자료구조
1.승섭 7/17
방학을 맞아 새로운 프로젝트를 시작해서 관련해서 정리해보겠습니다,,
2.승섭 7/18
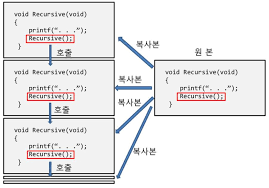
Chapter 02. 재귀(Recursive)
3.승섭 7/19

자료구조의 첫 번째 파트인 연결 리스트에 대해 정리해보겠습니다.연결 리스트를 알기 전에 먼저 리스트에는 2가지 종류가 있는데순차리스트 - 배열을 기반으로 구현된 리스트연결리스트 - 메모리의 동적 할당을 기반으로 구현된 리스트리스트의 ADT(리스트 자료구조가 제공해야할
4.승섭 7/20
원형 연결 리스트와 양방향 연결 리스트에 대해 알아보겠다.원형 연결 리스트란 전에 구현 했던 단순 연결 리스트에서 마지막 노드가 NULL을 가리켰는데 이 마지막 노드가 첫번째 노드를 가리키게 하면 이것이 바로 “원형 연결 리스트”가 된다.위의 코드는 원형 연결 리스트를
5.승섭 7/21
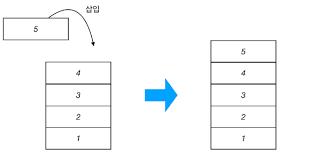
“스택” 이란 “먼저 들어간 것이 나중에 나온다!” 의 특성을 지닌 선형 자료구조의 일종이다.스택은 선입선출 방식이 아닌 ‘후입선출’(LIFO) 의 방식으로 스택의 ADT는 상대적으로 정형화된 편이다.push - 초코볼 통에 초코볼을 넣는다pop - 초코볼 통에서 초
6.승섭 7/22
큐(Queue) 는 앞서 설명한 스택과 반대로 먼저 들어간 데이터가 먼저 나오는 선입선출(FIFO) 방식의 구조이다.큐의 ADT 정의void QueueInit(Queue \* pq);큐의 초기화를 진행한다.큐 생성 후 제일 먼저 호출되어야 하는 함수이다.int QIsE
7.승섭 7/23
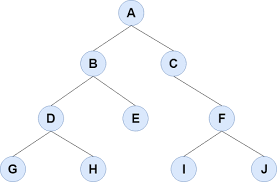
“트리는 계층적 관계를 표현하는 자료구조이다”트리와 관련된 기본적인 용어노드: node ⇒ 트리의 구성요소에 해당하는 A,B,C,D,E 와 같은 요소간선: edge ⇒ 노드와 노드를 연결하는 연결선루트 노드: root node ⇒ 트리 구조에서 최상위에 존재하는 A와
8.승섭 7/24
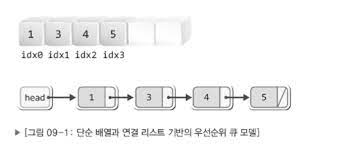
“큐”는 연산의 결과로 먼저 들어간 데이터가 먼저 나오는 FIFO 형식이다.“우선순위 큐” 는 들어간 순서에 상관없이 우선순위가 높은 데이터가 먼저 나온다.우선순위 큐의 구현 방법은 크게 3가지로 구분 된다.배열을 기반으로 구현하는 방법연결 리스트를 기반으로 구현하는
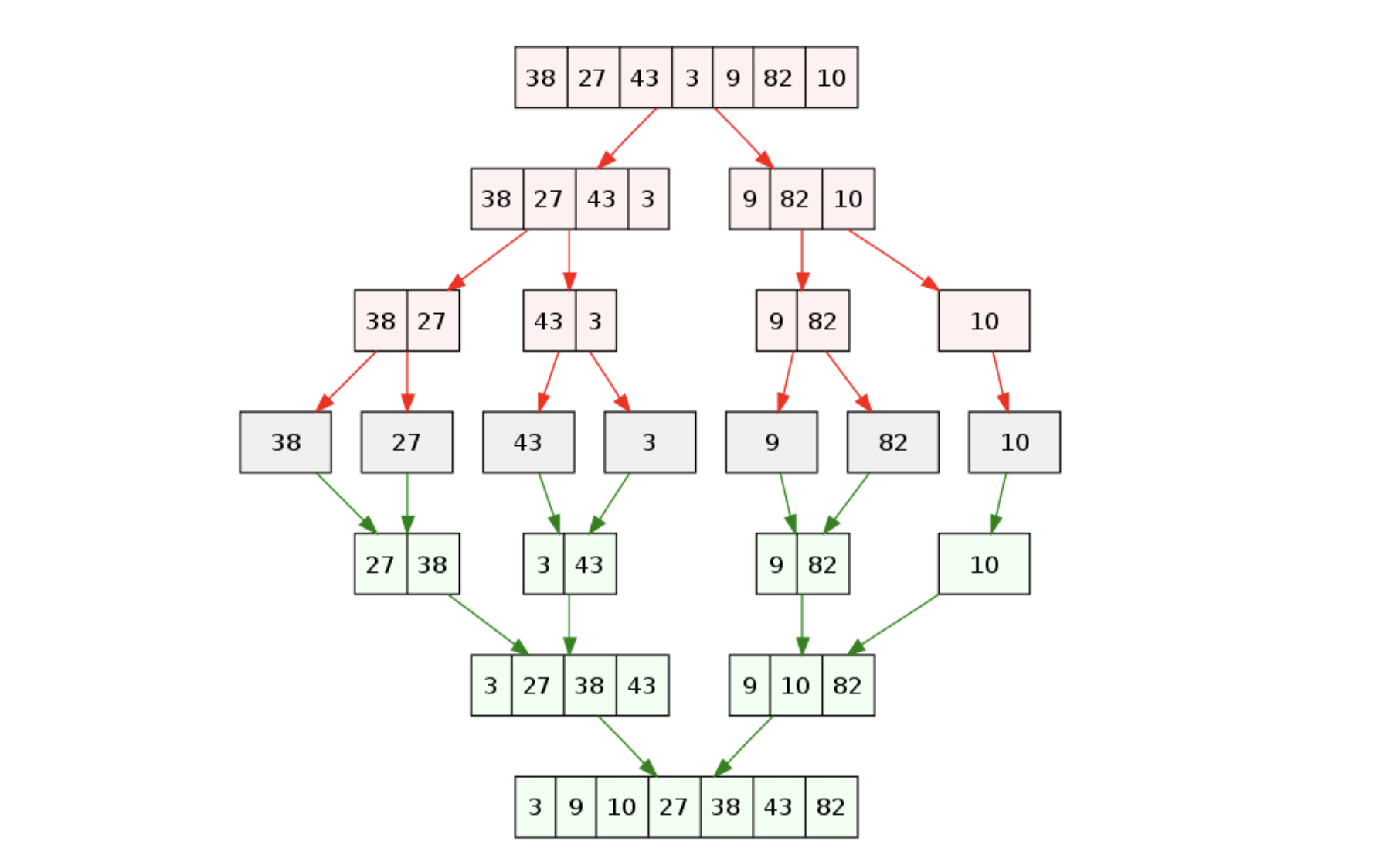
9.승섭 7/25

