NVDIA의 GET3D를 활용한 아바타 자동 생성 #5
먼저 사용법을 정확히 익히기 위해서 shapenet_car를 이용해서 학습하고, 추출해보도록 하겠다.car 사진의 렌더링 된 테이터는 일단 박죠 NVDIA의 GET3D를 활용한 아바타 자동 생성 사진과 같이 자동차 이미지에 대한 24장의 렌더링 된 이미지가 있다. 해당
8.[일단 박죠] NVDIA의 GET3D를 활용한 아바타 자동 생성 #6
지난번에 shapenet_car 데이터를 이용하여 학습 해보았으니, 이번에는 RenderPeople 데이터를 이용해서 학습 해보겠다. 학습시키는데 사용한 데이터는 이전에 일단 박죠 NVDIA의 GET3D를 활용한 아바타 자동 생성 사진에서 보는 것과 같이 10장 밖에
9.[일단 박죠] NVDIA의 GET3D를 활용한 아바타 자동 생성 #7
여러사이트를 돌아다니며 사람이 T자로 서있는 데이터를 찾으려고 노력해보았다. 그 결과 24개의 데이터를 더 구할 수 있었다.하지만 해당 데이터는 아래와 같이 mtl 파일이 아닌 jpg 파일에 색상정보를 저장하고 있었다.그래서 obj + mtl 파일을 렌더링 하는 코드로
10.[일단 박죠] NVDIA의 GET3D를 활용한 아바타 자동 생성 #8
아래 명령어를 이용하여 렌더링 된 사진을 이용해서 학습시켰다.아래 사진에서 볼 수 있듯이 사용된 모델은 34개이며, 사용된 이미지는 34 \* 24 인 816장이다. 그리고 1000 kimg 로 설정하여 실행하였다.아래 사진과 같이 3일 14시간 끝에 실행이 종료됐다.
11.[일단 박죠] NVDIA의 GET3D를 활용한 아바타 자동 생성 #9
업로드중..이전 게시글에서 추출해서 데이터를 뽑아보았는데 너무 안좋은 퀄리티이다. 그래서 더 좋은 퀄리티의 아바타를 뽑아보기 위해서.. 발버둥을 쳐보자!아래는 이상한 점이 보인다. 바로 위에서 내려다보는 렌더링 된 사진이 없다는 점이다. 카메라 위치 변수를 수정해서 해
12.[일단 박죠] NVDIA의 GET3D를 활용한 아바타 자동 생성 #10
아래는 이전 게시글에서 다뤘던 추출 결과이다. 해당 결과를 보면 정작 사용할 면접관의 아바타는 몇장 보이지 않는 모습을 보여준다.그래서 데이터셋을 면접관과 닮은 아바타 만을 주고 결과를 볼 것이다. 아래는 여러장의 데이터 셋중 면접관의 복장을 입은 아바타 4장이다.해당
13.[일단 박죠] PanoHead를 활용한 아바타 자동 생성 #1

지금까지는 전신의 아바타를 생성하는데 집중하였는데, 그렇게 만족스러운 결과를 뽑지 못하였다.그래서 전략을 바꾸어서 얼굴만 생성하는데 집중해볼 것이다. 얼굴만 생성해주는 모델을 찾아보았는데 PanoHead를 발견하였다.PanoHead 깃허브 주소사진에서 볼 수 있듯이 단
14.[일단 박죠] EVA3D를 활용한 아바타 자동 생성

EVA3D: Compositional 3D Human Generation from 2D Image CollectionsEVA3D는 2D 이미지 컬렉션에서 고품질 3D 사람 생성 모델이다. ICLR 2023에서 Spotlight도 받았다고 하니, 한번 사용해서 아바타를
15.[일단 박죠] PIFU를 활용한 아바타 자동 생성
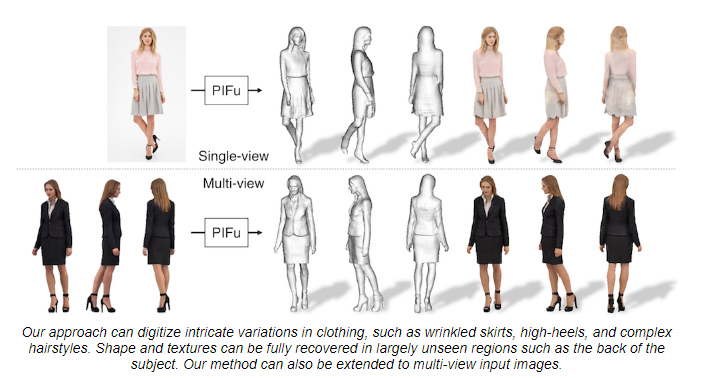
PIFU에 대한 시도는 이미 다른 랩원이 해보았기 떄문에, 공부한 내용만 정리하고 마무리하겠다.사진에서 보는 것과 같이 input 이미지를 이용해서 3D 모델을 생성해준다.훈련 단계에서는 다양한 예제 데이터를 통해 PIFu와 Tex-PIFu 모델을 학습시킨다. PIFu
16.[일단 박죠] AvatarCLIP 활용한 아바타 자동 생성

AvatarCLIP은 전문 지식 없이도 단순한 텍스트 설명만으로 원하는 3D 아바타를 생성하고 애니메이션화할 수 있다고 설명해준다.AvatarCLIP을 이용해서 아바타 생성에 도전해보겠다! AvatarCLIP 깃허브 주소AvatarCLIP 깃허브 주소에 보면 친절하게
17.[일단 박죠] PanoHead를 활용한 아바타 자동 생성 #2

write_frames() 함수에 'audio_path'라는 예상치 못한 키워드 인자가 전달되었습니다. 해당 함수의 정의를 확인하고, 필요하지 않은 인자를 제거하거나 올바른 인자를 전달해야 합니다./anaconda3/envs/panohead/lib/python3.9/s
18.[일단 박죠] PanoHead를 활용한 아바타 자동 생성 #3