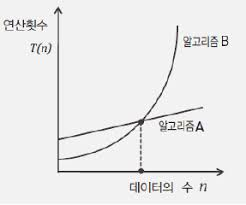
위의 그림은 버블 정렬이 이루어지는 과정을 설명한 그림이다.정렬 알고리즘의 성능 평가비교의 횟수이동의 횟수실제로 시간 복잡도에 대한 빅-오를 결정하는 기준은 “비교의 횟수”이다. 하지만 “이동의 횟수” 까지 살펴 보면 동일한 빅-오의 복잡도를 갖는 알고리즘 간의 세밀한
10.승섭 7/26
힙 정렬이란 “힙의 루트 노드에 저장된 값이 가장 커야 한다.” 라는 특성을 활용하여 정렬하는 알고리즘으로 최대 힙의 특성을 사용하여 정렬한다.코드에서 보이는 것 처럼 정렬의 대상인 데이터들을 힙에 넣었다가 꺼내는 것이 전부인데 정렬이 완료되는 이유는, 꺼낼 때 힙의
11.승섭 8/1
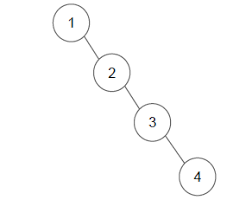
이진 탐색 트리의 연산은 O(log2n)의 시간 복잡도를 가진다. 그런데 이러한 이진 탐색 트리는 균형이 맞지 않을 수록 O(n)에 가까운 시간 복잡도를 보인다. 위의 그림과 같을때 2나 3을 루트 노드로 설정해주기만 하면 노드의 수의 가까운 높이를 형성한 트리의 성능
12.승섭 8/2

테이블 자료구조의 탐색 연산은 O(1)의 시간 복잡도를 보인다. “저장되는 데이터는 키(key)와 값(value)의 하나의 쌍을 이룬다.”“키(key)는 존재하지 않는 값은 저장할 수 없다. 그리고 모든 키는 중복되지 않는다.”위의 두개의 조건은 테이블의 기본 조건에