PanoHead에서 제공해주는 기본적인 데이터를 이용하여, 3D 모델을 생성해보았다. 그래서 이제 내가 원하는 사진을 타겟 이미지로 제공하여 3D 모델을 생성해보려고한다.
19.[일단 박죠] Stable-DreamFusion를 활용한 아바타 자동 생성 #3

이전글에서는 어려운 텍스트를 주어서 정말 좋지 않은 결과를 뽑았었다. 이번에는 비교적 쉬운 텍스트를 주어 결과를 보도록 하겠다. 아래는 학습한 명령어이다.아래는 결과이다.간단한 텍스트를 이용해서 뽑으니, 훨씬 좋은 결과를 보여준다. 하지만 아직 많이 부족한 모습이다.
20.[일단 박죠] NVDIA의 GET3D를 활용한 아바타 자동 생성 #11
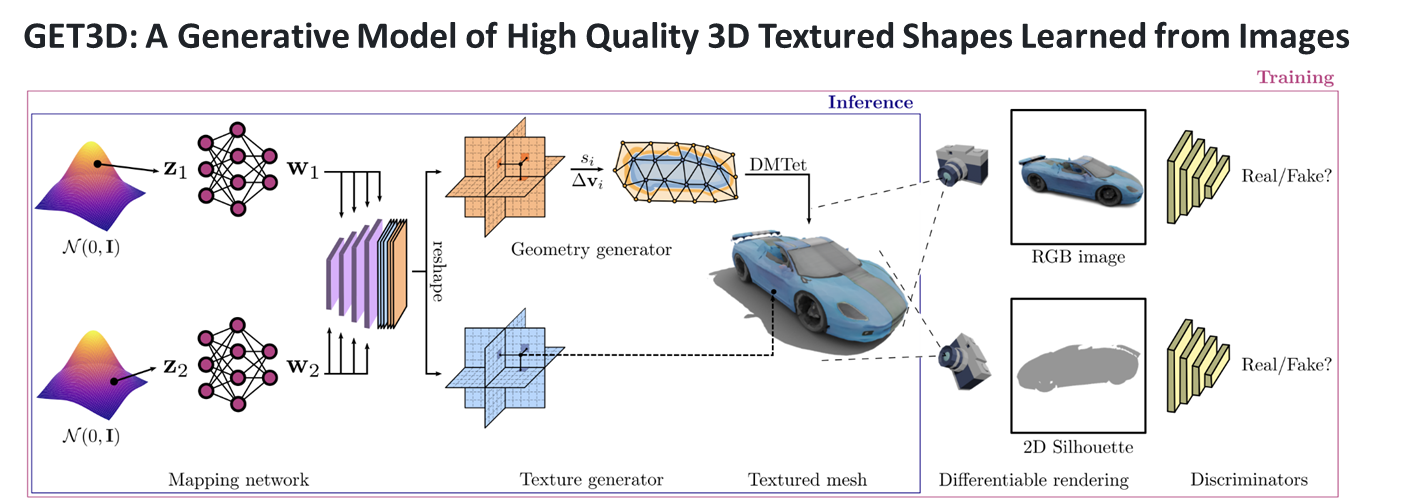
지난번에 글에서 비교적 괜찮은 결과를 뽑았지만 아직 많이 부족한 상태이다. 데이터가 많이 부족하기 때문에 좋은 결과를 기대하기 어렵다. 그래서 더 많은 데이터를 구해서 활용해보기로 하였다. 인터넷을 돌아다니다가 데이터를 구할 수 있었다. 하지만 보는 것과 같이 배경에
21.[일단 박죠] 2K2K를 활용한 아바타 자동 생성
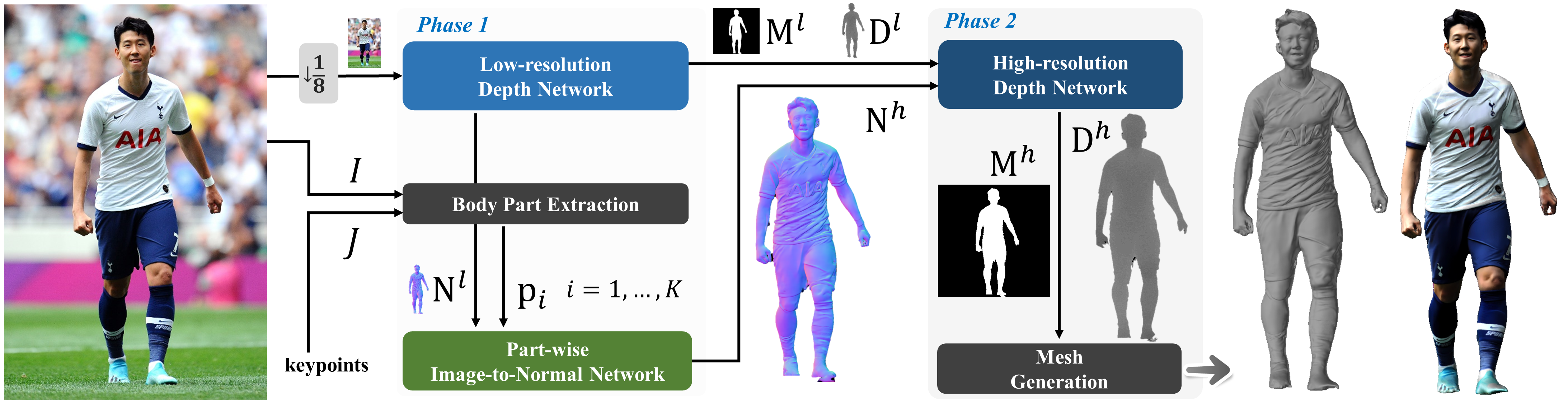
사진에서 볼 수 있듯이 2K 해상도 이미지로부터 3D 휴먼을 뽑아주는 모델이다. 프로젝트 페이지 를 가보면 굉장히 좋은 결과를 뽑아내는 모습을 볼 수 있다. 해당 모델을 사용해보려고 논문도 읽어보고 방법들을 공부해보았으나, 아마 사용해보지 못할 것 같다. 사진에서 보
22.[일단 박죠] NVDIA의 GET3D를 활용한 아바타 자동 생성 #12
저번 글에서 문제는 시간이 너무 오래걸린다는 것이었다. 나는 단순히 데이터 양이 늘어나서라고 생각했기 때문에 해결할 수 없다고 생각하고 있었다. 하지만 다시 한번 생각해보니 데이터양은 어차피 kimg 값에 따라서 정해지기 떄문에 결국 kimg값이 변하지 않았기 때문에
23.[일단 박죠] ESRGAN 모델을 이용한 이미지 해상도 향상

0. why? 이전 글에서 굉장히 절망적인 학습 결과를 보여주었다. 해당 문제를 해결하기 위해서 선택한 방법이 바로 이미지 해상도 향상이다. 그래서 이미지 해상도 향상을 위한 모델을 알아보던중 이미지 해상도 향상 모델중 유명한 ESRGAN모델을 이용해보기로 하였다.
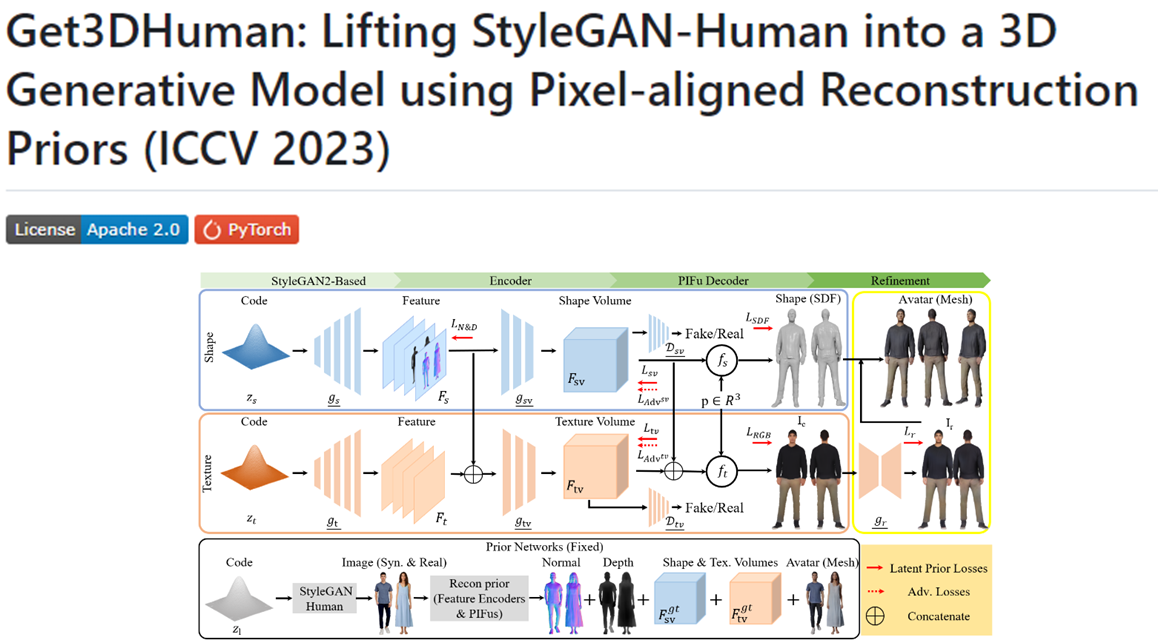
24.[일단 박죠] Get3DHuman을 활용한 아바타 자동 생성 #1
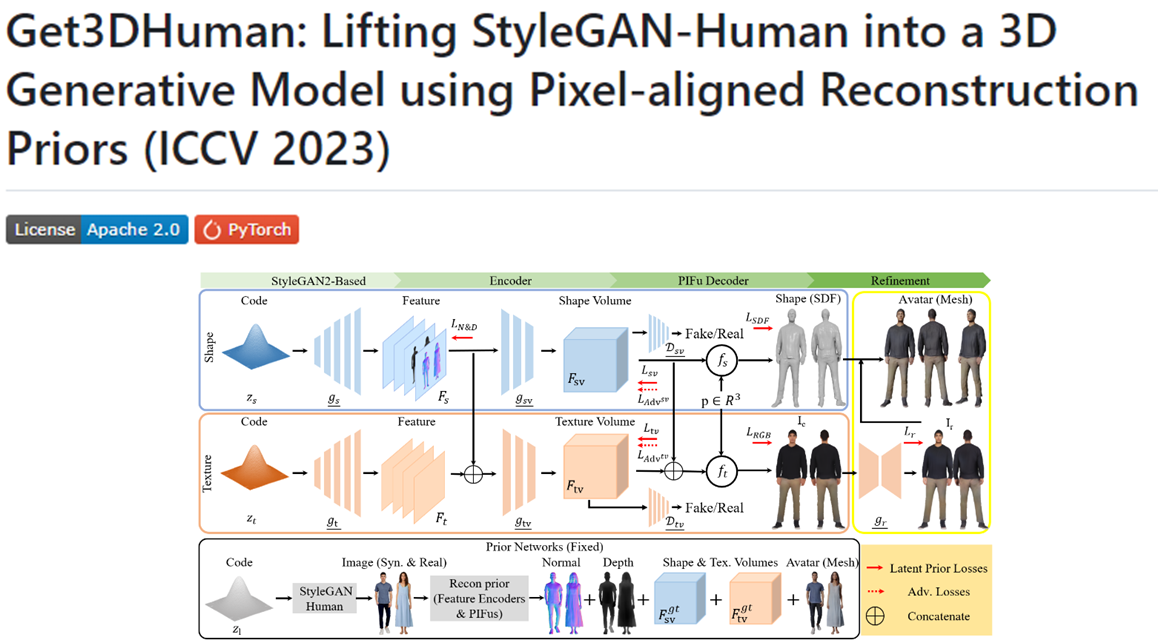
GET3D Human은 3차원 인간 형태 모델링 및 렌더링을 위한 고급 프레임워크다. 이 프로젝트의 목표는 사실적이고 정교한 3D 인간 모델을 생성하고 시각화하는 것이다. GET3D Human은 딥 러닝과 컴퓨터 비전 기술을 활용하여 다양한 포즈, 모양 및 질감을 가진
25.[일단 박죠] Get3DHuman을 활용한 아바타 자동 생성 #2
다양한 결과: 생성된 3D 휴먼 모델들은 전반적으로 인상적인 결과를 보여준다. 대부분의 경우 사실적이고 정교한 인간 형상을 잘 구현했지만, 가끔은 인간의 형상을 잃는 경우도 발생한다. 이는 아직 해결해야 할 과제를 나타낸다.색상 정보의 부재: 생성된 OBJ 파일에서 색
26.[일단 박죠] 생성형 AI 기반 면접 아바타 생성을 마무리 하며

앞으로도 취미로서 생성형 AI를 꾸준히 공부해 나갈 계획이다. 또한 AI 시대의 도래와 함께, 현재 주력으로 하고 있는 백엔드 기술과의 융합도 예상되기 때문에, 이 기술을 계속해서 탐구하는 것은 매우 가치 있는 일이라고 생각한다.
27.[일단박죠] Text2Light를 이용하여 가상 면접장 생성 #1
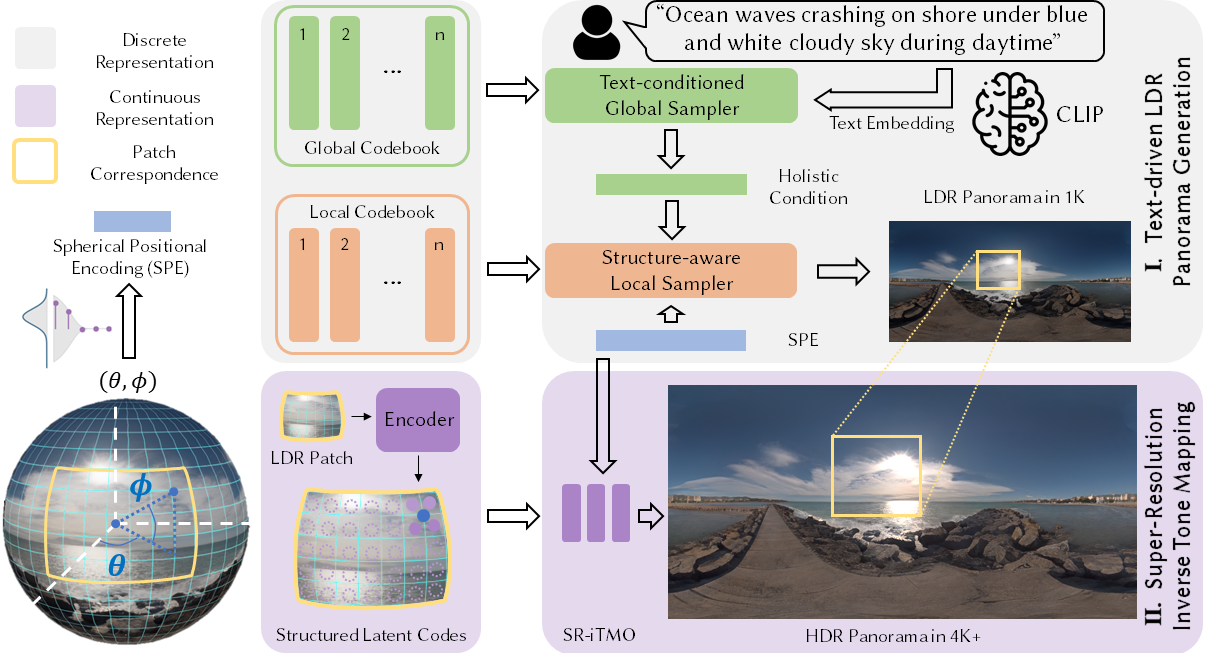
파노라마 이미지를 생성해주는 생성형 AI를 찾아보던 중 Text2Light 모델을 발견하였고, 해당 모델에 대해서 간단하게 공부한 결과를 정리하고자 한다.
28.[일단박죠] Text2Light를 이용하여 가상 면접장 생성 #2
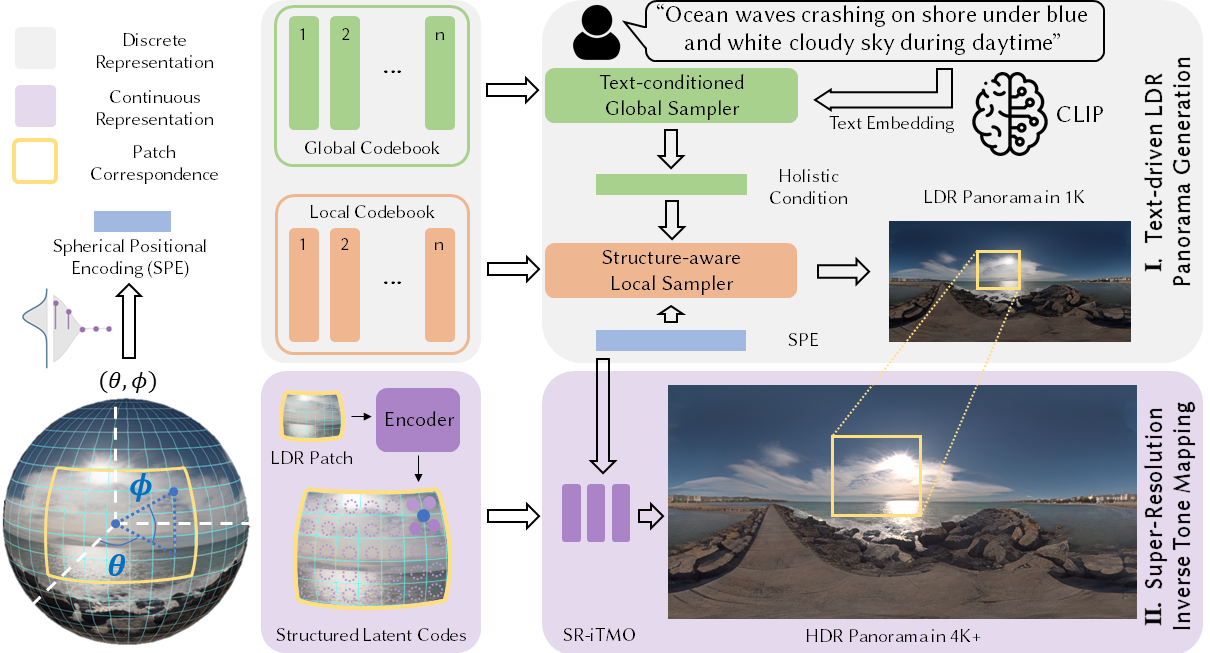
이번 게시글에서는 Text2Light 사용을 위한 환경 구축 과정 과 사용의 결과에 대한 내용을 작성할 것이다.